一種用于代碼注釋自動生成的語法輔助復制機制
2021-04-29 03:21:08許柏炎蔡瑞初梁智豪
計算機工程 2021年4期
許柏炎,蔡瑞初,梁智豪
(廣東工業大學計算機學院,廣州 510006)
0 概述
目前,代碼托管平臺Github 的提交量已達10 億,涉及337 種編程語言,但是其中大量代碼缺乏可讀的自然語言注釋[1]。代碼注釋是軟件開發的重要環節,可大幅提高代碼的可讀性,但是其過程十分耗時[2]。隨著深度學習技術的應用,自然語言生成任務得到快速發展,其中典型代表有機器翻譯[3-4]和文本摘要生成[5-7]等任務。代碼自動注釋是自然語言生成中最具挑戰性的任務之一,目標是基于輸入代碼生成相應的可理解的自然語言注釋或描述。
早期的研究人員將代碼注釋生成建模為源代碼序列到自然語言注釋序列的翻譯任務,但是不足之處在于其僅提取源代碼中的文本信息而忽略了結構信息。近年來,學者們考慮引入源代碼的結構化輸入,如抽象語法樹(Abstract Syntax Tree,AST),并采用機器學習的方法或模型來提取源代碼中結構信息的語義表達。然而,這些研究工作未充分考慮如何從結構化數據輸入中復制提取關鍵信息。代碼注釋生成的目標注釋中通常會出現目標詞典中不存在的單詞(Out Of Vocabulary,OOV),如數值型、字符型等變量單詞,從而導致生成的自然語言注釋輸出不完整。為解決該問題,研究人員在代碼注釋生成模型中引入指針網絡[8],指針網絡通過在單位時間步輸出指向輸入序列的某一個單詞,從而形成一種復制機制。但是,經典的指針網絡只支持代碼的序列化輸入,不支持代碼的結構化輸入,從而難以利用源代碼的結構化信息。同時,源代碼的抽象語法樹存在復雜多變的語法結構,使得指針網絡需花費大量的學習成本來學習復雜語法結構,導致難以準確地提取核心信息。此外,引入復制機制的代碼注釋生成模型傾向于頻繁復制核心詞,使得生成的自然語言注釋較易出現冗余信息。
本文提出一種用于代碼注釋自動生成的語法輔助復制機制。將編碼器-解碼器作為基本框架,編碼器為樹型長短期記憶網絡(Tree-LSTM)[9],解碼器為長短期記憶網絡(LSTM)[10]。由于經典的指針網絡僅支持序列結構網絡,無法直接應用于上述框架,因此本文通過改進指針網絡結構使其支持源代碼的抽象語法樹輸入。具體地,在編碼階段,編碼器網絡通過對源代碼的抽象語法樹進行編碼得到結構化的語義信息并存儲于節點的隱狀態中。在解碼階段,解碼器網絡在每個時間步通過當前隱狀態和輸入所有節點的隱狀態來計算注意力向量,并輸入到二元分類器中以選擇復制機制或生成機制。本文所提語法輔助復制機制包含基于語法信息的節點篩選策略和基于時間窗口的去冗余生成策略,前者根據語法節點類型使用掩碼向量過濾無關的語法節點,后者在時間窗口內對被復制過的節點進行概率懲罰,從而抑制重復復制該節點的現象。
1 相關工作
多數代碼注釋生成任務主要關注源代碼的文本信息。具體地,文獻[11]通過主題模型和n-gram 技術來生成代碼注釋,文獻[12]提出一種基于長短時記憶網絡與注意力機制的語言模型Code-NN,從而生成C#和SQL 注釋,文獻[13]利用卷積神經網絡與注意力機制來預測生成代碼注釋。
近年來,研究人員除考慮源代碼的文本信息外,還探究如何提取其抽象語法樹中的結構信息。文獻[14]提出結合語法結構信息和文本信息的語義表達方法。文獻[15]通過遍歷Java 的語義解析樹節點獲得序列形式,將其作為輸入以捕獲語義特征和語法信息。文獻[16]提出的Graph2Seq 將結構化查詢語言(SQL)序列看作有向圖,利用圖網絡學習全局結構信息。本文同樣采用樹型結構編碼器,輸入源代碼的語義解析樹以提取結構化信息。
目前,研究人員普遍采用經典的復制機制解決自然語言注釋生成的OOV 問題,如文獻[17]提出結合復制機制的混合生成網絡以進行文本摘要生成,文獻[18]利用復制機制復制子句,文獻[19]利用復制機制進行代碼生成。與上述工作不同,本文建立一種支持樹型結構化數據輸入的指針網絡變體,并基于源代碼的語法結構和特性,提出包含節點篩選策略和去冗余生成策略的語法輔助復制機制,以從源代碼的語義解析樹中提取關鍵內容信息。
2 代碼自動注釋模型
代碼自動注釋模型的輸入一般是源代碼對應的抽象語法樹表示,而非源代碼本身[20]。抽象語法樹省略編程語法上的部分無用細節,只保留語法結構以及與代碼內容相關的部分,作為源代碼語法結構的抽象化表示。以SQL 查詢語句為例,其對應的抽象語法樹表示如圖1 所示。

圖1 SQL 查詢語句對應的抽象語法樹表示Fig.1 Abstract syntax tree representation of SQL query statement
本文對代碼自動注釋任務進行定義:給定一個源代碼的抽象語法樹X={x1,x2,…,x|X|},目標的自然語言注釋為Y={y1,y2,…,y|Y|},其中,xi代表抽象語法樹的第i個節點,yj是自然語言注釋序列的第j個單詞。本文建立的代碼自動注釋模型是基于編碼器-解碼器框架設計的,結合編碼器(樹型長短期記憶網絡[9])、解碼器(長短期記憶網絡[10])和注意力機制[21]。在編碼階段,樹型長短期記憶網絡自下而上遞歸式地遍歷抽象語法樹,最終以根節點的隱含層表示作為抽象語法樹的語義表達向量;在解碼階段,長短期記憶網絡接收編碼器的語義表達并解碼出目標序列,在每個時間步基于當前的隱狀態與編碼階段得到的抽象語法樹上節點的隱狀態,通過注意力機制[21]計算注意力向量以復制或生成目標單詞。本文模型在給定代碼抽象語法樹X下,生成對應的自然語言注釋序列Y。其中,每個時間步t的預測輸出為yt,條件概率為p。本文采用極大似然估計(Maximum Likelihood Estimation,MLE)優化如下的目標函數:

為了解決OOV 問題,本文將復制機制引入到代碼注釋生成模型中。復制機制使得生成模型除了從目標詞典中選擇單詞外,還可從源代碼輸入中提取信息。具備復制機制的代碼注釋生成模型的目標函數可基于式(1)展開為:

其中,at表示第t個時間步執行的解碼動作,可為輸入復制或詞典生成,即at∈{gen,copy},p(at|y<t,X)表示一個伯努利分布,且p(at|y<t,X)∈{0,1}。
為了從源代碼的復雜語法結構中提取信息,本文提出一種語法輔助復制機制,該機制包含基于語法信息的節點篩選策略與基于時間窗口的去冗余生成策略。如圖2 所示,編碼器(Encoder)對源代碼的抽象語法樹進行編碼,將編碼后的語義表達(enc.embed)傳遞到解碼器(Decoder)進行解碼。解碼器使用LSTM 在每個時間步進行從源輸入復制(CP)或從詞典生成(GEN)操作。解碼器若選擇CP 操作,將執行基于語法信息的節點篩選策略(①)和基于時間窗口的去冗余生成策略(②);否則,解碼器選擇GEN操作,直接從詞典中選擇單詞。長虛線區域內的節點為經過節點篩選策略篩選后的候選語法節點,短虛線框為在時間步t時“China”節點的被復制概率的衰減過程,γ表示衰減持有率,λt-1表示上一個時間步的衰減率,p為每個節點具體的復制概率。節點篩選策略過濾抽象語法樹的無關節點,保留字符型變量節點;去冗余生成策略對已被復制的節點“China(string)”進行懲罰,防止該節點被錯誤地重復復制。
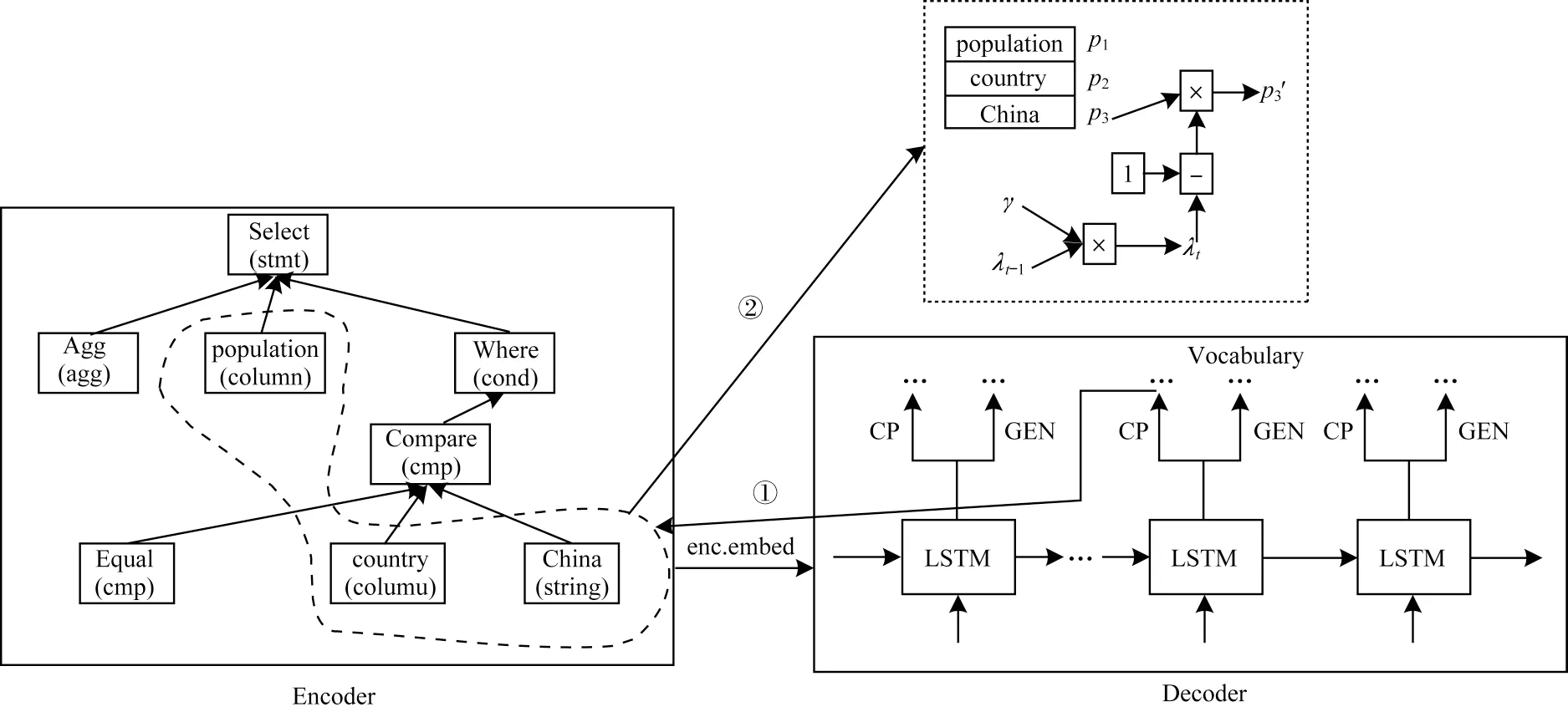
圖2 代碼自動注釋模型整體架構Fig.2 Overall architecture of automatic code comment model
3 抽象語法樹編碼
編碼階段的目標是得到抽象語法樹的語義編碼表達,本節將介紹公式化編碼過程。編碼階段分為語法節點向量化和抽象語法樹向量化2 個過程。
3.1 語法節點向量化
抽象語法樹X由多個節點組成,每個節點xi可能包含一個或者多個單詞,即。初始化詞典詞嵌入矩陣為We∈Rle×d,其中,le為輸入詞典的大小,d為詞向量維度大小。對節點i中的第j個單詞ωij構建詞典的獨熱(one-hot)索引變量id(ωij)∈Rle,可以得到ωij的詞嵌入向量如下:
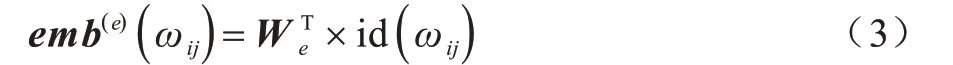
通過式(3)可以得到節點中每個單詞的詞嵌入向量,為了得到節點的向量化表示,需要獲得節點中的單詞序列表達。本文采用LSTM[10]作為序列學習網絡,在每個時間步循環地輸入序列中每個單詞ωij的詞嵌入向量,并存儲更新隱含層信息,如下:
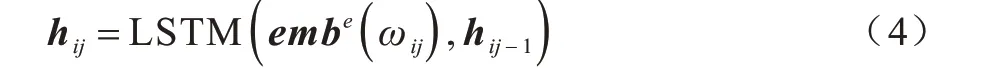

3.2 抽象語法樹向量化
通過3.1 節獲得抽象語法樹的節點向量化,編碼器需進一步將節點的表達通過抽象語法樹的結構聚合成抽象語法樹的整體表達。為了捕捉抽象語法樹的語法結構,將Tree-LSTM[9]作為編碼器,進一步對抽象語法樹進行編碼。Tree-LSTM 自下而上遞歸式和結構化地輸入抽象語法樹數據,將信息更新至節點隱狀態。與經典的LSTM 網絡相同,Tree-LSTM 同樣包含輸入門、遺忘門和輸出門,每個門都是基于節點的向量表示及其孩子節點的隱狀態。當抽象語法樹是N-ary 樹時,語法樹的非葉子節點最多存在N個孩子節點。對于任意節點j,其第k個孩子的隱狀態和單元狀態(Cell State)分別為sjk和cjk,則對節點j隱狀態的更新過程如下:
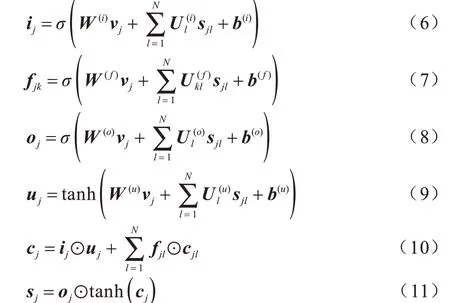
其中,ij、fjk、uj、oj∈Rd分別代表輸入門、遺忘門、輸出門和被用來更新細胞狀態cj∈Rd的狀態向量,W(?)∈Rd×d和U(?)∈Rd×d代表可學習的參數矩陣,b(?)∈Rd代表偏置向量,vj∈Rd代表節點j的向量化表示。
Tree-LSTM編碼器遞歸式地計算抽象語法樹以更新各節點的隱含層信息,根節點的隱含層狀態含有其他所有節點的語義結構信息,因此,本文將根節點的隱含層狀態作為抽象語法樹的語義結構表達,用于解碼器更新。
4 自然語言注釋
4.1 基于注意力的解碼過程
模型的解碼器負責將從編碼器得到的抽象語法樹結構語義表達迭代式地生成自然語言注釋。本文解碼器采用LSTM[10],以結構語義表達作為初始化隱狀態,按單位時間步更新輸出新的隱狀態,且解碼器輸出的隱狀態用于構造注意力向量。具體地,對于任意時間步t,解碼器LSTM 輸出的隱狀態為ot∈Rd,注意力向量qt∈Rd的計算過程如下:
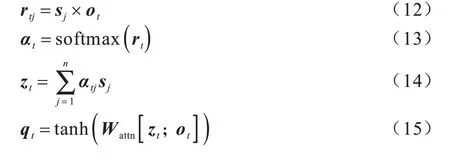
從上述公式可知,在解碼器階段,根據當前時間步t的隱狀態ot與編碼器得到的抽象語法樹各節點的隱狀態分別計算得分rtj;接著,通過softmax 函數進行歸一化得到權重向量αt∈R|X|;然后,對各節點隱狀態進行加權求和得到當前時間步的內容向量zt∈Rd;最終,利用可學習參數矩陣Wattn∈Rd×2d和tanh 激活函數融合內容向量zt和當前解碼隱狀態ot,得到注意力向量qt∈Rd。通過上述注意力機制過程,解碼器生成自然語言注釋時可以更關注抽象語法樹的相關節點,使得生成模型輸出的自然語言注釋具備更高的語義準確性。
為了解決自然語言生成的OOV 問題,本文模型引入復制機制,使其具備從源輸入中提取關鍵信息的能力。本文模型存在2 種生成來源,分別是從目標詞典中預測和從源輸入中復制提取。因此,該模型需要一種機制來選擇生成來源,本文構造基于注意力向量輸入的分類器,以選擇生成來源。構造參數為Wgc∈R2×d的全連接神經網絡,輸入注意力向量產生at∈{gen,copy}二元概率分布,如下:

當預測概率大于復制概率時,解碼器選擇從目標詞典中生成。具體地,構造參數為Wgen∈Rld×d的全連接神經網絡,輸入注意力向量產生目標詞典的概率分布,如下:

4.2 語法輔助復制機制
4.1節介紹了解碼器生成來源為目標詞典下的解碼過程,本節將重點闡述當生成來源為源輸入信息時的解碼過程,并通過語法輔助來提高復制提取的準確率。
當生成來源分類器輸出的復制概率大于預測概率時,解碼器將從輸入信息中進行復制提取。具體地,對時間步t的注意力向量qt,計算其與編碼器中抽象語法樹各節點隱狀態的得分向量gt∈R|X|,歸一化后選擇概率最大的節點并復制其中的文本信息,過程如下:
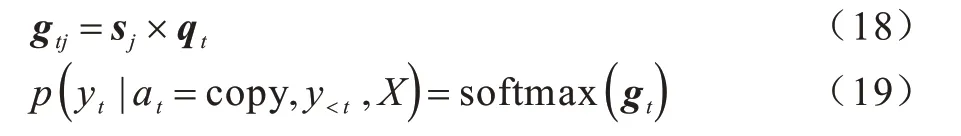
從上述過程可以看出,復制機制與注意力機制實現過程相似,但是復制機制依賴于注意力機制的注意力向量并進行二次計算。
4.2.1 基于語法信息的節點篩選策略
代碼自動注釋任務的輸入是程序代碼的抽象語法樹,其具有復雜多變的結構信息。現有的復制機制多為非結構化輸入數據而設計,模型需要花費大量的時間學習如何從復雜結構中提取有用的信息,且提取效果通常不佳。本文利用語法輔助復制機制從抽象語法樹中提取關鍵信息。對于代碼自動注釋任務而言,關鍵信息一般為抽象語法樹上的數值型節點和字符型節點。因此,本文將復制過程的搜索范圍從語法樹所有類型的節點壓縮至這兩類節點,該過程可以降低搜索空間,也能夠減少抽象語法樹結構變化所帶來的干擾以及神經網絡的學習成本。
本文通過引入掩蓋變量來過濾無效候選節點。假設時間步t的節點掩蓋向量為dt∈R|X|,長度為節點數,取值為0 或-∞,0 代表對應語法節點有效,-∞代表節點無效,將其從候選節點集中剔除。在復制過程中,剔除無效節點后余下候選節點的概率計算公式如下:

由上述過程可得到復制機制下當前時間步對應的損失函數為:
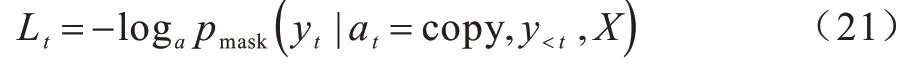
一方面,通過掩蓋向量可以剔除無效節點,使得無效節點集概率恒等于0,正確節點掩蓋后的概率大于等于原始概率,當前時間步的損失下降,神經網絡的整體成本函數也會下降;另一方面,從候選節點集合中過濾無效候選節點,可以使得當前時間步搜索空間得到一定的壓縮。因此,節點篩選策略在一定程度上可以加速神經網絡的學習。
4.2.2 基于時間窗口的去冗余生成策略
現有代碼自動注釋方法生成的自然語言注釋存在主要關鍵詞冗余與部分關鍵詞缺失的現象,造成該現象的原因是復制機制與注意力機制原理相近,導致指針網絡傾向于重復指向最具注意力的少數節點,而忽略了其他有用節點。為解決上述問題,本文提出一種基于時間窗口的去冗余生成策略,通過在時間窗口內對已被復制的語法節點的復制概率進行衰減,從而提高候選集合中其他有用且未被復制的節點被初次復制的概率。具體地,對于一個已被復制的語法節點xi,設置基于時間窗口變化的衰減率λit,用超參數γ∈(0,1) 表示衰減持有率,用于控制每次衰減率的減少量。λit表示如下:

在時間步t下,抽象語法樹候選節點集合有一一對應的衰減變量集合。結合基于語法信息的節點篩選策略和基于時間窗口的去冗余生成策略,最終抽象語法樹復制候選節點的概率分布如下:

5 實驗結果與分析
5.1 數據集
本文采用結構化查詢語言(SQL)和邏輯表達式(Lambda)2 種不同編程語言的源代碼數據進行測試,源代碼數據分別來自WikiSQL[22]和ATIS[23]數據集。WikiSQL 數據集數據來源于維基百科,含有24 241 個小規模數據表格,基于以上數據表格產生80 654 個結構化查詢語句-自然語言對。ATIS 數據集數據來源于現實航空業務數據庫,含有25 個真實數據表,基于以上數據表格產生5 373 個邏輯表達-自然語言對。為了驗證各方法的有效性,將WikiSQL 數據集進一步劃分為分別含有56 355 個樣本的訓練集、8 421 個樣本的驗證集和15 878 個樣本的測試集。同樣地,將ATIS 數據集劃分為分別含4 434 個樣本的訓練集、491 個樣本的驗證集和448個樣本的測試集。上述數據集涉及的2種編程語言均可通過抽象語法描述語言(Abstract Syntax Description Language,ASDL)來獲得對應的抽象語法樹。其中,SQL 結構化查詢語言和Lambda 邏輯表達式的ASDL 語法分別在文獻[24]和文獻[25]中有所定義。
5.2 基準方法
本文將具有代表性的兩類結構性方法作為實驗的基準方法,其中包括樹至序列(Tree to Sequence,Tree2Seq)模型[26]和圖至序列(Graph to Sequence,Graph2Seq)模型[16],以上基準方法均采用注意力機制。需要注意的是,Tree2Seq 模型輸入結構為源代碼的抽象語法樹,而Graph2Seq 模型的原文輸入結構是專為SQL 查詢語句設計的圖結構,其無法支持Lambda 邏輯表達式,而且原文沒有提供為SQL 查詢語句轉換的預處理代碼。因此,本文將統一采用抽象語法樹作為Graph2Seq 模型的輸入結構。編程語言的抽象語法樹表示具有普遍性,可應用于大部分編程語言。具體地,本文將源代碼的抽象語法樹看作一個無向圖,父、子節點之間的連接看作圖節點的邊。此外,為了更好地驗證語法輔助復制機制的性能,本文在Tree2Seq 模型中引入一種傳統的復制機制。
5.3 評價指標
本文采用BLEU[27]和ROUGE[28]作為自然語言注釋生成的評價指標。BLEU 是自然語言處理任務常用的評價指標,其通常從字符或單詞級別來評價2 個文本或2 個文本集合的相似度。ROUGE 指標評價所生成文本句子的充分性和忠實性,為了提高所生成文本的連貫性,本文使用考慮文本上下文的ROUGE 指標,分別為ROUGE-2 和ROUGE-L。
5.4 實驗設置
實驗參數設置如下:詞向量、編碼器和解碼器的隱狀態維度大小均為128 維,批量大小均設置為32 個,梯度優化器選擇Adam 優化器[29],學習率設置為0.001。此外,為了降低詞典大小,源詞典和目標詞典只記錄詞頻不低于4 的單詞。實驗沒有采用由其他語料庫預訓練的詞向量,如Word2Vec[30]和Glove[31]等,而是使用xavier 初始化器[32]隨機初始化詞向量。本文所提復制機制中基于時間窗口的去冗余生成策略的衰減持有率,在WikiSQL 和ATIS 數據集中分別設置為80%和90%時系統性能達到最優,5.5.3 節將對該參數進行詳細的敏感性分析。
5.5 結果分析
5.5.1 模型性能分析實驗
表1 和表2 所示分別為本文模型和基線模型在WikiSQL 和ATIS 2 個數據集上進行代碼自動生成的實驗結果,其中最優結果加粗表示。從中可以看出,本文模型在WikiSQL 數據集中的性能表現明顯優于2 個基線模型,與最佳基線模型Tree2Seq+copy 相比,本文模型的BLEU 提升14.5%,ROUGE-2 和ROUGE-L 分別提升10.3%和5.5%。在ATIS 數據集上,與最佳基線模型Tree2Seq+copy 相比,本文模型的BLEU 提升2.8%,ROUGE-2 和ROUG-L 分別提升6.6%和2.5%。上述結果表明,本文模型相比現有代碼注釋生成方法有顯著的性能提升,其能生成更加準確的代碼自然語言注釋。
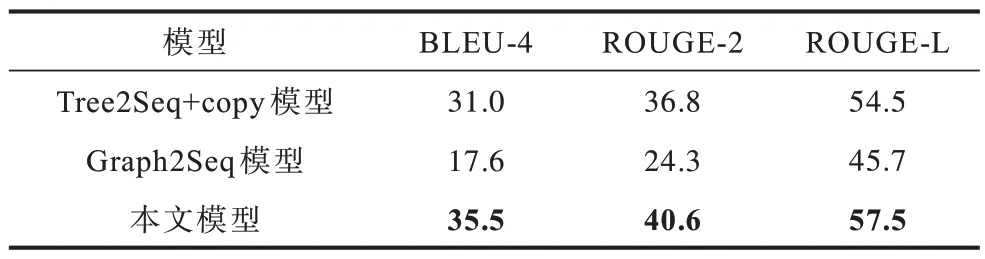
表1 3 種模型在WikiSQL 數據集上的性能對比結果Tabel 1 Performance comparison results of three models on WikiSQL dataset
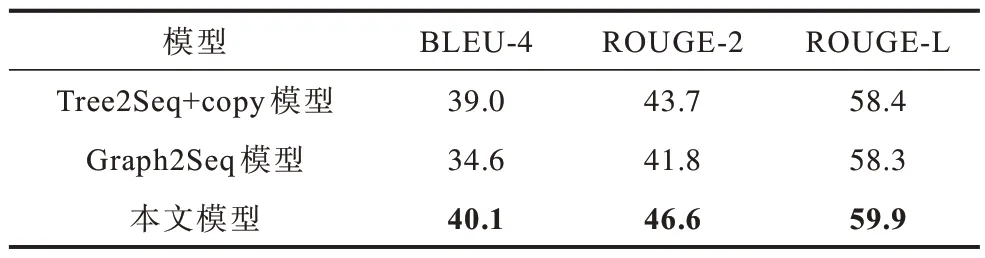
表2 3 種模型在ATIS 數據集上的性能對比結果Tabel 2 Performance comparison results of three models on ATIS dataset
5.5.2 節點篩選策略的有效性實驗
為了量化節點篩選策略在壓縮搜索空間方面的性能,本文統計WikiSQL 和ATIS 數據集單位時間步內的平均候選節點個數,結果如表3 所示。從表3 可以看出,通過節點篩選策略過濾無效的語法節點,在WikiSQL 數據集中候選節點空間的壓縮比例超過60%,在ATIS 數據集中壓縮比例超過50%,即節點篩選策略能大幅降低代碼注釋生成的搜索空間。
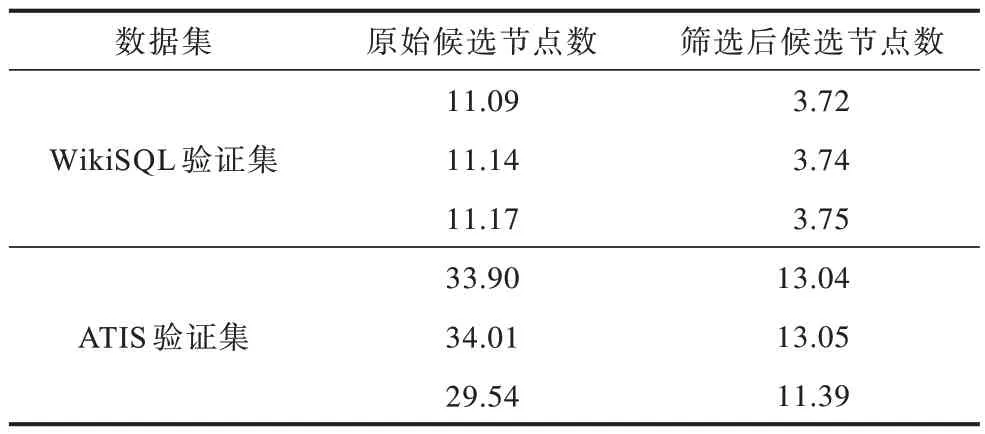
表3 2 種數據集在單位時間步內的平均候選節點數Table 3 The average number of candidate nodes per unit time step of two datasets
為了驗證節點篩選策略在收斂速度方面的性能,本文在WikiSQL 的驗證集下測試BLEU 指標的收斂趨勢。為了公平有效地對比,在本文模型中去除去冗余生成策略,僅保留節點篩選策略,并與結合復制機制的Tree2Seq 模型進行對比,結果如圖3 所示。從圖3 可以看出,相比基線模型,僅保留節點篩選策略的本文模型收斂速度有所提升,即節點篩選策略能在一定程度上加速神經網絡的學習。
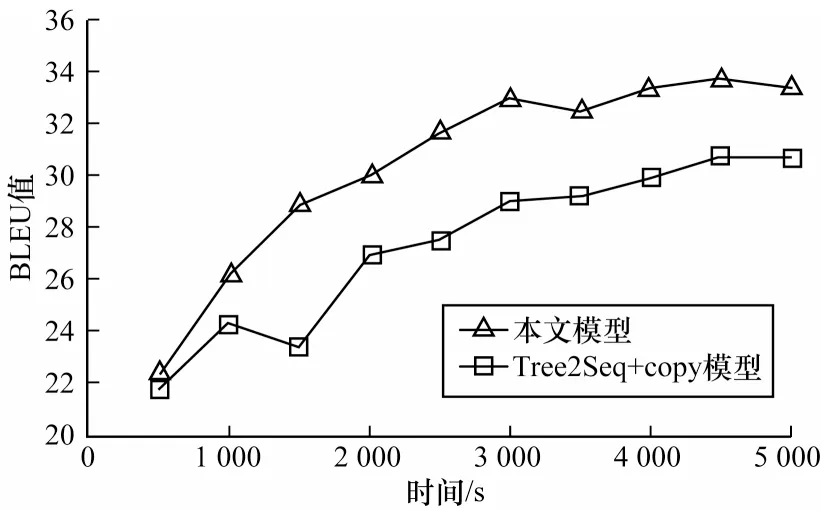
圖3 2 種模型在WikiSQL 驗證集上的收斂速度對比Fig.3 Convergence rate comparison of two models on WikiSQL verification set
5.5.3 衰減持有率的敏感性實驗
為了驗證去冗余生成策略中的衰減持有率對模型影響的敏感程度,本文在WikiSQL 和ATIS 數據集上設計針對衰減持有率的敏感性實驗,結果如圖4和圖5 所示。從圖4 可以看出,在WikiSQL 數據集上,當衰減持有率為80%時,模型達到該數據集上的最高BLEU 值。從圖5 可以看出,在ATIS 數據集上,當衰減持有率為90%時,模型達到該數據集上的最高BLEU 值。衰減持有率能夠直觀反映自然語言注釋中一個字或詞重復出現的間距,圖4 和圖5 的實驗結果表明,在2 個數據集上重復字詞出現的間距均較大。
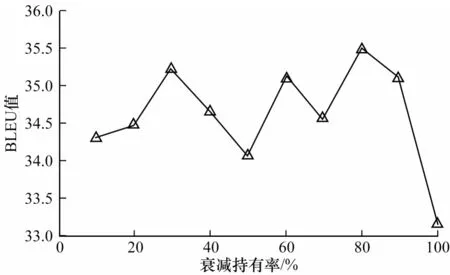
圖4 WikiSQL 測試集上的衰減持有率敏感性實驗結果Fig.4 Sensitivity experimental results of decay keeping probability on WikiSQL test set

圖5 ATIS 測試集上的衰減持有率敏感性實驗結果Fig.5 Sensitivity experimental results of decay keeping probability on ATIS test set
5.5.4 分離實驗
為了更好地體現基于語法信息的節點篩選策略和基于時間窗口的去冗余生成策略在模型中的重要性,本文設計分離實驗以驗證去除其中一種策略后的模型性能,測量不同的變種模型在WikiSQL 和ATIS 驗證集上的BLEU 值變化。本文定義如下的變種模型:
1)Ours-SA:只去除基于語法信息的節點篩選策略的模型,其他保持不變。
2)Ours-CD:只去除基于時間窗口的去冗余生成策略的模型,其他保持不變。
分離實驗結果如表4 所示,從表4 可以看出,與原始模型相比,Ours-SA 和Ours-CD 的BLEU 值在2 個數據集上均出現明顯下降,驗證了本文所提2 種策略的有效性。此外,基于時間窗口的去冗余生成策略對WikiSQL 影響較大,去除該策略后模型的BLEU 值降低超過10%,而2 種策略對ATIS 數據集的影響相差不大。

表4 2 種數據集上的分離實驗結果Table 4 Results of separation experiments on two datasets
6 結束語
本文提出一種用于代碼注釋自動生成的語法輔助復制機制,其中主要包括節點篩選策略和去冗余生成策略2 個部分。實驗結果表明,與Tree2Seq+copy 和Graph2Seq 模型相比,該機制的BLEU 和ROUGE 指標值均較高。下一步將在代碼注釋生成模型框架中引入語法信息,以提升模型對復雜語法的學習效果。
猜你喜歡
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
文苑(2018年21期)2018-11-09 01:23:06
數學大世界(2018年1期)2018-04-12 05:39:14
中華手工(2017年2期)2017-06-06 23:00:31
中國衛生(2015年9期)2015-11-10 03:11:12
中外會展(2014年4期)2014-11-27 07:46:46
中國衛生(2014年3期)2014-11-12 13:18:12
時代英語·高三(2014年5期)2014-08-26 02:49:51
中國火炬(2014年4期)2014-07-24 14:22:19
