基于游客好奇心的旅游信息推薦系統(tǒng)
2021-04-29 08:40:50劉娜
微型電腦應用 2021年4期
劉娜
(陜西工業(yè)職業(yè)技術學院 財經與旅游學院, 陜西 咸陽 71200)
0 引言
隨著我國旅游市場的逐漸擴大,景區(qū)、景點層出不窮,增加了游客在海量旅游信息中的篩選難度[1]。因此,設計一款按照游客興趣進行主動推薦的旅游信息系統(tǒng)十分必要,能夠極大程度為游客服務。推薦系統(tǒng)的核心為推薦算法,例如在各個領域都有廣泛應用的上下文感知推薦算法、協(xié)同過濾推薦算法、混合推薦算法和興趣點算法等[2]。但現(xiàn)有算法各自的缺點也十分明顯,不適合旅游信息的推薦。因此,本文結合游客好奇心設計一種個性化推薦算法,并開發(fā)旅游信息推薦系統(tǒng),以期為游客提供更好的旅游信息服務。
1 個性化推薦算法設計
由于游客評分、景點信息、訪問記錄等信息數(shù)據(jù)量龐大,本設計采用爬蟲技術從旅游及景點相關網站上爬取數(shù)據(jù)。經過數(shù)據(jù)分析發(fā)現(xiàn),不同游客訪問景點的分布具有很大差異,訪問時期也存在差異。結合游客興趣將其分為三種,即興趣單調游客、興趣多樣性游客和興趣變化游客。其中,興趣單調游客喜歡景點的類別比較單一,大多旅游目的地都是該類景點,具有固定興趣點;興趣多樣化游客喜歡的景點類別多樣,分布差別不大,也屬于固定興趣點的游客;興趣變化游客會隨著時間改變訪問景點,興趣變化存在很大不確定性,難以預測。
由此可見,無論是按照游客興趣點還是群體進行推薦算法設計,都不能對游客情況進行很好地描述。因此,本設計引入游客好奇心作為描述游客情況的特征參數(shù),利用新穎度分布來描述好奇心,能夠有效解決游客興趣點不確定的問題。經過調查分析,新穎度高的景點類型被游客選擇次數(shù)明顯高于其他,說明游客對該類景點具有很大好奇心。因此,針對興趣固定的游客推薦新穎度低的景點,對興趣不固定的游客推薦新穎度高的景點。
本設計將游客歷史行為轉化為可描述好奇心的新穎度公式,設計推算算法流程,如圖1所示。
步驟一:新穎度分布構建,通過游客歷史訪問記錄得到游客所去景點的新穎度,經過統(tǒng)計得到游客新穎度選擇分布情況,即游客好奇心。


圖1 推薦算法流程
(1)


(2)

最后,建立新穎度計算式,如式(3)。
(3)
步驟二:構建新穎度區(qū)間分數(shù)。每個游客的新穎度選擇分布存在一定的差異,可依據(jù)分布情況計算景點的新穎度個性化推薦分數(shù),以描述游客好奇心與景點的匹配程度。
步驟三:集合協(xié)同過濾分數(shù)和個性化推薦分數(shù)生成景區(qū)推薦列表。其中,協(xié)同過濾分數(shù)可描述游客度對景點的評分,個性化推薦分數(shù)可描述游客對該類景點的傾向,兩者結合即可得到推薦策略。
2 推薦系統(tǒng)設計與實現(xiàn)
旅游信息推薦系統(tǒng)按照層級結構進行設計,分為四個層次,即業(yè)務應用層、模型層、數(shù)據(jù)處理層和數(shù)據(jù)采集層,如圖2所示。

圖2 推薦系統(tǒng)架構
2.1 數(shù)據(jù)采集層
數(shù)據(jù)是推薦系統(tǒng)的基礎,因此系統(tǒng)首先要對網絡數(shù)據(jù)進行大量地采集。本系統(tǒng)采用python語音實現(xiàn)分布式爬蟲功能,抓取互聯(lián)網上的網頁信息。通過與旅游相關類網站的特定連接,實現(xiàn)對HTML信息的獲取。系統(tǒng)使用xpath網頁解析包對HTML網頁階段進行數(shù)據(jù)發(fā)現(xiàn),通過內容節(jié)點來鎖定數(shù)據(jù)路徑,最終獲得海量旅游相關數(shù)據(jù)流程,如圖3所示。

圖3 數(shù)據(jù)采集實現(xiàn)流程
2.2 數(shù)據(jù)處理層
數(shù)據(jù)采集完成后需要按照特定需求對數(shù)據(jù)進行處理,使其能夠運用到模型層和業(yè)務應用層。數(shù)據(jù)處理層分為數(shù)據(jù)清洗和存儲兩個部分。其中,數(shù)據(jù)清洗是刪除不屬于景點的一類信息,如沒有相關描述的小景點數(shù)據(jù)(缺乏項目介紹),或者不屬于景點的數(shù)據(jù),如酒店、洗浴等信息。以此來提高推薦的準確度。此外,數(shù)據(jù)清洗還要刪除游客訪問記錄中不屬于國內的景點信息。
完成數(shù)據(jù)清洗后將數(shù)據(jù)存儲到系統(tǒng)的Postgre數(shù)據(jù)庫中,通過該數(shù)據(jù)庫的外鍵設置完成對某些數(shù)據(jù)重要屬性的限制,并利用SQL語言對其進行操作,最后按照屬性不同生成景點列表和用戶訪問列表。景點列表主要記錄了景點信息,如景點介紹、所處省份、城市等。用戶訪問列表是推薦系統(tǒng)的主要數(shù)據(jù)來源,通過自增加ID作為主鍵,包括用戶ID、景點評分、訪問時間、景點名稱等,如圖4所示。

圖4 數(shù)據(jù)處理實現(xiàn)界面
2.3 模型層
該層主要是利用上文設計的推薦算法對數(shù)據(jù)進行計算,實現(xiàn)旅游信息的主動推薦功能。該層與系統(tǒng)數(shù)據(jù)庫進行協(xié)調工作,提取推薦算法和景點分類的數(shù)據(jù),最終得到推薦結果,如圖5所示。

圖5 推薦列表實現(xiàn)過程
景點分類部分,首先提取景點描述分詞,篩選出關鍵詞后構建詞向量,輸入至分類型進行可能性計算,最后得到分類結果。將結果按照順序進行排列并增加ID主鍵后,更新至景點列表中。利用前文的推薦算法對新穎度分布進行計算,結合協(xié)同過濾得到推薦結果列表。
2.4 業(yè)務應用層
業(yè)務應用層主要展示系統(tǒng)的推薦結果,該層框架采用Django框架進行設計,方便網站后期的維護和安全,采用Python語言編寫,該設計方法不受特定服務器平臺的限制,可使該系統(tǒng)作為一個模塊融入到旅游網站現(xiàn)有的平臺中,可為更多旅游信息網站進行服務。該系統(tǒng)與某智慧旅游網站融合后的推薦結果,如圖6所示。

圖6 旅游信息推薦系統(tǒng)用戶頁面展示
3 系統(tǒng)應用對比
為了驗證本文設計的旅游信息推薦系統(tǒng)的有效性和優(yōu)越性,選擇三種主流的旅游信息推薦系統(tǒng)進行對比,分別為基于用戶協(xié)同過濾的旅游信息推薦系統(tǒng)(系統(tǒng)A)[3]、基于景點標簽的旅游信息推薦系統(tǒng)(系統(tǒng)B)[4]和基于景區(qū)內容的旅游信息推薦系統(tǒng)(系統(tǒng)C)[5]。采用爬蟲技術收集攜程網上的用戶歷史訪問記錄,包括用戶ID、景點名稱、訪問時間和評分,共計320萬條記錄,其中包括61 284個景點和41 368個用戶。將該系統(tǒng)與三種主流系統(tǒng)的推薦結果進行對比,分布比對推薦準確率、用戶召回率和景點覆蓋率。對比過程中,將近鄰數(shù)作為控制變量,通過改變用戶推薦時使用的近鄰個數(shù)來比對不同系統(tǒng)的推薦效果。
推薦準確率、用戶召回率和景點覆蓋率對比結果,如圖7—圖9所示。

圖7 推薦準確率對比結果
由圖7—圖9可知,各系統(tǒng)準確率隨著近鄰數(shù)的增加都有所提升,在近鄰數(shù)相同的情況下本文設計的系統(tǒng)準確率更高,即使在近鄰數(shù)較小的情況下本系統(tǒng)的推薦準確率也明顯高于其他系統(tǒng)。各系統(tǒng)的用戶召回率隨著近鄰數(shù)的增加而增大,即用戶可能感興趣的景點所得分數(shù)越高。各系統(tǒng)景點覆蓋率隨著近鄰數(shù)的增大而有所降低,這是因為用戶訪問的景點大多為熱門景點,推薦過程中會向流行度較高的景點靠攏,導致冷門景點覆蓋率降低。對比結果發(fā)現(xiàn),本文系統(tǒng)無論是在近鄰數(shù)較小還是較大的情況下,均有不錯的表現(xiàn),具有一定的優(yōu)勢。
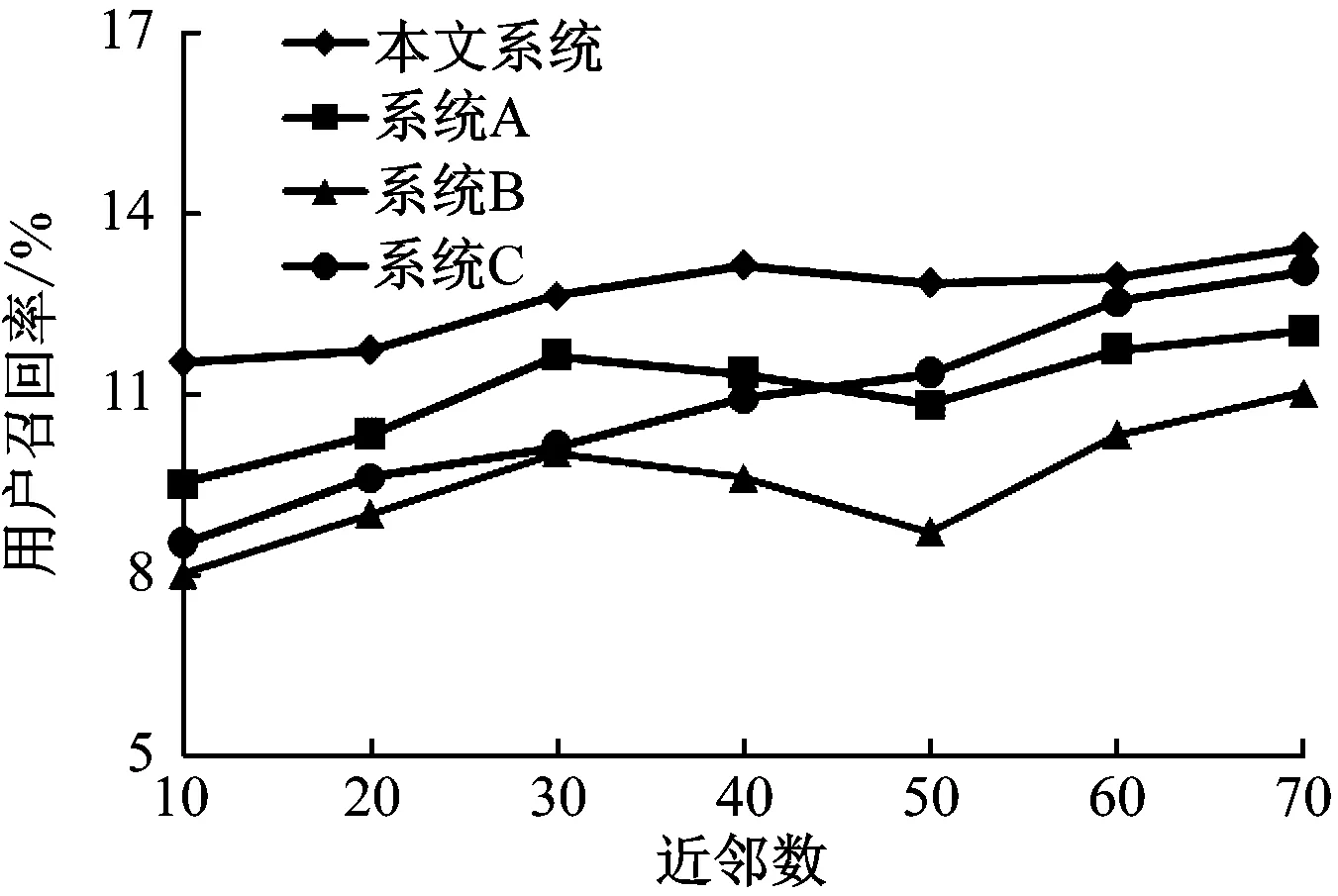
圖8 用戶召回率對比結果

圖9 景點覆蓋率對比結果
4 總結
針對當前推薦系統(tǒng)的問題,提出了基于游客好奇心行為的旅游信息推薦系統(tǒng)。該系統(tǒng)將景點游客訪問頻率和時間間隔作為構建參數(shù),設計了新穎度計算公式來反映游客好奇心,并將該算法融入到推薦系統(tǒng)中。該系統(tǒng)結合爬蟲技術爬取互聯(lián)網中旅游相關信息,通過數(shù)據(jù)清洗和存儲利用推薦算法生成推薦結果,在業(yè)務應用層直觀地展示給游客。經過與三種主流的旅游信息推薦系統(tǒng)對比可知,本文系統(tǒng)在推薦準確率、用戶召回率和景點覆蓋率方面均存在一定的優(yōu)勢。該算法及系統(tǒng)設計為旅游信息推薦方式的研究提供了參考。
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
今古傳奇·故事版(2016年24期)2017-02-07 04:29:04
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創(chuàng)業(yè)家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
數(shù)學大王·低年級(2014年7期)2014-08-11 16:36:44
海外英語(2013年8期)2013-11-22 09:16:04
祝您健康(1987年3期)1987-12-30 09:52:32
