社交網站數據采集與熱點分析技術研究
2021-04-29 06:56:24黃德勝
微型電腦應用 2021年4期
黃德勝
(廣州衛生職業技術學院 基礎學院, 廣東 廣州 510925)
0 引言
實現快速準確的社交網站數據采集與熱點分析,有利于及時發現熱點信息。眾所周知,社交網絡是用戶在線交流、傳播信息的重要場所。社交網絡可以讓所有用戶都能夠自由注冊賬戶,與其他人建立聯絡,同時還能夠查看其他好友的動態,為人們帶來了很大便利。然而任何事情都有兩面性,在社交網絡用戶以及信息不斷增長的同時,去中心化問題也尤為突出。社交網絡中的信息具有稀疏性、高維性、主題不均勻等特點,這些特點導致用戶難以獲取自己感興趣的話題以及某一時間段內的熱點話題。因此,如何從雜亂無章的海量社交網絡信息中提取到熱點話題是一個巨大的挑戰。
當前常使用的關于社交網絡數據采集與熱點分析的方法有兩種,一種是基于時間序列的社交網站數據與熱點分析方法;另一種是基于事件關聯的社交網絡數據采集與熱點分析方法。其中基于時間序列的社交網站數據與熱點分析方法主要是將一定情況、場景或者某一個統計維度在不同時刻點上的各個數據,按照時間的先后順序排列而成的序列,能夠研究隨機數據序列所服從的統計特征,從而對社交網絡的熱點進行分析。基于事件關聯的社交網絡數據采集與熱點分析方法主要對采集的大量網絡安全事件信息進行分析,從中查找到關聯數據,從而分析社交網站數據熱點。
盡管這兩種方法在社交網站的數據采集與熱點分析中分別具有一定優勢,但依舊存在部分問題,為了提高社交網站的數據采集與熱點分析的速度以及準確性,本研究設計了一種社交網站的數據采集與熱點分析方法。首先進行社交網絡數據的采集與預處理,再通過計算社交網站數據語義相似度對相關數據進行檢索,最后計算社交網站中的數據熱度,完成社交網站的數據采集與熱點分析。實驗證明,本研究設計的社交網站的數據采集與熱點分析方法能夠及時發現熱點信息。
1 社交網絡數據采集
數據采集通過網絡爬蟲抓取指定社交網絡平臺上的原始數據[1-2],下載到計算機中作為社交網絡數據熱點分析的數據源,并從這些數據源中抽取有價值的信息,主要包括用戶信息、發布時間、文本內容、評論信息以及關注人數等,將這些信息轉化為結構數據存儲到數據庫中。網絡爬蟲可以自動采集所有其能夠訪問到的頁面內容,為搜索引擎和大數據分析提供數據來源。在抓取工作中,首先選取一部分種子統一資源定位符(Uniform Resource Location、URL),將其放入待抓取URL隊列中,從中取出待抓取URL,解析DNS得到主機的IP地址,并將URL對應的網頁下載下來存儲到已下載網頁庫中。此外,將以上URL放進已抓取URL隊列,再分析已抓取URL隊列中的URL,分析其中的其他URL,并且將這些URL放入待抓取URL隊列,在此基礎上進入下一個循環。網絡爬蟲工作流程,如圖1所示。

圖1 網絡爬蟲工作流程
由于本研究采集的數據中包含重復數據,因此需要對采集的數據進行分詞處理與過濾。處理流程,如圖2所示。

圖2 社交網站數據分詞處理流程圖
在此基礎上,選取社交網站數據特征,其處理流程如下所示。
Step1:采用TF-IDF(Term Frequency-inverse Document Frequency)權值計算方法,計算經過分詞的社交網站數據詞頻。其中TF-IDF權值計算方法的主要思想是分析某個數據在一個網站中出現的頻率值[4],如果該數據在其他數據中很少出現,則認為此數據具有很好的類別區分能力;
Step2:將數據高維向量空間[5]進行降維縮減;
Step3:提取最能反映社交網站數據的特征向量;
Step4:存儲特征數據。
以此,通過上述過程完成社交網絡數據分詞的處理,通過分詞可得到每個數據對應句子的權重,其流程如下所示。
第一:特征數據存儲;
第二:社交網站特征數據加權處理;
第三:按照上述權重計算結果對原文數據排序,完成數據分詞權重的處理。
2 社交網站數據熱點分析
2.1 數據語義相似度計算
在上述社交網站數據采集的基礎上,對社交網絡數據熱點進行分析。在分析過程中,需要將獲取的數據轉換為計算機內部能理解的形式以進行數值運算[6]。因此建立向量空間模型,即對文本數據建模[7]。向量空間模型的主要思想是將數據看成孤立的、互不相關的部分,以將文本數據轉化為多維度的空間向量。向量空間模型中文本與空間存在的關系,如圖3所示。
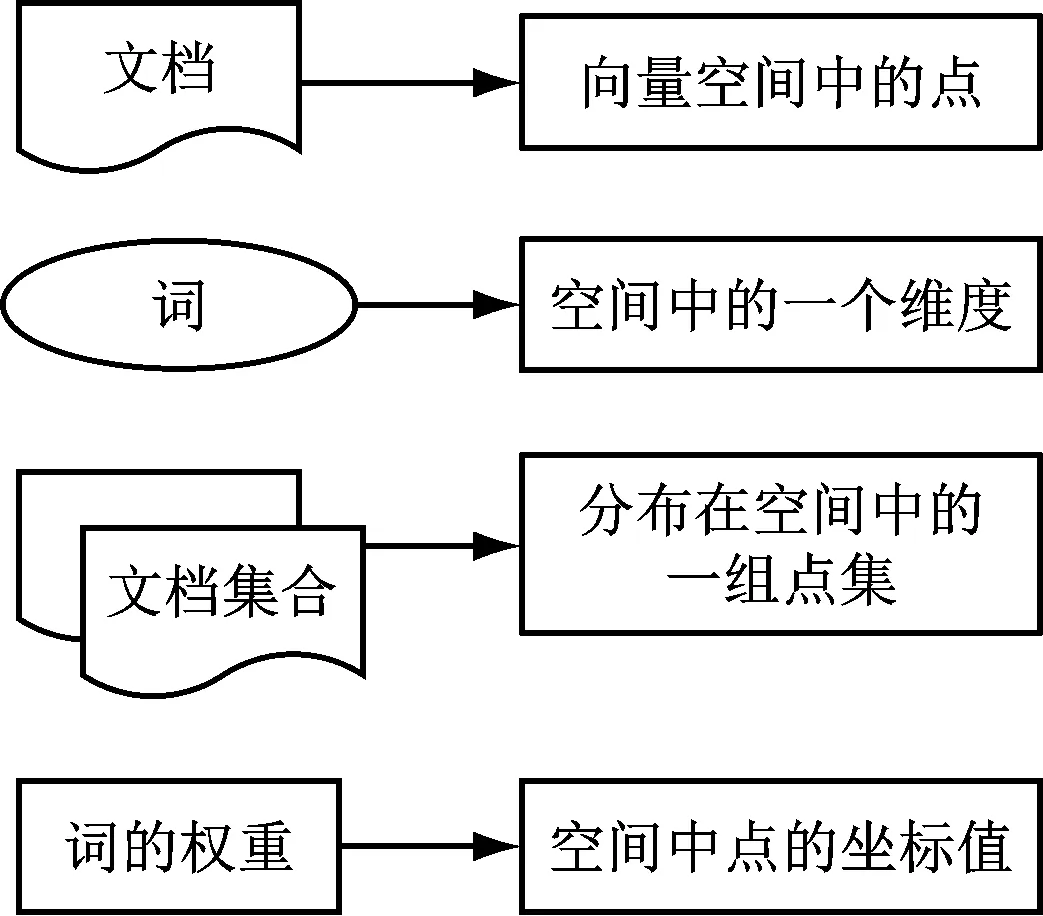
圖3 向量空間模型中文本與空間存在的關系
將社交網站文本數據轉換為空間向量后,就可以進行相關計算,通過向量空間模型將整個數據映射為一個特征向量,如式(1)。
Q=D+R/x
(1)
式中,D表示社交網站文本數據中互不相同的詞條項;R表示社交網站文本數據詞頻函數;x表示數據在文檔中出現的次數。
在此基礎上,計算數據語義相似度[8],這是由于社交網絡數據熱點分析過程中,數據之間具有相關性,因此采用語義相似度的方法度量數據相關性。語義相似度方法主要以信息特征為計算基礎,通過分析兩個概念在知識庫中共享信息情況,計算二者所有信息的比率[9],如式(2)。
(2)
式中,X表示最小上層詞語的深度;y表示詞語包含的語義信息;d表示同義詞集合中元素集合中的部分。
2.2 相關數據檢索
尋找社交網站中熱點數據,需要依據語義相似度計算結果建立事件關聯圖[10],以分析數據之間的關聯關系。對相關數據檢索通過兩個方面展開,如圖4所示。
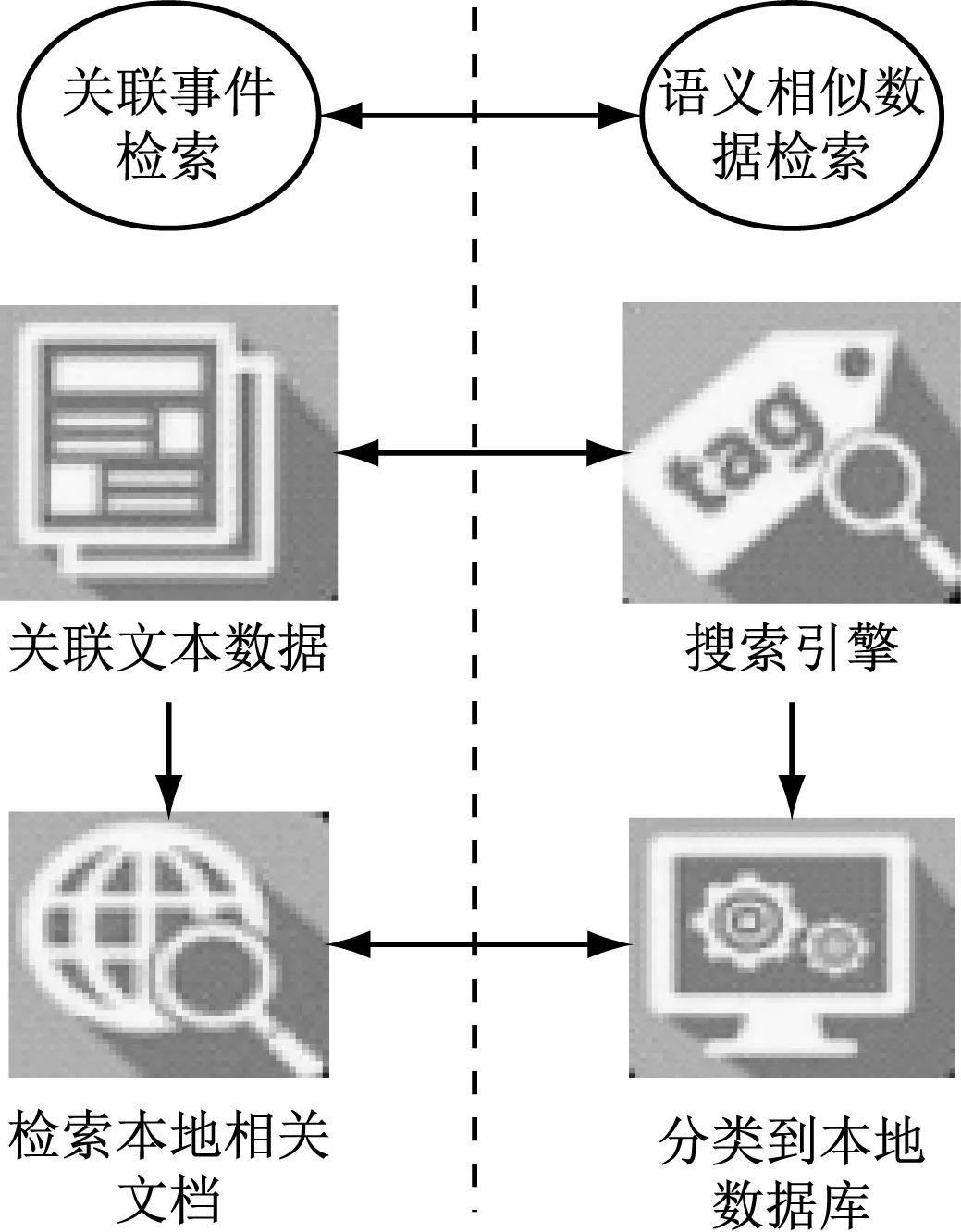
圖4 相關數據檢索流程
本地事件檢索主要應用了特征詞提取技術[11],其具體表達式,如式(3)。
F=H/k+l
(3)
式中,H表示社交網站數據詞頻;k表示數據長度;l表示數據特征參數。
在互聯網事件檢索上,借助互聯網上的搜索引擎[12]對數據進行處理,將檢索到的文檔分類到在本地數據庫中獲得的相關話題中,從而獲得新的相關話題。
2.3 數據熱度計算
將上述獲得的相關話題文檔按照時間進行劃分,根據各個事件的數據文檔衡量數據的熱度[13]。數據熱度計算涉及的主要內容,如圖5所示。

圖5 數據熱度計算主要內容
從圖5可知,社交網站的數據紛繁復雜,數據量極為龐大,而且各種各樣的話題涉及到的內容不同,但只有部分數據是用戶重點關注的話題。因此以衡量數據的重要度來確定數據的影響力[14],綜合考慮網民關注度與媒體關注度[15],計算數據熱度,如式(4)。
w=At*Et+B
(4)
式中,At表示社交網站數據在時間t內的總點擊次數,即表示數據的評論數;w表示社交網站數據的權威度;Et表示社交網站數據在時間t內的報道總數;B表示調整因子。
通過上述過程,完成社交網站中數據熱點的分析。
3 實驗對比
為了更好地證明本研究方法的有效性,本研究使用Chrome瀏覽器,并利用網上一綜合性大型網站為實驗對象進行相關實驗,通過網絡爬蟲抓取實驗使用的4個數據集,其中主要包括娛樂類數據、體育類數據、美食類數據和美妝類數據,其大小分別為45 kB、125 kB、256 kB和452 kB,實驗分析了該網站總計8天的數據。將每小時對該帖子的評論數作為熱度值,采用此次設計的社交網站的數據采集與熱點分析方法識別這4個數據集中的熱點話題。為了增強實驗的對比性,將傳統的基于時間序列的社交網站數據與熱點分析方法、基于事件關聯的社交網絡數據采集與熱點分析方法對比。此次設計的方法發現在這4個數據集上的熱點數據的時間。
3.1 娛樂類數據熱點發現時間
三種方法發現娛樂數據熱點內容的時間對比結果,如表1所示。

表1 娛樂類數據熱點發現時間
由表1可知,所設計的方法能夠在短時間內識別社交網站的數據。傳統的基于時間序列的社交網站數據與熱點分析方法、基于事件關聯的社交網絡數據采集與熱點分析方法的娛樂類數據熱點發現時間顯著高于所設計的社交網站數據采集與熱點分析方法。
3.2 美食類數據熱點發現時間
三種方法發現美食類數據熱點內容的時間對比結果,如表2所示。

表2 美食類數據熱點發現時間
由表2可知,美食類數據多于娛樂類數據,在此類數據識別上,傳統兩種方法發現美食類數據熱點的時間呈增加的趨勢。并經過對比可知,所設計方法發現美食類數據熱點內容的時間較短。
3.3 美妝類數據熱點發現時間
美妝類數據為452 kB,數據量多于上述兩種對比內容的數據,三種方法在此數據下的發現時間,如表3所示。

表3 美妝類數據熱點發現時間
由表3可知,此次設計的方法發現熱點的時間沒有明顯變化,花費時間依舊較少。而傳統兩種方法的美妝類數據熱點發現時間仍然高于所設計的社交網站數據采集與熱點分析方法。
3.4 體育類數據熱點發現時間
三種方法發現體育類數據熱點內容的時間對比結果,如表4所示。
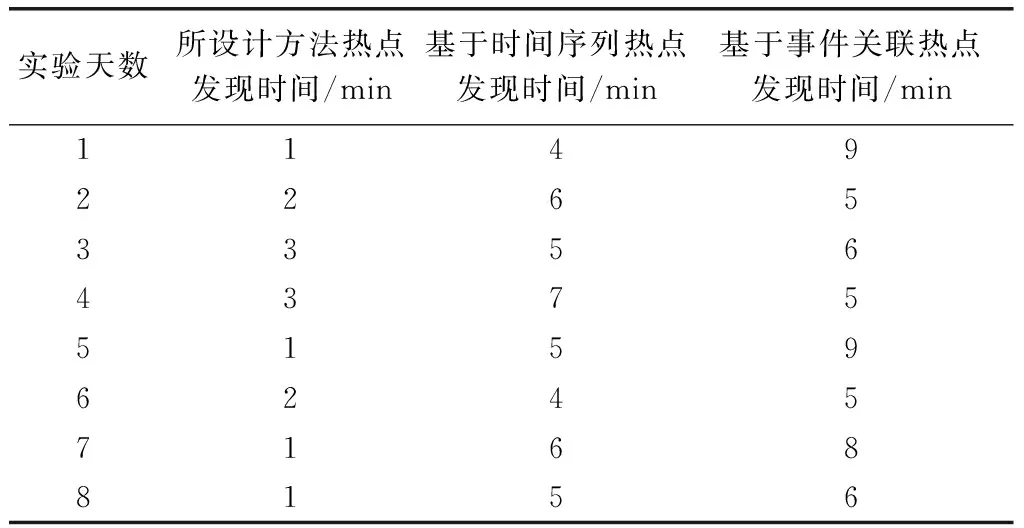
表4 體育類數據熱點發現時間
由表4可知,所設計方法發現體育類數據熱點的時間較短,明顯低于傳統兩種方法。或許是傳統方法在分詞、特征提取、權重計算與聚類處理等方面上耗費了大量時間,導致數據熱點發現時間延長。因此,通過上述實驗能夠證明,所設計的方法數據熱點發現時間短于傳統兩種分析方法,能夠及時向社交網站用戶推送熱門內容。
4 總結
社交網站數據采集與熱點分析是一個隨著時代變化不斷發展的研究領域,還有許多問題有待進一步探索與研究。針對此次研究內容的不足,今后將重點研究三方面內容,分別為如何有效及時獲取網絡中的最新消息;如何挖掘社交網站數據中蘊含的語義信息以提高熱點數據挖掘能力;如何對音頻、視頻等多媒體信息進行處理以進一步提高社交網站數據熱點分析效果,及時為用戶提供熱點數據。
猜你喜歡
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
兒童故事畫報(2019年5期)2019-05-26 14:26:14
電子制作(2018年18期)2018-11-14 01:48:24
山東工業技術(2016年15期)2016-12-01 05:31:22
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
中國中醫藥現代遠程教育(2014年11期)2014-08-08 13:23:44
終身教育研究(2014年5期)2014-02-28 01:23:06
