居民出行與軌跡行為交互模式挖掘與關聯技術
2021-04-28 00:25:38代維秀陳占龍
測繪學報 2021年4期
關鍵詞:語義
代維秀,陳占龍,謝 鵬
1. 中國地質大學(武漢)地理與信息工程學院,湖北 武漢 430074; 2. 西安測繪研究所,陜西 西安 710054; 3. 地理信息工程國家重點實驗室,陜西 西安 710054
大數據對地理信息的研究提供了新的視野,人們從基礎的地理信息研究轉移到利用計算機技術解決地理和城市問題上。與傳統小數據相比,地理大數據具有粒度細、廣度寬、密度大、偏度重和精度差的特點[1-2]。合理利用地理大數據的優(yōu)點,挖掘其隱藏價值,使其在實際應用中發(fā)揮作用。出租車作為城市交通工具的重要組成部分,對居民出行尤為重要。出租車軌跡數據包含移動過程中的位置、速度、時間等信息,能夠體現人們時間序列上的位置變化,反映人們的出行規(guī)律,并且數據量極大,符合地理大數據的特征。隨著技術的發(fā)展,挖掘軌跡數據信息,研究城市居民活動極具價值。軌跡數據的研究從個體研究群體,從大量的個體數據之間,分析群體性特征。隨著城市的發(fā)展,一些與居民出行有關的城市問題逐漸顯現,如交通擁堵等,軌跡數據是研究這類問題的基礎。
軌跡數據在城市中的應用研究主要分為城市空間結構功能單元識別、人類活動模式的挖掘、行為預測、異常監(jiān)測、城市計算等內容[3]。出租車軌跡數據反映城市居民行為特征,通過對其挖掘和分析能夠揭示居民的生活規(guī)律、行為特征。一些學者通過對軌跡數據進行分析來識別城市結構單元,為城市建設決策和交通疏導提供參考依據[4-10]。除了對人們出行活動的研究外,利用出租車軌跡數據對居民活動進行預測和推薦也是研究的重點[11-14]。通過分析軌跡數據的規(guī)律分析及預測,從而進行異常檢測,來識別異常移動模式[15-16]。文獻[17]提出了位置鏈接和用戶鏈接模式挖掘算法,利用手機位置數據驗證了算法的可行性。此外,語義信息的挖掘也是出租車軌跡數據的一項重要研究內容,彌補了軌跡數據豐富而活動信息匱乏的不足[18-33]。眾多國內外學者[34-39]都在軌跡數據信息挖掘方面進行深入的研究,為進一步利用地理大數據提供經驗。
根據包含出租車的位置、時間等信息的軌跡數據對居民活動規(guī)律進行挖掘,是研究軌跡數據的一項重要內容。考慮時空約束,首先對軌跡數據進行停留點提取,并對停留點進行語義類別推斷,然后利用語義類別信息建立語義交互矩陣,對居民行為目的交互模式挖掘。以北京市出租車軌跡數據為樣本進行方法的驗證,分析不同日常活動的時空特征,挖掘行為目的交互模式。本文有助于揭示城市結構和資源配置,為城市規(guī)劃提供科學依據。
1 研究方法
出租車軌跡數據包含上下客位置、時間等信息,但上下客位置信息并不代表確定的活動語義信息。本研究首先通過軌跡數據提取停留點,以停留點和興趣點為基礎數據,然后采用高斯核密度推斷停留點的語義類別,采用DBSCAN聚類方法識別居民活躍度高的區(qū)域,最后通過停留點語義類別交互信息構建語義交互矩陣,并對不同時間段語義交互矩陣進行相似性度量,挖掘行為目的交互模式。整體研究流程如圖1所示。

圖1 研究流程Fig.1 Research scheme
1.1 停留點語義類別推斷
根據出租車的載客狀態(tài)變化可以確定出租車的上、下客情況。當出租車載客狀態(tài)由0變?yōu)?時,則可確定該處為上客點。定義上客點位置集為SP,表示為P={spk∈SP|spk=1 and spk-1=0}。當出租車載客狀態(tài)由1變?yōu)?時,則可確定該處為下客點。定義下客點位置集為SD,表示為D={sdk∈SD|sdk=0 and sdk-1=1}。其中k為連續(xù)的k個出租車位置,spk表示第k個上客位置對應的出租車狀態(tài),sdk表示第k個下客位置對應的出租車狀態(tài)。為了方便后續(xù)研究,本文將上客點和下客點統稱為停留點。
根據居民日常出行目的對POI進行重分類,以便更準確的刻畫居民活動,本文中POI重分類結果為:住宿、工作、休閑、教育、餐飲、其他(一定范圍內無以上類型POI定義為基于其他目的出行),對分類后的POI點賦予合理的開放時間[40]。考慮到權重分配的全面性和平滑性,構建高斯核密度估計方程計算各類POI成為停留目的的概率公式,停留點目的概率為聚集在停留點一定范圍內的不同類別的POI成為該停留點目的的概率,如式(1)所示
(1)
式中,yj為第j類POI點成為停留點目的概率密度;j為1,2,3,…,6,表示POI類別;xi是該點距離停留點的直線距離;i為1,2,3,…,n,表示搜索半徑內第j類POI點的數量;δ是標準差,本文中定義為250 m;μ是均值,本文忽略道路優(yōu)勢,故取值為0;ρj表示第j類POI數量之和的倒數。為了消除由于POI數量差異引起的結果誤差,故采用倒數對其數量進行平衡。綜合居民行為特點,大都會選擇在臨近目的地的位置上下車,本文中將搜索半徑選為100 m,研究對象為搜索范圍內所有的POI點,通過采用式(1)確定每類POI對應的停留點目的概率密度,選取其最大值所對應的POI類別作為該停留點的語義類別。停留點語義類別為該停留點研究范圍內,概率密度最大值所對應的POI類別,具體為:①計算停留點目的概率yj; ②判斷max(yi)所對應的POI類別; ③將②所得出的POI類別作為此停留點的語義類別。停留點語義類別如式(2)
Pt=max(yi)
(2)
式中,Pt為停留點語義類別;yi為停留點目的概率。停留點語義類別推斷過程如圖2所示。

圖2 居民出行停留點類別推斷Fig.2 The inference of residents’ travel purpose
本研究通過對語義類別相同停留點進行聚類,分析不同語義類別的停留點在不同時間段內空間分布情況,對其進行可視化及聚類研究。DBSCAN算法因其結構簡單,多用于處理高密度數據,因此本文采用DBSCAN聚類算法對不同語義類別的停留點進行聚類分析,根據相關研究可知DBSCAN對Eps(簇半徑參數)和minPts(鄰域密度閾值)參數非常敏感。本文通過多次試驗分析,設置minPts值為當前數據集總點數的1/25[41]。Eps通過k-距離曲線取值為500 m。
1.2 行為目的交互模式度量
停留點活躍度指相同時間段內每類語義類別的停留點的數量之和,即每類停留點的活躍程度,如式(3)所示,反映了不同時間段內居民出行行為的特征。
(3)
式中,j為停留點的語義類別,j為1,2,3,…,6;pij為研究時段內第i個j類的停留點,i為1,2,3,…,n。
停留點活躍度可以直觀反映居民出行目的隨時間的分布狀態(tài),但是不能反映上下客點之間的語義交互情況,因此在停留點活躍度研究的基礎上進一步進行停留點交互情況的研究。在不同的時間段,居民出行目的不同,即停留點的語義類別不同。本文將停留點語義類別作為居民的行為目的屬性,以此構建不同時段內的語義交互矩陣,度量行為目的屬性之間的交互。即對一天24個時間段的語義交互矩陣進行度量,總結居民出行的交互規(guī)律。交互一般指發(fā)生在可以互相影響的兩方或多方之間的行為,相同時間段內,不同行為目的屬性的上、下客點發(fā)生互動,此過程即形成了城市居民的行為目的交互模式,例如語義類別為住宿的上客點與語義類別為工作的下客點之間的互動為住宿-工作交互模式。頻繁交互是指在行為目的交互模式中頻繁出現的互動,通過頻繁交互挖掘可以對居民行為進行總結分析。
語義交互矩陣構建是研究行為目的交互模式的重要部分。為了構建不同時間段內的語義交互矩陣,首先對不同時間段內的上下客點的行為目的屬性的交互情況進行統計,即每類上車點語義類別流向各類不同下車點語義類別的交互次數構成矩陣的元素,然后對同時間段的上下車點的語義類別進行交互索引,構建語義交互矩陣。具體矩陣如下
(4)
式中,Dt表示t時對應的語義交互矩陣,Dtij表示在t時刻上車點的語義類別為i(i為1,2,3,…,6)的流向下車點語義類別為j(j為1,2,3,…,6)的關聯值。矩陣的行表示上車點語義類別為i與下車點各類語義類別之間的交互,矩陣的列表示下車點語義類別為j與上車點各類別間的交互。
由于不同時間內出行量差異巨大,不同時間段對應的矩陣元素差異較大,因此需要進行矩陣的歸一化處理,這樣可以平衡矩陣元素之間的巨大差異,也可以均衡不同特征值差異太大導致的影響差異大。本文對交互矩陣進行了歸一化處理,選取的歸一化方法為min-max scaling方法。該方法將原始矩陣的行采用線性化的方法將數轉換到[0,1]之間。具體實現公式如下
(5)
對歸一化的語義交互矩陣進行相似性度量,可以對24個時間段內的語義交互矩陣進行相似性區(qū)分,進而挖掘不同時間段居民出行規(guī)律。該研究中語義交互矩陣維度相同,傳統的矩陣度量方法如矩陣減法、R平方法等均可以作為該類型矩陣的度量方法。本文采用矩陣減法度量歸一化后的矩陣,對兩個時段歸一化后的矩陣作差,分別計算3個矩陣范數,通過式(6)進行相似度計算
sim=1-dis(m1,m2)
(6)
式中,sim為度量后兩個矩陣的相似性,取值范圍sim∈[0,1];dis(m1,m2)為差向量范數與m1、m2歐氏距離度的比值。sim越接近于0則表示兩個矩陣相似性越低,sim越接近于1則表示兩個矩陣相似度越高。
2 試驗與分析
2.1 試驗數據及區(qū)域概況
北京市是我國的政治、經濟、文化、科教以及創(chuàng)新中心,圖3所示區(qū)域是北京核心功能區(qū),其城市功能齊全,人口密度大,城市結構復雜,且出租車是北京市居民重要的出行方式,因此選擇該區(qū)域作為研究區(qū)。
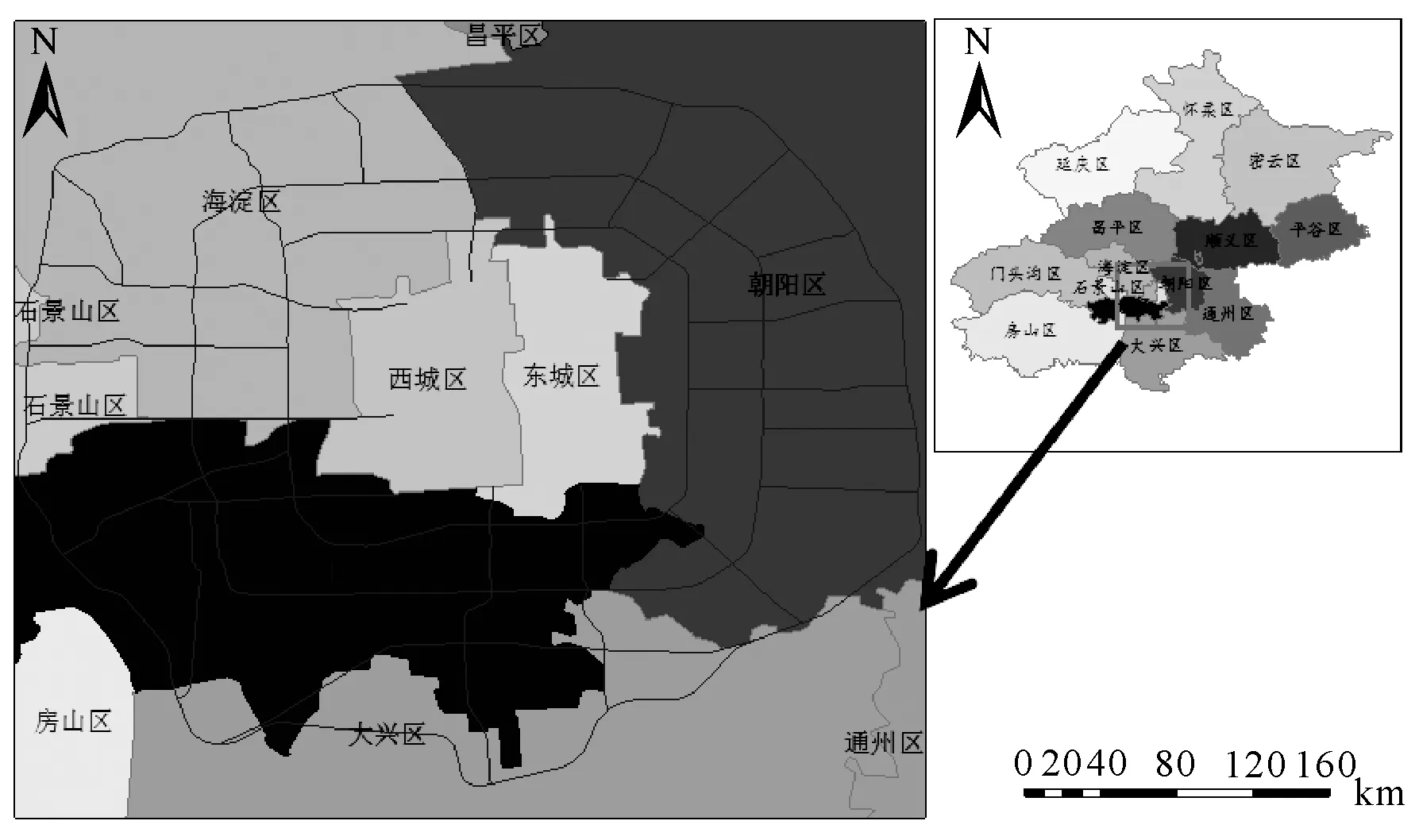
圖3 研究區(qū)域Fig.3 Research area
本文中采用的是北京市2012年11月共30 d的出租車GPS記錄數據,以*.txt格式存儲,出租車軌跡數據說明見表1,根據研究需求對軌跡數據進行處理。研究中采用的POI數據通過百度地圖服務(http:∥map.baidu.com)獲取;北京市路網數據從open street map(OSM)獲取,研究數據說明見表2。
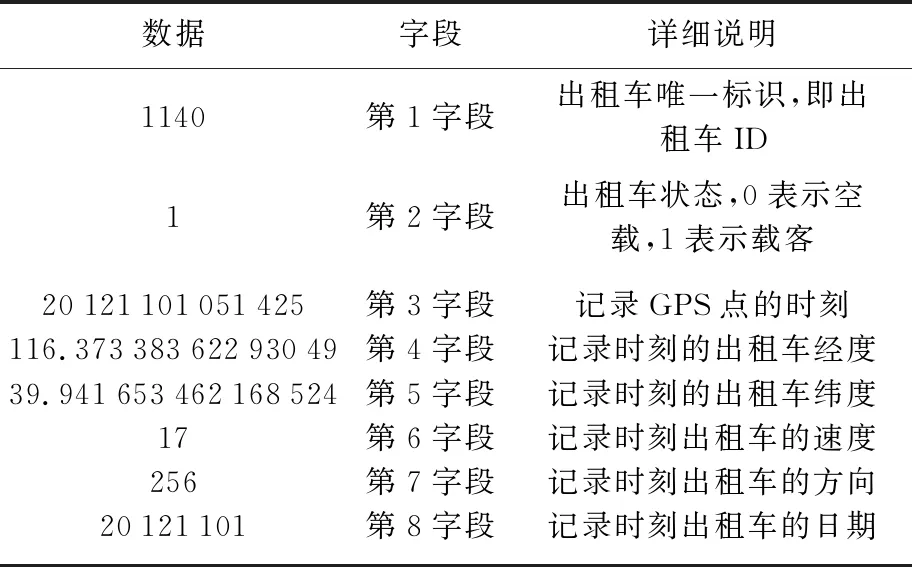
表1 軌跡數據說明
2.2 出行熱點區(qū)域分析
通過推斷停留點的語義類別,對不同語義類別的停留點進行聚類分析,以獲得不同類別的熱點區(qū)域分布情況。不同語義類別的停留點分布可以直觀表現區(qū)域規(guī)劃情況以及各類別停留點間的關系,分析結果如圖4—圖13所示。

圖4 工作日上午9時住宿類別停留點分布Fig.4 The distribution of accommodation data stay point at 9 am on workdays
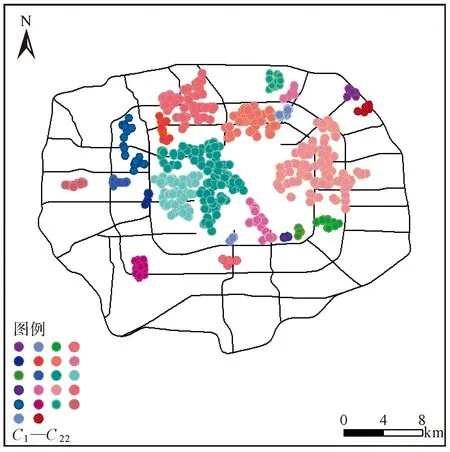
圖5 工作日上午9時工作類別停留點分布Fig.5 The distribution of work data stay point at 9 am on workdays

圖6 工作日9時教育類別停留點分布Fig.6 The distribution of educational data stay point at 9 am on workdays

圖7 非工作日11時休閑類別停留點分布Fig.7 The distribution of leisure data stay point at 11 am on non-workdays
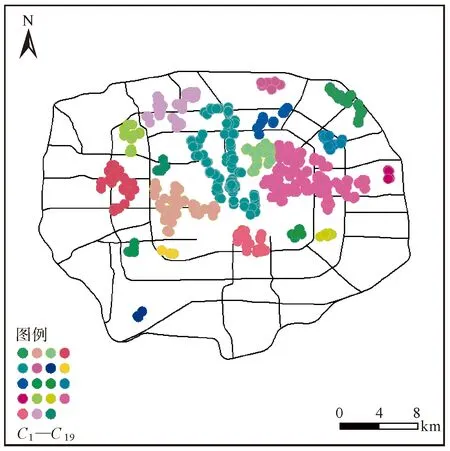
圖8 工作日13時餐飲類別停留點分布Fig.8 The distribution of catering data point at 1 pm on workdays
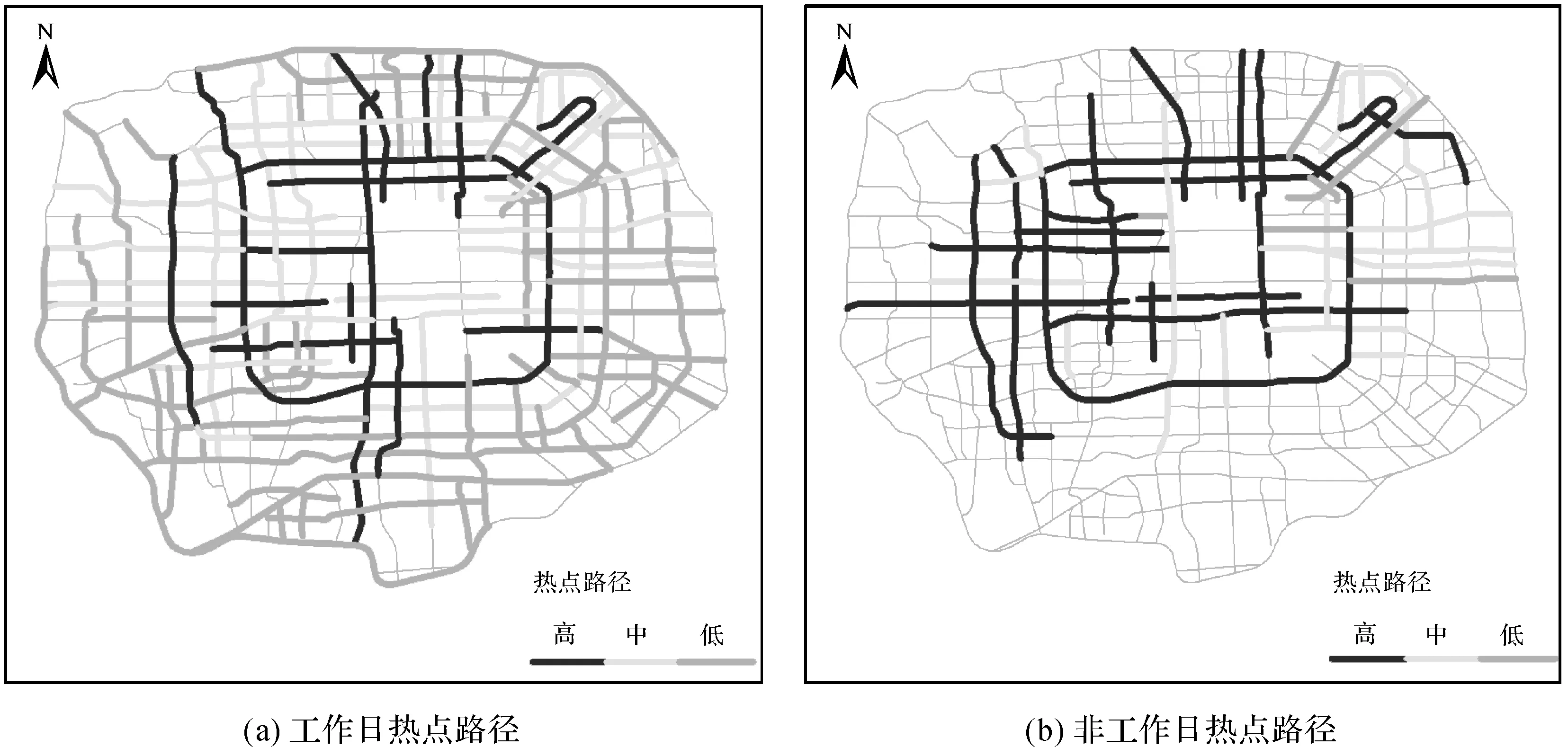
圖9 工作日和非工作日住宿熱點載客路徑Fig.9 The hot routes for accommodation on workdays and non-workdays
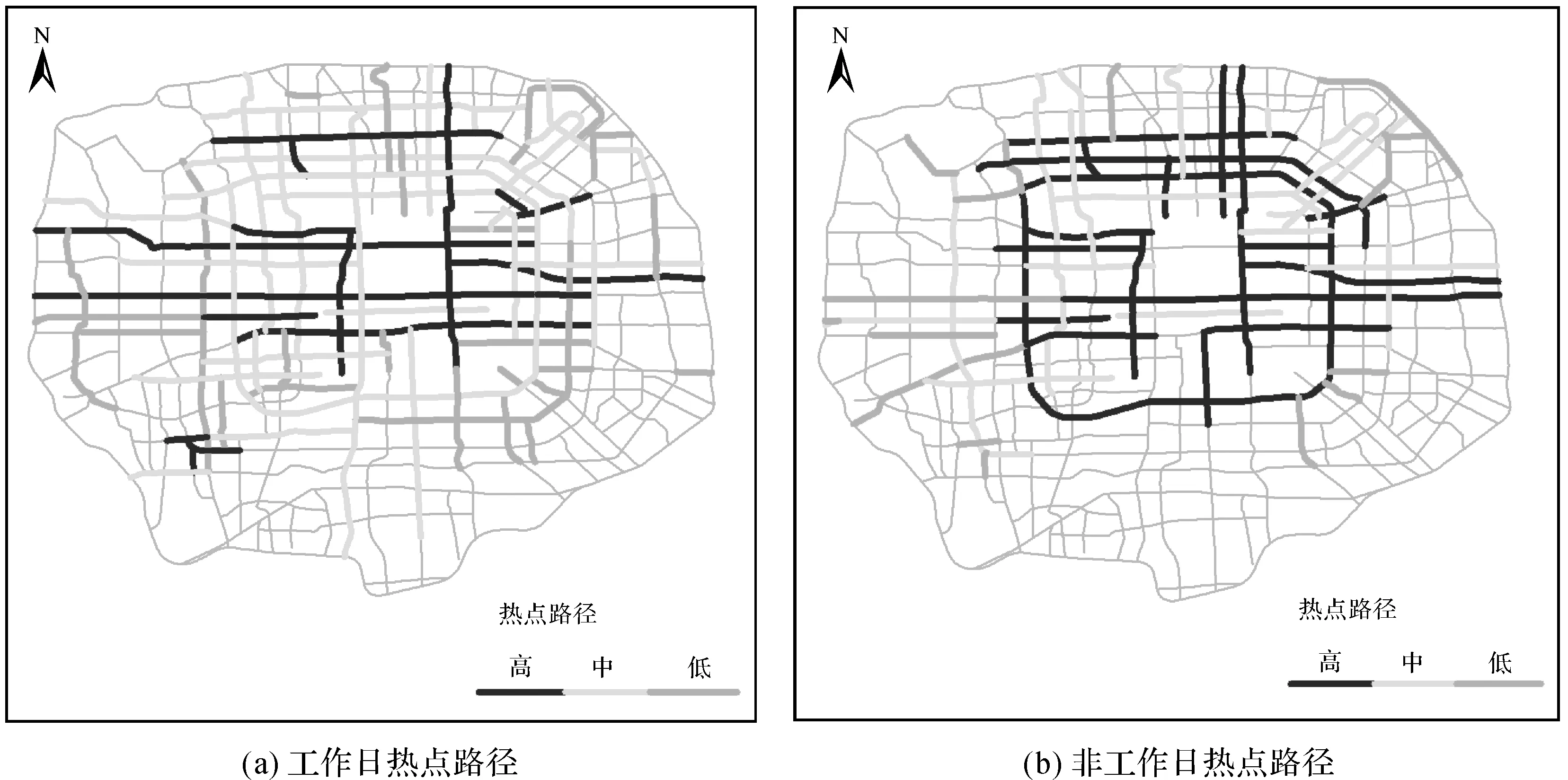
圖10 工作日和非工作日工作熱點載客路徑Fig.10 The hot routes for work on workdays and non-workdays

圖11 工作日和非工作日教育熱點載客路徑Fig.11 The hot routes for education on workdays and non-workdays
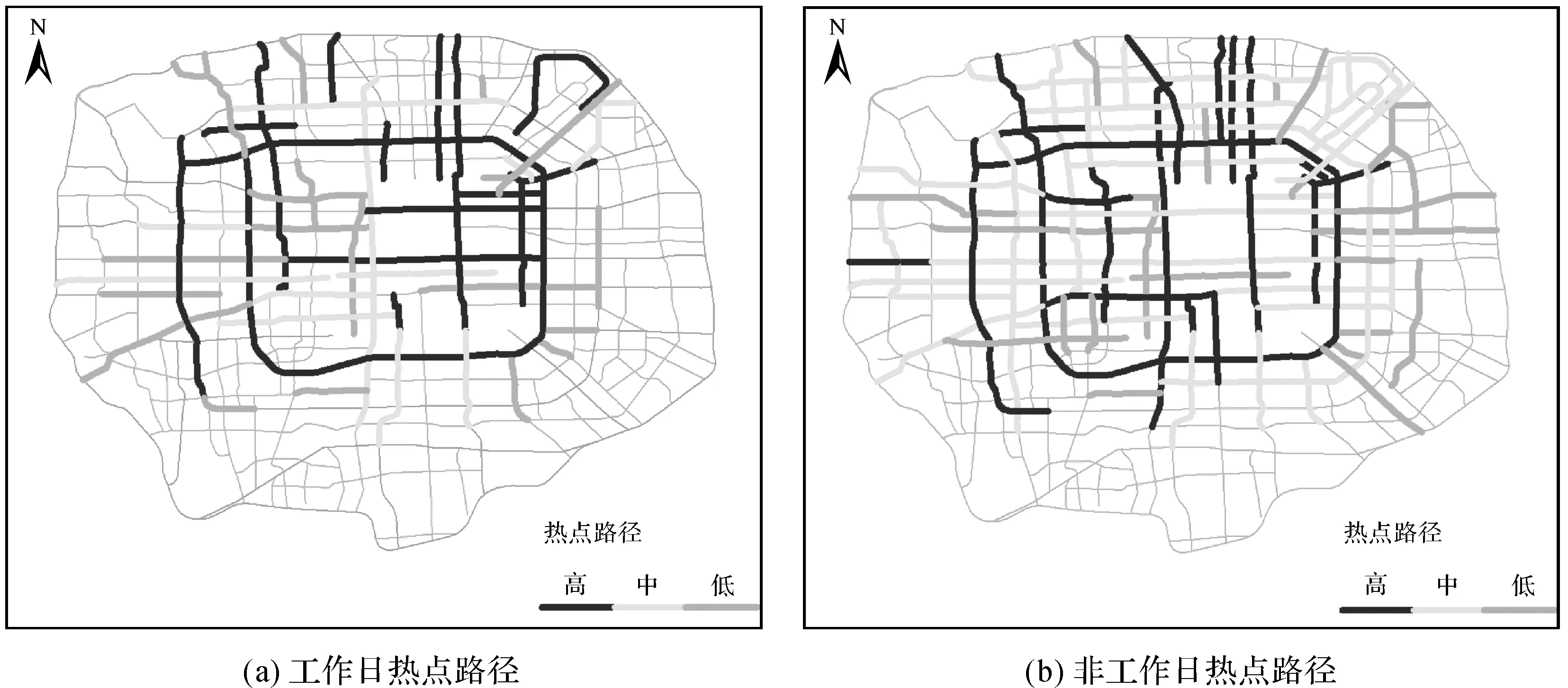
圖12 工作日和非工作日休閑熱點載客路徑Fig.12 The hot routes for leisure on workdays and non-workdays

圖13 工作日和非工作日餐飲熱點載客路徑Fig.13 The hot routes for catering on workdays and non-workdays
圖4—圖8為各類語義類別的停留點時空分布情況,圖中不同顏色的停留點為聚類結果可視化,以Ci(i為正整數)表示。工作日8—9時段為上班高峰期,工作類別的停留點分布能直接反映研究區(qū)的商業(yè)分布情況;住宿類別的停留點分布與商業(yè)分布有一定的關聯,這一現象在中心區(qū)域反映較為明顯;教育類別的停留點與商業(yè)分布一定程度上相關,特別是教育發(fā)達的海淀區(qū);休閑類別的停留點除了在商業(yè)圈分布,在景點處也形成明顯聚集;餐飲類別的停留點分布與商業(yè)分布的相關程度不能僅通過停留點反映,這與居民多擇近就餐有關。
通過分析不同語義類別的停留點聚集情況可知:北京市的商業(yè)分布和高校之間互相依托,共同發(fā)展,奠定了經濟發(fā)展與教育事業(yè)共存的基礎;居民區(qū)圍繞著商業(yè)圈分布,這符合職住一體的規(guī)劃,從一定程度上節(jié)省了通勤時間;餐飲與商業(yè)的分布有限相關;五環(huán)內的休閑不僅與景點有關也與商業(yè)分布相關,這與商業(yè)圈規(guī)劃的多功能性有關。
將沿道路分布的各類語義停留點進行可視化表達(圖9—13),對停留點聚集程度高的路段進行提取分析可知:①工作日和非工作日各類停留點的載客熱點路徑分布存在明顯差異,特別是工作、住宿和休閑類別,工作日時工作和住宿類別的停留點高于非工作日,工作和住宿類別停留點在工作日分布相對發(fā)散,非工作日分布更趨向中心集中,休閑類別停留點的活躍度在非工作日時明顯比工作日高且非工作日時更為發(fā)散;②教育和餐飲類別的停留點的熱點載客路徑在工作日和非工作日的發(fā)散程度區(qū)別不太,但教育類別的停留點在工作日時更趨于中心分布。
研究不同類別的停留點的分布情況,可以直觀認識城市布局,即北京市的商業(yè)和高新科技集中于中心城區(qū),也可以得出人流量大的熱點區(qū)域。北京市城市規(guī)劃政策即通過疏解非首都功能,實現人隨功能走、人隨產業(yè)走,不斷調整人口布局,緩解城市壓力。中心城區(qū)人口密度大,以業(yè)控人,通過產業(yè)疏解進而達到人口疏散,緩解中心城區(qū)的壓力。此外也將增加公共服務設施、交通市政基礎設施、公共綠地等用地規(guī)劃,以人為本,提高居民生活品質,從源頭入手,解決“大城市病”。
2.3 居民行為目的交互模式挖掘
通過分析不同時段、不同語義類別的停留點活躍度,直觀了解居民出行目的的差異,為交互模式挖掘提供一定的依據。與其他交通系統類似,基于出租車服務的居民出行行為表現出時間和空間的日常周期性,反映了潛在的人類活動模式[42]。不同行為目的屬性的上下客點發(fā)生互動形成了城市居民的交互模式,交互模式反映了不同類型停留點之間的互動情況。O-D矩陣可以表達居民的行為,通過挖掘O-D矩陣在不同時段描述的居民行為變化或差異,以便有效管理出租車服務運營以及資源分配。本文通過構建停留點語義交互矩陣,基于該語義交互矩陣進行交互模式分析,并根據不同語義類別的停留點之間的互動情況進一步挖掘居民行為目的的頻繁交互。
通過式(3)對不同類別的停留點活躍度進行統計,并對其進行標準化處理,分析每類停留點活躍度相對變化情況(圖14、圖15)。

圖14 工作日各類停留點上下車的活躍度變化Fig.14 Activity change of track stay points of up and down vehicles on workdays
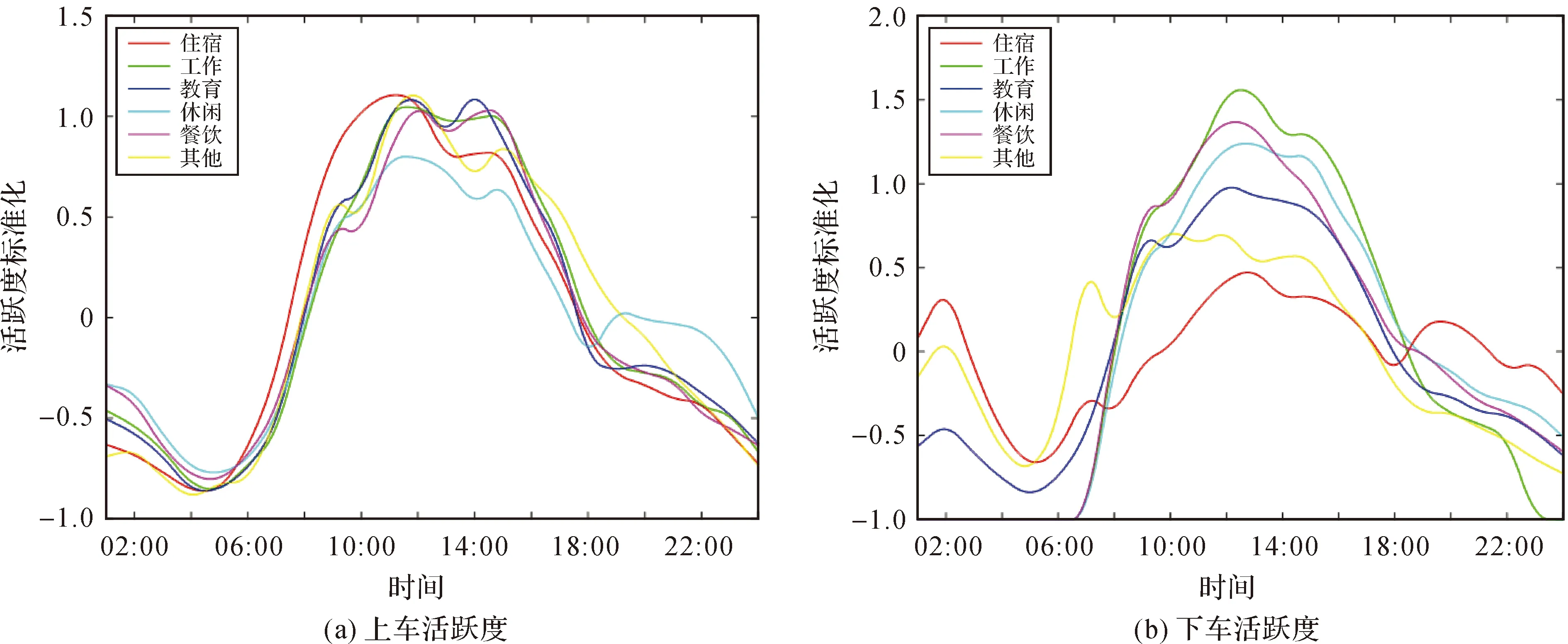
圖15 非工作日各類停留點的上下車活躍度變化Fig.15 Activity change of stay points of up and down vehicle on non-workdays
通過工作日和非工作日各類停留點的活躍度對比分析可知:
(1) 工作日和非工作日在0—6時段各類停留點的活躍度較低并在該時段內出現最小值,下客點的活躍度最小值遲于上客點的出現;6—8時段停留點的活躍度呈陡增趨勢,9—22時段活躍度出現波動,在22時后整體呈現下降趨勢。
(2) 非工作日的各類停留點的活躍度峰值比工作日出現晚,非工作日停留點在10—16時段活躍度較高,工作日停留點的活躍度從10時持續(xù)到22時。非工作日18—24時段停留點的活躍度驟減。
(3) 工作日各類停留點的活躍度對比明顯,對于上客點,住宿類別的停留點的活躍度在8時陡增;休閑類別的停留點的活躍度在19—22時段活躍程度較高。對于下客點,工作類別的停留點的活躍度在9—10時段達到峰值,19時起其活躍度驟降;住宿和休閑類別停留點呈現小幅增長。各類型的停留點的活躍度均在12—13時段出現谷值。
(4) 非工作日停留點的活躍度在10—14出現峰值。對于上客點,住宿類別停留點的活躍度峰值在10—11時段出現;住宿、休閑和其他類別停留點在13—14時段出現下降,而教育類別停留點在14時上升達到峰值;休閑類別停留點的活躍度在18時后高于其他類型。對于下客點,住宿類別的停留點在18時前低于其他類型停留點的活躍度,18時后有所增長;工作類別停留點的活躍度在11—12時達到峰值。除住宿外其他類別停留點在16時后活躍度逐漸下降。
分析不同類別停留點的活躍度可以直觀展現居民出行情況,但僅研究停留點活躍度無法提示出居民出行的交互情況,因此,后續(xù)需要進行交互模式研究。對語義類別分類后的停留點,構建停留點語義類別信息的語義交互矩陣(式(4)),通過對語義交互矩陣歸一化后的相似性度量(式(6)),可以得出工作日和非工作日不同時段的居民行為目的交互模式。將一天24 h的語義交互矩陣分別進行相似性度量,根據相似性度量的結果構建相似度熱力圖(圖16、圖17)。

圖16 工作日與非工作日居民出行交互熱度Fig.16 Interaction heat of residents’ travel on workdays and non-workdays

圖17 工作日和非工作日交互模式Fig.17 Interactive mode of residents’ travel on workdays and non-workdays
由圖16、圖17可知:工作日凌晨0—6時段內,多為其他語義類別與住宿之間的交互;8—10時和14時內,主要為工作與工作之間的交互、住宿與工作的交互、其他各語義類別與工作交互;上午10—12時和下午15—17時內,表現為工作與其他類別的交互;18—24時內交互類與下班后居民的生活習性有關,主要為工作類型與住宿、休閑以及餐飲間的交互。非工作日凌晨0—5時相似性較高,主要是與住宿相關的交互;8—17時交互相似性較高,多為居民的休閑娛樂出行相關,非工作日居民出行時間寬泛,可以自由選擇出行時間;19—24時交互相似性高,多為居民活動結束后返回居住地有關。總體而言,工作日住宿、工作、教育為主要的交互內容,其中工作和住宿之間的交互最為主要;非工作日則以休閑、住宿、教育交互為主,住宿與休閑的交互明顯。
工作日和非工作日之間交互整體上都分為3段,0—7時、7—18時和18—24時。但是在行為目的交互模式方面有所不同,工作日主要為職住交互、工作交互、住宿交互。非工作日的交互主要為居住-休閑交互、休閑交互、住宿交互。工作日和非工作日同一時間段內對應著不同的行為目的交互模式,這與工作時間對于居民的影響有關。挖掘行為目的交互模式可以反映居民出行中不同語義類別的停留點間的交互情況,可以根據不同時段的交互特征,為城市的管理、交通規(guī)劃提供一定的參考依據,在城市規(guī)劃時應更加注重職住資源匹配、通勤成本以及資源協調分配,也為居民在不同的高峰時間段出行提供合理的規(guī)劃建議,既節(jié)省了交通成本,又避免了時間的浪費。
3 結 語
本文提出了基于語義交互矩陣進行居民行為活動挖掘的方法,該方法考慮了時空約束。首先對軌跡數據進行停留點提取,并對停留點進行語義類別推斷,然后利用語義類別信息建立語義交互矩陣,挖掘居民行為目的的交互模式。采用北京市中心區(qū)域出租車軌跡數據對本文方法進行了驗證,研究了北京市中心區(qū)域居民的不同日常活動的時空特征,挖掘行為目的的交互模式。本文方法可以為城市規(guī)劃管理、資源調度和應急管理提供一定的決策支持。隨著出行方式的多樣化,人們有更多的出行方式選擇,下一步將考慮集成新的數據源進行研究,對研究方法進一步改進,使之能夠更充分反映居民的行為。
猜你喜歡
小學時代·科學小問號(2024年10期)2024-10-31 00:00:00
開放教育研究(2020年2期)2020-03-31 01:54:14
中國社會歷史評論(2016年2期)2016-06-27 07:11:52
現代語文(2016年21期)2016-05-25 13:13:44
長江學術(2016年4期)2016-03-11 15:11:31
中學語文·大語文論壇(2015年1期)2015-05-30 22:02:35
大連民族大學學報(2015年2期)2015-02-27 08:28:11
語言與翻譯(2014年2期)2014-07-12 15:49:25
語文知識(2014年2期)2014-02-28 21:59:18
當代修辭學(2011年6期)2011-01-29 02:49:50
