基于批量計算的網絡狀態(tài)細粒度感知方法
2021-04-22 07:38:44吳禮華陳源寶江偉健
無線電通信技術 2021年2期
吳禮華,陳源寶,黃 雙,謝 剛,江偉健
(1.武漢第二船舶設計研究所,湖北 武漢 430000;2.武漢大學 電子信息學院,湖北 武漢 430000)
0 引言
近年來,隨著網絡用戶和應用數(shù)量的顯著增長,網絡運營商不得不對基礎設施進行大規(guī)模升級,以滿足不斷增長的用戶需求。Cisco公司的調研報告指出,到2021年全球移動數(shù)據(jù)流量將進一步增長63%[1]。通過網絡監(jiān)控技術來感知網絡的性能對于現(xiàn)代化的運維體系而言至關重要,我們不僅希望了解關于網絡流量的信息,還需要知道他們在網絡傳輸過程中所經歷的細節(jié)。因此,建立一個強大的網絡監(jiān)控系統(tǒng)有3個必須考慮的因素:測量信息的覆蓋面、測量值的精確度和測量任務所消耗的資源開銷。
然而,如今的很多監(jiān)控解決方案迫使用戶在這三者中做出取舍,其根本原因在于目前的方案過于依賴外部服務器對于數(shù)據(jù)的處理,當網絡流量速度很快時,將會率先成為系統(tǒng)的性能瓶頸。因為目前的分析系統(tǒng)在面對高速流量時,要么使用采樣的方式來降低收到的流量速率,要么必須采用針對性強的專用硬件,這樣不得不損失部分信息,抑或增加系統(tǒng)成本。因此,考慮在可編程交換機上實現(xiàn)一種能讓這兩種目標兼顧的遙測系統(tǒng),即利用交換機中的可編程轉發(fā)流水線(Programmable Forwarding Engine,PFE)和運行在交換機操作系統(tǒng)中的CPU等本地計算資源,結合網絡帶內遙測(In-band Network Telemetry,INT)技術以及報文合并與壓縮技術在本地生成包含足夠信息量的遙測報告,即無需通過外置的服務器,直接在本地即可生成。這種方法無疑可以顯著降低成本,但是又會帶來新的挑戰(zhàn),即交換機本地計算資源難以承擔高速流量(Tbit/s級)下的報告生成任務。因此本文主要研究如何在面對高速流量時,在交換機本地生成高精度、特征參數(shù)豐富的測量報告,提出了一種可部署在硬件交換機上的批量計算測量報告生成方法。
1 相關工作
數(shù)據(jù)平面的主要功能是實現(xiàn)數(shù)據(jù)包的處理和轉發(fā),一般由交換機或路由器等組成,它將數(shù)據(jù)包作為輸入,經過流水線式的處理后將它們從指定端口輸出。在傳統(tǒng)數(shù)據(jù)平面設備中通常由專用集成電路(ASIC)負責實現(xiàn)。這些ASIC通常是可配置的,但是其能夠執(zhí)行的轉發(fā)邏輯在設計之初是固定好的。
軟件定義網絡(SDN)[2]是一種全新的網絡體系架構,它的核心思想包括將網絡中控制平面和數(shù)據(jù)平面的解耦以及可編程的特性,它將控制平面從封閉的網絡設備中剝離出來,而數(shù)據(jù)平面以通用“白盒”硬件的形式存在。網絡監(jiān)控系統(tǒng)的主要功能是掌握網絡中各種流量的當前狀態(tài),并為其建立模型來描述當前和未來網絡的運行狀態(tài)。這些被監(jiān)控系統(tǒng)感知到的狀態(tài)信息可以用來進行深度分析,解決比如網絡故障定位等問題。
P4.org推出了一種專用的編程語言P4(Programming Protocol-Independent Packet Processors)[3]來配置可編程數(shù)據(jù)平面,這是一種用于網絡數(shù)據(jù)平面的特定域編程語言,它可以描述網絡中的可編程轉發(fā)設備(如硬件或軟件交換機、可編程智能網卡及路由器等)處理數(shù)據(jù)包的方式和流程,讓數(shù)據(jù)平面的功能得到進一步開放。
可編程交換機上實現(xiàn)一種遙測系統(tǒng)能同時兼顧測量精度、覆蓋范圍和降低硬件成本,即利用交換機中的可編程轉發(fā)流水線和運行在交換機操作系統(tǒng)中的CPU等本地計算資源,結合網絡帶內遙測技術、報文合并與壓縮技術在本地生成包含足夠信息量的遙測報告,即無需通過外置服務器,直接在本地生成。
網絡帶內遙測[4]是一種典型的背負式測量方法,其核心思想是在普通數(shù)據(jù)包的轉發(fā)過程中,利用可編程流水線能識別的指令在數(shù)據(jù)包頭中插入一些需要的元數(shù)據(jù)(比如時間戳),從而使測量能力擁有數(shù)據(jù)包級別而不是流級別的細粒度。由于整個過程只在數(shù)據(jù)平面內部完成,無需控制平面參與,使得數(shù)據(jù)平面自動擁有了端到端的數(shù)據(jù)搜集能力,能夠實時掌握網絡狀態(tài)信息。然而,這種方法雖然帶來了高精度、高細粒度、高實時性的好處,同時也會帶來采集數(shù)據(jù)冗余的問題。為了節(jié)省不必要的處理開銷,針對不同測量需求,需要在處理測量報告時,在采樣精度方面做出針對性的調整。
測量指標的豐富程度,用于評價測量報告中包含的自定義統(tǒng)計信息和元數(shù)據(jù)的種類多少。擁有自定義測量參數(shù)的功能就可以支持更多的應用,因為不同功能的應用程序需要不同的測量參數(shù),以BOT Net檢測[5]、QoS測量[6]和Incast故障調試[7]三種常見任務為例。BOT Net檢測主要依靠系統(tǒng)分析主機之間的通信模式,僅使用報告中數(shù)據(jù)包的基本屬性(例如數(shù)據(jù)包計數(shù)器、字節(jié)計數(shù)器和時間戳)就能實現(xiàn)。QoS測量需要一些網絡性能的統(tǒng)計信息,如丟棄數(shù)據(jù)包計數(shù)和路徑延遲。而Incast問題的調試則需要使用平均隊列深度這個指標來評價交換機的內部運行情況。除了支持更多的應用之外,豐富的測量指標還可以提高許多應用程序的性能,例如基于機器學習的分類器[8]或網絡異常檢測器[9],它們可以同時利用多種特征參數(shù)。
2 基于批量計算測量報告生成方法
2.1 問題描述
我們的需求是在不犧牲測量信息豐富度的情況下,實現(xiàn)高覆蓋、高精度的網絡監(jiān)控。結合可編程數(shù)據(jù)平面的特點以及INT的優(yōu)勢,考慮利用P4的靈活性對可編程交換機的功能進行優(yōu)化,使其能夠在本機上為超高速流量(即>1 Tbit/s)生成可定制的測量報告(INT report),而且無需進行采樣操作或依賴外部服務器的支持。
如果要使用可編程交換機中的計算資源直接以Tbit/s速率生成測量報告是很難的[10]。可編程交換機內部有兩種計算資源:可編程轉發(fā)引擎(Programmable Forwarding Engine,PFE)和通用CPU(例如,多核心的XEON處理器)。這兩個處理器本身都不能支持測量報告的生成,一方面因為PFE本身沒有足夠的內存來跟蹤所有并發(fā)的流量,并且其計算模型往往受限(為單一功能準備),這些模型不支持測量報告生成所需的復雜數(shù)據(jù)結構。另一方面,交換機上的通用CPU也無法提供足夠的吞吐量。
2.2 解決方法
我們的目標是將產生INT report的功能直接部署到數(shù)據(jù)平面的交換機上。所以,需要將整個報告的產生工作分解成兩個互補的部分,讓這兩部分分別被兩種處理器處理。首先可利用PFE對INT包頭中攜帶的測量數(shù)據(jù)進行預處理,以減少后續(xù)CPU所需的工作量,而CPU則專注于處理那些PFE無法計算的復雜邏輯,每種處理器都依靠另一個處理器來克服其自身的局限性。
如圖1所示,首先讓PFE在流水線上生成Mini report,但每次生成只考慮每條流中最近到達的一批數(shù)據(jù)包(小型批處理)。這樣在PFE中生成Mini report而不是完整的測量報告減少了對于內存的需求,并允許使用更適合PFE處理的數(shù)據(jù)結構(例如哈希表)。每當兩條流發(fā)生沖突時,PFE會將較舊流的Mini report優(yōu)先發(fā)送到交換機CPU并更新表項。這種精簡的計算邏輯可以在計算資源和模型嚴重受限的可編程交換機的PFE上實現(xiàn)。然后,PFE的DMA引擎再將Mini report傳輸?shù)紺PU的主存儲器,在該內存中配置有一個聚合器,使用針對測量任務優(yōu)化過的哈希表將它們重新組合成完整的INT report。最后,這些INT report可以直接導出到外部收集器或分析服務器,而無需任何額外的處理。使用這種方案,即使在交換機的CPU上運行的聚合器也不需要用采樣的方式來減緩高速流量。

圖1 本地生成INT report示意圖Fig.1 Generate INT report schematics locally
如圖2所示,為可編程交換機系統(tǒng)結構圖,整個系統(tǒng)分為兩層,下層是可編程的硬件流水線PFE,可用P4語言描述其功能,支持全線速轉發(fā),用于對收到的流量進行分段生成Mini report,上層是交換機內置Linux操作系統(tǒng)和通用CPU,用于將多個Mini report組合成完整的INT report后導出到外部數(shù)據(jù)分析平臺。
可編程交換機上的通用CPU和專用可編程轉發(fā)引擎(PFE)。如前所述,這兩種處理器單獨運行都不能支持生成完整INT report的工作。交換機CPU無法滿足支持所需的處理速度,例如,對于Tbit/s級速率的流量而言,每秒會收到數(shù)億個數(shù)據(jù)包。主要的瓶頸是將數(shù)據(jù)包轉換成INT report的過程,由于內存延遲高,鍵值對比較的操作需要花費很多個時鐘周期。例如,在Wedge100 BF-32x的CPU上使用Redis所支持的吞吐量約為500 packge/s,比要求的速度低兩個數(shù)量級。另一方面,PFE雖然可以使用片上內存,以很高的速率執(zhí)行鍵值對查找的任務,但這個內存太小,無法存儲足夠的INT report以滿足整個測量任務的需要。此外,PFE屬于受限計算模型[5],該模型阻止了PFE,以線速實現(xiàn)除查找(例如插入)以外的對完整鍵值(key-value)數(shù)據(jù)結構的操作。

圖2 系統(tǒng)結構圖Fig.2 System structure drawing
通過將INT report生成算法分解為適合PFE和CPU的兩個部分,其中,PFE僅僅負責產生微報告(Mini report),用于收集短時間內的活動流量,這樣可以減少并發(fā)處理的次數(shù),以降低內存開銷,同時這樣做有利于將更簡單的數(shù)據(jù)結構映射到PFE硬件上。在交換機CPU上運行的Mini report聚合器使用優(yōu)化過的key-value數(shù)據(jù)結構,負責最后將它們組合在一起形成完整的INT report,以發(fā)揮CPU適合做復雜運算的特點。由于在Mini report上操作而不是直接在數(shù)據(jù)包上操作可能會降低CPU鍵值操作的速率,所以需要對CPU線程進行優(yōu)化,降低單條報告的計算成本,以最大限度地提高總吞吐量。
2.3 CPU層對于INT report的生成
如圖3所示,交換機的CPU上主要運行Mini report聚合器,并將從PFE中收到的Mini report片段組合成完整的INT report。

圖3 內部結構圖Fig.3 Internal structure diagram
設計Mini report聚合器的挑戰(zhàn)在于優(yōu)化鍵值運算的數(shù)據(jù)結構,使其能夠將Mini report合并成完整INT report的速率最大化。主要分為以下步驟:
(1) 從提交緩沖區(qū)讀取Mini report
PFE的DMA引擎從提交緩沖區(qū)中讀取Mini report,然后拷貝到交換機主內存中的環(huán)形緩沖區(qū)。Mini report聚合器以批處理的方式對Mini report進行合并,然后將空閑單元的地址重新發(fā)送到DMA引擎,這種工作方式與某些高性能網卡的工作方式類似,只要存在可用的空閑單元,DMA引擎就可以動態(tài)地調整拷貝速率。基于多核處理器的優(yōu)勢,多個Mini report聚合器可以與獨立的緩沖區(qū)同時工作,PFE會基于鍵值對的判斷標志來自動平衡提交的Mini report與這些緩沖區(qū)的關系。
(2) 以哈希表的形式存儲Mini report
聚合器以哈希表的形式存儲那些活動流量的Mini report,對于每個Mini report,聚合器要么通過插入新INT report來更新現(xiàn)有報告的特征參數(shù),要么直接拷貝INT report到輸出緩沖器,然后移除其對應的哈希表。
然而,這樣的操作方式,導致哈希表的效率成為聚合器的性能瓶頸,所以對其進行優(yōu)化是需要關注的重點問題。考慮了4種優(yōu)化哈希表性能的方法:
① 線性探測法(Linear Probing,LP):線性探測法對哈希表進行線性搜索,它可以顯著提高INT report的輸出吞吐量。當哈希表出現(xiàn)匹配失敗時,下一個待處理的報告已經被CPU讀入緩存了。
② Flat Table:在這種方法中,聚合器會直接在哈希表中存儲報告內容,如每個表項中存儲一個報告文件,而不是通過指向容器地址的指針。這樣做的好處是提高多份報告之間的關聯(lián)性,節(jié)省了時鐘周期的數(shù)量,并進一步減少了緩存失配的可能性。
③ 鍵值合并法(Integer Key,IK):該方法讓聚合器使用兩個64 bit整型數(shù)組表示流的鍵值,第一個數(shù)組存儲IP地址,第二個存儲端口ID、協(xié)議類型以及物理鏈路ID。這樣就可以利用SSE4.1來進行128 bit鍵值對處理,這樣就只需要兩個指令周期。
④ 查找表預讀取(Lookup Prefetching,LPre):聚合器通過批處理查找的方式來降低內存延時,它會預先從哈希表項中讀取那些最有可能被提前處理的報告,預讀取哈希表的方法可以算是對線性探測法的補充,因為當報告不在預期的表項中時,預讀取的方法仍然會加載它。
(3) 重新封裝合并成INT report
CPU中有一個獨立線程用于將提交的INT report合并成數(shù)據(jù)包的形式,然后發(fā)送到外置的分析服務器。同時,它還會周期性地掃描哈希表項,并刪除那些因為未處理而超時的流。
3 實驗與性能評估
3.1 實驗環(huán)境設置
實驗平臺基于5臺Edgecore公司生產的可編程交換機Wedge 100BF-32X,它擁有32個100 Gbit/s端口,使用Barefoot公司的TofinoP4可編程交換芯片,和Intel D1517四核CPU,內置8GB RAM。實驗平臺拓撲如圖4所示,Mini report聚合器模塊在Linux系統(tǒng)上使用C++實現(xiàn)。生成的INT report中包含IP五元組和另外幾種測量參數(shù): CPU利用率、數(shù)據(jù)包總數(shù)、字節(jié)總數(shù)、入口時間戳和出口時間戳。測試流量的設置如表1所示。

圖4 實驗平臺結構圖Fig.4 Experimental platform structure diagram
實驗中使用Ixia公司的IxLoad工具包來產生測試流量,流量模式為數(shù)據(jù)中心模式。為了模擬出數(shù)據(jù)包速率和活動流的數(shù)量隨著鏈路容量線性變換的場景,提前對Mini report表項進行了設置,為有流量接入的鏈路提前分配了不同的段,并在每個活躍鏈路的Mini report與CPU緩沖區(qū)之間配置了靜態(tài)負載均衡。

表1 測試流量Tab.1 Test flow
3.2 實驗結果分析
首先測量Tofino的PFE,用于生成Mini report時消耗的片上資源。在Tofino的PFE上,Mini report生成器可以達到線速運行,因此問題通過統(tǒng)計消耗的Tofino片上資源來確定還剩余多少資源可供其余功能單元使用。此處以Tofino中4種主要的片上資源為對象:可編程轉發(fā)表(Match-Action Table,MAT)、超長指令字(Very Long Instruction Word,VLIW)、帶狀態(tài)算術邏輯單元(stateful Arithmetic and Logic Unit,sSLU)以及三態(tài)內容尋址存儲器(Ternary Content Addressable Memory,TCAM)。
由表2可以看出哈希的計算不需要額外的資源,而Tofino中大部分的sALU被消耗,這是因為在訪問寄存器數(shù)組時,通過配置sALU的方法來計算數(shù)據(jù)包的哈希,因此避免了這些計算步驟。

表2 Tofino PFE的資源消耗Tab.2 Resource consumption of Tofino PFE
然后,測試Tofino的PFE中Mini report的生成效率,PFE通過生成Mini report的方式,明顯減少了交換機CPU的計算負荷。利用Mini report與數(shù)據(jù)包的比率隨著PFE中內存消耗的變化來描述這種效果。圖5描述了TOR和AGG交換機的Mini report生成率。由圖5可以看出,初期每10個包就會生成一個Mini report,隨著消耗PFE內存的增加,處理能力逐漸增強到每50個包產生一個Mini report,此時僅需要消耗100 K PFE內存,然后生成效率趨于穩(wěn)定,隨后即使占用更多的內存也不會再提高生成效率,說明已經達到最佳值,大約每65個包產生一個Mini report。

圖5 Mini report生成效率Fig.5 Mini report generation efficiency
由于CPU層的聚合器模塊是采用哈希表存儲的方式處理Mini report,所以如何優(yōu)化哈希表的性能非常重要。因此對比了2.3節(jié)介紹的4種不同哈希表優(yōu)化方法,其中加入了使用Redis數(shù)據(jù)庫做存儲的數(shù)據(jù)作為參考。由圖6可以看出,4種優(yōu)化方法的吞吐量都是隨著CPU核心數(shù)的增加而增加,其中優(yōu)化效果最好的是LPre方法,在4個核心全部啟動時可以接近40 Mrps。

圖6 吞吐量對比Fig.6 Throughput comparison
表3 統(tǒng)計了添加多種額外特征參數(shù)時生成INT report所需要消耗的硬件資源的變化。由表3可以看出,在Tofino的PFE中,為了添加新的特征參數(shù),需要額外消耗8個MAT和sALU。對于交換機的CPU而言,新參數(shù)的加入對吞吐量的影響較小,因為瓶頸的出現(xiàn)是由大量針對Mini report的操作造成的,而不是針對單個Mini report中的字節(jié)進行操作造成的。

表3 添加特征參數(shù)引起的開銷變化Tab.3 Changes in overhead caused by adding feature parameters
表4的統(tǒng)計結果表明,即使只使用少量的PFE內存,Mini report與CPU之間的傳輸速率相比于Tofino PCIe3.0X4接口可達32 Gbit/s的速度而言也很低。同時可以發(fā)現(xiàn),將經過交換機本地處理后的INT report發(fā)送到外部收集器時所消耗的網絡帶寬很低,只相當于同等信息量下原始報告流量的1/1 000,說明這是一種對外部服務器要求不高的解決方案。
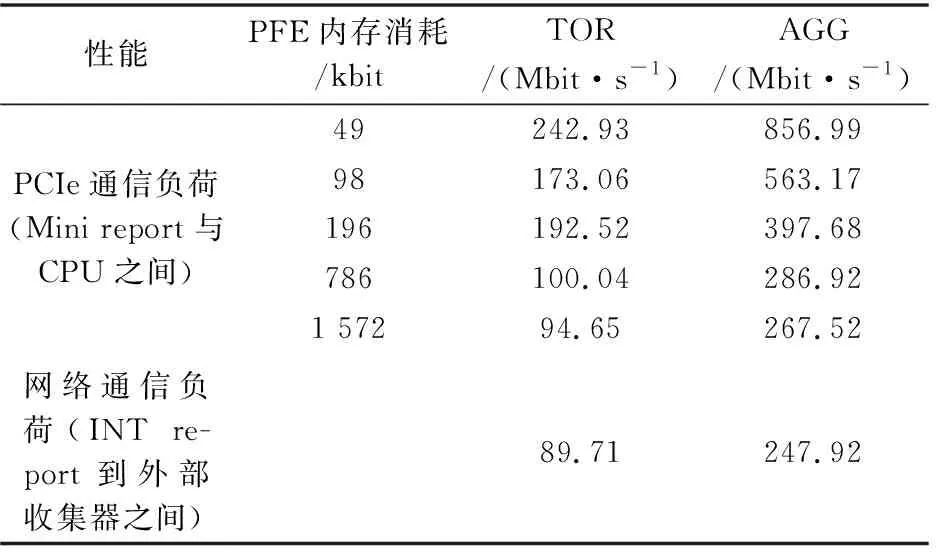
表4 通信開銷Tab.4 Communication overhead
4 結論
利用P4可編程交換機來實現(xiàn)一種批量計算測量報告的方法,該方案將網絡測量報告的生成工作轉移到交換機本地進行,設計了一種二段式報告生成方法。先讓交換機的PFE對接受到的INT包數(shù)據(jù)進行小規(guī)模批處理,生成微報告;然后通過DMA的方式上傳至CPU層,利用CPU對它們做二級聚合,將這些微報告合并成完整的測量報告。實驗表明,這種方案可以使商用可編程交換機支持Tbit級別的處理任務,從而能夠在單節(jié)點上實現(xiàn)高覆蓋率的網絡測量,既保障了測量指標的豐富程度,又降低了計算成本。
猜你喜歡
中學生數(shù)理化·八年級物理人教版(2019年9期)2019-11-25 07:33:02
中學生數(shù)理化·八年級物理人教版(2019年3期)2019-04-25 06:20:54
中學生數(shù)理化·八年級物理人教版(2018年3期)2018-05-31 08:52:45
數(shù)學小靈通(1-2年級)(2017年10期)2017-11-08 08:39:45
南方人物周刊(2017年32期)2017-10-28 22:48:36
南風窗(2016年26期)2016-12-24 21:48:09
少兒科學周刊·兒童版(2016年1期)2016-03-14 03:52:21
南風窗(2015年22期)2015-09-10 07:22:44
南風窗(2015年14期)2015-09-10 07:22:44
南風窗(2015年7期)2015-04-03 01:21:48
