基于DenseNet的紅外圖像熱斑狀態分類研究
2021-04-13 11:23:12賈帥康白英君孫海蓉曹瑤佳
山東電力技術 2021年3期
賈帥康,白英君,孫海蓉,曹瑤佳
(1.華北電力大學控制與計算機工程學院,河北 保定 071003;2.華北電力大學河北省發電過程仿真與優化控制技術創新中心,河北 保定 071003)
0 引言
隨著傳統化石能源面臨著諸多如資源不可再生、環境污染的問題,而在新能源領域如太陽能,由于其環保、分布區域廣等優點在能源產業結構的比重逐漸增加,使得新能源領域光伏發電產業迅速發展。然而,在產業規模擴大的同時,光伏組件系統的安全運行也越來越受到研究人員的關注。當光伏組件受到物體的遮擋后,受其特性的影響,遮擋部分所在的電池片流過的電流變小,在其他串聯電池片的影響下,成為負載,并將其他電池片產生的能量以熱量的形式消耗掉,這就是熱斑效應[1]。為保證光伏發電的安全有效運行,對光伏發電系統進行可靠的故障檢測就尤為重要[2]。由于熱斑會以熱量的形式消耗能量,導致其與周圍的電池片會出現溫度上的巨大差異,因此可借助紅外熱像儀判斷熱斑。關于利用紅外圖像進行熱斑檢測已有不少學者進行了相關實驗和研究。文獻[3]通過分析紅外圖像的溫度線輪廓以及灰度直方圖特征,得出熱斑與特定的不連續電池片相關的結論。文獻[4]提出利用圖像處理的方法,采用Canny 邊緣檢測算子檢測熱斑模塊及其相關故障。文獻[5]提出一種利用無人機技術采集數據的熱斑識別方法,通過統計學的方法區分異常狀態的光伏組件。
近年來,深度學習大放光彩,在各個研究領域都取得了優異的表現,文獻[6]利用卷積神經網絡將預處理好的光伏紅外圖像的熱斑進行訓練測試。文獻[7]利用VGG16 對Faster RCNN 進行初始化,并在制作的數據集上進行訓練微調。在實際中,熱斑區域面積偏小,上述研究工作未能充分利用熱斑的細微特征,為進一步提高準確率,提出一種基于深度學習DenseNet模型的方法,在原有的DenseNet(Densenet-40-12)網絡基礎上改進網絡結構,并將原模型的損失函數更換為Focal 損失函數,增強網絡中對熱斑的學習能力,提高模型分類準確率。
1 數據采集及預處理
模型訓練所采用的數據集,來源于某光伏電場。將采集的光伏紅外圖像進行規則裁剪,經篩選整理后,分為8個類別,共計1 011幅圖像,每幅圖像僅包含一塊電池片。數據集圖像根據光伏板的不同狀態劃分為類型白、類型紅、類型黃、類型黃綠相接、類型藍、類型藍綠相接、類型綠和類型湛藍8種。區分依據如下。
1)類型白:圖像整體呈紅白色,光伏板溫度高,狀態異常,為重度熱斑隱患狀態。
2)類型紅:圖像整體呈紅色,光伏板溫度較熱,狀態有異常,為中度熱斑隱患狀態。
3)類型黃:圖像整體呈黃色,光伏板較正常工作狀態溫度略高,狀態較正常,為輕度熱斑隱患狀態。
4)類型黃綠相接:圖像主要為黃色與綠色點相互黏合在一起,在電池片邊緣,綠色點一般呈不規則的絮帶狀分布,狀態較正常,黃色點聚集區為重度熱斑隱患危險狀態。
5)類型綠:圖像整體呈淺綠色或者綠色,光伏板溫度正常,狀態較正常,為中度熱斑隱患危險狀態。
6)類型藍綠相接:圖像主要為藍色與綠色點相互黏合在一起,圖像上層以藍色絮狀物為主,圖像下層為綠色,狀態較正常,為輕度熱斑隱患危險狀態。
7)類型藍:圖像整體呈藍色,一般會有輕微的白色或者湛藍色絮狀物在藍色上層顯示,光伏板溫度較低,狀態正常,為熱斑潛伏狀態。
8)類型湛藍:圖像整體呈湛藍色,光伏板溫度低,狀態正常,為光伏組件正常工作狀態。
為獲取模型有效輸入,對構建的數據集圖像進行如下預處理:1)為降低卷積運算的計算量,提高模型的訓練速度,對模型輸入圖像的大小進行適應調整(針對提出模型設置圖像大小為32×32(寬32 像素,高32 像素),其余對比模型的輸入圖像大小為默認大小),對不足模型輸入大小的圖像部分進行填充、對超出的區域進行像素壓縮,使之符合模型的輸入尺寸;2)為增加數據集的樣本量,避免模型因訓練樣本小導致模型過擬合,提高模型的魯棒性,對圖像分別進行隨機旋轉(旋轉的最大角度設置為30°)、隨機水平移動和隨機垂直移動(平移設置的最大距離為圖像寬或高的0.2 倍)、隨機縮放、隨機水平和隨機豎直翻轉等操作來實現數據集的擴充工作。
2 Densenet 神經網絡
DenseNet[8](Dense Convolutional Network)是2017 年由何凱明等人提出的一種深度卷積神經網絡,DenseNet 在思想上借鑒了ResNet[9]模型結構,通過設置特征復用[10-11]和旁路連接,保證輸入信息在網絡模型層與層之間最大程度地傳輸,能夠有效將圖像的原始特征傳遞給后層各個網絡,保障了每一層都可以直接連接輸入層和損失層,能有效避免網絡過深而使得模型訓練效果變差的現象,整體的網絡結構變得十分稠密。
2.1 DenseNet網絡
DenseNet 神經網絡主要由多個緊密塊以及過渡層堆疊而成,如圖1 所示。每個緊密塊內,第L層所得到的特征圖是將此層前面所有的前向特征圖進行連接后再通過卷積核卷積的結果,如式(1)所示。
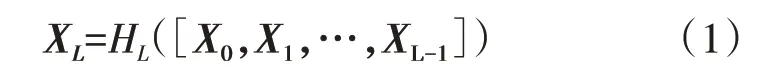
式中:XL為第L層的輸出;HL([X0,X1,…,XL-1])為網絡非線性變換(包含批歸一化,線性整流函數(ReLU)和卷積層(Conv)操作);([X0,X1,…,XL-1])對各層特征圖進行連接的操作,則L層的網絡就會有L(L+1)/2個連接。
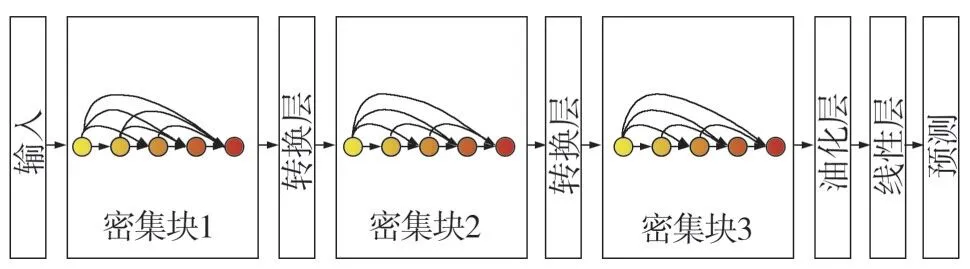
圖1 DenseNet模型結構
DenseNet 網絡中增加了兩個超參數,第一個稱之為生長率,是Block 內經過卷積層后輸出的特征圖個數k;第二個是Block 中卷積的層數L。如果產生k個特征映射,經過第L層的緊密塊,其輸出的通道數的計算方法如式(2)所示。
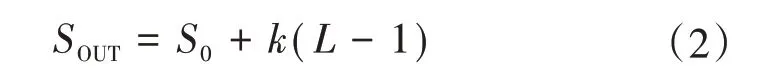
式中:S0為Block的輸入通道數,SOUT為輸出通道數。
由于密集神經網絡結構其稠密性的特點,特征圖的數量會逐級增長,為減少特征圖的數量,設置的卷積核于每個緊密塊的卷積之前,DenseNet 模型在相鄰的Dense Block之間添加Translation Layer降低網絡整體參數量,Translation Layer 由一層卷積層和一層池化層(Pooling Layer)構成,使得DenseNet可以學習更多的低層次特征,其模型的訓練效果也更具泛化能力。
2.2 改進的DenseNet網絡
基于DenseNet(L=40,k=12,即每個block 中有40 層,每層卷積產生12 個特征圖)網絡模型針對構建數據集的特點進行改進,主要改進策略為對構建數據集進行遷移學習,更改模型的前連接層結構。
2.2.1 DenseNet網絡結構改進
在DenseNet(L=40,k=12)網絡基礎上保留原有的Block 模塊,并在模型全連接層之后增加一層全連接層和Dropout 層,全連接層神經元個數為64,Dropout層設置系數為0.25。模型自動學習紅外光伏圖像的底層到高層的特征信息,并在全連接層進行特征整合,最后通過SoftMax 分類器進行故障狀態的識別判斷。
2.2.2 Focal-Loss損失函數
在深度學習中,損失函數用于評估樣本在神經網絡運算后其模型的預測值與標簽真實值的不一致情況。研究表明,在相同實驗下,不同的損失函數表征相同的模型性能時也不盡相同,因此,合理選用損失函數對深度學習模型的性能有一定的影響[12]。DenseNet 網絡使用的是交叉熵損失函數(Cross Entropy Loss),如式(4)所示。
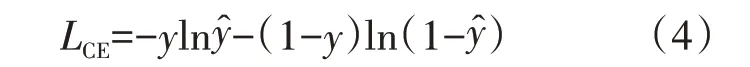
式中:y∈{0,1}是真實標簽;是預測值。
由于構建的樣本數據集類別具有不平衡的特點,為提高模型分類效果,采用Focal-Loss[13]對數據集進行校正,對難分類樣本加大權重,對易分類樣本減輕權重,使模型多關注難分類的樣本。如式(5)所示。
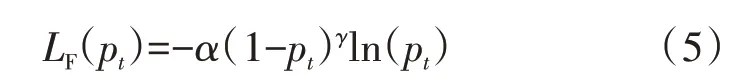
式中:α(1-pt)γ為交叉熵損失函數對應的權重;pt為特征值屬于第t類的預測概率;γ相當于懲罰項;α∈[0,1],表示權重因子,用來平衡難分類和易分類樣本的重要性。依據文獻[13]實驗,設置超參數γ為2,α為0.5。實驗結果表明,Focal Loss通過改變損失函數的非線性度,從而使模型訓練中針對難分類的樣本會進行自動學習調整,解決了數據集樣本本身不平衡的特點,提升模型分類精度。
2.3 遷移學習
深度學習神經網絡的訓練往往需要大規模的樣本,才能使模型訓練出較好的分類效果,而當訓練樣本不夠充分時,通常模型效果會不夠理想,可以考慮通過遷移學習,獲取非目標圖像的基本特征,改善模型效果。通過采用遷移學習[14]的方式,將模型在圖像數據集CIFAR 10[15]進行預訓練,得到的權重參數遷移到構建的數據集中進行微調訓練,模型的所有層都參與方向傳播的參數更新,以進一步學習構建數據集的特征信息。
2.4 模型評價指標
模型使用在圖像分類領域中常用的平均準確率Acc 評價指標,作為評估模型分類結果的評判依據,計算表達式如式(6)所示[16]。

式中:nc為數據集的類別數,此處為8;t為數據集類別的標簽值(取值范圍1~8);nt為類別標簽為t的樣本數目;ntt為模型預測類別t正確的個數。
2.5 模型參數設置
模型采用批量訓練的方法,每批次送入神經網絡16 幅圖像,即模型每次迭代處理圖像個數16 張。設置迭代輪數為20,每輪迭代125 次,其初始學習率設置為0.001。
3 實驗結果與分析
本文所有實驗均使用Tensorflow 作為后端的Keras 深度學習框架搭建,利用Python3.7 進行編程,其處理器為Intel(R)Xeon(R)Platinum 8259CL CPU@2.50 GHz,內存大小為8 GB。
3.1 實驗數據集
數據集經過篩選后得到總樣本數為1 011幅,其中訓練集大小為671 幅,測試集大小為340 幅,不同數據集類型中各個類別樣本數據集的分布如圖2 所示,各個類別的樣本數分布不均衡,可能會導致模型在識別不同類別時存在偏差,因此將訓練集數據增強3 倍,最終數據集擴充至3 025 幅圖像,其中訓練集大小為2 684 幅,測試集大小為341 幅,部分數據增強效果如圖3所示。
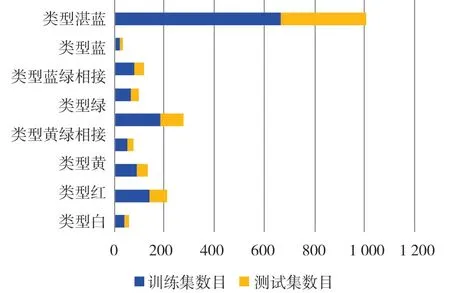
圖2 數據分布效果

圖3 數據增強部分效果
3.2 模型分類準確率
為驗證本方法的有效性,將不同模型采用相同的實驗參數,給出對比實驗結果,各個模型準確率對比如表1所示。

表1 各模型準確率對比
表1 中DenseNet 表示原始的DenseNet 模型,DenseNet+Focal-Loss 表示使用Focal-Loss 損失函數的DenseNet 模型,DenseNet+Focal-Loss+遷移學習表示使用Focal-Loss 損失函數和遷移學習的DenseNet模型。表1 的結果表明:改進后的DenseNet 模型取得了最好的分類準確率,比其余DenseNet(損失函數選擇交叉熵)、DenseNet+Focal-Loss(損失函數使用Focal-Loss)模型提高5%~7.06%,改進模型結構后,通過采用Focal-Loss,模型的分類效果繼續提升,這說明Focal-Loss 損失函數能夠有效改善數據集樣本的不平衡性,提升模型分類精度,模型在遷移學習后,模型精度進一步提高,表明選用的權重參數能夠有效學習圖像的基本特征,有效防止模型的過擬合的風險。
3.3 模型穩定性
各個模型在20 輪迭代過程中測試集上的準確率與損失函數的變化情況如圖4 和圖5 所示。圖4結果表明,改進后的模型,雖然在初始迭代過程中的準確率較低,但隨著模型的不斷訓練,模型的穩定性較好,由圖5 可知,改進后模型的損失函數的波動問題有了較好的改善,證明了在小樣本數據集中利用遷移學習的方法是可行的。
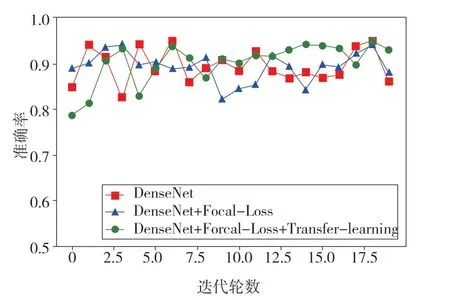
圖4 不同模型測試集準確率對
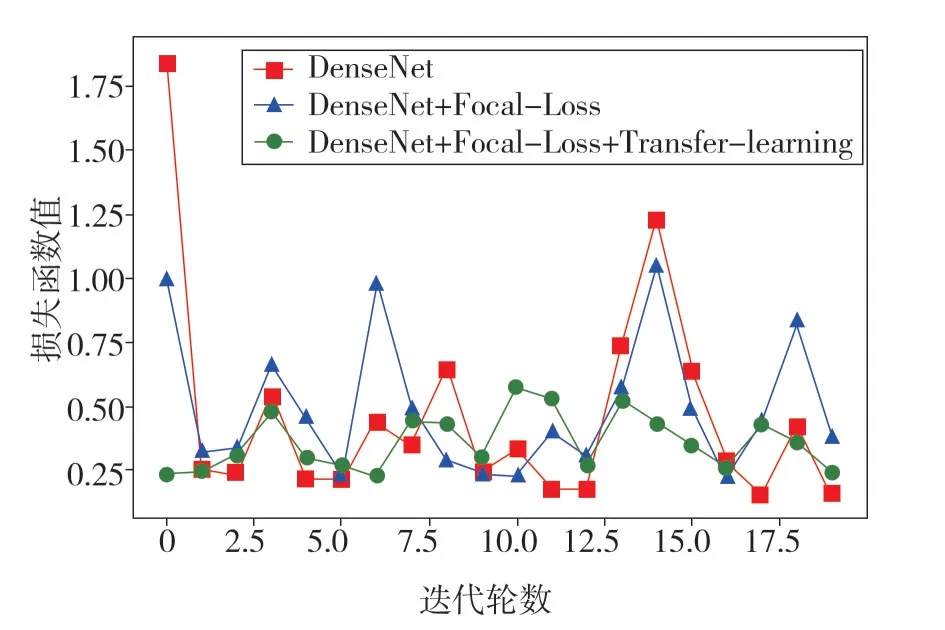
圖5 不同模型測試集損失函數對比
4 結語
提出的基于改進的密集連接神經網絡的方法,避免傳統深度學習需要進行復雜的特征提取,節省了訓練時間;所采用的Focal-Loss 損失函數,對分布不均衡的樣本具有良好的效果,由網絡的輸出和真實的偏差決定分類樣本的權重,實現網絡自適應調整,模型能夠得到有效的訓練,大大增強了模型的泛化能力,提高分類效果,改進后的DenseNet-40-12網絡能夠更好地處理紅外光伏圖像,并通過數據增強的方法,使得模型能夠得到有效的訓練,實驗結果證明所提方法具有較高的識別準確率,并且具有較強的魯棒性和泛化能力。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
