基于注意力的短視頻多模態(tài)情感分析
2021-04-10 05:52:42孫力娟任恒毅
圖學(xué)學(xué)報 2021年1期
黃 歡,孫力娟,2,曹 瑩,郭 劍,2,任恒毅
基于注意力的短視頻多模態(tài)情感分析
黃 歡1,孫力娟1,2,曹 瑩3,郭 劍1,2,任恒毅1
(1. 南京郵電大學(xué)計算機學(xué)院,江蘇 南京 210003; 2.南京郵電大學(xué)江蘇省無線傳感網(wǎng)高技術(shù)重點實驗室,江蘇 南京 210003; 3. 河南大學(xué)計算機與信息工程學(xué)院,河南 開封 475001)
針對現(xiàn)有的情感分析方法缺乏對短視頻中信息的充分考慮,從而導(dǎo)致不恰當(dāng)?shù)那楦蟹治鼋Y(jié)果。基于音視頻的多模態(tài)情感分析(AV-MSA)模型便由此產(chǎn)生,模型通過利用視頻幀圖像中的視覺特征和音頻信息來完成短視頻的情感分析。模型分為視覺與音頻2分支,音頻分支采用卷積神經(jīng)網(wǎng)絡(luò)(CNN)架構(gòu)來提取音頻圖譜中的情感特征,實現(xiàn)情感分析的目的;視覺分支則采用3D 卷積操作來增加視覺特征的時間相關(guān)性。并在Resnet的基礎(chǔ)上,突出情感相關(guān)特征,添加了注意力機制,以提高模型對信息特征的敏感性。最后,設(shè)計了一種交叉投票機制用于融合視覺分支和音頻分支的結(jié)果,產(chǎn)生情感分析的最終結(jié)果。AV-MSA模型在IEMOCAP和微博視聽(WB-AV)數(shù)據(jù)集上進行了評估, 實驗結(jié)果表明,與現(xiàn)有算法相比,AV-MSA在分類精確度上有了較大的提升。
多模態(tài)情感分析;殘差網(wǎng)絡(luò);3D卷積神經(jīng)網(wǎng)絡(luò);注意力;決策融合
近年來,隨著社交媒體的發(fā)展,如微博、抖音、快手的出現(xiàn),人們越來越傾向于在平臺上傳文字、圖片、視頻來表達個人情感,由此短視頻的數(shù)量日益增多。面對海量的短視頻數(shù)據(jù),根據(jù)其情感進行分類,從而引導(dǎo)用戶從大量數(shù)據(jù)中找到有價值的信息,已成為當(dāng)前的研究熱點之一。因此,研究人員開始專注于短視頻情感分析的研究。
現(xiàn)有研究所探討的情感分析多指文本中的情感分析(尤其是短文本情感分析),如推特以及電影評論等。由于文字是抽象的,文字個體之間是相互獨立的,且具有不同語調(diào)的文字所承載的用戶的情感是不一樣的,單純的基于文字來完成情感分析是遠遠不夠的。考慮到短視頻已經(jīng)成為當(dāng)前較為主流的情感載體,研究者們開始思考基于短視頻的視頻幀信息來完成情感分析。
但基于視頻幀圖像的短視頻情感分析在一些場景下是不準確的,如在表達喜極而泣時,用戶的面部表情和聲音所表達的情感是不一樣的,會對情感的分析造成誤差。由此,學(xué)者們開始考慮多模態(tài)情感分析來降低上述場景對短視頻情感分析的影響。PORIA等[1]使用卷積神經(jīng)網(wǎng)絡(luò)(convolutional neural networks,CNN)提取文本、音頻和視覺特征;連接其特征,并采用多核學(xué)習(xí)(multiple kernel learnin,MKL)進行最終情感分類。MA等[2]融合了用于情感識別的音頻模態(tài)和EEG信號。上述方法都依賴于特征級融合。WU和LIANG[3]在決策層融合了音頻和文本特征。上述研究表明,多模態(tài)系統(tǒng)比任何單模態(tài)系統(tǒng)具有更優(yōu)的性能。因此,多模態(tài)情感分析[4-7]成為當(dāng)前短視頻情感分析較為重要的研究方向。
本文采用音視頻多模態(tài)情感分析(audio-visual multimodal sentiment analysis,AV-MSA)來完成短視頻的情感分析,框架如圖1所示。該模型包括2個分支:①音頻情感分析,采用CNN架構(gòu)[8]提取音頻圖譜中的情感特征并進行分析;②視頻情感分析,首先,為了確保特征的時間相干性,本文使用了3D卷積[9];其次,在ResNet[10]的基礎(chǔ)上,為了突出情感相關(guān)特征,添加了注意力機制,以提高模型對信息特征的敏感性;最后,以交叉投票機制融合2個分支的結(jié)果,最終的輸出即為短視頻的情感。將本文模型在IEMOCAP[11]和微博視聽(Weibo audio-visual,WB-AV)數(shù)據(jù)集上進行了評估。本文自制了WB-AV數(shù)據(jù)集,主要反映亞洲人的語言特點。實驗結(jié)果表明,與其他方法相比,本文模型在性能上提升了約3%。主要貢獻為:①提出了基于殘差注意力的AV-MSA模型,充分利用音頻和視頻中的信息對其中所包含的情感進行分類;②設(shè)計了交叉投票機制,以融合音頻和視頻的分類結(jié)果并獲取短視頻的情感;③在基于視頻幀的基礎(chǔ)上,改進了壓縮獎懲[12](squeeze-and-excitation)網(wǎng)絡(luò)模塊的操作,并用于多模態(tài)情感分類;④制作了符合亞洲人語言特點的WB-AV數(shù)據(jù)集。其包含:生氣、害怕、厭惡、中性、快樂、悲傷和驚訝7種類型的情緒。

圖1 多模態(tài)情感分析流程圖
1 多模態(tài)情感分析模型
圖2為本文提出的AV-MSA模型。用公式表述為=-(PA,PV)。其中,為網(wǎng)絡(luò)的整體輸入;PA為音頻網(wǎng)絡(luò)輸入;PV為視頻網(wǎng)絡(luò);-為交叉投票機制;為輸出。
1.1 音頻網(wǎng)絡(luò)
現(xiàn)有的方法一般使用開源軟件openSmile[13]直接提取聲學(xué)特征,但可能會丟失一些重要特征。本文首先將原始音頻文件轉(zhuǎn)換為音頻圖譜,并提取其特征;然后用對數(shù)梅爾帶能量和梅爾頻率倒譜系數(shù)(Mel-scale frequency cepstral coefficients,MFCC)作為聲學(xué)特征,如圖3所示。

圖2 多模態(tài)情感分析框架圖

圖3 音頻特征提取過程
本文采用CNN架構(gòu),在softmax層生成輸出概率,包括2個連續(xù)的CNN塊和一個全連接層,每個CNN塊的輸出與上一模塊的輸出沿頻域連接,以在執(zhí)行最大池化之前增加特征的數(shù)量。其中,每個CNN塊由一個內(nèi)核大小為3的卷積層,一個ReLU激活函數(shù)和一個批量歸一化[14]組成。
1.2 視頻網(wǎng)絡(luò)
1.2.1 3D-CNN
對視覺內(nèi)容的情感分析可以幫助正確識別短視頻中包含的情感。相較于SIFT和HOG等傳統(tǒng)特征提取方法,深度學(xué)習(xí)[15]方法由于隨著網(wǎng)絡(luò)深度的增加,特征提取愈發(fā)完備而得到了廣泛地應(yīng)用。
首先,由于2D CNN未考慮視頻幀序列中特征的時間相干性[16],所以會降低短視頻情感分類結(jié)果的準確性。其次,短視頻中的異常情況(如目標(biāo)位置失真)也會降低情感結(jié)果的準確性。最后,對于基于CNN的方法,隨著深度的增加,會陷入局部最優(yōu)解,這也會降低結(jié)果的準確性,并且訓(xùn)練過程變得極其緩慢。
為了解決上述問題,本文采用3D卷積形式的殘差網(wǎng)絡(luò)(ResNet)。如圖4所示,時間維度為第三維。3D卷積是通過堆疊多個連續(xù)的幀組成一個立方體,然后再運用3D卷積核。在這個結(jié)構(gòu)中,卷積層中每一個特征圖都會與上一層中多個鄰近的連續(xù)幀相連,因此能夠捕捉時間信息。

圖4 3D卷積結(jié)構(gòu)圖
1.2.2 改進SE模塊
現(xiàn)有研究未考慮不同通道之間重要性可能不一樣,而是將其看成同等重要來處理的。因此,為了提高模型對信息特征的敏感性,本文基于SE (squeeze-and-excitation)進行改進。在SE模塊中,不同通道的重要性是通過學(xué)到的一組權(quán)值來標(biāo)定的,即對原來通道權(quán)值的一個重新標(biāo)定。這提高了模型對信息特征的敏感性,使后續(xù)處理能夠有效地利用與情感相關(guān)的信息特征。改進后的結(jié)構(gòu)如圖5和圖6所示。
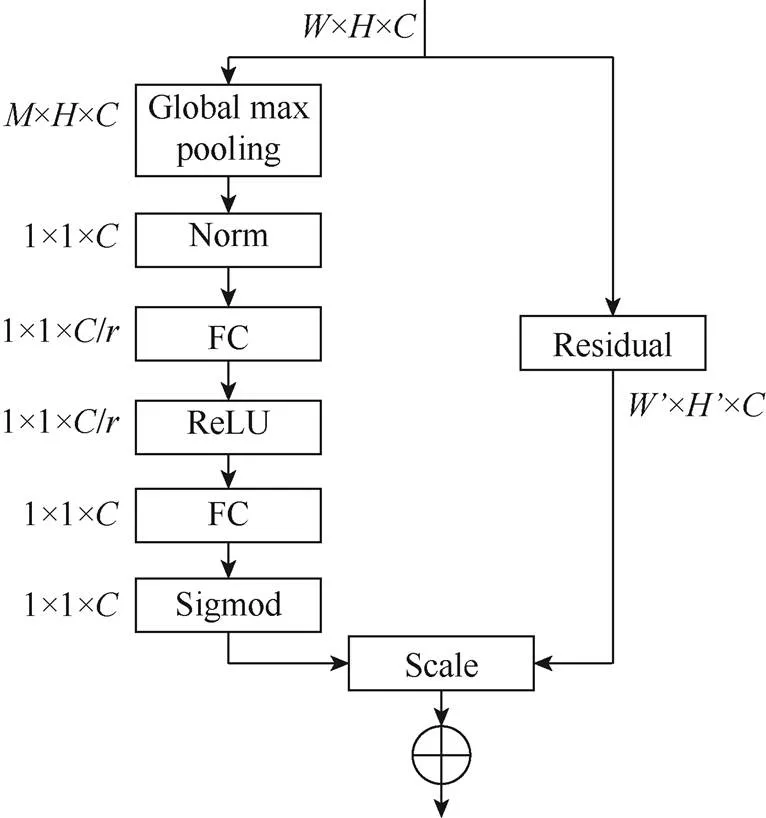
圖5 改進SE模塊結(jié)構(gòu)圖

圖6 殘差SE模塊
實現(xiàn)過程為:
(1) 進行全局最大池化(global max pooling)操作,即相當(dāng)于原來壓縮(squeeze)操作中的全局平均池化操作。采用全局最大池化操作,是因為其可以有效地保留背景信息,并最大程度地提取有用的紋理特征,這對于進行情感分類十分重要。


其中,為經(jīng)過卷積操作后,每個特征向量與基準之間的最小距離,通過max函數(shù),可獲取其中的最大值。
(2)由于全局最大池化操作后的輸出值有時幅度波動較大,因此需添加歸一化操作,即
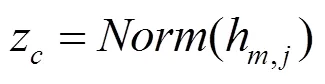
(3) 通過excitation全面捕獲通道依賴性。并采用了簡單的門控機制,使用的Sigmoid激活函數(shù)為


(4) 得到后,可以對原來殘差網(wǎng)絡(luò)的輸出進行操作,即

其中,U為殘差網(wǎng)絡(luò)的輸出,是一個二維矩陣,下標(biāo)表示channel。S是上一步的輸出(向量)中的一個數(shù)值,也是權(quán)重,因此相當(dāng)于將U矩陣中的每個值都乘以S。
1.3 交叉投票機制



其中,和分別為音頻和視頻中的情感,對每一種情感每次需連續(xù)取20幀。


其中,,分別為通過與閾值對比而確認的情感。
最后,使用P和P分別表示用視頻和音頻的結(jié)果去統(tǒng)計音頻和視頻分類的結(jié)果,其計算結(jié)果為



其中,為2種模態(tài)的權(quán)重。在諸如生氣、快樂、悲傷等情緒的表達中,視頻模態(tài)中表達的情感特征要多于音頻模態(tài),因此,將設(shè)置為0.2;correct為最終的分類正確結(jié)果。
2 實驗和結(jié)果
2.1 數(shù)據(jù)集介紹
本實驗中所采用了IEMOCAP和WB-AV 2個數(shù)據(jù)集。其中IEMOCAP數(shù)據(jù)集是用來研究多模態(tài)表達以及動態(tài)交互,包含的情感有快樂、悲傷、中性、生氣、驚訝、興奮、沮喪、厭惡、害怕等等。WB-AV數(shù)據(jù)集是本文采集制作的符合亞洲人語言特色的數(shù)據(jù)集,包含7種類型的情感,如圖7所示。
2.2 實驗環(huán)境配置
本文在NVIDIA GeForce GTX 1080Ti GPU平臺上對所提出的網(wǎng)絡(luò)進行訓(xùn)練和測試。在訓(xùn)練過程中,固定網(wǎng)絡(luò)的一支,單獨對另一支進行訓(xùn)練,在每次池化后,采用50%的Dropout[19-20]來減少過擬合問題。最后采用交叉投票進行決策融合。訓(xùn)練和測試過程,batch size大小設(shè)置為32,20。在訓(xùn)練中,根據(jù)訓(xùn)練次數(shù)使用動態(tài)學(xué)習(xí)率,初始學(xué)習(xí)率為0.01,隨著訓(xùn)練次數(shù)的增加,學(xué)習(xí)率下降,最小值為0.000 01。另外,權(quán)重衰減系數(shù)(weight decay rate)用于避免模型過度擬合,其值為0.000 20。本文模型中引入了泄露修正線性單元,以防止在反向傳播過程中ReLU的導(dǎo)數(shù)為0,relu_leakiness 的值為0.1。此外,在實驗數(shù)據(jù)集中,80%的數(shù)據(jù)用于訓(xùn)練,20%的數(shù)據(jù)用于測試。所有的對比方法均采用相同的訓(xùn)練方法和實驗環(huán)境。
2.3 實驗結(jié)果分析
本文將音頻、視頻以及多模態(tài)情感分析的精確度在IEMOCAP和WB-AV 2種數(shù)據(jù)集上對SVM、文獻[21]、文獻[22]、文獻[23]和本文的AV-MSA 5種方法的精確度進行了比較,結(jié)果見表1和表2。從實驗結(jié)果可知,SVM結(jié)果較差,而深度學(xué)習(xí)方法均取得較好的結(jié)果。經(jīng)過實驗分析可知,與SVM依賴于核函數(shù)的方法不同,深度學(xué)習(xí)方法能夠基于少數(shù)樣本集中學(xué)習(xí)訓(xùn)練數(shù)據(jù)的本質(zhì)特征。在此基礎(chǔ)之上,本文方法引入注意力機制,其加強特征選擇,聚焦于情感相關(guān)的特征。從表中可以看出,結(jié)合注意力機制的方法在性能上約有3%的提高。

圖7 情感示意圖

表1 IEMOCAP數(shù)據(jù)集上情感分類精確度

表2 WB-AV數(shù)據(jù)集上情感分類精確度
2.3.1 3種模態(tài)之間的比較
表1和表2展示了音頻、視頻和多模態(tài)分類的結(jié)果,可以看到在音頻模態(tài)方面,本文采用的情感分類的幾種方法差距不大,是因為將音頻文件轉(zhuǎn)化為音頻圖譜后,由于表達情感的方式不同,某些情感特征在音頻圖譜中表現(xiàn)不明顯或某些特征表現(xiàn)形式比較相近;另在視頻模態(tài)中,深度學(xué)習(xí)的方法要比傳統(tǒng)的機器學(xué)習(xí)方法如SVM性能優(yōu)異,這是由于直接從視頻幀圖片上提取的特征較多,且特征分布在面部的各個區(qū)域,如眼睛、嘴巴、鼻子等等,此外隨著網(wǎng)絡(luò)的加深,網(wǎng)絡(luò)對特征的提取與學(xué)習(xí)也越來越準確。在多模態(tài)方面,可以看出使用了音頻和視頻模態(tài)后的結(jié)果相較單模態(tài)有了大約10%~14%的提升。另外,相較于其他方法,AV-MSA約提升了3%。
2.3.2 7種情緒在3種模態(tài)下精確度比較
圖8為在AV-MSA方法下7種情緒在3種模態(tài)下的精確度,結(jié)果顯示,音頻的分類準確率要普遍低于視頻的分類,并且可以看到,對于害怕及生氣2種情緒,不管是用視頻還是音頻分類的結(jié)果,準確性均高于其他幾類情緒,而對于中性,如厭惡之類情緒的準確度相對較低,這可能是因為當(dāng)產(chǎn)生生氣以及害怕情緒時,人的面部表情比較豐富,聲音中的抖動也較多,能提取到較多的特征,而中性、驚訝之類的情緒則特征不明確。這與亞洲人在表達情感時較為含蓄有關(guān),因此能提取到的特征較少。
2.3.3 數(shù)據(jù)增強vs非數(shù)據(jù)增強
在深度學(xué)習(xí)中,充足的、高質(zhì)量的樣本能夠增強訓(xùn)練模型的泛化能力,因此,在本實驗中,采用數(shù)據(jù)翻轉(zhuǎn)、圖像縮放、圖像裁剪、圖像平移、色彩增強等分別對音頻和視頻數(shù)據(jù)集進行增強操作。從表1和表2的結(jié)果可以看出,采用數(shù)據(jù)增強后的性能約有5%~7%的提高。
2.3.4 遷移學(xué)習(xí)
由于WB-AV在采集方面條件比較苛刻,每次采集到新的短視頻,就要重新進行模型訓(xùn)練,這無疑增加了時間成本,降低了工作效率。因此,本文考慮通過較完備的IEMOCAP數(shù)據(jù)集來訓(xùn)練一個模型,并將其遷移到WB-AV數(shù)據(jù)集上進行分類實驗。從表3中可以看出,通過遷移學(xué)習(xí)后,多模態(tài)情感分類的準確度大約在52%左右。產(chǎn)生這一結(jié)果的原因可能是由于人種的差異引起的情感表達方式不同,從而導(dǎo)致了2個數(shù)據(jù)集的數(shù)據(jù)分布存在差異,使得分類的精確度不高。

表3 遷移學(xué)習(xí)

3 結(jié)束語
本文提出了AV-MSA模型,以分析短視頻中表現(xiàn)出的情感。該模型有2個分支:①音頻情感分析,采用CNN架構(gòu)提取音頻圖譜中的情感特征,實現(xiàn)情感分析的目的;②視頻情感分析,首先,為了確保特征的時間相干性,使用了3D卷積;其次,在Resnet的基礎(chǔ)上,為了突出情感相關(guān)特征,添加了注意力機制,以提高模型對信息特征的敏感性;最后,提出了將2分支結(jié)果融合在一起的交叉投票機制,融合結(jié)果即為短視頻的情感。所提模型在IEMOCAP和WB-AV數(shù)據(jù)集上進行了評估,其中WB-AV數(shù)據(jù)集由本文制作,主要反映了亞洲人的特點。實驗結(jié)果表明,與其他方法相比,該模型在性能上大約有3%的提升。在未來的研究中,將繼續(xù)擴展數(shù)據(jù)集以添加更多特征,例如人類生理行為。
[1] PORIA S, CHATURVEDI I, CAMBRIA E, et al. Convolutional MKL based multimodal emotion recognition and sentiment analysis[C]//2016 IEEE International Conference on Data Mining (ICDM). New York: IEEE Press, 2016: 439-448.
[2] MA J, SUN Y, ZHANG X. Multimodal emotion recognition for the fusion of speech and EEG signals[J]. Xi’an Dianzi Keji Daxue Xuebao/Journal of Xidian University, 2019, 46(1): 143-150.
[3] WU C H, LIANG W B. Emotion recognition of affective speech based on multiple classifiers using acoustic-prosodic information and semantic labels[J]. IEEE Transactions on Affective Computing, 2011, 2(1): 10-21.
[4] SOLEYMANI M, GARCIA D, JOU B, et al. A survey of multimodal sentiment analysis[J]. Image and Vision Computing, 2017, 65: 3-14.
[5] HUSSION I O, JAZYAH Y H. Multimodal sentiment analysis: a comparison study[J]. Journal of Computer Science, 2018, 14(6): 804-818.
[6] 吳良慶, 劉啟元, 張棟, 等. 基于情感信息輔助的多模態(tài)情緒識別[J]. 北京大學(xué)學(xué)報: 自然科學(xué)版, 2020, 56(1): 75-81. WU L Q, LIU Q Y, ZHANG D, et al. Multimodal emotion recognition based on emotional information assistance[J]. Journal of Peking University: Natural Science Edition, 2020, 56(1): 75-81 (in Chinese).
[7] 宋緒靖. 基于文本、語音和視頻的多模態(tài)情感識別的研究[D].濟南: 山東大學(xué), 2019. SONG X J. Research on multimodal emotion recognition based on text, speech and video[D]. Jinan: Shandong University, 2019 (in Chinese).
[8] DANG A, VU T H, WANG J C. Acoustic scene classification using convolutional neural networks and multi-scale multi-feature extraction[C]//2018 IEEE International Conference on Consumer Electronics (ICCE). New York: IEEE Press, 2018: 1-4.
[9] AKILAN T, WU Q J, SAFAEI A, et al. A 3D CNN-LSTM-based image-to-image foreground segmentation[J]. IEEE Transactions on Intelligent Transportation Systems, 2019, 21(3): 959-971.
[10] HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2016: 770-778.
[11] BUSSO C, BULUT M, LEE C C, et al. IEMOCAP: interactive emotional dyadic motion capture database[J]. Language Resources and Evaluation, 2008, 42(4): 335-359.
[12] HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 7132-7141.
[13] PéREZ-ROSAS V, MIHALCEA R, MORENCY L P. Multimodal sentiment analysis of Spanish online videos[J]. IEEE Intelligent Systems, 2013, 28(3): 38-45.
[14] IOFFE S, SZEGEDY C. Batch normalization: accelerating deep network training by reducing internal covariate shift[EB/OL]. [2020-03-02]. https://arxiv.org/ abs/1502.03167.
[15] PORIA S, CAMBRIA E, HAZARIKA D, et al. Context-dependent sentiment analysis in user-generated videos[C]//The 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg, PA: Association for Computational Linguistics, 2017: 873-883.
[16] PORIA S, CAMBRIA E, GELBUKH A. Deep convolutional neural network textual features and multiple kernel learning for utterance-level multimodal sentiment analysis[C]//2015 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2015: 2539-2544.
[17] NAIR V, HINTON G E. Rectified linear units improve Restricted Boltzmann machines[C]//The 27th International Conference on Machine Learning. New York: ACM Press, 2010: 807-814.
[18] HAN J, MORAGA C. The influence of the sigmoid function parameters on the speed of backpropagation learning[J]. From Natural to Artificial Neural Computation, 1995: 195-201.
[19] SRIVASTAVA N, HINTON G E, KRIZHEVSKY A, et al. Dropout: a simple way to prevent neural networks from overfitting[J]. Journal of Machine Learning Research, 2014, 15(1): 1929-1958.
[20] 程俊華, 曾國輝, 魯敦科, 等. 基于Dropout的改進卷積神經(jīng)網(wǎng)絡(luò)模型平均方法[J]. 計算機應(yīng)用, 2019, 39(6): 1601-1606. CHENG J H, ZENG G H, LU D K, et al. Improved convolutional neural network model averaging method based on Dropout[J]. Journal of Computer Applications, 2019, 39(6): 1601-1606 (in Chinese).
[21] TZIRAKIS P, TRIGEORGIS G, NICOLAOU M A, et al. End-to-end multimodal emotion recognition using deep neural networks[J]. IEEE Journal of Selected Topics in Signal Processing, 2017, 11(8): 1301-1309.
[22] CHAE M, KIM T H, SHIN Y H, et al. End-to-end multimodal emotion and gender recognition with dynamic joint loss weights[EB/OL]. [2020-06-12]. https://arxiv.org/abs/1809.00758.
[23] PARISI G I, BARROS P, WU H, et al. A deep neural model for emotion-driven multimodal attention[C]//2017 AAAI Spring Symposium Series. Palo Alot: AAAI, 2017: 482-485.
Multimodal sentiment analysis of short videos based on attention
HUANG Huan1, SUN Li-juan1,2, CAO Ying3, GUO Jian1,2, REN Heng-yi1
(1. College of Computer, Nanjing University of Posts and Telecommunications, Nanjing Jiangsu 210003, China; 2. Jiangsu High Technology Research Key Laboratory for Wireless Sensor Networks, Nanjing University of Posts and Telecommunications, Nanjing Jiangsu 210003, China; 3. College of Computer and Information Engineering, Henan University, Kaifeng Henan 475001, China)
The existing sentiment analysis methods lack sufficient consideration of information in short videos, leading to inappropriate sentiment analysis results. Based on this, we proposed the audio-visual multimodal sentiment analysis (AV-MSA) model that can complete the sentiment analysis of short videos using visual features in frame images and audio information in videos. The model was divided into two branches, namely the visual branch and the audio branch. In the audio branch, the convolutional neural networks (CNN) architecture was employed to extract the emotional features in the audio atlas to achieve the purpose of sentiment analysis; in the visual branch, we utilized the 3D convolution operation to increase the temporal correlation of visual features. In addition, on the basis of ResNet, in order to highlight the emotion-related features, we added an attention mechanism to enhance the sensitivity of the model to information features. Finally, a cross-voting mechanism was designed to fuse the results of the visual and audio branches to produce the final result of sentiment analysis. The proposed AV-MSA was evaluated on IEMOCAP and Weibo audio-visual (Weibo audio-visual, WB-AV) datasets. Experimental results show that compared with the current short video sentiment analysis methods, the proposed AV-MSA has improved the classification accuracy greatly.
multimodal sentiment analysis; ResNet; 3D convolutional neural networks; attention; decision fusion
TP 751.1
10.11996/JG.j.2095-302X.2021010008
A
2095-302X(2021)01-0008-07
2020-07-22;
22 Jnly,2020;
2020-08-04
4August,2020
國家自然科學(xué)基金項目(61873131,61702284);安徽省科技廳面上項目(1908085MF207);江蘇省博士后研究基金項目(2018K009B)
:National Natural Science Foundation of China (61873131, 61702284); Anhui Science and Technology Department Foundation (1908085MF207); Postdoctoral Found of Jiangsu Province (2018K009B)
黃 歡(1995–),男,浙江嘉興人,碩士研究生。主要研究方向為數(shù)字圖像處理與模式識別。E-mail:13736832754@163.com
HUANG Huan (1995-), male, master student. His main research interests cover digital image processing and pattern recognition. E-mail:13736832754@163.com
孫力娟(1963–),女,江蘇南京人,教授,博士。主要研究方向為無線傳感網(wǎng)、深度學(xué)習(xí)、模式識別等。E-mail:sunlijuan_nupt@163.com
SUN Li-juan (1963–), female, professor, Ph.D. Her main research interests cover wireless sensor network, deep learning, pattern recognition, etc. E-mail:sunlijuan_nupt @163.com
猜你喜歡
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
湖北經(jīng)濟學(xué)院學(xué)報·人文社科版(2015年8期)2015-12-29 05:53:07
上海電機學(xué)院學(xué)報(2015年4期)2015-02-28 14:30:00
計算物理(2014年2期)2014-03-11 17:01:39
