基于改進字節(jié)對編碼的漢藏機器翻譯研究
2021-04-09 03:10:26頭旦才讓仁青東主尼瑪扎西于永斌鄧權(quán)芯
電子科技大學(xué)學(xué)報 2021年2期
頭旦才讓,仁青東主,尼瑪扎西*,于永斌,鄧權(quán)芯
(1. 青海師范大學(xué)藏文信息處理教育部重點實驗室 西寧 810008;2. 西藏大學(xué)信息科學(xué)技術(shù)學(xué)院 拉薩 850000;3. 電子科技大學(xué)信息與軟件工程學(xué)院 成都 610054)
機器翻譯是利用計算機自動地將一種自然語言轉(zhuǎn)換為相同含義的另一種自然語言的過程[1]。機器翻譯在語言形態(tài)上分為語音翻譯和文本翻譯,其歷史發(fā)展已從基于規(guī)則的機器翻譯、基于統(tǒng)計的機器翻譯發(fā)展至基于神經(jīng)網(wǎng)絡(luò)的機器翻譯(即神經(jīng)機器翻譯)。目前,神經(jīng)機器翻譯已經(jīng)取代統(tǒng)計機器翻譯,成為Google、微軟、百度、搜狗等商用在線機器翻譯系統(tǒng)的核心技術(shù)[2]。
神經(jīng)機器翻譯最早在2013 年被提出,但是存在長距離重新排序和梯度爆炸消失等問題,翻譯效果不理想[3]。2014 年,文獻[4]提出了編碼器和解碼器框架,引入了長短時記憶模型,解決了長距離重新排序和梯度爆炸消失等問題,同時神經(jīng)機器翻譯的主要難題變成了固定長度向量問題。2015 年,文獻[5]將注意力機制應(yīng)用到機器翻譯中,解決了固定長度向量問題。
注意力機制的模型將注意力放在一些相關(guān)性高的詞上,編碼器和解碼器之間通過注意力機制連接[6],在翻譯目標(biāo)單詞時檢測其與源端語句相關(guān)的部分,解碼時融合了更多的源語言端信息,可以顯著提升機器翻譯效果,是目前神經(jīng)機器翻譯的主流方法,應(yīng)用廣泛。2018 年,文獻[7]使用自注意力機制來增強序列標(biāo)注模型的全局表示能力,從序列標(biāo)注任務(wù)端減少漢文分詞對隨后翻譯對影響的方法。在此基礎(chǔ)上,文獻[8]提出了格到序列的神經(jīng)機器翻譯模型。通過實驗,該模型在翻譯性能上顯著優(yōu)于傳統(tǒng)的基于注意力機制的序列到序列基線系統(tǒng)。同年,文獻[9]提出簡單循環(huán)單元的注意力機制模型。2019 年,文獻[10]提出了一個稀疏注意力模型,解決了注意力權(quán)重分布問題。2020 年,文獻[11]提出了一種深度注意力模型,大大提高了系統(tǒng)翻譯的忠實度。綜上,基于注意力機制的模型成為目前神經(jīng)機器翻譯領(lǐng)域的主流模型。
近幾年,研究人員在基于注意力機制模型的基礎(chǔ)上,利用不同的方法進行了漢藏藏漢神經(jīng)機器翻譯研究。2017 年,文獻[12]基于注意力機制和遷移學(xué)習(xí)方法,將英漢神經(jīng)網(wǎng)絡(luò)機器翻譯模型參數(shù)遷移到藏漢神經(jīng)網(wǎng)絡(luò)機器翻譯模型中。2018 年,文獻[13]將注意力機制模型應(yīng)用于漢藏機器翻譯任務(wù)中,實現(xiàn)了漢藏書面語料和口語語料的神經(jīng)機器翻譯。2019 年,文獻[14]在transformer 模型上,運用百萬句子單語數(shù)據(jù)大規(guī)模迭代式回譯策略,實現(xiàn)了藏漢神經(jīng)機器翻譯模型,文獻[15]也使用transformer實現(xiàn)了藏漢神經(jīng)機器翻譯模型,并將藏語單語語言模型融合到藏漢神經(jīng)機器翻譯中。
漢藏機器翻譯中的命名實體處理一直是最難以突破的一個技術(shù)環(huán)節(jié),為處理命名實體、同源詞、外來詞和形態(tài)復(fù)雜的詞,本文在模型訓(xùn)練時,改進藏文字節(jié)對編碼算法,優(yōu)化了基于注意力機制的翻譯模型,使得漢藏神經(jīng)機器翻譯效果更加準(zhǔn)確。
1 基于注意力機制和改進字節(jié)對編碼模型
藏文是拼音文字,音節(jié)之間用分隔符隔開,詞與詞之間沒有明確的分隔符,再者藏文有格助詞、助動詞等漢語文法不具有的語法單元,所以對應(yīng)的翻譯句子長度比漢語長。
1.1 注意力機制模型
為了解決長句的翻譯問題,本文系統(tǒng)(陽光漢藏機器翻譯系統(tǒng)V2)采用了基于注意力機制的神經(jīng)機器翻譯模型。
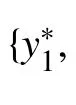
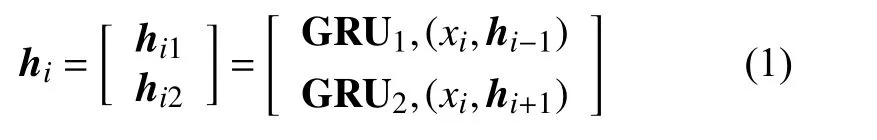
式中,GRU1和GRU2是兩個門控循環(huán)單元,從兩個方向循環(huán)地對x 編碼,然后拼接每個詞的輸出狀態(tài),即h={h1,h2,···,hls}。
解碼器依次生成藏文詞 yj:
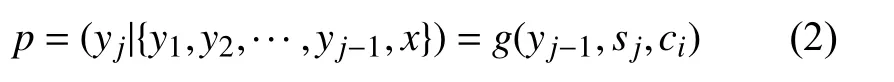
通過最大化藏文詞匯的似然來優(yōu)化整個翻譯模型:
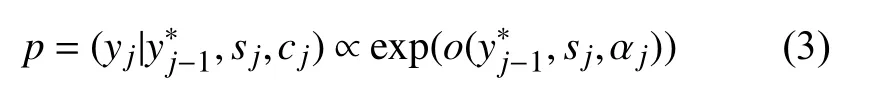
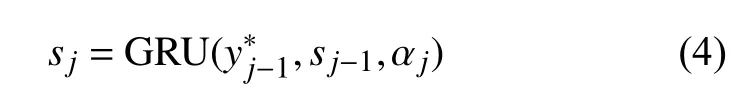
式中,GRU 是非線性函數(shù); αj是每次解碼動態(tài)更新的漢文上下文表示,依賴于漢文編碼序列h={h1,h2,···,hi}即每個漢文詞語狀態(tài)的加權(quán)和:
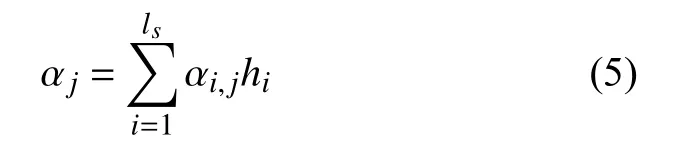
式中, αi,j是第i 個漢文詞語與第j 個藏文詞語之間的對齊概率:
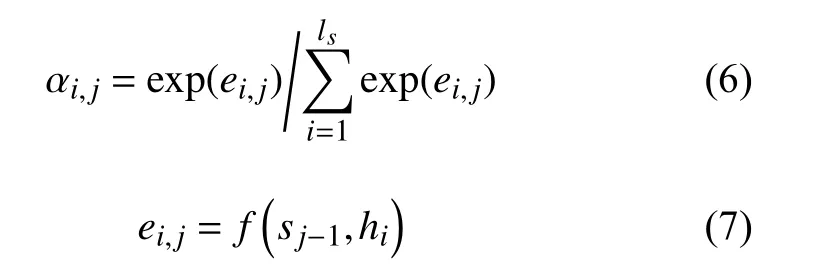
式中, ei,j是對齊模型,通過前饋神經(jīng)網(wǎng)絡(luò),計算出i 時刻生成的藏文詞與第j 個漢文詞的匹配程度。圖1 為基于注意力機制的神經(jīng)網(wǎng)絡(luò)翻譯模型,其中, yj表示模型在第j 步所預(yù)測詞語的概率分布,極大似然估計(MLE)表示計算損失的方法[16]。
1.2 改進的藏文字節(jié)對編碼算法
本文為了提高模型的穩(wěn)定性和翻譯的準(zhǔn)確率,訓(xùn)練時使用了一種帶字?jǐn)?shù)閾值的的藏文字節(jié)對編碼算法,優(yōu)化了翻譯模型。首先簡單描述一下原始字節(jié)對編碼算法。
1.2.1 字節(jié)對編碼
字節(jié)對編碼(byte pair encoding, BPE)指通過自動發(fā)現(xiàn)稀疏詞,建立基于稀疏詞的神經(jīng)網(wǎng)絡(luò)翻譯模型[17],即通過構(gòu)造高頻的字符片段,將稀疏詞拆分為合適的子詞,使得這些子詞在語料中的出現(xiàn)次數(shù)足夠高,從而進行訓(xùn)練,得到最優(yōu)的翻譯模型,BPE 算法流程圖如圖2 所示。
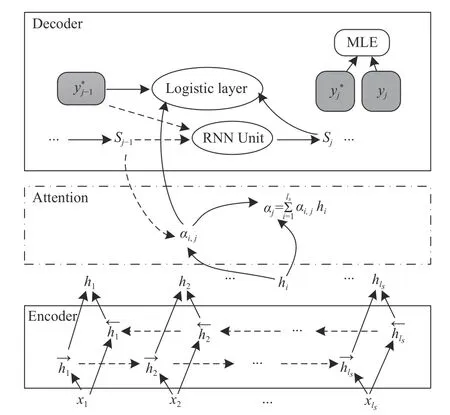
圖1 基于注意力機制的神經(jīng)網(wǎng)絡(luò)翻譯模型
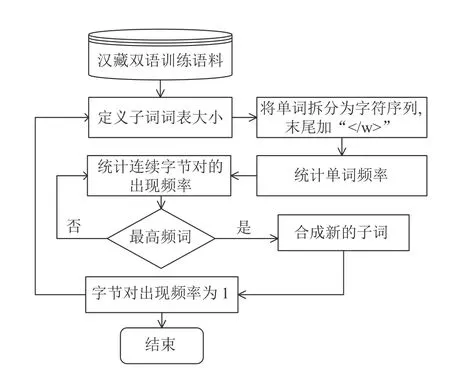
圖2 原始BPE 算法流程圖
1.2.2 改進的藏文字節(jié)對編碼算法
BPE 算法不需要對語料中的詞匯進行任何處理,由于藏文的詞與詞之間沒有空格,所以形式上不存在單詞邊界的問題,所以改進的BPE 算法中不需要詞頭詞尾標(biāo)記符號“</w>”。另外,通過分析藏文和漢文使用原始BPE 算法之后生成的子詞長度分布情況,發(fā)現(xiàn)藏文和漢文對應(yīng)最大子詞長度分別為39 和21,在長度峰值上,藏文子詞明顯大于漢文子詞。基于此,在分詞粒度較大的藏文部分,本文提出了一種改進的BPE 算法,使用長度閾值控制藏文子詞,合并出現(xiàn)頻率略低但長度更適合的子詞。其算法流程如圖3 所示。
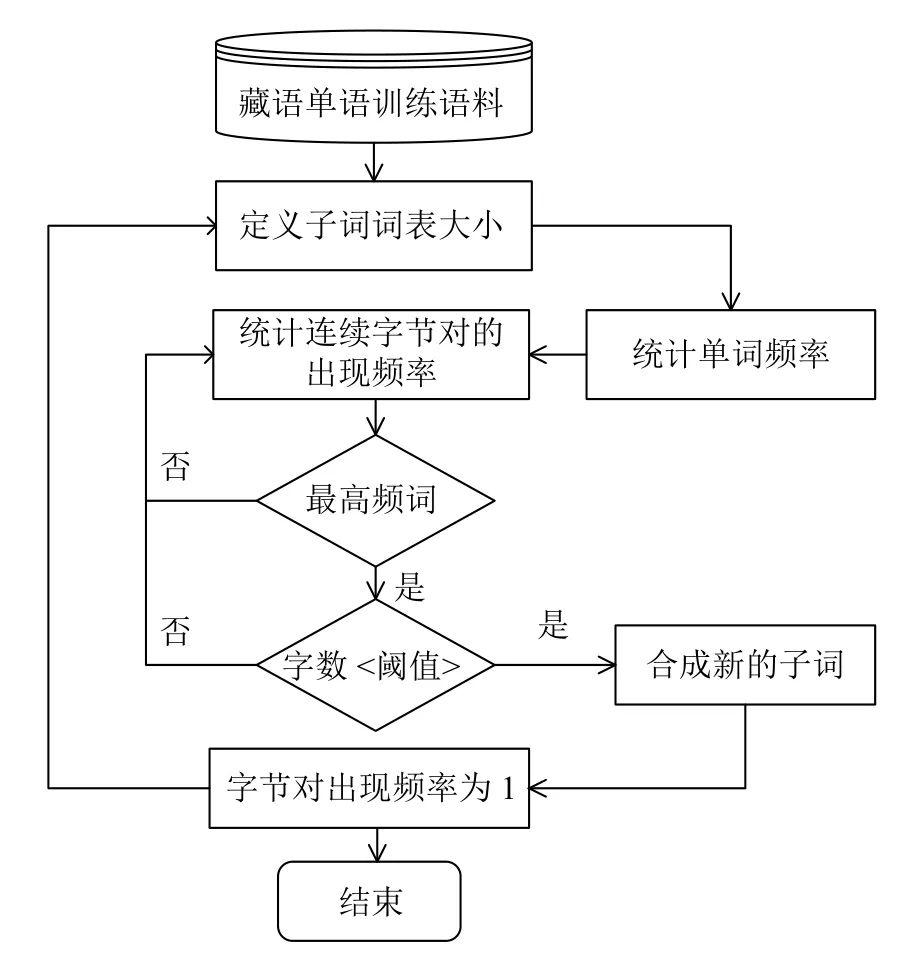
圖3 改進的BPE 算法流程圖
通過對比圖2 和圖3 的流程,相對于原始的BPE 算法,改進的藏文BPE 算法設(shè)置子詞字?jǐn)?shù)閾值,不提取字?jǐn)?shù)超過該閾值的子詞。實驗表明,當(dāng)設(shè)置的字?jǐn)?shù)閾值為23 時,效果提升最為明顯。
2 實驗結(jié)果對比與分析
2.1 數(shù)據(jù)集
本文使用西藏大學(xué)和青海師范大學(xué)建設(shè)的107 萬漢藏句對,經(jīng)糾正錯峰句對、檢查拼寫錯誤、校對斷句錯字和過濾重復(fù)句子,最終將100 萬句對作為訓(xùn)練語料,其中80 萬句對為新聞和法律題材,20 萬句對為其他領(lǐng)域語料;測試集和驗證集各1 000 句對。此外,為了提高翻譯效果,建立了15 萬詞條的漢藏地名詞典和5 萬條的漢藏人名詞典作為輔助工具。
2.2 參數(shù)設(shè)置
模型訓(xùn)練中,通過反復(fù)調(diào)整參數(shù),最終獲得最優(yōu)的模型參數(shù),具體描述如下。
所有的模型參數(shù)都使用隨機梯度下降算法進行優(yōu)化[18],學(xué)習(xí)率使用Adadelta 算法[19]進行自動調(diào)節(jié);訓(xùn)練語料漢文端和藏文端保留的最大句長為50 詞;漢文和藏文詞向量維度為512;編碼器和解碼器中循環(huán)神經(jīng)單元的隱狀態(tài)和輸出狀態(tài)均設(shè)為512;模型最終輸出層采用dropout 策略,dropout設(shè)置為0.5。
測試時本文使用束搜索算法進行解碼[20],搜索過程中束大小設(shè)置為10。漢文端和目藏文端的詞表大小設(shè)置為15 萬,覆蓋率100%。語料訓(xùn)練的輪數(shù)最大為50 輪。模型的超參數(shù)需要根據(jù)訓(xùn)練數(shù)據(jù)量來設(shè)置,通常數(shù)據(jù)量越大,模型的超參數(shù)如enc_hid_size、dec_hid_size 可以適當(dāng)放大。
2.3 結(jié)果與分析
本文實現(xiàn)了基于PyTorch 框架的注意力機制漢藏神經(jīng)網(wǎng)絡(luò)機器翻譯系統(tǒng),循環(huán)單元采用門控循環(huán)單元,評測指標(biāo)使用了BLEU4,采用基于字的評測方法。
漢藏雙語語料庫進行分詞時,漢文分詞使用了感知機、Hanlp 和BPE。藏文分詞使用了西藏大學(xué)開發(fā)的基于Perceptron+CRF 模型的藏文分詞系統(tǒng)[21]和改進的藏文BPE 算法。
本文在測試集、驗證集一致的前提下,做了6 組實驗。訓(xùn)練模型時,除實驗1 未使用BPE 算法外,其他實驗的譯文和原文都使用了BPE 算法和改進的藏文BPE 算法。6 組實驗的驗證集和測試集情況如下表1 所示。
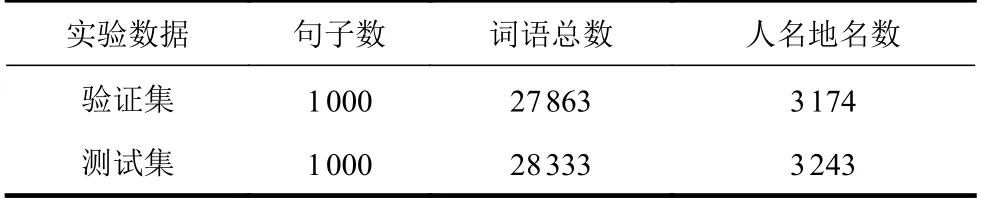
表1 實驗數(shù)據(jù)集
為了體現(xiàn)命名實體的翻譯效果,驗證集和測試集的每個句子中至少包含了一個地名或人名,因此通過該測試集得到的結(jié)果應(yīng)當(dāng)具有一定的通用性且能夠說明模型具有的泛化能力。
實驗數(shù)據(jù)、方法、結(jié)果如表2 所示。
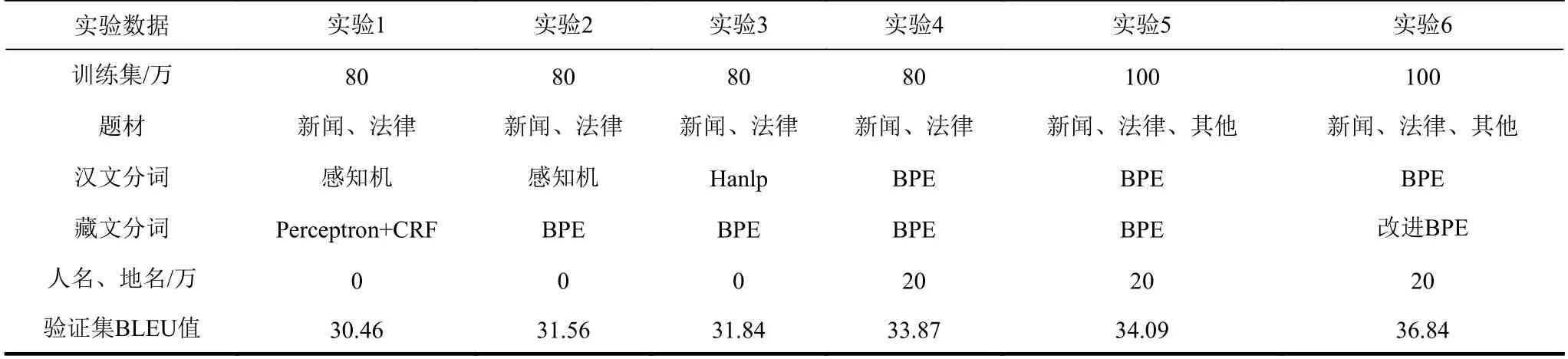
表2 實驗數(shù)據(jù)、方法、結(jié)果
在實驗中,第一組實驗使用了基于平均感知機的漢文分詞方法[22],目標(biāo)端沒有使用BPE 操作,BLEU 值最低,只有30.46。由于該漢文分詞器的分詞粒度較大,而藏文分詞器的分詞粒度較小,分詞粒度的差異導(dǎo)致翻譯效果不夠好,另外由于漢文分詞器的算法問題,導(dǎo)致前端的查詢速度很慢。
第二組實驗的漢文分詞方法和第一組實驗方法一樣,但是對藏文端使用了BPE 算法。雖然分詞粒度的差異導(dǎo)致翻譯效果不夠好,但是解決了一些稀疏詞和低頻詞翻譯問題,BLEU 值提高了1.10。
為了解決漢藏分詞粒度的耦合性,第三組實驗使用了Hanlp 漢文分詞器[23],因為其分詞粒度較小,也提供了更友好的Python 訪問接口;同時還提供了詞性標(biāo)注等更高級的功能,為后續(xù)對模型的優(yōu)化提供了更好的擴展性,另外查詢速度也得到提升。使用BPE 操作,提供了更細的分詞粒度,致使?jié)h文分詞和藏文分詞粒度契合,BLEU 值達到了31.84。
為了進一步提高翻譯效果,第四組實驗的漢文分詞使用了BPE 算法,并增加了20 萬條的人名地名詞典作為訓(xùn)練輔助工具,解決了命名實體翻譯問題,BLEU 值提高了2.03,達到了33.87。
第五組實驗在第四組實驗的基礎(chǔ)上,增加了20 萬條的人物傳記、小說和口語等雙語語料,由于語料題材的多樣性,BLEU 值僅提高了0.22,達到34.09。
上述五組實驗結(jié)果得知,如果僅僅使用原始BPE 算法,BLEU 值提高1.06,如果增加命名實體詞典,BLEU 值也僅僅提高2.03。為了體現(xiàn)改進的藏文BPE 算法的性能,第六組實驗在第五組實驗的基礎(chǔ)上,在藏文端使用了本文提出的BPE 改進算法,這時BLEU 值提高了2.75,達到了36.84。
本文根據(jù)模型在驗證集上的BLEU 值分?jǐn)?shù),當(dāng)BLEU 值出現(xiàn)震蕩或者模型過擬合,BLEU 值開始出現(xiàn)明顯下降時,停止訓(xùn)練。
2.4 與已商用化的漢藏翻譯對比
在已有的漢藏神經(jīng)機器翻譯研究[13-15]中,每個模型采用的訓(xùn)練語料和測試集不同,且目前漢藏機器翻譯領(lǐng)域尚未存在公開的數(shù)據(jù)集,因此各模型的BLEU 值無法進行對比。
本系統(tǒng)在翻譯任務(wù)上的效果較好,BLEU 值達到了36.84。原因如下:一方面,對訓(xùn)練語料進行了較為全面的校對,語料質(zhì)量較高;另一方面,神經(jīng)機器翻譯中命名實體翻譯一直是一個難題[24-25],通過改進BPE 算法和人名地名雙語詞典提升了命名實體翻譯現(xiàn)象,如由于詞典覆蓋率不夠,導(dǎo)致譯文中出現(xiàn)了unk,而本文方法能夠把原文的所有詞語完整地翻譯出來,不會出現(xiàn)unk。目前,國內(nèi)一些高校和研究機構(gòu)研發(fā)了在線漢藏機器翻譯系統(tǒng),其中,廈門大學(xué)開發(fā)的“云譯”[26]和中國民族語文翻譯局開發(fā)的在線智能翻譯系統(tǒng)[27]等的影響較大。現(xiàn)將本文翻譯系統(tǒng)與騰訊民漢翻譯、小牛翻譯[28]等已商用化的漢藏機器翻譯系統(tǒng)進行對比,其翻譯實例及結(jié)果如表3 所示。
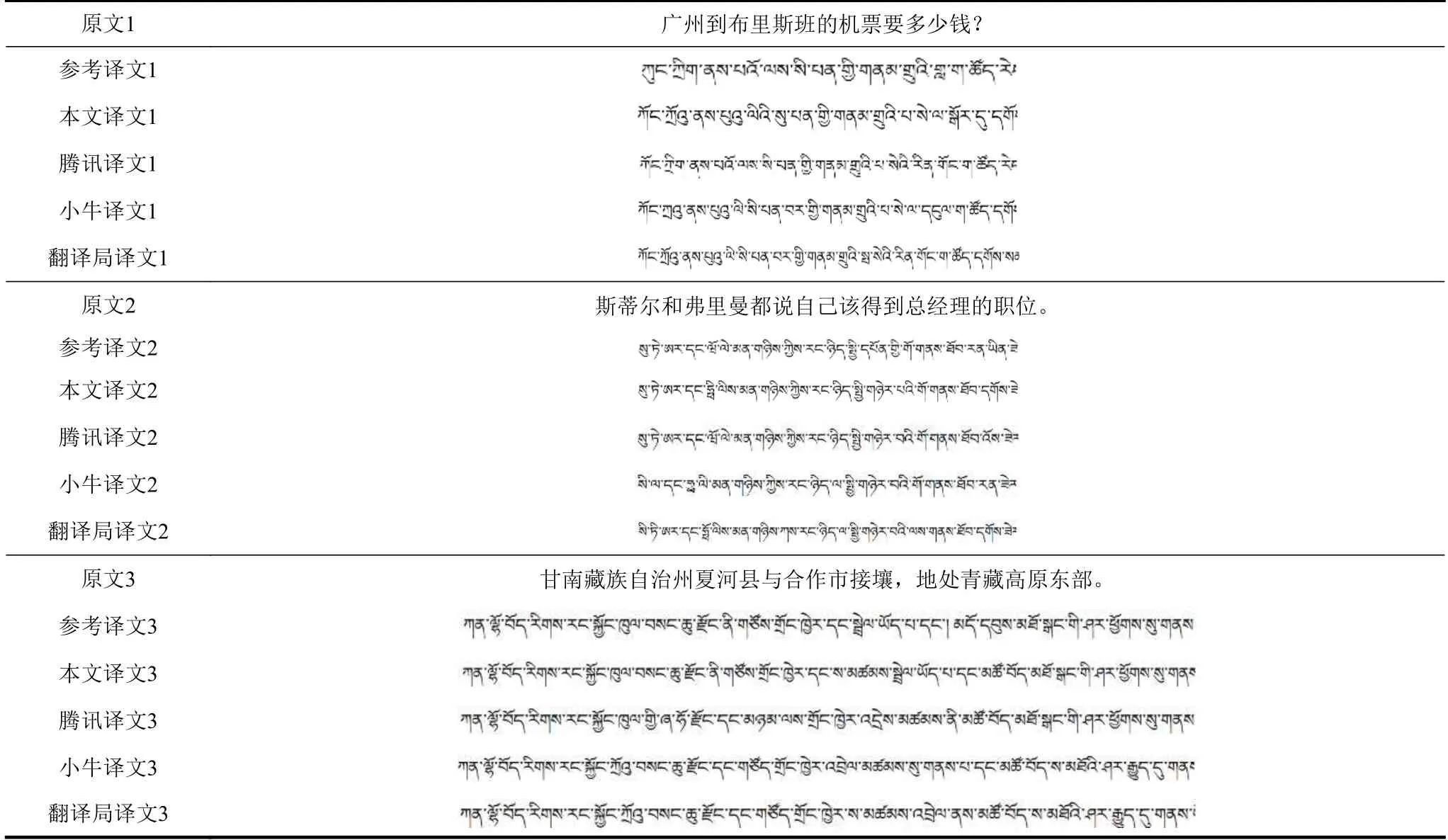
表3 本系統(tǒng)與已商用化的漢藏翻譯系統(tǒng)翻譯實例結(jié)果對比
翻譯實例1 和2 中包含了地名和人名,雖然1個漢文地名或人名的翻譯結(jié)果有5 個對應(yīng)的藏文地名和人名,但是漢藏地名人名翻譯沒有統(tǒng)一的標(biāo)準(zhǔn)可依,均可音譯,所以5 個譯文都沒有錯誤,結(jié)果相當(dāng)。
翻譯實例3 中包含了藏區(qū)地名,漢文中的藏區(qū)地名翻譯結(jié)果是統(tǒng)一的,所以本文翻譯系統(tǒng)的譯文完整地翻譯了實例中的地名“夏河”和“合作”,其他譯文的翻譯都有錯。
從以上翻譯結(jié)果對比可以看出,各種漢藏神經(jīng)機器翻譯雖然翻譯效果不錯,但各自也都存在一些不足。就本文翻譯系統(tǒng)而言,新聞和法律領(lǐng)域的翻譯結(jié)果較為流暢,但是其他領(lǐng)域的翻譯有待改進,如同樣的句子加上和去掉標(biāo)點符號得到的結(jié)果不同等現(xiàn)象。
3 漢藏神經(jīng)機器翻譯系統(tǒng)化
3.1 漢藏神經(jīng)機器翻譯模型總體流程
漢藏神經(jīng)機器翻譯模型由數(shù)據(jù)處理模塊、模型選取模塊、模型訓(xùn)練模塊、翻譯評測模塊和系統(tǒng)化模塊5 個部分組成,如圖4 所示。
3.2 本文漢藏機器翻譯系統(tǒng)架構(gòu)
本文漢藏機器翻譯系統(tǒng)V2 架構(gòu)由電子科技大學(xué)數(shù)字信息系統(tǒng)實驗室與西藏大學(xué)藏文信息技術(shù)人工智能自治區(qū)重點實驗室搭建。系統(tǒng)架構(gòu)主要由算法、后端和前端組成,算法就是模型的實驗,后端設(shè)計主要由Flask 框架實現(xiàn),首先將分詞器和神經(jīng)翻譯模型的初始化工作放在Flask 后端初始化之前,并將其保存在內(nèi)存中。每次請求到來時,只需調(diào)用已初始化完成的模型即可,這樣減少了大量響應(yīng)時間。經(jīng)簡單測試,加載神經(jīng)翻譯模型和分詞器只需要50 ms。通過后端設(shè)計,還實現(xiàn)了Android前端和網(wǎng)頁前端。漢藏神經(jīng)機器翻譯系統(tǒng)化總體架構(gòu)如圖5 所示。
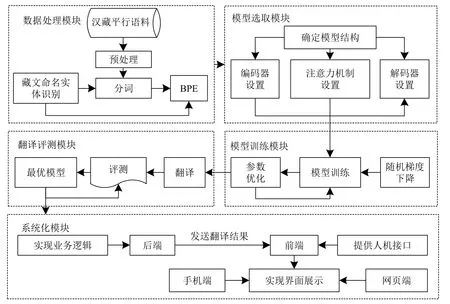
圖4 漢藏神經(jīng)機器翻譯模型總體流程
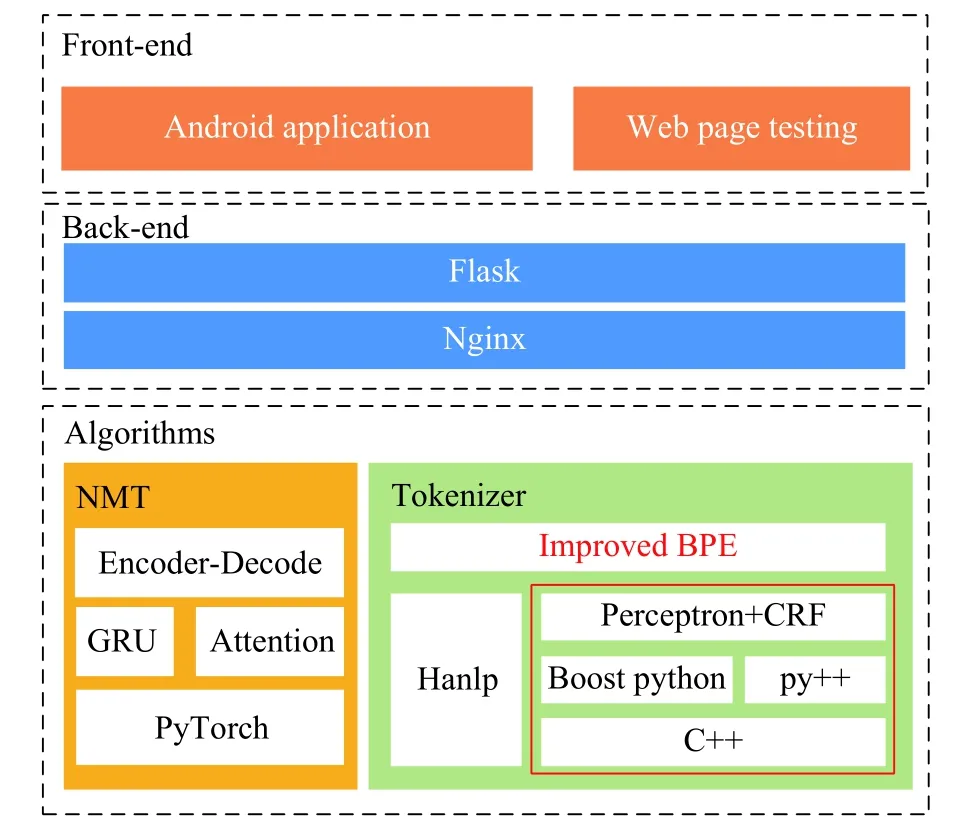
圖5 漢藏神經(jīng)機器翻譯系統(tǒng)總體架構(gòu)
4 結(jié) 束 語
本文利用100 萬漢藏句對和20 萬漢藏人名地名詞條,進行了基于注意力機制的神經(jīng)機器翻譯實驗,并提出了一種改進的BPE 算法,用以協(xié)調(diào)原始BPE 得到的藏文粒度大于漢文粒度的情況,將BLEU 提升了2.75%,減少了過度翻譯、翻譯不充分的問題,提升了命名實體翻譯效果。設(shè)計實現(xiàn)了基于注意力機制和改進字節(jié)對編碼的漢藏神經(jīng)機器翻譯模型,部署在陽光漢藏機器翻譯網(wǎng)站,實現(xiàn)了該漢藏神經(jīng)機器翻譯系統(tǒng)的應(yīng)用推廣。本文漢藏機器翻譯系統(tǒng)的模型具有語言無關(guān)性,完全可以應(yīng)用到藏漢神經(jīng)機器翻譯研究中。
由于漢藏神經(jīng)機器翻譯目前缺乏大規(guī)模雙語數(shù)據(jù),而藏語單語語料比較充足,所以下一步將利用格到序列、半監(jiān)督和無監(jiān)督方法提升翻譯效果。
共享和開放是計算語言學(xué)(自然語言處理)研究的發(fā)展趨勢,該工作在漢英機器翻譯技術(shù)領(lǐng)域獲得了很好的進展,免費開放了一些漢英英漢雙語平行語料,使得漢英機器翻譯技術(shù)具有可比性和競爭性。漢藏機器翻譯研究語言資源較少,沒有公開的語料,而且資源問題一直是困擾神經(jīng)機器翻譯研究和產(chǎn)業(yè)化的首要問題[29]。為此,我們開放了部分實驗數(shù)據(jù)和藏文地名詞典(獲取地址:https://github.com/toudancairang/Tibetan-Computationallinguistics/tree/master),希望吸引更多的人參與其中,建立藏文資源開放平臺,推動藏語計算語言學(xué)(藏語自然語言處理)研究,促進中文信息處理技術(shù)的整體發(fā)展。
致謝:該模型的構(gòu)建得到了中科院計算所自然語言處理實驗室同仁的大力支持。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學(xué)生數(shù)理化·中考版(2022年11期)2022-02-16 07:01:20
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
