基于改進Self-Attention的股價趨勢預測
2021-04-06 10:13:40鄭樹挺徐菲菲
計算機技術與發(fā)展 2021年3期
鄭樹挺,徐菲菲
(上海電力大學 計算機科學與技術學院,上海 200000)
0 引 言
金融市場被認為是世界經濟的核心,每天交易額巨大,對市場未來行為的預測對投資者來說具有重要的價值,包括股票市場、貨幣匯率[1]、原油價格[2]、商品價格和比特幣[3]等加密貨幣。由于市場的動態(tài)和嘈雜的行為,市場預測也是一項非常具有挑戰(zhàn)性的任務,吸引了較多學者的關注。
對股票市場的預測是一個非常具有挑戰(zhàn)性的問題,影響股票市場價格有很多因素,如公司新聞和業(yè)績、行業(yè)表現(xiàn)、投資者情緒、社交媒體情緒和經濟因素,用于預測的特征更是多種多樣:價格數(shù)據,歷史數(shù)據的技術指標,與個股有關的其他市場價格波動,貨幣匯率,油價等。自動提取特征并進行準確的市場預測受到了較多學者的關注。
現(xiàn)有的金融市場分析方法一般分為兩大類,一是基本面分析,另一個是技術分析。
在技術分析中,目標市場的歷史數(shù)據和其他一些技術指標均是預測的重要因素。根據有效市場假設[4],股票價格可以反映出它們的所有信息。技術分析通過分析以前的價格數(shù)據和技術指標預測市場價格的未來趨勢。而基本面分析研究證券投資的內在價值,可以通過獲取相關資產(主要是股票或交易所交易基金)的財務報表的詳細信息來實現(xiàn),如現(xiàn)金流量、增長率、貼現(xiàn)因子、每年折扣和資本化率等,以深入了解公司的未來發(fā)展前途。基本面分析通常用于決定應選擇哪種股票進行交易。
已經有多種機器學習技術廣泛應用于金融市場的預測,并取得了一定的效果,其中神經網絡和支持向量機(support vector machine,SVM)[5-7]使用的最多,例如,趙澄[8]使用SVM來預測金融新聞對股票市場的影響。此外,隨機森林[9]、遺傳算法[10-13]、集成學習[14-15]等技術也已成功應用于從原始金融數(shù)據中提取特征并基于特征進行預測[16-17]。
深度學習(deep learning)[18-19]是一類適合自動特征提取和預測的方法,在許多領域如機器視覺、自然語言處理以及語音信號處理,深度學習方法能夠從原始數(shù)據或更簡單的特征逐漸構建有用的復雜特征。由于股票市場的行為是復雜的、非線性的,而且股票數(shù)據具有噪聲,提取出準確的特征以進行預測面臨著巨大的挑戰(zhàn)。研究者嘗試了多種深度學習算法用于預測股票市場,如:深層多層感知器(MLP)[20]、Restricted Boltzmann Machine(RBM)[21-22]、Long Short-Term Memory(LSTM)[23-25]、Auto-Encoder(AE)[26]和Convolutional Neural Network(CNN)。
Periso & Honchar[27]將CNN用于股票分析中,根據收盤價的歷史數(shù)據進行預測,由于忽略了技術指標等其他可能的信息數(shù)據,預測的準確率并不高。Gunduz[28]將每個樣本的相關技術指標送入CNN中,提高了預測的準確率。Ding[29]通過對上市公司發(fā)出的公告進行事件提取來進行預測股價走向;Nguyen[30]、劉斌[31]則是基于社交媒體情緒分析的主題建模,然后用于股票市場預測。基于文本信息處理的方法雖然取得了一定的效果,但因為目前自然語言處理技術中語義理解方面仍然是一個難題,所以有一定的局限。
總體來說,現(xiàn)有的機器學習應用于股票預測主要分為兩類方法。第一類包括通過增強預測模型來提高預測性能的算法,而第二類算法側重于改進基于預測的輸入特征。雖然現(xiàn)有的研究取得了一些成果,但預測的準確率有待進一步的提升。該文通過改進Self-Attention結構,分別對日線數(shù)據、分時線數(shù)據以及籌碼結構進行編碼并融合信息。實驗結果表明,所提方法能夠有效提升股票未來走勢的判斷準確率并提高投資收益率。
1 相關研究
循環(huán)神經網絡(RNN)已經被證實適合處理時間序列數(shù)據,圖1所示為RNN的結構。

圖1 RNN結構示意圖
令s
s
(1)
其中,f一般是非線性的激活函數(shù),如sigmoid或tanh。RNN通過Backpropagation Through Time (BPTT)算法更新參數(shù),然而缺陷是無法處理序列長度過大的數(shù)據,因為會帶來梯度消失或梯度爆炸的問題。當然,目前已經提出多種方法解決這個問題,如LSTM、GRU。
LSTM與GRU在結構上很相像,在Transformer出現(xiàn)之前是處理時間序列問題的主流算法,如圖2所示為一個LSTM cell的網絡結構。

圖2 LSTM結構示意圖
具體來說,在LSTM循環(huán)單元中包含三個門(gate),F(xiàn)orget gate決定要扔掉哪些信息,計算公式見式(2):
f
(2)
Updating gate決定要增加哪些新的信息,計算公式見式(3):
i
(3)
Forget gate和Updating gate一起決定了“長記憶”c
(4)

(5)
Output gate決定了“短記憶”a
o
(6)
a
(7)
可以看出,在實際使用時,幾個門值不僅僅取決于a
Transformer[32]是谷歌在2017年發(fā)布的一個全新的網絡結構,Transformer本質上就是一個Attention結構,它能夠直接獲取全局的信息,而不像RNN需要逐步遞歸才能獲得全局信息,也不像CNN只能獲取局部信息,并且其能夠進行并行運算,要比RNN快很多倍。Transformer中一個重要的結構是Multi-Head Attention,計算公式見式(8),其中headi的計算公式見式(9):
MultiHead(Q,K,V)=Concat(head1,head2,…,
headh)Wo
(8)
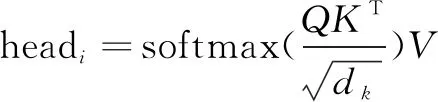
(9)
這里的Multi-Head的含義是,每個Transformer結構會由多層結構完全一樣,但權重矩陣不同的Attention組成,也就是Self-Attention結構。這么做的目的是為了防止模型只關注到一部分特征,卻忽略了其他特征,所以增加模型的厚度,讓模型擁有多層結構相同但是權重不同的Attention,每一個head都關注到不同的特征,那么模型整體就會關注到更多的特征。
2 基于改進Self-Attention的股票預測
2.1 數(shù)據獲取
實驗采用的數(shù)據將是從2018年1月1日到2019年10月31號、上證50成份股中的股票數(shù)據。數(shù)據獲取途徑均是從網絡上爬取下載獲得,從滬股通官網獲取到每日上證股票的港資持股量以及所占個股比例,從上海證券交易所官網獲取到每日個股的融資余額、融資買入額以及融資償還額,其他的分別是從“同花順”、“東方財富”等網站獲取。Input0包括K線數(shù)據,例如:開盤價、收盤價、最高價、最低價、日成交量、日成交額、換手率、MA5、MA10、MA20、MA30、市盈率、市凈率等,以及個股的滬股通數(shù)據、融資融券數(shù)據、資金流向數(shù)據(小、中、大、特大單的買入賣出量以及買入賣出額,以及凈流入量和凈流入額)等;Inpu1包括分時線數(shù)據,包含分時價格和分時成交量;Input2包括籌碼結構信息。
2.2 時序數(shù)據處理
因為獲取到的K線數(shù)據是未復權的,所以從2019年10月31號開始向前復權。將所有跟成交量有關的數(shù)據的單位統(tǒng)一轉換成“手”(1手等于100股),將所有跟金額有關的數(shù)據的單位統(tǒng)一轉換成“萬元”。下載的滬股通數(shù)據包括總持股數(shù)量和總持股占比,由前后兩日的總持股數(shù)量計算出單日滬股通成交量,再計算出滬股通當日凈成交量的占比。下載的融資融券數(shù)據包括融資余額和融券余額,分別計算出當日融資余額和融券余額占當日成交額的占比。小、中、大、特大單的買入賣出量以及買入賣出額,以及凈流入量和凈流入額也相應轉換成當日成交量或成交額的占比。
對部分特征進行歸一化處理,如成交量、成交額、流通股本等。對所有股票數(shù)據進行處理,生成時間序列數(shù)據(模型的Input0、Input1),維度為(L,M,N),其中M表示樣本數(shù),N表示總特征數(shù),L表示序列長度,也就是已知的前L天的數(shù)據,即L天的數(shù)據為一組特征,用前L天的數(shù)據來預測后一天漲幅。將時間序列數(shù)據的特征數(shù)分為兩個輸入分別對應于模型的兩個輸入Input0和Input1。
“漲幅”為用來訓練的標簽,定義為:(當日收盤價-昨日收盤價)/昨日收盤價;“漲幅正負”為用來驗證準確率和精度的標簽。這邊設定當漲幅為正時,則判定該股票的趨勢為漲(label:1);當漲幅不為正時,則判定該股票的趨勢為跌(label:0)。
對數(shù)據集進行劃分,其中訓練集數(shù)據的時間段為2018.01.01~2019.08.31,測試集數(shù)據的時間段為 2019.09.01~2019.10.31。分別對訓練集和測試集的漲跌分布進行了統(tǒng)計分析,發(fā)現(xiàn)訓練集和測試集的漲跌分布有一定的差異性,證明了改進的模型在后續(xù)的實驗中具有一定的泛化性。
2.3 融合多源數(shù)據
在股票交易操作上,一般短線操作都會實時關注個股的分時線走勢。在之前的一些研究中,利用機器學習預測股票一般都只關注了個股的日K線走勢及數(shù)據,而忽略了每日的分時線數(shù)據及其他一些數(shù)據。每日的分時線數(shù)據隱藏了大量的交易信息,例如可以看出大資金的流入流出,對于個股未來趨勢的預測提供了大量有用的信息。
改進的模型基于Self-Attention架構,解碼器采用全連接層,在編碼器端合并了日線數(shù)據(Input0)、分時線數(shù)據(Input1)以及籌碼結構數(shù)據(Input2),如圖3所示。分時線數(shù)據編碼器采用Multi-Head Attention和Feed Forward堆疊而成,有N層;日線數(shù)據編碼器也由N層堆疊而成,前N-1層結構一樣,但不共享參數(shù),最后一層通過對分時線數(shù)據編碼器輸出做Multi-head Attention輸出o1,對自身做Multi-head Attention輸出o0;籌碼結構編碼器采用全連接層,輸出o2。融合三個輸出o并進行解碼,計算公式見式(10)、(11)、(12):
m=σ(Wm·[o0,o1]+bm)
(10)
n=m⊙o0+(1-m)o1
(11)
o=Concat(n,o2)
(12)

圖3 改進的Self-Attention模型
3 實驗與分析
3.1 評估指標
在訓練階段,做的是回歸任務,即預測股票漲跌的幅度,損失函數(shù)用的是均方根誤差(root mean squared error,RMSE),計算公式見式(13):

(13)
根據樣本的真實結果和模型預測結果,將樣本分為四類:
TP(true positive),樣本是正樣本并且模型預測結果也是正樣本的個數(shù);
FN(false negative),樣本是正樣本但模型預測結果是負樣本的個數(shù);
FP(false positive),樣本是負樣本但模型預測結果是正樣本的個數(shù);
TN(true negative),樣本是負樣本并且模型預測結果也是負樣本的個數(shù)。
評價模型性能使用以下2個指標:準確率 (Accuracy)和精確率(Precision)。

(14)

(15)
3.2 實驗配置
實驗硬件配置為CPU:AMD-3700X,內存:32 G,GPU:RTX-2070。操作系統(tǒng)為UBUNTU 18.04,Python版本為3.7.3,深度學習框架采用Pytorch。優(yōu)化器選擇Adam,學習率為1e-4,使用256的小批量大小。
3.3 不同長度的時間序列數(shù)據效果對比
為了測試不同長度L的歷史數(shù)據對實驗結果的影響,使用改進的Self-Attention模型測試了不同L對預測準確率的影響,實驗結果見圖4。

圖4 不同長度L對結果的影響
3.4 模型效果
在測試集數(shù)據上,使用相同步驟的預處理步驟(這邊使用的歷史數(shù)據長度L為30),在不同的模型上進行測試得出的數(shù)據,如表1所示。可以發(fā)現(xiàn),RMSE降低了不少。圖5展示了改進的Self-Attention模型在部分個股上的預測結果。

圖5 改進的Self-Attention預測值

表1 算法性能對比
3.5 個股預測及投資收益
通過模型對測試數(shù)據進行預測買賣點以及收益率,選取股票“浦發(fā)銀行”作為操作說明。因為該模型是通過前L天(這里L取30)的數(shù)據預測后一天的漲幅,所以當預測的漲幅大于等于1%的時候,模型提示買入;預測的漲幅小于等于-1%的時候,模型提示賣出;當預測的漲幅在-1%到1%之間的時候,模型提示不操作。圖6展示了預測模型對買點和賣點的判斷,圖中提示的買賣時間點是每日的剛開盤時間(即9:30)。假設采取的策略是:當未持有該股票時,提示買入的時候,買入100股的股票;當持有該股時,提示買入的時候,不進行買賣操作;當提示賣出的時候,賣出持有該個股的所有股票,如果不持有該個股的股票則不進行買賣操作;既沒有提示買入也沒有提示賣出的時候,則不進行買賣操作。根據圖6,在“20190904”日剛開盤的時候以11.4的價格買入100股,在“20190905”日的時候雖然提示買入,當已經持有該股票,所以不進行操作,直到在“20190916”日剛開盤的時候以11.99的價格賣出100股,收益率是(11.99-11.4)/11.4=0.051 7,所以在“20190613”賣出的操作中收益率為0.051 7,其他的賣點收益計算類似。只有當進行賣出操作的時候收益率才會變化,圖7展示了三只股票在測試數(shù)據上的收益率變化。圖8展示了同期上證50指數(shù)的投資收益率以及采用模型預測的上證50個股平均收益率。可以發(fā)現(xiàn),改進Self-Attention模型可以提高投資收益率。
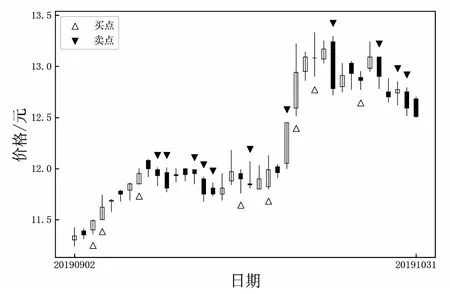
圖6 浦發(fā)銀行K線及買賣提示圖

圖7 部分個股投資收益變化曲線

圖8 同期投資收益變化
4 結束語
該文提出一種基于Self-Attention模型的金融時間序列預測模型,使用該模型預測中國證券市場上證50成分股,通過實驗驗證了模型的準確率和精確率:模型的預測準確率為61.32%,對正樣本的預測精確率為63.04%,這說明了改進的模型可以有效預測股票趨勢。在與其他模型的對比中效果更優(yōu)。由圖8可知,通過模型的預測買賣點進行股票買賣操作,在測試數(shù)據上的投資收益率為6.562%,而同期上證50指數(shù)的收益率3.260%,收益率提高了101.28%。所以改進的模型可以有效輔助投資并取得一定的收益,這表明該模型在股價趨勢預測上具有一定的有效性和實用性。
由于中國股市的散戶占比大,市場容易受到情緒波動的影響,因此下一步將結合對股民情緒的分析以增加模型的準確率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
