科技文獻中學術圖表標注研究進展
2021-04-02 12:08:33丁培葉蘭
現(xiàn)代情報 2021年4期
丁培 葉蘭

收稿日期:2020-10-10
基金項目:廣東省哲學社會科學規(guī)劃學科共建項目“支持深度知識發(fā)現(xiàn)的文內數(shù)據與文獻關聯(lián)研究”(項目編號:GD18XTS07);教育部人文社會科學研究青年基金項目“基于成熟度視角的高校圖書館科學數(shù)據管理服務能力評價研究”(項目編號:19YJC870028);國家社會科學基金項目“科技論文全景式摘要知識圖譜構建與應用研究”(項目編號:19BTQ61)。
作者簡介:丁培(1987-),男,館員,博士研究生,研究方向:知識組織,科學數(shù)據管理。
通訊作者:葉蘭(1983-),女,副研究館員,碩士,研究方向:數(shù)字圖書館,科學數(shù)據管理。
摘要:[目的/意義]科研用戶需要學術圖表助力精準知識發(fā)現(xiàn)服務。圖表標注是學術圖表融入學術知識發(fā)現(xiàn)體系需要解決的核心問題。[方法/過程]定義學術圖表標注范疇,以歷史研究為脈絡,梳理學術圖表發(fā)現(xiàn)研究及實踐發(fā)展階段,重點研究圖表標注的兩個核心問題:圖表標注組織和圖表標注實現(xiàn)。[結果/結論]總結現(xiàn)存研究問題,指出基于本體的學術圖表自動語義標注是支撐未來大規(guī)模學術圖表精準語義發(fā)現(xiàn)的圖表標注形態(tài)。未來還需要在學術圖表本體構建、學術圖表異構信息抽取等方面深入開展研究。
關鍵詞:科技文獻;學術圖表;圖表標注;知識組織;信息抽取;語義標注
DOI:10.3969/j.issn.1008-0821.2021.04.017
〔中圖分類號〕G254〔文獻標識碼〕A〔文章編號〕1008-0821(2021)04-0165-13
Research Progress of Academic Figures and
Tables Annotation in Scientific Literature
Ding PeiYe Lan*
(Library,Shenzhen University,Shenzhen 518060,China)
Abstract:[Purpose/Significance]Researchers need academic figures and tables to facilitate precise knowledge discovery services.Academic figures and tables annotation is a core problem to be solved when academic figures and tables are integrated into academic knowledge service system.[Method/Process]The authors define scope of academic figures and tables annotation.Taking the historical research as the context,the paper sorted out the development stage of academic figures and tables discovery in research and practical dimension,and then focued on the two core issues of academic figures and tables annotation:annotations organizational structure and annotating implementation.[Result/Conclusion]On the basis of summarizing the existing research problems,the paper pointed out that ontology-based automatic semantic annotation of academic figures and tables was the form of academic figures and tables annotation supporting the accurate semantic discovery of large-scale academic figures and tables in the future.In next,further research should be carried out in academic figures and tables ontology construction and heterogeneous information extraction of academic figures and tables.
Key words:scientific literature;academic figures and tables;academic figures and tables annotation;knowledge organization;information extraction;semantic annotation
學術圖表大量存在于科技文獻中。相關研究統(tǒng)計發(fā)現(xiàn),學術圖表正成為STEM期刊論文標配內容[1-2]。學術圖表是一系列、多步驟科學研究過程的最終產物。它被作者用于體現(xiàn)不同的用途,如多維指標對比(表),復雜對象論證(復合圖),特殊對象展示(DNA圖),直觀實驗展示(照片、成像圖),對比/趨勢/統(tǒng)計數(shù)據分析等,助力讀者直觀理解論文,提供比正常摘要更多的信息內容。通常STEM論文中,重要的科學研究結果需要借助圖表解釋說明;另一方面,讀者通過閱讀查看文獻內學術圖表評估文檔的相關性,并借助圖表信息來提高檢索效率。同時,相當部分的學術圖表和學術研究中產生的科學數(shù)據同源,甚至是科學數(shù)據精華所在,因而學術圖表成為科技文獻和科學數(shù)據間關聯(lián)的紐帶。總之,提供給定信息快速發(fā)現(xiàn)相關學術圖表成為科研發(fā)現(xiàn)中越來越重要的需求。
學術圖表具有表現(xiàn)類型多樣化、信息內容高度濃縮、與科學文獻內容高度相關的特征。類型多樣化帶來圖表識別挑戰(zhàn),信息內容高度濃縮需要構建有效的模型來幫助知識呈現(xiàn),而與科學文獻內容高度相關則帶來異構內容融合發(fā)現(xiàn)及建立文本內容與圖表間關系的問題。這些致使學術圖表檢索發(fā)現(xiàn)難以融入當前學術知識發(fā)現(xiàn)體系。
未來學術知識服務體系需要細粒度知識組織、基于語義的知識關聯(lián)、面向全資源類型的知識發(fā)現(xiàn)以及有效支持智能問答、意圖精準刻畫的認知計算。學術圖表作為重要的學術知識表現(xiàn)對象,要融入未來學術知識服務體系,則需要解決學術圖表標注這一關鍵瓶頸問題。
1學術圖表標注
“標注”一詞的含義很多,如標注是對文本特定部分所添加的形式注釋[3],又如附加數(shù)據到其他類型的數(shù)據[4],筆者認為標注是為數(shù)字對象(包括文本對象和非文本對象)添加注釋數(shù)據,這些注釋或是自身內容語義深度挖掘,或是系統(tǒng)化組織,或是與其他對象關聯(lián),其目的是增強人或機器對數(shù)字對象理解。學術圖表標注指為科技文獻中的學術圖表添加形式化或形式化語義注釋內容的過程及結果,其目的是理解學術圖表,發(fā)現(xiàn)學術圖表。
根據形式不同,標注可分為非形式化標注(如手寫筆記)、形式化標注及語義標注3種。形式化標注和語義標注按照一定的信息組織模式,均可用于機器理解,其中元數(shù)據組織標注作為一類形式化標注,已廣泛應用于計算機信息處理和信息資源發(fā)現(xiàn)過程中。形式化標注解決簡單的圖表語義描述問題,但其靈活性同時產生“信息孤島”,因此無法解決資源集合之間的相互關系問題,這需要語義標注的幫助。
語義標注是指為信息資源增加形式化、語義注釋,其形式化語義內容來源于本體(此處本體涵蓋領域敘詞表等語義組織體系),為信息資源提供標準化、形式化、抽象化的描述,也稱之為基于本體的語義標注。語義標注既是表示本體知識轉化為語義注釋的過程(包括信息抽取和實例標注),也是上述過程產生的語義注釋數(shù)據。通過語義形式化描述,它能幫助解決不同資源集合因不同描述產生的難以關聯(lián)問題,同時它將信息資源所隱藏的語義知識顯現(xiàn)地揭示出來,使這些內容更加容易被發(fā)現(xiàn)、關注及應用。學術圖表的語義標注是指基于本體對科技文獻中圖表信息內容實施語義組織、揭示語義關聯(lián),形成語義標注內容。
2學術圖表發(fā)現(xiàn)歷史
早在20世紀末數(shù)字圖書館興起之時,Bishop A P研究者就嘗試通過搜索特定期刊文章組成部分(圖、表格標題以及表格文字)來支持檢索科技期刊文章[5]。Futrelle R P發(fā)現(xiàn)在生物學領域中將近50%的論文文本內容與圖形相關[6]。Stelmaszewska H等研究計算機科學家閱讀文章行為及需求時發(fā)現(xiàn),用戶閱讀文章時會重點查看圖、表、公式等非文本內容,以此快速評估論文是否符合自身需求[7]。CSA通過期刊論文組件索引及檢索系統(tǒng)用戶需求的調查發(fā)現(xiàn),在檢索系統(tǒng)內搜索表格、圖形、圖表和地圖對研究、教學均非常重要,期刊文章中包含的表格及圖像能使判斷文章的相關性變得更加容易。此外需求分析還發(fā)現(xiàn)用戶要求在支持圖表檢索的系統(tǒng)應具有高精準度、靈活的檢索頁面、支持聯(lián)邦檢索、提供無縫的論文獲取、提供用于處理符號和支持符號檢索的標準化解決方案等功能[8]。
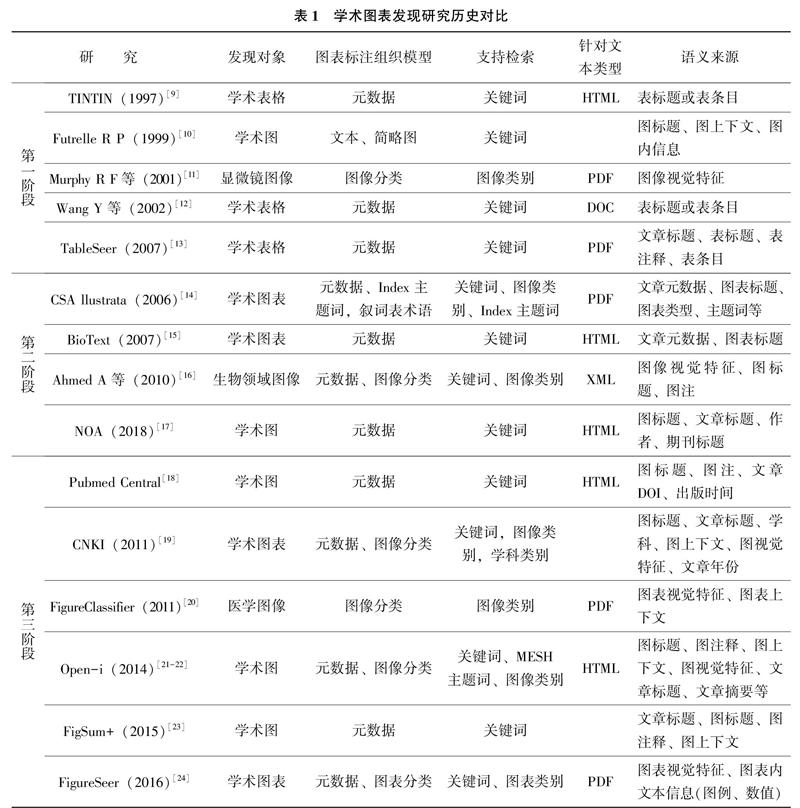
學術圖表的文本及視覺異物特征致使學術圖表的發(fā)現(xiàn)研究演進分化成兩條研究路徑。路徑一以學術圖表所涉及的文本信息為語義來源,通過信息抽取、知識組織將來源信息轉換為形式化標注內容,進而實施圖表發(fā)現(xiàn)。路徑二以學術圖表自身的特征內容(既包括圖像視覺特征,也包括圖表內文本特征)為語義來源,借助信息抽取和視覺識別等技術,并通過知識組織將來源信息轉換為形式化標注或語義標注內容來實現(xiàn)圖表發(fā)現(xiàn)。表1對部分學術圖表發(fā)現(xiàn)研究進行了對比。
歷經數(shù)十年的發(fā)展,學術圖表發(fā)現(xiàn)經歷了三方面的轉變,分別是發(fā)現(xiàn)對象從單一表或圖轉向綜合性的圖表,語義來源從簡單的標題等內容擴展到多模態(tài)信息復合,檢索支持從單一的關鍵詞檢索到關鍵詞檢索復合圖表分類及關聯(lián)發(fā)現(xiàn)。從發(fā)展歷史看,學術圖表發(fā)現(xiàn)總體經歷三階段的發(fā)展變化。
第一階段的發(fā)現(xiàn)研究主要關注于單一圖或單一表的發(fā)現(xiàn),語義來源較為簡單,如標題、表條目、圖特征等,通過元數(shù)據方式組織所抽取信息,并提供基于關鍵詞的檢索發(fā)現(xiàn)。第二階段的發(fā)現(xiàn)研究將學術圖表作為統(tǒng)一發(fā)現(xiàn)對象,語義來源擴展到圖表上下文,圖表所在論文的元數(shù)據信息。此階段以元數(shù)據組織方式為主,配合以關鍵詞檢索。第三階段嘗試融合路徑一和路徑二,將學術圖表的文本特征、視覺特征、外部關聯(lián)信息綜合為語義信息來源,借助信息抽取、視覺識別、機器學習等技術,基于元數(shù)據、圖表分類等組織方式形成形式化標注,并提供關鍵詞、簡單分類、主題語義等多維的圖表發(fā)現(xiàn)方式。
通過歷史研究發(fā)現(xiàn),無論哪個階段,學術圖表發(fā)現(xiàn)需要借助標注實現(xiàn),而標注需要解決兩個核心問題:圖表標注組織和圖表標注實現(xiàn)。前者為學術圖表標注提供結構化、形式化內容組織框架,幫助人和機器理解圖表的語義,后者通過技術建立學術圖表語義來源信息和組織模型間關聯(lián),并轉換為結構化標注內容。
3學術圖表標注組織
學術圖表發(fā)現(xiàn)過程需要將圖表涉及的將雜亂無序的語義信息來源內容轉化為有序、結構化的形式標注內容,這一過程需要標注組織框架的幫助。現(xiàn)有學術圖表標注組織框架涉及元數(shù)據組織、圖表分類組織及本體組織3種方式。
3.1元數(shù)據
元數(shù)據通過結構化描述,對具體的情境進行定制化的解釋,實現(xiàn)對資源的組織、發(fā)現(xiàn)、互操作、歸檔和保藏等。基于其表達的多樣化、靈活、門檻低的優(yōu)勢,元數(shù)據是最早應用于學術圖表標注的信息組織方式,也是實踐中應用最多的方式。
TableSeer[13]將學術表格信息組織為表格環(huán)境元數(shù)據(如文檔類型,表格所在文檔頁碼,文檔標題等)、表格框架元數(shù)據(記錄表格四周是否有框)、表格附屬元數(shù)據(表格標題、腳注、參考文獻)、表格布局元數(shù)據(如表寬、表長、行數(shù)、列數(shù)、分割線等)、表格內容元數(shù)據(表格中的值)、表格內容類型元數(shù)據(數(shù)值或非數(shù)值)等五類元數(shù)據。
CSA[14]通過深度索引技術,抽取文獻中的表格、圖片等數(shù)據,人工標引其元數(shù)據。標引的元數(shù)據框架包括圖表標題、圖表類別、DOI、地理術語、文獻作者、文獻標題、文獻摘要、期刊名稱、文獻主題等。
PMC[18]同樣基于元數(shù)據方式對論文中的學術圖進行增強表示,其學術圖的元數(shù)據包括圖標題、圖注、圖所在文章DOI、文章出版時間、同文圖片等。
CNKI[19]單獨抽取科技文獻中的學術圖片,使用15個元數(shù)據項描述圖片信息,包括圖片ID、圖片標題、圖片說明、圖片關鍵詞、圖詞、分類、圖片尺寸、圖片大小、圖片清晰度、圖片頁碼、圖片地址、同文圖片、語義相關圖片、讀者推薦圖片。
Open-i[22]是NIH開發(fā)的科研圖片數(shù)據庫,綜合來自Pubmed Central、Medpix、USC Orthopedic Surgical Anatomy、Images from the History of Medicine(NLM)、Indiana U.Chest X-rays等來源的科研圖片,其中Pubmed Central集合均是科技論文中的學術圖。其元數(shù)據組織內容包括圖片標題、圖片注釋、圖片上下文提及文本、圖片分類、論文標題、論文摘要、所屬機構、期刊名稱、MESH主題擴展等。
3.2圖表分類組織
圖表分類組織針對圖表視覺特征,從圖表類型上組織學術圖表信息。早在20世紀80年代,遙感領域[25]以及醫(yī)學領域[26]就研究各自領域中的學術圖像分類。圖表分類組織依賴計算機視覺識別和機器學習技術,而組織體系尚無通用性的標準,研究人員基于任務需求、領域特征、分類算法建立不同的圖表分類組織模型。表2列舉部分研究使用的圖像分類組織模型等信息。
3.3本體組織
本體是一種形式化組織方式,通過賦予異構數(shù)據以統(tǒng)一的語義信息,使得機器能夠理解信息并自動處理信息之間的語義聯(lián)系,從而提高異構數(shù)據之間的互操作性。
學術圖表作為文獻的重要組成部分,較早出現(xiàn)于文獻組織本體中。DoCo[32]、Discourse Elements Ontology(DEO)[33]等文獻本體將學術圖表作為單獨類目描述。學術圖表類目僅描述圖表標題、注釋(Lable、表格框Box)等內容。科學論文功能單元本體[34]嘗試組織學術圖表上下文內容,將其組織數(shù)據分析、數(shù)據描述內容,并匹配學術圖表的知識類型屬性(如確定性程度、情感傾向、來源),但未進一步細粒度分解學術圖表內容。
學術表格有固有組織特性(橫縱坐標分明),因而部分研究者采用自定義本體或者領域本體來對其進行語義組織。Madin J等構建了可擴展的觀測本體(Extensible Observation Ontology,OBOE),該本體由觀測、度量、實體、特征和度量標準5個核心概念構成,不僅可以描述每項觀測變量的上下文環(huán)境以及觀測值之間的相互關系,還支持魯棒性的單位描述和換算以及領域詞匯擴展[35]。開放城市數(shù)據平臺利用城市數(shù)據模型本體(City Data Model Ontology)將不同來源的數(shù)據轉換為RDF數(shù)據,轉換時根據一維表數(shù)據的特點(每一行對應一個城市和每一列對應一個統(tǒng)計指標),將每一行的數(shù)據映射到CityDataContext類的一個實例,每一列映射到一個屬性[36]。
領域敘詞表利用“用、代、屬、分、參、族”等關系對領域知識實施形式化組織,可看作一類簡單的領域知識本體。部分研究人員嘗試利用機器視覺識別、自然語言處理、機器學習算法等技術,結合領域敘詞表對學術圖表實施語義標注。結構化文本圖片發(fā)現(xiàn)系統(tǒng)(Structured Literature Image Finder System,SLIF)最早嘗試利用敘詞表語義組織圖表。它關注生物文獻中的顯微鏡成像圖,通過機器視覺識別的方法來發(fā)現(xiàn)成像圖中的基因、蛋白質概念[11]。Human Brain Project(HBP)將大腦成像圖片的特定區(qū)域和受控詞表中的概念關聯(lián)[37]。EMAP(The Edinburgh Mouse Atlas Project)利用解剖學詞表概念對老鼠胚胎的3D圖片和2D組織切面進行標注[38]。
筆者早期研究學術圖表的專門本體組織,將學術圖表的視覺信息、內外文本信息、學術圖表的外部關聯(lián)信息作為增強信息來源,梳理異構信息間語義關系,基于Protégé工具構建簡單文內數(shù)據本體框架[39]。后續(xù)基于語義標注任務構建水稻領域的學術圖表知識庫,并將其應用于學術圖表發(fā)現(xiàn)任務中。
3.4知識圖譜
知識圖譜(Knowledge Graph)是近年以來的熱點,它是一種知識表示方式。學界對于知識圖譜并沒有明確的定義。有研究者認為知識圖譜是一個知識庫,如Rospocher M等認為知識圖譜是從結構化知識庫或百科知識中抽取實體組成的事實知識庫[40]。部分研究者認為知識圖譜是基于圖的知識表示方式,如阮彤等定義知識圖譜是模式圖、數(shù)據圖及兩者關系組成的圖[41]。還有研究者把知識圖譜認為是一個本體,如認為知識圖譜是由實體、實體類型、屬性及關系構成的大型網狀網絡[42]。Paulheim H等認為圖譜包括實例A-box和模式T-box,其中A-box數(shù)據量遠大于T-box[43]。
本研究認為知識圖譜是包含大量實體、關系、屬性的結構化知識系統(tǒng)[44],它既包括模式層面的本體組織,也包括數(shù)據層的語義標注知識庫。簡而言之,知識圖譜包括本體和本體約束的實例內容(可稱為知識庫),本體為圖譜提供抽象表達,知識庫是本體的實例化。基于知識范圍,圖譜分為通用知識圖譜和行業(yè)知識圖譜兩大類[45]。通用知識圖譜如普林斯頓大學的Wordnet、谷歌的Freebase、維基百科的Dbpedia、微軟的Concept Graph等。行業(yè)知識圖譜如地理領域的Geonames、生物領域的UniprotKB、腦科學領域的Linked Brain Data知識庫、旅游領域的中國旅游景點知識圖譜等。學術資源領域也有知識圖譜應用,如微軟學術知識圖譜(MAKG)[46]、Springer Nature SciGraph[47]、學者網知識圖譜[48]、TechKG科技知識圖譜[49]等。目前暫未發(fā)現(xiàn)面向學術圖表知識組織的知識圖譜。
圖表標注實現(xiàn)的2個重點問題分別是學術圖表語義來源信息如何獲得,如何將無序的來源信息轉換為結構化語義內容,簡單而言,即信息抽取和實例標注。
4.1圖表信息抽取
信息抽取的覆蓋面及精準度直接影響到學術圖表標注的范圍和效果。學術圖表語義來源信息構成較為復雜,包括3個方面內容。第一方面內容來自圖表本身,如圖表類型、圖表內文本及數(shù)據(數(shù)據點、坐標軸、圖例、圖內對象)等;第二方面是圖表內容信息,包括圖表標題、圖表注釋、圖表上下文等;第三部分是圖表擴展信息,此部分信息能夠擴展圖表發(fā)現(xiàn)范圍,發(fā)現(xiàn)更多隱性關聯(lián)。包括論文信息、數(shù)據信息等。不同研究者基于不同來源信息對圖表實施信息抽取任務,具體而言可分為學術圖表自身信息抽取、學術圖表內容信息抽取、學術圖表擴展信息抽取。
4.1.1學術圖表自身信息抽取
學術圖表自身具有視覺信息和文本信息共存的特性。視覺信息一方面可用于增強表示為學術圖表類型;另一方面部分類型圖像視覺信息可以用于實體或概念標注(如成像圖、蛋白質序列圖)。文本信息(如坐標軸、圖例、圖內注釋等)則用于細粒度的知識描述。
1)圖像視覺信息抽取
視覺信息的抽取和標注通常結合在一起。抽取視覺信息標注圖表類型在3.2部分已有闡述。部分研究者針對照片、醫(yī)學圖像、成像圖等類型學術圖像,基于底層視覺信息,將視覺特征和文本特征共同考慮,利用視覺單詞或者領域術語來對圖像進行標注。Shamna P等將視覺信息位置信息補充到主題模型算法LDA中來抽取圖像視覺單詞,提高醫(yī)學成像圖的檢索精準度[50]。Kurtz C等基于圖像的顏色、位置、邊緣等特征,使用支持向量機(SVM)和Riesz小波自動學習方法,從醫(yī)學本體中自動注釋放射圖片[51]。深度卷積神經網絡在大規(guī)模視覺對象識別任務中獲得了廣泛的普及,尤其是在通用圖像檢索和醫(yī)學圖像檢索任務的多模(文本特征、圖像特征)特征學習上表現(xiàn)優(yōu)異[52-54]。
2)圖像文本信息抽取
圖像文本信息抽取可歸納為4個步驟。
第一步是文本檢測,測定圖像中文本存在。蔣夢迪等總結現(xiàn)存6種文本區(qū)域檢測算法:基于邊緣、基于紋理、基于連通分量、基于筆畫、基于深度學習和其他算法[55]。
第二步是文本定位,確定圖像中文本位置并且生成文本邊界框。顏色、邊、紋理特征及文本特征是文本定位常規(guī)使用的特征,點、區(qū)域、角色外觀等特征也被部分研究者關注和探索[56-57]。
第三步是文本分割階段,從圖像背景中分割文本,提取字符塊精確輪廓[58]。鑒于學術圖像分辨率偏低的特點,此過程容易產生噪音,需要進行文本圖像增強。
第四步是使用光學字符識別OCR技術將提取的文本圖像轉換成純文本。
3)圖像數(shù)值信息抽取
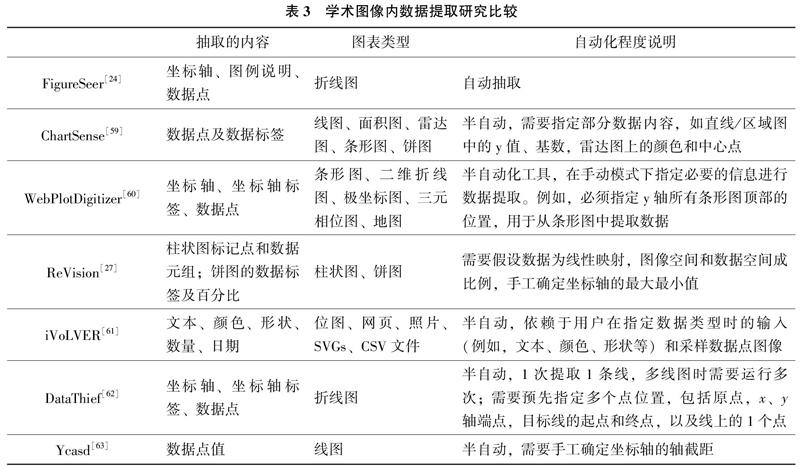
對于統(tǒng)計類型圖像,研究者不僅研究文本抽取,還研究圖內數(shù)據提取。學術圖像的數(shù)據提取可以分解為多個任務。在經過文本檢測和識別步驟獲得坐標軸標簽、圖例、數(shù)據點值后,需要建立數(shù)據標簽和數(shù)據內容之間的對應關系。已有學者研究不同類型圖表的數(shù)據內容提取,并嘗試開發(fā)相應的數(shù)據提取工具。數(shù)據提取工具對比如表3所示。
4)表格文本信息抽取
表格中文本抽取分兩類方式。一類是將表格轉換為圖片格式,基于圖像文本抽取步驟實施;一類是基于表格特征抽取表格文本。
表格特征指表頭、數(shù)據區(qū)的布局、文本特征,當前基于表格特征抽取文本內容又分為:
1)基于布局和樣式特征的自動抽取:將表格分為不同類型的布局,采用貝葉斯分類算法或者樹形遍歷算法,基于單詞間距、空格位置、文字大小、文字粗細、文字位置、縮進等特征,對表格的標題、表頭、數(shù)據區(qū)域做區(qū)分[64-65]。
2)半監(jiān)督學習的抽取:通過人工干預,確定表格的部分特征,利用機器分類算法來幫助識別表頭、數(shù)據區(qū)域。如Nagy G等早期使用半自動的方式,借助WNT、TAT、VeriClick工具來協(xié)助表格結構內容的理解[66]。
4.1.2學術圖表內容信息抽取
學術圖表的文本型信息包括圖表標題、注釋、上下文(論文正文中提及圖表的段落)。學術圖表的文本信息抽取的難點在于需要保證盡可能找到圖表所涉及的文本內容,同時盡量少引入無關的文本信息。
早期研究關注圖表標題的抽取。例如ACM檢索系統(tǒng)[67],MARIE項目[68]。隨著對圖表精確檢索需求顯化,與此同時自然語言處理技術取得突破進展,研究人員更關注正文中圖表提及文本內容的抽取。Demnerfushman D等強調分析與圖像關聯(lián)文本以理解圖像,并抽取醫(yī)學圖像的標題及論文中討論部分的圖表提及文本來增強醫(yī)學圖像的圖像注釋及檢索[69]。圖形摘要系統(tǒng)FigSum嘗試從醫(yī)學文獻中抽取出圖形的結構性文本摘要,并將文本分類為簡介、方法、結果和討論[70]。
現(xiàn)有研究提出了幾種圖表上下文抽取的方法,分別是:
1)明確提示法:基于標示性文字來識別明確引用圖表的句子或者段落,例如借助Fig、Table等關鍵詞,識別圖表所引用的句子或者段落。
2)基于信息檢索的方法:以圖表標題、圖例信息、參考語句或段落(明確引用的語句)為基準,基于主題相關性來查找與圖表標題最相似的句子來查找與圖表關聯(lián)的語句。
3)基于位置的抽取方法:以明確引用語句為參考語句,抽取與參考語句間距離為N句的內容。
Balaji P R等在生物學領域的圖像文本標注實驗中對比不同方法,發(fā)現(xiàn)明確提示法在精準度上獲得最好表現(xiàn),而基于信息檢索的方法在召回率上表現(xiàn)最佳,而混合兩者方法則在F值上表現(xiàn)最佳[71]。
4.1.3學術圖表外部關聯(lián)信息抽取
學術圖表外部關聯(lián)信息主要是指論文中的與圖表發(fā)現(xiàn)相關但并非對圖表進行直接描述的內容,如論文信息(論文標題、論文作者、作者機構、論文引用、論文關鍵詞等),數(shù)據信息(如補充數(shù)據標題、補充數(shù)據描述)和圖表引用信息(圖表引用文獻、圖表引用數(shù)據)等。
針對論文信息抽取,薛歡歡[72]總結論文信息抽取3種方式,并指出基于規(guī)則的論文信息抽取方法準確度高但可擴展性差,基于模板的論文信息抽取方法下效率高但受制于模板構建,基于機器學習的論文信息抽取方法靈活性、魯棒性最佳,但需要構建訓練語料。李朝光等利用正則表達式直接從PDF文檔中抽取首頁元數(shù)據,包括標題、作者、摘要和關鍵字[73]。更多的研究者利用工具將PDF轉換為XML格式文檔,基于XML規(guī)則來抽取論文信息,抽取信息有標題、作者名、地址、電子郵箱、摘要、關鍵字、引文[74-75]。Day M Y等采用模板匹配方法,設計層次化知識描述框架的InfoMap抽取論文中的引文元數(shù)據[76]。黃澤武也基于模板的方法識別與抽取標題、作者、摘要、參考文獻等信息[77]。機器學習的興起為論文信息抽取帶來新格局,研究者們采用包括SVM[78]、條件隨機場[79]、隱馬爾可夫模型[80]、深度神經網絡[81]等分類算法,通過訓練語料并建立樣本的輸入與輸出之間的關系來預測論文信息所屬分類。
數(shù)據信息主要指論文中補充數(shù)據材料信息。由于現(xiàn)有科技文獻中補充數(shù)據并非必須字段,且不同數(shù)據庫平臺對補充數(shù)據表示不一,因而尚未有人專門研究補充數(shù)據信息抽取。Kafkas S等挖掘Europe PMC FTP上41萬篇XML格式論文,通過元素和數(shù)據庫登錄號等方式篩選,發(fā)現(xiàn)16.8%的文章包含可轉換格式的補充數(shù)據[82]。Li J等[83]、Zhao M N等[84]均基于XML全文分析模式對文章中引用科學數(shù)據情況實施統(tǒng)計,但未針對補充材料項實施抽取。
盡管尚未有專門針對圖表引用信息的抽取研究,但此任務與文本中引文發(fā)現(xiàn)和抽取類似。多數(shù)學者關注引文數(shù)據的抽取,如Cortez E等從已經存在的領域訓練集元數(shù)據中自動生成模板,從而實現(xiàn)無監(jiān)督的引文元數(shù)據抽取[85],Peng F C等基于條件隨機場算法從Cora數(shù)據集中抽取引文元數(shù)據取得不錯效果[86]。部分學者對引文發(fā)現(xiàn)進行研究,如高良才等通過構建融合序號規(guī)則、內容規(guī)則、標點符號規(guī)則的特征集合從文本中發(fā)現(xiàn)、分割及標注引文信息[87]。還有學者研究引文上下文的抽取,如He Q等采用語言模型來定位引文內容,并采用了文獻不同部分的上下文相似度以及給定的引文內容聚類及概率模型的主題相關性來計算引文相關度值[88]。
4.2圖表實例標注
圖表實例標注是建立圖表標注組織模型和圖表語義信息內容關聯(lián),產生標注數(shù)據的過程。其中圖表標注組織模型為實例標注提供語義描述框架。不同組織模型產生不同的圖表標注數(shù)據。學術圖表元數(shù)據標注采用元數(shù)據組織模型描述學術圖表的語義信息來源,以形式化標注方式展示于HTML或XML頁面中,例如CNKI學術圖片知識庫中的圖片條目。學術圖表分類標注是將圖表視覺信息標注為人和機器可讀的文本型形式化標注內容,例如ReVision工具產生的圖類型標注結果。學術圖表語義標注以本體為組織模型,通過語義標注產生形式化語義標注內容,最終以XML、RDF、關聯(lián)數(shù)據等方式呈現(xiàn)。
元數(shù)據標注是目前主流的學術圖表標注方式。上文研究提到的CSA llustrata、Open-i、TableSeer、CNKI圖片檢索等均實踐了元數(shù)據標注方式。圖表分類標注通常會和元數(shù)據方式結合,共同展示于圖表發(fā)現(xiàn)平臺中,例如CNKI圖片檢索提供學術圖像分類的元數(shù)據標注。語義標注方面,現(xiàn)有研究多數(shù)以領域敘詞表或者領域本體為語義組織框架對學術圖表進行語義標注。
從實現(xiàn)方式看,圖表實例標注可分為人工標注和自動標注兩大類型。學術圖像的實例標注多采用人工標注方式。例如CSA llustrata[21]、Human Brain Project(HBP)[37]、EMAP(The Edinburgh Mouse Atlas Project)[38]。自動實例標注在學術表格中實踐較多。例如SemAnn利用PDF文檔解析工具PDF.js和自定義抽取算法將PDF文檔中人工選中的表格轉換為CSV格式,然后利用CSV-To-RDF轉換工具結合嵌入本體(如DBpedia、FOAF或自定義)實現(xiàn)對抽取出來的表格數(shù)據進行自動的語義標注[89]。Cao H等通過構建觀測事件模型,借助本體工具,利用規(guī)范化的觀測術語、實體對象,將觀測數(shù)據表格轉化為可理解的事件,進行自動語義標注[90]。Berkley C等對生態(tài)學領域用EML描述的一維表數(shù)據進行語義描述,采用的方法是首先采用OBOE本體描述數(shù)據的結構(即區(qū)分觀測、度量、上下文和實體并識別它們之間的關系),然后識別每個度量的特性、標準、度量值和條件,最后進行領域本體擴展[91]。
5學術圖表標注的未來研究展望
學術圖表是一個復雜的數(shù)字對象,其兼具視覺及文本兩方面特征,同時與科技文獻、科學數(shù)據存在緊密關聯(lián)。未來圖表發(fā)現(xiàn)需要融入支持全類型資源發(fā)現(xiàn)、支持語義關聯(lián)、支持細粒度精準知識發(fā)現(xiàn)的學術知識服務體系,圖表標注作為圖表發(fā)現(xiàn)的基礎,需要采用支持上述需求的圖表標注組織框架,并需要在面向海量圖表資源的自動圖表標注實現(xiàn)方面有所突破。
5.1構建支持全類型資源發(fā)現(xiàn)、語義關聯(lián)、細粒度精準知識發(fā)現(xiàn)學術圖表本體
圖表標注組織框架方面,現(xiàn)有3種圖表組織模式各有所長,適用于不同階段、不同需求的圖表發(fā)現(xiàn)任務中。元數(shù)據組織表達多樣化、靈活、門檻低,但不同領域元數(shù)據模型造成的“信息孤島”阻礙了知識融合和交互。圖像分類組織方式解決學術圖表視覺特征語義表示的問題,但無法凸顯學術圖表的綜合知識內容。本體組織以一種明確、形式化的方式表示信息資源,統(tǒng)一語義信息,但目前圖表的本體組織依托于其他學術知識本體或領域敘詞表知識組織,描述粒度粗,或僅表示領域知識,或未建立圖表與其他類型學術資源語義關聯(lián),難以滿足支持全類型資源發(fā)現(xiàn)、語義關聯(lián)、細粒度知識組織、精準知識發(fā)現(xiàn)需要。
從組織方式看,本體有支持跨學科形式化表達、支持細粒度語義關系擴展及支持語義推理等優(yōu)勢。本體結合知識圖譜等技術應用,可形成結構化、語義化、富關聯(lián)、可發(fā)現(xiàn)、可應用的知識庫。故而本文以為基于本體對學術圖表實施語義組織更適應未來發(fā)展趨勢。
一方面,可結合自上而下及自下而上的方式探索構建內容完整、關系清晰、知識可擴展、動態(tài)進化、機器可理解的學術圖表本體。通過解構學術圖表的形式結構(圖表本身、圖表內容、圖表關聯(lián)信息),按照圖表語義邏輯重新構造為圖表類型、圖表論證對象、圖表論證維度、圖表論證實驗內容(如實驗背景、實驗目的、實驗方法、實驗結果、實驗結論)、圖表論證關鍵特征(如對比、觀察、流程、分布等)、圖表外延內容(如同文圖表、同證圖表、同項目圖表、同作者圖表、同被引圖表、同數(shù)據來源圖表、同主題圖表、引用文獻、引用數(shù)據等)等內容,根據圖表語用邏輯,描繪學術圖表本體應用于圖表發(fā)現(xiàn)場景,定義核心概念、關系、屬性,形成學術圖表本體,豐富本體實例,在領域學術圖表語義標注實踐中應用本體,構建可用于圖表發(fā)現(xiàn)的學術圖表領域知識庫,并基于本體的標注任務中對本體不斷進化;另一方面,可以采取自下而上的知識圖譜構架模式,抽取圖表的實體、關系、屬性,對異構數(shù)據進行實體消歧、實體共指消解、實體鏈接、關系融合等步驟,最后通過知識推理、邏輯公理總結形成學術圖表本體。
5.2深入研究面向海量圖表資源的自動圖表語義標注實現(xiàn)
海量學術圖表資源標注需要自動技術的支持。這包含圖表信息自動抽取和基于本體的自動標注。
圖表信息抽取是圖表標注的內容基礎,需要從工程化、自動化實現(xiàn)方面深化研究。PDF格式文檔中的圖表信息抽取要解決圖表的識別與提取的問題。將文檔轉換為圖片,基于圖像識別的位圖分割技術、區(qū)域分類或連接組件等技術方法可解決部分類型學術圖像和表格識別及提取問題,可以在新的神經網絡算法支持下研究不同類型圖像識別的特征。
圖表自身信息抽取的4個子任務中,圖像中文本抽取、表格內文本信息抽取兩個任務的技術相對更加成熟,自動抽取準確度較高。而另外兩個任務則還有較大的發(fā)展空間。
在圖像視覺信息抽取及標注任務方面,目前未有工具實現(xiàn)所有類型圖表的分類標注,并且部分類型圖像的分類準確度不足以用于大規(guī)模應用。因而在圖表類型覆蓋以及分類精準度等方面還需深入研究。鑒于圖表類型在不同領域分類和分布不一,可結合圖表展示的視覺特征和圖表論證的內容特征,形成特定領域的圖表分類,再從領域分類中歸納出部分通用圖表分類,并基于機器學習算法提取相關特征。此外,圖像分類中要關注復合圖識別和子圖分類問題。可從基于復合圖文本特征、復合圖視覺特征、混合特征等角度來研究復合圖識別。復合圖的子圖識別是多標簽的分類任務,可從復合圖分割并分類或多標簽學習方法的角度識別子圖類型。分類精準度方面,新的卷積神經網絡算法相比傳統(tǒng)基于圖像低層特征的算法而言,可以獲得更高的分類精準度,其可擴展性和穩(wěn)定性都優(yōu)于傳統(tǒng)的分類算法。可以將圖像底層特征和圖表文本特征(如圖像的標題及圖注文本等)結合,基于神經網絡學習算法提升圖表類型分類精準度。
學術圖像中數(shù)值信息抽取是一個具有挑戰(zhàn)性的任務,已有研究多數(shù)針對折線圖、條形圖、散點圖、餅圖等圖像,其他圖像類型(如直方圖、氣泡圖、箱形圖、雷達圖、面積圖)的數(shù)據抽取精準度較低,需要基于這些圖形特征研究其數(shù)值信息的自動提取。此外,上述圖像數(shù)值抽取工具以半自動方式為主,需要人工輸入或者確定圖像的坐標軸信息(如起點、終點、截距等),應進一步結合圖像視覺識別技術,研究圖像內數(shù)值信息的全自動抽取。
圖表內容信息抽取技術相對成熟,在以下3個方面需要繼續(xù)研究。圖表標題和圖表本身匹配是重要的研究問題。自動抽取PDF格式論文內圖表標題時需要基于不同的圖表—標題布局(如1-to-1、N-to-N、N-to-M)確定對應關系。注釋內容抽取,需要關注學術復合圖中子圖標題和子圖注釋抽取問題,可總結和構建相關規(guī)則幫助抽取。重點關注圖表上下文提及內容自動抽取的準確率及召回率,深入研究圖表所在篇章位置和抽取模式的關系。
當下,論文中的補充數(shù)據信息抽取和論文文本中的圖表引用信息抽取暫且空白,可借鑒現(xiàn)有論文元數(shù)據抽取及論文引文抽取的思路,通過構建抽取規(guī)則、定義抽取模式或基于文本特征的機器學習方法來實現(xiàn)論文內數(shù)據信息自動抽取和圖表引用信息自動抽取。
基于本體的自動標注是建立抽取內容和學術圖表本體間關聯(lián)的過程。自動語義標注過程需要綜合圖表不同特征及本體中的概念、屬性、關系定義實施不同的語義實例標注方式。例如圖表標題、主題、圖表實驗信息等內容的自動語義標注可基于文本特征或利用規(guī)則或借助機器學習分類算法來獲得,而圖表類型的語義標注要融合視覺特征及文本特征來實現(xiàn)。
6結語
基于本體的學術圖表自動語義標注是支撐未來大規(guī)模學術圖表精準語義發(fā)現(xiàn)的圖表標注形態(tài)。它通過學術圖表本體對科技文獻中圖表信息內容實施多角度、深度語義組織,揭示學術圖表—論文—人—機構—項目—基金—補充材料等科學實體間語義關聯(lián),借助自動信息抽取、自動語義標注等技術支持,最終形成支撐圖表內容精準發(fā)現(xiàn),異構科學實體的統(tǒng)一發(fā)現(xiàn)的語義標注內容。現(xiàn)有研究和技術為基于本體的學術圖表自動語義標注創(chuàng)造部分條件,未來還需要在學術圖表本體構建、學術圖表異構信息抽取等方面深入開展研究。
參考文獻
[1]Siegel N,Lourie N,Power R,et al.Extracting Scientific Figures with Distantly Supervised Neural Networks[C]//ACM IEEE Joint Conference on Digital Libraries,2018:223-232.
[2]Lee P S,West J D,Howe B,et al.Viziometrics:Analyzing Visual Information in the Scientific Literature[J].IEEE Transactions on Big Data,2018,4(1):117-129.
[3]米楊.基于頂級本體整合的醫(yī)學領域語義標注研究[D].長春:吉林大學,2012.
[4]于曉繁.基于本體和元數(shù)據的語義標注平臺模型與系統(tǒng)架構研究[D].淄博:山東理工大學,2012.
[5]Bishop A P.Document Structure and Digital Libraries:How Researchers Mobilize Information in Journal Articles[J].Information Processing and Management,1999,35(3):255-279.
[6]Futrelle R P.Handling Figures in Document Summarization[C]//Proceedings of the ACL-04 Workshop:Text Summarization Branches Out,2004:61-65.
[7]Stelmaszewska H,Blandford A.From Physical to Digital:A Case Study of Computer Scientists Behaviour in Physical Libraries[J].International Journal on Digital Libraries,2004,4(2):82-92.
[8]Sandusky R J,Tenopir C,Casado M M.Figure and Table Retrieval from Scholarly Journal Articles:User Needs for Teaching and Research[J].Proceedings of the American Society for Information Science and Technology,2007,44(1):1-13.
[9]Pyreddy P,Croft W B.TINTIN:A System for Retrieval in Text Tables[C]//ACM International Conference on Digital Libraries,1997:193-200.
[10]Futrelle R P.Summarization of Diagrams in Documents[J].Advances in Automated Text Summarization,1999:403-421.
[11]Murphy R F,Velliste M,Yao J,et al.Searching Online Journals for Fluorescence Microscope Images Depicting Protein Subcellular Location Patterns[C]//Bioinformatics and Bioengineering,2001:119-128.
[12]Wang Y,Hu J.A Machine Learning Based Approach for Table Detection on the Web[C]//The Web Conference,2002:242-250.
[13]Liu Y,Bai K,Mitra P,et al.TableSeer:Automatic Table Metadata Extraction and Searching in Digital Libraries[C]//ACM/IEEE Joint Conference on Digital Libraries,2007:91-100.
[14]Carol T,Robert J S,Margaret C.The Value of CSA Deep Indexing for Researchers(Executive Summary)[EB/OL].https://trace.tennessee.edu/cgi/viewcontent.cgi?article=1001&context=utk_infosciepubs,2020-08-31.
[15]Hearst M A,Divoli A,Guturu H,et al.BioText Search Engine:Beyond Abstract Search[J].Bioinformatics,2007;23(16):2196-2197.
[16]Ahmed A,Arnold A,Coelho L P,et al.Invited Paper:Structured Literature Image Finder:Parsing Text and Figures in Biomedical Literature[J].Journal of Web Semantics,2010,8(2):151-154.
[17]Charbonnier J,Sohmen L,Rothman J,et al.NOA:A Search Engine for Reusable Scientific Images Beyond the Life Sciences[C]//European Conference on Information Retrieval,2018:797-800.
[18]PMC[EB/OL].https://www.ncbi.nlm.nih.gov/pmc/,2020-08-31.
[19]CNKI學術知識圖片庫[EB/OL].http://image.cnki.net/Default.aspx,2020-08-31.
[20]Kim D,Ramesh B P,Yu H,et al.Automatic Figure Classification in Bioscience Literature[J].Journal of Biomedical Informatics,2011,44(5):848-858.
[21]Simpson M S,Demner-fushman D,Antani S K,et al.Multimodal Biomedical Image Indexing and Retrieval Using Descriptive Text and Global Feature Mapping[J].Information Retrieval,2014,17(3):229-264.
[22]Open-i[EB/OL].https://openi.nlm.nih.gov/,2020-08-31.
[23]Ramesh B P,Sethi R J,Yu H,et al.Figure-associated Text Summarization and Evaluation[J].Plos One,2015,10(2).
[24]Siegel N,Horvitz Z,Levin R,et al.FigureSeer:Parsing Result-Figures in Research Papers[C]//European Conference on Computer Vision,2016:664-680.
[25]王一達,沈熙玲,謝炯.遙感圖像分類方法綜述[J].遙感信息,2006,(5):67-71.
[26]李莉,木拉提·哈米提.醫(yī)學影像數(shù)據分類方法研究綜述[J].中國醫(yī)學物理學雜志,2011,28(6):3007-3011.
[27]Savva M,Kong N,Chhajta A,et al.ReVision:Automated Classification,Analysis and Redesign of Chart Images[C]//User Interface Software and Technology,2011:393-402.
[28]Prasad V S,Siddiquie B,Golbeck J,et al.Classifying Computer Generated Charts[C]//Content Based Multimedia Indexing,2007:85-92.
[29]Huang W,Zong S,Tan C L,et al.Chart Image Classification Using Multiple-Instance Learning[C]//Workshop on Applications of Computer Vision,2007:27-27.
[30]Tang B,Liu X,Lei J,et al.DeepChart:Combining Deep Convolutional Networks and Deep Belief Networks in Chart Classification[J].Signal Processing,2016:156-161.
[31]Kim D,Ramesh B P,Yu H,et al.Automatic Figure Classification in Bioscience Literature[J].Journal of Biomedical Informatics,2011,44(5):848-858.
[32]Constantin A,Peroni S,Pettifer S,et al.The Document Components Ontology(DoCO)[J].Semantic Web,2016,7(2):167-181.
[33]The Discourse Elements Ontology(DEO)[EB/OL].https://sparontologies.github.io/deo/current/deo.html,2020-05-02.
[34]王曉光,李夢琳,宋寧遠.科學論文功能單元本體設計與標引應用實驗[J].中國圖書館學報,2018,(4):73-88.
[35]Madin J,Bowers S,Schildhauer M,et al.An Ontology for Describing and Synthesizing Ecological Observation Data[J].Ecological Informatics,2007,(2):279-296.
[36]Bischof S,Martin C,Polleres A,et al.Collecting,Integrating,Enriching and Republishing Open City Data as Linked Data[C]//International Conference on the Semantic Web-ISWC 2015.Berlin:Springer,2015:58-75.
[37]Gertz M,Sattler K U,Gorin F,et al.Annotating Scientific Images:A Concept-based Approach[C]//Scientific and Statistical Database Management,IEEE,2002:59-68.
[38]EMAGE.Data Annotation Methods[EB/OL].http://www.emouseatlas.org/emage/about/data_annotation_methods.html#auto_eurexpress,2015-11-02.
[39]丁培.科學論文內的科學數(shù)據組織和發(fā)現(xiàn)研究[J].現(xiàn)代情報,2020,40(2):34-43.
[40]Rospocher M,Erp M V,Vossen P,et al.Building Event-Centric Knowledge Graphs from News[J].Web Semantic:Science,Service and Agent on the World Wide Web,2016:132-151.
[41]阮彤,王夢婕,王昊奮,等.垂直知識圖譜的構建與應用研究[J].知識管理論壇,2016,(3):226-234.
[42]Kroetsch M,Weikum G.Journal of Web Semantics:Special Issue on Knowledge Graphs[EB/OL].http://www.websemanticsjournal.org/2019/05/cfp-jws-special-issue-on-language.html,2020-11-16.
[43]Paulheim H,Cimiano P.Knowledge Graph Refinement:A Survey of Approaches and Evaluation Methods[J].Semantic Web,2017,8(3):489-508.
[44]Su Y,Zhang C,Li J,et al.Cross-Lingual Entity Query from Large-Scale Knowledge Graphs[C]//APWeb 2015 Workshops,2015:139-150.
[45]白林林.基于知識圖譜的領域知識結構構建方法研究[D].北京:中國科學院大學,2019.
[46]Microsoft Academic Knowledge Graph[EB/OL].http://ma-graph.org/,2020-11-10.
[47]SN SciGraph[EB/OL].https://www.springernature.com/gp/researchers/scigraph,2020-11-10.
[48]SCHOLAT學者網[EB/OL].http://www.scholat.com/,2020-11-10.
[49]東北大學-知識圖譜研究組[EB/OL].http://www.techkg.cn/,2020-11-10.
[50]Shamna P,Govindan V K,Nazeer K A,et al.Content Based Medical Image Retrieval Using Topic and Location Model[J].Journal of Biomedical Informatics,2019.
[51]Kurtz C,Depeursinge A,Napel S,et al.On Combining Image-based and Ontological Semantic Dissimilarities for Medical Image Retrieval Applications[J].Medical Image Analysis,2014,18(7):1082-1100.
[52]Frome A,Corrado G S,Shlens J,et al.DeViSE:A Deep Visual-Semantic Embedding Model[C]//Neural Information Processing Systems,2013:2121-2129.
[53]Weston J,Bengio S,Usunier N,et al.Large Scale Image Annotation:Learning to Rank with Joint Word-image Embeddings[C]//European Conference on Machine Learning,2010,81(1):21-35.
[54]Pereira J C,Vasconcelos N.Cross-modal Domain Adaptation for Text-based Regularization of Image Semantics in Image Retrieval Systems[J].Computer Vision and Image Understanding,2014:123-135.
[55]蔣夢迪,程江華,陳明輝,等.視頻和圖像文本提取方法綜述[J].計算機科學,2017,(2):8-18.
[56]Bschen F,Scherp A.A Comparison of Approaches for Automated Text Extraction from Scholarly Figures[C]//Conference on Multimedia Modeling,2017:15-27.
[57]Ye Q,Doermann D.Text Detection and Recognition in Imagery:A Survey[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2015,37(7):1480-1500.
[58]De S,Stanley R J,Cheng B,et al.Automated Text Detection and Recognition in Annotated Biomedical Publication Images[J].International Journal of Healthcare Information Systems and Informatics,2014,9(2):34-63.
[59]Jung D,Kim W,Song H,et al.ChartSense:Interactive Data Extraction from Chart Images[C]//Human Factors in Computing Systems,2017:6706-6717.
[60]Ankit Rohatgi.WebPlotDigitizer[EB/OL].https://automeris.io/WebPlotDigitizer,2020-09-02.
[61]Méndez G G,Nacenta M A,Vandenheste S,et al.iVoLVER:Interactive Visual Language for Visualization Extraction and Reconstruction[C]//Human Factors in Computing Systems,2016:4073-4085.
[62]DataThief III[EB/OL].https://www.datathief.org/,2020-09-02.
[63]Gross A,Schirm S,Scholz M,et al.Ycasd-A Tool for Capturing and Scaling Data from Graphical Representations[J].BMC Bioinformatics,2014,15(1):219-219.
[64]Nagy G.Learning the Characteristics of Critical Cells from Web Tables[C]//International Conference on Pattern Recognition,2012:1554-1557.
[65]Seth S C,Nagy G.Segmenting Tables via Indexing of Value Cells by Table Headers[C]//International Conference on Document Analysis and Recognition,2013:887-891.
[66]Nagy G,Tamhankar M.VeriClick:An Efficient Tool for Table Format Verification[C]//Document Recognition and Retrieval,2012.
[67]Guglielmo E J,Rowe N C.Natural-language Retrieval of Images Based on Descriptive Captions[J].ACM Transactions on Information Systems,1996,14(3):237-267.
[68]Rowe N C.Precise and Efficient Retrieval of Captioned Images:The MARIE Project[J].Library Trends,1999,48(2):475-495.
[69]Demner-fushman D,Antani S,Simpson M S,et al.Annotation and Retrieval of Clinically Relevant Images[J].International Journal of Medical Informatics,2009,78(12):59-67.
[70]Agarwal S,Yu H.FigSum:Automatically Generating Structured Text Summaries for Figures in Biomedical Literature[C]//American Medical Informatics Association Annual Symposium,2009:6-10.
[71]Balaji P R,Sethi R J,Hong Y,et al.Figure-associated Text Summarization and Evaluation[J].Plos One,2015,10(2).
[72]薛歡歡.基于條件隨機場的中文期刊論文信息識別與抽取[D].北京:中國農業(yè)科學院,2019.
[73]李朝光,張銘,鄧志鴻,等.論文元數(shù)據信息的自動抽取[J].計算機工程與應用,2002,38(21):189-191.
[74]Constantin A,Pettifer S,Voronkov A,et al.PDFX:Fully-automated PDF-to-XML Conversion of Scientific Literature[C]//Document Engineering,2013:177-180.
[75]陳俊林,張文德.基于XSLT的PDF論文元數(shù)據的優(yōu)化抽取[J].現(xiàn)代圖書情報技術,2007,(2):18-23.
[76]Day M Y,Tsai R T H,Sung C L,et al.Reference Metadata Extraction Using a Hierarchical Knowledge Representation Framework[J].Decision Support Systems,2007,43(1):152-167.
[77]黃澤武.基于語義的科技文獻共享平臺的信息抽取系統(tǒng)[D].武漢:華中科技大學,2007.
[78]Kovacevic A,Ivanovic D,Milosavljevic B,et al.Automatic Extraction of Metadata from Scientific Publications for CRIS Systems[J].Program:Electronic Library and Information Systems,2011,45(4):376-396.
[79]Lopez P.GROBID:Combining Automatic Bibliographic Data Recognition and Term Extraction for Scholarship Publications[C]//European Conference on Research and Advanced Technology for Digital Libraries,2009:473-474.
[80]Cui B,Chen X.An Improved Hidden Markov Model for Literature Metadata Extraction[C]//International Conference on Intelligent Computing,2010:205-212.
[81]Liu R,Gao L,An D,et al.Automatic Document Metadata Extraction Based on Deep Networks[C]//Natural Language Processing and Chinese Computing,2018:305-317.
[82]Kafkas S,Kim J H,Pi X,et al.Database Citation in Supplementary Data Linked to Europe PubMed Central Full Text Biomedical Articles[J].Journal of Biomedical Semantics,2015,6(1).
[83]Li J,Zheng S,Kang H,et al.Identifying Scientific Project-generated Data Citation from Full-text Articles An Investigation of TCGA Data Citation[J].Journal of Data and Information Science,2016,(2):32-44.
[84]Zhao M N,Yan E,Li K.Data Set Mentions and Citations:A Content Analysis of Full-text Publication[J].Journal of the Association for Information Science & Technology,2017,69(1):32-46.
[85]Cortez E,Silva A S D,Mesquita F,et al.FLUX-CiM:Flexible Unsupervised Extraction of Citation Metadata[C]//Proceedings of the 7th ACM/IEEE-CS Joint Conference on Digital Libraries,ACM,2007:215-224.
[86]Peng F C,McCallum A.Accurate Information Extraction from Research Papers Using Conditional Random Fields[C]//Proceedings of the Human Language Technology Conference of the North American Chapter of the Association for Computational Linguistics,Association for Computational Linguistics,2004:329-336.
[87]高良才,湯幟,陶欣,等.一種自動發(fā)現(xiàn)、分割與標注引文元數(shù)據的方法[J].北京大學學報:自然科學版,2010,46(6):893-900.
[88]He Q,Kifer D,Pei J,et al.Citation Recommendation Without Author Supervision[C]//Proceedings of the Fourth ACM International Conference on Web Search and Data Mining,ACM,2011:755-764.
[89]Takis J,Islam A Q M,Lange C,et al.Crowdsourced Semantic Annotation of Scientific Publications and Tabular Data in PDF[C]//Proceedings of the 11th International Conference on Semantic Systems.ACM,2015:1-8.
[90]Cao H,Bowers S,Schildhauer M P.Approaches for Semantically Annotating and Discovering Scientific Observational Data[C]//Database and Expert Systems Applications.Springer Berlin Heidelberg,2011:526-541.
[91]Berkley C,Bowers S,Jones M B,et al.Improving Data Discovery for Metadata Repositories Through Semantic Search[C]//International Conference on Complex,Intelligent and Software Intensive Systems.Fukuoka:IEEE,2009:1152-1159.
(責任編輯:孫國雷)
