基于HLS 工具的CNN 加速器的設(shè)計(jì)與優(yōu)化方法研究*
2021-04-02 03:44:14程佳風(fēng)王紅亮
電子技術(shù)應(yīng)用 2021年3期
程佳風(fēng),王紅亮
(中北大學(xué) 電子測(cè)量技術(shù)國(guó)家重點(diǎn)實(shí)驗(yàn)室,山西 太原030051)
0 引言
近年來(lái),卷積神經(jīng)網(wǎng)絡(luò)的應(yīng)用范圍越來(lái)越廣泛,其應(yīng)用場(chǎng)景也日益復(fù)雜,卷積神經(jīng)網(wǎng)絡(luò)的計(jì)算密集和存儲(chǔ)密集特征日益凸顯,成為快速高效實(shí)現(xiàn)卷積神經(jīng)網(wǎng)絡(luò)的限制。 于是基于GPU[1]、ASIC[2]、FPGA[3]的不同的加速器平臺(tái)被相繼提出以提升CNN 的設(shè)計(jì)性能。 GPU 的電力消耗巨大,硬件結(jié)構(gòu)固定,限制了卷積神經(jīng)網(wǎng)絡(luò)在嵌入式設(shè)備的應(yīng)用;ASIC 開(kāi)發(fā)成本極高,靈活性低,不適合搭載復(fù)雜多變的卷積神經(jīng)網(wǎng)絡(luò);FPGA 具有功耗低、性能高、靈活性好的特點(diǎn),因此更加適用于卷積神經(jīng)網(wǎng)絡(luò)硬件加速的開(kāi)發(fā)研究,但由于Verilog HDL 開(kāi)發(fā)門(mén)檻高,開(kāi)發(fā)周期相對(duì)較長(zhǎng),影響了FPGA 在卷積神經(jīng)網(wǎng)絡(luò)應(yīng)用的普及[4-5]。
本文基于軟硬件協(xié)同的思想,利用HLS 工具,在PYNQ-Z2 上實(shí)現(xiàn)了一個(gè)卷積神經(jīng)網(wǎng)絡(luò)加速器, 并采用矩陣切割的設(shè)計(jì)方法對(duì)卷積核運(yùn)算進(jìn)行優(yōu)化。
1 PYNQ-Z2 和卷積神經(jīng)網(wǎng)絡(luò)
本設(shè)計(jì)采用Xilinx 公司推出的PYNQ-Z2 開(kāi)發(fā)板作為實(shí)驗(yàn)平臺(tái)。 PYNQ-Z2[6-9]是基于Xilinx ZYNQ-7000 FPGA 的平臺(tái),除繼承了傳統(tǒng)ZYNQ 平臺(tái)的強(qiáng)大處理性能外,還兼容Arduino 接口與標(biāo)準(zhǔn)樹(shù)莓派接口,這使得PYNQ-Z2 具有極大的可拓展性與開(kāi)源性。 PYNQ 是一個(gè)新的開(kāi)源框架,使嵌入式編程人員無(wú)需設(shè)計(jì)可編程邏輯電路即可充分發(fā)揮Xilinx Zynq All Programmable SoC(APSoC)的功能。 與常規(guī)方式不同的是,通過(guò)PYNQ-Z2,用戶(hù)可以使用Python 進(jìn)行APSoC 編程,并且代碼可直接在PYNQ2 上進(jìn)行開(kāi)發(fā)和測(cè)試。通過(guò)PYNQ-Z2,可編程邏輯電路將作為硬件庫(kù)導(dǎo)入并通過(guò)其API 進(jìn)行編程,其方式與導(dǎo)入和編程軟件庫(kù)基本相同。
卷積神經(jīng)網(wǎng)絡(luò)[10-13]是一種復(fù)雜的多層神經(jīng)網(wǎng)絡(luò),擅長(zhǎng)處理目標(biāo)檢測(cè)、目標(biāo)識(shí)別等相關(guān)的深度學(xué)習(xí)問(wèn)題。 卷積神經(jīng)網(wǎng)絡(luò)通過(guò)其特有的網(wǎng)絡(luò)結(jié)構(gòu),對(duì)數(shù)據(jù)量龐大的圖像識(shí)別問(wèn)題不斷地進(jìn)行圖像特征提取,最終使其能夠被訓(xùn)練。一個(gè)最典型的卷積神經(jīng)網(wǎng)絡(luò)由卷積層、池化層、全連接層組成。 其中卷積層與池化層配合,組成多個(gè)卷積組,逐層提取特征,最終通過(guò)全連接層完成圖像的分類(lèi)任務(wù)。卷積層完成的操作可以認(rèn)為是受局部感受野概念的啟發(fā),而池化層主要是為了降低數(shù)據(jù)維度。綜合起來(lái),CNN 通過(guò)卷積來(lái)模擬特征區(qū)分, 并且通過(guò)卷積的權(quán)值共享及池化來(lái)降低網(wǎng)絡(luò)參數(shù)的數(shù)量級(jí),最后通過(guò)傳統(tǒng)神經(jīng)網(wǎng)絡(luò)完成分類(lèi)等任務(wù)。
本文采用一種典型的手寫(xiě)數(shù)字識(shí)別網(wǎng)絡(luò)CNN LeNet5 模型[14-16]對(duì)系統(tǒng)進(jìn)行測(cè)試,模型結(jié)構(gòu)如圖1 所示,總共包含6 層網(wǎng)絡(luò)結(jié)構(gòu):兩個(gè)卷積層、兩個(gè)池化層、兩個(gè)全連接層。 網(wǎng)絡(luò)的輸入為28×28×1 像素大小圖片,輸 入 圖 像 依 次 經(jīng) 過(guò)conv1、pool1、conv2、pool2、inner1、relu1、inner2 層后,得到10 個(gè)特征值,然后在softmax 分類(lèi)層中將10 個(gè)特征值概率歸一化得出最大概率值即為分類(lèi)結(jié)果。 網(wǎng)絡(luò)中的具體參數(shù)設(shè)置如表1 所示。
由表1 可以計(jì)算出,該CNN 網(wǎng)絡(luò)總共的權(quán)重參數(shù)量為260+5 020+16 050+510=21 840 個(gè)變量。若將這21 840個(gè)變量都采用ap_int(16)來(lái)存儲(chǔ),將大約消耗43 KB 的存儲(chǔ)資源,本文采用的PYNQ-Z2 有足夠的存儲(chǔ)空間用于存放這些變量。
2 系統(tǒng)設(shè)計(jì)與實(shí)現(xiàn)
本文設(shè)計(jì)并實(shí)現(xiàn)基于PYNQ-Z2 的CNN 通用加速器,采用PYNQ-Z2 的PS 部分做邏輯控制,PL 部分執(zhí)行卷積神經(jīng)網(wǎng)絡(luò)運(yùn)算。由于全連接運(yùn)算是特殊的卷積運(yùn)算,因此依據(jù)卷積神經(jīng)網(wǎng)絡(luò)的特性設(shè)計(jì)了兩個(gè)通用的運(yùn)算模塊,即通用的卷積運(yùn)算模塊和通用的池化運(yùn)算模塊,如圖2 所示。
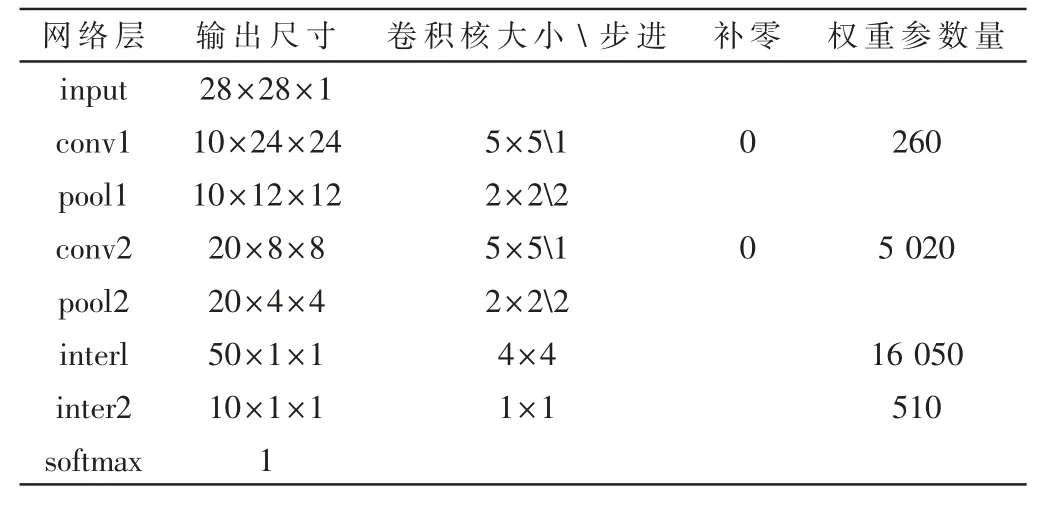
表1 網(wǎng)絡(luò)參數(shù)表
由圖2 可以看出,這種加速器框架實(shí)現(xiàn)了兩種通用的加速電路(即通用的卷積運(yùn)算電路和通用的池化運(yùn)算電路),CPU 通過(guò)axi_lite 總線對(duì)卷積池化電路的參數(shù)進(jìn)行配置,卷積池化電路通過(guò)axi_hp 總線對(duì)CPU 中存儲(chǔ)的特征權(quán)重參數(shù)進(jìn)行讀取。當(dāng)存儲(chǔ)器中輸入一組數(shù)據(jù)的時(shí),CPU 就會(huì)進(jìn)行參數(shù)配置并調(diào)用卷積運(yùn)算模塊進(jìn)行運(yùn)算, 卷積ReLU 后的結(jié)果保存在存儲(chǔ)器中再進(jìn)行參數(shù)配置并調(diào)用池化運(yùn)算模塊進(jìn)行運(yùn)算,可以通過(guò)這種循環(huán)運(yùn)算的方式實(shí)現(xiàn)卷積神經(jīng)網(wǎng)絡(luò)的運(yùn)算。
2.1 CNN LeNet5 模型訓(xùn)練
本文在TensorFlow 中搭建CNN LeNet5 網(wǎng)絡(luò)模型并進(jìn)行訓(xùn)練,訓(xùn)練過(guò)程如圖3 所示。 其中橫坐標(biāo)軸代表訓(xùn)練次數(shù),縱坐標(biāo)軸表示每次訓(xùn)練的誤差。 設(shè)置訓(xùn)練速率為50,訓(xùn)練20 000 次,隨著訓(xùn)練次數(shù)的不斷增多,誤差逐漸減小,最后的模型錯(cuò)誤率僅為1.58%。
2.2 CNN 加速器的IP 核的設(shè)計(jì)與實(shí)現(xiàn)
Xilinx 推出的HLS[17]工具是基于FPGA 的設(shè)計(jì)與開(kāi)發(fā),用戶(hù)可以選擇多種不同的高級(jí)語(yǔ)言(如C、C++、System C)來(lái)進(jìn)行FPGA 的設(shè)計(jì),在代碼生成時(shí)可以快速優(yōu)化FPGA 硬件結(jié)構(gòu),提高執(zhí)行效率,降低開(kāi)發(fā)難度。
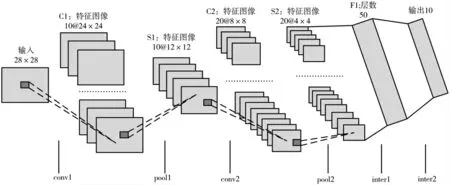
圖1 典型的手寫(xiě)數(shù)字識(shí)別網(wǎng)絡(luò)結(jié)構(gòu)

圖2 系統(tǒng)硬件原理框圖
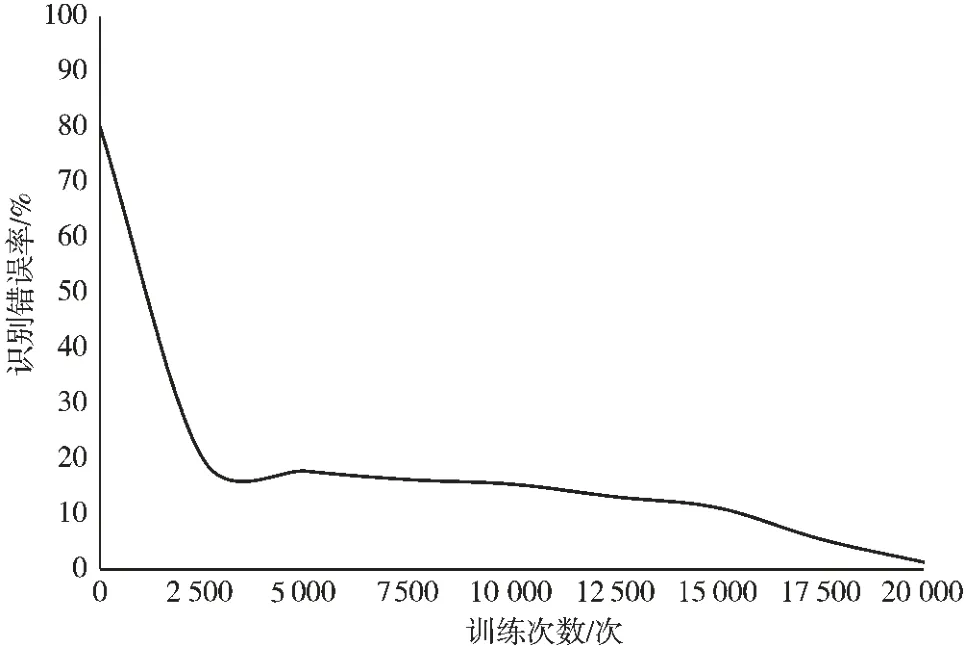
圖3 CNN LeNet5 誤差與訓(xùn)練次數(shù)的關(guān)系
本文通過(guò)C 語(yǔ)言描述了兩個(gè)加速電路,利用HLS 工具生成加速器的IP 核。 系統(tǒng)通過(guò)CPU 配置IP 核的參數(shù),采用AXI 的通信方式進(jìn)行數(shù)據(jù)傳輸,輸入的數(shù)據(jù)通過(guò)IP 核進(jìn)行CNN 運(yùn)算,運(yùn)算的結(jié)果通過(guò)AXI 總線輸出。圖4 是加速器IP 核的原理圖。
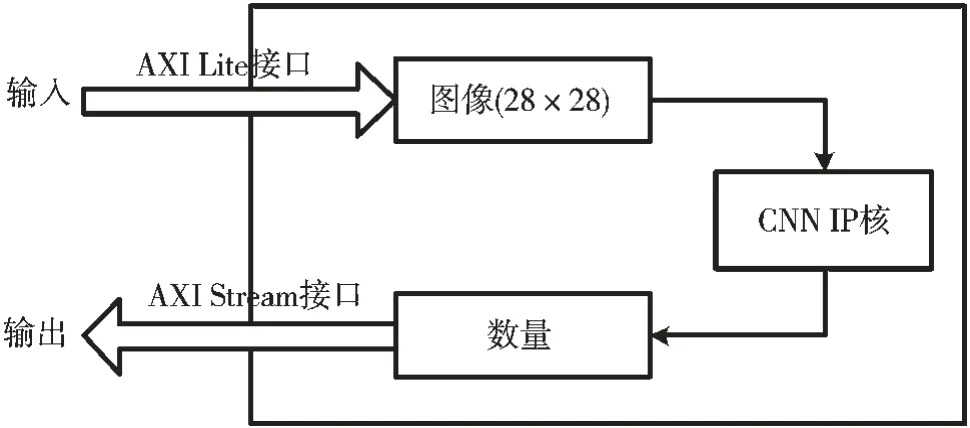
圖4 加速器IP 核原理圖
2.3 CNN 加速器的IP 核優(yōu)化
由于特征、權(quán)重參數(shù)都是多維的空間變量,無(wú)法在計(jì)算機(jī)中讀取,因此需要將其展開(kāi)為一維變量。 如圖5 所示,對(duì)于特征參數(shù), 它在空間中的排布方式為三維變量,因此需要將其展開(kāi)為一維變量,考慮到FPGA 的并行計(jì)算能力優(yōu)秀,所以在空間中沿輸入特征的通道C 將其切割為C/k 通道,每一個(gè)通道可以實(shí)現(xiàn)k 路并行的計(jì)算且需要的特征存儲(chǔ)空間減少,大大提高了加速電路的運(yùn)算效率,節(jié)約了FPGA 的存儲(chǔ)資源。 特征參數(shù)經(jīng)過(guò)切割后,它在內(nèi)存中的排布方式變?yōu)榱艘痪S變量:[C/k][H][W][k]。
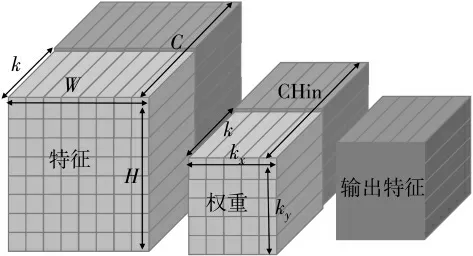
圖5 卷積運(yùn)算的矩陣切割
權(quán)重參數(shù)在空間中的排布方式為四維變量,要將它展開(kāi)為一維變量,也是對(duì)其輸入通道CHin 切割為CHin/k通道,實(shí)現(xiàn)每一個(gè)通道的k 路并行,它在內(nèi)存中的排布方式變?yōu)橐痪S變量:[CHout][ky][kx][CHin/k][k]。
其中k 的取值會(huì)對(duì)系統(tǒng)性能造成極大的影響,一個(gè)合適的k 值可以使得存儲(chǔ)資源、計(jì)算資源、帶寬資源三者達(dá)到平衡。 通常k 的取值有8、16、32、64,其不同的取值對(duì)應(yīng)的資源消耗如表2 所示,不同取值對(duì)應(yīng)的計(jì)算圖片的時(shí)間如表3 所示。
通過(guò)表2 和表3 的數(shù)據(jù)對(duì)比可以得到,在k=32 時(shí)的資源占用較為合理,可以使得系統(tǒng)的性能達(dá)到最優(yōu),同時(shí)權(quán)衡了計(jì)算時(shí)間和數(shù)據(jù)存儲(chǔ)時(shí)間,達(dá)到了比較好的均衡效果。

表2 不同k 的取值對(duì)應(yīng)的資源消耗
3 實(shí)驗(yàn)與結(jié)果
3.1 實(shí)驗(yàn)測(cè)試平臺(tái)
本實(shí)驗(yàn)采用PYNQ-Z2 開(kāi)發(fā)板,其主芯片是XC7Z020,主要由PS 和PL 兩部分組成,PS 端是650 MHz 雙核Cortex-A9 處 理 器,PL 端 的 時(shí) 鐘 頻 率 為100 MHz。 通 過(guò)表3 可以看出,在進(jìn)行單張圖片測(cè)試時(shí),CNN IP 核在k=32 時(shí)計(jì)算圖片的時(shí)間比PS 端減少了將近39 ms,達(dá)到了近6 倍的加速效果。接下來(lái)進(jìn)行多張圖片測(cè)試來(lái)記錄加速效果。
3.2 圖片流測(cè)試
在MNIST 數(shù)據(jù)集中選取1 000 張圖片,分成10 組,每組100 張測(cè)試圖片,組成圖片流,分別送入ARM 層和硬件層的加速器IP 核進(jìn)行CNN 運(yùn)算, 并且記錄各自所用的時(shí)間,從而得到加速器IP 核對(duì)圖片流的加速效果。實(shí)現(xiàn)結(jié)果如圖6 所示。
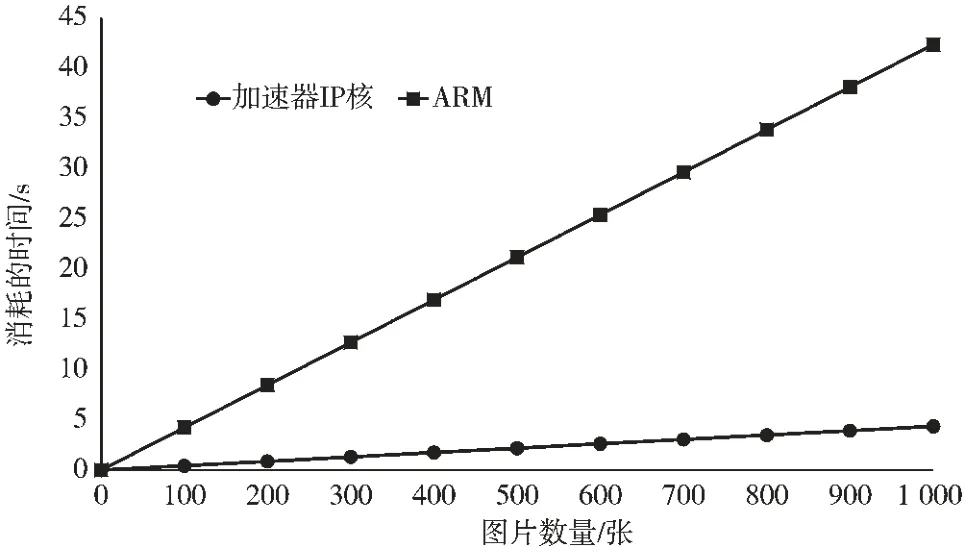
圖6 圖片流的測(cè)試結(jié)果
由圖6 可以看出,兩種不同平臺(tái)的測(cè)試結(jié)果都成線性關(guān)系,說(shuō)明每張圖片的運(yùn)算時(shí)間都是固定不變的,加速器IP 核處理單張圖片的平均時(shí)間為4.3 ms, 而ARM平臺(tái)處理單張圖片的平均時(shí)間約為42 ms,由此可見(jiàn),當(dāng)運(yùn)算相同數(shù)量的圖片時(shí),CNN IP 核可將運(yùn)算速度提高到近10 倍,遠(yuǎn)遠(yuǎn)超過(guò)了單張圖片的加速效果。 當(dāng)處理1 000 張圖片時(shí),加速器IP 核比ARM 端快了38 s 左右,并且隨著圖片的數(shù)量越來(lái)越多, 加速器IP 核的性能也將越來(lái)越好,加速效果也將越來(lái)越顯著。
3.3 實(shí)驗(yàn)結(jié)果比較
本文采用的HLS 工具實(shí)現(xiàn)的加速器IP 核與FPGA實(shí)現(xiàn)卷積神經(jīng)網(wǎng)絡(luò)[18]相比較,比較結(jié)果如表4 和表5所示。
通過(guò)表5 可以看出,文獻(xiàn)[18]中提出的利用FPGA實(shí)現(xiàn)CNN 加速器與傳統(tǒng)的CPU 相比有很大的加速效果,在處理單張圖片時(shí)的加速比為4.17,在處理10 000張圖片時(shí)的加速比為3.43,可見(jiàn)隨著處理圖片的數(shù)量逐漸增加,加速器的效果在不斷降低。 本文提出的利用HLS 工具生成的CNN 加速器在處理單張圖片時(shí)所耗時(shí)間為8 ms,加速比為5.875,與傳統(tǒng)CPU 相比有很好的加速效果;在處理1 000 張圖片時(shí),加速器IP 核耗時(shí)4.352 s,通用CPU 耗時(shí)42.322 s,此時(shí)的加速比為9.72,加速效果越來(lái)越明顯,并且隨著處理的圖片數(shù)量越來(lái)越多,加速效果會(huì)越來(lái)越好,具有很好的參考意義。
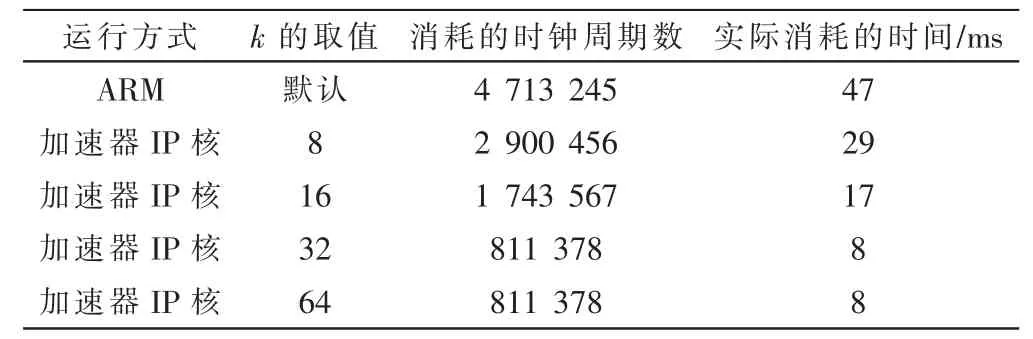
表3 不同k 的取值對(duì)應(yīng)的計(jì)算圖片的時(shí)間

表4 文獻(xiàn)[18]與本文實(shí)驗(yàn)平臺(tái)的對(duì)比
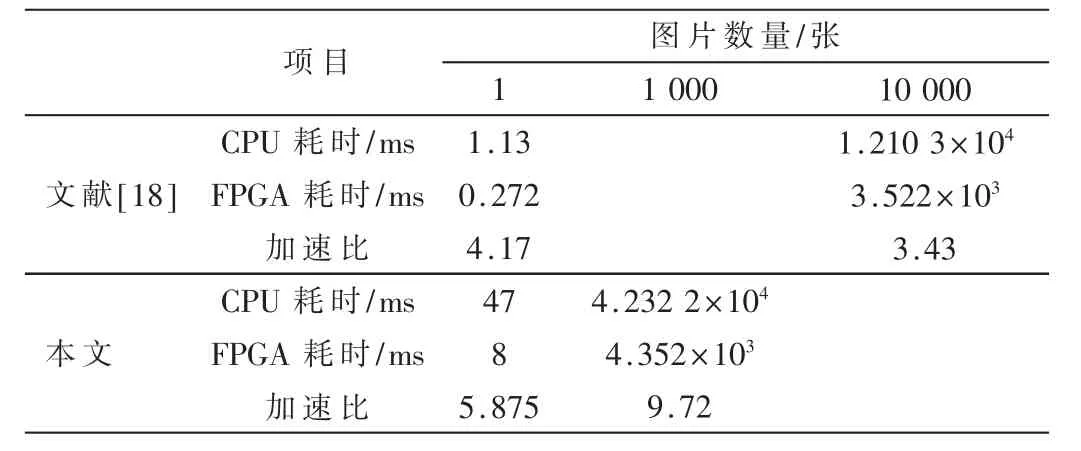
表5 文獻(xiàn)[18]與本文對(duì)不同數(shù)量的圖片處理的運(yùn)算速度的對(duì)比
4 結(jié)束語(yǔ)
本文在PYNQ-Z2 平臺(tái)上利用HLS 工具設(shè)計(jì)了加速器IP 核來(lái)進(jìn)行卷積神經(jīng)網(wǎng)絡(luò)運(yùn)算,并通過(guò)矩陣切割的方法對(duì)加速器IP 核進(jìn)行優(yōu)化,充分利用了FPGA 的并行計(jì)算能力。 通過(guò)實(shí)驗(yàn)證明在k=32 時(shí),均衡了存儲(chǔ)資源和計(jì)算資源,使得加速器IP 核的性能達(dá)到最優(yōu),運(yùn)算速度得到明顯的提升。由于本實(shí)驗(yàn)采用的開(kāi)發(fā)平臺(tái)資源有限,若采用資源更多的FPGA 平臺(tái)進(jìn)行加速運(yùn)算,加速器的性能將得到更大的提升。
