面向理想性能空間的跨架構編譯分析方法
2021-04-01 01:19:32賴慶寬賀春林何先波馮曉兵
計算機研究與發展 2021年3期
賴慶寬 呂 方 賀春林 何先波 馮曉兵,3
1(計算機體系結構國家重點實驗室(中國科學院計算技術研究所) 北京 100190) 2(中國科學院計算技術研究所 北京 100190) 3(中國科學院大學 北京 100049) 4(西華師范大學計算機學院 四川南充 637009)
(laiqingkuan@outlook.com)
編譯器性能優化是計算機系統結構優勢得以充分發揮的基礎,是關乎整個系統功能與性能的重要環節.編譯器優化的實質是“取眾人之長,補己之短”.一款高性能編譯器需要汲取其他諸多編譯器的長處,它的優化契機和提升空間也往往源于對同期編譯器的優勢挖掘.但是,面對眾多同期編譯器設計,選擇哪些作為參照物分析才能攫取更多收益是編譯器優化分析最為關注的問題.
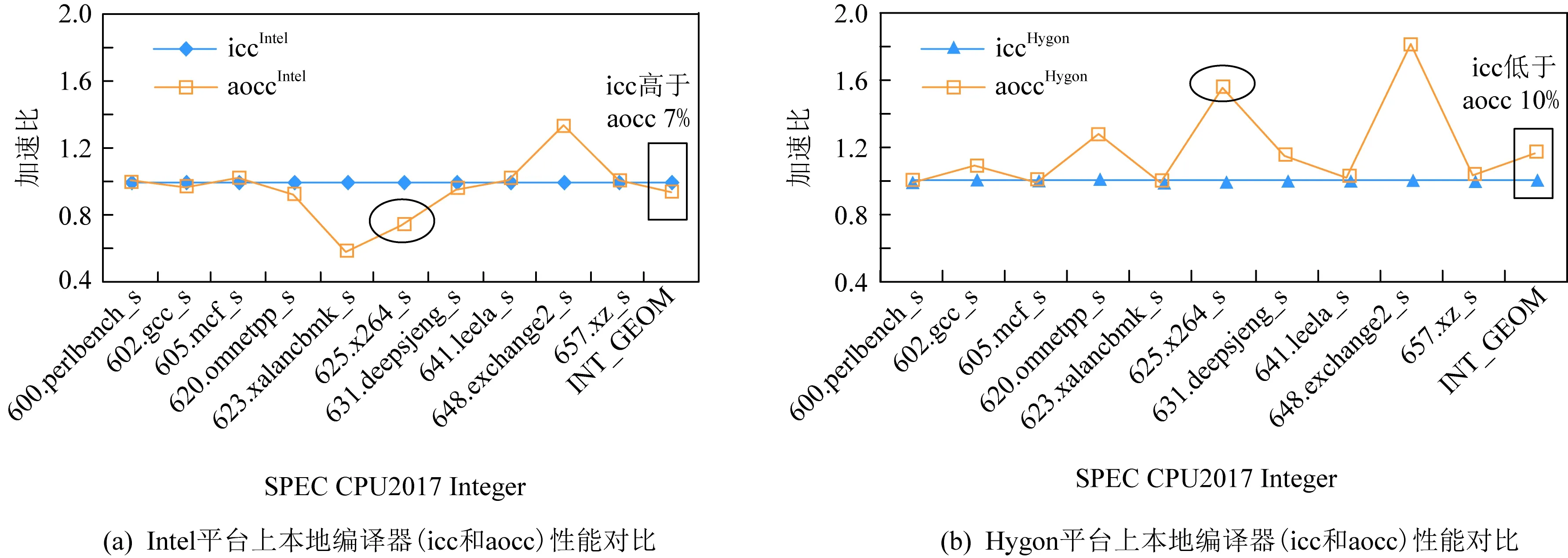
Fig. 1 Interference with compiler performance by different platforms (processors)圖1 不同平臺(處理器)對編譯器性能的干擾作用
編譯器性能直接受平臺影響,因此,對它們進行性能分析時,不僅需要考慮編譯器自身的性能優勢,也不能忽視平臺所產生的影響.圖1展示了同期版本的icc和aocc編譯器在Intel平臺以及基于海光處理器的驗證平臺(Hygon)上表現出截然相反的性能表現.以SPEC CPU2017定點測試集為例,圖1(a)中的2組曲線分別代表Intel服務器本地安裝的2款編譯器icc編譯器(iccIntel)和aocc編譯器(aoccIntel)所產生的SPEC CPU2017定點性能對比數據.標記菱形的曲線所代表的iccIntel在Intel服務器上呈現出明顯“主場實力”,在SPEC CPU2017定點幾何平均分值(INT_GEOM)上與標記方形的曲線所代表的aoccIntel的差值將近7%;然而在圖1(b)中,海光平臺上的2款本地編譯器的性能與Intel平臺上的編譯器性能剛好相反,其中aocc編譯器的性能相對于icc編譯器性能更好,超過icc編譯器10%.如圖中選定的625.x264_s例子,在Intel平臺上icc性能最好,在Hygon平臺上aocc性能最好.根據以上的數據分析,不同的平臺上相同的編譯器優化能力不同,機器平臺是影響編譯器性能的關鍵因素.
平臺影響從編譯器安裝伊始就開始了,它決定了平臺之上的編譯器具有啟發式的優化能力.當平臺(處理器)不同時,相同的編譯器源碼在安裝過程中會受到不同指引,繼而生成具有不同優化能力的本地編譯器.例如,對于同一份gcc8.2.0源代碼,它在Intel、Hygon和龍芯上所生成的編譯器具有不同的優化能力.在編譯器安裝過程中,機器平臺的影響的不可忽略,否則會影響后續的優化方案的確定.因此,跨平臺編譯器性能分析的基礎應該是編譯器與機器平臺的組合,本文稱之為架構組合.
然而,結合平臺的編譯器分析將產生巨大的數據量.編譯器分析又是一個極大依賴于編譯專家經驗的過程,由于數據過多必定會大大增加人工分析的工作量,所以目前編譯器性能分析過程中,會忽略機器平臺(處理器特征)的影響,僅僅關注于編譯器本身.目前的編譯器性能分析方法只選定一款高性能編譯器來做分析,以降低分析壓力.工業屆主流芯片服務器廠商都研發了只適合于自家芯片和服務器的高性能編譯器.如icc是Intel公司高性能編譯器,aocc是AMD公司的高性能編譯器,這些編譯器在各自的芯片服務器上擁有著非常顯著的性能,所以是編譯器性能分析的最佳參照編譯器.但是這些編譯器并不能一成不變的普適風云萬變的領域體系結構.這些編譯器脫離自己所定位的芯片結構,是否仍然能夠發揮出“主場效應”?顯然,當目標編譯器所在平臺與icc,aocc不同時,這個問題就關系到優勢編譯器選型是否正確,更關乎目標編譯器優化分析的優化方向決策是否正確.對于編譯器優化而言,減少分析目標,就會大大削弱了集眾長于一身的機會.因此,我們需要一種高效的分析方法,此方法可以快速地選擇出性能高的架構組合,精確地預估出最大化的理想性能提升空間.根據這些性能數據指標實行詳細的分析,以確定出優勢優化選項,并在目標編譯器上實現此優化功能.
本文提出了一種與機器平臺相關的編譯器性能分析技術——基于峰值數據的跨架構組合分析方法(a peak-data based approach for cross-framework compiler analysis, PDCA),此方法可應用于多平臺上的多編譯器性能分析.首先,以SPEC CPU2017為測試用例,根據業界提供的峰值選項對平臺和編譯器的架構組合做峰值測試,用最高的性能數據建立理想峰值性能,其與我們的目標編譯器性能差距構建出一個理想性能區間(ideal-peak).此性能區間是目標編譯器在理想情況下可以達到的性能.其次,選項篩選,直至獲得有明顯性能優勢的優化措施指示,通過人工分析,在目標編譯器中實現性能提升,PDCA是使得目標編譯器的優化來源于其他多個架構組合,最終性能逼近理想性能.
本文主要貢獻有3個方面:
1) 提出一種跨架構分析方法PDCA,該方法是對多平臺和多編譯器架構組合的編譯器優化分析方法.
2) 該方法是針對多個優勢峰值架構組合,以理性性能區間為目標的編譯器性能分析方法,最高的性能數據和目標編譯器性能數據之間的差距構成了理想性能區間,它代表了一個切實可以提升的性能空間.因此,是一種具有實用價值的分析方法.
3) 通過實驗驗證,PDCA是一種高效使用的編譯器性能分析方法,可以以多個架構為參照,為目標編譯器挖掘出更多的優化技術方案,使得目標編譯器獲得巨大的性能提升.
1 研究背景
1.1 問 題
現有編譯器性能分析方法通常采用弱化架構組合選型的方式進行,即簡化平臺與編譯器選型,直接鎖定某一種優勢架構組合.例如安騰處理器平臺上的ORC編譯器是以同期的商用編譯器ecc作為參照編譯器而研發的.基于mips架構的龍芯編譯器也將同期x86與icc編譯器作為自己的參照分析物.在此基礎上采用機器模型輔助等自動分析手段對編譯器優化進行深度篩選[1],目的是迅速聚集到使性能最大化的優化選項.
如果只對單一的架構組合做性能分析,那么編譯器的性能提升控制將受到很大的限制.編譯器性能分析通常借助于SPEC CPU2017測試集[2],此測試集包含的領域非常廣泛,包括壓縮算法、地震模型等,并且對于每個測試用例存在定點和浮點數據集以及條件密集或訪存密集等不同特征. 因此,一個架構組合很難使SPEC CPU2017測試集中的所有類型應用百分百受益.
如圖2所示,gcc編譯器在Intel平臺上有極大的性能提升空間.如圖2(a)所示,icc有明顯的優勢,2種編譯器之間有84%的性能差,這也是我們參照icc進行優化所能達到的可能最大提升限度.圖2(b)中,如果在這個基礎上增加aocc,依舊是這5個測試用例具有非常大的性能差距,但它們分別來源于icc和aocc.此時,平均性能若涵蓋標記空心方形所示的最好性能數據,它較gcc基準的優勢就會提升至107%.由此可見,參照編譯器的擴充將帶來更大的潛在性能提升空間.如果據此性能區間的指引,目標編譯器gcc可獲得更多性能提升.
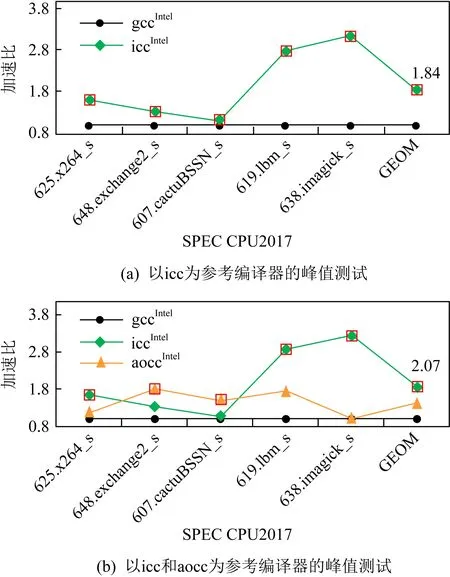
Fig. 2 Performance ratio based on icc and aocc圖2 以icc和aocc為參考形成的性能差
然而,弱化架構組合選型的主因之一是無法承受跨架構組合所引發的龐大的人工分析開銷.式(1)對跨架構編譯器分析的時間成本進行了估算.
overheads=(platforms×compilers×options×
benchmarks×runtime)24.
(1)
結合平臺因素的編譯器分析需要在平臺(platforms)、編譯器(compilers)以及性能分析選項(options)、測試集(benchmarks)和測試時間(runtime)之間建立關系.
其中,性能分析選項往往是引爆機器學習搜索空間的主因,因為通用編譯器的優化模塊多達數百種[4],由此衍生出的性能分析的時間成本和復雜度是難以估量.以圖2(a)為例,在Intel平臺上對gcc和icc這2種編譯器的4種常用優化選項O2、O3、內聯、插裝profiling分析,至少需要16(即24)組實驗,在SPEC CPU2017測試用例上每組實驗至少12 h,因此至少需要16 d才能完成實驗.如果增加1個待分析的架構aoccHygon,實驗會延長至24 d,數據會膨脹至960個,對于人工分析來說基本是很難完成的.因而編譯器性能分析會陷入到選擇架構組合的困難,那么弱化架構選擇成為了現在主流的編譯器心梗分析方法.
因此,為適度拓展性能分析覆蓋的應用類型,我們需要適度擴張架構組合的選型集合,它在可能接受的人工開銷范圍內,聚集了更多有價值的優勢架構組合,從而有利于我們實施更精準的性能分析,使目標編譯器受益.
1.2 挑 戰
多種平臺、多種編譯器所形成的架構組合會帶來急劇膨脹的數據量,應用性能表現各異,在現有技術下,基于架構組合的性能分析很難開啟.
然而,我們從實驗數據中發現了一些契機.如圖2所示,對于607.cactuBSSN_s例子,它最好的性能來自于aoccIntel,而對于619.lbm_s例子,它最好的數據形成于iccIntel.對于我們優化的目標gcc而言,理想的性能提升空間是在同一個X86平臺上,目標編譯器和其他編譯器的峰值數據之間的差距,此區間值越大,目標編譯器的提升空間就越高.所以可以為目標編譯器借鑒其他編譯器的優化技術,把目標編譯器的性能提升至同一平臺上的峰值數據,因此,面向理想性能空間的分析技術是可行的,且可以實施的.
實際上,目標編譯器優化的現實目的是盡可能把優勢優化技術納入自身,而不在意這個技術是哪個架構組合產生的.因此,我們將眼光從單一優勢編譯器選型轉移到性能分析用例的峰值數據所產生的架構組合上,重點研究它們的成因.首先,借助于已有峰值研究成果,我們對架構組合的峰值數據進行一次摸底測試,將不同架構組合的峰值匯聚到目標平臺上,與目標編譯器性能形成可以比較的集合.此時,所有測試用例的最高性能數據形成一個峰值數據集合,它們與目標編譯器的性能差就構成了一個理想情況下最大化的性能提升空間,即理想優化空間,這個優化空間通常會超越icc等單一編譯器所帶來的性能提升空間.此時,性能分析不需要對所有架構進行繁瑣的排列組合實驗,僅僅需要從單一用例入手,對產生該數據的峰值選項進行細化分析,從而精準定位出決定其性能優勢的優化技術,而分析的結論可以推廣適用于同類用例中.這種在理想性能提升空間指引下的分析更具實用意義.它大大縮減了機器學習等輔助手段所進行的繁瑣的選項分析過程,明確地以峰值性能為目的,其性能分析以及提升收益也更為明確,是具有實際應用價值的分析方法.這是本文所述面向理想性能空間的跨架構編譯分析技術的基本思想.
1.3 方 法
面向理想性能空間的跨編譯器分析技術PDCA是一種面向跨平臺、跨編譯器所構成的復雜場景下的編譯分析和優化技術.它包括3個核心步驟:理想性能空間構建、細粒度優勢優化定位、優化建議與實施.
圖3展示了PDCA的主要思路,包括3個主要步驟.
1) 理想性能空間構建.圖3中采用了Intel和gcc構成目標架構.選取了Intel和Hygon為待分析的平臺,分別選取{gcc,icc,aocc}3種編譯器作為參照編譯器,在它們形成的架構組合上對SPEC CPU2017測試集進行性能測試與分析.表1中列舉了平臺、編譯器以及SPEC CPU2017的關鍵信息.在理想性能空間構建過程中,在每個平臺上,采用峰值選項對SPEC CPU2017進行動態編譯,并將可執行碼均匯集到目標平臺上,進行性能測試.最終,形成圖3①中的性能加速比分析曲線,此時,目標平臺上匯集了3個架構組合產生的性能數據曲線.對于607.cactuBSSN_s而言,其最好性能來自aoccIntel,而619.lbm_s的最好性能來自iccIntel,即Intel平臺上的icc編譯器.如圖3①中標記方形的標注,SPEC CPU2017的每一個用例的最好性能共同形成了理想峰值數據集,而它們的平均值與基準的gcc性能構成了一個理想性能空間,它優于單一的icc或者aocc帶來的性能差.
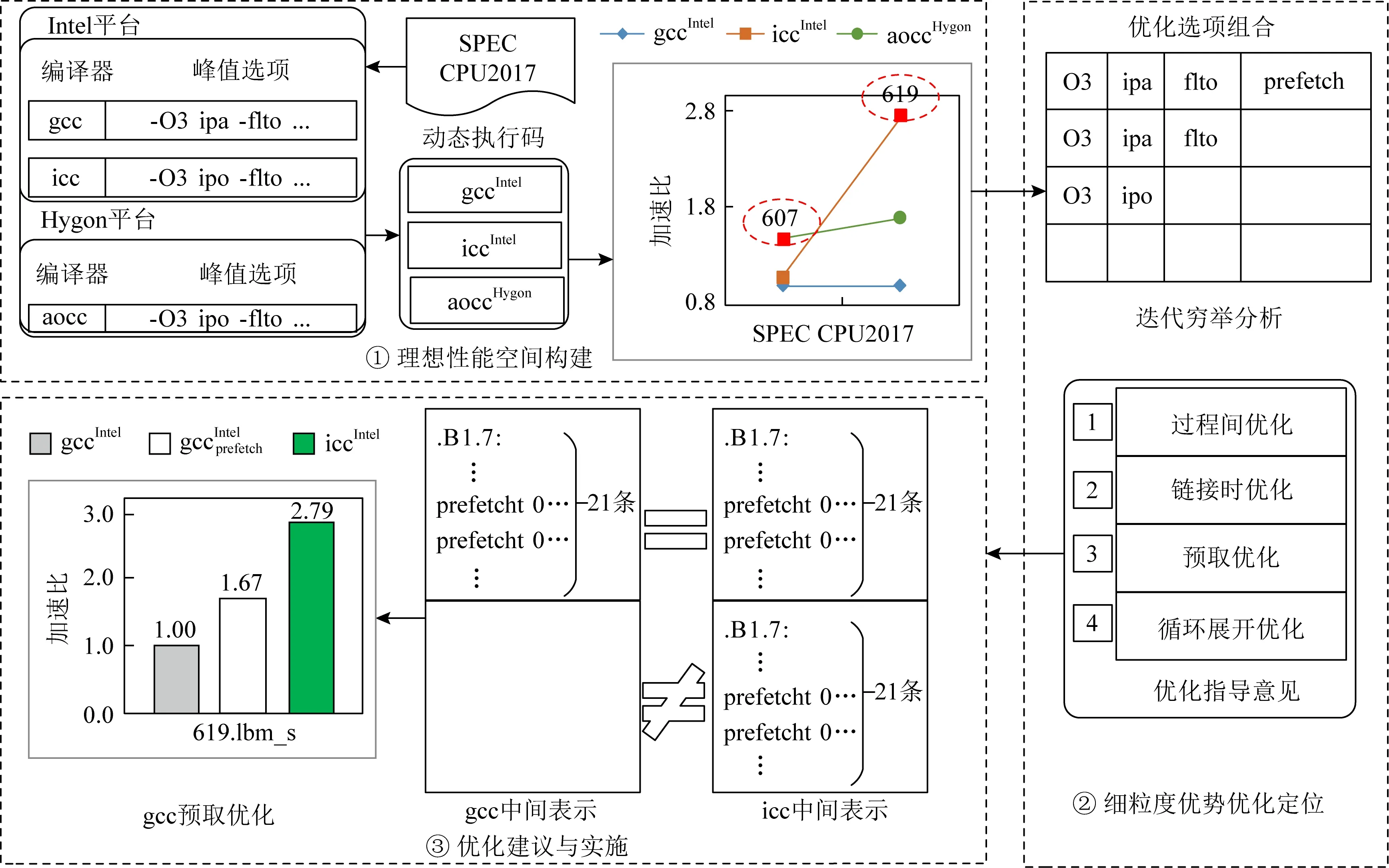
Fig. 3 A example of cross-architectural analysis techniques for the ideal performance space圖3 面向理想性能空間的跨架構分析技術例子
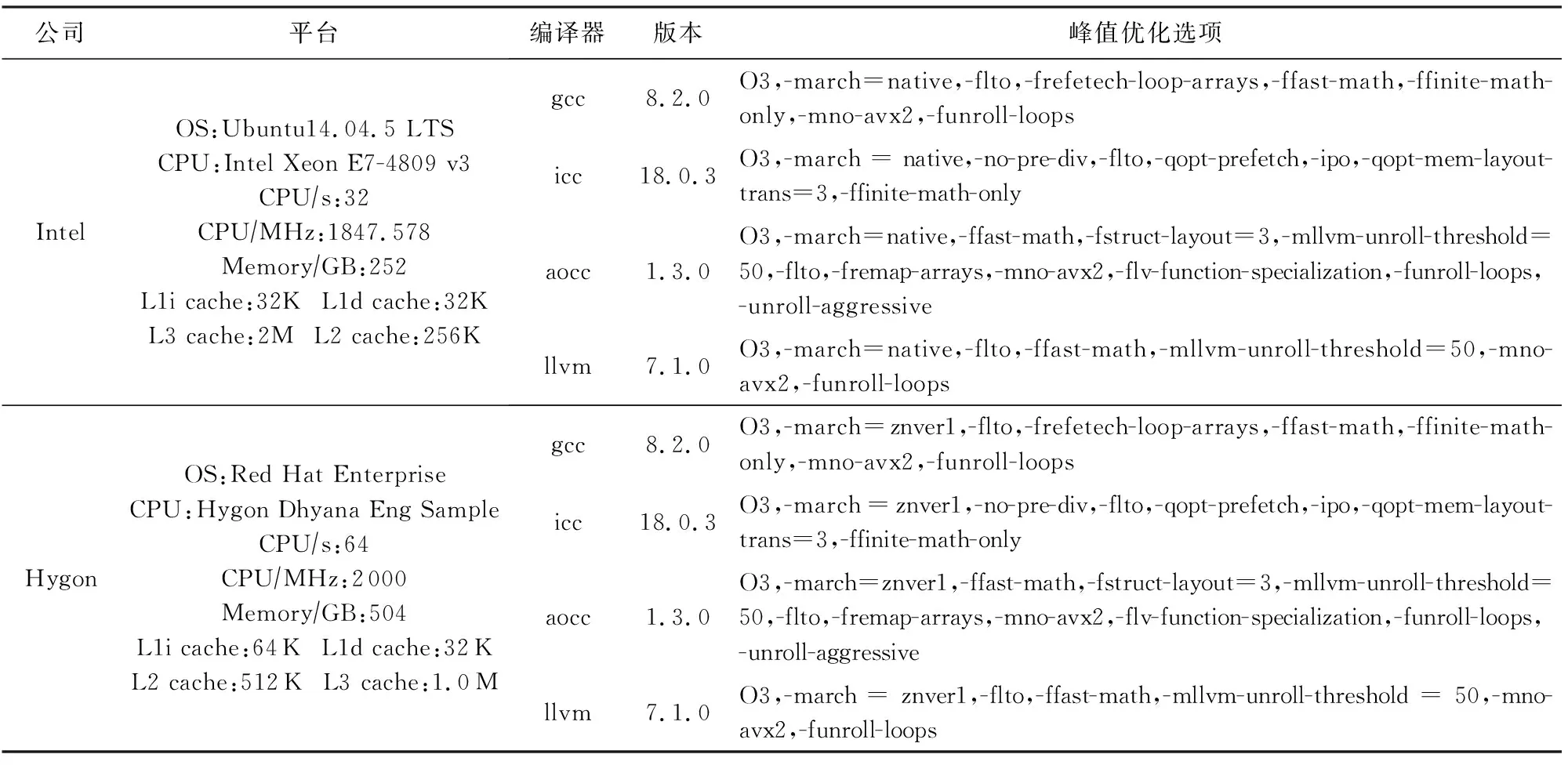
Table 1 PlatformInformation and Peak Optimization Options表1 平臺信息及編譯器峰值優化選項
2) 細粒優勢優化定位.如圖3②所示,在挖掘出產生峰值性能數據的架構后,在每一個峰值架構上,就可以采用成熟的機器學習等方法,僅僅在峰值選項范圍內進行優化選項分析,直至分析出具有明顯性能優勢的優化技術.圖3③中,619.lbm_s經過對常用峰值優化選項的有限次迭代測試,最后確定預取優化(prefetch)是非常重要的手段.到此,機器輔助的分析就結束了.
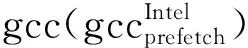
2 面向理想性能空間的跨架構編譯分析方法
面向理想性能空間的跨架構編譯分析技術是在跨平臺、跨編譯器的復雜場景下,獲得更大性能提升的一種實用型性能分析技術.它將不同架構下用峰值選項形成的動態可執行碼匯聚到目標平臺上實施性能對比,借此形成一個峰值性能數據集.峰值性能數據與目標編譯器之間就形成了一個理想情況下可以達到的最大性能提升空間,以它作為后續性能優化的目標.針對這個有限集合,PDCA對每個用例的峰值架構的選項進行深入分析,準確定位出帶明顯性能變化的優勢優化技術,并指導目標編譯器設計實現.
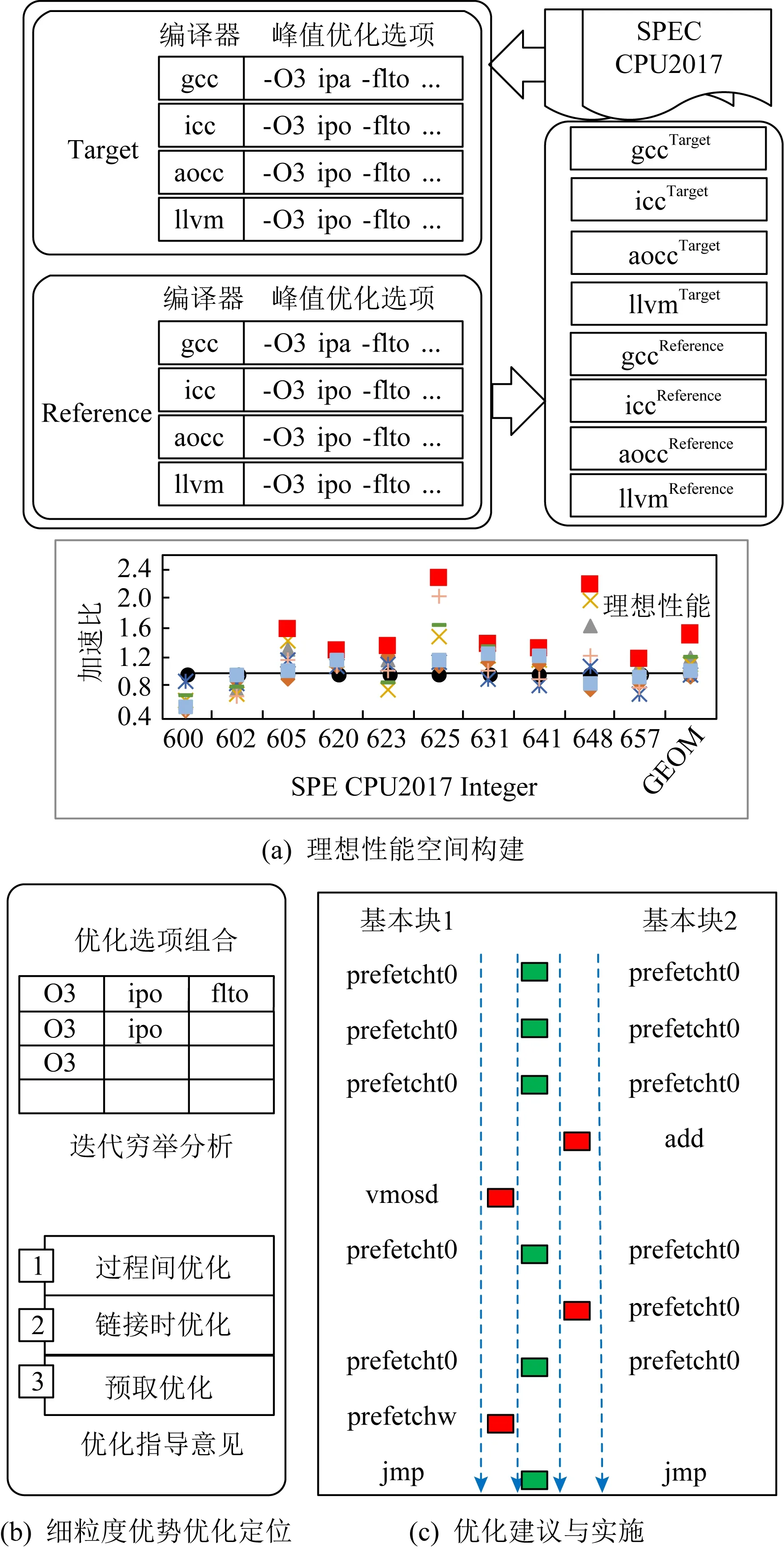
Fig. 4 Cross-architectural analysis techniques for the ideal performance space圖4 面向理想性能空間的跨架構分析技術
圖4展示了面向理想性能空間的跨架構編譯分析技術的主要架構,它包括理想性能空間構建、細粒度優勢優化定位、優化建議與實施3個主要模塊.首先PDCA構建一個理想情況下,目標編譯器能獲取的理想性能提升空間.它借鑒業界發布的峰值數據,將候選平臺和候選編譯器所形成的架構組合形成的用例匯集到目標平臺上進行性能測試.在此過程中,由每一個測試用例最好的性能組成了理想峰值數據集,平均的理想峰值數據與目標編譯器性能之間的差距形成了理想性能空間,這是后續優化提升的依據.每一個峰值數據對應的架構構成一個峰值架構組合.其次,在細粒度優勢優化定位過程中,針對每一種峰值架構,在限定的選項范圍內,即峰值選項范圍內進行機器學習自動選項分析,輔以VTune等性能分析工具,明確引發性能差異的主要優化手段;最后,經過人工分析,明確優化方式,線性比對熱點區域代碼的中間表示指令(intermediate representation, IR),并仿照參照編譯器的設計實施到目標編譯器中.經過上述3個步驟,目標編譯器可以獲得最終性能提升.
PDCA是一種實用型分析技術,它在一個理想性能空間的指引下,對峰值選項進行分析.這種方式不僅大大減少了分析的工作量,還可以對目標編譯器的最終受益效果更加明確.在理想性能空間的指引下,將分析結論和設計方案逐步實施在目標編譯器中,使其真正獲益,繼而縮小目標編譯器與峰值性能數據之間的差距.
2.1 理想性能空間構建
構建理想性能空間需要擴大待分析的架構組合數量,為目標編譯器提供盡可能多的提升機會.如圖4(a)所示,首先明確選擇出待分析的平臺和待分析的編譯器組合,在每個平臺上根據峰值選項使用每個編譯器對SPEC CPU2017測試集編譯出動態可執行碼.然后將所有的動態可執行碼集中于目標平臺上運行測試.這樣,無須考慮外圍庫的干擾,不同架構組合下的可執行碼的性能差距可以近似地認為是由編譯器優化能力所致,在后面的分析過程中,只需僅僅關注編譯器本身即可.
跨平臺測試完之后,在目標平臺上會產生多組性能數據.對于每個測試用例均選取最高的性能,即可構成峰值架構集合,此峰值架構集合最終的性能與目標編譯器構成理想性能空間(idea-peak).一般來說,PDCA所關注的編譯器越多,理想性能空間就越大,目標編譯器多能汲取的優化經驗也越為廣泛.
需要說明的是,在這個過程中,在某個編譯器中的峰值選項可能與其他編譯器選項不同,我們會在其他編譯器上對該選項做性能測試,將能夠呈現優勢的選項補充到其他編譯器的峰值選項中.但是我們的目標是為目標編譯器優化提供最大的優化空間,并不是尋找最佳的優化選項組合,所以峰值選項進一步地改進不在本文討論范疇中.
2.2 細粒度優勢優化定位
編譯器性能分析首先需要明確性能差距的原因,即優勢優化選項.通常我們對峰值選項做有限次的迭代測試,確定優勢優化選項的大致方向;然后分析由諸多優化交疊作用后、歷經重重演變的應用程序中間代碼,例如llvm的中間表示IR,或者匯編碼.這些中間代碼有時甚至是經過代碼膨脹數倍.人工需要在眾多優化選項中進行排除并進行驗證.這個過程耗時耗力,并且十分低效.為了降低分析難度,有很多機器學習的相關研究用于分析優化選項的作用[5];一些分析工具還可以幫助定位代碼的熱點函數、熱點區域[6].因此,我們將這些方法結合在PDCA中,使它更加實用.
對于每一個峰值架構,我們可以采用成熟的機器學習的方法繼續輔助分析,從而圈定更有分析價值的選項范圍(優勢選項)以及它所影響的代碼范圍.這里,由于峰值選項是最直接帶來優化效果的組合,因此,具有明顯優化效果的技術一定藏于其中.因此,PDCA將分析目標圈定在峰值選項范圍內,大大降低了分析的時間開銷.在明確出優勢選項后,用VTune和gprof等工具輔助,我們最終可以將優勢選項以及它所影響的代碼范圍圈定在很小的區域內,有利于人工分析.
2.3 優化建議與實施
在自動分析結束后,待分析的代碼區域相對較小,需要進行人工分析,我們稱之為“最后一步”.這個過程高度依賴于編譯器設計人員的專業經驗,對來自目標編譯器以及峰值架構的中間代碼區域(IR)進行線性對比,確定區域中存在的差異,依賴經驗推測出2個編譯器在優化上的不同原因.通過對目標編譯器的相關優化模塊進行深入了解,仿照峰值架構進行改進優化,從而獲得一定性能提升,盡量縮小理想性能空間.現今,研究領域尚欠缺成熟的自動工具來替代這一步,因此,這一步也成為編譯器性能分析中難度最大的環節,編譯器設計人員的經驗決定了優化分析的時間開銷.我們接下來的研究將針對“最后一步”問題展開研究.
3 實驗與分析
PDCA一種面向由多平臺、多編譯器構成的復雜場景下的編譯分析技術.本節,我們將PDCA應用在Intel和Hygon平臺上,并圍繞2個問題進行探索:
1) 在多平臺、多編譯器的復雜場景下,PDCA是否可以給目標編譯器更大的性能提升空間,即PDCA是否具有實用價值.
2) PDCA是否足夠精準,即它所快速定位出的優勢優化是否可以帶來實際性能提升.
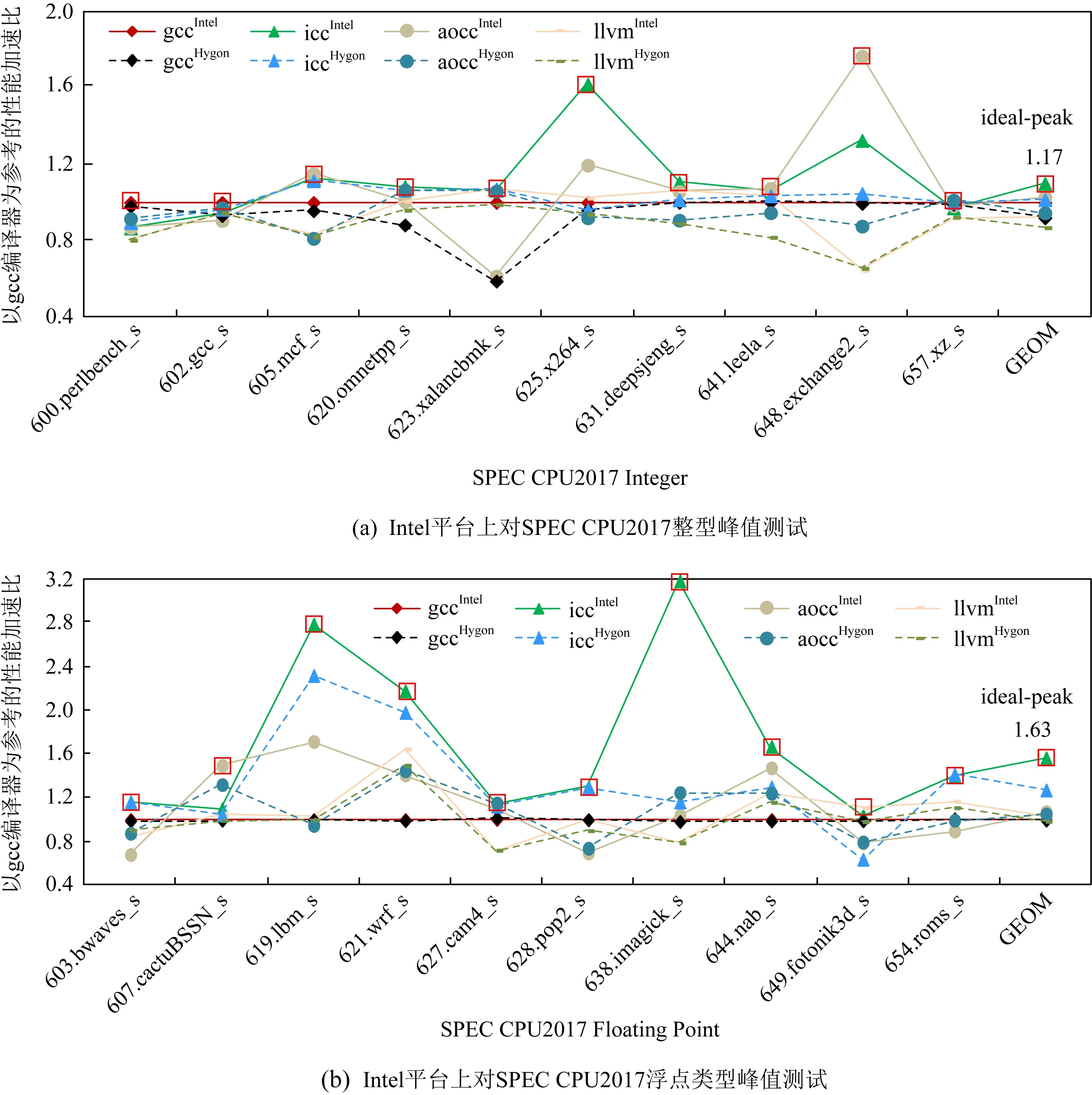
Fig. 5 Peak testing on the Intel platform with gcc as the benchmark圖5 Intel平臺上以gcc為基準的峰值的測試
針對問題1,我們將PDCA應用在Intel和Hygon兩個平臺上,并選擇4個代表性編譯器gcc,icc,aocc,llvm作為候選編譯器,它們最終形成表1所列的8個候選架構組合.其中,以Intel平臺為例,compilerIntel是指在Intel機器平臺上編譯并運行,compilerHygon是指在Hygon機器平臺上編譯后經跨平臺匯集到Intel平臺上執行的動態可執行碼.峰值選項經參考SPEC CPU2017官網和測試用例的基本特征而形成[7].一些編譯器的峰值選項具有特有選項,我們會在其他編譯器中嘗試運行,將會帶來性能提升的選項補充到其他編譯器中.總的來說,不同峰值選項均包括了O3、內聯、循環優化、鏈接時優化、高效內存管理庫等主要優化手段.通過將8組架構的峰值數據匯集在目標平臺Intel上,用以判斷PDCA技術是否比單一icc帶來更大的性能分析空間;同理,我們在Hygon上對來自上述8個候選架構的組合進行對比分析,用以判斷PDCA是否具有一定普適效果.針對問題2,我們將PDCA施用于峰值架構上,并完成細粒度分析,生成優化建議.通過優化實施效果來展示PDCA在分析指導方面的精準性.
3.1 理想性能空間
3.1.1 以Intel平臺gcc為目標編譯器
gcc是使用范圍最廣的通用編譯器之一,它具有卓越的健壯性,然而在性能上與商用編譯器之間存在一定的差距,有很大的優化空間.在Intel平臺上以gcc為優化目標編譯器,采用常用的性能加速比來進行2款編譯器的性能對比.如式(2)所示,以目標編譯器架構(gccIntel)為基準,其他編譯器架構(compilerplatform)的性能與之對比,即可算得性能加速比(speedup):
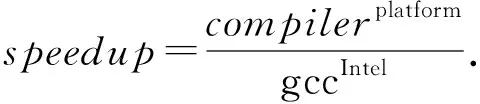
(2)
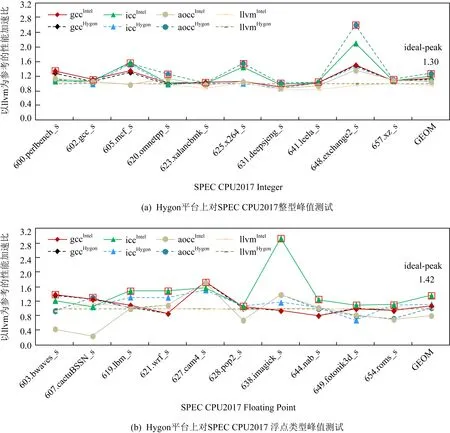
Fig. 6 Peak testing on the Hygon platform with llvm as the benchmark圖6 Hygon平臺上以llvm為基準的峰值測試
我們在Intel和Hygon上,采用表1所列各個編譯器分別對應的峰值選項對SPEC CPU2017定點和浮點20個測試用例分別進行編譯,形成8組動態鏈接可執行碼,并將其放入目標平臺Intel上執行,依據各個用例最好的性能數據來建立理想性能區間以及峰值架構集合.在這個過程中,由于每組代碼都是動態連接,在執行過程中會使用本地編譯器相同的庫代碼,因此,SPEC CPU2017性能差異主要體現在編譯器自身優化能力上.圖5列舉了Intel上定點和浮點集合所產生的8組架構組合的性能曲線.在圖5(a)中,iccIntel的性能比基準gccIntel的性能高出10%,在整個定點測試用例中,峰值架構并不是僅僅來源于單一的icc編譯器,從圖5可以發現在不同應用上其他架構組合也表現不出,如648.exchange2_s的峰值架構是aoccIntel,并不是icc編譯器.對以上所有的定點測試用例選擇峰值架構,即有17%的理想性能空間.同理,如圖5(b)中的浮點數據曲線一樣,雖然icc針對浮點用例的優化是具有一定優勢,但理想性能空間不僅僅來源于icc,還來源于其他的峰值架構,如607.cactuBSSN_s,它最好的性能來自于aoccIntel.最終對浮點測試用例選擇最好的峰值架構,即有63%的理想性能空間.
3.1.2 以Hygon平臺llvm為目標編譯器
為了說明PDCA跨架構分析的必要性以及可行性,我們將PDCA布局在Hygon上,并選擇了另外一款主流編譯器llvm(llvmHygon)[8].隨著芯片的飛速發展及多元化,llvm所具有的小巧、易組合等特點使它成為研究領域以及AI等芯片設計公司首選的編譯器工具之一.本節的實驗也有助于評估llvm的性能.同3.1.1節實驗一樣,我們在Intel和Hygon上采用表1的峰值選項對SPEC CPU2017定點和浮點分別編譯,形成8組動態鏈接執行碼,并將其放入到目標平臺Hygon上執行.圖6是Hygon平臺上定點和浮點所產生的8組架構組合的性能數據曲線.圖6(a)數據表明,峰值數據不僅僅來源于aoccHygon架構,還來源于gccIntel架構,并且理想性能達到30%.圖6(b)中所有的峰值數據均來自于Intel平臺上編譯的可執行碼,多數峰值數據來自于標記三角形的曲線代表iccIntel架構,結合gccHygon架構所產生的峰值數據,理想性能空間高達42%,說明在Intel機器上icc編譯器編譯的可執行碼性能突出,是非常可值得作為目標平臺上目標編譯器優化的參考.
3.1.3 小結
采用PDCA對Intel和Hygon上編譯器進行全面的對比分析.如圖7所示,在同一個平臺上,理想性能區間很難由一個架構組合覆蓋;在不同平臺上,同一種編譯器的性能優化能力也不盡相同.因此,PDCA提供了一種實用分析技術,可以在擴張的架構組合的基礎上進行更大范圍的分析,從而使跨平臺跨編譯器構成的復雜場景下的編譯分析成為可能,使得目標編譯器有更大的性能提升可能.
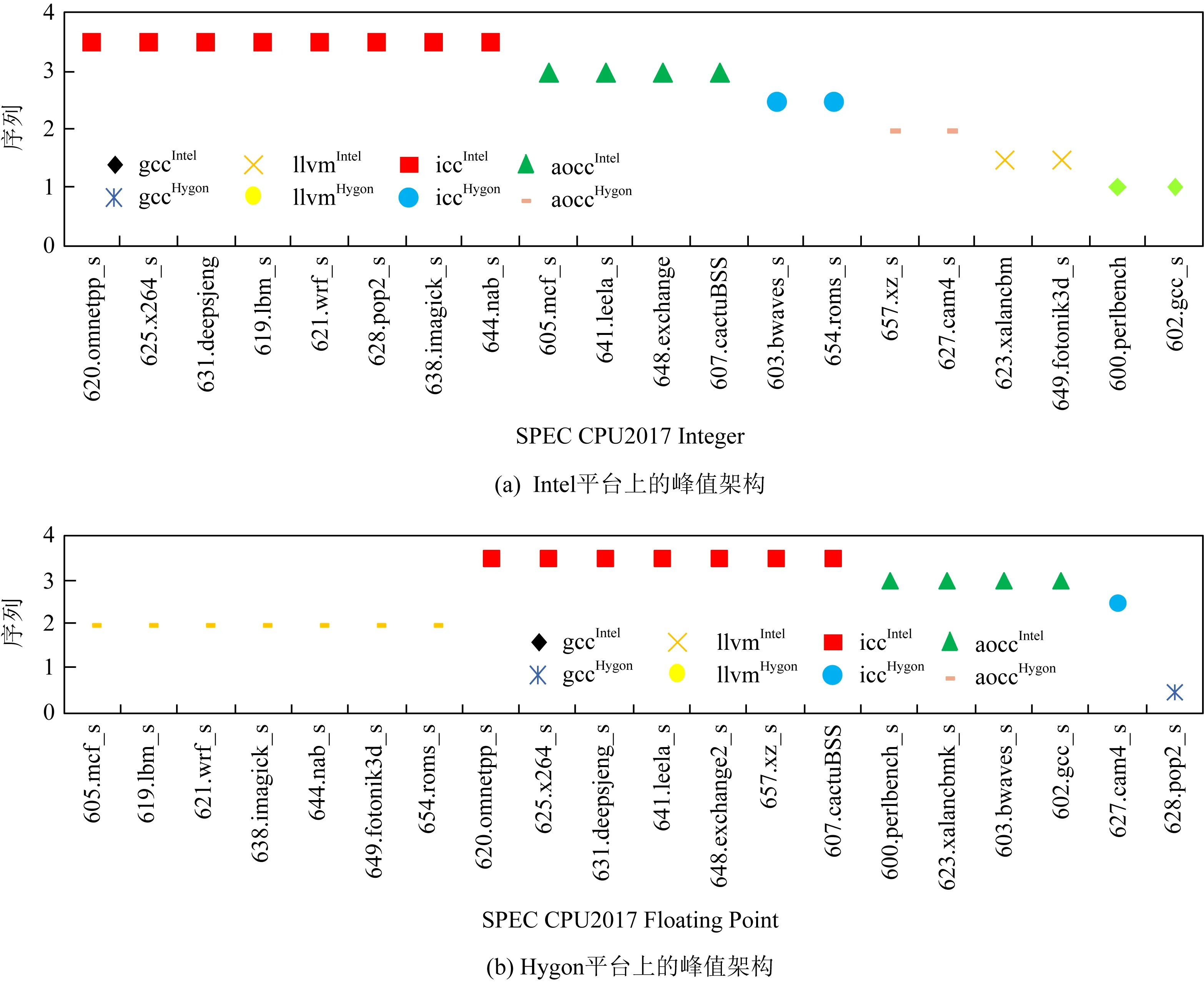
Fig. 7 Peak architecture set on the Intel and Hygon platform圖7 Intel和Hygon平臺峰值架構集
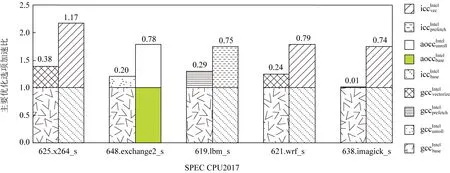
Fig. 8 Advantage optimization options on the Intel platform圖8 Intel平臺上優勢優化選項
3.2 細粒度性能分析以及優化指導
圖7展示的是SPEC CPU2017定點和浮點測試用例在Intel和Hygon平臺上的峰值架構組合.根據以上的呈現的峰值架構,選定性能差距最大且最有可能優化的測試用例,如Intel平臺上的619.lbm_s,625.x264_s和638.imagick_s等用例.然后對以上的具體測試用例根據峰值優化選項做有限次地迭代測試,可以明確出優化方向,即優勢優化選項.
如圖8所示,我們在Intel平臺上選擇了峰值架構性能比目標編譯器gcc性能差距更大的測試用例,對選定的測試用例做仔細地分析,可以明確出優勢優化選項.首先,以峰值選項全部關閉為基準數據,然后只打開某一重要峰值選項,這樣即可測試出該優化選項的性能加速比,然后與基準架構在該優化選項的加速比做比較,差值越大表示此優化選項最有可能是優勢優化選項.如619.lbm_s測試用例,iccIntel架構中預取優化選項的加速比為75%,但gccIntel架構上的加速比只有29%,所以該測試用例的優勢優化選項為預取優化選項,為后面的優化確定了優化方向.
在此基礎上,我們借助VTune工具,確定熱點區域函數,將分析代碼縮減至一定的范圍,有助于下一步的分析.接下來進一步線性對比該熱點函數優化之后的匯編指令,經發現是代碼分支和預取距離的因素導致gcc編譯的預取指令少于icc編譯的預取指令,為此修改gcc源碼,最終相較于優化之前的gcc版本,該測試用例有67%的性能提升.
綜上所述,PDCA是一個實用的分析優化方法,在選定峰值架構之后,通過細粒度分析,可以準確定位出優勢優化選項和優化意見,并最終達到很好的性能提升效果.
4 相關工作
編譯器的選型受機器平臺和編譯器特征的影響.現今機器平臺也越發復雜,通常是處理器與多個加速設備互聯組成異構系統[9].高性能計算系統架構基本使用了MIC(many integrated core architec-ture)和GPU[10]等眾核處理器作為加速器或協處理器.王淼團隊在異構多核處理器上提出了一種代碼自動生成框架[11].
隨著半導體工藝技術的提升,編譯器的發展也是日新月異.華為為解決Android應用程序安裝速度慢和運行效率低的問題,開發了方舟編譯器.llvm是目前研究最熱和發展最快的開源編譯器之一.根據它可定制的特性以及遵守伯克利軟件發行版(Berkeley software distribution, BSD)的開源協議,許多廠商已經開源出了許多優秀的產品.谷歌基于llvm開發了Gollvm,旨在為Go語言提供更強大的特定編譯器.微軟基于llvm開發了LLILC,作為跨平臺的.net代碼生成工具.AMD也基于llvm開發出AOCC編譯器,旨在針對AMD系列17 h處理器-Zen架構提高性能.不僅國外企業熱衷于llvm,國內許多企業也越來越多地選擇了llvm,將其作為它們核心產品的基本框架.AI領域的創業公司,如寒武紀、地平線等,將llvm搭載于自己的智能芯片上.
編譯器的優化模塊高達數百種,編譯器的優化順序也非常重要.迭代搜索是一種確定優化選項執行順序的一種重要技術,相對于靜態模式有顯著的性能體現[12].Ogilvie團隊將序列分析的方法和迭代編譯的主動學習技術相結合,可以降低迭代編譯花費的成本并且能預測特定應用程序的重要優化選項[1].Dubach團隊基于機器主動學習的方法在不同平臺上自動學習最佳的優化,以適用于任何新的微體系架構[4].Kulkarni團隊是使用機器學習的方法將優化順序構建成Markov模型,以減小編譯器優化階段的排序問題[13].優化之后的測試用例代碼大小是決定其性能高低的關鍵因素,為了減小測試用例代碼量,王錚團隊采用了序列對比來合并任意函數,以此可以提升過程間優化的性能[5].為了實現高效的預取優化,Timothy團隊采用深度優先算法實現了一種新的編譯器通道,實現自動生成用于間接訪問內存的預取[14].Doerfert團隊根據Presburger算法框架來收集、概括程序特征和簡化優化先決條件[15].Fursin團隊在gcc編譯器上使用了機器學習的方法,實現自動提取程序特征以調整程序優化變換[16].
SPEC CPU2017是重要的性能測試集,此測試集包含的程序用例多,復雜度高,代碼量大且涉及的算法廣泛[17].Panda團隊基于主成分分析(PCA)和聚類等統計方法來尋找測試基準程序間的相似性[7].使用測試基準的子集,這可極大減少測試時間.Genesis[18]是一種生成用于機器學習的性能自動調優的合成程序語言.Cummins團隊在大量的開源庫源碼中,使用深度學習方法自動地推測程序片段結構,然后自動生成與此程序片段結構相似的應用測試程序[19].
5 總結與展望
本文闡述了編譯器的優化受機器平臺和編譯器特征的影響.提出了一種基于峰值數據的面向跨平臺跨編譯器的編譯器分析與優化方法.選擇峰值架構,構建目標編譯器在目標平臺上的理想性能提升空間,并為其做最大可能的性能優化與提升.
本文通過實驗驗證了該方法在多平臺與多編譯器之間的普適性與實用性.分別在Intel和Hygon平臺上為SPEC CPU2017定點和浮點每個測試用例提供可靠實用的峰值架構,并在Intel平臺上對突出的峰值架構測試用例做了詳盡分析,結合對常用峰值選項的迭代編譯與成熟的機器學習優化分析方法為目標編譯器總結出優化方向.在“最后一步”的分析中更多地依賴工作者的經驗確定待優化方向,還沒有成熟的自動化工具,這是我們未來研究的方向與重點.
貢獻聲明:賴慶寬進行了該論文的實驗驗證和論文撰寫等工作;呂方進行了論文中方法的設計和論文的修改;何先波和賀春林進行了論文的修改和校正;馮曉兵進行了課題的調研、論文的修改和討論.
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
電子制作(2018年18期)2018-11-14 01:48:24
山東工業技術(2016年15期)2016-12-01 05:31:22
現代企業(2015年2期)2015-02-28 18:45:09
中國中醫藥現代遠程教育(2014年11期)2014-08-08 13:23:44
