基于深度學習的圖像隱寫研究進展
2021-04-01 01:18:40付章杰李恩露黃永峰胡雨婷
計算機研究與發展 2021年3期
付章杰 李恩露 程 旭 黃永峰 胡雨婷
1(南京信息工程大學計算機與軟件學院 南京 210044) 2(鵬城實驗室 廣東深圳 518066) 3(清華大學電子工程系 北京 100084)
(fzj@nuist.edu.cn)
隱寫是一種將秘密信息隱藏于載體進行隱蔽通信的技術,在信息安全、數據通信等多方面都發揮著重要作用,對保障數據安全、維護社會穩定都具有重要意義.常用的隱藏載體包括文本、圖像、音頻、視頻等,其中應用最廣泛的是基于圖像的隱寫技術,嵌入秘密信息之前的原始圖像稱為載體圖像,嵌入秘密信息之后的圖像稱為含密圖像.
在圖像隱寫的第1階段,研究者們通過特定的嵌入方式修改像素值[1-3],如最低有效位替換或修改,將秘密信息隱藏于載體圖像中,達到隱蔽通信的目的.這種類型的像素修改一般發生在像素比特位的低位,低位的比特值反映圖像的細節信息,因此替換為秘密信息并不會影響圖像的整體效果.但是該類方法會對圖像的統計特性造成明顯的改變,隨著專用型隱寫分析方法與通用型隱寫分析方法的出現,該類圖像隱寫技術難以滿足隱蔽通信的安全性要求.
在圖像隱寫的第2階段,研究者們考慮載體圖像的自身屬性,使用內容自適應的隱寫方法.由于圖像本身具有高度的復雜性、存在較多的冗余信息,對圖像做微小的改動并不會引起人類視覺異常,如紋理復雜區域的統計特性難以被檢測出異常情況,因此,在這些區域進行隱寫就可以提高圖像隱寫的隱蔽性.內容自適應隱寫又稱為最小失真隱寫,為每個像素分配嵌入成本,嵌入成本反映像素修改后被檢測出的風險,該圖像的隱寫失真為所有更改像素的嵌入成本之和.內容自適應隱寫的最終目標是找到合適的嵌入位置使隱寫失真最小,研究的主要內容是隱寫失真代價函數的設計,該函數用于衡量每個像素的嵌入成本.最常用的定義失真代價函數的準則是啟發式原則,由于圖像復雜區域的異常模式難以被檢測,因此復雜區域的嵌入成本較小,HUGO(highly undetectable stego)[4]為此原則下第一個失真函數,WOW(wavelet obtained weights)[5],UNIWARD(universal wavelet relative distortion)[6-8],HILL(high-pass,low-pass,and low-pass)[9]等都是先進的內容自適應圖像隱寫方法.隨著內容自適應隱寫的出現,隱寫分析器的檢測能力也進一步提升,出現了捕捉圖像高維特征的富模型隱寫分析器[10-12],如空域富模型(spatial rich model, SRM)[10].通過特定的高通濾波器獲得噪聲殘差的高階統計量,以此作為隱寫特征進行分析,富模型在傳統隱寫分析領域具有突出的性能,傳統的圖像隱寫方法已經難以抵抗隱寫分析的檢測.
近年來,為了提升隱寫的隱蔽性,研究者們致力于研究新的隱寫技術.由于深度學習具有強大的特征學習能力,且在計算機視覺等領域產生了許多研究成果,研究者們將深度學習引入圖像隱寫中,用大量的數據訓練神經網絡,讓網絡學習更隱秘的隱寫行為.最核心的轉變是將傳統的依賴手工、先驗知識設計的隱寫方法轉化為依賴于數據驅動、網絡自主學習的隱寫方法,具體而言,深度學習的引入對載體圖像本身、信息嵌入的原則、信息嵌入的方法等多方面都有較大的應用意義.為了增強隱寫的隱蔽性,人們選擇紋理豐富的圖像作為隱寫載體,隨著深度學習的引入,載體圖像的獲取來源并不局限于圖像庫.生成對抗網絡(generative adversarial network, GAN)[13]具有強大的圖像生成能力,可以根據隱寫的需要生成適合隱寫的載體圖像;結合生成對抗樣本[14-15]的技術增強原始圖像,使含密圖像具有主動欺騙隱寫分析器的能力,這些方法都使載體圖像更適于隱寫過程.為了設計合理的失真函數,制定更好的自適應嵌入原則,基于深度學習的失真函數設計方法,不根據先驗知識設計失真函數,而是考慮統計上的不可檢測性,在與隱寫分析網絡對抗學習的過程中,由生成網絡自動學習圖像中每個像素點的失真值.在自適應隱寫方法中,隱寫算法常常結合編碼方法一起使用[16],研究者們大多采用伴隨式矩陣編碼(syndrome-trellis codes, STC)[17]的方式得到含密圖像,STC編碼方法可以在給定隱寫容量和像素失真的前提下實現最小的嵌入失真,以像素值最少的修改實現秘密信息的嵌入.基于深度學習的含密圖像生成方法,通過編碼-解碼網絡就可以實現秘密信息的嵌入與提取,對于圖像隱寫的操作者而言,無需具備隱寫的先驗知識,同時可以實現大容量的圖像隱寫.
由此可見,深度學習為圖像隱寫方法帶來了巨大的變革,但上述3種基于深度學習的載體圖像獲取、隱寫失真設計、含密圖像生成方法沒有脫離隱寫方法的本質,即載體修改,在隱蔽通信中只要圖像被修改,就會使隱寫分析有跡可循.除了通過修改載體圖像實現圖像隱寫,還存在通過選擇或者合成載體的無載體圖像隱寫方法.無載體圖像隱寫不需要原始的載體圖像,更不需要對載體圖像進行像素修改,通過與秘密信息構建映射關系來選擇或者合成圖像獲得載體圖像.由于沒有動態的嵌入過程且所獲得載體圖像本身已經攜帶秘密信息,該類載體圖像即含密圖像.無載體圖像隱寫與上述3種基于深度學習的載體圖像獲取、隱寫失真設計、含密圖像生成方法相比最大的不同之處在于,隱寫時不需要對載體圖像做出修改,因此不會在圖像上留下隱寫痕跡,含密圖像具有天然的抗隱寫分析能力.隨著研究的深入,出現了一些與深度學習相結合的無載體圖像隱寫方法,進一步提升了隱寫的隱蔽性與容量.鑒于無載體圖像隱寫具有天然的抗隱寫分析性能,尤其在結合深度學習之后又有了更大的發展空間,因此,該類隱寫方式值得進一步研究.
本文從基于深度學習的圖像隱寫和無載體隱寫2個方面對近期的圖像隱寫方法進行分析和總結,具體分類如圖1所示.著重討論基于深度學習的圖像隱寫技術,將基于深度學習的圖像隱寫分成3類:1)基于深度學習的載體圖像獲取;2)基于深度學習的隱寫失真設計;3)基于深度學習的含密圖像生成.最后闡述與分析無載體圖像隱寫方法的優缺點.
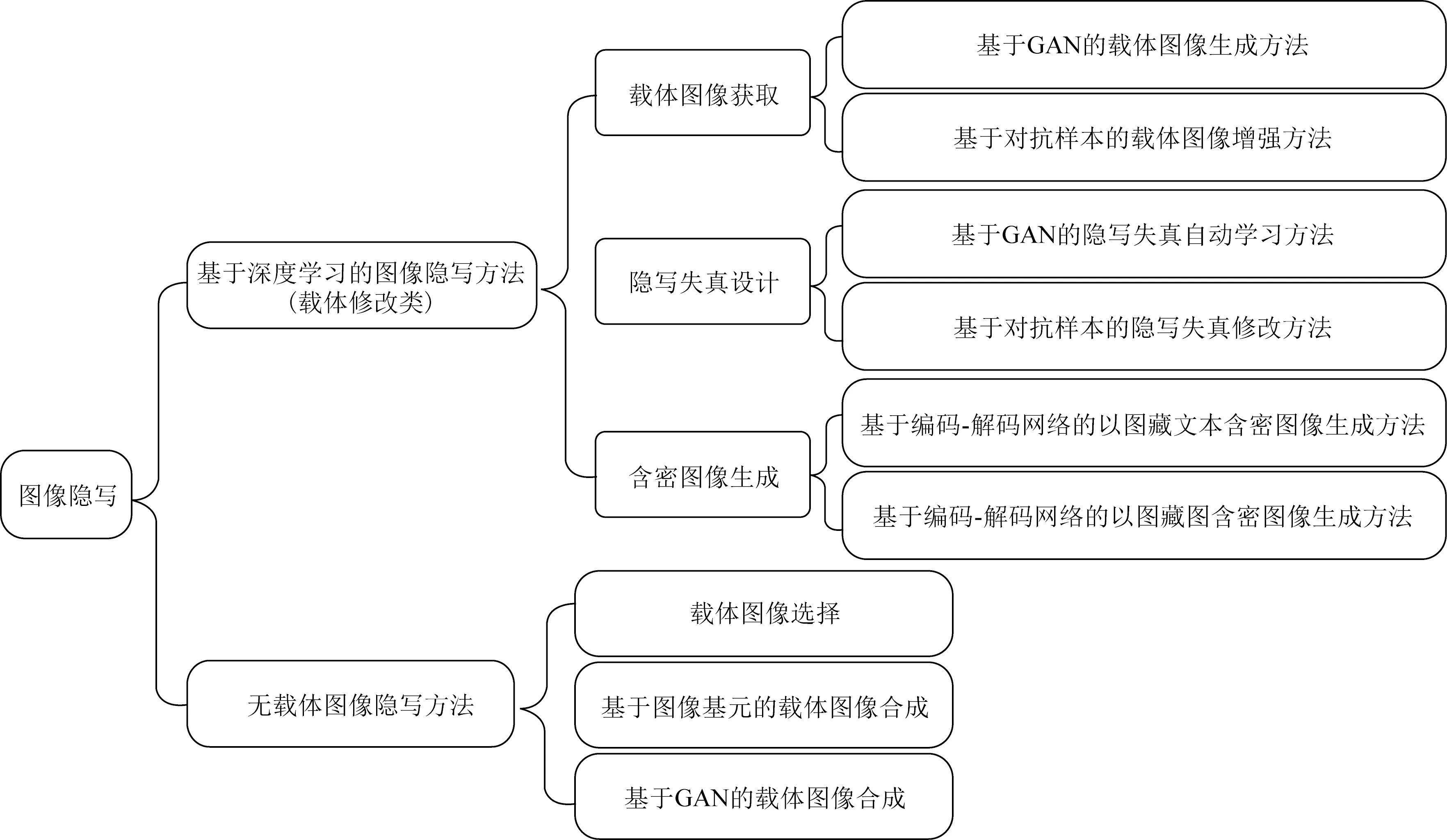
Fig. 1 The classification of recent image steganography圖1 近期的圖像隱寫分類
1 基于深度學習的載體圖像獲取
隨著LeNet[18]、AlexNet[19]、GAN[13]、VGG[20]、Inception[21-22]、殘差網絡(residual networks, ResNet)[23]等網絡模型的提出,深度學習的研究與發展進入了爆發時期,在圖像去噪、圖像識別、圖像分類等計算機視覺領域有成功的應用.其中,研究較為廣泛的有生成對抗網絡和對抗樣本,二者在圖像隱寫領域的應用為隱寫方法帶來了巨大的變革.隨著深度學習的引入,用于隱寫的載體圖像的獲取來源并不局限于圖像庫,還可以借助深度學習技術獲得更適合隱寫的載體圖像.根據獲取方式的不同,本節從基于生成對抗網絡的載體圖像生成、基于對抗樣本的載體圖像增強2個方面分析深度學習在載體圖像獲取中的應用.
1.1 基于GAN的載體圖像生成方法
基于生成對抗網絡的載體圖像生成方法,運用了GAN網絡中對抗博弈的思想,網絡訓練的依據是2014年Goodfellow等人在文獻[13]中提出的目標函數.將生成對抗網絡引入圖像隱寫,目標是在對抗訓練的過程中生成適于隱寫的載體圖像,嵌入秘密信息后使隱寫分析器誤判.
2017年Volkhonskiy等人[24]提出SGAN(ste-ganographic generative adversarial networks)網絡模型,這是第1個基于生成對抗網絡的圖像隱寫方法.生成網絡在與判別網絡、隱寫分析網絡的對抗博弈中調整網絡參數,使得生成的圖像在嵌入信息后達到自然圖像真實的效果,可以欺騙隱寫分析,換句話說,生成的圖像更適用于隱寫,該方法從載體圖像的角度提高了隱寫的隱蔽性.具體的網絡結構如圖2所示,在基礎GAN的結構上,加入隱寫分析網絡,以生成網絡生成的圖像為載體,載體輸入給判別網絡,提高載體圖像的真實性.在得到載體圖像之后,用傳統的隱寫方法嵌入秘密信息,將得到的含密圖像輸入給隱寫分析網絡進行判別,根據判別結果優化生成網絡,提高含密載體抵抗隱寫分析檢測的能力.在網絡訓練穩定后,生成的載體圖像真實自然且適于隱寫,判別網絡無法正確地區分生成的載體圖像與真實圖像,隱寫分析網絡無法區分載體圖像與含密圖像,隱寫的隱蔽性得到了保障.
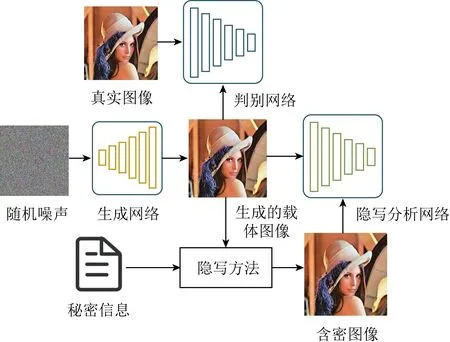
Fig. 2 The architecture of SGAN framework[24]圖2 SGAN網絡結構[24]
文獻[25]指出不同噪聲分布的載體圖像對隱寫安全性存在顯著影響,因此使用適于隱寫的載體圖像極為重要.SGAN最早實現了基于生成對抗網絡的圖像隱寫,對深度學習在圖像隱寫中的應用有著重大的意義,利用神經網絡學習自然圖像的分布特征,從而生成適用于隱寫的載體圖像.但是由于模型的限制,SGAN中的GAN網絡結構難以使生成網絡與判別網絡的訓練達到平衡狀態,這造成生成圖像的視覺質量不佳,影響了圖像隱寫的安全性能.
為了提升圖像的視覺質量,Shi等人[26]提出SSGAN(secure steganography based on generative adversarial networks)圖像隱寫方法,保留SGAN的網絡模型,修改了生成網絡結構[27],生成的載體圖像更自然更真實,使隱寫分析的準確率下降了18%.
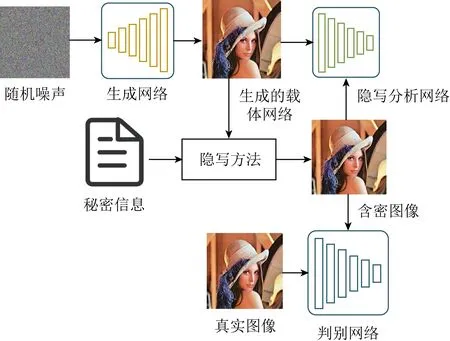
Fig. 3 The architecture of Stego-WGAN framework[28]圖3 Stego-WGAN網絡結構[28]
2018年王耀杰等人[28]進一步改變了模型結構,提出Stego-WGAN(steganography based on wass-erstein generative adversarial networks)圖像隱寫方法,圖3為該模型的結構框架圖.對比圖2可以看出,Stego-WGAN與SGAN最重要的不同之處在于,SGAN將載體圖像與真實圖像一起輸入判別網絡中,而Stego-WGAN將含密圖像與真實圖像一起輸入判別網絡中.這樣做的目的在于,使生成的載體圖像更適用于隱寫嵌入的同時,使生成的載體圖像在嵌入秘密信息后依然能呈現真實圖像的視覺效果,進一步增加了隱寫的安全性.為了直觀地反映SGAN,SSGAN,Stego-WGAN 3種網絡的隱寫效果,表1列舉了這3種網絡在0.4 bpp(bit per pixel)嵌入率下隱寫分析的準確率,數據集為CelebA,bpp表示秘密信息在每個像素中的比特數.可以發現,隨著網絡結構的優化,隱寫分析的準確率在不斷下降,但整體而言,隱寫的隱蔽性仍有很大的提升空間.表1中的數據來源于文獻[26].
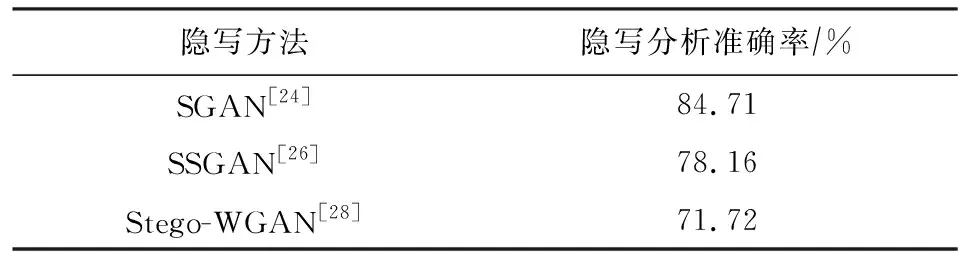
Table 1 Performance Comparison of SGAN,SSGAN,Stego-WGAN Against Steganalysis[26]
基于生成對抗網絡生成載體圖像的方法都運用了對抗博弈的思想,在基礎GAN的基礎上加入隱寫分析模塊,相當于對生成網絡的優化加入了一個約束條件,使得生成的圖像不僅自然真實而且可以提升抗隱寫分析器檢測的能力.盡管隱寫分析的準確率隨著網絡的改進在不斷下降,但含密載體對隱寫分析的抵抗性仍然很差,網絡訓練不穩定,生成的載體圖像的生成痕跡、含密圖像的修改痕跡都會被隱寫分析器檢測.如果要提升該隱寫方法的隱蔽性,可以使用特征學習能力更強的網絡,獲得圖像的深層特征,提高圖像的真實性.但該類方法對于深度學習在圖像隱寫領域中應用的意義是毋庸置疑的.
1.2 基于對抗樣本的載體圖像增強方法
為了增強對隱寫分析器的抵抗能力,研究者們引入對抗樣本增強載體圖像.對抗樣本指的是對原始圖像做一些微小改動,在人眼看來圖像沒有變化的情況下,可以對神經網絡的判斷進行干擾.運用對抗樣本的這個特征,將對抗樣本引入圖像隱寫領域,在含密載體上添加微小的改動,使其偽裝成自然圖像,欺騙隱寫分析器.
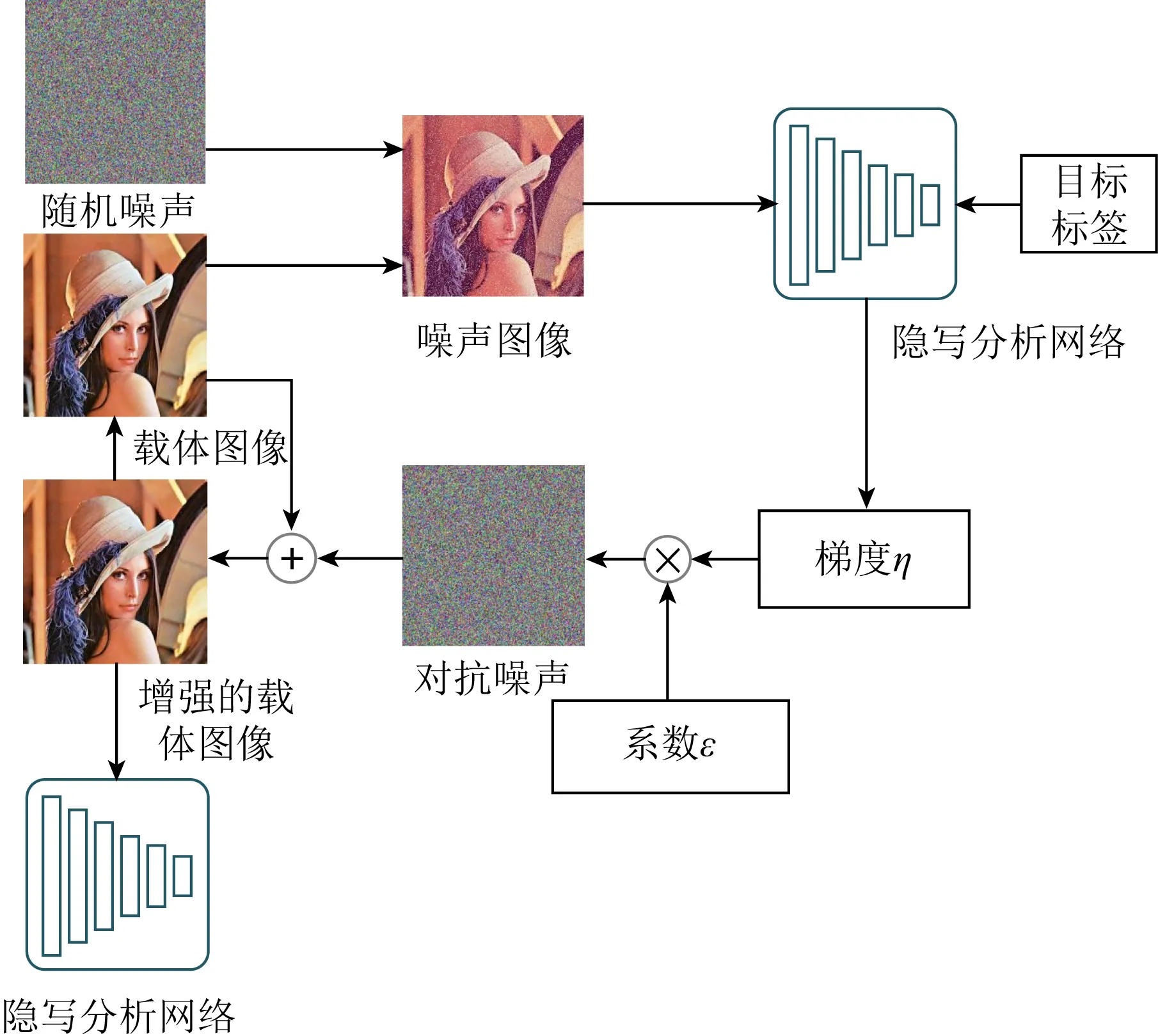
Fig. 4 The process of cover image enhancement[29]圖4 載體圖像增強的過程[29]
2018年Zhang等人[29]結合了對抗樣本的方法,提出了一種有效抵抗隱寫分析的圖像隱寫方法,使含密圖像具有主動欺騙隱寫分析器的能力.提出的方法為:在隱藏信息之前,用生成對抗樣本的方法對載體圖像做增強;在載體圖像的基礎上添加噪聲,模擬信息嵌入,得到含密圖像;在隱寫分析網絡判別時,將含密圖像的標簽設置為載體圖像,根據反向傳播時的梯度即可設定對抗噪聲值,將對抗噪聲添加到原始載體上得到增強的載體圖像.對該載體采用傳統的自適應隱寫算法實現秘密信息的嵌入,若隱寫分析網絡將含密圖像誤判為載體圖像,則得到了增強的載體圖像,否則循環上述操作,繼續對載體圖像增強.載體圖像增強的過程如圖4所示.該方法改變了傳統的圖像隱寫模式,化被動為主動,載體圖像增強成為對抗樣本,使圖像嵌入秘密信息之后得到的含密載體仍然可以偽裝為載體圖像,達到了欺騙隱寫分析器的目的.相比于基于生成對抗網絡的圖像隱寫方法,該方法具有更強的安全性,但是每個圖像都要經過不同的訓練周期得到具有對抗樣本性質的載體圖像,訓練具有復雜性.
2020年Li等人[30]同樣也使用了對抗樣本增強載體圖像的方法,不同于Zhang等人[29]提出的方法,該方法對載體圖像劃分了區域,在部分圖像中隱藏所有的秘密信息,對剩余部分的圖像用生成對抗樣本的方法進行增強,使整個圖像具有欺騙隱寫分析的能力.然而,這種方法隨著欺騙隱寫分析器成功率的提高,圖像質量有所下降,由于只有部分圖像進行了圖像增強,會與另一部分圖像在視覺上形成對比,更增加了被隱寫分析器識別的風險.根據表2可以觀察發現,隨著被攻擊像素點數量的增加,欺騙隱寫分析器的成功率(含密圖像被誤判為載體圖像的比率)在不斷上升,用峰值信噪比(peak signal-to-noise ratio, PSNR)衡量圖像質量,發現整體的圖像質量在不斷降低,這增加了含密圖像被隱寫分析器檢測的風險.表2中用于實驗的數據集為BOSSbase,數據來源于文獻[30].
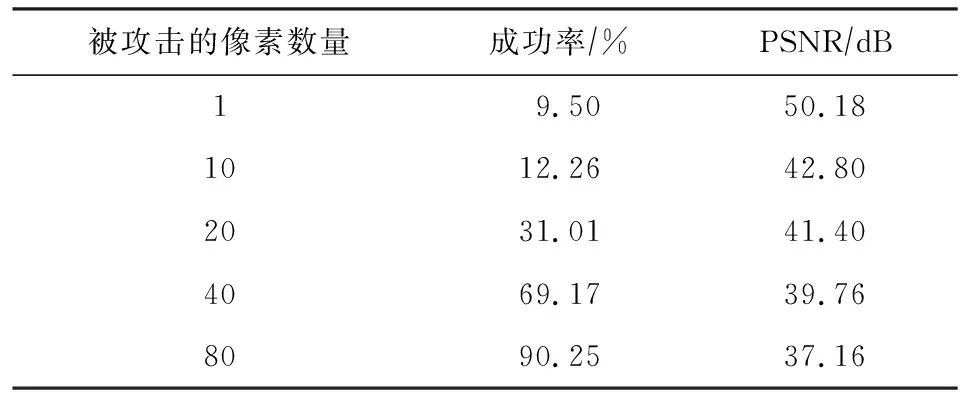
Table 2 Relationship Between Success Rate of DeceptionSteganalysis and PSNR Value[30]
1.3 載體圖像獲取方法的對比與總結
1.1節和1.2節所述2類方法基于深度學習從載體圖像獲取的角度,對傳統的圖像隱寫做出了改進.分別借鑒對抗博弈的思想和對抗樣本的思想,通過神經網絡生成更適于隱寫的圖像或對已有的載體圖像做出修改,達到提升隱寫安全性的目的,但這2類方法仍然存在一些問題.表3是基于深度學習的載體圖像獲取隱寫方法與傳統圖像隱寫方法的對比總結,分別從安全容量、隱蔽性、魯棒性、圖像視覺質量、欺騙隱寫分析器的方式、泛化性、計算效率、結構復雜度8個方面進行總結.在隱寫安全容量方面,將所述方法的安全容量與傳統圖像隱寫的安全容量0.4 bpp進行比較,分為沒有提升、略有提升、大大提升3種情況.在隱蔽性方面,本文提到的每一類隱寫方法中所有方法與傳統內容自適應隱寫方法S-UNIWARD(spatial universal wavelet relative distortion)進行對比,以S-UNIWARD隱寫分析檢錯率作為參考值,觀察每一個類別中大部分隱寫方法的隱寫分析檢錯率,高于參考值,則認為該類隱寫方法隱蔽性好;低于參考值,則認為該類隱寫方法隱蔽性差;與S-UNIWARD接近,則認為該類隱寫方法隱蔽性一般.在魯棒性方面,由于在真實環境下傳輸的圖像都是經過壓縮的,圖像質量受損會造成部分信息丟失,影響秘密信息的提取,因此認為大部分圖像隱寫方法的魯棒性弱.一些基于深度學習的圖像隱寫技術在網絡訓練時模擬了真實環境下圖像壓縮的過程,提升了圖像受損的情況下秘密信息提取的準確度,這類隱寫方法的魯棒性較強.在圖像視覺質量方面,使用PSNR作為衡量含密圖像質量的指標,一般認為:PSNR值高于40 dB的圖像質量好,非常接近原始圖像;位于30~40 dB之間的圖像質量一般,此時可以察覺圖像失真,但失真效果可以接受;位于20~30 dB之間的圖像質量差.欺騙隱寫分析器的方法分為被動和主動,大部分隱寫方法致力于將秘密信息藏得更隱蔽,我們認為這種隱寫方法是防守的、被動的;而基于對抗樣本的隱寫方法通過微小地改動圖像使隱寫分析器誤判,這種隱寫方法具有主動攻擊性.在隱寫方法的泛化性方面,某些基于深度學習的隱寫方法在訓練時只使用了某個隱寫分析器作為判別器,在測試時會對這個隱寫分析器具有較強的抵抗作用,此時,觀察其他隱寫分析器的檢測效果,如果該類隱寫方法仍有較強的抗隱寫分析檢測能力,則認為泛化性好,否則認為泛化性能差.在計算效率和結構復雜度方面,綜合考慮基于深度學習的隱寫方法在構建網絡、訓練網絡等過程中耗費的時間,與傳統圖像隱寫進行對比,由于基于深度學習的圖像隱寫方法需要耗費大量的訓練時間,一般認為基于深度學習的圖像隱寫方法計算效率低、網絡結構復雜.
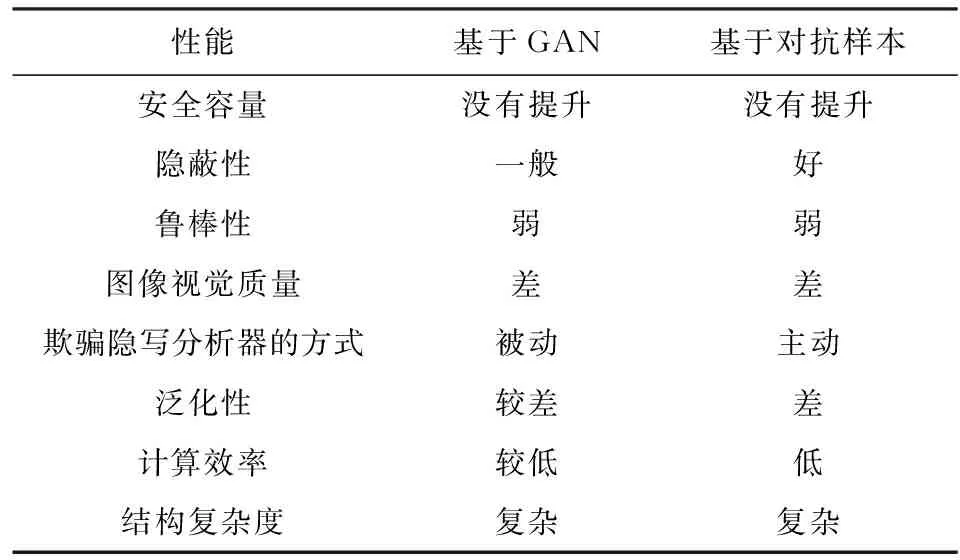
Table 3 Summary of the Application of Deep Learning inthe Acquisition of Cover Images
根據這8種評價指標,我們對上述2種隱寫方法進行如下分析:
基于生成對抗網絡的載體圖像獲取隱寫方法將深度學習引入圖像隱寫領域,對于圖像隱寫的發展具有重大的意義.但是,由于網絡訓練不穩定等因素,人眼直接能看出生成的載體圖像異常,圖像質量差.在相同情況下與S-UNIWARD進行對比,只有Stego-WGAN的隱蔽性優于S-UNIWARD,因此認為該類方法的隱蔽性一般,仍有較大的提升空間.由于在網絡訓練時,只有個別隱寫分析器參與訓練,含密圖像難以抵抗多種隱寫分析器的檢測,隱寫模型的泛化性較差.由于載體圖像質量差、獲取載體圖像之后仍然使用傳統的隱寫方法等因素,隱寫安全容量沒有提升,同時由于前期構建網絡結構、訓練網絡需要耗費一段時間,因此該類方法與傳統隱寫方法相比,計算效率較低,網絡結構復雜.對于該類隱寫方法,可以使用更穩定、更輕量級的生成網絡模型和多種不同的隱寫分析器,在隱蔽性、圖像質量、泛化性、計算效率、結構復雜度等方面進一步做出提升.
對抗樣本可以使神經網絡分類器誤判,基于對抗樣本的圖像隱寫模型使載體圖像具有主動欺騙目標隱寫分析器的能力,提高了隱寫分析器的檢測錯誤率,隱寫的隱蔽性好.網絡結構復雜度與基于生成對抗網絡的載體圖像獲取隱寫方法相似,都比傳統隱寫方法復雜.目前,該類圖像隱寫方法存在3個主要問題:1)在訓練過程中,容易對某種隱寫分析器過度適應,使對抗樣本具有特異性,但是很可能被其他隱寫分析器檢測出異常,難以抵抗多種類型隱寫分析器的檢測,隱寫方法的泛化性差;2)隨著對抗樣本對神經網絡欺騙能力的增強,圖像的視覺質量受到影響,會出現清晰的圖像噪聲而被人眼察覺;3)每次隱寫前都要對載體圖像進行增強,使載體圖像具有對抗樣本的性質,計算效率低.為了解決第1個問題,一方面可以在訓練過程中增加隱寫分析器的類型;另一方面增強對抗樣本的泛化性;為了解決第2個問題,在生成對抗樣本的過程中,只對小部分像素進行修改,減少對圖像全局的改動;為了解決第3個問題,可以尋找生成可分離對抗樣本的方法,將對抗噪聲與圖像分離,在不同載體圖像結合的同時保持對抗樣本的性能,減少隱寫過程中的計算效率.
2 基于深度學習的隱寫失真設計
對于傳統的自適應隱寫框架,除了利用深度學習的方法得到更適合嵌入的圖像,還可以考慮利用神經網絡設計更好的失真函數,使信息嵌入后含密圖像的總隱寫失真最小,減少由像素修改引發的圖像統計異常.從使用生成對抗網絡和對抗樣本2個不同的角度,深度學習在隱寫失真設計中的應用可以分為:利用生成對抗網絡自動學習圖像失真、利用對抗樣本修改已有的失真值.無論是哪種方法,在得到圖像失真之后,都利用STC編碼方法找到最優的嵌入策略,實現最小嵌入失真情況下修改最少的圖像隱寫.
2.1 基于GAN的隱寫失真自動學習方法
現有的基于生成對抗網絡的隱寫失真代價設計主要包括ASDL-GAN(automatic steganographic distortion learning using a generative adversarial network)[31],UT-SCA-GAN[32-33]等.在對抗訓練中,利用生成網絡得到每個像素的嵌入改變概率,使用網絡學習或公式推導的方法將嵌入改變概率轉化為像素修改圖,最終根據像素修改圖修改載體圖像即可得到含密圖像.該類方法的框架如圖5所示:
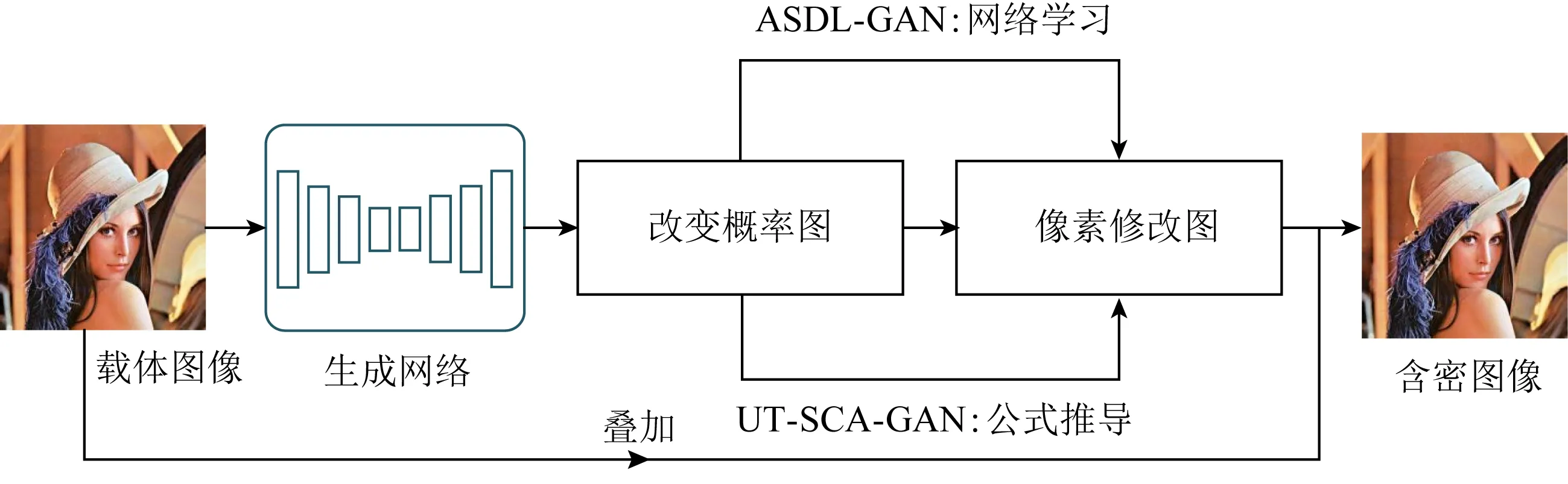
Fig. 5 The basic architecture of automatic steganographic distortion learning using GAN圖5 基于生成對抗網絡的隱寫失真自動學習方法基本框架
2017年Tang等人[31]首次使用生成對抗網絡自動學習圖像的隱寫失真,改變了傳統根據先驗知識設計隱寫失真的方法,在生成網絡與隱寫分析網絡對抗訓練的過程中,提高含密圖像統計上的不可檢測性,因此該隱寫模型可以有效抵抗隱寫分析器的檢測.圖6為所提出的ASDL-GAN的網絡結構,生成網絡的輸入是原始載體圖像,輸出修改概率圖,圖中每個像素對應的值pij表示的是該像素被修改的可能性,但不確定像素具體的修改方向.為了在神經網絡訓練過程中模擬信息的嵌入,在像素修改的前提下,默認+1,-1修改的可能性相同,像素值的修改可以表示為
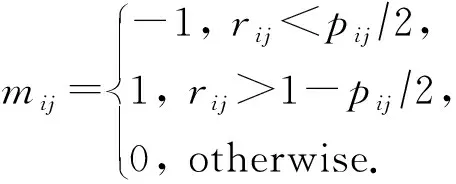
(1)
其中,rij為0~1之間的隨機變量,根據rij的隨機取值和像素修改概率,確定像素具體的修改方向.
根據這個原則,ASDL-GAN設計了TES(ternary embedding simulator)激活函數,是一個小型的神經網絡,網絡結構如圖6所示.生成網絡輸出修改概率圖,XuNet[34-35]作為判別網絡,在對抗訓練中不斷調整生成網絡輸出的修改概率值,經過TES網絡模擬信息的嵌入得到含密圖像,將原始圖像與含密圖像共同輸入判別網絡中,根據判別結果優化生成網絡.在實際嵌入的過程中,得到修改概率值之后,利用STC編碼嵌入秘密信息.
利用生成對抗網絡設計隱寫失真代價的方法值得進行深入研究和優化,減少了傳統隱寫失真設計過程中的人為參與,利用生成網絡與隱寫分析網絡的對抗訓練,自主學習圖像像素的修改可能性,提高含密圖像統計上的不可檢測性,從而增強對隱寫分析器的抵抗能力.但是,該方法與經典的自適應隱寫方法S-UNIWARD[6]相比,性能還有一定差距,對隱寫分析器的抵抗能力有待提高;另外該網絡模型的訓練時間較長,遠遠大于傳統自適應隱寫模型中失真函數的設計過程,且TES網絡需要提前訓練,增加了時間開銷.
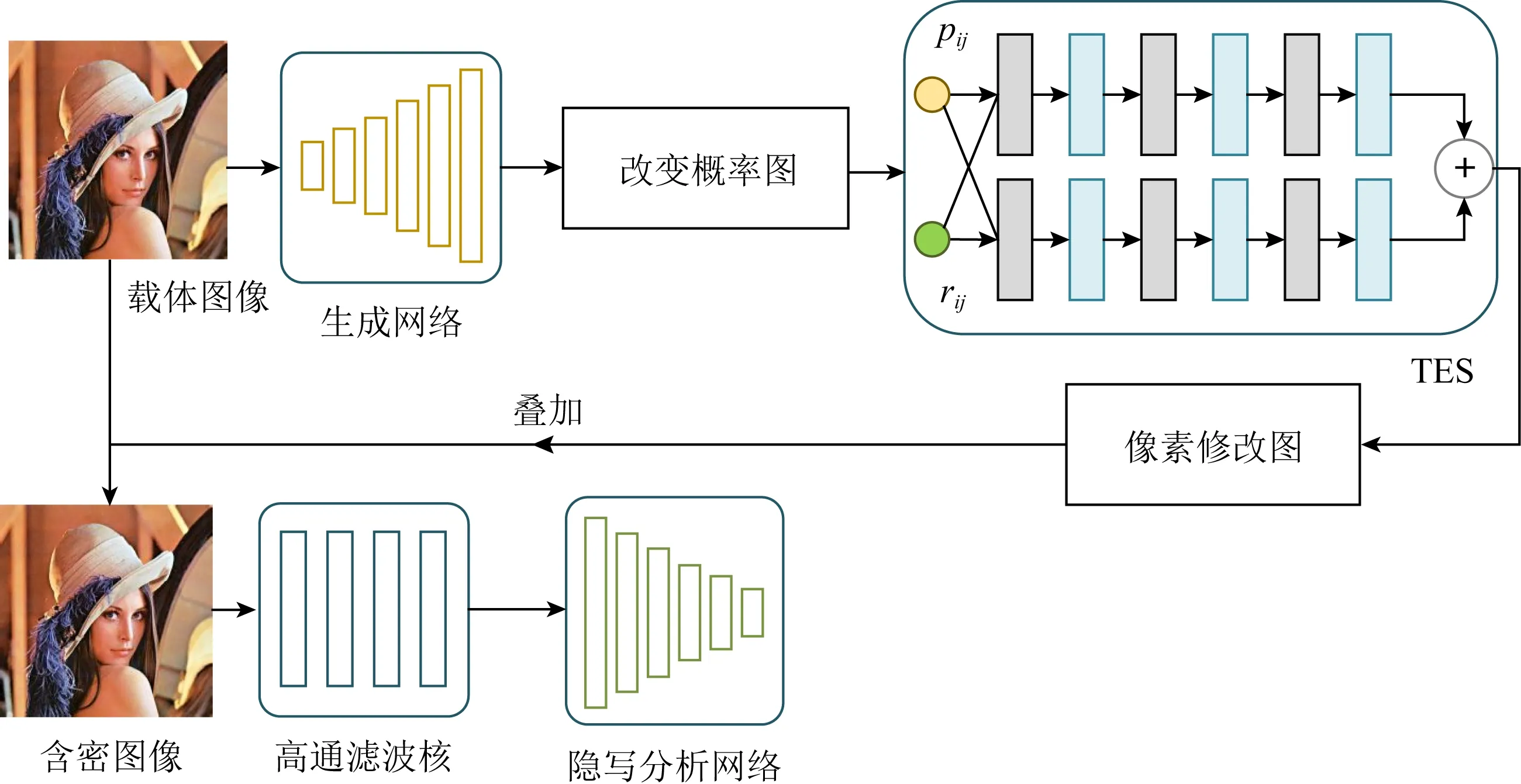
Fig. 6 The architecture of ASDL-GAN framework[31]圖6 ASDL-GAN網絡結構[31]
為了減少訓練的時間,2018年Yang等人[32]使用tanh模擬器作為激活函數來代替ASDL-GAN中的TES激活函數,代替網絡模擬信息的嵌入.tanh模擬器在式(1)原則下設計為
mij=-0.5 tanh(λ(pij-2×rij))+
0.5 tanh(λ(pij-2×(1-rij))).
(2)
UT-SCA-GAN與ASDL-GAN最大的不同是:用公式代替網絡模擬修改像素的過程,減少了ASDL-GAN中TES網絡預訓練的時間開銷;在判別網絡的設計中選擇通道,即考慮嵌入改變概率,使學習到的失真代價能夠抵御基于通道選擇的隱寫分析檢測;以U-Net這種緊湊網絡結構作為生成網絡,在捕捉圖像細節信息、低頻信息方面具有較好的性能.因此,在學習圖像像素的修改概率時有更好的表現,進一步提升了網絡隱寫的隱蔽性,圖7為該網絡模型.
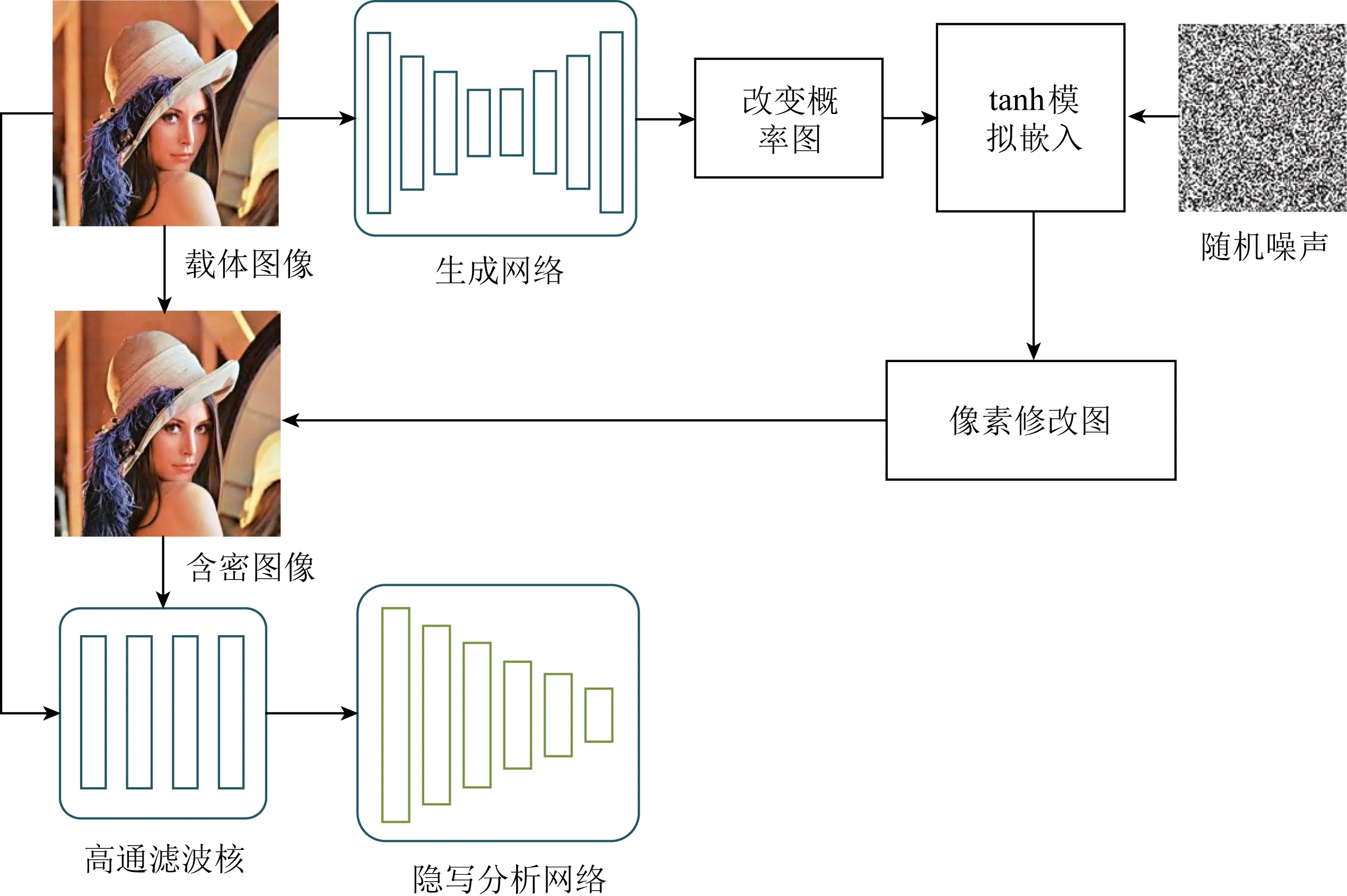
Fig. 7 The architecture of UT-SCA-GAN framework[32]圖7 UT-SCA-GAN網絡結構[32]
在使用相同數據集(BOSSbase)訓練的情況下,將UT-SCA-GAN與S-UNIWARD,ASDL-GAN相比,對比結果如表4所示,包括了隱寫分析器檢測的錯誤率和訓練時間(以epoch=1為例).可以發現,無論是0.1 bpp還是0.4 bpp的嵌入量,UT-SCA-GAN的安全性比ASDL-GAN更高,甚至超過了S-UNIWARD的安全性,這得益于UT-SCA-GAN的網絡結構,生成網絡捕獲更細節的圖像信息,在判別網絡的設計中考慮通道選擇,因此利用網絡學習的嵌入改變概率值得到的含密圖像更能抵抗統計檢測.除此之外,由于設計了tanh函數,模型的計算效率得到了提高.表4中數據來源于文獻[32-33].
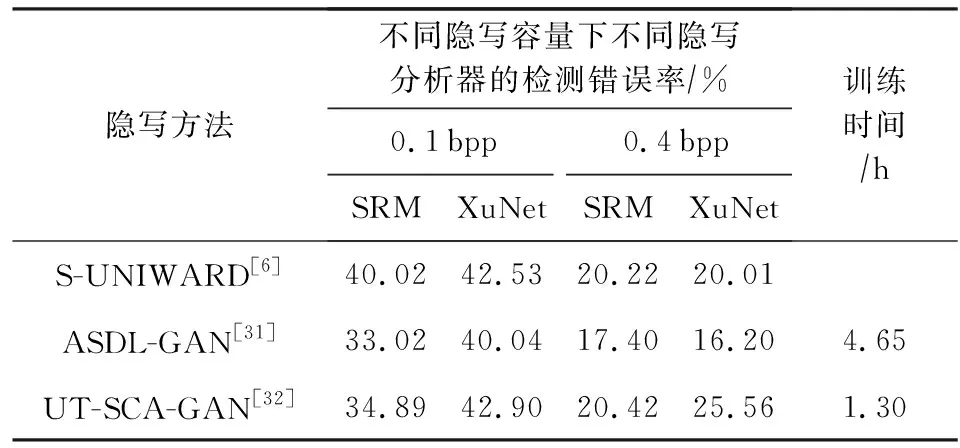
Table 4 Security Performance Comparison of AutomaticSteganographic Distortion Learning Methods Using GAN[32-33]
2.2 基于對抗樣本的隱寫失真修改方法
2018年Tang等人[36]利用對抗樣本來調整隱寫失真代價,提出了ADV-EMB(adversarial embedding)模型.該方法的訓練目標是選擇合適的像素修改方向,在信息嵌入的同時得到具有對抗樣本性質的含密圖像,使隱寫分析器將該含密圖像誤判為載體圖像.首先,輸入原始載體圖像,此時判別的標簽為載體圖像,計算反向傳播過程中每個像素點對應的梯度值,得到1張梯度圖.然后,給定1個已知的失真函數,計算圖像的隱寫失真,每個像素點都有對應的失真代價.最后,根據梯度圖和失真圖,以及對抗樣本的計算規則,更新每個像素的失真代價.若像素修改方向與梯度的反方向相同,則減小該方向的失真代價,若像素修改方向與梯度的反方向不一致,則增大該方向的失真代價:
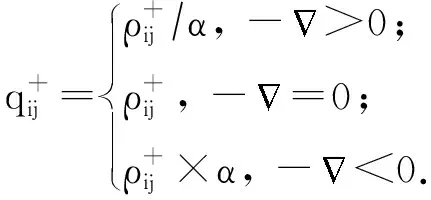
(3)
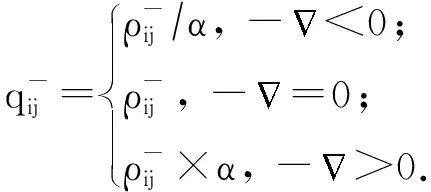
(4)

根據調整后的隱寫失真代價,采用傳統的自適應隱寫框架實現秘密信息的嵌入,這種對抗嵌入的方法很大程度上提高了隱寫的安全性.根據自適應隱寫失真找到嵌入的位置,接著利用對抗樣本的生成方法,更新這些像素的失真代價,在沒有額外修改像素的情況下,使含密圖像具有對抗樣本的特性,從2個方面增強了抗隱寫分析檢測的能力.
使用BOSSbase數據集訓練,針對于空域和JPEG域,該方法與S-UNIWARD,J-UNIWARD(jpeg universal wavelet relative distortion)在隱寫分析器檢測錯誤率方面的對比如表5,6所示.表5,6中的數據表示隱寫分析器(XuNet)的檢測錯誤率.可以發現,ADV-EMB方法提高了隱寫分析的檢測錯誤率,圖像隱寫的隱蔽性更高.
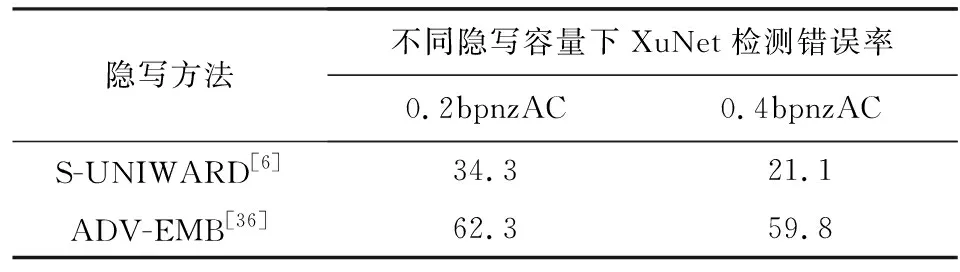
Table 5 Security Performance Comparison of ADV-EMB,S-UNIWARD Against Steganalysis[36]
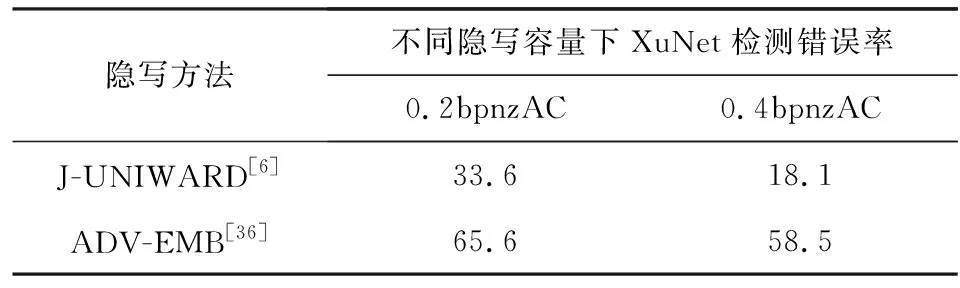
Table 6 Security Performance Comparison of ADV-EMB,J-UNIWARD Against Steganalysis[36]
傳統的自適應圖像隱寫方法在確定需要修改的像素點位置之后,并不會指定像素修改的方向.Tang等人[36]提出的方法在此基礎上,根據對抗樣本的梯度方向對像素修改的方向進行了建議,增大了其中1個方向上像素修改的概率,使其成為對抗樣本.該方法本身并不會對圖像造成過多的干擾,且該方法同時適用于空域和JPEG域的隱寫失真代價更新.但在對抗樣本的生成過程中,圖像像素的全局平衡遭到破壞,這會引起統計異常,也會出現對某種隱寫分析方法過度適應的情況,在未來的研究中這些問題都是需要解決的.
2.3 隱寫失真設計方法的對比與總結
2.1節和2.2節所述2類方法都從深度學習的角度對隱寫失真的計算有了新的定義,提高了隱寫分析的檢測錯誤率.深度學習在失真函數設計中的應用總結為表7,從安全容量、隱蔽性、魯棒性、圖像視覺質量、隱寫失真的設計是否考慮統計上的不可檢測性、欺騙隱寫分析器的方式、泛化性、隱寫適用的域、計算效率這9個方面進行總結.其中,在隱寫失真的設計是否考慮統計上的不可檢測性上,如果設計過程是基于先驗知識手工設計的,則沒有考慮統計上的不可檢測性;如果在設計過程中,加入了對圖像統計特征的衡量,則認為考慮了統計上的不可檢測性.
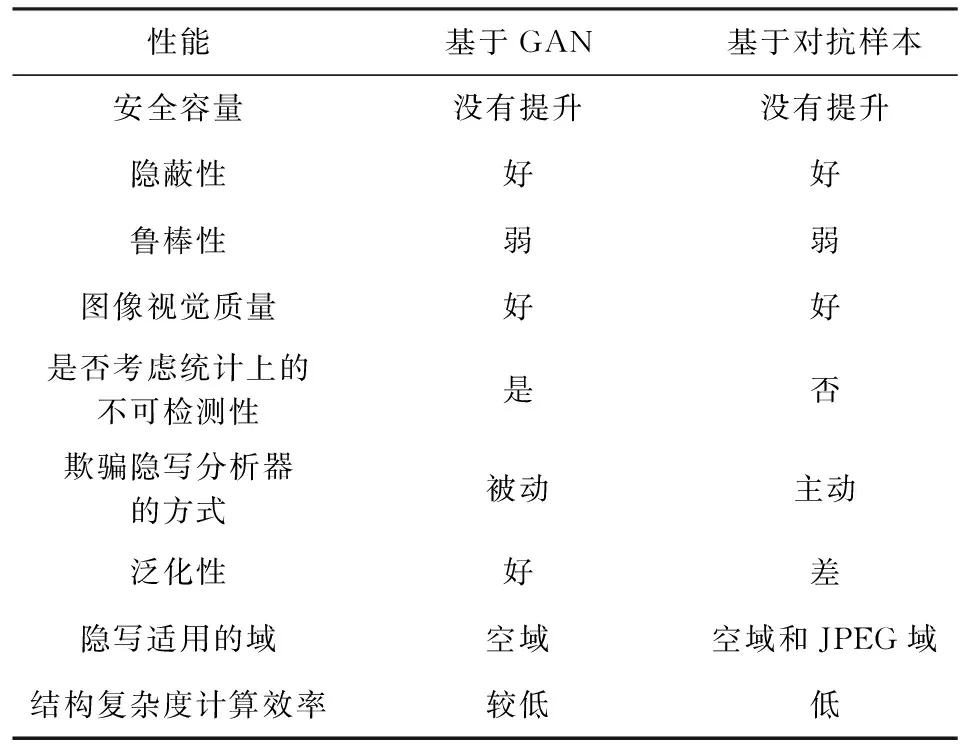
Table 7 Summary of the Application of Deep Learningin Distortion Designing
根據這9種評價指標,我們對上述2種隱寫方法進行分析:
1) 基于生成對抗網絡的方法拋棄了傳統的根據先驗知識設計失真的方法,在學習隱寫代價的過程中,根據隱寫分析器的檢測結果,對抗地調整每個像素的改變概率,在此基礎上使用傳統的隱寫方法實現秘密信息的嵌入.由于設計隱寫失真時考慮了統計的不可檢測性,因此隱蔽性更高,同時可以保證含密圖像與傳統內容自適應隱寫方法得到的含密圖像具有類似的視覺質量.但是隱寫安全性的提升以復雜的網絡結構和長時間的訓練過程為代價,網絡學習合理的像素改變概率花費了大量的時間.在訓練時,雖然只有單個隱寫分析器參與訓練,但是在傳統隱寫分析器檢測時仍然表現出較好的抵抗性,泛化性能好.在訓練的過程中,可以使用多種隱寫分析器集成的方法,進一步提高抵抗多種隱寫分析器的能力.除此之外,由于訓練的網絡較為龐大,在實際使用過程中會花費較長的時間,因此,可以使用該網絡的蒸餾模型或設計輕量級的網絡計算隱寫失真,提高效率.
2) 基于對抗樣本的隱寫失真修改方法適用于空域和JPEG域任何已有的自適應隱寫框架.根據傳統的方法計算得到像素失真,ADV-EMB就可以根據對抗樣本的梯度方向更新失真,使得含密圖像具有對抗樣本的性質,主動欺騙隱寫分析器,提升了隱寫的隱蔽性.由于生成對抗樣本的過程并沒有對圖像做額外擾動,圖像上不會出現對抗噪聲,因此不會對圖像視覺質量產生影響.與基于生成對抗網絡的隱寫失真設計方法類似,在訓練的過程中使用單個隱寫分析器,對抗樣本具有特異性,容易對某種隱寫分析器形成過度適應,模型的泛化性能差,可以在訓練時增加隱寫分析器的種類解決該問題.由于在實際的隱寫過程中需要對每張載體圖像的隱寫失真進行修改,因此計算效率低.另外,由于對抗樣本的生成過程破壞了像素修改的隨機性,因此含密圖像可能會引起圖像統計特性上的異常.
3 基于深度學習的含密圖像生成
在傳統的隱寫方法中,自適應隱寫將信息隱藏在圖像內容復雜的區域或邊緣區域,隱寫分析難以發現這些區域的異常.通過設計失真函數,為每個像素分配嵌入成本,減少信息嵌入引起的圖像失真;利用編碼方法減少信息嵌入時像素的改動,STC編碼可以做到在給定隱寫容量和像素嵌入成本的基礎上,用最少的改動逼近失真函數的最小值,這是傳統的隱寫中含密圖像生成最主要的方式.在深度學習中,編碼網絡的作用類似于傳統的編碼算法,可以直接實現文本與圖片、圖片與圖片的結合,因此將編碼網絡引入圖像隱寫,隱寫方與解密方可以在沒有圖像隱寫先驗知識的情況下完成信息的隱藏與提取,同時,該方法實現了更大容量的隱寫.本節從以圖藏文本、以圖藏圖2個方面分析基于深度學習的含密圖像生成方法,相比于其他圖像隱寫方法,隱寫內容更豐富,隱寫容量更大,該類隱寫方法基本的網絡模型框架如圖8所示:
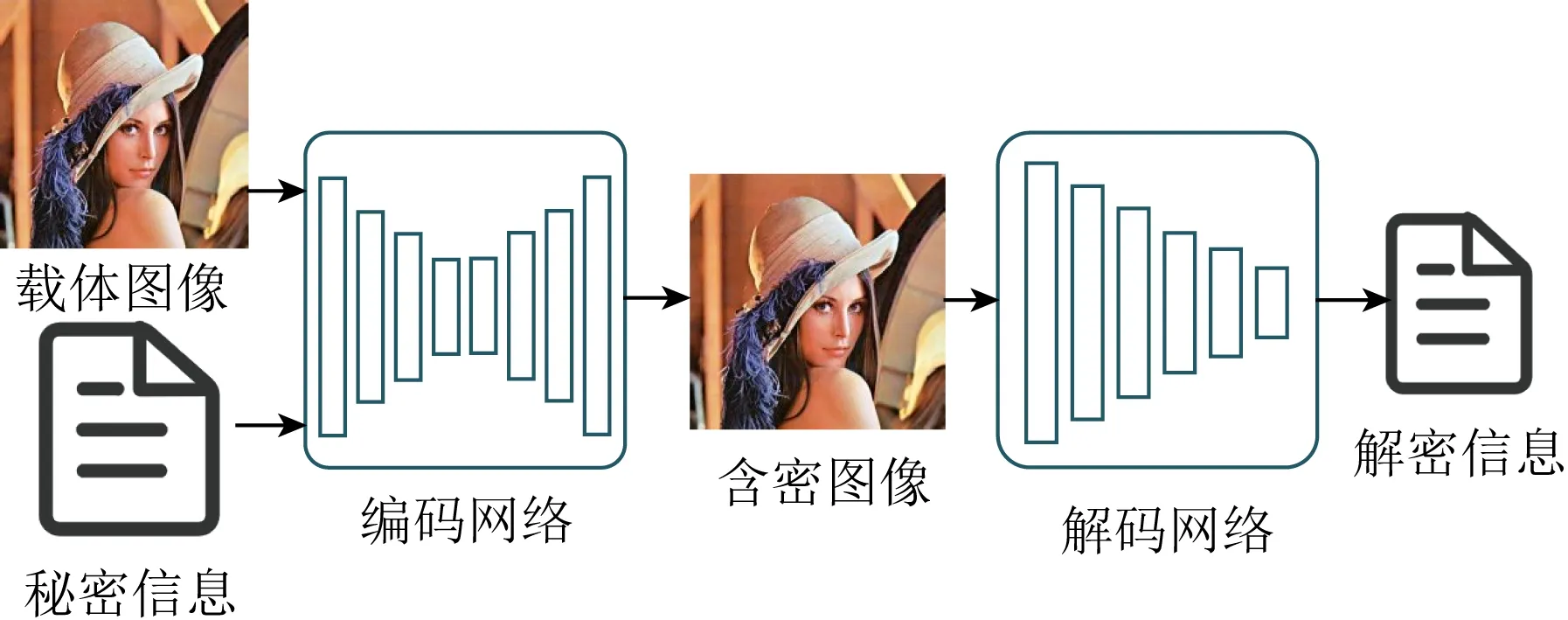
Fig. 8 The basic architecture of image steganographybased on encoder-decoder network圖8 基于編碼-解碼網絡的圖像隱寫基本框架
3.1 以圖藏文本含密圖像生成方法
2017年Hayes等人[37]提出了以圖藏文本的圖像隱寫框架HayesGAN,網絡結構如圖9所示,第1次用編碼網絡實現圖片隱藏秘密信息.秘密信息與載體圖像共同輸入給編碼網絡中,得到含密圖像;隱寫分析網絡,也相當于判別網絡,對生成的含密圖像和原始載體圖像做分析檢測;信息的接收方通過解碼網絡可以得到解密信息.損失函數:
L=α×LCC+β×LSS+γ×LG.
(5)
通過歐氏距離LCC,LSS衡量載體圖像與含密圖像、秘密信息與解密信息之間的損失,保證載體圖像與含密圖像的相似性、秘密信息與解密信息的一致性,通過編碼網絡與隱寫分析網絡的對抗損失LG保證圖像隱寫的隱蔽性.α,β,γ為權重參數.
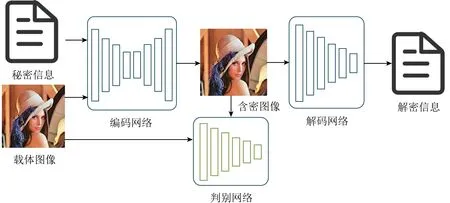
Fig. 9 The architecture of HayesGAN framework[37]圖9 HayesGAN網絡結構[37]
在該網絡結構中,秘密信息提取的準確率是衡量該類網絡性能的重要指標,神經網絡提取秘密信息不同于傳統的信息嵌入與提取,網絡的學習過程具有不可解釋性,信息提取的過程不完全可控,如何設計提取網絡的結構,控制訓練過程以提高秘密信息恢復的準確率是修改網絡結構的關鍵.在實際的圖像傳輸過程中,圖像往往會因為幾何攻擊或通信壓縮而受損,如果含密圖像在傳輸過程中受到了攻擊,則信息的準確提取會更加困難.因此如何保證生成的含密圖像有效抵抗隱寫分析檢測,同時保證秘密信息提取的準確率,是該類圖像隱寫方法面臨的重大挑戰.
為了增加隱寫的魯棒性,2018年Zhu等人[38]提出HiDDeN(hiding data with deep networks)圖像隱寫方式,在網絡訓練的過程中加入了噪聲層,模擬真實情景下含密圖像傳輸過程中所遇到的噪聲攻擊、壓縮等情況,將攻擊后的圖像放入解碼網絡中提取秘密信息.該網絡考慮到含密圖像的真實性、秘密信息提取的準確性、隱寫的隱蔽性,進一步增強了隱寫的魯棒性,為后續隱寫方法提升魯棒性提供了思路.
為進一步增大隱寫容量,2019年Zhang等人[39]提出了SteganoGAN(steganography with generative adversarial networks)隱寫模型,將判別網絡改為評分網絡,評價含密圖像的真實性,同時修改了生成網絡的網絡結構,最終實現了4.4 bpp的大容量圖像隱寫.與前2種網絡模型的隱寫容量對比如表8所示,該網絡還可以有效抵抗YeNet[40]的隱寫分析檢測.表8中數據來源于文獻[37-39].
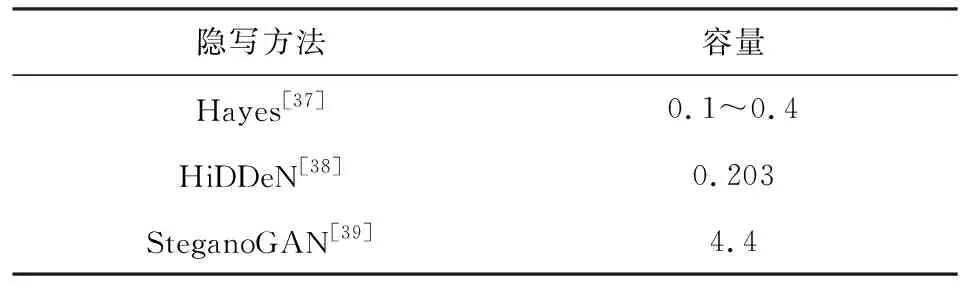
Table 8 Steganography Capacity Comparison of Stego Image Generation Methods for Hiding Text Within Images[37-39]
3.2 以圖藏圖含密圖像生成方法
2017年,Baluja[41]首次提出以圖藏圖的隱寫模型,實現了在彩色圖像中隱藏彩色圖像.所提出的網絡模型包括預處理網絡、編碼網絡和解碼網絡.預處理網絡將秘密圖像變換為載體圖像的大小,將基于色彩的像素轉化為利于編碼的特征;秘密圖像與載體圖像經過編碼網絡得到含密圖像,在視覺上與載體圖像沒有差異;解碼網絡將從含密圖像中提取秘密圖像,網絡結構如圖10所示.在訓練時,通過控制載體圖像與含密圖像的距離,保證二者的相似性,減少秘密圖像嵌入引起的圖像變化;通過控制秘密圖像與解密圖像的距離,保證圖像重構的準確性.
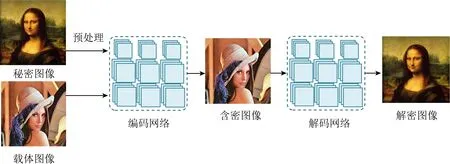
Fig. 10 The architecture of the hiding images within images proposed by Baluja[41]圖10 Baluja提出的以圖藏圖網絡結構[41]
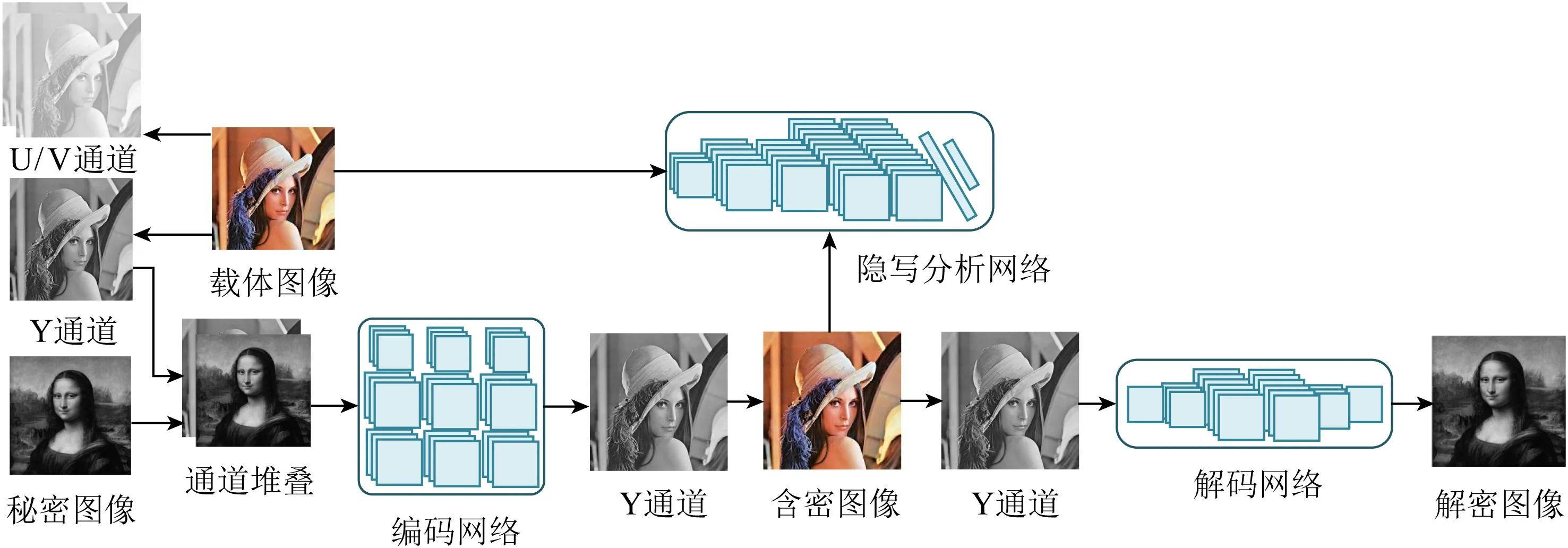
Fig. 11 The architecture of ISGAN framework[46]圖11 ISGAN模型[46]
Baluja[41]提出的網絡模型中,含密圖像與重構的秘密圖像視覺質量較差,圖像的平滑區域存在許多噪聲,會引起數據統計異常且容易被人眼察覺.為了解決上述問題,2018年Wu等人[42]提出了StegNet(steganography with deep convolutional network)的網絡模型,修改了損失函數,Duan等人[43]修改了編碼網絡的網絡結構,2種方法都有效改善了圖像的質量.Wu等人[42]通過設計新的損失函數,最小化加權損失,控制含密圖像中的噪聲,使這些噪聲均勻分布在圖像中,而不是集中在容易發現的平滑區域:
其中,載體圖像與含密圖像的L1范數LCC和方差損失Var(LCC)、秘密圖像與解密圖像的L1范數LSS和方差損失Var(LSS),保證載體與含密圖像、秘密與解密圖像在圖像高度、寬度等多方面的相似性,這使噪聲分布在圖像的整個區域內.
U-Net[44]作為編碼網絡的網絡結構,借助了U-Net網絡自身的優勢,上采樣與下采樣的網絡結構有連接操作,保存了圖像淺層與深層的特征,因此重構的解密圖像與原始秘密圖像具有較高的相似性,且圖像質量相較于Baluja的方法更佳.
除了彩圖藏彩圖,還有彩圖藏灰度圖的圖像隱寫方法[45-46],值得注意的是2019年Zhang等人[46]所提出的ISGAN(invisible steganography via generative adversarial networks)模型.將彩色載體圖像分解為3通道UVY,其中通道UV包含圖像的色度信號,Y通道包含圖像的亮度信號,利用人眼對亮度信息不敏感的特性,將代表秘密圖像的灰度圖像與載體圖像的Y通道進行通道堆疊,通過編碼網絡得到Y通道的含密圖像,與UV通道結合得到彩色的含密圖像.如果要提取秘密圖像,則先將含密圖像的Y通道剝離,然后通過解碼網絡得到秘密圖像,圖11為該網絡模型.通過這種方法,載體圖像除了亮度信息有所損害之外,保留了原圖的色彩信息,這增強了秘密圖像的隱蔽性.
以ImageNet[47]為數據集,對上述5種模型的隱寫效果進行總結,含密圖像與載體圖像的峰值信噪比、結構相似度、解密圖像與秘密圖像的峰值信噪比、結構相似度,結果如表9所示,表9中的數據來源于文獻[41-46].基于編碼-解碼網絡的以圖藏圖含密圖像生成方法在隱藏容量方面都有巨大的提升,但是在嵌入秘密信息后,圖像的PSNR值都有所下降,圖像質量有所影響,但秘密圖像的恢復度較高,且與原始秘密圖像保持較高的相似性.
根據表9可以看出,無論是彩圖藏彩圖還是彩圖藏灰圖,隱寫的容量都得到了大幅度提升.但該類圖像隱寫模型都面臨2個問題:1)嵌入秘密圖像后,圖像的視覺質量受到影響,可能引起隱寫分析者的注意;2)在傳輸過程中,由于信道壓縮等因素含密圖像一定會受損,導致秘密信息丟失,這會使秘密圖像的準確恢復面臨更大的困難.
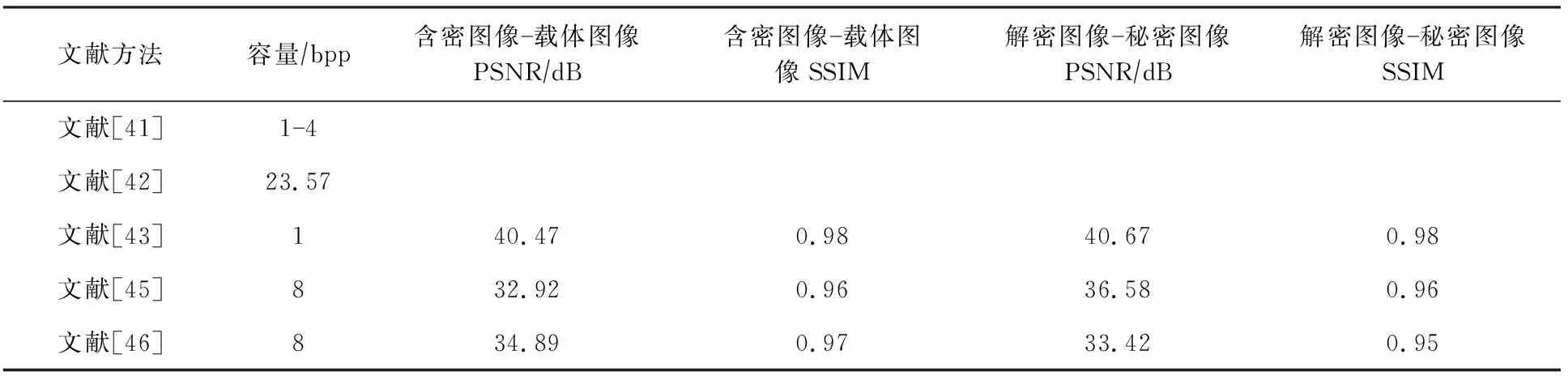
Table 9 Performance Comparison of Stego Image Generation Methods for Hiding Images Within Images[41-43,45-46]表9 以圖藏圖含密圖像生成方法的性能對比[41-43,45-46]
3.3 含密圖像生成方法的對比與總結
基于編碼-解碼網絡的圖像隱寫顛覆了傳統的圖像隱寫模型,不需要手工設計具體的嵌入方法,也不需要設計失真函數來衡量修改像素引起的失真,是圖像隱寫領域的創新.依靠網絡強大的學習能力,實現秘密信息與圖像的結合以及秘密信息的再次提取,大大降低了人為參與.將上述2種基于編碼-解碼網絡的含密圖像生成方法的主要特點總結至表10,從隱寫安全容量、隱蔽性、魯棒性、圖像視覺質量、是否需要先驗知識、計算效率、結構復雜度這7個方面進行總結.其中,是否需要先驗知識從隱寫者是否需要掌握隱寫知識的角度進行判斷.使用基于編碼-解碼網絡圖像隱寫方法的隱寫者可以沒有任何圖像隱寫的先驗知識,擁有編碼網絡與解碼網絡就可以實現秘密信息的嵌入與提取.

Table 10 Summary of Stego Image Generation Methods表10 含密圖像生成方法總結
以圖藏文本的含密圖像生成方法將隱寫的安全容量從0.4 bpp提升至4.4 bpp,與傳統內容自適應的隱寫方法相比,相同隱寫分析檢測率下隱寫容量更高,相對地,隱寫的隱蔽性更高.以圖藏圖的含密圖像生成方法將秘密圖像作為秘密信息嵌入載體圖像中,大大提升了隱寫的容量,同時保持了與傳統隱寫方法相近的隱蔽性.但與傳統隱寫方法相比,構建的信息嵌入與提取網絡較為復雜,構建合適的網絡也占用了一定的時間開銷,為了提高秘密信息的恢復準確率和圖像的視覺質量,網絡訓練的時間一般較長,隱寫方法整體的效率較低.這2種基于編碼-解碼網絡的含密圖像生成方法存在2個共同的問題:1)在藏入信息之后,圖像的亮度、色調等都會發生較大的變化,影響視覺質量;2)由于信息的嵌入與提取都依靠網絡,過程不可逆,秘密信息提取的準確率難以保證,損失使信息的準確提取更加困難,隱寫方法的魯棒性弱.對于第1個問題,可以調整網絡的損失函數,加入圖像質量評價指標,使信息與圖像編碼后仍保持良好的圖像質量;對于第2個問題,文獻[38]給出了很好的解決方案,在秘密信息提取之前添加噪聲層,模擬圖像傳播過程中信息受損的情況,以此提升含密圖像的魯棒性,提高信息恢復的準確率.
4 無載體圖像隱寫方法
無論是基于深度學習的載體圖像獲取、隱寫失真設計、含密圖像生成都借助網絡強大的學習能力實現了圖像隱寫,進一步減少了隱寫過程中的人為參與.但由于在信息嵌入的過程中都修改了載體圖像,圖像的視覺質量或統計特性不可避免地受到了影響,使隱寫分析器有跡可循.無載體圖像隱寫針對載體修改隱寫定義了一種新型的隱寫模式,由于不存在對圖像修改的過程,具有天然的抗隱寫分析能力.無載體圖像隱寫并不是完全不需要載體,而是根據秘密消息選擇載體或者生成載體,在圖像隱寫的過程中,沒有像素修改的操作.可以將現有的無載體隱寫分成2類[49]:基于載體選擇的無載體圖像隱寫、基于載體合成的無載體圖像隱寫,后者根據載體合成方法的不同又可以分成:基于圖像基元合成載體的無載體圖像隱寫和基于生成對抗網絡合成載體的無載體圖像隱寫.無載體圖像隱寫在與深度學習技術結合之后有了更廣闊的發展前景.
4.1 基于載體選擇的無載體圖像隱寫方法
基于載體選擇的無載體隱寫方法通過構建信息與圖像之間的映射關系,傳遞秘密信息前根據映射關系在圖像庫中進行搜索,傳遞1張或多張圖片,信息接收方根據相同的映射表還原秘密信息.2016年周志立等人[50]提出了一種基于圖像詞袋模型(bag-of-words, BOW)[51]的無載體圖像隱寫方法,圖12為提出的隱寫框架圖.創建圖像庫,使用BOW模型提取圖像中的視覺關鍵詞,并構建詞匯的單詞表,然后構建字典中的詞和國標一、二級字庫中的字與視覺關鍵詞的映射關系,在進行秘密通信時,根據映射表找出與傳遞字段對應的視覺關鍵詞,從圖像庫中挑選含有該視覺關鍵詞的圖,將這些圖作為含密圖像進行傳遞.實驗表明,該方法可以有效實現無載體圖像隱寫,并且可以較好地抵抗現有隱寫分析算法的檢測.但是從隱寫容量角度分析,該方法的隱寫容量遠遠小于傳統的隱寫方法,由于映射關系是該方法中傳遞秘密信息的關鍵,因此擴大隱寫容量的方式較為局限,不能有效實現較大容量的信息隱藏.
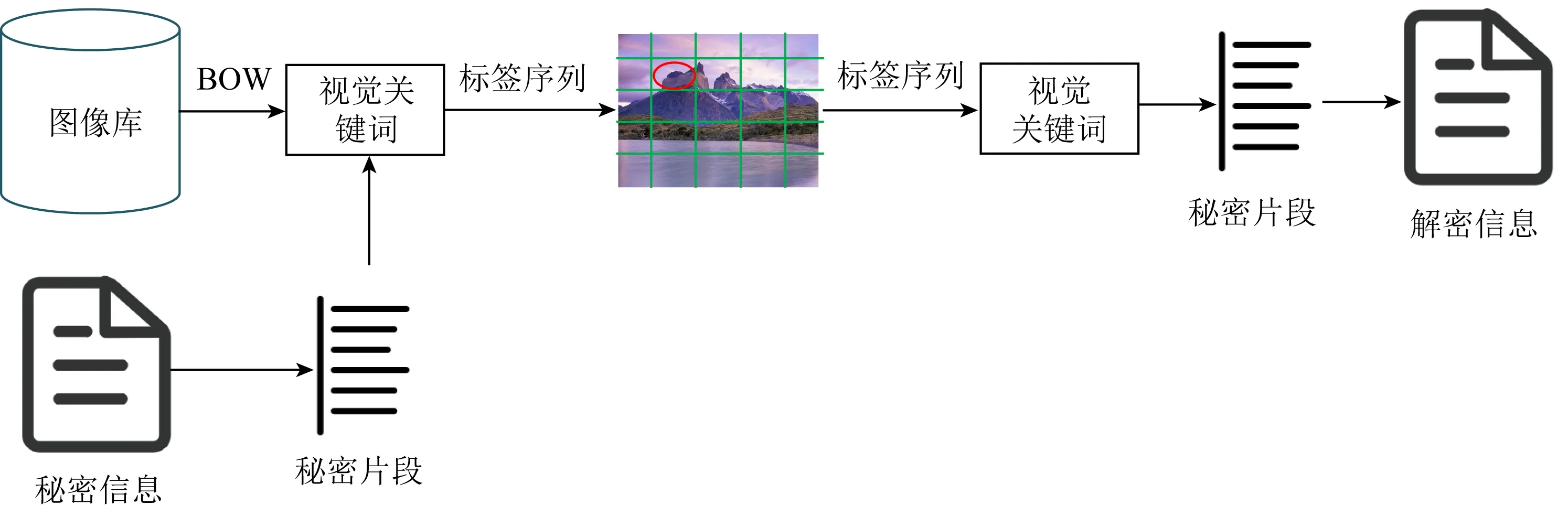
Fig. 12 The architecture of coverless image steganography based on bag-of-words of image[50]圖12 基于圖像bag-of-words模型的隱寫框架圖[50]
文獻[52-54]在1張圖像中的多個子圖像中隱藏秘密信息.文獻[52]提出基于魯棒圖像散列的無載體圖像隱寫,分別計算9個子圖中的尺度不變特征變換點(scale-invariant feature transform, SIFT),選取每個子圖中特征點出現最多的方向與長度為2的比特串形成映射.SIFT特征點滿足空間內位置、尺度、旋轉的不變性,因此保證了秘密信息再次提取的準確性,且可以有效抵抗隱寫分析的檢測,唯一的不足是隱寫容量較小,1張圖只能傳遞18 b信息.
2018年Cao等人[53]對該方法做出了改進,將0~255的像素取值劃分為16個區間,與長度為4的比特串構建映射關系.將圖片分為9個子圖,計算每個子圖的平均像素值,對照映射表,得到秘密消息.因此,1張圖片的隱寫容量為36 b,此方法的隱寫容量是文獻[52]中容量的2倍,同時也具有魯棒性且能抵抗隱寫分析的檢測.
4.2 基于圖像基元合成載體的無載體圖像隱寫方法
2009年Otori等人[55]最早提出在紋理合成過程中嵌入秘密信息的方法.在小紋理圖像中選擇若干像素點,通過局部二值模式(local binary patterns, LBP)構建像素點與二進制數據的映射關系,該方法屬于基于像素的紋理合成方法,雖然隱寫的安全性有所提高,但是隱寫容量小、提取誤碼率較高.2015年Wu等人[56]提出基于塊的紋理合成方法,提高了隱寫容量.但是Zhou等人[57]在文中指出該方法存在安全漏洞,可以根據含密圖像中塊與塊之間的關系重建源紋理圖案,進而模擬含密圖像的生成過程,恢復出秘密信息.
Xu等人[58]模仿計算機生成真實紋理的過程,將秘密文字或者圖案繪制在白紙上,通過一系列可逆的變形公式,使含密圖像旋轉、平移,最終達到真實紋理的效果,如果要恢復秘密消息,只需要依次進行公式的逆變換操作即可.該方法只適用于具有含義的圖案、文字等,并不適用于二進制數.2016年潘琳等人[59]又對此方法進行了改進,構建形狀、顏色等圖形特征與二進制數之間的映射關系,在白紙上繪制形狀和顏色,接著使用可逆變形公式得到紋理圖像,為二進制數據也量身定制了秘密通信的方式,同時該方法達到了較高的隱寫容量.
2019年Li等人[60]提出了基于指紋構造的信息隱藏方法,指紋構造包含2個階段:螺旋相位合成與連續相位合成,該方法在合成螺旋相位時將秘密信息映射在指紋的細節信息中,具體表現為指紋的脊尾和分叉,基于指紋構造的隱寫框架如圖13所示.合成的指紋圖像魯棒性高、隱蔽性好,但是指紋圖像只能傳遞短小的信息,如加密解密密鑰,不能滿足較大的隱寫容量.
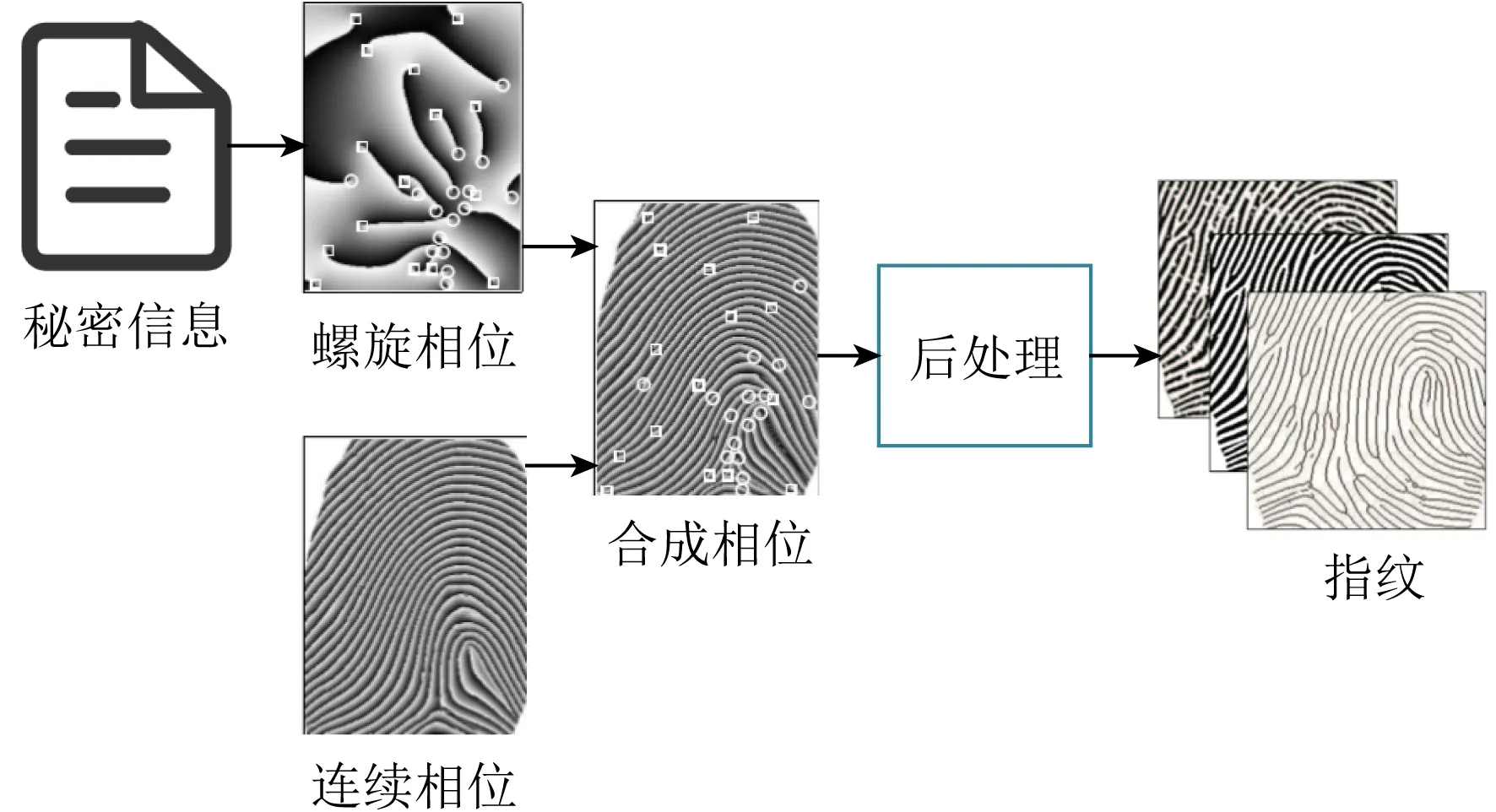
Fig. 13 Architecture of coverless image steganographybased on fingerprint construction[60]圖13 基于指紋構造的無載體圖像隱寫框架[60]
與傳統隱寫方式相比,基于圖像基元合成載體的無載體圖像隱寫方法隱藏容量較小,雖然提高了隱蔽性,可以有效抵抗隱寫分析的檢測,但是每次傳遞的信息容量較小,如果傳遞的信息較多,需要生成多張含密圖像,這增加了被隱寫分析者檢測的風險.
4.3 基于GAN合成載體的無載體圖像隱寫方法
由于GAN具有強大的圖像生成能力,研究者們開始研究基于GAN的無載體圖像隱寫.利用生成對抗網絡模型本身的特點,將秘密信息的映射融入圖像生成的某個步驟中,如圖像標簽的設定、輸入噪聲的獲取,一旦圖像生成,即可將圖像作為含密圖像進行傳遞.在這個過程中,只存在圖像是否真實的問題,不存在圖像是否含密的判斷問題,巧妙地抵抗了隱寫分析的檢測.
2018年Hu等人[61]提出了一種基于深度卷積生成對抗網絡(deep convolutional generative adversarial networks, DCGAN)[62]的無載體圖像隱寫方法,將秘密信息映射為噪聲向量,用DCGAN和卷積神經網絡(convolutional neural network, CNN)訓練生成網絡和提取網絡,生成無異于真實圖像的含密圖像.和現有的基于圖像基元合成載體的無載體圖像隱寫方法相比,隱寫容量得到了很大的提升,圖14為該隱寫模型.但是在該方法中,盡管噪聲向量由秘密信息映射而來,其本質仍然是隨機無規律的,網絡難以穩定地恢復噪聲向量,因此秘密信息不能準確重構.
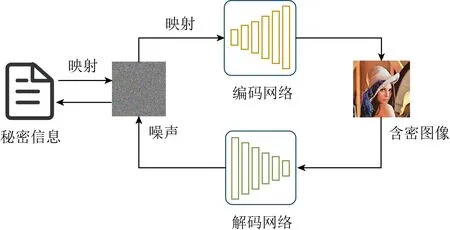
Fig. 14 Architecture of coverless image steganographybased on DCGAN[61]圖14 基于DCGAN的無載體圖像隱寫框架[61]

Fig. 15 Architecture of coverless image steganography based on O-GAN[63]圖15 基于正交GAN的無載體圖像隱寫框架[63]
2019年朱翌明等人[63]在此基礎上提出基于正交生成對抗網絡(orthogonal generative adversarial networks, O-GAN)[64]的無載體圖像隱寫方法,在目標函數中加入約束條件,使得模型訓練更加穩定,秘密信息的提取更加穩定.圖15為所提出的基于O-GAN的無載體圖像隱寫框架,按文獻[61]中的映射規則將秘密消息映射為-1~1之間的噪聲,輸入生成網絡中得到含密圖像,將含密圖像輸入提取網絡,提取特征碼向量,根據約束條件,該向量與輸入噪聲有較強的相關性,最后經過U-Net[44]將特征碼轉化為噪聲,根據映射關系實現秘密消息再次提取.基于O-GAN的圖像隱寫方法對Hu等人[61]提出的方法做了有效的優化,對含密圖像的特征添加約束,建立了噪聲向量與特征之間的內在聯系,使網絡模型訓練更加穩定,提高了秘密信息提取的穩定性.
文獻[61,63]都建立了噪聲與秘密信息的映射關系,除此之外還要建立圖像標簽與秘密信息的映射.文獻[65]提出了一種基于輔助分類生成對抗網絡(auxiliary classifier generative adversarial networks, ACGAN)[66]的無載體圖像隱寫方法,建立秘密信息與圖像類別標簽的映射關系.類別標簽和噪聲作為ACGAN網絡的輸入部分,生成含密圖像,提取秘密信息時,通過ACGAN的判別網絡提取圖像的類別標簽,根據映射關系實現秘密信息的恢復.但是由于類別標簽數量有限,該方法的隱藏容量仍然較低.
4.4 無載體圖像隱寫方法的對比與總結
將無載體圖像隱寫方法在隱寫容量、隱蔽性、秘密恢復準確率的對比總結至表11.無載體圖像隱寫沒有像素痕跡,隱寫的隱蔽性強,且可以抵抗隱寫分析的檢測,大部分無載體圖像隱寫方法信息恢復的準確率高.主要缺點是隱寫容量特別低,難以與傳統的圖像隱寫容量或基于深度學習的圖像隱寫容量相比較,無論是載體選擇、圖像基元合成還是基于生成對抗網絡的無載體隱寫,隱寫容量最多只能達到10-3數量級,表11中列出了每種無載體隱寫方法的隱寫容量.因此,傳遞的信息有限,如果要傳遞大容量的信息,需要傳遞較多的圖片,這會降低隱寫的安全性.由此看來,在無載體圖像隱寫中,尚未出現可行的方法能夠在隱寫容量上實現突破性進展,即使是基于生成對抗網絡合成載體的方法也難以在隱寫容量和信息提取準確率二者上同時取得良好的性能.總體而言,隱寫的隱蔽性好,信息恢復的準確率較高,但是隱寫容量較低,難以達到基于修改的圖像隱寫的容量.
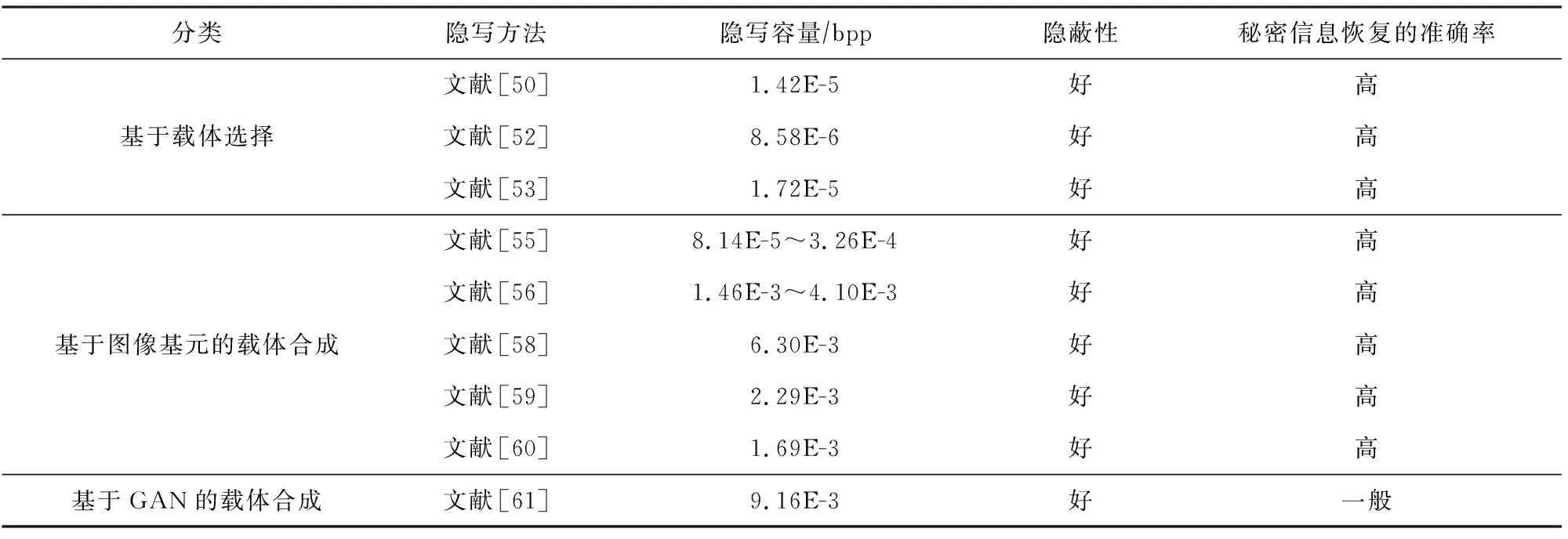
Table 11 Comparison and Summary of Coverless Image Steganography Methods[50-61]表11 無載體圖像隱寫方法對比與總結[50-61]
5 總 結
本文從基于深度學習的圖像隱寫和無載體圖像隱寫2個方面對近期的圖像隱寫方法進行了分析與總結.基于深度學習的圖像隱寫方法大部分都應用了生成對抗網絡中對抗博弈的思想,在隱寫與隱寫分析對抗的過程中提高隱寫隱蔽性.除了對抗博弈,另一類隱寫方法借鑒了對抗樣本的思想,使含密圖像具有對抗樣本的性質,在圖像上添加微小的擾動達到使隱寫分析器誤分類的目的.事實表明:基于深度學習的圖像隱寫技術在不斷取得突破,并且仍有較大的發展空間.區別于通過修改載體實現信息隱藏的圖像隱寫方法,無載體圖像隱寫通過載體選擇、載體合成等方式實現信息隱藏,該類方法最大的特點是隱寫隱蔽性高,但隱寫容量低.本文從4個方面對基于深度學習的圖像隱寫和無載體圖像隱寫進行總結,并將不同類型隱寫方法的優缺點歸納如表12所示.
1) 基于深度學習的載體圖像獲取.載體圖像的獲取可以分為利用生成對抗網絡生成適合嵌入的載體圖像和利用生成對抗樣本的方法增強載體圖像,在獲得載體圖像之后,使用傳統的圖像隱寫方法進行信息隱藏.由于生成圖像的質量不佳,基于生成對抗網絡生成載體圖像的隱寫方法不能有效抵抗隱寫分析的檢測,該類方法提出的意義在于將深度學習引入圖像隱寫領域,為圖像隱寫方法開拓了新的研究方向.基于對抗樣本增強載體圖像的隱寫方法,使含密圖像具有對抗樣本的性能,可以主動欺騙隱寫分析器.雖然隱寫的安全性得到了一定的提升,但圖像的視覺質量會隨著對抗樣本性能的提升而下降,且可能對參與訓練的某種隱寫分析器具有較強的抵抗作用,產生過度適應的效果.
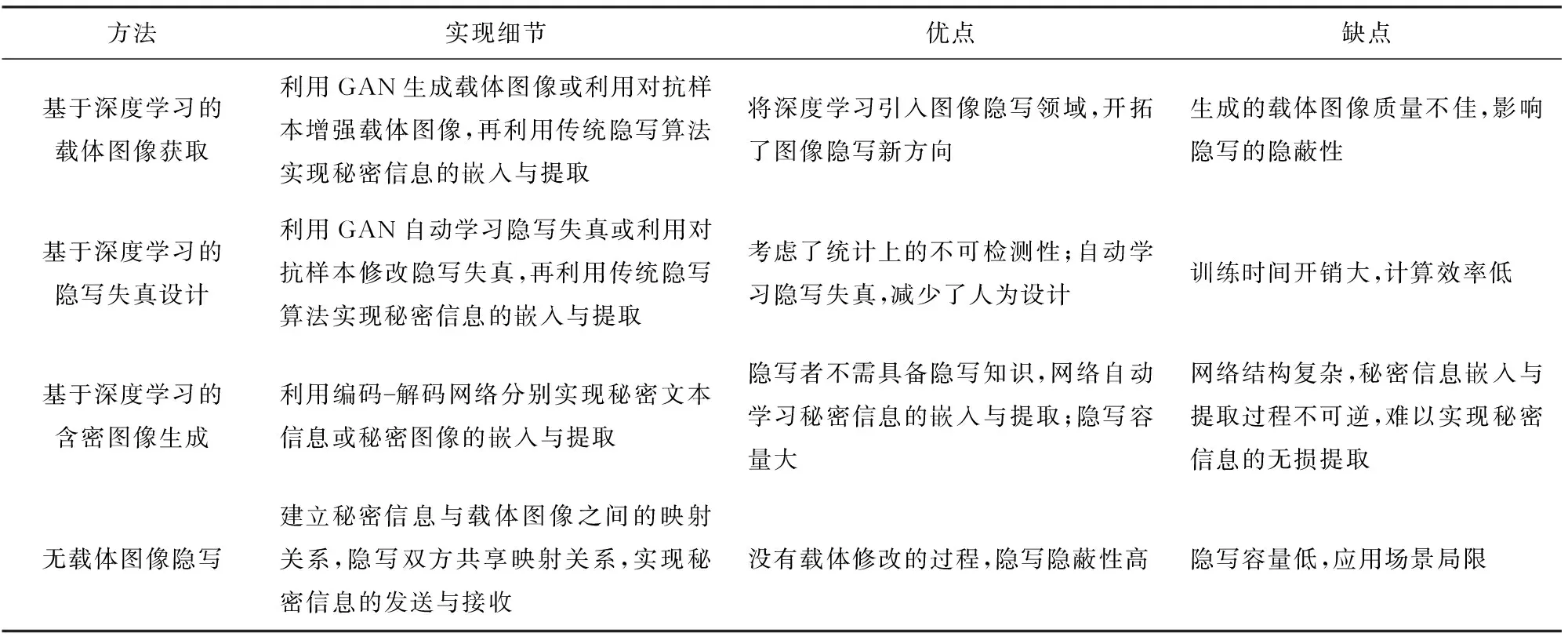
Table 12 Comparison and Summary of Different Types of Image Steganography Methods表12 不同類型隱寫方法的比較與總結
2) 基于深度學習的隱寫失真設計.使用傳統的最小失真隱寫框架,但隱寫失真的設計由網絡自主學習.基于生成對抗網絡的隱寫失真設計方法相較于傳統的失真函數設計已經逐漸展現出優勢,改變了根據先驗知識設計隱寫失真的方法,根據統計上的不可檢測性,在生成網絡與隱寫分析器的對抗博弈中,得到每個像素的嵌入改變概率,主要的缺點在于網絡訓練時間開銷較大.基于對抗樣本的隱寫失真代價設計方法,巧妙地將對抗樣本引入到傳統的失真設計中,可以應用于空域與JPEG域任意的失真函數設計中.
3) 基于深度學習的含密圖像生成.摒棄了傳統的隱寫框架,由神經網絡直接生成含密圖像.可以認為該類方法取代了傳統的編碼方式,通過神經網絡中的編碼-解碼網絡實現信息的嵌入與提取,該類方法可以實現大容量的圖像隱寫.但在這類圖像隱寫中,隱寫的隱蔽性常常受圖像質量影響,尤其在以圖藏圖的含密圖像生成方法中,在載體圖像中隱藏秘密圖像的過程會使圖像亮度、色調等多方面出現異常變化,容易被人眼檢測.另一方面,含密圖像在傳輸過程中會受到信道壓縮和噪聲攻擊,秘密信息的準確提取成為一大挑戰.
可以發現,在基于深度學習的圖像隱寫中,圖像質量與隱寫隱蔽性密切相關,直接影響圖像抗隱寫分析檢測的能力.在對抗樣本應用于圖像隱寫的方法中,除了要考慮圖像質量,還需要考慮該方法生成的含密圖像是否可以抵抗多類隱寫分析和經過對抗樣本訓練的隱寫分析器的檢測.
4) 無載體圖像隱寫.通過載體選擇和載體合成的方法實現信息隱藏,對隱寫分析具有較強的抵抗能力.存在的最主要的問題是隱寫容量遠遠低于基于圖像修改的隱寫方法的容量.基于生成對抗網絡的無載體圖像隱寫除了需要提高隱寫容量之外,還需要提高信息提取的準確率.
6 未來展望
深度學習的發展為圖像隱寫領域帶來了巨大變革,同時也使之面臨更多技術上的挑戰:1)無論是基于生成對抗網絡還是基于對抗樣本,生成的含密圖像往往會因為視覺質量不佳而引起隱寫分析者的注意,甚至難以抵抗人眼檢測,圖像質量與隱寫隱蔽性已經產生了密不可分的關聯性;2)對抗樣本已經展現出抵抗基于深度學習的隱寫分析器的優勢,但是面對多種類型的隱寫分析器和受過對抗樣本訓練的隱寫分析器,對抗樣本的泛化性還有待提高,需要讓含密圖像在不損失圖像視覺質量的同時對多種隱寫分析器具有主動欺騙和抵抗分析的能力;3)在利用神經網絡提取秘密信息的隱寫模型中,需要考慮含密圖像的魯棒性,因為在圖像傳輸過程中,難免會受到噪聲攻擊與信道壓縮,在這種情況下,保證信息恢復的準確率是魯棒隱寫的一大難題.針對這3個挑戰,本文對圖像隱寫的發展前景做出4個方面的展望:
1) 生成高視覺質量的含密圖像.在網絡訓練的過程中,應用人類視覺模型對含密圖像的視覺質量進行評估與約束,從提高含密圖像視覺質量的角度增強隱寫的隱蔽性.在具有對抗樣本性質的含密圖像生成過程中,使用迭代攻擊等方法減少對原圖的擾動.由于基于對抗樣本的隱寫失真設計方法在生成對抗樣本時對圖像的修改相對較小,且能達到主動欺騙隱寫分析的目的,因此,這種類型的高視覺質量含密圖像的生成方法值得繼續研究與學習.在對含密圖像進行隱寫分析的過程中,結合圖像取證的方法評估含密圖像,在保證圖像視覺質量的同時減少圖像修改的痕跡,增強圖像隱寫的隱蔽性.
2) 生成強泛化性的對抗式含密圖像.為避免出現對某種隱寫分析器產生過度適應的情況,在訓練與測試的過程中,使用多種隱寫分析器對含密圖像進行分析,另外可以使用經過對抗樣本數據訓練的隱寫分析器對對抗式含密圖像進行判別,以此增強含密圖像主動欺騙多種隱寫分析器的能力.
3) 提出高魯棒性隱寫網絡.在圖像傳輸的過程中,信道壓縮、噪聲攻擊無可避免,為了提高隱寫的魯棒性和信息恢復的準確性,在網絡訓練時加入約束條件,建立秘密圖像、含密圖像與重構圖像之間的相關性.除此之外,在訓練時通過加入噪聲層對含密圖像進行噪聲攻擊,使解碼網絡根據約束條件和對抗訓練提高信息恢復的準確率,增強圖像隱寫的魯棒性.
4) 設計輕量級隱寫網絡.隨著隱寫網絡深度和復雜度的不斷增加,網絡訓練的時間消耗在不斷增加,為了提高網絡使用的靈活性,在實際隱寫的過程中,使用網絡的蒸餾模型代替原模型,簡化網絡層數和網絡參數,提高隱寫的效率.
綜上,深度學習為圖像隱寫方法提供了新的隱寫理念與技術,但在提高隱寫的隱蔽性、魯棒性、安全容量、計算效率等方面仍然存在很多問題亟待解決,努力開展基于深度學習的圖像隱寫研究對網絡空間中信息的安全傳輸具有重要意義.
猜你喜歡
兒童故事畫報(2019年5期)2019-05-26 14:26:14
中華手工(2017年2期)2017-06-06 23:00:31
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
祝您健康(1987年2期)1987-12-30 09:52:28
