集中式集群資源調度框架的可擴展性優化
2021-04-01 01:18:22毛安琪湯小春李戰懷
計算機研究與發展 2021年3期
毛安琪 湯小春 丁 朝 李戰懷
(西北工業大學計算機學院 西安 710129) (工信部大數據存儲與管理重點實驗室(西北工業大學) 西安 710129)
(maoanqi@mail.nwpu.edu.cn)
隨著大數據處理技術的發展,數據內在價值的分析與挖掘成為這個時代的研究熱點之一.當數據的體量以驚人的速度增長時,單臺機器已經無法滿足大數據的存儲與處理,于是以Hadoop分布式文件系統(Hadoop distributed file system, HDFS)為代表的分布式文件系統應運而生.它以主從架構管理模式,將數據劃分到多臺機器節點上存儲,形成一個集群系統,也稱數據中心,推動了大數據計算的發展.在企業或組織內,數據中心上通常會存在各種不同類型的數據處理應用程序.如果為每種數據處理應用程序建立專用的集群基礎設施,不但為企業帶來巨大的建設成本,也導致數據在各個集群之間來回復制,容易產生錯誤.因此,越來越多的企業開始在數據中心上部署集群資源管理系統,確保各種各樣的數據處理應用程序共享一套硬件基礎設施.
集群資源管理系統的主要功能是管理集群的可用計算資源并分配給不同的數據處理應用程序.集群計算資源的分配要按照一定的策略進行,保證各個應用程序獨自使用集群的部分資源,避免各個數據處理應用程序之間的資源競爭和相互干涉,實現各個應用程序對資源的公平使用.
現有的集群資源管理系統種類非常豐富,如文獻[1-43]都是有關集群資源管理和用戶應用程序調度的系統.從集群資源調度框架的觀點看,集群資源管理系統分為3個大類,即集中式資源調度框架、分布式資源調度框架以及混合式資源調度框架.集中式資源調度框架又分為單一資源調度和二級資源調度模型,前者采用“拉”的模式,后者采用“推”的模式.文獻[1-25]研究單一資源調度模型,文獻[26-34]研究二級資源調度模型.文獻[35-40]研究分布式調度框架,文獻[41-43]研究集中分布混合的資源調度框架.文獻[22]是一種典型的單一資源調度模型,分3步完成資源的分配:應用程序向資源管理主節點請求計算資源;資源管理主節點負責資源的分配;應用程序提交任務執行.文獻[34]是一種二級調度模型,也分為3步完成資源的分配:應用程序按照次序向資源管理框架請求資源;資源管理器按照各個應用程序使用資源情況,依次為各個應用程序分配計算資源;應用程序使用資源執行任務.文獻[38]是分布式資源調度框架,分2步完成資源分配:各個應用程序獨立向請求發出“采樣請求”;根據采樣結果提交任務.文獻[42]是集中分布混合的資源調度框架,短時間的應用程序使用分布式調度框架,長時間應用程序采用集中式調度框架.
文獻[44]指出,集中式資源調度框架的優點是調度實現簡單,所以應用廣泛,但是集中式調度框架存在著可擴展的瓶頸.相比于集中式調度框架,分布式資源調度框架不存在單一的資源管理節點,所以在可擴展性方面具有較大的優點,但是分布式資源管理缺乏集中管理,增加了資源狀態的同步和并發控制的難度,也無法做到最優全局決策與資源控制,所以真正應用的系統較少.混合式資源管理框架結合了2個系統,由于存在集中式資源監視,雖然在一定程度上緩解了分布式調度的不一致問題,但是其集中式調度和分布式調度相互獨立,需要維護2套代碼,維護代價較大.另外,分布式調度和集中式調度相互預留資源,影響總體資源利用率,因此混合式資源管理框架處于研究狀態,很少有成熟的系統廣泛使用.
從以上的研究文獻看,80%以上的集群資源管理模型采用集中式,如果再加上混合式中的集中式調度模型,集中式資源調度框架可以達到85%左右.一些大的互聯網公司,例如微軟、騰訊、百度等,目前也使用集中式資源調度框架來處理自己的大數據業務.但是,集中式資源調度框架中,資源管理器為了獲得集群可用資源,需要集群上的每個計算節點周期性地發送健康狀態信息以及容器狀態信息到集中式調度器,以便監控整個集群計算節點的健康狀態以及整個集群節點上容器(任務)的運行情況.當計算節點的數量擴大到一定的規模后,大量心跳信息的存儲和處理給資源管理器帶來較大的負載壓力.另外,網絡延遲以及通信次數的快速增長使得集群資源管理中的調度器無法在調度許可的時間內處理全部的心跳信息,造成調度過程的失效.
隨著集群規模的增大,集中式資源管理器很快達到心跳信息處理上限,從而限制了集群節點規模的橫向擴展.所以,當集群節點的規模較大時,集中式集群資源管理通常采用增加心跳的時間間隔的方法來減少心跳發生的頻率,降低心跳信息的產生次數.但是心跳時間間隔的增大,會導致資源狀態的變化不能及時地匯報到調度器,一邊是資源的空閑,另一邊是用戶作業需要等待更長的時間才能被調度.文獻[45]在備用節點上開啟資源監控服務提高大規模心跳信息的處理效率,并借助分布式存儲服務(MySQL NDB)對心跳信息一致性進行保證.雖然文獻[45]的測試結論中,使用模擬器可以將YARN支持的機器數量從4 000臺擴展到7 500臺,但是其引入了C++版本的MySQL數據庫以及NDB事件流庫,使用JNI與YARN進行耦合,增加了代碼的維護代價,同時MySQL NDB需要增加多個資源監視節點,不但增加了硬件代價,也增加了數據一致性檢測代價.
集中式資源調度框架的易用性和可擴展性是一對矛盾.一面是大量用戶使用集中式資源管理系統,一面是集中式資源管理可擴展的困境.基于這兩方面原因,對集中式資源管理系統進行可擴展的優化研究有一定的迫切性,而且也實實在在地符合用戶的意愿.因此,本文對集中式資源管理系統的可擴展性進行了優化,改善了集中式資源管理系統的可擴展性.
論文的主要貢獻有3個方面:
1) 提出了基于差分模式的資源狀態監控模型,減少了心跳信息的大小和規模,減輕了資源調度器的存儲和處理壓力,使得調度器可以處理更多計算節點的消息;
2) 提出了基于環形監視的節點監控模型,將調度器的監控功能分散到各個計算節點,緩解了調度器的處理壓力;
3) 對YARN[22]系統的資源管理功能進行了優化,并使用YARN提供的模擬器進行了可擴展測試,實驗證明我們的方法可以使集群的規模提高1.88倍以上.
1 可擴展資源管理系統模型
本節首先針對集中式資源監控模塊的流程進行了分析,揭示了可擴展性問題.然后,提出基于差分模型的心跳信息處理流程,在計算節點上對心跳信息進行預處理.最后提出了基于環形監視的節點監控過程.
1.1 資源監控服務的性能瓶頸分析
集中式資源調度框架有3個主要的服務:1)應用程序管理服務,用戶的資源請求由應用程序管理服務提交到資源調度器,請求分配計算資源來運行任務;2)資源調度器,集群計算資源上運行著許多應用程序,而每個應用程序會包含大量的任務,這些任務會分散在不同的計算節點上并行運行,資源調度器的任務是將不同應用程序的任務映射到集群計算節點上并執行任務;3)資源監控服務,它是調度器與計算節點之間連接的紐帶,負責接收集群計算節點的加入和退出消息,同時周期性捕獲計算節點的心跳信息,即將各個集群節點的容器(任務)狀態信息進行匯總處理后通知調度器,更新集群資源的最新狀態.這些更新信息對資源調度器來說非常重要,它們是資源分配的依據.
當集群計算節點注冊到資源管理器后,便周期性向集群資源管理的資源監控服務匯報心跳消息.心跳信息包含2個重要的內容,即機器的健康狀態信息和集群節點上全部任務的運行狀態信息.健康狀態信息主要用于檢測資源的使用情況以及評價系統的性能等.計算節點的全部任務運行狀態信息用來維護資源管理器中的全局資源視圖.另外,任務狀態的變化決定了資源可用狀態的變化.因此,周期性的心跳信息使得資源管理器與計算節點之間保持聯系,并保證集群資源與任務狀態的一致性.
當心跳信息到達資源監控服務后,首先判斷計算節點的健康狀態.若該計算節點為非健康狀態,則通知調度器減少相關計算節點的可用資源配額,防止進一步將該機器的資源分配給其他計算任務.否則,資源監控服務就開始檢查該節點上任務運行狀態,通過與上次心跳信息的對比,提取出新啟動的任務與運行結束的任務相關信息.如果存在新啟動任務和結束任務,說明任務狀態有變化,資源監控服務產生一個更新事件通知給資源調度器,資源調度器將相關任務運行狀態進行更新維護,并對集群資源全局視圖進行更新.另外,對于已經結束的任務,將任務的結束狀態保存到日志中,這些信息是資源分配模塊進行系統優化時的參考依據.
在計算節點心跳匯報以及資源監控服務處理心跳這2個過程中,資源管理的資源監控服務要承受的通信量以及計算量將會給資源管理器帶來較重的負載壓力.隨著集群規模的增大,該問題將更加明顯.究其原因,有2個方面問題:1)當集群節點上無運行的任務,仍會周期性向資源監控服務發送心跳信息,以便記錄心跳更新時刻,作為新的心跳信息處理依據.這些信息僅能代表節點處于正常運行中,并沒有實質的數據傳輸.它不但增加了集群節點內部的通信開銷,也增加了資源監控服務的處理開銷.2)集群計算節點只是按心跳時間間隔,定期將本機所有容器以及任務狀態等相關信息匯報給集群資源監控服務.如果任務的運行時間較長,心跳間隔期間狀態沒有發生變化,無變化信息也會被匯報到資源監控服務,那么這將給資源監控服務增加額外的工作量,浪費計算資源.
綜上,當集群計算節點進行大規模擴展后,資源監控服務需要處理大量的無用心跳信息,導致負載過重,無法及時處理應用程序的資源分配請求,延遲了調度器的資源分配.而擴大心跳間隔雖然減少了單位時間內心跳信息的發送和處理,卻導致計算節點的有用狀態信息無法被及時更新,使得這些計算節點的資源處于閑置狀態.因此,減少計算節點與資源監控服務之間的通信次數,降低資源監控服務的數據處理強度,是集中式資源管理橫向擴展的主要策略.
1.2 基于差分的心跳信息處理模型
鑒于資源監控服務承擔著太多的心跳信息處理,本文提出一種策略,將心跳信息處理功能進行分解,一部分功能由計算節點承擔,一部分功能由資源監控服務承擔,即:讓計算節點承擔容器狀態的過濾功能以及健康狀態的檢測,資源監控服務只承擔容器狀態和健康狀態的更新,降低資源監控服務的負荷.圖1給出了基于差分的心跳信息處理模型,具體流程如下描述.
用戶應用程序向集中式資源管理器的客戶端管理服務進行注冊并提交應用程序,如圖1中的1.1.資源分配模塊為該計算框架分配第1個容器資源用于運行用戶應用程序,并通知計算節點的容器管理服務啟動該應用程序,如圖1中的1.2~1.4.
應用程序成功啟動后,向應用程序管理服務注冊并為其包含的任務申請資源,如圖1中的2.1.應用程序管理服務從資源分配模塊讀取資源的分配結果返回給應用程序,如圖1中的2.2.應用程序拿到資源后,將資源與任務映射匹配后,通知各計算節點容器管理服務,如圖1中的2.3.計算節點容器管理服務接收到啟動容器消息后,啟動容器并配置任務所需的運行環境,監控與管理任務的生命周期,如圖1中的2.4.心跳匯報程序首先從周期性健康檢測程序中讀取健康狀態進行保存,然后與上次所緩存的健康狀態進行對比,獲得健康狀態的差分值.另外,心跳匯報程序還需要讀取當前任務相關狀態信息時,并與上一次緩存的任務狀態進行對比,得到有任務狀態變化的差分值.如果差分值不為空,則向資源監控服務發送心跳信息,如圖1中的3.1;否則,省略本次心跳匯報過程.
資源監控服務收到心跳信息后,無需進行過濾處理,直接將本次接收的任務狀態信息更新,并通知資源分配模塊進行資源更新,如圖1中3.2.資源分配模塊收到通知后,對相關資源進行更新維護,并通過一定資源分配方法將可用資源分配給應用程序,等待應用程序資源請求并領取資源.
1.3 基于環形監視的節點監控模型
定時發送心跳信息是資源管理器判定計算節點正常運行的依據,如果長時間不發送心跳信息,資源管理器就可以認為節點出現故障,將該節點納入不可用計算節點列表中.基于差分的心跳信息處理模型中,任務狀態或健康狀態不發生變化就不產生心跳信息,這可能會導致資源管理器錯誤判斷計算節點的運行狀態.由于計算節點在不發生狀態變化的情況下取消心跳信息的發送,從而使得資源管理器無法辨別長期不發送心跳信息的節點是宕機還是計算節點無狀態變化.例如,在運行過程中某個計算節點宕機后,宕機節點就不能匯報任務的狀態導致應用程序無法得到任務的最新狀態,必須等待超過設定的超時范圍后,應用程序才會終止該任務并重新申請資源,進而影響相關作業的執行效率.
針對該問題,本文提出將所有的集群計算節點組成對等的環形監視網絡,處于環形網絡的每個計算節點都有一個前驅節點和后繼節點.當前計算節點向自己的后繼節點定時發送自己的心跳消息.對于后繼節點,發送消息的就是它的前驅節點.如果后繼節點在設置的時間間隔內沒有收到前驅節點的心跳消息,就認為前驅節點出現故障,立即向資源監控服務發送該節點宕機的信息描述,以便資源管理器做出相應的處理.當存在新的節點加入或者一個節點出現故障后,系統需要重組對等環形監控網絡,保證集群節點的正常運行,實現節點監控心跳信息的及時收集和發送.
針對對等環形監控網絡,資源管理器對集群中的計算節點分配一個唯一的機器編號,編號按照從小到大的順序產生.這些信息被各個計算節點維護,當新加入計算節點或者節點故障退出時,需要同步這些信息.節點的生存狀態發送過程按照節點的機器編號大小來進行,即編號為N的節點接收編號為N-1的節點的心跳消息(第1個節點接收最后一個節點的心跳消息).當節點N-1出現故障時,它既不能接收消息,也無法發送消息.當心跳周期到達期間,節點N未收到節點N-1的生存狀態匯報消息,則立即將節點N-1故障的消息通知資源管理器,資源管理器則將計算節點設置為不可用狀態,并通知各個集群節點更新緩存的機器編號信息.當新節點加入或者故障節點從失效狀態恢復正常,這些節點向資源管理器發送注冊消息,資源管理器從機器編號緩沖中獲得一個編號分配給當前節點,同時通知各個集群節點更新緩存的機器編號信息.計算節點接收到這些消息后,則重新設置自己接收心跳消息和發送心跳消息的節點,維持一個完整的對等環形監控網絡.
當計算節點宕機時,環形監控處理流程如圖2所示.圖2中1.1表示集群有5個節點組成為環形監控網絡.如果節點4宕機,則節點5在當前心跳時間內未收到節點4的生存狀態匯報信息,則默認該計算節點不可用,并向資源監控服務匯報監視節點的故障信息,如圖2中2.1.資源監控服務收到節點5匯報信息后,將節點4從監視列表中刪除,并釋放節點4編號,同時通知集群節點更新監視列表,如圖2中2.2~2.5.當計算節點收到監視列表更新通知后,重新設置監視節點與匯報節點.因此在下一次心跳周期到達后,節點3向節點5匯報心跳消息,同時,節點5等待節點3的心跳匯報,如圖2中2.6.最終節點1、節點2、節點3以及節點5組成了新環形監控結構.
當新的計算節點加入時,環形監控處理流程如圖3所示.圖3中1.1表示有4個節點組成了環形監控網絡,即節點1、節點2、節點3以及節點5.當一個節點向資源監控服務注冊節點信息,如圖3中2.1.資源監控服務檢查節點管理列表,找到1個可用編號4號為該節點分配,然后更新監視列表,并通知集群節點更新監視列表,如圖3中2.2~2.5.當計算節點收到節點列表更新通知后,重新設置監視節點與匯報節點.因此在下一次心跳周期到達后,節點3向節點4發送心跳信息,且節點4向節點5發送心跳信息,如圖3中2.6.最終這5個節點重新組成了環形監控結構.
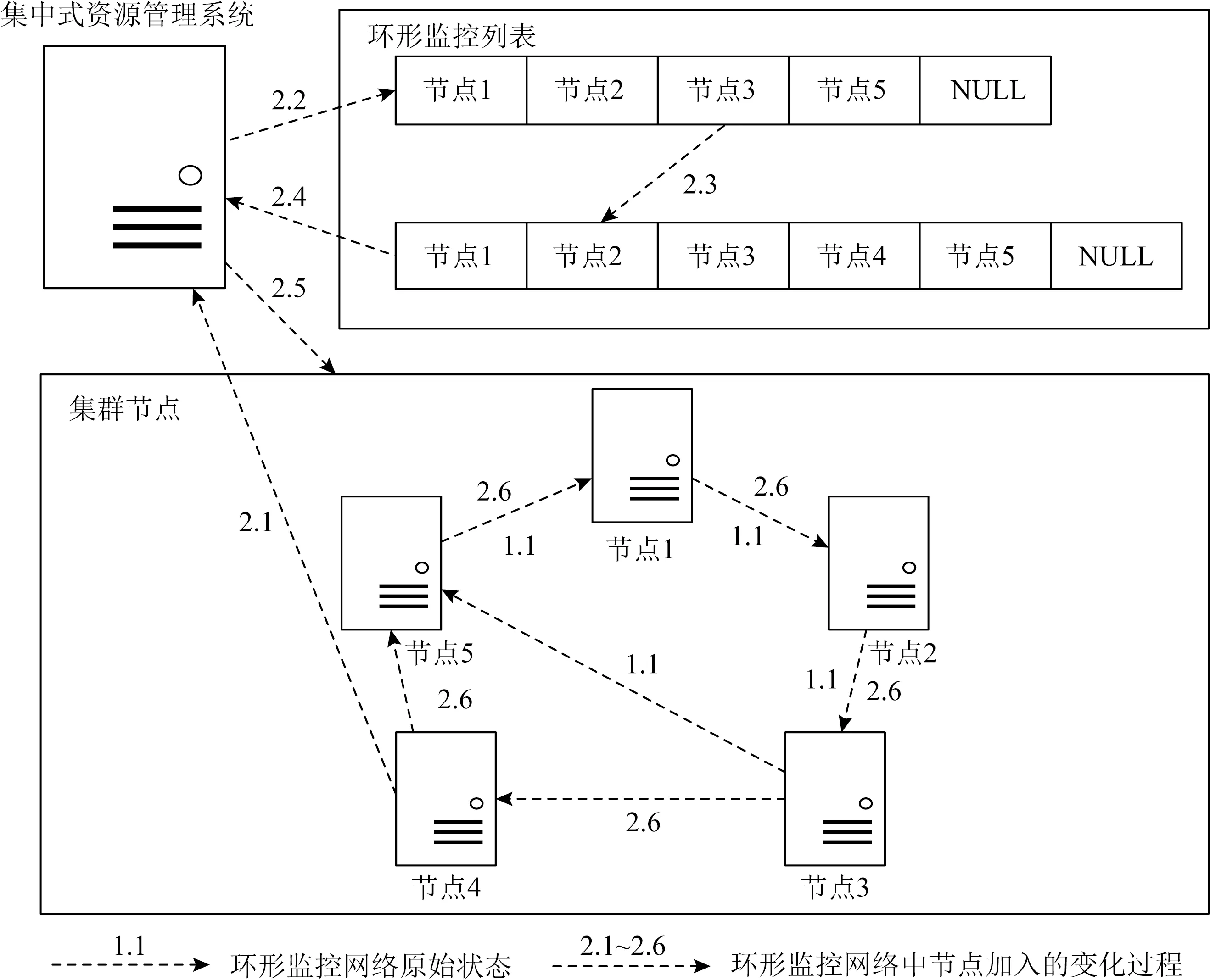
Fig. 3 The node is added to the ring monitoring network圖3 節點加入環形監控網絡
在傳統的資源調度框架中,資源管理器需要通過接收集群計算節點的周期性心跳匯報來判定節點是否宕機.通過圖2和圖3的改進,宕機的監視由對等的計算節點來完成,不再由資源管理器來實施,只有當某個計算節點出現故障時,才向資源管理器匯報,從而降低了資源管理器的壓力.雖然資源監控服務增加了監視列表的管理功能,但是在通常運行過程中,宕機的概率較小,發生的頻度也較低,對系統的整體調度的影響有限.
總之,集群的計算節點通過增加有狀態變化的心跳匯報以及環形監控功能,改變資源監控服務嚴格地接收周期性心跳信息的機制,加快資源監控模塊心跳信息處理效率,降低資源狀態更新延遲,改善資源管理器的可擴展性問題.
2 可擴展資源管理系統的實現
YARN的資源管理器稱為ResourceManager,其資源監控服務稱為ResourceTrackerService.計算節點管理程序稱為NodeManager,該程序的Node-StatusUpdater組件負責與ResourceTrackerService建立RPC通信機制,完成相應的節點注冊以及心跳的匯報功能.YARN同樣存在心跳信息周期性發送問題,因此本文按照基于差分的心跳信息處理模型以及基于環形監視的節點監控模型對YARN進行了優化.主要針對計算節點組件NodeStatusUpdater以及資源管理器的資源監控服務ResourceTracker-Service進行相關修改.
2.1 集群計算節點的修改
為了完成差分心跳信息的匯報以及宕機監控功能,計算節點需要在計算節點的注冊過程以及心跳匯報過程進行相應修改,并增加環形列表的異步更新,保證計算節點組成完整的環形監控網絡.
1) 計算節點注冊過程修改
計算節點上的服務啟動后,NodeStatusUpdater組件首先調用內部函數registerWithRM()完成節點向資源監控服務發起注冊請求的信息.為了保證環形監控列表的建立,每個計算節點在注冊成功后,應保存由資源監控服務分配的唯一標識.因此,在函數registerWithRM()流程中增加機器序列號的保存工作.
流程1.節點注冊.
輸入:當前節點信息curMac;
輸出:當前被更新的節點信息curMac.
① 初始化通信接口resourceTracker;
② 發送RegisterNodeManagerRequest(curMac);
③ 接收RegisterNodeManagerResponse;
④ ifRegisterNodeManagerResponse是正常狀態
⑤ 更新curMac.Mid;
⑥ end if
行①初始化建立resourceTracker通信接口.行②表示計算節點與資源監控服務的通信注冊過程,RegisterNodeManagerRequest將節點IP地址、對外端口號以及總資源的描述信息進行封裝,通過resourceTracker通信接口,調用遠程RegisterNode-Manager函數向資源監控服務注冊節點信息.行③表示資源監控服務向計算節點返回注冊成功消息,其消息類型為RegisterNodeManagerResponse.例如當返回消息標識為shutdown時,可能的原因是當前注冊節點資源不符合集群最小分配資源,因此拒絕該節點注冊,該節點的服務應該關閉.而在正常情況下被接受注冊的節點會收到信息標識為normal.另外,我們對該消息格式增加變量描述,即資源監控服務為計算節點返回1個機器編號.行④~⑥表示計算節點收到正常執行消息后保存機器編號,使得節點知道自身所在環形網絡的位置,便于找到其前驅以及后繼節點.
2) 心跳信息匯報的修改
在心跳信息匯報過程中,目的是減少不必要的心跳信息發送,并完成計算節點的監控.其過程分為2個步驟:第1步,當心跳時刻到達,計算節點對比本次與上一次緩存的容器狀態和資源健康狀態,根據對比結果有選擇地匯報心跳信息.第2步,增加各個計算節點環形網絡的監控功能,保證宕機節點能夠被監測到.
流程2.節點心跳匯報.
輸入:當前節點信息curMac;
輸出:當前被更新的節點信息curMac.
① 初始化Tnew,Told,Healthnew,Healthold,
TaskInfo;
② 創建1個線程;
③ while !isstopped
④ 讀取消息Tnew,Healthnew;
⑤ ifTnew-Told??或Healthnew≠Healthold;
⑥TaskInfo=Tnew-Told;
⑦ 發送NodeHeartbeatRequest(TaskInfo,
Healthnew);
⑧ 接收NodeHeartbeatResponse;
⑨ if 檢測NodeHeartbeatResponse為
shutdow或resync
⑩ 通知NodeManager關閉計算節點服務或重啟NodeStatusUpdater服務;
內容不為空
行①為變量初始化,行④周期性獲取節點容器狀態以及健康狀態.行⑤~⑧表示若有任務狀態或健康狀態變化,則先將任務進行過濾處理后,再向資源監控服務匯報心跳信息.行⑨~表示如果資源監控服務返回心跳回復信息執行狀態為shutdown或resync,則根據相應行為狀態通知NodeManager關閉計算節點全部服務或僅重啟NodeStatusUpdater服務,并影響NodeStatusUpdater服務的isstopped值的變化,防止當前心跳匯報函數進入下一次循環.行表示按照心跳回復消息內容更新心跳序號,保證計算節點有序匯報心跳信息,同時更新上一次的容器狀態以及健康狀態信息.行表示計算節點向后繼節點發送生存狀態信息.行~表示如果當前節點檢測前驅節點未發送生存狀態消息,則認為節點宕機,并向資源監控服務匯報該節點不可用.否則,不用匯報.行~表示如果節點監控關系不符合當前資源監控服務所維護的環形監控列表,則計算節點需要重新更新前驅與后繼節點.
3) 環形監控列表的更新
由于節點的加入或退出會引起計算節點環形監控列表的變化,因此計算節點需要及時更新環形監控列表.為此,在計算節點上增加了環形監控列表更新功能,該功能由資源監控服務觸發.針對環形監控列表的更新功能,計算節點相當于服務端,資源監控服務相當于客戶端.通過YARN提供的類YarnRPC,在計算節點上構建RPC協議,實現了與環形監控列表更新功能相關的函數接口,并在NodeStatus-Updater組件初始化時啟動該通信服務.同時,對該函數的參數與返回消息進行相關定義與封裝.
流程3.處理環型列表更新消息.
輸入:計算節點環形列表更新消息請求;
輸出:計算節點環形列表更新消息回復.
① ifrequest不是來源于中心節點
② returnNodeListUpdateResponse(reject);
③ end if
④ 更新curMac.NodeList;
⑤ 更新curMac.next,curMac.prev;
⑥ returnNodeListUpdateResponse(accept).
函數參數為NodeListUpdateRequest消息,內容主要包含節點來源信息以及環形監控列表信息.函數返回為NodeListUpdateResponse消息,內容主要包含1個標志信息,即是否接受處理該信息.行①~③檢測該請求來源信息,如果該請求不是資源管理器發來的消息,則拒絕該消息.行④表示讀取該消息內容,并更新環形節點列表.行⑤表示計算節點根據自身機器編號以及環形列表,更新前驅節點以及后繼節點,即計算節點形成新的環形監控網絡.行⑥表示計算節點接受并完成本次列表更新事件,并返回消息.
2.2 資源監控服務處理的實現
利用計算節點差分心跳信息匯報機制,減輕了集中式資源管理器的負載.然而,計算節點的存活狀態監控需要資源管理器進行一致性保證.因此,資源管理器的資源監控服務端需要增加環形監控列表的維護功能,相應實現如下.
1) RPC注冊函數的修改
當計算節點發來注冊請求消息時,資源監控服務需要對環形監控列表進行更新構建.
流程4.處理節點注冊消息.
輸入:注冊請求消息;
輸出:注冊回復消息.
① ifrequest不是來自有效節點
② returnRegisterNodeManagerResponse
(shutdown);
③ end if
④rmnode=newRMNode(request);
⑤NodeList+=rmnode.Mid;
⑥ 排序NodeList;
⑦ 異步通知各節點更新NodeList;
⑧ returnRegisterNodeManagerResponse
(normal,rmnode.Mid).
行①~③是對該消息相關內容進行安全檢測.行④表示根據消息中節點信息為新注冊節點創建狀態機,用來管理該節點的生命周期,并為該節點分配1個可用機器編號.行⑤表示將該節點編號加入環形監控列表中.行⑥⑦表示將環形列表按照節點序號進行排序,并異步地通知各個計算節點更新環形監控列表,保證計算節點收到節點列表更新消息后,根據自身節點機器編號找到對應的前驅與后繼節點,組成完整環形監控網絡.行⑧表示對節點注冊信息的回復,為計算節點額外返回1個節點編號,用于標識該計算節點在環形網絡的序列關系.
2) RPC心跳響應函數的修改
RPC心跳響應函數中,刪除了心跳信息的過濾步驟,直接發送更新通知.下面描述了該函數的正常執行流程.
流程5.處理節點心跳匯報消息.
輸入:心跳匯報請求消息;
輸出:心跳匯報回復消息.
① ifrequest不是來自有效節點
② returnNodeHeartbeatResponse
(shutdown);
③ end if
④ if管理列表中無request.Node
⑤ returnNodeHeartbeatResponse(resync);
⑥ end if
⑦ ifrequest.heartbeatID不是有序的
⑧ returnNodeHeartbeatResponse(resync);
⑨ end if
⑩ ifrequest.NodeStatus是健康狀態
HearbeatID).
行①~⑨表示收到計算節點的心跳匯報請求后,對心跳匯報的節點信息進行安全性檢測、判斷是否為注冊的節點以及是否嚴格符合消息匯報順序,如果不符合要求則返回相應計算節點下一步執行行為.由于計算節點狀態的變化,會引起資源的變化,因此當資源監控服務收到心跳后進入行⑩~過程,對相應計算節點狀態進行更新同步.行表示計算節點從健康狀態或非健康狀態轉化為健康狀態的過程.如果該計算節點處于健康狀態,則說明容器狀態有變化,把計算節點上的變化信息直接通知調度器,完成資源的更新與釋放.如果計算節點之前處于非健康狀態,則在狀態轉化過程中,向調度器通知計算節點資源可用消息.行表示計算節點從健康狀態到非健康狀態的轉化,在狀態轉化過程中,通知調度器當前計算節點資源不可用.行~更新節點心跳序號,并返回心跳回復信息,控制計算節點心跳信息的發送順序.
3) 宕機節點監控消息的處理
為保證集群計算節點環形一致性監控,資源監控服務需要額外增加功能函數,即計算節點發生宕機時的響應與處理.
流程6.處理節點宕機匯報消息.
輸入:宕機消息請求;
輸出:宕機消息回復.
① ifrequest不是來自有效節點
② returnUnLivelinessResponse(shutdown);
③ end if
④ if管理列表中無request.Node
⑤ returnUnLivelinessResponse(resync);
⑥ end if
⑦ ifrequest.Node,request.Pre不符合NodeList
⑧ returnUnLivenessResponse(NodeList);
⑨ end if
⑩ 狀態轉化request.Pre→Lost;
在當前通信協議中增加了1個RPC函數,定義為UnLivenessNodeManager,該函數包含1個參數UnLivelinessRequest消息結構和1個返回值UnLive-linessResponse消息結構.UnLivelinessRequest主要包含當前計算節點的信息,以及被監控的計算節點的信息.UnLivelinessResponse主要包含當前環形監控列表信息,以及節點下一步執行行為.
行①~⑥首先進行計算節點的安全性檢測.行⑦~⑨檢查當前計算節點以及它的前驅節點之間的監控關系,判斷是否符合當前的環形監控列表,如果不符合則返回最新環形監控列表,通知該計算節點更新前驅與后繼的監控關系;否則,接受本次匯報.行⑩將該節點所匯報的前驅節點的狀態轉為丟失狀態,同時向調度器發送節點資源減少消息.行~表示將宕機節點從環形監控列表中移除,重新將環形監控列表排序并異步通知各個計算節點.
另外,YARN資源管理器的NMLivelinessMonitor服務,會根據上一次心跳時間與當前時間之間的差值,判斷節點是否宕機.若2個時間差值超過規定時間,則認為該節點宕機,從計算節點管理列表中移除當前節點信息.采用基于差分的心跳信息處理模型后,NMLivelinessMonitor服務就不再承擔這項功能,因此該服務被刪除.
由于YARN采用基于事件驅動的資源調度,為避免心跳數量減少而影響資源調度過程,我們開啟YARN的持續調度機制.
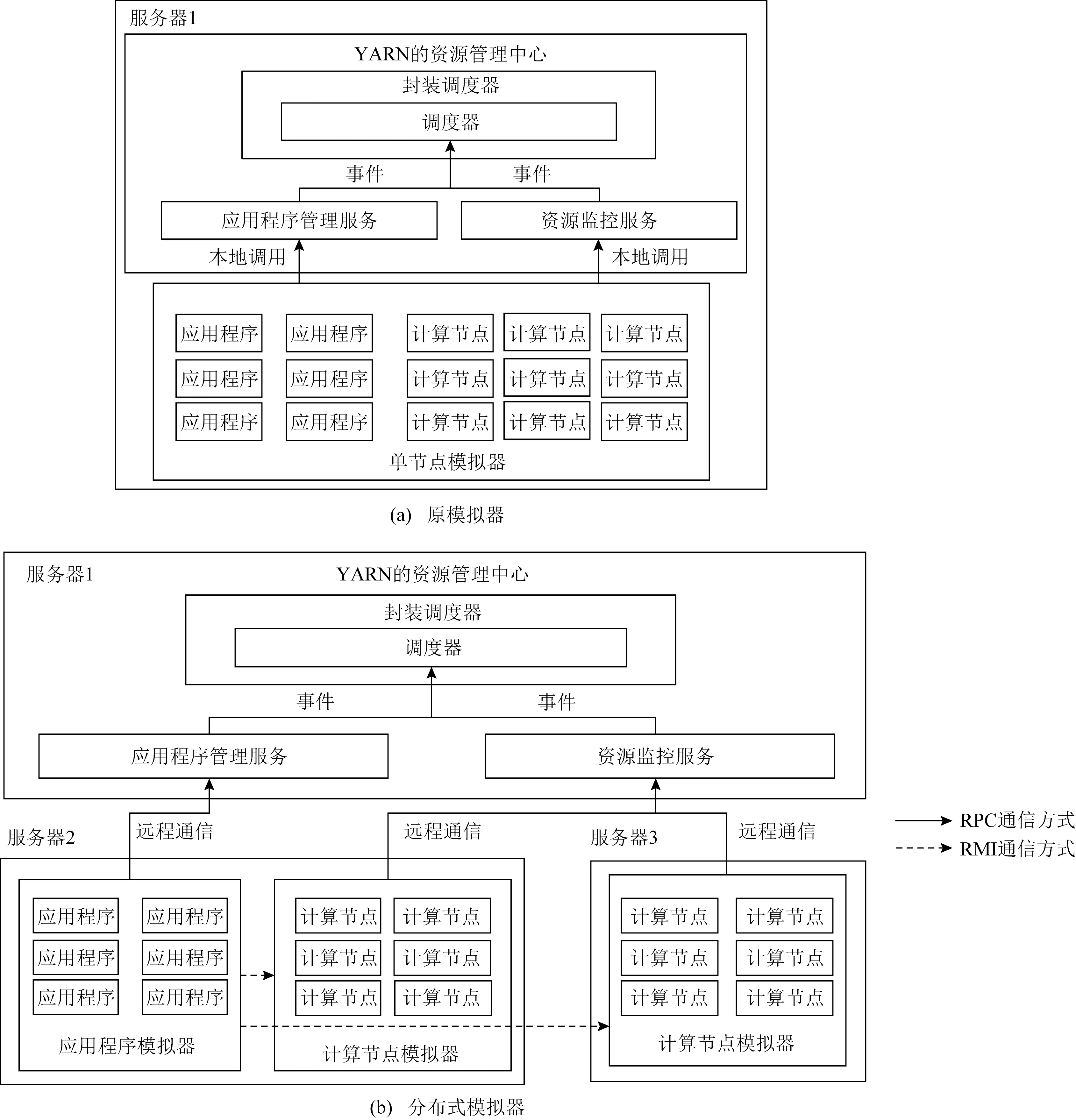
Fig. 4 Architecture of YARN SLS圖4 YARN SLS運行結構圖
3 實驗與結果
為了評價YARN調度器的性能,YARN官方針對YARN資源管理架構提供了一套性能模型工具SLS(scheduler load simulator),它可以在單臺機器上模擬大規模集群,然后根據歷史日志信息,獲得應用程序負載、資源分配、任務調度和資源回收過程的信息.但是隨著模擬的計算節點數量增多以及模擬負載的加大,SLS中的線程數也相應增加,線程數量的增加導致線程上下文切換開銷加大,致使模擬的性能數據受到影響.經過測試,單臺機器的最大模擬節點數量為5 000個.
為了驗證優化后的資源管理框架的可擴展性,提高模擬節點的數量,本文將SLS模擬器的應用程序模擬部分以及節點運行模擬部分進行了分離,使其可以運行在多個物理機器上,改進了SLS模擬器的運行結構,改進后的SLS如圖4(b)所示,稱為分布式模擬器.
實驗評價過程中,使用了3臺服務器,每臺機器均為NF5468M5服務器,包含2顆Xeon2.1處理器,每個處理器包含8個核、32 GB DDR4內存、2塊RTX2080TI GPU卡、10 GB顯存.3臺服務器中的1臺服務器作為資源管理器使用,另外2臺作為集群計算節點使用.
SLS的系統結構如圖4(a),YARN的資源管理器的主要服務有Scheduler,ResourceTrackerService,ApplicationMasterService,它們分別為調度器、資源監控服務、應用程序管理服務.在模擬過程中,應用程序主要模擬作業申請與任務調度.計算節點主要模擬接受應用程序發布的任務,維護其運行狀態并周期性向資源監控服務心跳匯報.單節點模擬器發送的心跳方式是通過本地調用的方法來實現,應用程序以及計算節點不通過網絡與資源管理系統進行交互,因此無法真實地模擬通信過程.分布式模擬器的資源管理器運行在單獨的節點上,計算節點與應用程序運行在其他物理機上.它們之間需要通過RPC協議與資源管理系統的各個模塊進行信息的交互.另外,應用程序獲得資源后,將任務封裝成容器描述信息,通過RMI通信方式來調用本地或遠程機器的對象方法,將容器信息添加到相應模擬計算節點的任務運行管理隊列中,保證調度器分配的資源與任務的映射關系在模擬計算節點上得到正確的體現.
為了測試調度器的可擴展性,分布式模擬器的資源管理系統則使用優化后YARN的實際代碼,集群計算節點使用模擬代碼,模擬代碼上添加了任務狀態與健康狀態差分過濾功能,即有變化時匯報心跳消息.
3.1 可擴展性測試
對于計算節點上的負載變化,使用正在運行的容器數量作為負載單位.把計算節點正在運行的容器數與其總容器數的比值稱為負載壓力.為了合理模擬不同集群節點的負載壓力,應保證作業的負載量與集群資源總量成正比.每個作業需要運行的任務數量與計算節點數量和最大運行任務數有關.作業數量的計算公式為t=(n×c×l)/a,其中n為計算節點模擬數量,c為每個計算節點最大運行任務數量,c=20,l為負載因子,在實驗中規定l=0.95,a為作業的數量,a=30.每個作業相繼每隔10 s啟動一個,每個作業預計執行時間為400 s,其任務的運行時間隨機.預計總運行時長為T=a×Toffset+(Tjob-Toffset),其中Toffset為每個作業啟動的時間間隔,Tjob為每個作業的預計執行時間,代入公式得到最終總的預計完成時間為690 s.隨著作業逐個啟動,處于運行狀態的容器數量逐漸增加,這些信息被周期性匯報給資源監控服務,資源監控服務負載開始上升,當時間到達400 s后,資源監控服務的負載開始下降.從第1個作業開始到全部作業結束,負載類似正態分布,并在300~400 s之間時,負載壓力會達到最大,即40%~50%之間.另外,對于集群節點數量,模擬數量從1 000個逐漸增加到10 000個進行實驗測試.計算節點心跳匯報時間間隔至少設為3 s,并記錄每個心跳周期內發送的消息數量以及接收到心跳回復消息數量.
資源監控服務接收到計算節點的心跳信息后,完成1次交互.資源監控服務將心跳信息進一步過濾處理后,產生節點更新事件并通知調度器,調度器更新相應的資源狀態.隨著計算節點上正在運行的容器數量的增加,每次心跳信息的數據量也相應增大,資源監控服務接收到的數據量也增大,資源監控服務將使用更多的CPU資源以及內存資源來處理這些數據,并且產生更多的調度器更新事件.由于調度器必須為每個更新事件進行對應的處理,所以調度負載加大.因此集群節點的管理規模取決于調度器對更新事件的處理效率.對于每一次心跳信息的處理,既包括資源監控服務器的數據過濾也包括調度器過濾后的數據的處理.而資源監控服務的處理效率以及調度器的處理效率,決定了整個集群資源管理的能力.資源監控服務的心跳信息處理效率定義為h1=min(mi/ni),而調度器對于節點資源更新事件的處理效率為h2=min(si/ni).其中ni為集群模擬節點在心跳時間間隔發送的心跳數量,mi為集群模擬節點心跳時間間隔內收到來自資源監控服務的心跳信息回復的數量,si為調度器心跳時間間隔內處理的節點資源更新事件數量.
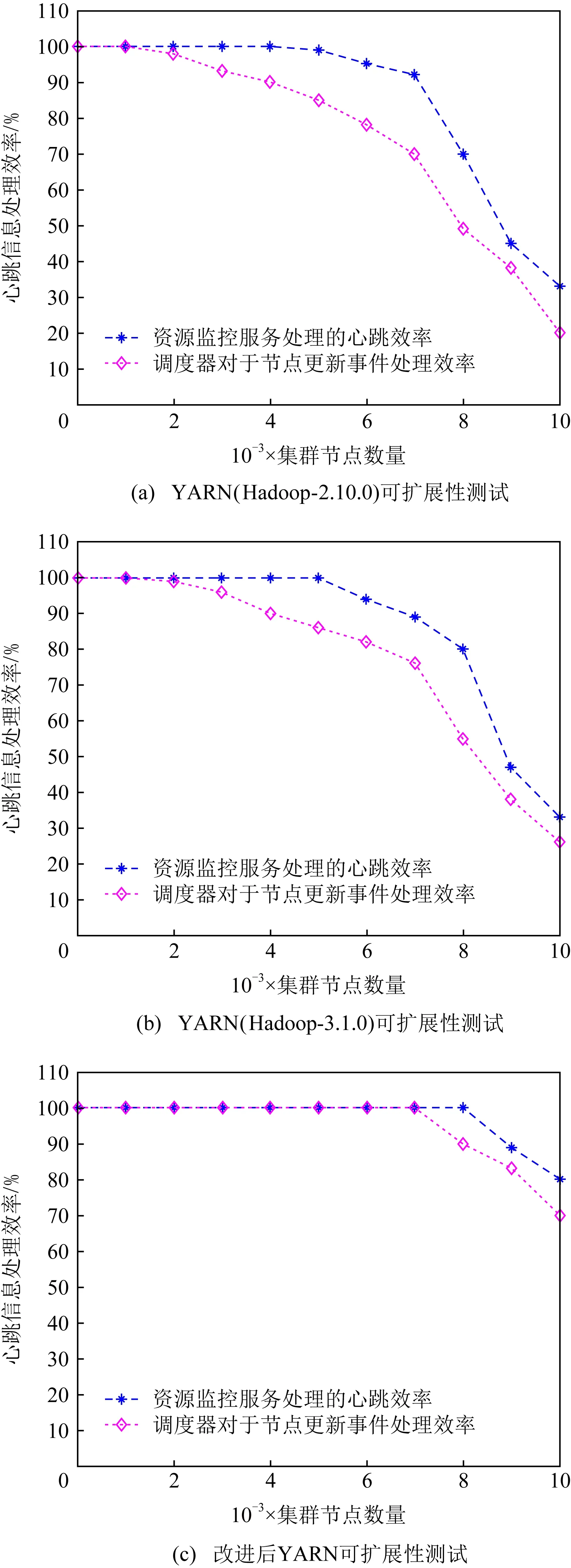
Fig. 5 Scalability bottleneck test圖5 可擴展性瓶頸測試
為了對比改進前后的效果,使用了YARN發布的2個版本與我們改進后的版本進行測試.圖5是YARN在不同集群規模下的心跳信息處理效率.圖5(a)是使用YARN的Hadoop-2.10.0版本獲得的數據;圖5(b)是YARN的Hadoop-3.1.0版本獲得的數據,Hadoop-3.1.0對Hadoop-2.10.0中的資源監視等服務進行了一定的優化;圖5(c)是本文對YARN的Hadoop-3.1.0使用差分模型和環形監控優化后的資源管理系統.對比看出,改進后的YARN資源管理系統對于心跳信息的處理效率明顯高于原系統.YARN原系統的心跳監控服務大約在4 500個計算節點時,就出現性能下降;在4 000個節點時,調度器的更新事件處理只能達到90%左右.而本文優化后的系統,心跳信息處理能夠達到8 000個計算節點,在7 500個計算節點處,才出現調度器更新事件的處理能力下降.我們知道,資源監控服務以及調度器在同一節點運行,心跳信息處理開銷增大,必然影響調度處理開銷,反之亦然.YARN的調度器每接收1個更新事件,便進行1次資源的回收與分配操作.然而,當資源監控服務對于心跳信息處理出現過載時,更新事件就不能及時發送給調度器,這嚴重限制了調度器資源回收與分配的性能,因此在大規模集群管理下,更新事件驅動的資源分配方式不太適用.而改進后的系統,在計算節點通過容器狀態差分方式對心跳信息進行預處理,減少了心跳數量以及心跳信息所帶來的數據量,進而減少通信開銷,提高了資源監控服務對于心跳信息的處理效率,使得資源監控服務可以快速地將更新事件發送到調度器,使得調度器的處理性能有較大提升.另外,資源監控服務對于心跳信息的處理效率影響調度器對于資源分配的公平性以及可用資源回收的及時性.總之,提升資源監控服務性能可以進一步提升調度器的性能,進而提升集群管理規模.
當集群管理規模為8 000個節點以上時,由于大規模的任務在模擬節點上隨機運行,新啟動的任務以及結束任務的數量不斷出現,導致大量的集群計算節點的心跳匯報信息不能被響應,改進后YARN系統的資源監控服務達到了處理瓶頸.同時隨著集群節點規模的增大,YARN內部多種狀態機制的轉化與管理使得各模塊交互事件增多,導致資源管理中的異步事件分派器下發能力限制,調度器對于節點更新事件的處理達到了瓶頸.因此,在心跳時間間隔為3 s時,改進后YARN的管理集群規模可以擴大到7 500個節點,系統亦可以正常地調度任務.修改前的YARN在集群節點數量超過4 000個時,開始出現調度延遲的現象.改進后的YARN資源管理系統的集群規模可以擴大到原來的1.88倍.
3.2 調度器對于事件的處理時間測試
YARN調度器需要處理資源分配請求以及節點更新事件,這些操作分別由應用程序管理服務與資源監控服務引發.在YARN的 SLS結構中,為了獲得調度器的各方面性能,SLS將調度器進行了一次封裝,即添加了一個構件Scheduler wrapper.當資源監控服務處理完心跳信息后,調度器處理開始,同時通過異步事件分派隊列,將計算節點更新事件傳入Scheduler wrapper,開始計時.當調度處理結束后,再通過異步事件分派隊列,將調度結束消息傳入Scheduler wrapper,停止計時.從處理開始到處理結束的時間段就是處理一次事件所消耗的時間.通過YARN的Metric性能統計工具,計算出處理相應事件類型的平均耗時.
圖6和圖7分別記錄了Hadoop-2.10.0,Hadoop-3.1.0以及改進后的YARN對于節點更新事件的處理時間,以及響應資源請求更新與分配的時間.通過記錄節點更新事件的處理時間,可以分析資源監控服務對調度器處理性能的影響.同時,通過分析應用程序管理服務的資源分配處理過程,可以得到調度器對應用程序的資源分配請求的響應時間.這些數據可以使我們進一步分析應用管理程序、調度器以及資源監控服務之間的性能影響關系.

Fig. 6 Scheduler cost time on node update event圖6 調度器對于節點更新事件處理時間
圖6為7 500節點下調度器對于節點更新事件的處理時間記錄,可以看出改進后YARN系統的調度器運行時間與預計時間相符合,即在690 s內完成整個模擬過程.而Hadoop-2.10.0,Hadoop-3.1.0版本的YARN系統,在模擬過程中調度器的運行時間均出現一定程度的延遲.另外,在模擬運行過程中,調度器對于事件處理的平均時間明顯高于改進后的YARN系統.其最主要原因是,改進后的YARN系統的資源監控服務可以及時響應集群計算節點的心跳信息并高效地處理,系統未出現過載現象,改善了調度器的更新事件的處理能力.
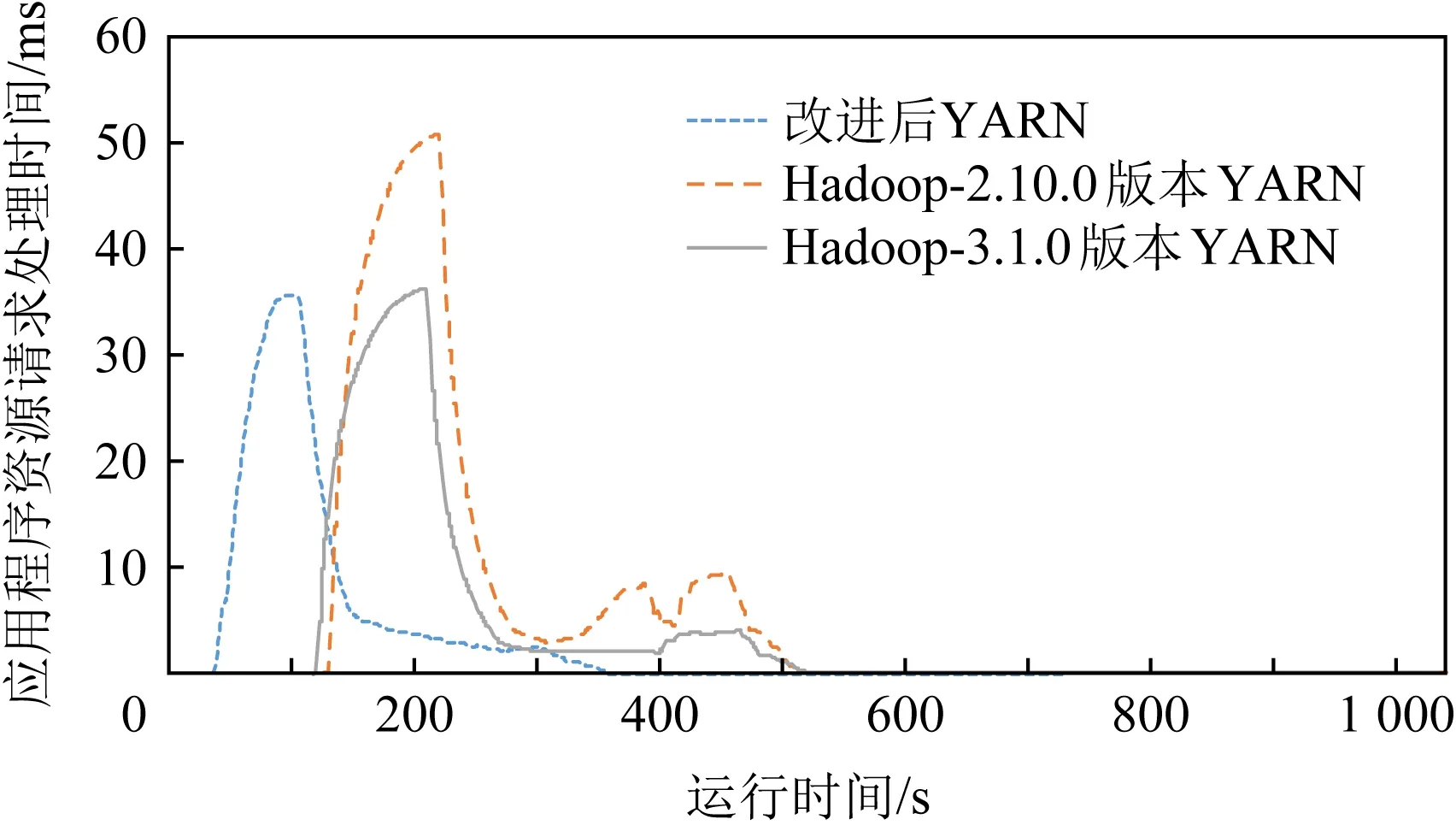
Fig. 7 Scheduler cost time on processing update requests from application master service圖7 調度器對應用程序管理服務的更新請求處理時間
從圖7可以看出,改進后的系統能較快地更新資源,大大提高了資源分配請求的更新速度.其主要原因是,當YARN的資源監控服務對于心跳信息的處理變得緩慢時,會導致節點資源更新的延遲,使得應用程序對于本次資源分配請求所獲取資源不能達到要求,導致應用程序不斷地向應用程序管理服務發送資源分配請求,增大了資源請求更新的頻率.在2次調度之間數據本地化,優先級等因素可能發生變化,調度器需要重新進行資源分配,進一步加重調度器負載壓力.因此,資源監控服務心跳信息的處理效率直接影響了資源的回收,進一步影響了資源分配效率,導致調度器在性能方面受到了一定的影響.
3.3 系統性能整體測試
為了測試系統繁忙程度,本文將CPU使用率作為參考指標.本節CPU使用率特指在用戶態下的CPU使用率.圖8給出了系統在維護不同集群規模期間的CPU平均使用率.從圖8可以看出,在6 000節點之前,各系統的CPU平均使用率隨著集群管理規模擴大呈現升高趨勢.由于改進后的YARN系統的資源監控服務通過接收少量的關鍵心跳信息來管理大規模集群,使得CPU平均使用率相比原系統會低一些.對于改進前的YARN系統,當集群規模進一步擴大以及負載壓力的提高,集群節點持續地發送大批心跳信息導致資源監控服務過載,因而處理效率更加緩慢.由于心跳信息無法被及時處理,模擬計算節點會長時間等待心跳信息的回復消息,從而導致模擬節點無法正常發送心跳消息,因此其模擬節點上的CPU平均使用率從7 000節點開始明顯下降.相反,由于改進后的YARN系統的資源監控模塊對于心跳信息的處理效率提高,因此可以響應更多的心跳,其模擬節點不會出現長時間等待心跳回復事件,相比之下CPU平均使用率較高,但當節點數量超過8 000后其處理能力達到瓶頸.
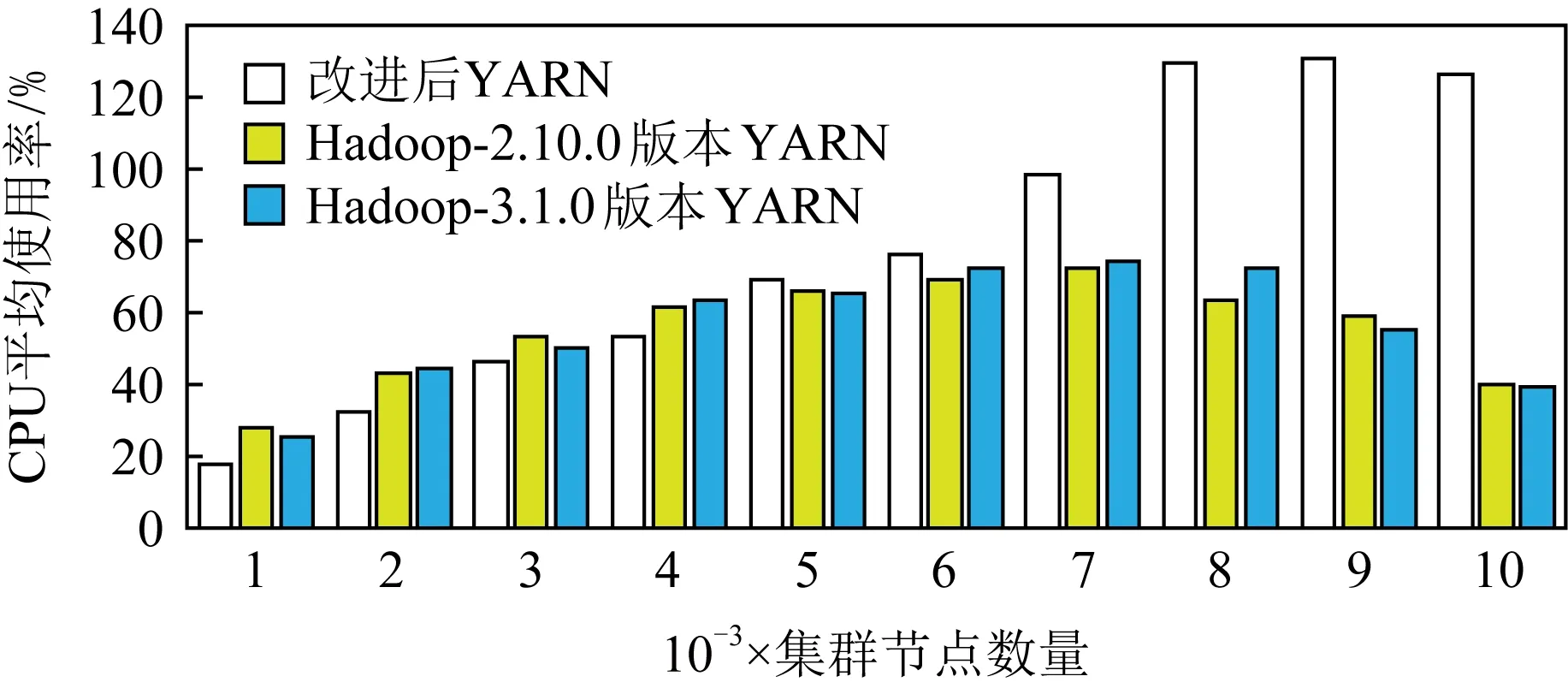
Fig. 8 CPU average usage under different cluster sizes圖8 不同集群規模下CPU平均使用率對比圖
3.4 節點宕機情況匯報性能測試
為了驗證改進后資源管理系統對于節點宕機情況的處理性能,本文在節點模擬過程中增加基于環形監視的節點狀態監控功能.對于節點自身以及其后繼節點在同一臺物理機器的場合,則直接調用函數來更新狀態事件;對于節點自身與后繼節點不在同一臺物理機器的場合,則需要與另一臺機器建立通信連接,然后進行狀態事件的發送與更新.圖9給出宕機時的測試結果.測試過程中,模擬節點數量為7 500個,從整個模擬集群節中隨機選擇5%的模擬節點,在運行了400 s后停止匯報心跳功能,同時停止向監控節點匯報自己的生存狀態,用來模擬節點宕機情況.在該運行過程中,通過Metric性能統計工具,記錄了節點移除事件.
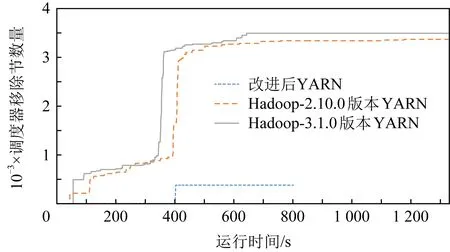
Fig.9 Comparison of the numbers of removed nodes圖9 節點移除數量對比
從圖9結果可以看出,對于Hadoop-2.10.0與Hadoop-3.1.0版本的YARN系統,發現大量的額外節點被移除.分析原因后發現,由于節點存活檢測時間設置過小,隨著在后續過程中心跳信息帶來的負載量增大,心跳信息處理的延時增加,導致越來越多的節點被誤認為宕機狀態而被移除.由于大量的節點被移除,使得調度器需要對該部分資源回收,同時對移除節點上的任務需要重新分配資源,進一步加大了調度器負載,使得任務的運行被延遲.然而設置時間間隔太大,其宕機監控效果將會不敏感.
對于改進后的YARN系統,集群計算節點的存活狀態監控由計算節點來實施,每個節點只監控它的前驅節點,只有當計算節點向資源監控服務匯報某個節點宕機時,資源監控服務才會將相應節點移除,并通知調度器進行資源的更新與任務的回收,因此上述情況不存在.同時,由于計算節點提前對心跳數據過濾,只有計算節點真正出現宕機時,才向資源監控服務匯報,從而減少了資源監控服務處理消息的數量,使得集群管理器的資源監控服務負荷降低.因此,改進后的YARN能夠改善集群系統的可擴展性.
4 總 結
資源管理系統處理心跳信息的效率影響系統的可擴展性,因此提高系統運行效率,加快資源狀態視圖的更新,可以緩解調度器不能及時處理更新事件而導致的延遲等問題.通過資源管理器的資源監控服務功能的分解,將心跳信息的過濾功能轉移到計算節點的方式,改變嚴格的周期性心跳匯報機制,最終減輕資源管理器的負載壓力,提高了集中式資源管理系統的可擴展性.事實上,集中式的心跳處理依舊會成為瓶頸.隨著集群規模的擴展和狀態的規模進一步擴大,集群的資源狀態的存儲必須使用分布式數據儲存機制來保證可用性和低延遲.
猜你喜歡
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
今日農業(2019年12期)2019-08-15 00:56:32
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年16期)2019-01-03 11:39:20
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
商周刊(2017年9期)2017-08-22 02:57:56
中華手工(2017年2期)2017-06-06 23:00:31
資源再生(2017年3期)2017-06-01 12:20:59
中外會展(2014年4期)2014-11-27 07:46:46
