基于Storm平臺的數據恢復節能策略
2021-04-01 01:18:10蒲勇霖李梓楊國冰磊
計算機研究與發展 2021年3期
關鍵詞:資源
蒲勇霖 于 炯 魯 亮 李梓楊 國冰磊 廖 彬
1(新疆大學信息科學與工程學院 烏魯木齊 830046) 2(中國民航大學計算機科學與技術學院 天津 300300) 3(新疆財經大學統計與數據科學學院 烏魯木齊 830012)
(puyonglin1991@foxmail.com)
近年來,隨著各種功能強大的高速互聯技術的出現,物聯網場景下產生的數據量日益增多,對計算能力的需求日益增長,高性能集群由于其高性價比、高可用性以及可擴展性等特點[1]已成為商業應用與學術研究的基礎架構.但是各種高性能集群在處理數據時產生的高能耗問題同樣不容忽視.高德納(Gartner)公司指出預計到2015年,全球數據中心占比71%的大型數據中心其電費支出超過1 262億美元[2],而預計2020年,全球數據中心的能耗產值為20 000億kW·h[3].我國數據中心的總耗電量同樣驚人,截至2018年中國數據中心的總耗電量為1 608.89億kW·h,占全國總用電量的2.35%[4].高額的能耗成本已對社會與環境造成巨大影響,因此解決IT行業的高能耗問題已經刻不容緩.
希捷(Seagate)公司與IDC聯合發布的《數據時代2025》白皮書中預測,2025年全球數據量將達到163ZB.其中,超過25%的數據將成為實時數據,而物聯網實時數據占比將達到實時數據的95%[5].針對大數據處理的高性能集群一般分為批量計算框架與流計算框架2類.其中批量計算框架由于存在先存儲后計算的特性無法滿足實時數據的處理需求;而流計算框架由于其強大的實時性,為實時大數據分析提供了良好的平臺層解決方案[6].但是流式計算在高速處理實時數據的過程中同樣伴隨著高能耗的問題[7],因此流計算框架的節能優化是一個亟待解決的問題.
目前針對大數據流式處理的平臺主要以Apache Storm框架[8]為主.Storm是一個主從式架構、開源、橫向擴展性良好且容錯能力強的分布式實時處理平臺,其編程模型簡單,支持包含Java在內的多種編程語言,且數據處理高效.與不開源的Puma[9]以及社區冷淡的S4[10]相比,Storm具有更活躍的社區發展;與屬于微批的Spark Streaming[11]框架相比,Storm具有更穩定的集群性能;與后起之秀Flink[12]與Heron[13]相比,Storm具有更成熟的平臺架構和更廣泛的產業基礎.目前Storm憑借低延遲、高吞吐的性能優勢以及高效的容錯機制[14],已經成為華為、百度以及小米等企業針對流數據處理業務的最佳選擇,被譽為“實時處理領域的Hadoop”[15].
在Storm框架中,流式作業(拓撲)中的1個任務通常運行于1個工作線程內,1個工作進程包含有多個工作線程.但當Storm集群拓撲在處理任務出現計算資源不足或拓撲報錯時,缺乏合理的應對策略,從而對集群拓撲任務處理的計算延遲與能耗造成影響,具體體現有2點:1)集群拓撲在執行任務時,工作節點可能會出現資源瓶頸的問題,工作節點的資源接近溢出,其功率不斷增大,集群的計算延遲不斷上升,對集群的性能與能耗造成巨大影響;2)拓撲在執行任務時,由于網絡等問題而出現錯誤,需要終止拓撲內的任務并從磁盤重新讀取數據,但是從磁盤讀取數據存在較高的計算延遲與能耗,會對集群拓撲任務的正常執行造成一定的影響.因此,為了解決該問題.本文提出基于Storm平臺的數據恢復節能策略(energy-efficient strategy based on data recovery in Storm, DR-Storm),該策略在降低集群出現過高計算延遲的基礎上,保證集群拓撲任務的順利執行并有效節約能耗.
本文的主要貢獻包括3個方面:
1) 通過分析Storm框架的任務邏輯,建立任務分配模型,用于描述集群內工作節點間任務分配的邏輯關系,為后續監控集群拓撲內的元組信息提供幫助,并為研究集群拓撲內的任務執行情況奠定了理論基礎.
2) 根據任務分配模型,建立了拓撲信息監控模型,通過監控反饋信息判斷是否終止拓撲內的任務,并進一步建立數據恢復模型,其中是否對集群拓撲進行數據恢復由拓撲信息監控模型反饋的元組信息決定.在確定終止集群任務后,對集群拓撲進行數據恢復.
3) 根據拓撲信息監控模型與數據恢復模型,建立能耗模型,并在此基礎上提出基于Storm平臺的數據恢復節能策略,該策略包括吞吐量檢測算法與數據恢復算法,其中吞吐量檢測算法通過監控拓撲內的元組信息計算集群吞吐量,判斷是否終止集群拓撲內的任務;而數據恢復算法根據吞吐量檢測算法執行情況,確定是否對集群拓撲進行數據恢復.此外,實驗選取4個代表不同作業類型的基準測試[16],從不同角度驗證了算法的有效性.
1 相關工作
目前針對Storm,Flink,Spark Streaming,Heron等主流大數據流式計算框架的節能研究相對較少.但是IT行業日益增長的高能耗問題,已經嚴重制約著平臺的發展.因此針對大數據流式計算框架的節能優化已經刻不容緩,是未來重要的研究方向.目前針對大數據流式計算框架的節能研究主要集中于硬件節能[17]、軟件節能[18]與軟硬件結合[19]3種方法.
硬件的節能主要基于2種思路:1)通過用低能耗、高效率的電子元件替換高能耗、低效率的電子元件[20];2)對集群的節點電壓進行縮放管理[21].2種思路的節能效果顯著,但是由于其價格高昂,且對節點電壓進行縮放管理存在較大誤差,因此不適合部署在大規模的集群當中.蒲勇霖等人[22]通過對Storm集群工作節點的內存電壓進行動態調節,在不影響集群性能的條件下分別節約了系統28.5%與35.1%的能耗.Shin等人[23]提出了一種混合內存的節能策略,通過用低能耗高效率的PRAM(parallel random access machine)替換高能耗低效率的DRAM(dynamic random access memory),從而達到提高集群性能并降低能耗的目的.實驗結果表明該策略降低了集群36%~42%的能耗.Pietri等人[24]通過將流式處理平臺的部分CPU替換成GPU,使得CPU與GPU進行混合,從而減少了集群處理圖數據的能耗,實驗結果表明在節約9.69%能耗的前提下減少了8.63%的訪問時間.文獻[25]通過使用動態電壓頻率縮放技術(dynamic voltage frequency scaling, DVFS),對集群節點的CPU電壓進行了動態縮放管理,以此達到了節能的效果.文獻[26-28]通過替換高能耗、低效率的電子元件,在提高集群性能的基礎上節約了能耗.
軟件與軟硬件結合的節能策略是目前研究的重點,其中軟件的節能主要根據建立能耗感知模型[29]與通過資源調度[30]提高集群的能效,以達到節能的目的.文獻[31]根據分析Spark Streaming框架的基本特性,提出一種自適應調度作業的節能策略,該策略通過在集群中建立能耗感知模型,對集群內的數據信息進行實時捕捉,從而分析集群任務的實際運行情況,根據不同任務的執行結果對集群的性能與能耗進行調控.實驗表明該策略降低了集群的時間開銷并節約了能耗.文獻[32]提出一種作用于Spark Streaming的能耗分析基準測試方法,該方法通過使用機器學習算法,查找集群內數據流的大小與通信開銷的平衡,實驗結果表明當集群內數據流的大小與通信開銷達到平衡時,集群執行任務的功耗最小.
文獻[7]對流式大數據處理的框架進行了優化,提出了一種基于Storm框架的實時資源調度節能策略,該策略通過構建Storm的能耗、響應時間以及資源利用率之間的數學關系,獲得了滿足高能效和低響應時間的條件,并以此建立了實時資源調度模型,該模型在實現最佳能效的前提下,對集群的資源進行調度.然而該策略還存在2點值得探討:1)節能策略只考慮了CPU的資源利用率與能耗,忽視了集群其他電子元件(內存、網絡帶寬與磁盤等)的資源利用率與能耗.由于流式處理集群的實時性較高,其他電子元件的資源利用率與能耗對其影響巨大而不容忽視;2)該節能策略使用自己定義的拓撲,而非公認的數據集,因此缺乏一定的通用性.
軟硬件結合的節能主要通過對資源遷移后節點的電壓進行動態縮放管理[33]或關閉其空閑的節點[34],以達到節能的效果.文獻[35]通過分析流式大數據的自身特性,設計了2種節能算法,即能量感知副本算法與性能和能量均衡副本算法.2種節能算法根據集群任務的實際運行情況,對任務完成后或不執行任務處理的節點進行降壓處理,以此達到節能的目的.文獻[36]通過分析Spark Streaming框架在執行任務時性能與能耗的權衡,提出一種基于調度工作負載的高效節能策略.該策略通過建立時間序列預測模型對集群任務的處理時間與能耗進行捕捉,并使用DVFS技術來調節集群節點的電壓,以此達到降低集群能耗的目的.
文獻[19]從集群拓撲任務處理的彈性出發,提出一種針對流式大數據平臺的彈性能耗感知節能策略(keep calm and react with foresight:strategies for low-latency and energy-efficient elastic data stream processing, LEEDSP),該策略通過建立能耗感知模型,對集群的任務處理進行彈性調節,以實現提高集群吞吐量并節約能耗的目的.但是該節能策略并不是始終有效的,這是由于大數據流式處理平臺的任務一旦提交,將持續運行下去,而長時間運行節能策略會導致集群拓撲內的任務處理出現不平衡,從而嚴重影響集群拓撲任務的正常執行.
文獻[37]針對Storm框架在進行數據處理時存在高能耗的問題,提出數據遷移合并節能策略(energy-efficient strategy for data migration and merging in Storm, DMM-Storm),該策略通過設計資源約束模型與最優線程數據重組原則,對集群內的資源進行遷移,并使用DVFS技術對遷移資源后工作節點的CPU進行電壓縮放管理,有效降低了集群的能耗與節點間的通信開銷.但是仍存在2點有待優化:其一為該節能策略對集群拓撲處理任務的實時性造成一定影響;其二為使用DVFS技術調節集群節點CPU的電壓存在較大的偶然性,且技術的實現難度較高不適合部署于大規模集群當中.
與上述研究成果相比,本文的不同之處在于:
1) 文獻[19,23-36]均未考慮任務遷移后,對集群工作節點的資源占用(CPU、內存與網絡帶寬等)是否造成影響,而文獻[7]忽視了除CPU之外,其他電子元件對集群工作節點資源占用的影響.本文通過建立資源約束模型,避免了集群在進行任務處理時對節點資源占用造成的影響.
2) 文獻[37]存在影響集群性能的問題,且節點CPU電壓的調節存在偶然性.本文通過減少集群拓撲任務處理的延遲,在提高集群性能的同時節約了集群的能耗.此外,并未對節點CPU的電壓進行調節,避免了因動態調節CPU電壓而對集群拓撲正常執行任務造成影響.
3) 實驗選取Intel公司Zhang[16]發布在GitHub上的4組Benchmark進行測試,而非自己定義的拓撲,因此更具有公認性.此外,本文與LEEDSP[19],DMM-Storm[37]進行實驗對比,驗證了節能策略的效果.
2 問題建模與分析
為了量化集群拓撲執行任務的能耗,本節首先建立Storm的任務分配模型、拓撲信息監控模型以及數據恢復模型,并在此基礎上建立能耗模型.其中Storm的任務分配模型描述了拓撲中工作節點與各個任務之間的對應關系,為后續判斷集群拓撲的任務執行奠定了基礎;拓撲信息監控模型通過定義集群工作節點的資源約束設置滑動時間窗口,并計算集群吞吐量,確定集群拓撲任務的執行情況,以此判斷是否終止拓撲內的任務;數據恢復模型將集群內的數據備份到內存,根據信息監控模型的反饋信息,確定是否進行數據恢復,并根據數據存儲限制對節點內備份的數據進行實時刪除;能耗模型通過任務的執行時間與功率計算集群能耗,為節能策略的實現提供了理論依據.

Fig. 1 Data allocation in the topology圖1 拓撲內的數據分配
2.1 Storm的任務分配模型
在Storm框架中,1個流式作業由1個稱為拓撲(topology)的有向無環圖構成,其中由數據源編程單元Spout和數據處理編程單元Bolt這2類組件(component)共同構成了有向無環圖的頂點,各組件之間通過不同的流組模式發送和接收數據流,構成了有向無環圖的邊.為了提高集群拓撲的執行效率,需要滿足每個組件在同一時刻創建多個實例,稱之為任務(task).1個任務運行于1個工作線程(executor)內,是各組件最終執行的代碼單元.拓撲提交到集群后,任務將分布到各個工作節點中,并開始進行任務的處理和任務間數據流的傳輸工作.令Storm集群工作節點的集合為N={n1,n2,…,n|N|},且工作節點內存在組件的集合為C={c1,c2,…,c|C|},由于每個組件都可同時創建多個實例,則組件ci創建的第j個實例作為任務tij(若組件ci創建的實例數為1,則將該任務簡化為任務ti),由此存在T(N)={ti1,ti2,…,tin}表示工作節點分配到拓撲的任務集合.圖1為集群拓撲內的任務分配情況,共由3個工作節點、12個實例與19條有向邊組成.其中節點集合為N={n1,n2,n3},各工作節點內的任務集合為Tn1={ta,td1,tf1,th1},Tn2={tb,td2,tf2,th2},Tn3={tc,te,tg,ti}.
2.2 拓撲信息監控模型
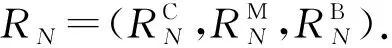
(1)
(2)
(3)
此外,集群拓撲在執行任務時可能會出現節點丟失(報錯)的問題,則集群拓撲就會舍棄該節點(不再向該節點分配任務),此時集群內工作節點的資源占用率會迅速升高,從而接近工作節點資源占用的極限(該現象被稱為工作節點的資源瓶頸),進而影響任務的順利執行,并提高工作節點執行任務的功率.為解決這一問題,需要設置滑動時間窗口計算集群吞吐量,從而實時反饋拓撲執行任務的信息,對任務的執行情況進行判斷.滑動時間窗口的設置可用定義2表示:
定義2.滑動時間窗口.滑動時間窗口的取值可通過定義時間窗口的初始值對額外增加的網絡資源占用率與系統延遲的影響確定.令滑動時間窗口的初始值為wori,額外增加的網絡資源占用率為oext,系統計算延遲為tdel,則滑動時間窗口的初始值對額外增加的網絡資源占用率與系統計算延遲的影響為
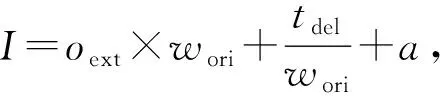
(4)
其中,a表示其他因素如拓撲任務處理帶來的影響,為常數.為選擇對額外增加的網絡資源占用率與系統延遲影響最小的時間窗口取值,則可通過式(5)獲得其相應窗口
Ii=min(I1,I2,…,In).
(5)
通過式(5)可知,當時間窗口為Ii時,其取值對額外增加的網絡資源占用率與系統延遲的影響最小,此時對應的時間窗口取值為wi.本文滑動時間窗口的取值通過4.1節進行測試.此外在實際應用中,可將不同數值帶入式(4)(5),通過多次訓練,確定合適的時間窗口取值.
為保障拓撲執行任務時Storm集群的性能不受影響,需要對拓撲內的每個tuple進行標記,使其在單位時間內以心跳信息形式進行信息反饋,并通過計算集群吞吐量判斷拓撲任務的執行情況,從而確定是否結束拓撲內的任務.圖2為時間窗口的設置與集群吞吐量的計算示意圖,令滑動時間窗口的長度為w(單位為s),數據的標記信息為Mlab,發送信息的節點為NWorkNode,接收信息的節點為NNimbus,則滑動時間窗口的信息反饋為
(6)


(7)
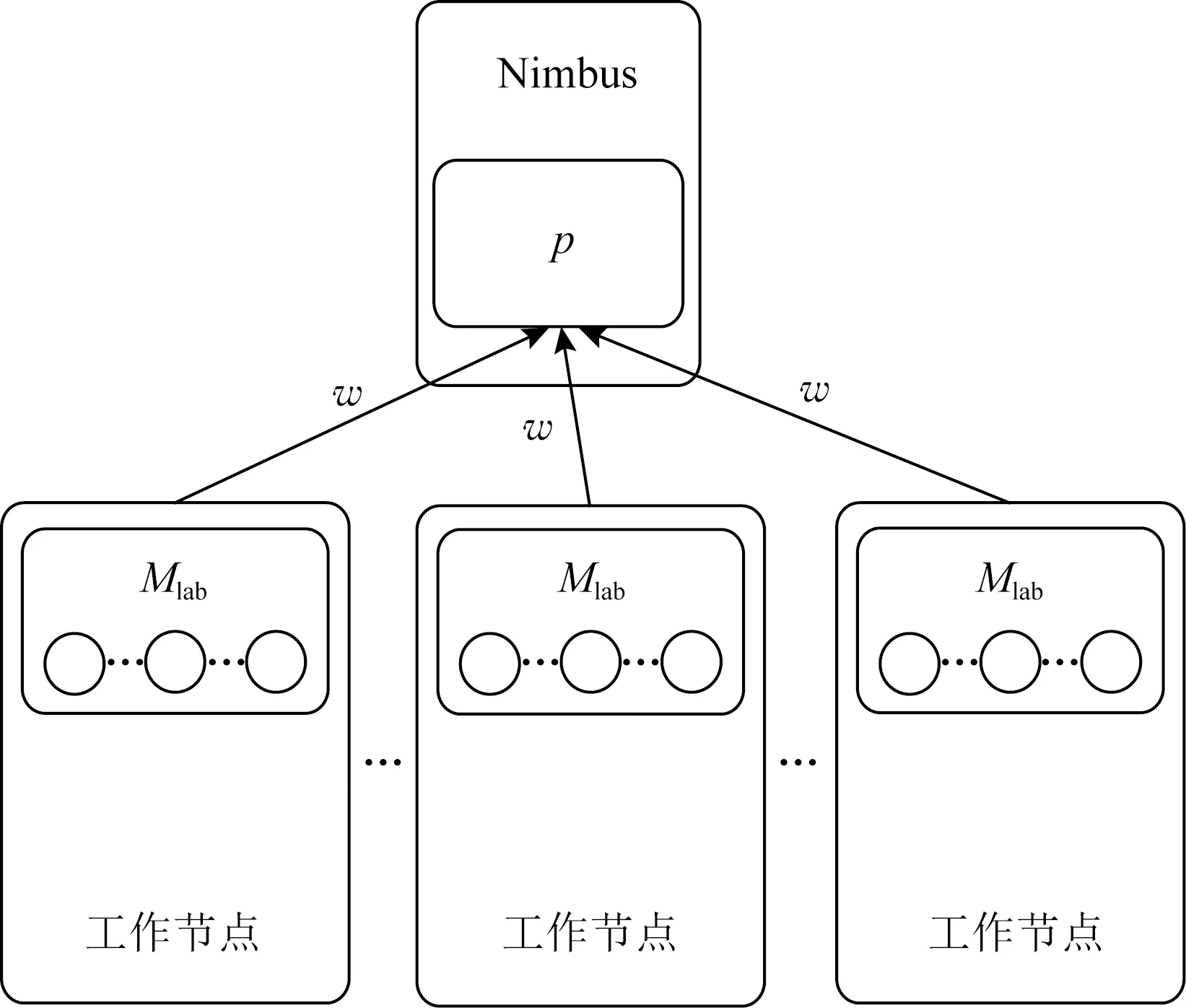
Fig. 2 Time window setting and cluster throughput computing圖2 時間窗口的設置與集群吞吐量的計算
此外,檢測集群吞吐量存在2個限制條件:1)因節點丟失等問題而出現資源瓶頸,導致集群吞吐量低于原集群吞吐量的最低值;2)因網絡等問題而出現拓撲報錯,集群吞吐量為零.因此為檢測集群吞吐量是否受限制條件的影響,需要設置集群吞吐量的下限,令集群吞吐量存在1個閾值下限為pval,為保障集群拓撲內的任務順利執行,則:

(8)
因此,根據式(8)對集群拓撲執行任務進行判斷,確定是否終止集群拓撲內的任務.
2.3 數據恢復模型
Storm集群在進行數據的傳輸與處理時,數據通過磁盤發送至集群拓撲.根據2.2節可知,當集群出現資源瓶頸或拓撲報錯時,終止集群任務,但由于從磁盤內讀取數據,整個集群的計算延遲與能耗開銷相對較大,因此建立數據恢復模型,使集群通過內存讀取數據,以此減少不必要的計算延遲與能耗開銷.
定義3.內存數據存儲.為減少由于數據從磁盤讀取而產生不必要的計算延遲與能耗開銷,現選擇內存資源占用率最小的節點作為備份節點,用于數據的存儲,具體的計算為
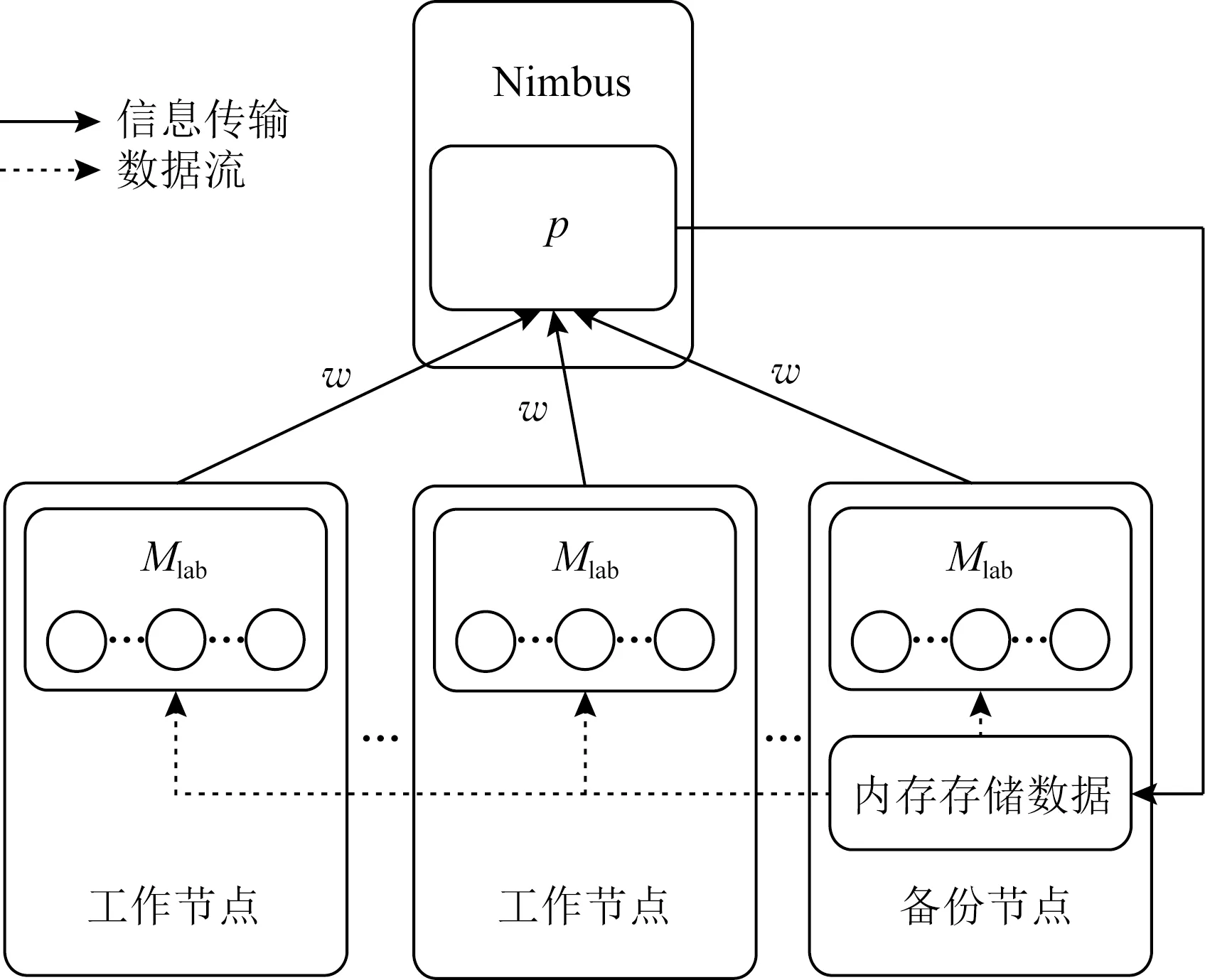
Fig. 3 Data monitoring and recovery in the topology圖3 拓撲內數據監控與恢復
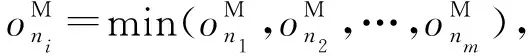
(9)
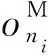

(10)
此外,將磁盤內的數據存儲至備份節點內存,會增加額外的節點間通信開銷,但由于出現資源瓶頸或拓撲報錯等問題而終止集群任務后,數據從備份節點內存讀取相比于從磁盤讀取降低了延遲,因此這部分額外增加的節點間通信開銷對集群拓撲任務處理的影響可忽略不計.
為計算集群數據恢復的時間,令拓撲從內存讀取數據的時間為Timeram,滑動時間窗口信息反饋的時間為Timewin,終止集群任務的時間為Timeter,則拓撲從內存恢復數據的時間Timeres為
Timeres=Timewin+Timeter+Timeram.
(11)
此外,由于滑動時間窗口信息反饋的時間與終止集群任務的時間非常短,可忽略不計,則化簡式(11)可得:
Timeres=Timeram.
(12)
為計算集群數據傳輸與處理的總時間,令拓撲從磁盤讀取數據的時間為Timedisk,由于集群拓撲數據傳輸與處理的時間為Timepro,則集群數據傳輸與處理的總時間Timetot為
Timetot=Timedisk+Timepro.
(13)
此外,若原集群拓撲在執行任務時因網絡等問題而出現拓撲報錯的問題,令報錯前數據傳輸與處理的時間為Timebef,報錯后數據傳輸與處理的時間為Timeaft,由于拓撲報錯之后,集群拓撲內的數據需要重新讀取,因此,數據傳輸與處理的時間與原集群拓撲任務處理的時間相等,即
Timeaft=Timepro.
(14)
由于拓撲報錯后,原集群拓撲從磁盤讀取數據,即
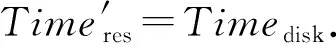
(15)

(16)
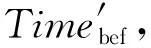
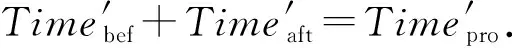
(17)
則當出現資源瓶頸時,集群數據傳輸與處理的總時間為
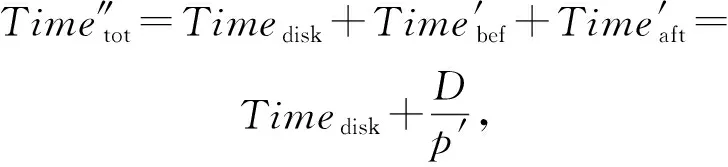
(18)
其中,p′表示原集群拓撲在執行任務出現資源瓶頸時集群的平均吞吐量.
若原集群拓撲在執行任務出現拓撲報錯或資源瓶頸時,集群使用數據恢復模型,則同理可得集群數據傳輸與處理的總時間Time?tot為
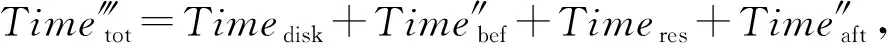
(19)
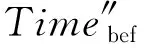
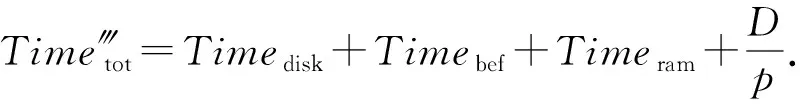
(20)
則集群使用數據恢復模型后,減少的計算延遲Timesave為

(21)
其中,式(21)內的參數與式(16)(18)(20)相同.
2.4 能耗模型
針對流式處理集群建立能耗模型首先需要注意是否影響集群的性能,而降低集群能耗一般從2個角度出發:1)提高集群拓撲任務處理的速度,減少任務處理的時間;2)降低集群拓撲任務處理的功率.因此需要引入經典的能耗模型,即
Energy=Power×Time,
(22)
其中,Energy表示集群拓撲任務處理的能耗,Power表示集群拓撲任務處理的功率,Time表示集群拓撲執行任務的總時間.現將式(13)代入式(22),化簡可得:
Energy=Power×(Timedisk+Timepro).
(23)
若集群拓撲在任務處理的過程中出現拓撲報錯,則系統的能耗為

(24)
其中,Energy1表示出現拓撲報錯后集群的能耗,Power1表示出現拓撲報錯后集群的平均功率.若集群拓撲在任務處理的過程中出現資源瓶頸,則系統的能耗為
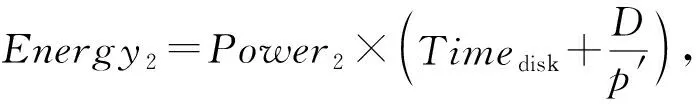
(25)
其中,Energy2表示出現資源瓶頸后集群的能耗,Power2表示出現資源瓶頸后集群的平均功率.若原集群拓撲在執行任務出現拓撲報錯或資源瓶頸時,使用數據恢復模型,則系統的能耗為
Energy3=
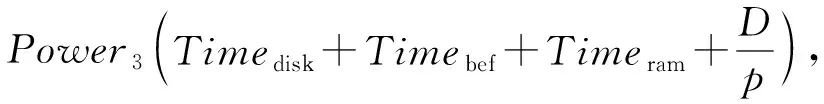
(26)
其中,Energy3表示使用數據恢復模型后集群的能耗,Power3表示使用數據恢復模型后集群的平均功率.則集群使用數據恢復模型后,節約的能耗Energysave為

(27)
其中,式(27)內的參數與式(24)~(26)相同.
3 節能策略分析
在理論模型的基礎上,提出基于Storm平臺的數據恢復節能策略,該策略包括吞吐量檢測算法與數據恢復算法,通過在原集群拓撲執行任務出現拓撲報錯或資源瓶頸時,終止拓撲內的任務并通過備份節點內存讀取數據,以此降低了系統計算延遲與能耗開銷.該策略主要分為4個步驟:
1) 選擇內存資源占用率最低的工作節點作為備份節點,并對備份節點的內存進行邏輯分割以用于數據存儲.
2) 根據拓撲信息監控模型判斷集群拓撲是否出現資源瓶頸或拓撲報錯.
3) 根據數據恢復模型從備份節點的內存向集群拓撲讀取數據.
4) 根據節能策略計算集群的延遲與能耗開銷.
具體流程圖如圖4所示:

Fig. 4 Flowchart of energy-efficient strategy圖4 節能策略流程圖
3.1 吞吐量檢測算法
為監控集群拓撲在執行任務時是否會出現資源瓶頸或拓撲報錯的問題,需要設計吞吐量檢測算法.其中該算法需要對集群拓撲內的元組進行標記,并根據計算集群吞吐量判斷拓撲內的任務執行情況.該算法保證集群的實際吞吐量低于閾值下限時,終止拓撲內的任務.由于需要對整個集群拓撲內的數據信息進行遍歷,因此需要確定工作節點與各個任務之間的對應關系.具體情況在算法1中描述.
算法1.吞吐量檢測算法.
輸入:集群拓撲的任務集合T(N)={ti1,ti2,…,tin}、時間窗口長度w、數據的標記信息Mlab、集群實際吞吐量p、集群吞吐量的閾值下限pval;
輸出:判斷是否終止集群拓撲內的任務.
① newMlab(labletuple);*對集群內的元組信息進行標記*
②WindowLength=w;*滑動時間窗口的長度為w*
③ fortid=ti1toT(N).tindo
④NWordNode=NNimbus;*工作節點將數據信息匯總至主控節點*
⑤ 心跳信息轉化為集群吞吐量;
⑥ 根據式(7)計算集群吞吐量;
⑦ switchpval=pthen
⑧ case1:
⑨pval-p=pval;*出現拓撲報錯*
⑩ 終止集群拓撲內的任務;
算法1的輸入參數為集群拓撲的任務集合、時間窗口長度、數據的標記信息、集群實際吞吐量以及集群吞吐量的閾值下限;輸出參數為判斷是否終止集群拓撲內的任務.行①②表示對集群拓撲內的元組進行標記,并設置滑動時間窗口的長度;行③④表示遍歷整個集群拓撲內的任務信息,并以心跳信息的形式返回Nimbus節點;行⑤⑥表示心跳信息轉換為集群吞吐量,并根據式(7)計算集群的實際吞吐量,以判斷拓撲內的任務實際運行情況;行⑦~表示集群實際吞吐量與閾值下限進行對比,共存在3種情況,當出現拓撲報錯與資源瓶頸時,終止集群拓撲內的任務,當集群實際吞吐量高于或等于閾值下限時,集群拓撲內的任務正常執行.
由算法1可知,DR-Storm首先需要確定集群是否出現資源瓶頸與拓撲報錯,由此判斷是否終止集群拓撲內的任務.為滿足監控集群拓撲內的數據信息,需要對其元組進行標記,并設置滑動時間窗口,其中滑動時間窗口的取值通過式(4)(5)選擇確定.按照心跳信息的形式對主控節點進行反饋,根據反饋結果計算集群實際吞吐量,并與集群吞吐量的閾值下限進行對比,以此判斷集群任務處理的狀態.
基于Storm的節能策略首先需要判斷是否影響集群的性能,而Storm集群默認的輪詢調度策略,其時間復雜度為O(n).算法1首先對集群拓撲的元組進行標記并設置滑動時間窗口的長度,其時間復雜度為O(1);其次算法1需要對整個集群拓撲內的數據信息進行遍歷,并以心跳信息的形式返回Nimbus節點,類似于輪詢調度算法,因此其時間復雜度為O(n);最后算法1通過計算集群實際吞吐量,并與閾值下限進行對比,確定拓撲內的任務實際運行情況,從而判斷是否終止集群拓撲內的任務,其時間復雜度為3O(1).則算法1的時間復雜度T(A)為
T(A)=O(1)+O(n)×3O(1)=O(n).
(28)
3.2 數據恢復算法
為滿足算法1終止任務后恢復集群拓撲內的數據,提出數據恢復算法.該算法主要由3部分組成:1)根據工作節點的內存資源占用率選擇備份節點,并對備份節點的內存進行邏輯劃分;2)備份節點存儲數據后要滿足節點資源約束;3)集群拓撲內的數據處理完成后,實時刪除備份節點內存儲的數據.具體情況在算法2中描述.
算法2.數據恢復算法.
輸出:集群拓撲內的任務順利執行.

② 根據式(9)確定集群備份節點;
③ end for

⑤ 磁盤向備份節點的內存發送數據;
⑥ 備份節點的內存資源占用滿足式(10);
⑦ if集群出現拓撲報錯then
⑧ 集群拓撲從備份節點內存讀取數據;
⑨ end if
⑩ if集群出現資源瓶頸then
算法2的輸入參數為節點的內存資源占用率集合;輸出參數為集群拓撲內的任務順利執行.行①~③表示通過遍歷集群節點內存資源占用選擇備份節點;行④~⑥表示邏輯分割備份節點的內存,使磁盤向備份節點的內存發送數據時滿足式(10);行⑦~表示集群出現拓撲報錯或資源瓶頸時,拓撲從備份節點內存讀取數據;行表示集群完成數據恢復后,根據算法1重新判斷是否出現拓撲報錯或資源瓶頸;行表示實時刪除備份節點內存儲的數據,防止因集群備份節點內存空間不足而造成資源瓶頸的問題.
由算法2可以看出,數據恢復算法根據算法1執行情況判斷是否對拓撲內的數據進行恢復.數據恢復算法首先根據集群內節點的內存資源約束,確定備份節點用于數據存儲.其次若反饋信息顯示集群拓撲出現資源溢出或拓撲報錯,則通過備份節點內存向集群拓撲讀取數據,并將其元組重新返回算法1進行標記.數據恢復算法保證了可以快速恢復集群拓撲內的數據,進而減少集群的計算延遲.
為確定數據恢復算法對集群性能帶來的影響,現計算數據恢復算法的時間復雜度.1)算法2通過遍歷節點內存資源占用率確定備份節點,其時間復雜度為O(n);2)算法2確定備份節點的內存滿足資源約束,其時間復雜度為O(1);3)判斷集群是否出現拓撲報錯,從而進行數據恢復,其時間復雜度為O(1);4)判斷集群是否出現資源瓶頸,從而進行數據恢復,其時間復雜度為O(1);此外集群完成數據恢復后,重新將任務返回算法1,其時間復雜度為O(1);最后算法2實時刪除備份節點內存儲的數據,其時間復雜度為O(1).則算法2的時間復雜度T(B)為
T(B)=O(n)+5O(1)=O(n).
(29)
此外,DR-Storm由算法1與算法2組成,則該策略的時間復雜度T(C)為
T(C)=O(n)+O(n)=O(n).
(30)
3.3 算法的部署與實現
在Storm的基本架構中,1個完整的流式作業通常由主控節點(運行Nimbus進程)、工作節點(運行Supervisor進程)與關聯節點(運行Zookeeper進程)協同完成計算.其中Nimbus進程為Storm框架的核心,負責接受用戶提交的拓撲并向工作節點分配任務;Supervisor進程負責監聽Nimbus進程分配的任務并啟動工作進程及工作線程;Zookeeper進程負責其他節點的分布式協調工作,并存儲整個集群的狀態信息與配置信息.為了部署與實現基于Storm平臺的數據恢復節能策略,本研究在Storm原有架構基礎上新增了4個模塊,如圖5所示.各模塊功能介紹如下:
1) 負載監控器(load monitor).負責監控集群拓撲信息、工作節點的各類資源占用信息.具體實現需添加在拓撲組件各Spout的open()和nextTuple()方法以及各Bolt的prepare()和execute()方法中.
2) 數據庫(database).負責收集負載監控器發送的信息與拓撲任務分配信息,并實時更新.
3) 滑動時間窗口模塊(slide time window module).部署算法1,通過標記集群拓撲元組,并讀取數據庫的信息,設置滑動時間窗口的長度,執行吞吐量檢測算法.
4) 數據恢復模塊(data recovery module).部署算法2,通過算法1返回心跳信息的結果,執行數據恢復算法.
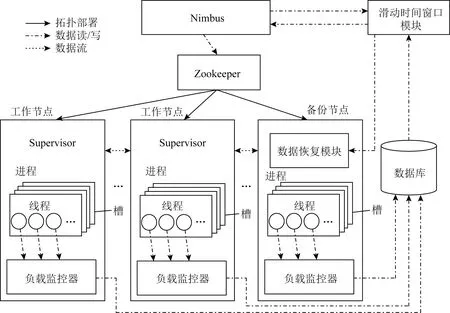
Fig. 5 Improved architecture of Storm圖5 改進后的Storm框架
此外,代碼編譯完成后,通過打jar包分組至主控節點Nimbus的STORM_HOMElib目錄下,并在confstorm.yaml中配置好相關參數后運行.
本文提出算法1與算法2設計并實現了基于Storm平臺的數據恢復節能策略,減少了集群的計算延遲,并節約了能耗.
4 實驗結果及數據分析
為了驗證DR-Storm的計算延遲與能耗,本文通過設置對比實驗,分別將DR-Storm與原集群及其相關研究成果進行對比.實驗選擇4組代表不同作業類型的標準Benchmark進行測試,最后對實驗結果進行討論與分析.
4.1 實驗環境
實驗搭建的集群由19臺同構的PC機組成.其中Storm集群包含1個主控節點(運行Nimbus進程、UI進程與數據庫)、16個工作節點(運行Supervisor進程)以及3個關聯節點(運行Zookeeper進程).此外,集群每臺PC機的網卡配置為100 Mbps LAN;內存為8 GB;硬盤容量為250 GB,轉速為7 200 rmin,接口為SATA3.0.除硬件配置外,各節點軟件配置相同,具體結果如表1與表2所示:
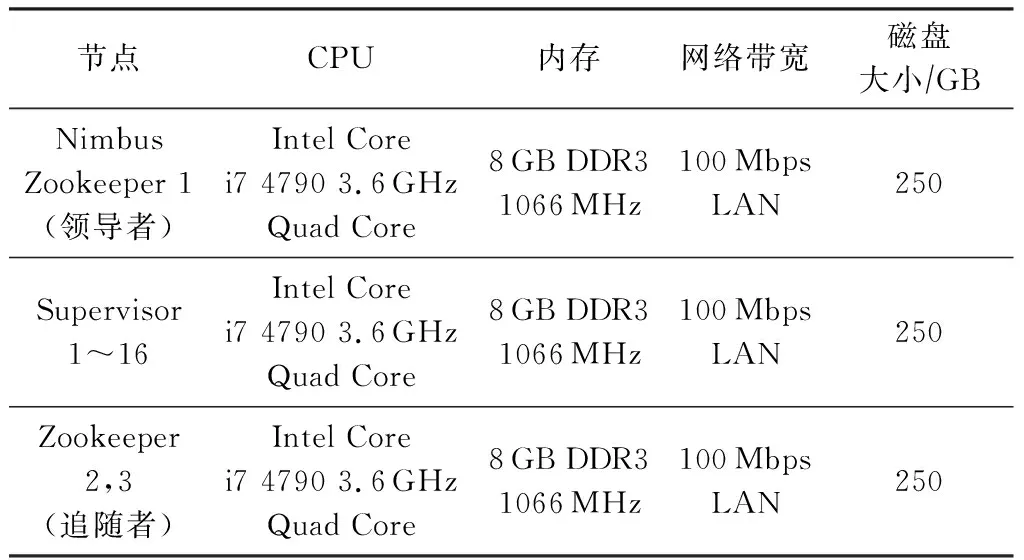
Table 1 Hardware Configuration of Storm Cluster表1 Storm集群的硬件參數配置

Table 2 Software Configuration of Storm Cluster表2 Storm集群的軟件參數配置
此外,為了檢驗不同基準測試下節能策略的效果,實驗選取Intel公司Zhang[16]發布在GitHub上的4組Benchmark進行測試,分別為CPU敏感型(CPU-sensitive)的WordCount、網絡帶寬敏感型(network-sensitive)的Sol、內存敏感型(memory-sensitive)的RollingSort以及Storm在真實場景下的應用RollingCount.表3為4組基準測試各項參數的基本配置,部分參數需要進一步說明如下:component.xxx_num為集群內組件的并行度;Sol中的topology.level為集群拓撲的層次,由于1個Spout對應2個Bolt,因此集群拓撲的層次設置為3;topology.works統一設置為16,表示集群內1個工作節點內僅分配1個工作進程;topology.acker.executors統一設置為16,表示滿足集群數據流的可靠傳輸;最后統一設置每個message.size等于1個tuple的大小.
為對比DR-Storm的效果,本文還與LEEDSP[19],DMM-Storm[37]進行了對比實驗.其中LEEDSP的核心思想是彈性調節集群節點的資源,并通過DVFS技術動態調節節點CPU的電壓,以此達到節能的效果,且該策略為流式處理節能策略的主要代表,適用于大多數流式處理平臺(如Storm,Spark Streaming[11],Flink[12]等);DMM-Storm的核心思想為使用DVFS降低被遷移任務后工作節點的電壓而達到節能的效果.此外DMM-Storm由關鍵線程中的數據遷移合并節能算法(energy-efficient algorithm for data migration and merging among critical executor, EDMMCE)與非關鍵線程中的數據遷移合并節能算法(energy-efficient algorithm for data migration and merging among non-critical executor, EDMMNE)組成.為保證在同等條件下驗證本文策略的有效性,LEEDSP,DMM-Storm的相關參數與DR-Storm保持一致.
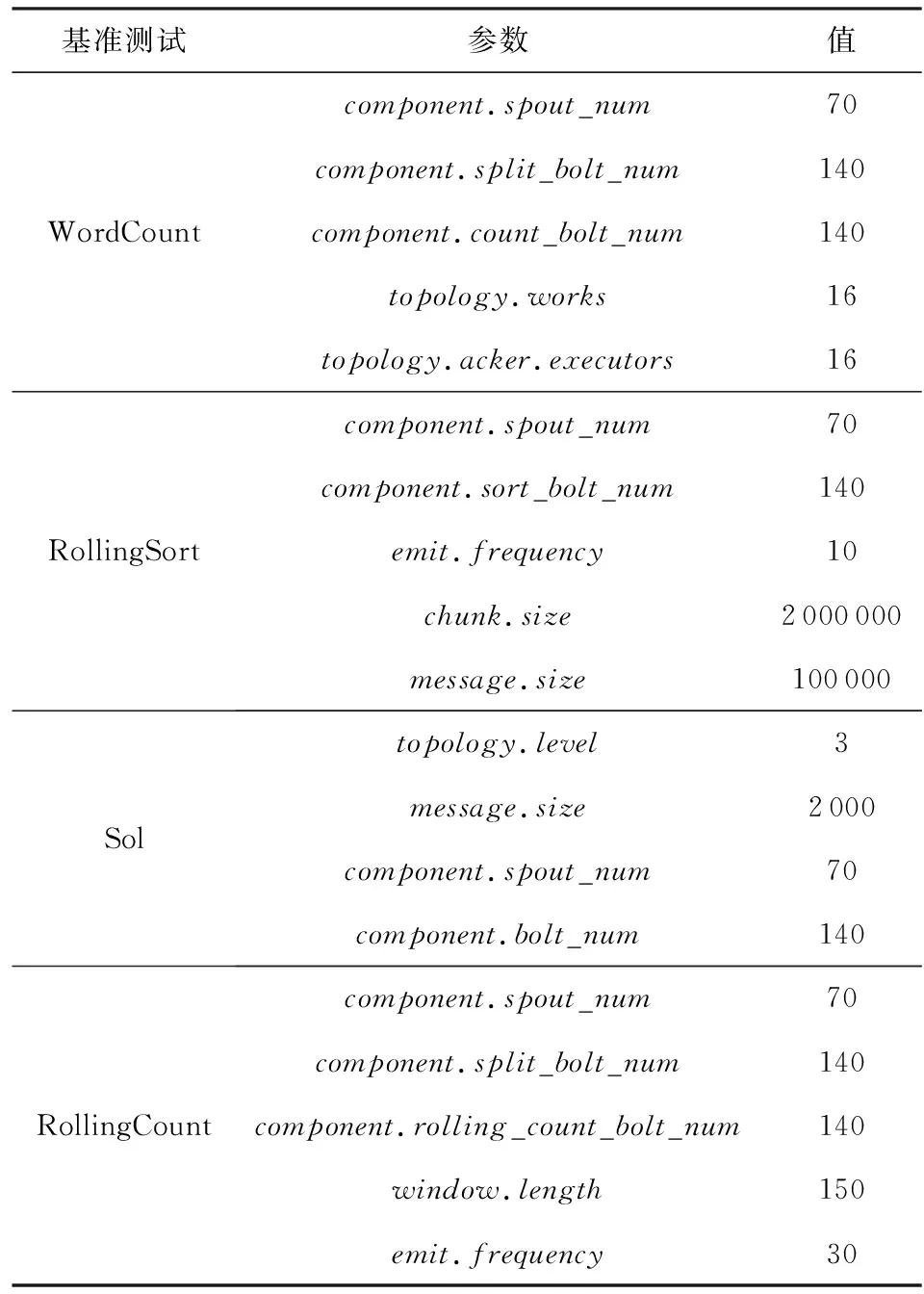
Table 3 Configuration of Benchmarks表3 基準測試參數配置
為選擇合適的時間窗口用于檢測集群拓撲內數據的信息,本文以WordCount為例在集群默認調度策略下,根據增加的網絡資源占用率與系統延遲對集群性能的影響選擇合適的時間窗口長度,具體的結果如表4所示:

Table 4 Choose of Time Windows表4 時間窗口的選擇
其中I的取值根據式(4)(5)確定.根據表4可知,當時間窗口長度為10 s,20 s時,集群增加的網絡資源占用率較大,且I值較高.其原因為時間窗口取值較低而導致集群內數據庫的讀寫過于頻繁,讀寫數據庫產生的網絡資源占用率相對較大,從而對集群拓撲內的任務處理性能造成影響.當時間窗口長度為40 s,50 s時,集群內增加的系統延遲與I值較高,已影響到集群拓撲內的任務正常執行.其原因為集群內數據庫的讀寫過于緩慢,影響拓撲內數據信息的獲取時間,進而延誤了DR-Storm的觸發時間,造成影響集群性能的問題.綜上所述,時間窗口的取值設置為30 s,在該時間窗口長度下能夠較好滿足實驗的執行.同理可得Sol,RollingSort,Rolling-Count的時間窗口長度.
此外,為便于數據統計,以下測試均設置metrics.poll=5 000,metrics.time=300 000,其單位為ms,即每組實驗每5 s進行1次采樣,時長為5 min.
4.2 工作節點的資源約束測試
為執行DR-Storm首先需要查找集群內的備份節點用于數據的存儲,而備份節點則需要根據集群內工作節點的內存資源占用情況確定.此外,為滿足集群內的任務順利執行,需要確定原集群內各節點的資源占用情況.具體結果如圖6所示.
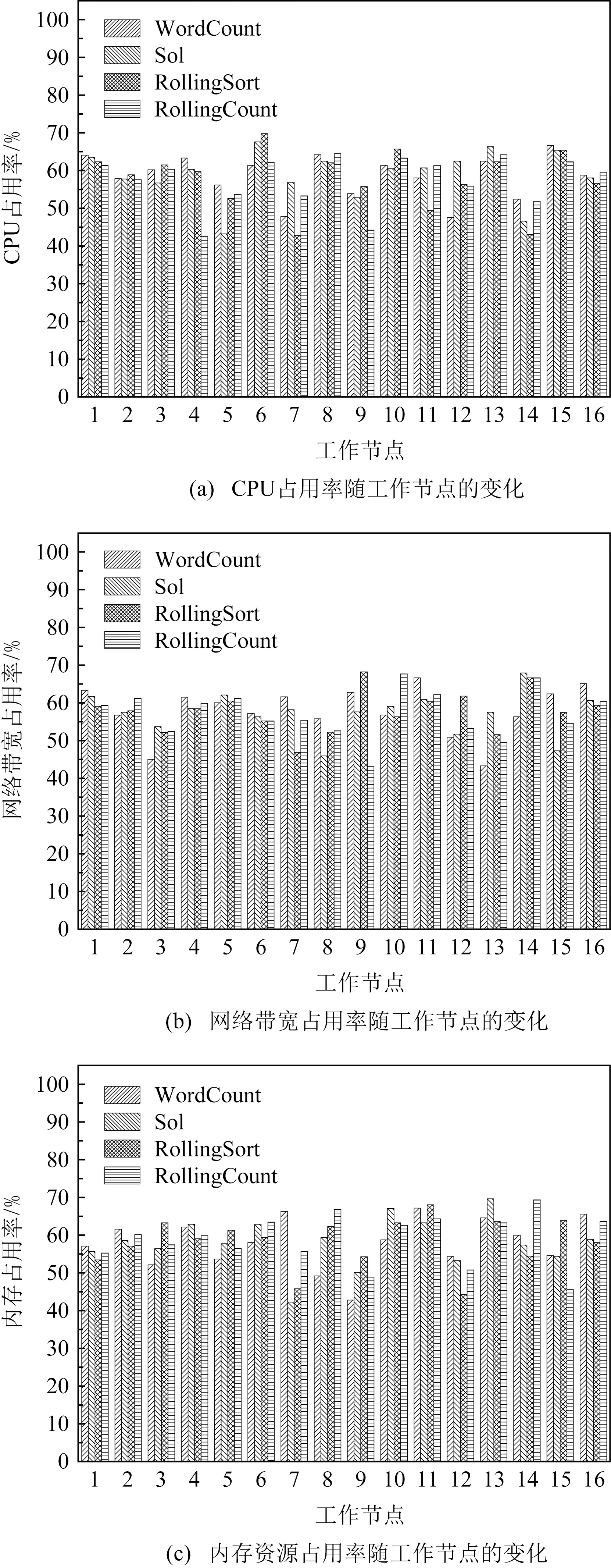
Fig. 6 Resources utilization of 16 work nodes in the original cluster圖6 原集群16個工作節點的資源占用率
圖6為集群運行4組基準測試后,16個節點的平均資源占用情況.由圖6可知,運行4組基準測試,集群內工作節點的資源占用率主要集中于40%~70%,滿足集群拓撲內的任務正常執行.由式(9)與圖6(c)可知,不同的基準測試由于其拓撲不同,節點平均內存資源占用率的最低值也不相同.其中原集群在WordCount下,9號節點的平均內存資源占用率最低為42.8%;原集群在Sol下,7號節點的平均內存資源占用率最低為42.3%;原集群在Rolling-Sort下,12號節點的平均內存資源占用率最低為44.3%;原集群在RollingCount下,15號節點的平均內存資源占用率最低為45.7%.則根據不同的基準測試,選擇平均內存資源占用率最低的節點為備份節點.為確定備份節點的內存進行數據存儲后,備份節點是否滿足資源約束,具體結果在圖7顯示.
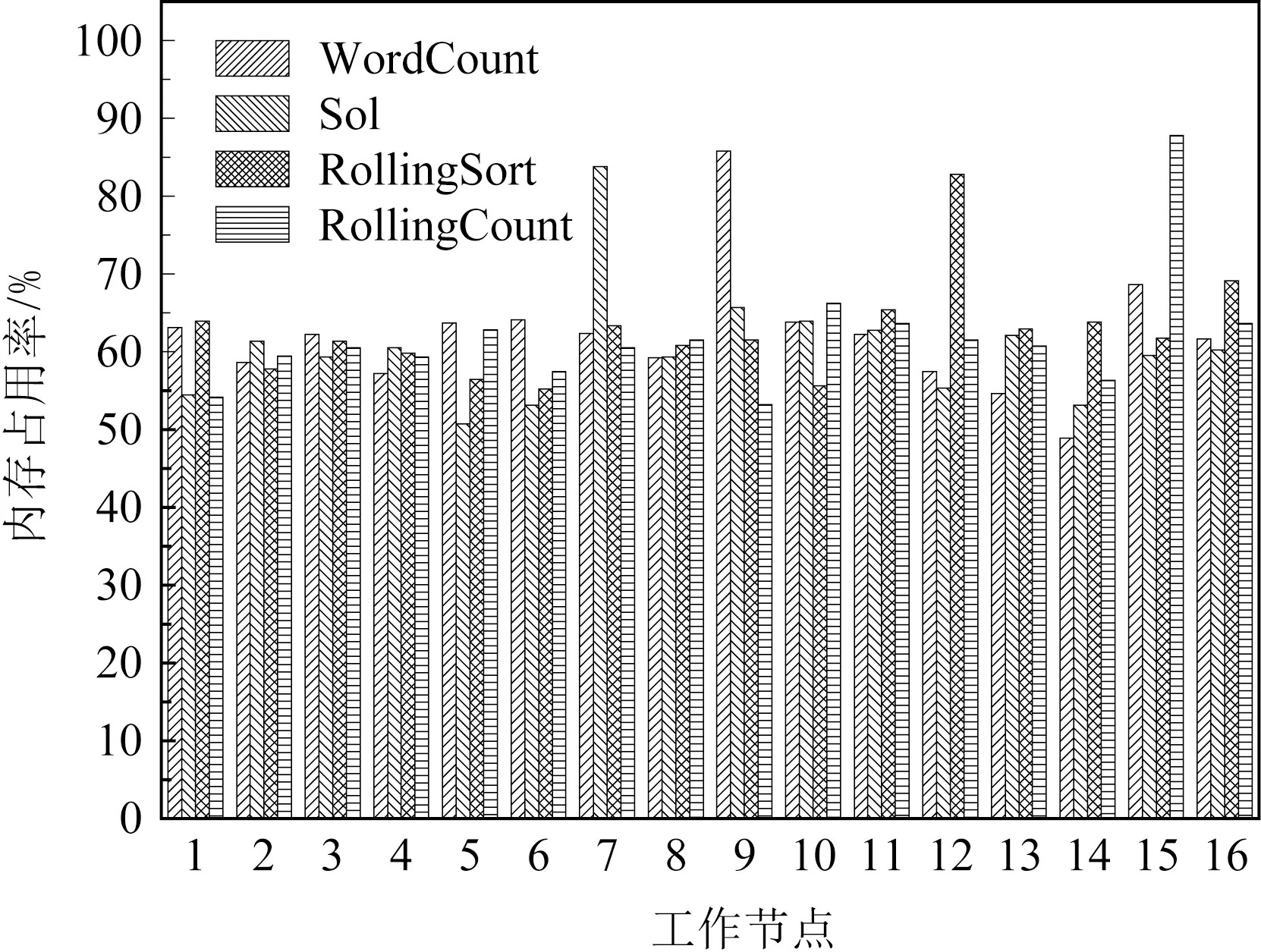
Fig. 7 Memory resources utilization after the backupnode store data圖7 備份節點存儲數據后的內存資源占用率
圖7為集群內備份節點存儲數據后節點的平均內存資源占用率.根據圖7可知,集群內4個備份節點的平均內存資源占用率遠高于原集群的相同節點,其內存資源占用率主要集中于80%~90%.其原因為備份節點的部分內存用于數據存儲,由于集群拓撲未發生改變,則集群節點數據的處理未發生改變,因此備份節點的內存資源占用率等于原節點用于數據處理的內存資源占用率與備份節點用于數據存儲的內存資源占用率之和,滿足式(10).
為檢測執行DR-Storm對集群性能造成的影響,需要測試集群的平均吞吐量.現計算原集群出現資源瓶頸、拓撲報錯與執行DR-Storm時對集群平均吞吐量的影響,具體結果如圖8所示.
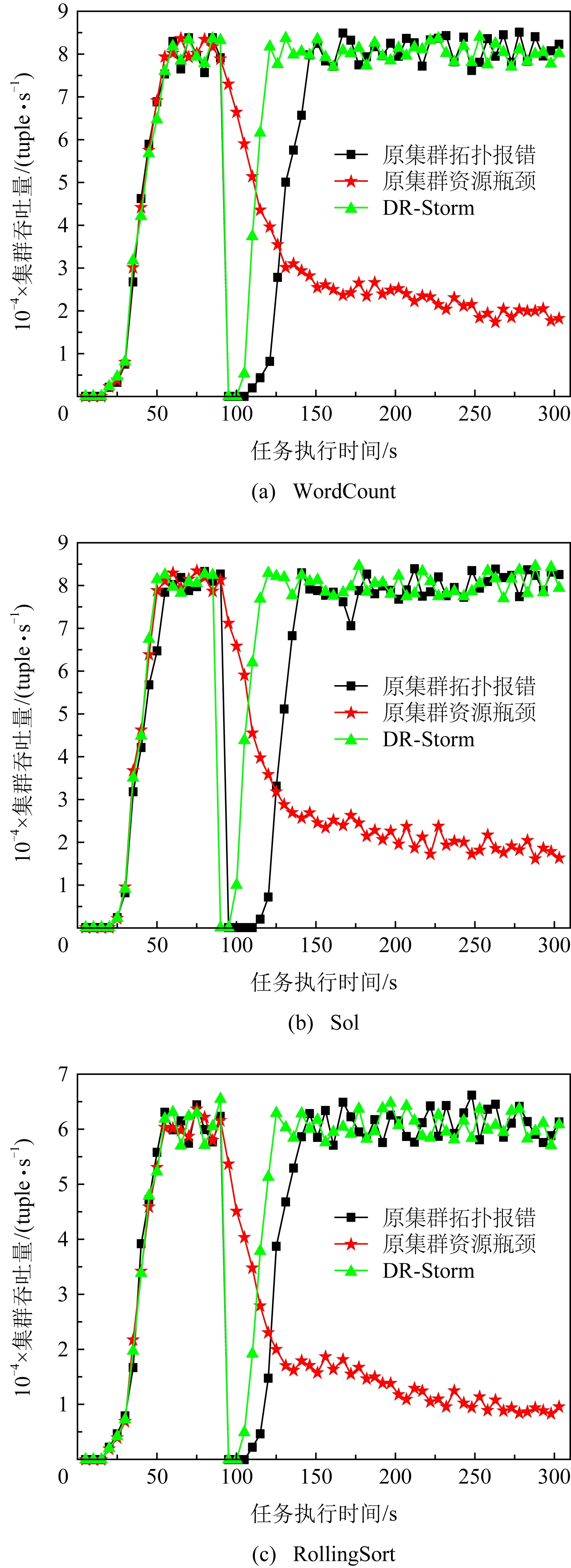
Fig. 8 Comparison of throughput under different benchmarks圖8 在不同的基準測試下比較吞吐量
圖8為集群執行3組(WordCount,Sol,Rolling-Sort)基準測試后,策略對集群平均吞吐量的影響.由圖8可知,在95 s前集群的吞吐量基本相同,這是由于集群在出現資源瓶頸或拓撲報錯前,未觸發DR-Storm,拓撲任務始終執行默認處理機制.
在95 s左右,由于出現節點計算資源不足或網絡故障等原因,而造成資源瓶頸或拓撲報錯的問題,其原因為節點間的數據傳輸量較大,容易導致集群內網絡傳輸出現擁擠現象,造成節點間計算資源不足或網絡故障的問題.由于在95 s左右發生網絡擁擠現象,故通過執行DR-Storm,重啟集群拓撲緩解網絡傳輸壓力,解決網絡擁塞的問題.
集群執行DR-Storm的平均吞吐量為68 927 tuples,70 913 tuples,51 855 tuples,相比于原集群拓撲報錯,執行DR-Storm時集群的平均吞吐量略高于原集群拓撲報錯.這是由于原集群出現拓撲報錯,集群拓撲從磁盤讀取數據,而執行DR-Storm,集群拓撲從內存讀取數據,數據恢復過程中的時間間隔較短,故對集群吞吐量的影響較小.相比于原集群資源瓶頸,執行DR-Storm時集群的平均吞吐量遠高于原集群資源瓶頸,這是由于原集群出現資源瓶頸時,節點的各類資源占用率不斷升高,集群拓撲的任務處理出現擁擠,集群默認策略的時間復雜度不斷上升,集群拓撲任務執行效率不斷下降,集群的吞吐量降低,而執行DR-Storm時,集群拓撲在經歷短暫重啟后迅速恢復了其吞吐量.因此原集群資源瓶頸時,執行DR-Storm的吞吐量遠高于原集群.此外,集群執行DR-Storm在95 s~115 s之間的集群吞吐量從0逐步上升,其原因為這段時間內終止了集群拓撲內的任務,并從備份節點內存重新讀取任務,但是由于從內存讀取數據時間間隔相對較短,因此對集群整體性能的影響較小.
4.3 節能策略的實驗結果與分析
針對DR-Storm的效果可通過系統延遲與能耗2個標準進行評估.
1) 系統延遲
系統延遲是評估策略是否影響集群性能的重要指標之一,本文根據式(16)(18)(20)對單位時間內集群拓撲任務處理的延遲進行計算,具體結果如圖9所示.此外還可通過Storm框架自身提供的Storm UI[8]進行統計.
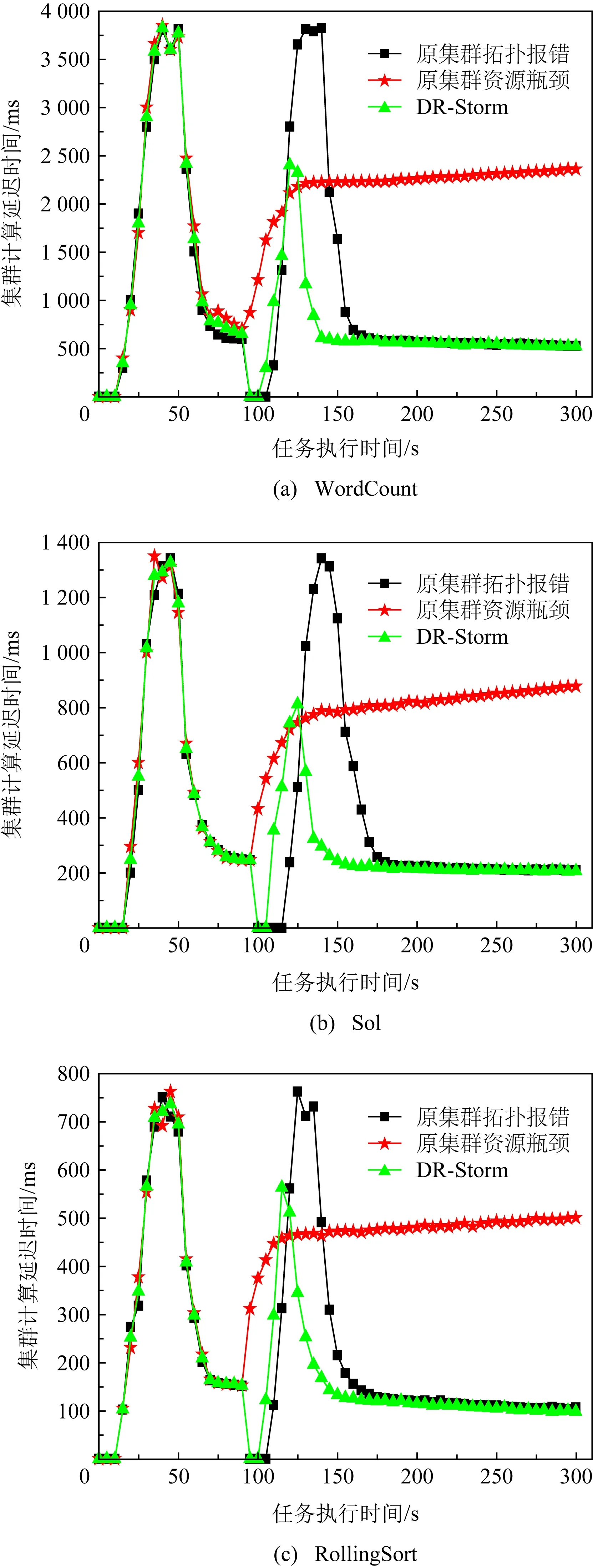
Fig. 9 Comparison of system latency under different benchmarks圖9 在不同的基準測試下比較系統的延遲
圖9為在各基準測試(WordCount,Sol,Rolling-Sort)下,單位時間內集群拓撲任務處理的延遲.由圖9可知,95 s前DR-Storm與原集群拓撲任務處理的延遲基本相同,這是由于集群拓撲在這段時間內進行任務部署,且集群并未觸發資源瓶頸與拓撲報錯.95s后觸發資源瓶頸與拓撲報錯,集群執行DR-Storm的平均延遲為660.2 ms,256.2 ms,143.9 ms,相比于原集群出現資源瓶頸其延遲降低了69.7%,67.9%,69.6%.這是由于原集群出現資源瓶頸各節點的計算資源不足,致使拓撲內的任務處理速度受到影響,故集群計算資源越來越接近溢出導致系統延遲不斷上升,集群于95 s~125 s內,共耗時約30 s,執行DR-Storm,使集群延遲在140 s后逐步趨于穩定,最終導致執行DR-Storm的計算延遲遠低于原集群.此外,集群執行DR-Storm存在1個峰值,這是由于執行策略在95 s左右終止了集群拓撲內的任務,并通過備份節點的內存對拓撲內的任務進行重新部署,但由于時間間隔較短,因此對整個集群拓撲內的任務處理影響較小.相比于原集群出現拓撲報錯其延遲降低了31.4%,27.5%,22.3%,其原因為雖然原集群出現拓撲報錯延遲趨于穩定后與執行DR-Storm基本相同,但由于原集群在終止任務后從磁盤對拓撲內的任務進行部署,時間間隔為95 s~155 s,共耗時約60 s,且存在峰值為3 821 ms,1 342 ms,763 ms,嚴重影響了集群拓撲任務的正常處理,因此DR-Storm的效果優于原集群.此外3組基準測試的延遲并不相同,這是由于不同基準測試的拓撲并不相同,且節點內的線程數量也不相同,但并不影響集群拓撲任務的執行結果.圖10為集群在實際應用場景下拓撲任務處理的延遲.

Fig. 10 Comparison of system latency under the RollingCount圖10 在RollingCount下比較系統的延遲
如圖10所示,集群在RollingCount下執行DR-Storm的平均延遲為497.2 ms,相比于原集群出現資源瓶頸與拓撲報錯其延遲降低了72.4%,26.7%,因此與原集群相比,執行DR-Storm具有更好的集群性能.
2) 集群能耗
集群能耗是反映節能策略效果的重要指標之一,本文通過拓撲執行任務的功率與時間相乘計算集群的能耗,并根據式(27)計算執行DR-Storm相比于原集群節約的能耗.此外引入LEEDSP,DMM-Storm與DR-Storm作對比,以驗證DR-Storm的實際效果.為計算集群能耗需要統計單位時間內集群執行不同策略的功率,具體結果如圖11所示:

Fig. 11 Comparison of power on RollingCount among different strategies圖11 RollingCount在不同策略下的功率對比
圖11為在RollingCount下集群執行不同策略的功率對比.根據圖11可知,集群執行DR-Storm的平均功率為1 073.34 W;原集群出現拓撲報錯與資源瓶頸的平均功率分別為1 103.69 W,1 244.01 W;執行LEEDSP拓撲報錯與資源瓶頸的平均功率分別為1 070.43 W,1 207.03 W;執行EDMMNE拓撲報錯與資源瓶頸的平均功率分別為984.89 W,1 268.70 W;執行EDMMCE拓撲報錯與資源瓶頸的平均功率分別為1 004.97 W,1 274.21 W.
根據11(a)可知,執行DR-Storm相比于原集群的功率降低了2.7%,13.7%,且在95 s前原集群與DR-Storm的功率基本相等.這是由于95 s前并未出現拓撲報錯與資源瓶頸,DR-Storm尚未觸發.95 s后集群功率波動較大,其原因為在95s后集群出現拓撲報錯與資源瓶頸,執行DR-Storm拓撲終止任務后,從備份節點內存讀取數據.原集群出現拓撲報錯終止任務后,從磁盤讀取數據,而從內存讀取數據消耗的功率小于磁盤內讀取數據,故集群功率趨于穩定后執行DR-Storm的功率略低于原集群出現拓撲報錯.原集群出現資源瓶頸,節點的資源占用持續上升,導致集群的功率不斷升高,因此原集群出現資源瓶頸的功率遠高于DR-Storm.
根據11(b)可知,DR-Storm,LEEDSP出現拓撲報錯的功率接近,低于LEEDSP出現資源瓶頸的功率,其原因為當集群出現資源瓶頸時,LEEDSP無法進行資源調度,節能策略失效,故與原集群出現資源瓶頸相同,節點的功率迅速上升.此外,雖然LEEDSP出現拓撲報錯與DR-Storm的功率接近,但由于LEEDSP進行資源調度,集群功率存在1個峰值,影響集群拓撲任務的正常執行,且LEEDSP由于使用DVFS技術調節節點電壓,集群節點的功率波動較大,非常不穩定,不適合部署在大規模的集群當中.
根據11(c)可知,DR-Storm的功率高于DMM-Storm出現拓撲報錯,低于DMM-Storm出現資源瓶頸的功率,這是由于當集群節點出現資源瓶頸時,集群節點內的任務無法正常進行遷移,故DMM-Storm失效,集群節點功率急速上升.雖然集群出現拓撲報錯時,DMM-Storm的功率低于DR-Storm,但DMM-Storm的功率因任務遷移同樣存在峰值,影響集群拓撲任務的正常執行.此外當出現資源瓶頸時,DMM-Storm完全失效,存在一定的缺陷,且DVFS的實現較為困難,因此同樣不適合部署在大規模的集群當中.為計算集群的能耗,需要對集群內的功率進行累加求和,具體結果如圖12所示:
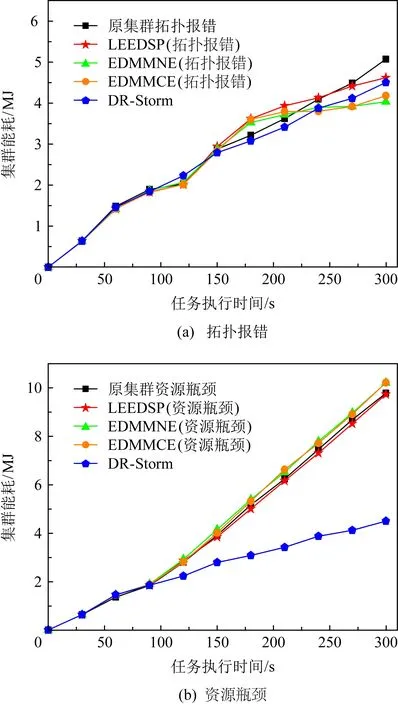
Fig.12 Comparison of energy consumption on RollingCount among different strategies圖12 RollingCount在不同策略下的能耗對比
圖12為在RollingCount下集群執行不同策略的能耗對比.根據圖12可知,集群在單位時間內執行DR-Storm的能耗為4.50 MJ;原集群拓撲報錯與資源瓶頸的能耗為5.07 MJ,9.79 MJ;執行LEEDSP拓撲報錯與資源瓶頸的能耗分別為4.62 MJ,9.73 MJ;執行EDMMNE拓撲報錯與資源瓶頸的能耗分別為4.03 MJ,10.22 MJ;執行EDMMCE拓撲報錯與資源瓶頸的能耗分別為4.18 MJ,10.22 MJ.
圖12(a)為集群出現拓撲報錯后不同策略的能耗對比,與原集群相比,執行DR-Storm的能耗降低了11.2%,但是在95 s~135 s內,DR-Storm的能耗在所有策略當中最高,這是由于執行數據恢復算法,集群拓撲內的數據從備份節點內存中讀取,且拓撲內的數據恢復時間較快,故集群節點的功率未下降至最低值,其他策略通過磁盤恢復集群拓撲內的數據,拓撲內的數據恢復時間較慢,集群內的功率降低至最低值,因此其他策略(包括原集群)在這段時間內的能耗低于DR-Storm.135 s后,執行DR-Storm的能耗趨于穩定,對于集群拓撲任務的整體處理影響較小.LEEDSP,DR-Storm的能耗接近,而DMM-Storm的能耗低于DR-Storm,但是由于LEEDSP,DMM-Storm都是使用DVFS技術進行電壓調節,功率的獲取存在較大的偶然性且容易對集群拓撲任務的正常執行帶來影響(LEEDSP容易帶來拓撲任務處理出現失衡的問題,DMM-Storm容易影響集群拓撲任務處理性能的問題),進而影響節能策略的實際效果.
圖12(b)為集群出現資源瓶頸后不同策略的能耗對比,與原集群相比,執行DR-Storm的能耗降低了54.1%,這是由于隨著集群內節點資源占用的不足,節點的功率持續上升,導致集群的能耗不斷增大.LEEDSP,DMM-Storm都是對資源遷移后的節點進行電壓縮放管理,但由于節點的資源占用已達到瓶頸,無法進行資源的遷移,故節能策略失效,集群還是按照系統默認機制進行任務的處理,與原集群的能耗基本相等.
此外,根據集群內功率與系統延遲的降低情況可以確定,當集群出現資源瓶頸時,執行DR-Storm的系統延遲每降低72.4%,功率下降13.7%,則集群的能耗節約54.1%;當集群出現拓撲報錯時,執行DR-Storm的系統延遲每降低26.7%,功率下降2.7%,則集群的能耗節約11.2%.因此,相比于原集群,本文提出的DR-Storm具有更好的節能效果.
5 總結與展望
高能耗問題已經成為制約綠色流式計算平臺發展的主要障礙之一,Storm作為最受企業界與學術界追捧的大數據流式計算平臺之一,在最初設計時并未考慮高能耗的問題,以至于影響平臺其他領域的發展.針對這一問題,本文通過研究Storm的框架結構與拓撲邏輯,建立了任務分配模型、拓撲信息監控模型、數據恢復模型以及能耗模型,并進一步提出了基于Storm平臺的數據恢復節能策略,該策略由吞吐量檢測算法與數據恢復算法組成,在減少系統計算延遲的前提下,降低了集群的功率,并節約了能耗.最后,實驗通過4組基準測試從資源占用、吞吐量、系統延遲與能耗的角度驗證了策略的效果.
下一步的研究工作主要包括3個方面:
1) 將DR-Storm部署到更為復雜的商業環境,使其具有更為廣闊的應用場景.
2) 與其他節能策略融合使用,達到雙重的節能效果.
3) 替換高能效的電子元件,在滿足節能的前提下,提高集群的性能.
猜你喜歡
江蘇安全生產(2023年1期)2023-02-08 05:58:38
資源節約與環保(2022年8期)2022-09-20 02:25:22
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
藝術品鑒(2020年7期)2020-09-11 08:04:44
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
當代貴州(2018年28期)2018-09-19 06:39:04
資源再生(2017年3期)2017-06-01 12:20:59
決策(2015年9期)2015-09-10 07:22:44
