面向高性能圖計算的高效高層次綜合方法
2021-04-01 01:18:06湯嘉武廖小飛
計算機研究與發展 2021年3期
關鍵詞:流水
湯嘉武 鄭 龍 廖小飛 金 海
(華中科技大學計算機科學與技術學院 武漢 430074) (大數據技術與系統國家地方聯合工程研究中心(華中科技大學) 武漢 430074) (服務計算技術與系統教育部重點實驗室(華中科技大學) 武漢 430074) (集群與網格計算湖北省重點實驗室(華中科技大學) 武漢 430074)
(jiawut@hust.edu.cn)
最近10年來隨著生物信息網絡、社交網絡、網頁圖等大數據分析問題的出現,圖應用變得越來越重要,圖是大數據關聯屬性的最佳表達方式,圖計算則是基于圖模式進行巨量、稀疏、超維關聯的挖掘和分析過程,當前大數據的機器學習和深度學習都依賴于圖計算,圖計算已經成為大數據處理的主流模式之一.
圖計算的復雜特性對當前硬件提出了新的挑戰,CPU和面向吞吐量的架構都有各自的局限性[1].對于通用的CPU,大量研究表明,即使對于最優的圖算法實現其指令級并行度仍然異常的低,絕大多數低于1.0,許多低于0.5[2].對于面向吞吐量的架構,比如GPU,按照單指令多數據(single-instruction multiple-data, SIMD)的方式執行,通過調度數以千計的線程來掩蓋耗時的內存訪問[3],雖然性能較高但是功耗巨大,圖數據的冪律分布和圖算法的不規則性天然對SIMD模式不友好,存在負載不均和低帶寬利用率問題,研究表明只有低于16%的時間GPU得到完全利用,主要性能瓶頸在于訪存單元在流水線中的停滯[4].
對于可重構硬件,例如現場可編程門陣列(field-programmable gate array, FPGA),由于其低功耗和可重構特性得到很大關注,研究人員在FPGA上針對圖計算設計了諸多高效的處理架構[5-8],體現了FPGA在圖計算領域的巨大潛力,而即使對于專業的研究人員,編寫完整的圖計算硬件代碼也是十分耗時的事情,一方面是圖計算自身的復雜性,另一方面是硬件編程過高的壁壘,表面上算法優化和架構設計是工作核心,實際上硬件語言的仿真測試、調試以及上板所必須的其他工作占了大量時間,因特爾公司指出1名資深的硬件工程師實現1個完整的最短路徑算法也需要幾個月的時間.
為了使FPGA開發人員從繁瑣的硬件細節中解脫出來,專心于算法本身和架構的設計,許多HLS系統被提出,大部分都采用CC++作為輸入并輸出寄存器傳輸級(register-transfer level, RTL)代碼,這極大地降低了硬件編程門檻并縮短了開發時間,HLS系統還提供了各種優化方法使得開發人員可以從高級語言層面對硬件結構進行優化,部分還提供了可視化的視圖方便對每個時鐘周期的電路行為進行分析,進一步提高了生成RTL的性能,但是目前與手動最優的RTL在面積和性能等多個方面有較大差距,特別地,針對圖計算這種不規則的復雜關聯應用,這一些現象尤為嚴重,這是由于HLS系統自身的結構特性造成的,具體而言:
1) 采用C或類C語言作為輸入,從這種命令式語言中很難提取到結構信息和并行特性,難以發掘其中的優化機會.
2) 優化指令和算法雜糅在一起,如果要進行算法結構上的變更必須修改大量代碼,編程效率低下,無法快速找到較好的算法結構和優化方案.
3) 優化指令不友好,由于輸入語言的原因,只有開發人員對硬件底層細節十分了解才能寫好優化指令,比如某一段程序想要并行執行,開發人員得自己設計好數據存儲和劃分,否則HLS系統會大量復制數據占用稀缺的片上存儲或者因為存儲空間不夠而自動取消并行,但是這些對開發人員是隱藏的,只能在生成RTL后通過硬件代碼或者資源利用情況判斷.
4) 中間表示(intermediate representation, IR)粒度太細,輸入的上層代碼編譯為最基本的操作,完全喪失了結構特性,底層硬件模板也是基本操作的簡單實現,會造成電路邏輯的大量冗余和關鍵路徑的延長,降低可讀性,同時與手寫代碼相比也要遜色許多.
5) 調度算法不高效,系統最耗時的部分就是調度部分,由于FPGA的天然并行特性,沒有依賴的邏輯是可以并行執行的,為了縮短關鍵路徑提高系統頻率,組合邏輯不應該過長,這要求可以并行的盡量放到同一個時鐘周期中執行,由于IR粒度太細,指令數目巨大,現有調度算法只能在可接受時間內找到次優解,或者直接采用簡單的啟發式算法,面對潛在的依賴關系沒有很好的方法解決或者直接串行執行,特別是圖計算這類不規則應用,對優化指令也沒有特定的支撐,這也是片上存儲資源被不必要地大量消耗和表面并行實則串行的原因.
6) 不支持片外數據傳輸,HLS系統不能自動生成存儲控制器和與主機端以及DRAM數據傳輸的接口,只能生成邏輯電路后手動編寫添加相應模塊,對于上板需求而言十分不便,同樣要求開發人員對底層內存系統細節十分了解,沒有從根本上提高硬件設計的抽象層次.
HLS系統整體流程也導致了編譯和綜合流程對開發人員不透明,難以通過在上層調整高級語言代碼從而在底層實現特定硬件架構,底層低效的硬件模板既無法靈活表達上層需求,也不能達到高效性能,特別是對現在一些復雜的特定應用,HLS系統的作用非常有限.因此出現了一些領域特定語言(domain-specific language, DSL),對特定領域需求作了相應的優化,從上層編程語言到底層硬件模塊都作了對應修改,取得了很好的效果,但是對于圖計算這類非規則的復雜應用還沒有很好的支撐,與其特性不能很好地契合,目前還沒有一個專門面向圖計算的HLS系統.
為了解決HLS系統缺乏對圖計算有效支撐的根本問題,提出了一種面向圖計算的高效HLS方法,通用自定義的編程原語編寫圖算法作為輸入,自動輸出RTL代碼.本文主要貢獻有4個方面:
1) 提出了一種面向圖計算的高效HLS方法,采用數據流架構實現高效的并行流水執行.
2) 提出了面向圖計算的函數式編程原語和對應的優化指令,可簡潔高效地表達各類圖算法.
3) 提出了模塊化的數據流IR,細粒度地暴露出圖算法中的點邊不規則并行性.
4) 提供參數化硬件模板,生成了BFS和PageRank算法的硬件實現,通過在不同數據集上的實驗結果驗證了方法的正確性和高效性.
1 相關工作
當前的FPGA設計工具支持相對原始的編程接口,需要大量的手動工作[9],Verilog和VHDL等硬件描述語言專為任意電路描述而設計.時序、控制信號和內存均由用戶處理.而Chisel[10],MyHDL[11],VeriScala[12]這樣的語言通過在軟件語言(例如Scala或Python)中使用硬件描述語言來簡化程序生成電路.Genesis2[13]為SystemVerilog添加了Perl腳本支持,以幫助推動程序生成.雖然與Verilog生成語句相比,這些改進允許更強大的元編程,但用戶仍然在時序電路級別編寫程序.
HLS系統提高了設計層級[14],比如LegUp[15],Lime[16],Vivado HLS[17],OpenCL[18],SDAccel[19],允許用戶用類C語言或者OpenCL進行FPGA設計,存儲單元用數組表示,整個應用不包含時序.但是對于圖算法中的嵌套循環,使用這些工具進行內層循環流水執行、循環展開、內存劃分、內存復制和建立緩沖區時,由于這些工作均由編譯器完成,命令式的設計描述給編譯器發現并行性、流水結構和內存訪問模式帶來了很大的困難,因此要求用戶進行顯示地標注,對用戶提出了很高的要求,而且數組很難映射到圖計算所需要的各種硬件存儲單元.
有工作采用多面體工具在單循環嵌套中自動對仿射訪問進行內存劃分[20],但是不能解決圖計算中非仿射訪問的情況和多循環嵌套中訪問相同存儲單元的情況.也有工作可以輔助對HLS程序中的編譯指示進行自動調整,但仍需要手動硬件優化.總而言之,HLS工具不能很好地挖掘粗粒度流水執行和嵌套循環并行的機會,同樣簡單的存儲模型對高并行流水的支持也不足.
DSL在提高設計層級的同時對特定領域進行了相應優化,DHDL[21]可以描述無時序嵌套并行的流水結構并將其轉化到硬件模塊,Spatial[22]是DHDL的改良版本,可以支持有數據依賴的控制流和豐富的存儲單元表達.但是對于圖計算這種非規則的應用,當并行執行時產生大量數據沖突,Spatial的內存劃分機制對其支撐不足,會簡單地對片上存儲單元進行復制操作,快速用完稀缺的存儲資源,無法實現高并行度.
在HLS系統中使用動態調度可以實現更高效的流水結構,ElasticFlow[23]可以對一類特定的不規則循環進行循環流水化,Dai等人[24]通過調度流水結構的多個啟動間隔實現流水線沖刷,他們后來開發了應用特定的動態沖突檢測電路,但是有嚴格的約束.Nurvitadhi等人[25]通過假定數據通路已經劃分到了流水線各個階段來實現自動流水化.這些方法還是基于傳統HLS系統中的靜態調度,引入了一些動態行為,只能在特定的情況下得到性能提升.
目前還沒有HLS工具可以從上層高級語言為圖算法直接生成高并行度的高效流水結構,一方面因為其表達能力有限,用戶很難準確描述所要的架構并指定微架構參數,另一方面對圖算法指定高并行度后會產生大量數據依賴和沖突,沒有足夠的底層優化去實現高并行度所需的存儲和計算結構,導致最后生成的硬件電路實際串行執行或者資源耗盡無法生成.
本文通過底層采用特定于圖算法的優化數據流架構和定制的存儲層級結構針對上述HLS工具中難以對圖算法高并行度執行和存儲模型低效的問題提出了解決方法,為從上層語言生成圖應用RTL提供有效支撐.
2 系統設計
本節中主要包含3個部分,分別是上層編程模型、模塊化數據流IR和底層參數化硬件模板與RTL代碼生成,對應整個方法的執行流程.
2.1 上層編程模型
編程模型使用的是以點為中心的模型,圖算法通過描述每個節點的計算行為描述整個算法邏輯,有較高的兼容性,在執行模型方面,圖計算中常見的執行模型有push和pull這2種.本文選擇pull作為執行模型.在pull模型中,圖算法每輪迭代會調度所有節點,并處理其所有入邊數據.選擇它的主要原因是:1)PageRank類算法更適合采用pull[26];2)基于push的BFS需要同時獲取源點和目標點數據,增加硬件開銷;3)基于notify-pullpull和pushpull的BFS的性能差距較低.
算法1給出了基于以點為中心的命令式圖算法偽代碼,在詳細解釋之前先給出圖術語,由于從數學到計算科學以及其他各個領域對圖的研究非常廣泛,標準的術語尚未確定,本文只簡單介紹此處使用的描述.
算法1.基于以點為中心的命令式圖計算偽代碼.
輸入:點數據VertexValue、邊數據Edge、邊偏移量EdgeOffsetTable;
輸出:迭代收斂后的點數據VertexValue.
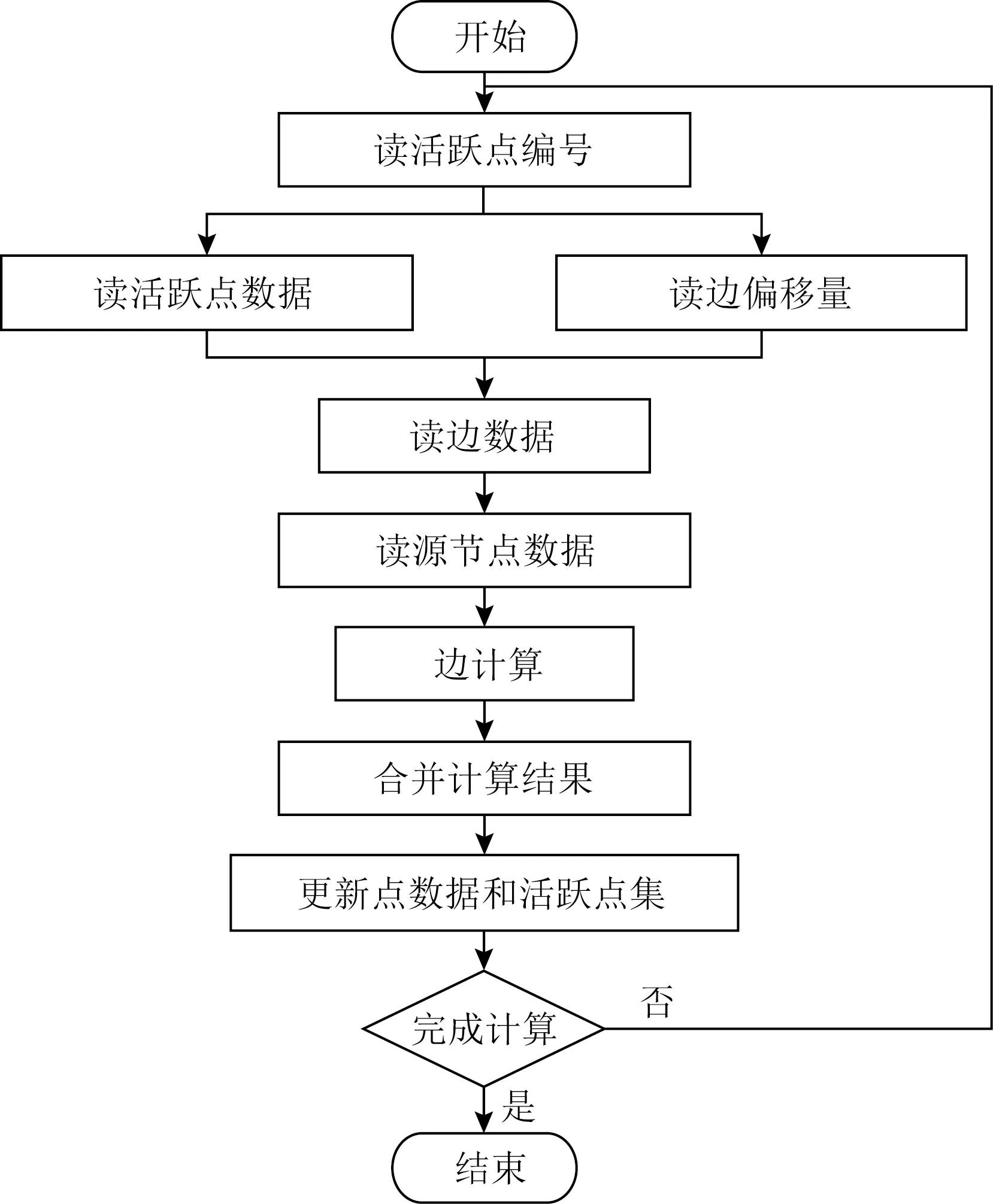
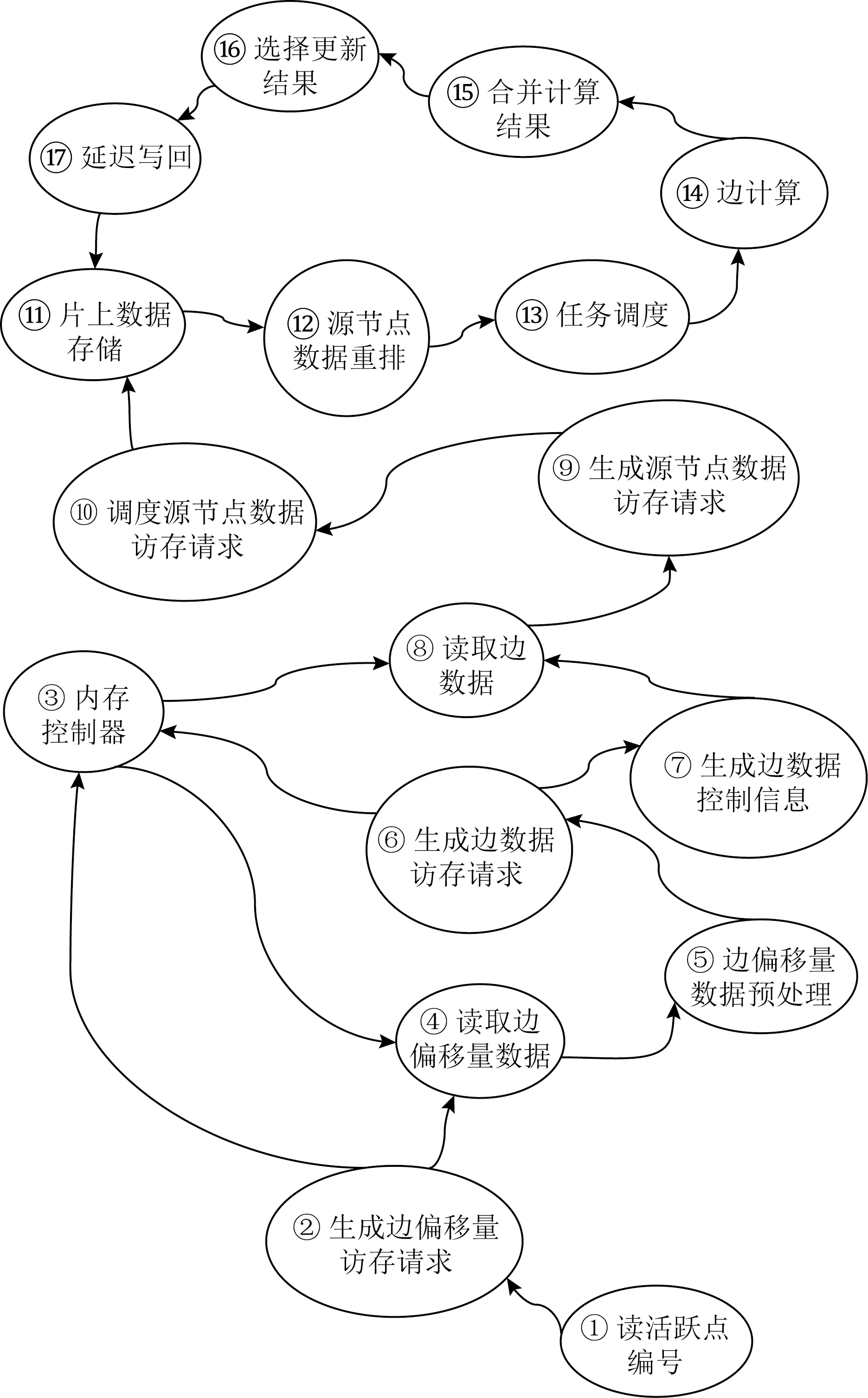
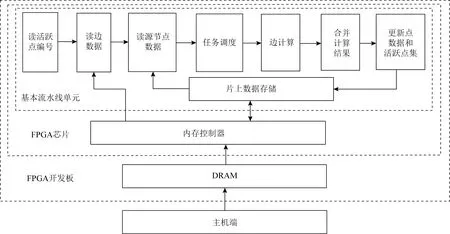
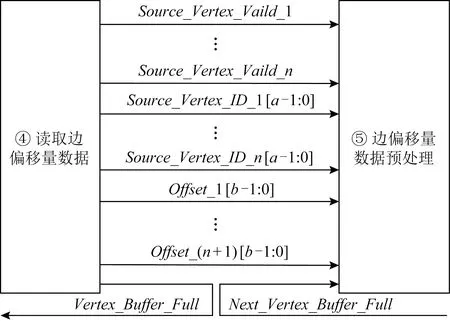
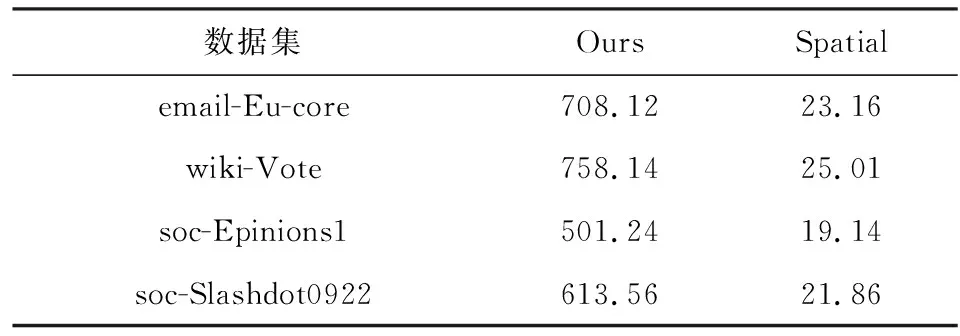
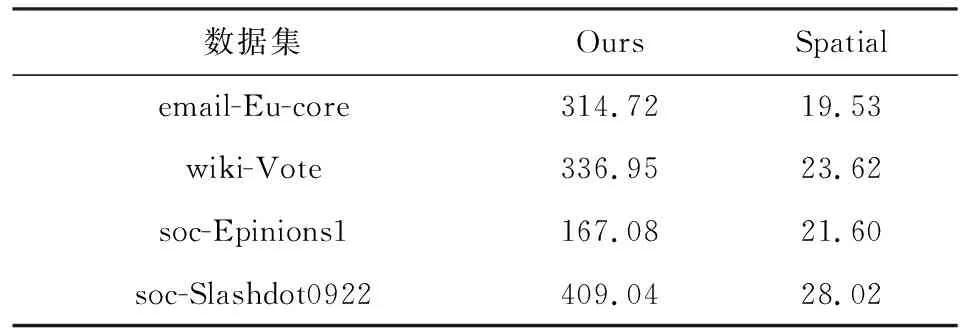
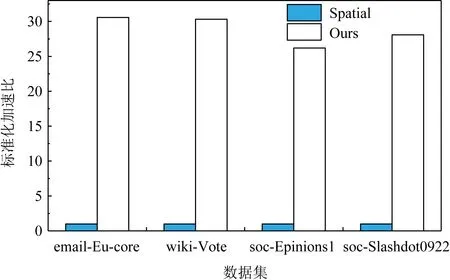
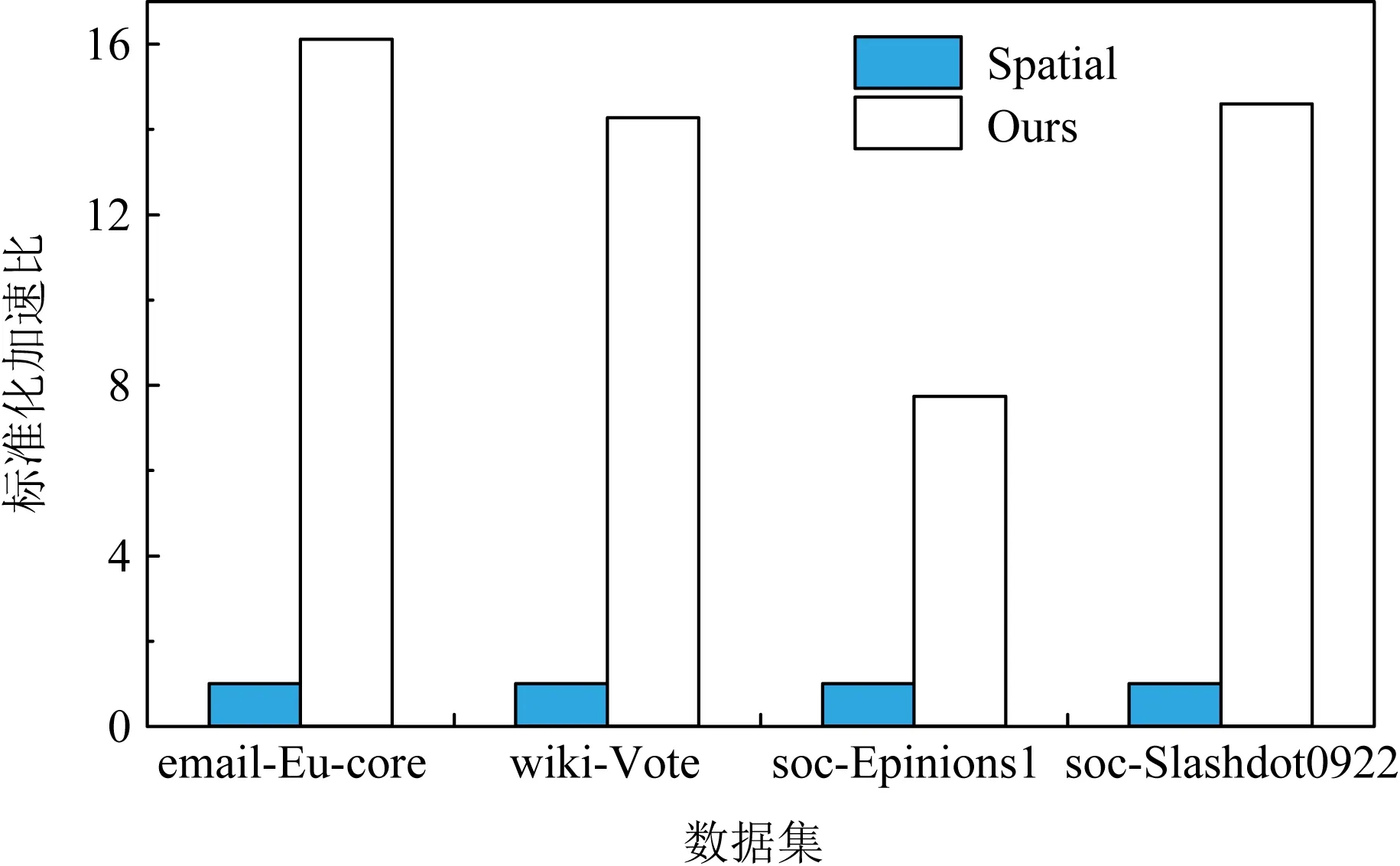
① for (inti=0;i ② Vertexv=ActiveVertex[i]; ③ EdgeOffseteoff=EdgeOffsetTable[v.id]; ④ for (intj=eoff.l;j ⑤ Edgee=Edge[j]; ⑥ Valueu.val=VertexValue[e.uid]; ⑦ Valuetmp=Process(e.weight,v.val,u.val); ⑧ Valuenewval=Reduce(tmp,newval); ⑨ endfor ⑩ UpdateVertex(v.val,newval); 圖數據結構建立在反映現實世界的基元上,包括頂點(vertex)、連接不同頂點的邊(edge)和屬性(property),節點和邊均有自己的屬性,屬性可以是任意類型的任意數據.編程模型要求輸入格式為壓縮稀疏行(compressed sparse row, CSR),引入了Offset的概念,即當前頂點對應邊在邊表中的偏移量,在具體算法實現中一般還會建立1個活躍點集(ActiveVertex),目標節點表示為u,屬性值表示為Value. 對算法1中的圖計算偽代碼,行①的循環代表依次處理所有活躍頂點,行④的循環代表依次處理當前活躍頂點的所有邊.首先考慮對嵌套循環進行粗粒度流水,即行②③作為1個流水階段,行④~⑨的循環整體作為1個流水階段(目前只有Spatial可以實現任意位置的粗粒度流水),接著對行④~⑨代表的循環整體進行細粒度流水,即使達到了HLS工具最大的流水能力,高并行度情況下依然會有嚴重的流水停滯.之后考慮添加并行指令,分為點間并行和點內并行,分別對應于行①的循環并行和行④的循環并行,兩者可同時添加. 首先考慮點內并行,對于高并行度的點內并行(圖加速器可達到并行度為16或32),在頂點度數較小時每個周期都有許多計算資源空閑.首先分析行⑤,邊數據存放在Edge數組中,因為采用CSR輸入格式,此處邊是連續的,可以通過劃分支持高并行訪問,第1節提到有HLS工具對這類訪存行為可以自動進行內存劃分,許多也支持手動劃分.之后行⑥通過邊數據訪問目標點屬性,由于每個頂點所連結的目標節點是不可預測的,此處會存在大量的數據沖突,對于這種訪問模式現有工具不能進行自動劃分,由于圖數據的冪律分布,少量頂點會連接大量的邊,這些頂點的訪問會尤其頻繁,Spatial不允許手動的內存劃分,其自動劃分機制此處支持有限,從而選擇簡單的內存復制導致片上稀缺的存儲資源大量消耗.行⑦是特定于圖算法的處理操作,行⑧計算得到更新值,此處由于每條并行的流水線都會讀同一個變量然后向其中寫入,有的HLS工具為保證結果正確性會串行執行,有的沒有檢測到這個依賴問題會產生錯誤的結果(多條流水同時往同一個地址寫入時只會寫入第1條流水的數據). 點間并行情況與點內并行類似,由于圖數據的冪律分布特性,并行流水線間存在負載不均的問題.在行②讀活躍點數據和行③讀邊偏移量以及后面的操作沖突同樣很嚴重.當邊數量太大無法存放在片上時會將其存放到片外動態隨機存取存儲器(dynamic random access memory, DRAM)中,一般在行③和行④之間增加1個通過Offset去片外取邊的操作,不改變行⑤取邊數據的沖突本質. 現有HLS系統雖然可以實現圖算法的粗細粒度流水結構,但是在指定高并行度時缺乏訪存和并行更新操作的支持,其生成的硬件邏輯依賴于用戶的輸入,但是高級語言對硬件描述能力有限,即使用戶熟悉底層硬件也很難在上層描述出特定的硬件結構,對算法1的分析可以發現在整個遍歷過程中可以將圖算法的操作分為讀活躍點集合、讀邊偏移量、讀邊數據、讀目標點數據、邊數據計算、合并計算結果和更新節點和活躍點集7個主要操作,但是針對于循環而展開的各種優化手段無法針對性地切實地解決這些操作中存在的依賴和沖突問題,其作用于循環內包含的多種操作,無法為每個操作生成特定的支持. 本文提出的編程模型突出了7個主要的圖操作,允許用戶直接在每個操作上添加特定的架構和微架構參數,包括并行度、數據位寬、數據類型和格式調整.如算法2所示的偽代碼. 算法2.基于以點為中心的函數式圖計算偽代碼. 輸入:點數據VertexValue、邊數據Edge、邊偏移量EdgeOffsetTable; 輸出:迭代收斂后的點數據VertexValue. ①ReadGraph(address); ② Foreach (ActiveVertex){i=> ③v=GetVertex(i); ④off=GetOffset(v); ⑤ Foreach (off){j=> ⑥e=GetEdge(j); ⑦u=GetNeighbor(e); ⑧tmp=Process(v,e,u); ⑨newval=Reduce(tmp,newval); ⑩ } 根據圖計算的依賴關系,算法2的數據流圖如圖1所示,算法2中行①由用戶指定輸入的CSR格式圖數據的地址,讀入圖數據,將根據后面的代碼自動決定數據的存放方式和地址;行②③對應圖1中讀活躍點數據,由于是pull執行,所有點都是活躍點,其中行②實際上作為本輪迭代是否完成的信號,此處可以選擇讀點的并行度;行④對應圖1中讀邊偏移量,同樣可以指定并行度,默認和點并行度保持一致;行⑤無實際作用,如2.1節所述此模型不依賴循環驅動執行;行⑥對應圖1中讀邊數據,可以指定邊并行度,由于是順序讀邊不依賴于源點數據,當頂點度數較大時相當于點內并行,頂點度數較小時相當于點間并行,保證了硬件資源的持續運行和解決了點間度數不均勻帶來的負載均衡問題;行⑦對應圖1中讀目標點數據,由于此處存在大量隨機訪存,將根據讀邊并行度生成對應數量的緩沖區,對片上點數據劃分的同時也對訪存請求實施調度保證較高的吞吐量.行⑧對應圖1中的邊計算,可以指定數據位寬和數據類型;行⑨對應圖1中合并計算結果,用戶只需編輯合并的邏輯操作,具體架構根據讀邊并行度按照文獻[5]中并行累加架構產生;行對應圖1中更新結果和活躍點集,同樣用戶只需在行編輯合并的邏輯操作即可,此處更新結果操作并行度不大于讀點并行度,且會對片上點數據存儲作相應設置,不會產生讀寫沖突問題. Fig. 1 The data flow diagram of algorithm 2圖1 算法2的數據流圖表示 基于圖1所示的數據流圖,本文設計了如圖2所示的模塊化數據流IR用以高效支撐圖1中的各個操作高并行度流水實現.IR分為17個模塊,每個模塊對應圖2中的1個節點,編號和數據流動方向如圖2所示,不同于將上層語言編譯為細粒度的中間表示后再去挖掘其中的并行機會,模塊化的IR通過更高抽象層次的表達將圖算法中如2.1節提到的關鍵點針對性地用特定的模塊顯式表達,精準地提供了優化支持,避免了大部分數據沖突.其中每個模塊都有2種緩沖區,其一接收上一模塊傳遞的數據并指示溢出情況,另外還有緩沖區存入本模塊產生的結果供下一模塊讀取,根據緩沖區的溢出信號產生控制信號.接下來按照圖1各個圖操作的連接順序依次說明IR中的對應模塊在每個時鐘周期的操作是如何進行支撐的,還會說明IR中各個模塊的實現細節. Fig. 2 Modular data flow IR圖2 模塊化數據流IR 1) 讀活躍點數據 模塊①對應讀活躍點數據.由于pull模型所有頂點都是活躍點因此可以順序讀取源節點,實現邏輯為1個源節點計數器按照讀點并行度每個周期生成對應數量的源節點編號存入輸出緩沖區,輸出緩沖區有溢出信號控制源節點計數器,輸出緩沖區的大小根據指定的位寬和點并行度實例化.假設點并行度指定為n. 2) 讀邊偏移量 模塊②③對應讀邊偏移量.模塊②從模塊①的輸出緩沖區讀取n個點,傳遞源節點信息,同時順序生成節點邊偏移量的訪存請求,同樣受到溢出信息的控制.模塊③處理邊偏移量的訪存請求和邊數據訪存請求,各有對應的訪存請求輸入緩沖區和數據輸出緩沖區,大小由訪存請求并行度和讀邊數據并行度決定. 3) 讀邊數據 模塊③~⑧對應讀邊數據.模塊④從模塊③中邊偏移量輸出緩沖區接收邊偏移量,同時從模塊②中讀取n個點信息繼續傳遞.模塊⑤從模塊④中讀取邊偏移量和源點數據并進行匹配,在節點信息中添加其對應的邊偏移量. 模塊⑥按照讀邊并行度順序生成邊訪問請求,假設讀邊并行度為m,不同于根據源節點對應的邊偏移量來生成邊訪存請求,模塊內有讀邊計數器,此處需要做1個調度.首先從緩沖區中取n個源節點,由于源節點是連續的,所以其對應的邊偏移量也是連續的,若讀邊計數器的值加上m大于最大的邊偏移量,即將取的m條邊包含了n個源節點的所有鄰邊,還存在不屬于這n個點的邊,那么此次時鐘周期傳遞n個源節點和m個邊訪存請求,但是邊計算器不增加,即下一時鐘周期依然生成這m條邊的訪存請求.若恰好相等,則傳遞n個源節點和m個邊訪存請求,邊計數器增加m;若小于,說明將取的m條邊不能完全包含這n個點的所有邊,根據源節點信息中包含的邊偏移量計算出哪些源節點的邊完全包含在這m條邊中,傳遞這些源節點并用無效點補充為n個,其余的源節點存入緩沖區中等待下個時鐘周期處理,傳遞m個邊訪存請求,邊計數器增加m.即此模塊根據實際節點度數可以處理大度數節點的多條邊,相當于點內并行,也可以處理多個小度數節點的所有邊,相當于點間并行. 模塊⑦對邊數據產生控制信息,即當點度數較小時m條邊中存在邊不屬于這n個源節點,需要標記這些無效邊,同時需要給邊加上標記指示屬于的源節點編號,向后傳遞節點信息和邊控制信息.模塊⑧從模塊③接收邊數據,從模塊⑦接收節點信息和邊控制信息,根據控制信號傳遞這3類信息. 4) 讀目標點數據 Fig. 3 Hardware architecture of graph processing accelerate圖3 圖計算加速器的硬件架構 5) 邊計算 6) 合并計算結果 7) 更新結果和活躍點集模塊 基于圖1的數據流圖,硬件架構如圖3所示,片上流水主要包括讀活躍點集合、讀邊數據、讀目標點數據、任務調度、邊計算、合并計算結果和更新節點和活躍點集.實際流水按照IR分為17個模塊,每個模塊有參數化的硬件模板支撐,按照2.2節所述各個模塊完成的功能不同,對應硬件模板內部結構包括外層接口也不相同,但是2個確定的硬件模板間傳遞的數據類型是確定的,主要包括源節點有效性信號、源節點編號、后續流水級溢出信號、內存控制器溢出信號、邊偏移量數據、邊數據、邊數據有效性、邊數據屬于的節點編號、目標點數據等等.而對于源節點編號、邊偏移量這類非控制性數據可以根據指令生成多個并行連線.硬件模板內部參數主要包括各類數據的位寬、緩沖區大小、點邊流水線個數等. 以模塊④和模塊⑤對應的硬件模板之間的連接為例(省略時鐘信號和重置信號),如圖4所示.模塊④輸出n個源節點有效性信號、源節點編號、n+1個邊偏移量、1個緩沖區溢出信號,其中源節點有效性信號和溢出信號位寬默認為1,源節點編號和邊偏移量位寬根據指令設置;模塊⑤接收對應數據并從下一流水級接收緩沖區溢出信號. 對于圖算法無關的模塊,其對應的硬件模板基本功能完備,只需根據用戶指定的并行度和數據位寬類型等要求實例化對應的點傳遞流水線、邊傳遞流水線、邊控制信號傳遞流水線和緩沖區的大小以及各個模塊內部控制信號的參數.對于圖算法相關的模塊,包括圖2中模塊,以邊計算對應的硬件模板為例(省略時鐘信號和重置信號),如圖5所示.圖5中輸入接口包括源節點有效性信號、源節點編號、邊控制信號、邊屬性等;內部結構包括單個點傳遞流水線和多邊操作模塊,源節點信息和邊控制信息通過單個點傳遞流水線向后續流水級傳遞,邊屬性進入多邊操作模塊處理得到更新值;輸出接口包括源節點有效性信號、源節點編號、邊控制信號、更新值等. Fig. 4 The connection diagram of edge offset reading hardware template ④ and ⑤圖4 邊偏移量讀取的硬件模板④和⑤連接示意圖 Fig. 5 The diagram of edge process hardware template圖5 邊計算硬件模板示意圖 除了多邊操作模塊內部與圖算法相關的部分外,輸入輸出接口和單個點傳遞流水適用于不同圖算法,同樣只需按照用戶指令參數實例化,包括各類數據的位寬以及單個點傳遞流水線的個數等,邊屬性數據中包含多條邊,根據邊并行度決定,依照相應的位數在多邊操作中并行處理.由于用戶只需編寫計算操作,不包含控制和訪存操作,根據其計算操作生成相應的基本硬件計算器在多邊操作模塊內連接即可.完成各個硬件模板的實例化和相應的連接后生成最終的Verilog代碼. 圖算法根據計算特點被分為2類:遍歷為中心和計算為中心,其中BFS和PageRank分別是這2類圖算法中最常用并且最具代表性的圖算法.在本節中,我們使用本文提出的方法生成了BFS和PageRank硬件實現,并且在4個不同類型的數據集上測試了硬件實現的性能,我們還使用特定于并行模式優化的DSL Spatial生成了手動調優的BFS和PageRank硬件實現,在相同數據集上進行了比較,驗證了本文中面向圖計算的HLS方法的有效性. 本文從SNAP網站上下載了4個不同類型的數據集,均為自然圖,如表1所示.按照邊數目大小分別為email-Eu-core,wiki-Vote,soc-Epinions1,soc-Slashdot0922,平均度數區分明顯,可以驗證硬件實現在不同度數下的表現,平均度數最大的email-Eu-core達到了25.4,平均度數最小的soc-Epinions1為6.7.將所有數據集預處理為圖計算中流行的CSR格式,包括邊偏移量文件(Offset)和邊表(edge).本方法和Spatial生成的硬件實現使用完全相同的輸入,包括格式和數據. Table 1 Datasets Used in Our Experiments表1 實驗數據集 本文按照Graph500的計算標準測試BFS硬件實現的性能,計算方法為:圖的邊數除以BFS運行時間,由于采用pull執行模式,BFS需要多輪迭代才能收斂,此處采用圖的邊數進行計算而不是多輪迭代的總邊數,剔除了迭代中無效的吞吐量.由于PageRank在每輪迭代中所有邊均為有效邊,因此通用的PageRank性能計算方法為:圖的邊數除以PageRank 1輪迭代時間,所有硬件實現使用Xilinx Virtex UltraScale+XCVU9P進行驗證. 本方法的優化參數設置為讀點并行度為4,讀邊并行度為16,其余各模塊并行度與其匹配,數據位寬設置為32 b,邊偏移量預處理模塊輸出的邊偏移量數據位寬為4 b,設置時鐘頻率為200 MHz. Spatial優化參數按照2.1節中描述的流水方式,首先將內層循環當做整體放到外層循環的粗粒度流水中,然后對內層循環內部進行細粒度流水,考慮到片上存儲資源的數量,設置內層循環并行度為2,即點間流水并行度為2,按照其默認的150 MHz時鐘頻率運行. 根據FPGA上運行時間按照評估方法分別計算2類硬件實現在4個數據集上的吞吐量,通用指標為每秒遍歷百萬條邊數(million traversed edges per second, MTEPS),PageRank性能如表2所示,BFS性能如表3所示,本方法硬件實現和Spatial硬件實現分別簡稱為Ours和Spatial.為了更直觀地體現性能優勢,圖6和圖7中以Spatial實現的性能為基準分別給出了PageRank和BFS性能加速比圖. Table 2 Performance Comparison of PageRank 表2 PageRank性能比較 Table 3 Performance Comparison of BFS表3 BFS性能比較 Fig. 6 Performance speedup of PageRank圖6 PageRank性能加速比 Fig. 7 Performance speedup of BFS圖7 BFS性能加速比 Spatial非常適合挖掘出深度學習、矩陣相乘這類規則訪存應用中的并行性,其自動內存劃分機制在其中發揮巨大作用,但是如2.1節中提到的原因,在圖算法中不規則訪存使其自動劃分不能發揮太大作用,大量復制存儲單元導致其并行度難以提升. 我們的實驗結果相比于Spatial有很大的性能優勢,BFS在不同數據集上有7.9~16.1倍的性能提升.對于以遍歷為中心的圖算法而言,由于底層優化后的架構各個模塊的時序約束較為寬裕,主要問題集中在圖2中的模塊邊處理模塊,因為這類圖算法邊處理模塊內的邏輯相對簡單,實際上整個設計可以采用更高的時鐘頻率,給性能帶來進一步提升. 另一個重要影響因素即圖數據,圖7中實驗結果表明對不同的圖數據性能差別較大,主要與圖2中的模塊⑥生成邊數據訪存請求和模塊片上數據緩存有關,當節點平均度數較大時,模塊⑥訪存的全是有效邊,性能較好,email-Eu-core,wiki-Vote,soc-Slashdot0922節點平均度數都大于11;而節點平均度數較小時,受限于讀點并行度,會產生許多無效邊導致性能較差.此外雖然在模塊⑩中做了調度允許不同時鐘周期到來的鄰點訪存請求同時執行,但是如果鄰點訪存行為不規則程度較大,對性能也會造成影響. 本文采用的pull編程模型最適合PageRank類型的圖算法,其在不同數據集上有26.19~30.57倍的性能提升,因為PageRank 1輪迭代里面所有邊都是有效邊,而BFS這類圖算法1輪迭代里面只有很少一部分是有效邊,由于我們是按照有效邊進行計算,剔除了遍歷的無效邊,因此PageRank性能會比BFS好很多. 2.2節提到邊處理模塊會影響時鐘頻率,因為PageRank需要復雜的浮點計算,頻率很難進一步提升,雖然可以采用流水線方式進行浮點計算,使得其啟動間隔為1個時鐘周期,即和BFS的邊處理模塊達到同樣的處理速度,但是由于流水線長度更長,當模塊停頓時,需要更多的時鐘周期才能重新啟動.類似地,圖數據也會對PageRank性能產生影響,由于邊處理并行度設置為16,當平均度數低于16時,由實驗結果可知更高平均度數的圖數據會有更高的性能. 針對通用HLS系統缺乏對不規則圖算法有效支撐的問題,提出了一種面向圖計算的高效HLS方法.結合圖算法固有的嵌套循環、大量隨機訪存、數據沖突以及圖數據冪律分布等特性,設計了數據流驅動的處理架構,實現高效的并行流水執行,保證了處理單元的負載均衡.通過自定義的編程原語,可快速定制現有圖算法,并將其轉化為模塊化的數據流中間表示,進而映射到參數化的硬件模板,最后生成RTL. 未來計劃考慮提供更豐富的編程原語和編譯支持,使得用戶可以在上層表達出現有各主流圖計算加速器的底層架構特性.2.2 模塊化數據流IR
2.3 底層參數化硬件模板和代碼生成

3 實驗與結果
3.1 實驗數據集

3.2 實驗評估方法
3.3 實驗結果
4 總 結
猜你喜歡
故事作文·高年級(2025年7期)2025-07-27 00:00:00云南畫報(2021年8期)2021-12-02 02:46:08文苑(2020年10期)2020-11-07 03:15:26揚子江(2018年1期)2018-01-26 00:36:54天津詩人(2017年2期)2017-11-29 01:24:12數位時尚(幼兒教育)(2017年6期)2017-07-18 11:47:56視野(2015年6期)2015-10-13 00:43:11六盤山(2015年3期)2015-06-29 12:26:37火花(2015年1期)2015-02-27 07:40:13海峽姐妹(2014年5期)2014-02-27 15:09:38
