基于PPR模型的稀疏矩陣向量乘及卷積性能優化研究
2021-04-01 01:17:54譚光明孫凝暉
計算機研究與發展 2021年3期
謝 震 譚光明 孫凝暉
1(計算機體系結構國家重點實驗室(中國科學院計算技術研究所) 北京 100190) 2(中國科學院計算技術研究所 北京 100190) 3(中國科學院大學計算機與控制學院 北京 100049)
(xiezhen@ncic.ac.cn)
近些年來,使用性能模型的方法去分析和優化程序已經被廣泛地使用.其中以稀疏矩陣向量乘(sparse matrix-vector multiplication, SpMV)y=Ax為例,作為典型的非規則訪存的重要計算核心,該算法被廣泛應用在信號處理、圖像處理和迭代求解器等科學計算和實際應用中[1].但是在現有的多級存儲器層次的體系結構上,稀疏矩陣向量乘的效率一般很低,浮點效率往往低于硬件浮點峰值的10%,其主要原因是復雜的存儲器層次結構以及應用數據可重用性差的特征導致cache命中率較低,從而凸顯了各級存儲器之間的訪問延遲差異的瓶頸.為了解決這些問題,李肯立等人[2]在GPU上使用概率質量函數模型去選擇最佳的稀疏矩陣格式,從而構造不同的訪存模式去優化數據重用性問題; Li等人[3]使用建模方法自動調優不同的向量寄存器從而優化矩陣計算開銷.但是這些方法都屬于粗粒度選擇和評判優化方法的優劣,不能細化SpMV在特定平臺上具體的執行行為.因此如何建模SpMV的計算過程以及隨機的數據傳輸特性仍然是性能優化的主要挑戰.此外,作為規則訪存的典型代表,卷積計算在圖像分類、目標檢測、圖像語義分割和神經網絡等領域[4]取得了一系列突破性的研究成果,其強大的特征學習與分類能力引起了廣泛的關注.之前的研究表明[5-7],卷積操作在不同的數據規模和體系結構下最優的實現方法差異巨大,從而也給性能模型優化提供了發揮的空間.
此外,得益于性能模型包含的分析和優化的特點,近年來已發展出多種建模方法,其中根據模型是否結合體系結構特征大致可以分為2類:
1) 黑盒模型.該方法提取應用特征或者采集運行時數據,擬合或使用機器學習方法對應用程序性能建模.
2) 白盒模型.該方法使用簡化的機器模型描述應用程序和硬件的執行關系.
如圖1所示,最簡化的白盒模型是Konstantinidis等人[8]提出的Roofline模型,該模型描述了應用程序最佳性能與峰值性能、計算訪存比和訪存帶寬之間的關系,預測了不同計算訪存比程序可達到的性能上限.同時Cache-aware Roofline模型[9]引入的數據局部性規則擴展了cache在性能模型中的作用.更細粒度的白盒模型由Stengel等人[10]提出的ECM(execution-cache-memory)模型包含了指令執行和內存層次2個部分,該模型把程序運行劃分為核內和核外2個階段,對應于程序在CPU核內的指令執行和數據在內存層次之間的傳輸2個過程.不過該模型使用Kerncraft工具[11]建模程序的指令開銷,導致對指令之間數據依賴的建模準確性較低,而且該模型使用的Pycachesim[11]假定數據在各級cache上的缺失數量相同,該假定對于不存在數據復用或者數據完全被復用的程序來說可以達到比較精確的性能預測,然而對于存在一定比例數據重用的非規則訪存應用來說,則無法準確預測出性能,更也無法依據模型的輸出結果給出具體的優化方案.
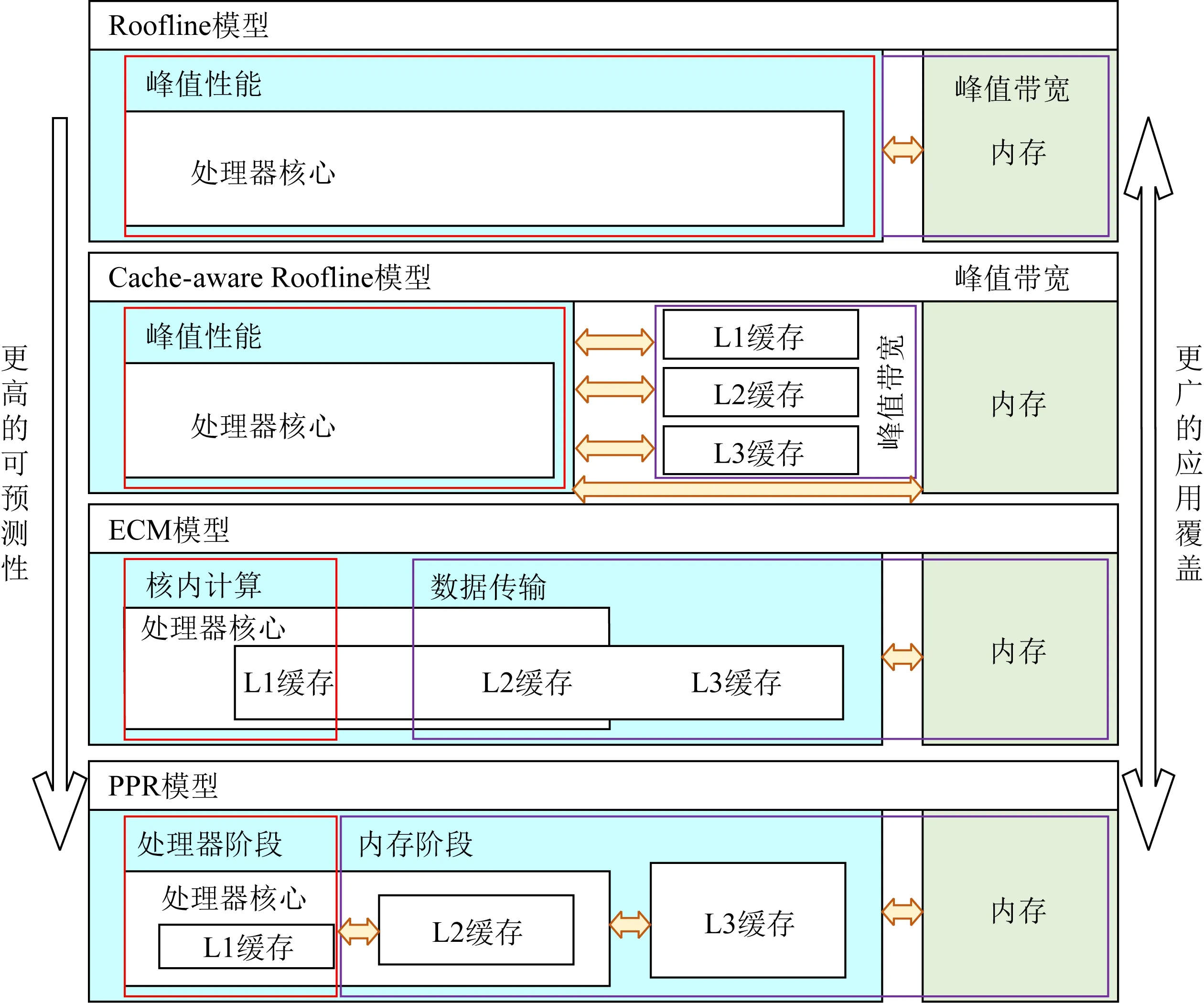
Fig. 1 PPR model and comparison with Roofline, Cache-aware Roofline and ECM圖1 PPR模型和Roofline,Cache-aware Roofline, ECM模型的對比
因此,為了改進指令數據依賴和數據復用的建模問題,我們提出了PPR(probability-process-ram)性能模型,該模型加入了處理器流水線指令建模,也加深了內存層次間數據訪存建模能力,以解決預測指令流水線執行和非規則訪存中數據傳輸的建模問題.由此我們的模型擴展了對數據依賴和非規則問題的覆蓋范圍,同時利用各階段的建模數據反饋開發者優化性能瓶頸.我們的性能建模由3個步驟組成:
1) 構建平臺,檢測和提取硬件參數,包括計算單元個數、訪存單元個數、流水線長度、指令發射寬度、指令開銷以及各級cache大小,cache分組策略和數據傳速率延遲等;
2) 對應用程序構建指令執行有向圖,預測指令執行開銷,并且標記出規則和非規則數據,通過檢測到的配置構建一個全新設計的cache模擬器去預測訪問數據的傳輸開銷;
3) 分析步驟2得到的時間開銷,針對所存在的瓶頸提出反饋的優化方案,并且預測出優化后的性能提升.
本文的主要貢獻有3個方面:
1) 提出了PPR性能模型,該模型完整考慮了指令流水、指令執行開銷和多級cache數據傳輸.通過細粒度的性能建模得出更精確的性能預測,并且擴展性能建模范圍到數據依賴和非規則應用.
2) 為了精確地模擬多級cache的數據傳輸開銷,我們設計了一個全新的cache模擬器,輕量級地構建于目標機器,并通過模擬應用程序的訪存順序,輸出各級cache miss,進而得到數據的傳輸開銷.
3) 通過計算指令執行和數據傳輸開銷預測出程序性能,并分析建模得到的各階段時間,找出影響性能的關鍵瓶頸,反饋開發者對應優化.同時我們也對不同的優化方法建模,預測不同優化策略帶來的提升效果,最終指導開發者選擇最佳的參數或策略.
1 相關工作
優化稀疏矩陣向量乘方面,前人已經做了很多的工作[12-13],截至目前,已經大量優化技術被提出,如cache blocking、壓縮、重排序以及啟發式優化等方法,同時也存在一些問題.具體而言,主要分為3個方面:
1) 改變矩陣存儲格式優化訪存性能,例如BCSR,ELL,SELL[14]等格式,這些格式存儲分塊矩陣或對齊數據從而改變訪存順序,減少右端向量的傳輸次數,優化數據傳輸開銷.所存在的主要問題是格式的選取和轉化成本較高,甚至我們也無法準確預測出特定平臺上可以獲取最佳性能對應的存儲格式.
2) 壓縮方法,該方法降低矩陣的存儲空間,緩解訪存帶寬的傳輸壓力,但缺點在于壓縮和解壓的額外開銷.
3) 自調優方法,由于不同的矩陣特征往往對應著最佳的矩陣格式和配置參數,通過提取矩陣信息自動選擇最優參數以達到最佳性能.但是當前工作[15]提取的矩陣特征有限,主要為行數、列數、非零元個數以及對角數等信息,無法給出十分準確的預測.而所選的格式和參數將決定SpMV性能,就BCSR格式而言,其主要利用分塊技術降低右端向量片段的數據傳輸,不過該格式存在多種分塊方法,根據不同矩陣的非零元分布情況,多種分塊會導致不同的cache miss次數,從而導致完全不同的性能表現.具體而言,過小的分塊對數據的重用不夠以至于不能顯著提升程序性能,而太大的分塊則會填充更多零元而大量增加數據集大小,從而導致訪存數據增加和性能降低.因此選取合適的分塊對SpMV的性能產生至關重要的影響,參數的選取策略也應該是性能模型的主要目的.所有這些都鼓勵我們建立一個針對于非規則訪存應用的性能模型.
此外近年來卷積神經網絡被廣泛應用在各個領域(為了加快訓練的速度通常選用單精度浮點計算),并取得了一系列突破性的研究成果.而卷積作為卷積神經網絡最大的耗時函數,也成為優化的重點.很多工作[16]也使用向量指令或者特定的硬件結構加速計算部分.但是對于開發者而言,如何在不同的指令集支持和數據規模下選擇最佳的優化方案仍然是一個亟待解決的問題,這也是我們提出性能模型的主要動機.
2 實驗平臺
如表1所示,我們的實驗基于Haswell微架構的Intel服務器平臺,處理器核心支持SSE,AVX,AVX2指令集,每個核心包含一個支持指令亂序執行的端口調度控制器,其中有4個計算端口支持核心每周期2次浮點或者FMA計算,配合使用向量寄存器每個周期最高可達到雙精度浮點(DP)16次或單精度浮點(SP)32次的浮點性能,其他4個端口支持訪存操作,每個周期支持2個Load和1個Store操作.每個CPU通過4個內存通道與DDR3-1866內存相連.處理器的內存層次由3個片上數據 cache組成(32 KB L1D cache, 256 KB L2 cache和30 MB L3 cache).CPU主頻被鎖定在2.7 GHz.
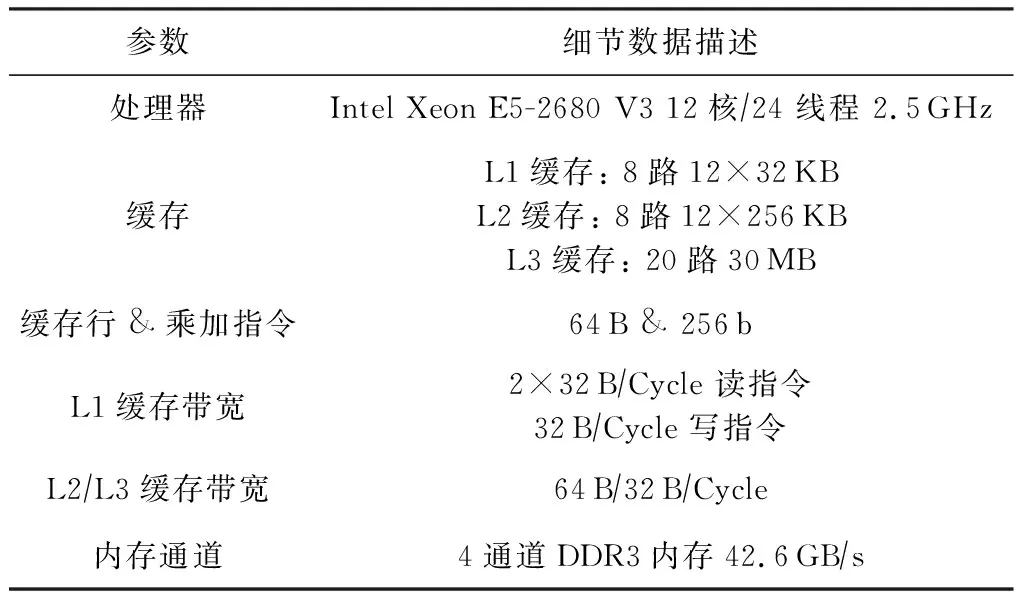
Table 1 Special Machine Parameters
3 PPR性能模型
我們詳細介紹PPR性能模型,該模型分為3個階段:執行階段、訪存階段和反饋優化階段.執行階段預測計算指令和訪存指令在核內的執行開銷,訪存階段描述了內存層次之間數據的傳輸開銷,反饋優化階段則匯總和分析建模信息從而指導瓶頸優化.
3.1 執行階段
在高性能領域,大量被使用的指令可以分為2類:計算指令和訪存指令,其中計算指令表示計算數值所需要的計算操作,訪存指令表示移動數據到寄存器的訪存操作.這2種指令在處理器核內部獨立端口調度運行.當程序需要的數據全部都緩存在L1 cache時,寄存器訪問數據不需要額外的數據傳輸,那么完成所有的計算和訪存指令則代表程序的結束.由于不同處理器指令執行能力差別很大,為了清晰地描述模型的功能,當前我們基于Intel Haswell 微架構E5-2680 V3搭建該模型,該架構1個周期支持2次浮點或者2次FMA計算以及2個Load和一個Store操作.最終2種指令執行所花費的最大時間將會是執行階段的開銷.
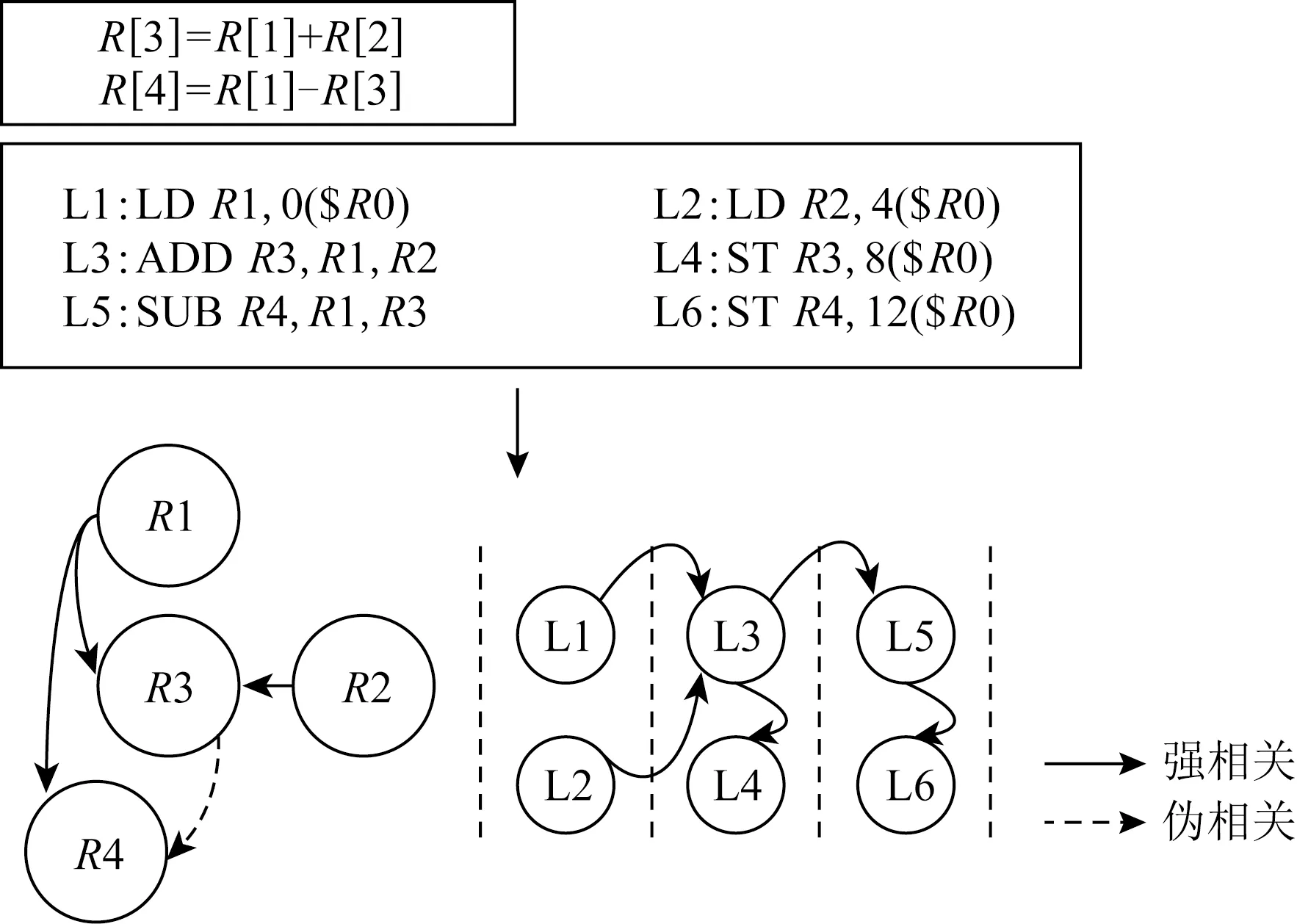
Fig. 2 Schematic for instruction DAG圖2 指令依賴DAG示意圖
我們詳細描述指令建模流程,在建模特定應用程序時,首先分析匯編后的代碼得知程序包含的加法指令、乘法指令、FMA指令、Load指令和Store指令數量分別為:A,M,IFMA,L,S,則A,M,IFMA條計算指令被調度到執行端口執行,而L,S條訪存指令被調度到訪存端口執行.同時這些指令之間蘊含著先后順序和數據依賴關系,因此為了充分模擬指令的執行時間,我們構建一個有向圖(DAG)分析指令的數據依賴,最終通過模擬DAG在硬件上的執行過程建模指令的執行開銷.如圖2所示,以一個簡單的程序為例,首先代碼被編譯為匯編指令,其中包含2條浮點計算指令、2條Load指令和2條Store指令,其次通過分析指令間數據依賴關系構建SDAG,并且以處理器雙發射和數據forwarding為例,映射出指令執行流水線,最終計算指令花費時間加上等待時間即可得到指令開銷.2類指令執行時間最大值即為執行階段的時間,通過式(1)得出:
Tprocess_phase=max(SDAG(A,M,IFMA),SDAG(L,S)).
(1)
3.2 訪存階段
訪存階段主要建模數據在緩存之間以及主存間的傳輸開銷.我們采用的測試平臺是3級cache和主存的多級內存層次結構,各級cache的大小、延遲和傳輸速率都不盡相同,數據可能出現在緩存或者主存的任何一個內存層次中,當訪存指令請求數據時會先查找最近的緩存,如在這一級請求失效則會請求更遠的數據層次,最終依次把數據從查詢到的緩存傳到L1 cache.與此同時,cache的數據預取機制可以無阻塞傳輸可能需要用到的數據到更近的緩存,從而降低數據的訪問延遲開銷.但是當前cache設計只針對規則訪存達到很好的預取,因此為了充分模擬cache的特性,如圖3所示,訪存階段首先把數據標記為規則和非規則訪存,分2種情況建模數據傳輸開銷.
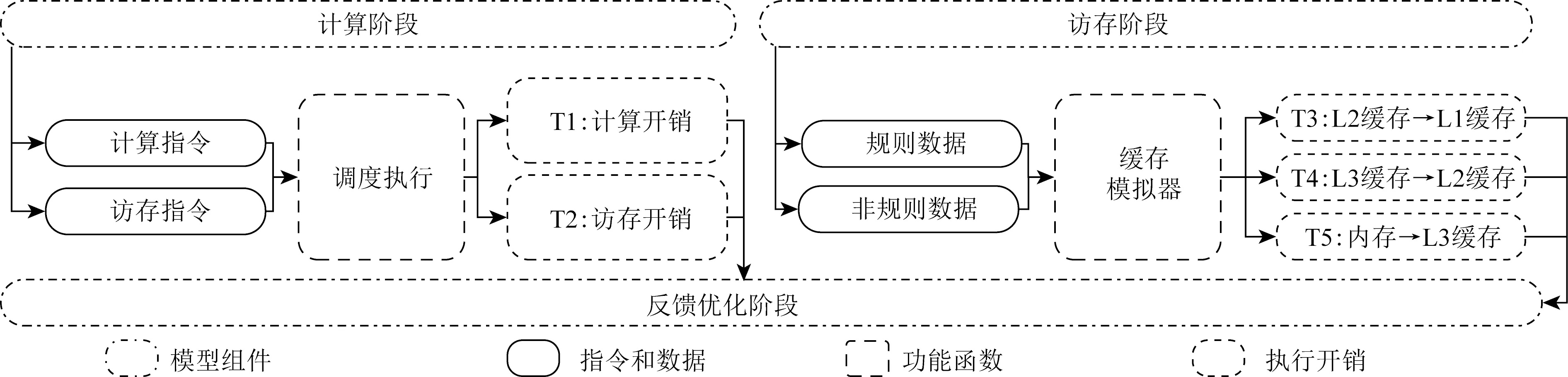
Fig. 3 Three components and execution flow of the PPR model圖3 PPR模型的3個組件和執行流程
1) 規則訪存條件.被訪問的數據保存在連續的地址空間或者小跨步的地址空間,且小跨步為不超過一個cache line大小的等段式跨越訪存.在CPU設計中,數據預取占據了很高的地位,主要原因充分利用無阻塞cache在多級緩存之間同時傳輸數據,可以最大化cache高帶寬特征.為了驗證Haswell架構的預取策略,我們設計了大量實驗得知 L2 cache和L3 cache對規則訪存有很高的預取效率,而L1 cache為了保障受限的空間不被大量未使用的數據占用,以及避免預測機制去競爭有限的帶寬,幾乎沒有使用預取策略.在訪問規則數據時,我們可以假設L2 cache 以及之后數據訪問延遲被預取機制完全隱藏,數據傳輸路徑上的最小帶寬即為傳輸速度.所需要的數據傳輸時間為
(2)
其中,Regular_data是規則訪存的數據量,Min_Bandwidth為數據所在內存層次傳輸到L2 cache的最小帶寬.
2) 非規則訪存條件.被訪問的數據保存在超出跨步大小或者隨機的地址空間.但是隨機的非規則訪存數據可能在同一個cache line中,如果假設數據傳輸大小等于全部訪存數據次數個cache line,預測則會大大高于真實的傳輸次數,此外,非規則訪存通常和規則訪存在程序中相伴出現,單純模擬非規則訪存也無法精確預估訪存開銷.因此為了精確預測訪存開銷,我們設計一個輕量級的cache模擬器建模硬件讀取數據時的傳輸行為.該模擬器的結構如圖4所示,構建方法為:
① 讀取機器的配置.獲取機器上各級cache的大小和組個數,模擬cache間組相聯映射構建cache表,組內每個cache line最初賦值為invalid,以表明該cache line沒有緩存任何數據.同時,通過使用修改的LRU機制模擬Intel的Smart Cache,并且加入cache替換和預取策略.

Fig. 4 Multi-level cache simulator圖4 多層次的cache模擬器
② 根據應用訪存順序構建訪存序列.首先我們把需要訪存的數據按照cache line大小劃分和編號,同時標記需要訪問的cache line為規則訪存或者非規則訪存,例如(index1-0,index3-1,index5-1,index2-0)(0代表規則,1代表非規則),該序列主要為了仿真讀取cache line的訪問順序.
③ 輸入訪存序列到cache模擬器.cache模擬器依次讀取序列的各個cache塊號.我們標記cache miss次數分別是L1_miss,L2_miss和L3_miss, cache line的大小為CL(例如,64 B).模擬器首先如果在L1表查找到該序號則使用LRU策略標記為最新使用過的塊,否則先使L1_miss+1,然后去L2表尋找該cache塊是否存在,如果存在則把該cache塊加入到L1表中,并且判斷該序列是否為規則訪存,如果是,則預取L3的下一塊數據到L2表,如果當前數據L2表不存在則使L2_miss+1,然后進一步尋找L3表,并且重復上述的查找替換操作.訪存開銷為

(3)
其中L2_Bandwidth,L3_Bandwidth,Mem_Bandwidth分別為L2到L1,L3到L2和主存到L3的帶寬.
3.3 反饋優化階段
由于計算階段和訪存階段可以并發運行:
PerfPPR=((A+M+2IFMA)×CPU_freq)
(max(SDAG(A,M,IFMA),SDAG(L,S)+
T(Regular_data)+T(IrRegular_data))).
(4)
其中,PerfPPR為基于PPR模型的性能預測,CPU_freq為處理器頻率,Regular_data為規則訪存數據,IrRegular_data為非規則訪存數據.
兩者中的最大值即為程序的執行時間,此式(4)則預測出程序的性能.最后通過分析最大時間作為性能瓶頸,反饋開發者優化相應部分.
4 SpMV建模
我們挑選了佛羅里達稀疏矩陣庫[17]的部分真實矩陣,借助PPR 模型建模和預測SpMV性能,并且找出性能瓶頸,最終針對瓶頸提出針對性的矩陣優化策略.
本節我們首先使用稀疏矩陣庫中13個矩陣來驗證PPR模型的正確性,并且與ECM模型對比(使用Kerncraft和Pycachesim工具建模SpMV),進而在建模的基礎上找到性能瓶頸并提出優化方案.最后,我們比較了優化后模型預測和實際測量的差異.
4.1 測試矩陣
用于建模的稀疏矩陣來自于廣泛使用的矩陣集如表2所示,這些矩陣具有各種不同的稀疏分布.同時我們的壓縮稀疏行(compressed sparse row, CSR)計算內核也使用循環展開和數據對齊等優化, 64 b浮點精度也更符合在實際應用中的效果.
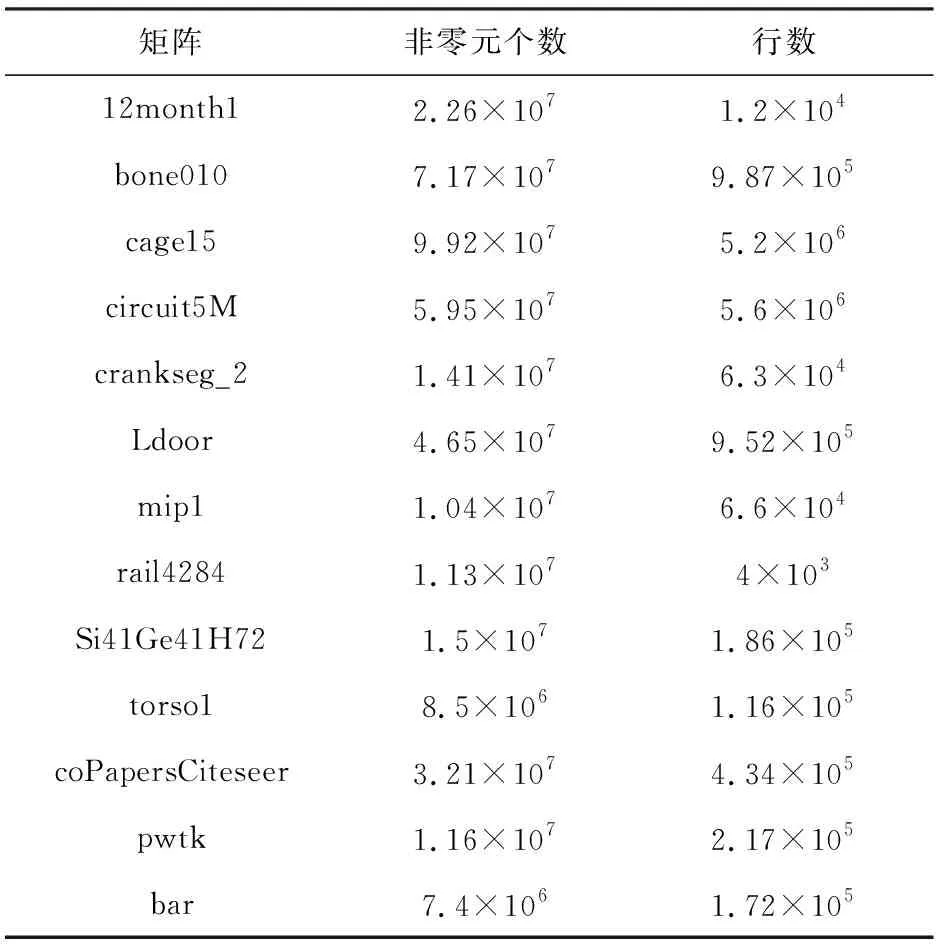
Table 2 Selected 13 Sparse Matrices and Scales
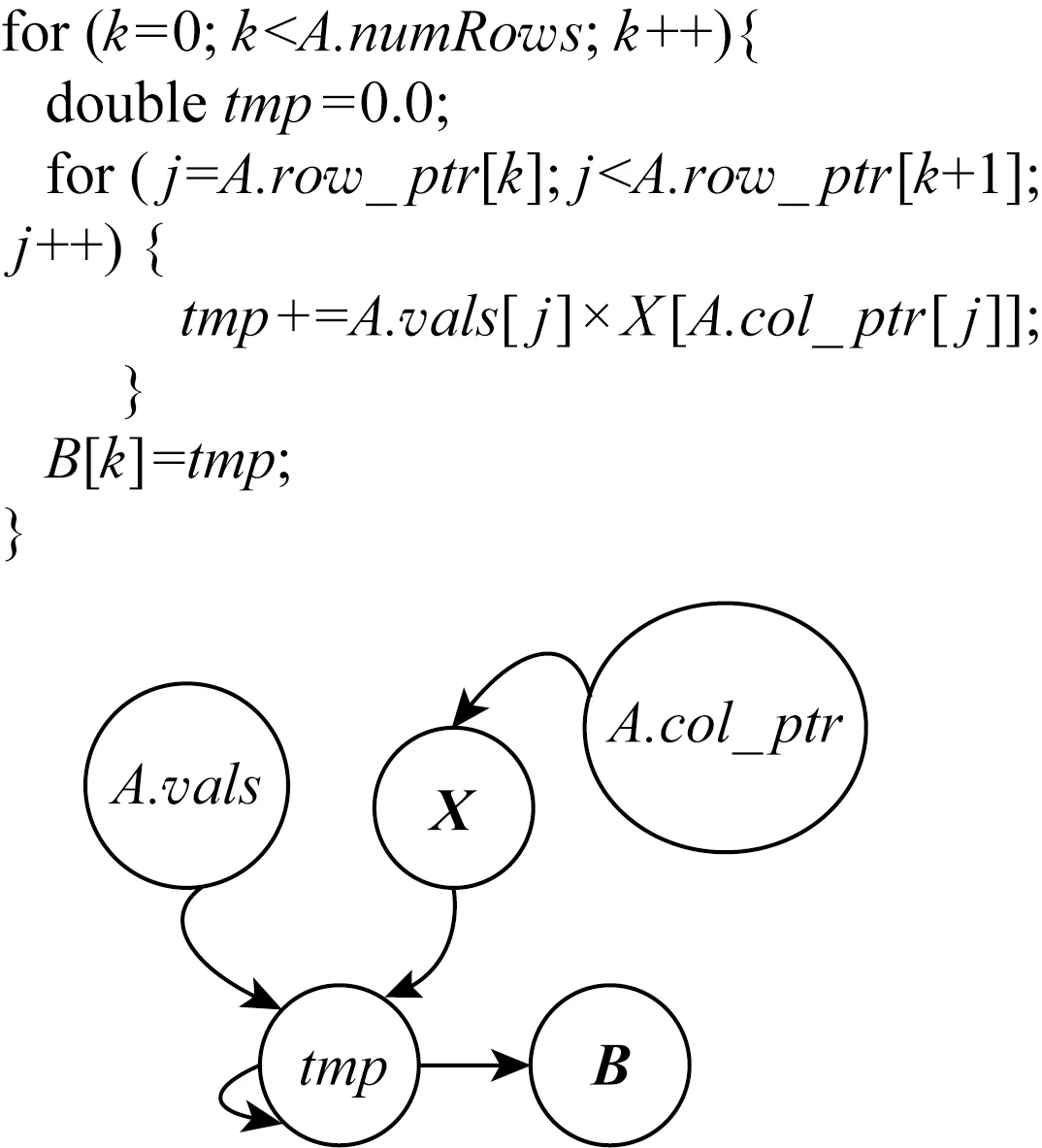
Fig. 5 Pseudo-code for CSR-based SpMV圖5 基于CSR格式的SpMV偽代碼
4.2 性能預測和瓶頸分析
基于CSR格式的SpMV偽代碼如圖5給出.在“執行階段”,我們首先基于偽代碼上構建指令數據依賴圖,其中向量X的數據讀入依賴A.col_ptr的結果,累加tmp則依賴于A.vals和X的結果.由于Haswell的1個周期可發射4條指令,編譯器通過使用多個寄存器可以生成相互獨立的累加指令,但是Load指令需要的數據依賴無法避免.而對于一個稀疏矩陣,令其行、列和非零元分別為R,C,NNZ,則整型數組A.row_ptr的大小為(R+1)×4 B,整型數組A.col_index的大小為NNZ×4 B,雙精度數組A.vals的大小為NNZ×8 B,雙精度向量X的大小是C×8 B.偽碼中的乘法和加法分別含有NNZ條加法和NNZ條乘法指令,此外訪問A.row_ptr需要R+1條Load指令,訪問A.col_index需要NNZ條Load指令,訪問A.value需要NNZ條Load指令,訪問向量X需要NNZ條Load指令,輸出向量B需要R條Store指令.對于“執行階段”,通過式(1),在執行計算指令上花費的時間是NNZ個周期,由于訪存指令的數據依賴,導致訪問X有3個周期的指令延遲,則執行訪存指令上花費的時間是5×NNZ個周期.通過循環展開和亂序執行可以使計算指令和訪存指令分開執行,則通過式(1),最終花費在執行階段的時間為5×NNZ個周期.
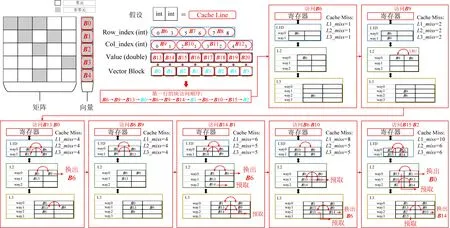
Fig. 6 Schematic work-flow of cache simulator for a fragment of sparse matrix圖6 用于稀疏矩陣片段仿真cache模擬器的執行示意圖

Fig. 7 Comparison of PPR model with actual measurement and ECM model圖7 PPR模型與實際測量和ECM模型的對比
對于“訪存階段”,模型主要建模的非規則訪存開銷是向量X的數據傳輸.如圖6所示,我們將矩陣和向量的數據以cache line為大小劃分為單個小分塊,分別標記出規則和非規則訪存,并構建訪問序列.根據3.2節中提到的建模方法,通過讀取目標機器的硬件參數來構建cache模擬器.模擬器依次讀取訪問序列并記錄緩存未命中次數.圖6給出了模擬器計算矩陣1行的示意流程圖.首先,按照訪問的順序依次讀取數據到cache中,其中模擬器對規則訪存的數據實現了充分的預取,對非規則訪問的數據則逐級讀入.具體來說,模擬器標記行偏移、列偏移和值數組為規則訪存數據,標記向量為非規則訪存數據,在讀取規則訪存數據1個分片的同時,遠端的cache也同時傳輸需要訪問的下一個分片到上一級cache,而對于讀取的非規則訪存數據,則按照傳輸順序,逐步傳輸到最上層的cache.同時,該模擬器記錄了傳輸所帶來的各級cache miss,使用式(3)得出訪存時間,最終使用式(4)得到了各個矩陣對應的性能. 如圖7所示,橫坐標表示我們挑選的13個稀疏矩陣,左側縱坐標為矩陣的浮點性能,單位GFLOPS.右側縱坐標表示各級內存層次中的cache miss次數.圖7的頂部顯示了不同形狀代表的不同含義.其中測量的L1,L2,L3緩存未命中使用了PAPI[18]工具統計,以及使用cache模擬器模擬的各級cache miss在圖7中用不同形狀的圖標標記.通過使用PPR模型及式(4)計算的性能用圓圈標記,ECM模型預測的性能則用菱形標記.觀察發現,使用cache模擬器模擬的cache miss次數十分接近于PAPI測量的cache miss.相比之下,使用PPR計算出的性能相比ECM模型預測更接近于真實測量,可以大大提升預測精度.結果也間接地反映了模型和cache模擬器的準確性.
從圖7中明顯看出L2 cache miss在部分矩陣計算時數量較高,原因是訪問CSR格式矩陣對應列的向量X導致重復的數據傳輸,并且結合分析SpMV的建模結果,我們發現主要的時間花費和瓶頸是非規則數據的傳輸開銷.為了解決這個問題,可以通過改變稀疏矩陣訪問模式去增加向量X的重用性以及減少數據分片的冗余傳輸,進而降低數據傳輸開銷,增加浮點運算效率.
4.3 反饋優化
對于降低數據傳輸開銷,矩陣分塊是一種用于優化數據重用的典型技術.一個m×n的稀疏矩陣可以在邏輯上被劃分為r×c塊,并且每個塊通常包含至少1個非零元素.在處理SpMV計算時,每個塊可以把向量的一部分保存在寄存器中,用來重用向量X中相應的元素,以增加向量數據的局部性.這種優化方法叫作分塊的CSR,是壓縮稀疏行存儲格式的一種變種,它也簡稱為BCSR.該格式連續存儲同一塊的所有元素,塊之間則以行主序存儲.BCSR也降低稀疏矩陣的列索引(每個塊1個而不是每個非零元1個),也減少了內存傳輸數量.但是,統一的分塊大小需要填充顯式的零元素,從而導致額外的計算和數據傳輸,也成為使用BCSR格式的挑戰.
基于以上原理,我們選擇BCSR格式并且使用PPR模型解決挑選最優分塊問題.傳統方法一般采用機器學習或統計方法來預測最優分塊形狀,其預測在一定條件下是有效的,但預測精度經常不穩定.因此我們使用PPR模型預測計算指令開銷并構建訪存序列以建模BCSR算法訪存開銷.通過讀取輸入矩陣,我們可以得到各種分塊下的指令開銷和各級cache miss次數,預測出每種分塊的性能,最終給出了最優的分塊方案.如表3所示,我們為13個矩陣構建BCSR模型并給出預測的最佳分塊.通過和實際測量的最佳分塊對比,模型的預測十分接近于最佳結果,并且帶來了平均124%的性能加速比.同時我們也考慮了建模開銷,通過對64種分塊大小性能建模和預測,該方法平均花費12個SpMV時間,低于直接執行的64個SpMV時間,相比于直接運行得到的性能,我們的方法大大節約了選擇最優參數的開銷.

Table 3 Optimal Block Sizes and Speedup
5 卷積建模
我們使用PPR模型建模規則訪存應用-卷積.根據我們的調研發現,直接卷積計算(不變換為矩陣乘法)在不同的數據規模和不同的機器結構下最有效的優化方法差異很大.以一維卷積為例(其他卷積方法都是建立在一維卷積基礎上),使用SSE,AVX或者AVX2指令集進行4或者8個單精度浮點計算對程序的影響很大,同時對于當前建模機器中向量寄存器Load指令而言,對齊數據花費時間是非對齊數據時間的一半,但是使用對齊的數據則會增加數據集的大小,而增加數據集大小在不同規模下會影響cache miss數量.所以,我們使用PPR模型定量執行指令、訪存指令、cache和內存傳輸時間,給出模型預期的性能,并且和真實測試到的性能作對比.最后給出在多個指令集支持和不同數據大小上的最佳優化方案.
5.1 原始代碼的性能預測和瓶頸分析
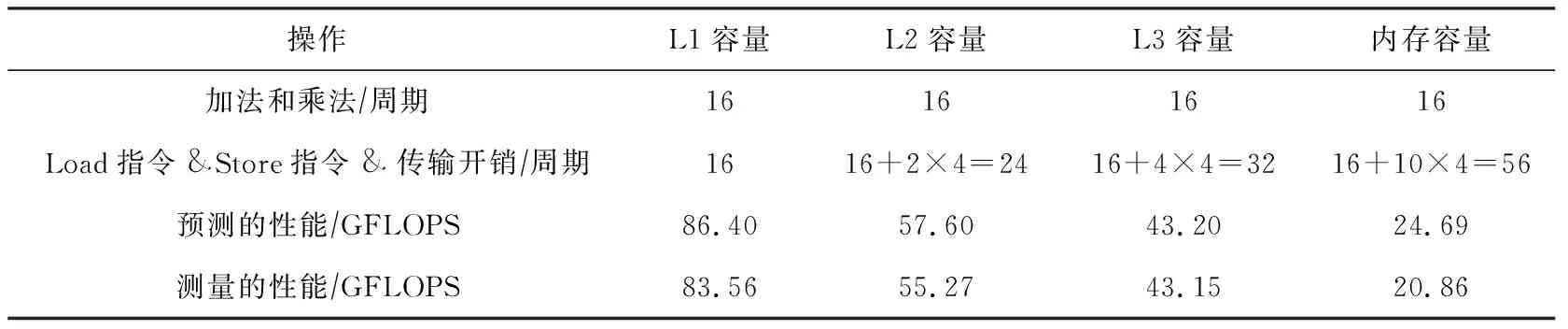
從算法1可以看出,該卷積1次讀取16個kernel數據和16個輸入數據去執行16個加法和16個乘法操作.我們可以看出數據具有極好的連續性,第2次卷積操作會重用上一次的15個數據.16次卷積計算則導致16個單精度浮點數傳輸,占據2個cache line.
算法1.Na?ve計算.
輸入:輸入數據IN、長度length、核數據KERNEL、核長度kernel_length;
輸出:輸出數據OUT.
① for (i=0;i<(length-kernel_length);
i=i+1) do
②tmp←0;
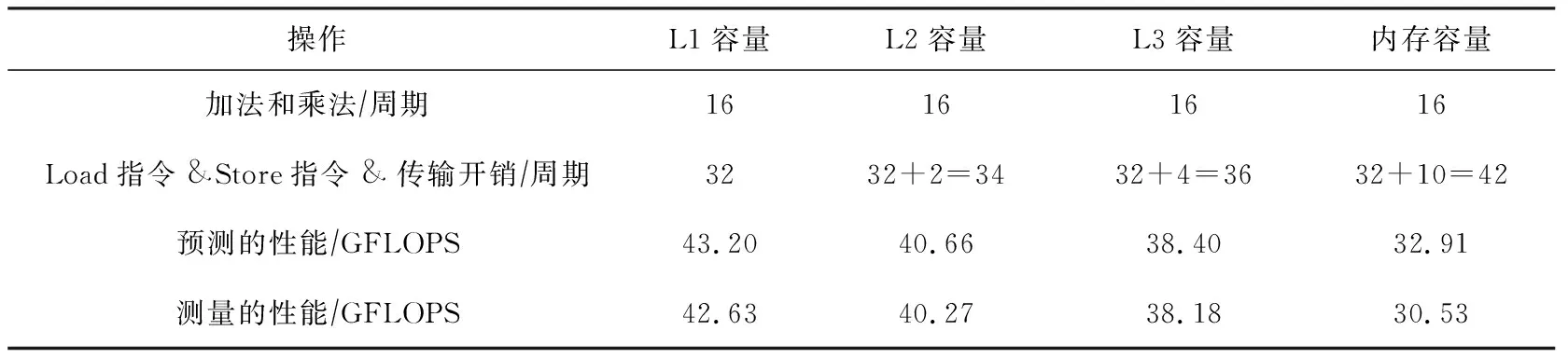
③ for (k=0,k do ④tmp←tmp+IN[i+k]× KERNEL[kernel_length-k-1]; ⑤ end for ⑥OUT[i]←tmp; ⑦ end for 在16次卷積操作的過程中,分別讀取數據IN中16個元素更新數據OUT的值,其中包含16×16個乘加指令,并且還產生16×16個Load和16個Store指令.通過使用多個寄存器和指令重排,可以完全消除指令之間的數據依賴.對于當前架構,1個周期可以執行2個乘加指令,因此計算指令開銷為16×162=128個周期,并且1個周期可以執行2個Load指令和1個Store指令,因此訪問指令開銷為16×162=128個周期.訪存階段,由于計算的數據都是規則地址空間,訪問數據的延遲可以被預取機制覆蓋,因此2個cache line需要消耗L2 cache到L1 cache的2個周期,L3 cache到L2 cache的4個周期,主存到L3 cache的10個周期,最后我們可以推斷出不同數據大小的GFLOPS性能.當數據都在L1 cache時,CPU主頻被鎖定在2.7 GHz,通過式(4)可計算出性能為(16×16×2)(max(128,128)2.7)=10.8 GFLOPS.當數據在L2 cache時,通過式(4)可計算出性能為(16×16×2)(max(128,128+2)2.7)=10.63 GFLOPS.當數據在L3 cache時,通過式(4)可計算出性能為(16×16×2)(max(128,128+4)2.7)=10.47 GFLOPS.當數據在主存時,通過式(4)可計算出性能為(16×16×2)(max(128,128+10)2.7)=10.02 GFLOPS.具體指令數量和性能如表4所示: Table 4 Measured and Predicted Performance Using Algorithm 1 從表4可以看出,無論數據在任何一層的內存層次中,卷積的主要瓶頸為執行計算指令和訪存執行的開銷.我們將介紹2種不同的優化方法,并分析優化所能帶來性能. SIMD(single instruction multiple data)指單指令多數據技術,從奔騰II處理器系列引入IA-32架構,并且擴展了128 b SSE指令和256 b AVX,AVX2指令的支持.使用SIMD可以向量化計算和訪問多個連續數據,從而大大降低指令執行時間.此外,對于向量化Load和Store指令需要確保被訪問的首地址按照16 B對齊,訪問未對齊數據所花費的時間是對齊數據的2倍.接下來,我們將使用AVX2指令實現數據非對齊和對齊2個版本,最終給出優化建議. 算法2設計了AVX2指令的非對齊算法,一次計算使用AVX2指令同時操作8個單精度浮點數,但是由于數據填充在連續的空間中,訪問數據的間隔為4 B,不能保證16 B的訪存對齊,因此必須選擇_mm256_loadu_ps接口使用非對齊向量訪問指令讀取非對齊數據. 算法2.AVX展開不對齊計算. 輸入:輸入數據IN、長度length、核數據KERNEL、核長度kernel_length; 輸出:輸出數據OUT. ①_m256kernel_reverse[kernel_length]; ② for (i=0;i ③kernel_reverse[i] ←_mm256_broadcast_ss (KERNEL[kernel_length-i-1]); ④ end for ⑤ for (i=0;i<(length-kernel_length16); i=i+1) do ⑥acc0,acc1←_mm256_setzero_ps(); ⑦ for (k=0;k k+1) do ⑧data_offset←i×16+k×16; ⑨ for (l=0;l<4;l=l+1) do ⑩ for (m=0;m<4;m=m+1) do (IN[0]+data_offset+l+ m×4); (kernel_reverse[k×16+l+ m×4],data_block,acc0); (IN[0]+data_offset+l+ m×4+8); (kernel_reverse[k×16+l+ m×4],data_block,acc1); acc0,acc1); 由此可以算出,當前架構AVX2指令1個周期可以執行2個乘加指令,每個乘加指令操作8個單精度浮點數,因此計算指令開銷為(16×16)(8×2)=16個周期.此外由于使用非對齊的訪存指令,1個周期可以執行一個非對齊的Load指令和半個Store指令,因此訪問指令開銷為(16×16)8=32個周期.數據在內存層次上的傳輸和算法1類似.當數據都在L1 cache時,性能則為(16×16×2)(max(16,32)2.7)=43.2 GFLOPS.當數據在L2 cache時,通過式(4)可計算出性能為(16×16×2)(max(16,32+2)2.7)=40.66 GFLOPS.當數據在L3 cache時,通過式(4)可計算出性能為(16×16×2)(max(16,32+4)2.7)=38.40 GFLOPS.當數據在主存時,通過式(4)可計算出性能為(16×16×2)(max(16, 32+10)2.7)=32.91 GFLOPS.性能如表5所示: Table 5 Measured and Predicted Performance Using Algorithm 2 從表5分析發現,算法2訪存指令成為了性能瓶頸,因此我們優化非對齊的訪存指令.算法3擴充數據到原有的4倍,使得每一次訪存地址都按照16 B地址對齊,不過也帶來了額外的數據傳輸. 算法3.AVX展開對齊計算. 輸入:輸入數據IN、長度length、核數據KERNEL、核長度kernel_length; 輸出:輸出數據OUT. ①_m256kernel_reverse[kernel_length]; ② for (i=0;i ③kernel_reverse[i]←_mm256_broadcast_ss (KERNEL[kernel_length-i-1]); ④ end for ⑤floatin_aligned[4][length]; ⑥ for (i=0;i<4;i=i+1) do ⑦memcpy(in_aligned[i],(IN[0]+i), (length-i)×sizeof(float)); ⑧ end for ⑨ for (i=0;i<(length-kernel_length16); i=i+1) do ⑩acc←_mm256_setzero_ps(); k+1) do l+1,m=m+1) do (in_aligned[l]+data_offset+ l+m×4); 算法3改進了訪存指令開銷,1個周期可以執行2個對齊的Load指令和1個Store指令,因此訪問指令開銷為(16×16)(8×2)=16個周期.為了保證每次訪存數據按照16 B對齊,我們擴展數據為原始數據的4倍,使之16次計算數據量增加到了8個cache line.在不同數據規模的性能如表6所示: Table 6 Measured and Predicted Performance Using Algorithm 3 對比多種優化方案后,我們發現最佳優化方案取決于數據集的大小.在Haswell架構上,我們發現,當數據小于L3 cache大小時,選擇數據對齊的優化算法(算法3)能夠得到較高性能,而隨著數據逐漸增大.非對齊算法(算法2)則更加合適. 我們詳細介紹了PPR性能模型,并且詳細描述了執行階段、訪存階段及反饋優化階段.然后我們將該模型應用到SpMV和一維卷積上,其中這2種算法是非規則訪存和規則訪存的典型代表.在建模SpMV時,我們實例化了cache模擬器的工作流程,輸出各級cache miss次數,進而幫助反饋優化階段分析各開銷的時間占比.在優化時,我們選擇了增加數據重用的BCSR格式,建模目標矩陣在各種分塊大小上的指令和數據傳輸開銷,進而得到最優的分塊選擇.此外,我們針對一維卷積的原始代碼和2種優化代碼分別建模,詳細了解各種優化方法在不同數據量下的性能表現,給出優化建議.該工作現階段主要是建模單核性能,在此基礎上可以進一步提高PPR模型針對多核應用的性能建模和預測能力,揭示出多核的性能瓶頸,最終指導并行程序的性能優化.
5.2 優化方法和建模分析
5.3 優化指導
6 總 結
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10房地產導刊(2022年5期)2022-06-01 06:20:14小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42建材發展導向(2021年12期)2021-07-22 08:06:48建材發展導向(2021年7期)2021-07-16 07:07:52數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48測控技術(2018年5期)2018-12-09 09:04:26電子測試(2018年18期)2018-11-14 02:30:34Coco薇(2017年11期)2018-01-03 20:59:57
