CGRA-PIMSim:基于粗粒度可重構陣列的存內處理架構仿真器
2021-04-01 08:14:30劉碩
現代計算機 2021年5期
關鍵詞:指令
劉碩
(上海交通大學電子信息與電氣工程學院,上海200240)
0 引言
隨著數據規模的不斷擴展和對DRAM需求的進一步提升,人們開始思考在內存中處理大數據應用的可能性。與傳統基于硬盤訪問的架構系統相比,將數據存儲在主存中可以實現數據訪問的量級加速。該類存內計算在數據處理方面的潛力已經被包括RAMCloud[1]、GraphLab[2]、Pregel、Oracle TimesTen[3]和SAP HANA[4]在內的學術和工業界所證實。
粗粒度可重構計算架構(Coarse-Grained Reconfigurable Array,CGRA)被證明在高性能系統計算和低功耗方面有顯著優勢[5-6],已經成為近年來的研究熱點[7-9]。其主要特點是芯片的功能可以在運行時根據不同的應用進行配置,結合了專用集成電路的高能效性和通用可編程處理器的高靈活性。這使得可重構處理器非常適合支持在性能和功耗方面具有較高要求的數據密集型應用,例如多媒體領域[10-12]和密碼學領域[13]。
由于可重構架構和存內處理都具有對數據密集型應用的友好性,本文將實現基于粗粒度可重構陣列的存內計算架構仿真,以探尋該架構在處理數據密集型應用上的性能優勢。為了實現按需求快速仿真,該仿真器采用面向對象的層次化建模設計和參數化定義。實驗結果表明,與傳統CPU架構相比,實現10x以上的加速提升。
1 設計策略
1.1 架構仿真策略
該仿真器的設計采用粗粒度可重構硬件體系結構的一般定義,如圖1所示,在具體設計實現過程中,該體系結構被劃分為三個抽象層:①處理單元(Processing Element,PE)級仿真;②處理單元陣列(Processing Element Array,PEA)級仿真;③CGRA級仿真。
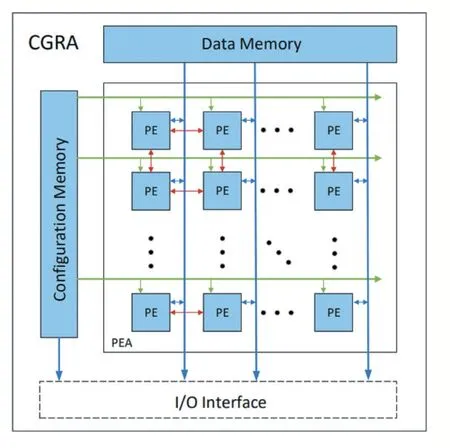
圖1 CGRA架構
PE級:在細粒度架構中,邏輯單元通常是查找表和可編程寄存器;在粗粒度架構中,PE則是存儲單元(Load/Store Unit,LSU)或是完整的運算邏輯單元(Algorithm Logic Unit,ALU),PE間支持并行數據處理。
PEA級:指定PE的數量和互連方案,PEA的規模和互連方案都會對架構性能造成顯著影響。該方案定義PE之間關聯方式和數據傳輸方式,PE的數量支持參數化配置,可以通過相關接口進行調整建模。
CGRA級:CGRA層是最高級別的抽象層。在該層視角下,PEA可以被認為是一個基本的計算單元。指令寄存器(Configuration Memory)用以存儲和配置ALU輸入和功能指令。數據存儲器(Data Memory)用于存儲臨時結果。I/O接口用以CGRA與外界的數據傳輸和交換,在本文仿真器中,I/O接口將與DRAM直連,實現近數據處理。
1.2 架構探索流程
本文采用的架構探索流程如圖2所示。基于CGRA設計存內處理架構建模首先要進行應用分析,確定性能要求;之后選擇架構參數,初步參數選擇是依據過往經驗,后續參數將依據具體性能評估結果進行調整;進行仿真建模,實現目標仿真器,進行性能評估。
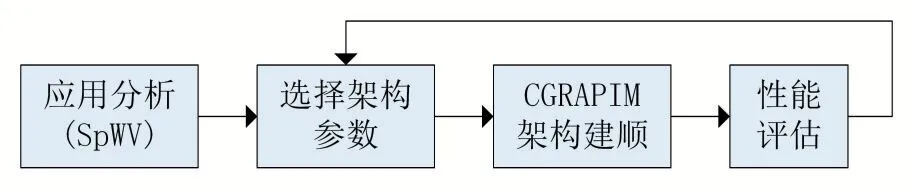
圖2架構探索流程圖
2 CGRA-PIMSim設計方法
2.1 CGRA仿真
CGRA架構仿真時基于面向對象的層次化建模概念,各組件之間有類的繼承關系,如圖3所示。
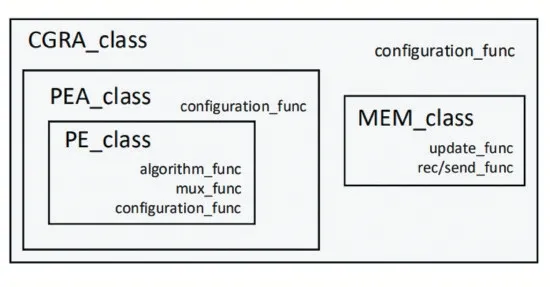
圖3 CGRA架構內繼承關系
對于圖1中的各組件,可以用類內函數來模擬硬件行為。例如PE類的函數包括運算(algorithm_func)、選擇器(mux_func)和指令配置(configuration_func)。運算函數將執行由配置指令控制的算術邏輯功能,這里將設置一系列通用算術運算(add、multiple等)和邏輯運算(AND、OR、XOR等),未來針對特定領域的應用將添加或移除額外的運算功能。選擇器函數根據配置指令接收目標輸入,并將它們輸送到運算部分。指令配置函數接收來自外部的命令,并將目標指令發送到運算和選擇函數中,作為一個配置參數變量。
PE的硬件架構如圖4所示,包含算術邏輯單元(ALU),兩輸入一輸出I/O接口,選擇器(MUX)和本地寄存器堆。
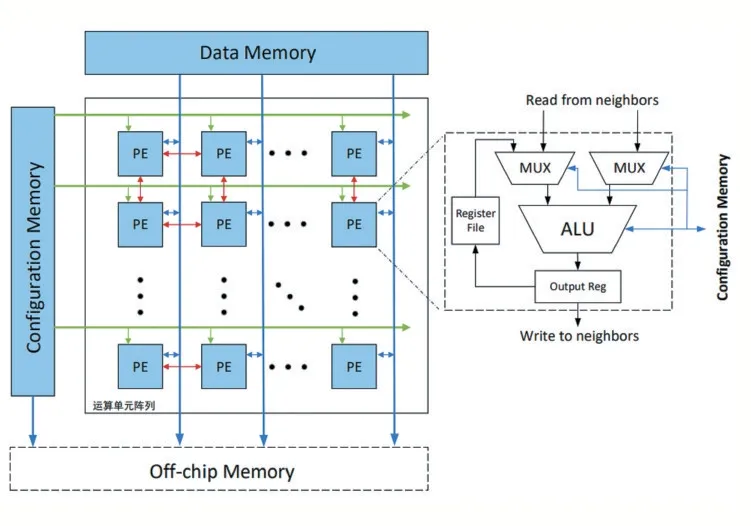
圖4處理單元的硬件架構
存內處理的概念體現在CGRA整體對外的I/O接口與DRAM(圖4中的Off-chip Memory)進行直連,實現數據近內存傳輸,減少數據傳輸延時和相應功耗。
2.2 事件驅動仿真機制
為了提高仿真效率和降低仿真模型編寫的困難程度,采用事件驅動仿真機制實現目標架構的搭建。
Gem5提供用于創建事件驅動的包裝器功能(EventFunctionWrapper類)。目標函數封裝時使用lambda表達式,例如:
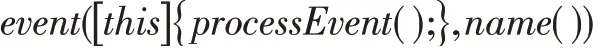
使用sch edule()函數進行事件安排,執行目標函數processEvent(),使其在某一時刻觸發:
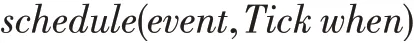
本次設計基于事件驅動仿真搭建PE的行為模型,PE類內的運算(algorithm_func)函數、選擇器(mux_func)函數和指令配置(configuration_func)函數作為processEvent目標函數被EventFunctionWrapper類封裝,根據具體行為的執行順序進行階段觸發。由于PE內數據傳遞都是非阻塞傳輸且物理距離很短,因此上述事件函數的觸發時間普遍設置為當前時刻的下一個周期。
3 基于Gem5的仿真實現
3.1 仿真流程
Gem5是一款高度模塊化、支持事件驅動方式的全系統仿真器。在Gem5中,所有模塊單元都被抽象設計為一個具體完成功能實現的C++類和一個對應模塊接口的Python類。當Python類與相關C++類綁定時,傳遞給Python類的具體參數將通過Gem5的參數傳遞機制賦值給C++類的相應成員變量。C++類內完成父類的繼承重寫(虛函數),構造函數和事件類(Event)實例化等。
仿真流程如圖5所示。由Scons軟件基于Python完成編譯,將所有模塊文件編譯并鏈接生成可執行文件。架構實現過程中相關配置參數的傳遞是通過Python模型對C++模型的接口實現的。具體應用時只需對Python模型中的參數進行設置,參數將會傳遞至C++模型中,完成對架構整體的搭建和初始化。具體仿真階段,將可執行文件加載到系統中開始相關仿真,Gem5提供debug-file功能,打印中間過程,并取得輸出結果。
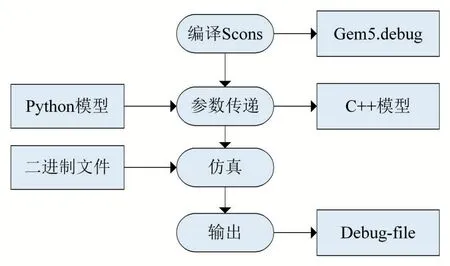
圖5 Gem5仿真流程
3.2 CGRA-PIM調度機制
Gem5仿真平臺有完整的CPU、總線和內存等的仿真,本文設計實現的CGRA-PIM架構通過仿真I/O接口直連到DRAM上。為了實現主處理器對CGRAPIM的調起操作,這里將在原有的X86指令集上進行擴展,利用Gem5中原有的X86預留空白指令位置實現目標CGRA-PIM指令。優勢在于CGRA-PIM指令可以直接作為已有主處理器指令的一部分進行相關執行,不需要對現有的編譯器和編程模型進行修改,降低實現難度。
將cpp文件編譯為可執行文件,由CPU進行文件執行,當CPU執行到CGRA-PIM特定指令時,由CPU負責調起相關處理單元。其中,CGRA-PIM和CPU是并行工作的,前者進行相關處理時,CPU將繼續執行之后的指令。這種并行處理的優勢在于能夠有效減少PE的空閑時間,有效提高計算資源利用率。
CPU和CGRA-PIM并發執行可能會帶來的問題是當處理的計算密集型應用需要循環操作時,CPU調取下一條CGRA-PIM相關指令的時間將有可能比CGRA-PIM自身完成上一條相關指令時間更短(與CGRA-PIM處理的數據規模有關,這里將根據實際運行時間有選擇性地控制可重構陣列規模),即后者在當前時刻有可能無法立即執行該條指令。因此為了避免主處理器運行阻塞,也為了避免造成當前指令的遺失,將設計添加CGRA-PIM工作隊列來存放待處理的任務,該工作隊列采用先進先出(FIFO)的行為方式。由CPU調取CGRA的待處理任務將會放入該工作隊列中,已經完成的任務會從隊列中彈出。
4 評估
系統參數設置如表1所示,目標架構CGRA為異構粗粒度可重構模型。處理單元陣列規模為8×8,共64個處理單元組成。其中LSU28個,ALU36個,LSU分布在四條邊上,ALU分布在陣列內部。
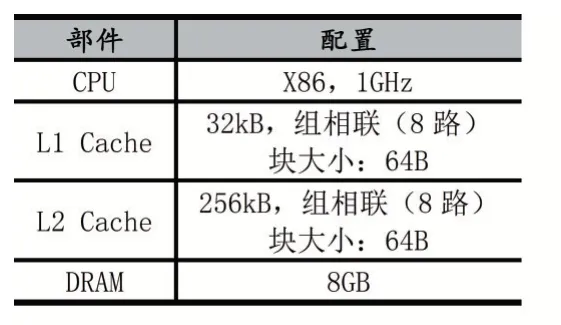
表1 系統參數設置
由于CGRA-PIM架構主要解決的是大規模數據傳輸造成的性能影響,因此將使用典型的數據密集型應用——稀疏矩陣向量乘(SpMV)來評估該架構性能。
選擇不同規模矩陣(N×N)作為測試樣本,將比較CGRA-PIM架構和CGRA-DRAM(不考慮近內存處理)架構以及傳統CPU架構(CPU-DRAM)的性能,將根據傳統CPU架構進行歸一化。不同規模矩陣進行SpMV應用后三者性能結果對比如表2所示。
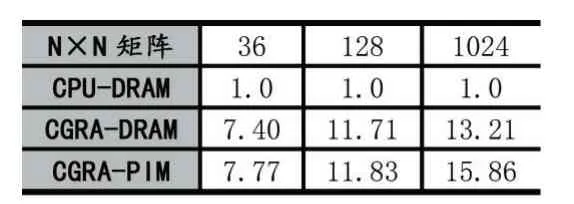
表2 各架構性能加速比
不同架構性能加速比在不同規模矩陣下呈現結果有一定差異。隨著矩陣規模的擴大,CGRA-DRAM和CGRA-PIM的加速比都有提高,原因是處理數據的時間占比上升。在矩陣規模較小時,數據讀取和預處理的時間占比較高,留給CGRA進行處理加速的循環操作時間占比較低,故而加速比較低,而隨著矩陣規模的擴大,循環操作的時間占比提升,這時可供CGRA加速的余地更大,因此帶來了更高的加速比,這也是CGRA-PIM更適合進行數據密集型應用加速處理的原因。
5 結語
本文從實際應用角度出發,針對數據密集型應用提出一種新型的存算一體架構CGRA-PIM。通過Sp-MV實例說明該架構較傳統架構的優越性,取得了明顯的性能提升。未來將考慮在該架構的通用性上進行擴展。
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
測控技術(2018年5期)2018-12-09 09:04:26
電子測試(2018年18期)2018-11-14 02:30:34
電信科學(2016年10期)2016-11-23 05:11:56
時代農機(2015年3期)2015-11-14 01:14:29
科技傳播(2015年20期)2015-03-25 08:20:30
信息安全研究(2015年3期)2015-02-28 20:18:12
西安航空學院學報(2014年5期)2014-07-13 01:27:52
家電科技(2014年5期)2014-04-16 03:11:28
汽車零部件(2014年2期)2014-03-11 17:46:27
