基于DTW算法的電力調度語音識別研究和應用
2021-03-25 04:18:46王素寧朱俊杰李志勇黃宇星田朝陽陳凱鋒
電力與能源 2021年1期
王素寧,朱俊杰,李志勇,黃宇星,李 琪,田朝陽,陳凱鋒
(1.國網上海市電力公司崇明供電公司,上海 202150;2.東方電子股份有限公司,山東 煙臺 370602)
調度自動化作為智能電網系統重要的一部分,在人工智能方向的應用有大數據、云計算、調控云等[1-5]。但是在調度控制系統方面還是采用鍵盤加鼠標的傳統交互方式,因此研究新形式的人機語音交互方式很有必要[6]。人機語音交互技術在其他領域應用已經比較成熟,因此把其應用到電網調度運行中具有可行性[7-8]。人機語音交互首要需要解決的問題就是語音識別技術,電力調度具有很強的專業術語和特殊符號等,同時每個調度員有自己的說話口音、語序和方式,在相對嘈雜的環境中如何有效地識別出調度人員的聲音并準確完成相對應的指令操作尤為重要[9-10]。
語音識別可分為孤立詞識別、連接詞識別和連續語音識別等[11]。針對語音識別最主要的方法有動態時間規整 (Dynamic Time Warping,簡稱DTW)算法、隱馬爾可夫模型(Hidden Markov Model,簡稱HMM)、神經網絡,深度學習等[12-15]。本文將采用改進的DTW與GMM-HMM算法相結合完成語音地精準識別。
1 語音識別系統原理和步驟
1.1 語音識別基本框架
一個語音識別系統框架主要包括:聲學分析(Signal Analysis)、聲學模型(Acoustic Model)、詞典(Lexicon)、語言模型(Language Model)、搜索/解碼(Search/Decoding),具體如圖1所示。

圖1 語音識別系統框架
(1)聲學分析,也稱特征提取,用于提取有用信息,將一段語音幀解析為一個固定維數的特征向量。常用方法有梅爾頻率倒譜系數(Mel-frequency cepstral Coefficient,簡稱MFCC)和感知線性預測系數(Perceptual Linear Prediction,簡稱PLP)。
(2)聲學模型:解析聲學信號,比如將特征向量解析到一個特征的建模單元上,并獲得相應的得分,常用算法有動態時間規整 (Dynamic Time Warping,簡稱DTW)、人工神經網絡-隱馬爾可夫模型(Artificial Neural Network-Hidden Markov Model,簡稱ANN-HMM)、深度神經網絡-隱馬爾可夫模型(Deep Neural Network-Hidden Markov Model,簡稱DNN-HMM)等。
(3)詞典:給單詞和發音提供HMM模型(亞詞)和語言模型間關聯。通常基于音素,由專家手工完成。
(4)語言模型:提供這部分的先驗概率,可以區分相同發音時的識別結果。
(5)搜索/解碼:根據狀態系列,在時間狀態序列(Time-state Trellis)中找到一個最優路徑,或者說根據聲學模型輸出的結果,結合辭典、語言模型信息,找出最有可能的識別結果。
1.2 語音識別流程
語音識別原理:①首先對聲音進行預處理(預加重、分幀、加窗和端點檢測);② 再根據人的語音特點建立語音模型,對輸入的語音信號進行分析,并抽取所需的MFCC 特征參數和基音周期,在此基礎上建立語音識別所需的模板[16-17]。計算機在識別過程中要根據語音識別的模型,將計算機中存放的語音模板與輸入語音信號的特征進行比較,根據一定的搜索和匹配策略,找出一系列最優的與輸入語音匹配的模板。然后根據此模板的定義,通過查表就可以給出計算機的識別結果。具體流程如圖2所示。

圖2 語音識別流程圖
圖2的左半部分可作為前端,用于處理音頻流,從而分隔可能發聲的聲音片段,并將它們轉換成一系列數值。聲學模型就是識別這些數值,給出識別結果。圖2的右半邊作為后端,是一個專用的搜索引擎,它獲取前端產生的輸出,在一個發音模型、一個語言模型、一個詞典這三個數據庫進行搜索[18-20]。顯然,計算機查表取得最優的結果與特征的選擇、語音模型的好壞、模板是否準確都有直接的關系。
2 改進的DTW算法
2.1 DTW算法原理
同一個人在不同時間段對相同組詞發音都可能存在差異。這種差異導致音強的大小、頻譜的偏移和音節長短每次都不完全相同[21]。DTW算法用于比較兩個序列的相似程度,或者說兩個序列的距離。基于動態規劃構建序列和序列的距離矩陣,具體公式如下:
dp(i)[j]=
(1)

DTW算法最后的輸出結果就是要找到一條累積距離最小的扭曲曲線,也就是損失矩陣的最后一行最后一列的值,即給定了距離矩陣,如何找到一條從左上角到右下角的路徑,使得路徑經過的元素值之和最小。最優路徑示意圖見圖3。
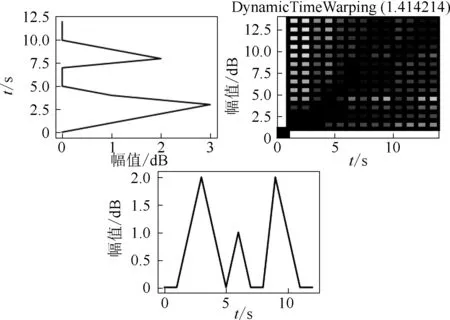
圖3 最優路徑示意圖
2.2 GMM-HMM算法原理
GMM-Model算法是基于高斯分布,主要通過加權的方式組合得到。隱馬爾可夫模型(HMM)由Markov(狀態轉移序列) 鏈和每次狀態轉移時轉移狀態和記錄的時間之間組成的信號和狀態序列兩個隨機過程組成[21]。HMM 模型在數學模型上的符號描述為λ=(π,A,B),如圖4所示。

圖4 HMM示意圖
在語音識別系統中,根據采集到的語音信號通過相應的算法去建立相對應的高斯混合模型,結合GMM算法擬合說話者的語音產生。
(2)
式中xi——D維語音特征矢量;pi(xi)——GMM模型片段概率;ai——相應片段概率pi(xi)的權重;M——GMM算法中的片段數目。
2.3 DTW算法的優化
在語音識別中使用DTW算法進行語音相似度比較,將實時語音指令與指令語音樣本序列號成向量進行相似度比較,選取相似度最大的指令語音樣本所對應的指令來判斷是否是實時語音所輸入的指令。通過相似度比較,簡單判斷可以取最近距離的結果來進行判斷,但為了提高準確率,需要進一步對算法進行優化。
2.3.1 對語音分片和分組
本次研究的輸入指令格式是固定的,每個指令有多少“3U0圖”、“電網精靈”、“通道監視圖”等。每個指令的元音輔音個數是確定的,即語音包絡的峰谷個數也是確定的,因此在進行語音DTW計算時不是與所有樣本匹配,同時由于發音會有長短變化,所以也不能只用時長、峰谷個數來限定匹配范圍,對于“圖”、“站”是指令中經常出現的語音單元,通過對包絡切片,識別最后一個包絡如圖5和圖6所示。

圖5 “圖”波形

圖6 “站”波形
2.3.2 路徑權重優化
根據式(1)計算出“測試指令”與“指令1”和“指令2”的距離,如圖7和圖8所示。

圖7 測試指令和指令1的距離

圖8 測試指令和指令2的距離
從圖7和圖8可以看出,“測試指令”與“指令1”相似。“測試指令”與“指令1”和“指令2”的距離分別是dq1和dq2。其中,dq1=1.802 776;dq2=1.723 369。dq2更小,這個結果與實際不符合。因此,對路徑計算引入權重,設權重系數為α。這個α和原算法的距離dp相乘,得到更新后的dp*。基于原算法距離,可以求出dp[i][j],改進后dp[i][j]*,的公式如下:
(3)
式中mseqLen——圖中最優路徑節點個數;mcomLen——每段直線路徑對角線個數。
改進后:dq1=0.725 113;dq2=0.861 68。改進后“測試指令”和“指令1”距離更小,更符合匹配結果。
2.3.3 路徑搜索范圍優化
同樣的語音指令在穩定狀態有時間長短、振幅差異,總體包絡形態相似。因此,在進行DTW計算之前先將峰谷單元進行歸一化。即每個峰谷都歸一化成時間長短0.5 s,振幅正負1的歸一化單元波形。DTW計算搜索的范圍不對所有點進行搜索,集中偏移和對角線鄰居范圍搜索。
2.4 頻譜優化及應用
頻譜反應了說話人聲音器官發音的頻率范圍,高頻率會在波形中產生更緊密的周期性能量疊加。同時固定的背景噪聲也有固定的頻譜,因此在以下方面進行優化。
通過語音波形計算出語譜,然后進行二階高斯模糊函數處理,降低高頻譜分量的權重,調整高斯函數的μ(x的均值),σ(x的方差)來適應不同語音速度的模糊處理。例如語音指令,其波形、語譜,高斯模糊處理后的語譜經過圖像壓縮后得到語譜hash,如圖9和圖10所示。通過處理后可減少DTW向量匹配個數,“地理圖”可加快匹配速度。
圖9 “地理圖”波形
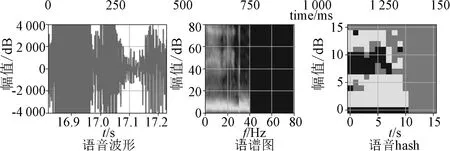
圖10 語音波形、語譜和hash圖
3 結語
本文提出了一種基于改進的DTW在電力調度中應用的語音識別方法,通過試驗表明該方法在電力調度語音識別中更具有優良性。通過在上海崇明電網主配網站一體化的DF8003系統上應用,減少了調控人員的操作,提高了崇明地調人員的工作效率,可以在上海甚至全國電網調度推廣。由于本次制作的電力調度語音庫詞匯有限,針對更復雜的語音庫需要進一步進行研究。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
測控技術(2018年5期)2018-12-09 09:04:26
電子測試(2018年18期)2018-11-14 02:30:34
電信科學(2016年10期)2016-11-23 05:11:56
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
西安航空學院學報(2014年5期)2014-07-13 01:27:52
