基于cw2vec 與CNN-BiLSTM 注意力模型的中文微博情感分類
2021-03-25 02:09:26盧昱波劉德潤蔡奕超楊慶雨劉太安
軟件導刊 2021年3期
盧昱波,劉德潤,蔡奕超,楊慶雨,陳 偉,劉太安,
(1.山東科技大學計算機科學與工程學院,山東青島 266590;2.山東農業大學信息科學與工程學院,山東泰安 271018;3.山東科技大學智能裝備學院,山東泰安 271019)
0 引言
據中國互聯網絡信息中心(CNNIC)發布的第45 次《中國互聯網絡發展狀況統計報告》[1],截至2020 年3 月,我國網民規模為9.04 億,手機網民所占比例高達99.3%,互聯網普及率達到64.5%。移動終端和互聯網的大規模普及已經改變了人們收集信息、表達觀點的方式,越來越多的公眾更傾向于通過網絡發表意見、抒發情感。互聯網上產生大量網民的認知、態度、情感和行為傾向,這些信息集合為網絡輿情[2]。目前以新浪微博為代表的中文微博取得空前發展。根據新浪微博2020 年第一季度財務報告[3],2020年Q1 的月活躍用戶為5.5 億,移動端月活躍用戶突破5億,日活躍用戶2.41 億。面對數據的爆炸性增長以及微博用戶較高的自由度進行中文微博的情感分類,不僅可對內容監控,而且也是突發事件預警及輿情分析的基礎,不但能幫助決策者更快地了解大眾意見,還能為企業進行市場分析、調查、反饋提供更多有參考性的信息。因此,中文微博信息處理技術具有重要的理論與應用價值。
情感分類研究可分為基于情感詞典的情感分類方法、基于傳統機器學習的情感分類方法和基于深度學習的情感分類方法。基于情感詞典的方法根據現有的情感詞典和計算規則獲得情感類型。國外對情感詞典的研究較早,其中應用最廣的英文詞典是SentiWordNet[4];在中文情感分類中,使用最廣泛的是知網HowNet 情感詞典[5]。傳統的基于機器學習的情感分類方法解決基于情感詞典方法中存在的問題,該方法將文本轉換為結構化數據,然后構造基于機器學習的分類器,最后確定文檔情感類型。Pang等[6]首次將機器學習引入情感分類中,通過實驗對比各類算法在電影評論情感分類中的表現,發現支持向量機的分類性能最優;García 等[7]在影評數據集上訓練樸素貝葉斯模型,提高了情緒分析的準確率;為克服傳統機器學習方法在時間序列上信息表達不足的缺點,基于深度學習的情感分類將深度學習模型引入自然語言處理領域,取得了很好效果;基于卷積神經網絡理論,Yang 等[8]改進Kim 提出的模型,對Twitter 的推文進行分類研究,驗證了卷積神經網絡對Twitter 信息情感分類的優越性能;Hassan 等[9]提出基于CNN 和LSTM 的網絡結構ConvLstm,利用LSTM 代替CNN 中的池化層,減少局部細節信息的丟失,在句子序列中捕獲長期依賴關系,表現出較好的分類效果;Wang 等[10]提出連接CNN 層的輸出作為RNN 輸入,將得到的句子特征表達輸入至Softmax 分類器,取得較好的分類效果。
從上述研究可知,目前理論不僅對中文的情感詞訓練缺乏關注,而且單一的深度學習模型也無法對局部特征和上下文信息同時提取。因此,本文提出基于中文筆畫的cw2vec 模型對中文詞進行訓練,使用CNN-BiLSTM 注意力的混合深度學習模型對中文文本進行情感分類。在相同的數據集上對比不同的單一深度學習模型,驗證本文方法的有效性。
1 cw2vec 模型
在自然語言處理領域,詞向量的訓練有重要作用,廣泛應用于詞性分類、命名實體識別、機器翻譯等領域[11]。現存的方法主要是詞級別的基于上下文信息表征學習,如2013 年Mikolov 等[12]提出兩種神經網絡語言模型—連續詞袋模型CBOW(Continuous Bag of Words)和Skip-gram 模型,從大量的新聞單詞中訓練出詞向量Word2vec,但是大量的詞向量模型都是基于英語進行訓練的。漢字作為中華民族的幾千年文化,具有集形象、聲音和詞義三者于一體特性,內部包含了較強的語義信息。由于中英語言完全不同,單個英文字符是不具備語義的,因此Cao 等[13]通過使用筆畫n-gram 詞向量捕獲中文詞的語義和形態信息。將中文筆畫劃分為5 類,將筆畫特征也使用相同向量表示,每個詞語使用n-gram 窗口滑動的方法將其表示為多個筆畫序列,每個gram 和詞語都被表示成向量,用來訓練和計算它們之間的相似度,如表1 所示。

Table 1 The relationship between stroke names and numbers表1 筆畫名稱與數字對應關系
詞語向量化過程如圖1 所示。將中文詞語分割為單個字符,按照筆畫順序抽取漢字筆畫特征得到整個詞語的全部筆畫信息,使用編號代替筆畫特征完成數字化,最后用大小為n 的窗口生成n-gram 筆畫特征。

Fig.1 The process of extracting n-gram stroke features from Chinese characters圖1 漢字抽取n-gram 筆畫特征過程
在cw2vec 模型中,定義相似函數sim(w,c)單詞與其上下文之間公式如式(1)所示。

其中,w和c分別是當前位置的詞和上下文單詞,S(w)為當前詞語w所對應的n 元筆畫集合,q→為當前詞語q對應的n 元筆畫向量,為上下文詞語的詞向量。目標函數計算公式如式(2)所示。
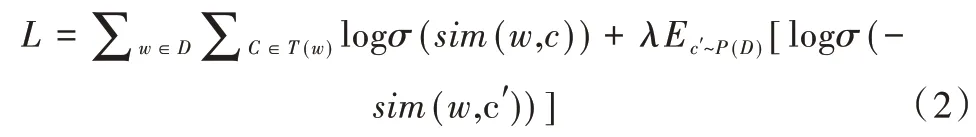
其中,w為當前詞語,D為訓練語料,T(w)是當前詞語劃窗內所有詞語集合,σ是sigmoid 函數。c′為隨機選取的詞語,稱為“負樣例”,λ是負樣例個數,Ec'~P(D)是期望,表示c′根據詞頻分布進行采樣,即語料庫中出現頻率更高的單詞可能被采樣的概率更高。
2 CNN-BiLSTM 注意力模型
通過cw2vec 模型預先訓練好詞向量,將其作為分類模型輸入。先使用CNN 進行局部特征提取,然后利用BiL?STM 進行上下文全局特征提取,最后通過注意力模型進行加權并采用Softmax 分類得到情感極性。模型結構如圖2所示。
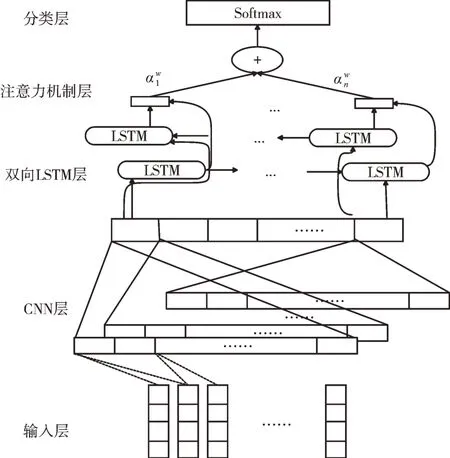
Fig.2 Network structure of CNN-BiLSTM attention model圖2 CNN-BiLSTM 注意力模型的網絡結構
2.1 CNN
CNN 是一種具有卷積結構的前饋神經網絡模型,本質上為多層感知機[14]。卷積結構能夠減少內存量占用,其中局部鏈接和權值共享操作是其廣泛應用的關鍵[15]。CNN具有多層網絡結構,卷積層、池化層和全連接層是卷積神經網絡的基本組成部分。
卷積層主要通過卷積操作感知文本的局部信息,不同尺寸的卷積核能夠提取不同的特征,卷積計算公式如式(3)所示。
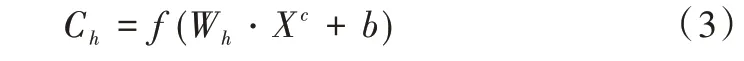
其中,Ch為不同高度過濾窗口提取到的特征,Wh為對應的權重矩陣,XC為特征矩陣,b為偏置,f為激活函數。在訓練過程中,使用Rule函數作為激活函數以提高模型的收斂速度。在對長度為n的句子進行卷積操作后生成特征圖Ch,如式(4)所示。
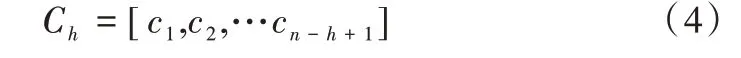
池化的主要作用是在保留局部最優特征的同時減少參數實現降維,防止過擬合。在情感分類中,一般采取最大池化策略,即只保留最大特征丟棄弱特征,如式(5)所示。
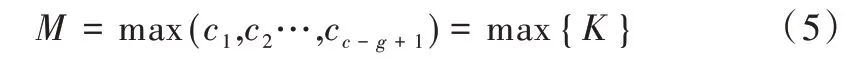
由于BiLSTM 輸入必須是序列化結構,池化將中斷序列結構K,所以需要添加全連接層,將池化后的K向量連接成向量J,如式(6)所示。

2.2 BiLSTM 模型
長短時記憶(Long short-term memory,LSTM)是一種特殊的RNN,主要解決長序列訓練過程中的梯度消失和梯度爆炸問題[16]。對于中文文本,復雜的語法和句法結構使文本的上下文都有一定的聯系,因此該層搭建了雙向LSTM對文本語義進行編碼,分別學習上文和下文,其內部結構如圖3 所示。
圖3 中,xt為t 時刻輸入,ht為t 時刻輸出,ct為t 時刻細胞狀態。LSTM 主要通過ft、it、Ot三個門結構有選擇性地實現信息流動。
ft表示遺忘門,用來控制ct-1中的信息遺忘程度,計算公式如式(7)所示。
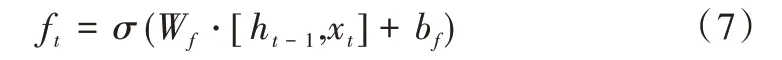
其中,σ為Sigmoid函數,Wf為遺忘門權重,bf為遺忘門偏置。

Fig.3 Internal structure of LSTM圖3 LSTM 內部結構
it代表輸入門,負責控制信息的更新程度,計算公式如式(8)所示。利用tanh函數得到候選細胞信息,計算公式如式(9)所示。依賴于遺忘門和輸入門,更新舊的細胞信息ct-1得到新的細胞信息ct,更新公式如式(10)所示。
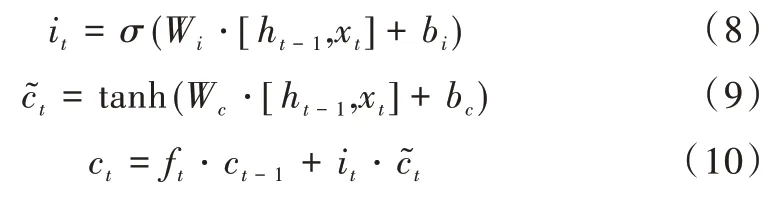
其中,Wi表示輸入門權重,bi表示輸入門偏置,Wc表示候選細胞信息權重,bc表示候選細胞信息偏置。
Ot代表輸出門,用以控制信息輸出,計算公式如式(11)所示。最終t時刻的隱層輸出ht計算公式如式(12)所示。

其中,Wo為輸出門權重,bo為輸出門偏置。
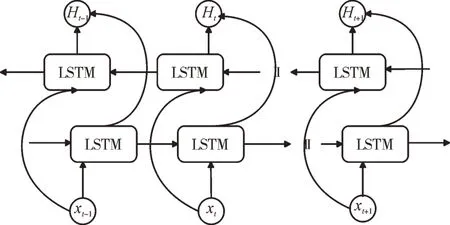
Fig.4 Bidirectional LSTM model structure圖4 雙向LSTM 模型結構
但是LSTM 模型只能學習到當前文本的上文信息,忽略了當前詞語與下文的聯系,因此通過構建雙向LSTM 充分學習上下文語義信息,如圖4 所示。為t 時刻正向LSTM 的輸出向量為t 時刻反向LSTM 的輸出向量,t 時刻雙向LSTM 的輸出Ht由連接而成,如式(13)所示。

2.3 注意力模型
注意力機制(Attention mechanism)的思想源于人類視覺系統中的“注意力”,最早應用于視覺圖像領域[17],可通過注意力概率分布的計算得出部分特征對整體的重要程度[18]。由于每個詞對于句子整體情感表達的重要程度不同,為了突出關鍵詞對情感表達的貢獻度,在雙向LSTM 模塊后引入注意力機制。通過對雙向LSTM 層提取到的序列信息進行加權變換,以生成具有注意力概率分布的向量,突出文本中重要特征對情感類別的影響程度,使情感分類準確率得到提升。計算公式如式(14)、(15)、(16)所示。
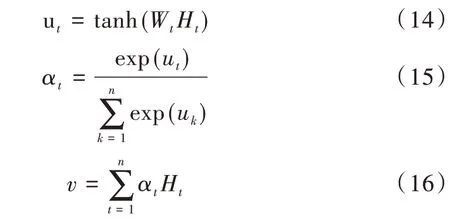
其中,ut表示Ht通過tanh層得到的隱層,Ht表示t 時刻雙向LSTM 輸出的特征向量,αt表示通過Softmax 函數得到的注意力權重,v表示加權后得到的特征向量。
用Softmax 層計算出所有可能標簽的概率,如式(17)所示。將公式進行變換得到多次迭代后的網絡參數,獲得得分最高的序列作為預測標記的正確序列。
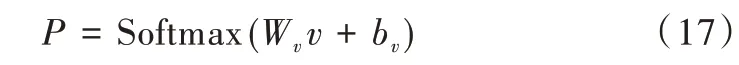
式中,Wv表示權重矩陣,bv表示偏置。
為使模型的分類誤差最小化,使用交叉熵作為損失函數并加入正則項防止過擬合,計算公式如式(18)所示。
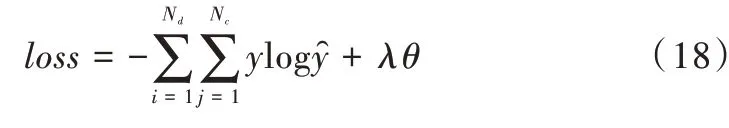
式中,Nd表示訓練集的大小,Nc表示情感類別的數量,y為文本中情感的類別,為模型預測的文本情感類別,λ表示L2 正則化,θ表示模型參數的集合。
3 實驗結果與分析
3.1 實驗數據
數據集來自GitHub 網站公開的標注微博評論,正面情感標注為1,負面情感標注為0,包含正向情感5 萬條,負向情感5 萬條共計10 萬條。實驗分別從正向和負向情感數據集中選取前3 萬條作為訓練集,其余數據作為測試集。
3.2 數據處理
(1)文本預處理。由于微博的表達形式多樣化,所以部分微博文本會帶有特殊符號,去除URL 地址、表情符號、用戶提及符號、轉發符號和主題符號等數據中的特殊符號不會影響微博文本的情感分析。本文使用正則表達式對其進行清理。
(2)文本切分。在中文中,詞與詞之間沒有明顯的分隔符,因此需要先對文本進行分割,然后才能繼續分詞。有很多常見的中文分詞工具如jieba、NLPIR、pyltp 等。通過比較不同的分詞能力,本文選擇使用jieba 分詞工具。
(3)去停用詞。解析微博文本時會有很多沒有實際意義的高頻詞,如介詞、代詞和連詞等。這些詞只是通過前后詞的連接使句子更加流暢,如“的”“了”“啊”等,在占用大量存儲空間的同時會降低數據處理效率,因此需要刪除。常用的有哈工大停用詞表和百度停用詞表。為了使停用詞覆蓋面更加全面,對上述兩個停用詞列表進行集成和刪除,獲得一個新的停用詞列表來過濾停用詞,以提高處理效率。
3.3 實驗環境與評價指標
(1)實驗環境。本文實驗環境與參數如表2 所示。
(2)評價指標。情感分類作為文本分類的一種,常見的評估指標有準確率(accuracy)、精確率(Precision)、召回率(Recall)和F1 值,計算公式如式(19)-(22)所示。

其中,T 是預測正確的數量,N 是全部數量。TP 是正向類預測為正向的數量,FP 是負向類預測為正向的數量,FN 是正向類預測為負向的數量。

Table 2 Laboratory environment configuration表2 實驗環境配置
3.4 實驗結果分析
在Tensorflow 深度學習框架下搭建CNN-BiLSTM 模型,為優化模型性能進行大量的調參實驗,最后設置本文的超參數如表3 所示。

Table 3 Parameter setting of emotion classification model表3 情感分類模型參數設置
(1)詞向量模型對比實驗。為驗證基于中文筆畫的cw2vec 模型在中文微博分類的有效性,均采用相同的中文微博文本數據集進行實驗,選取目前使用最多的word2vec中CBOW 模型和Skip-gram 模型作為參照實驗。分類模型采用本文提出的CNN+BiLSTM+注意力混合深度學習模型,評價指標采用準確率,實驗結果如圖5 所示,準確率如式(19)所示。
實驗結果表明,基于中文筆畫的cw2vec 模型比基于英文字母的CBOW 模型和Skip-gram 模型分別提升2.35%和1.19%,cw2vec 模型可以更好地利用漢字結構和筆畫信息有效捕捉漢字特征,準確率更高,魯棒性更好。
(2)分類模型對比實驗。為驗證混合深度學習模型有效性,全部采用cw2vec 模型訓練好的中文微博數據集作為輸入,設置SVM、CNN、LSTM 和BiLSTM 模型進行對比實驗,實驗結果如圖6 所示,評價指標如式(20)-(22)所示。
通過圖6 可知,SVM 模型作為機器學習中比較典型的分類模型,實驗結果較差;CNN 模型只對局部特征進行提取,學習詞語間長距離依賴的能力較差,最后的分類效果不理想;對比LSTM 模型與BiLSTM 模型,由于權值共享,會造成文本處理過程中的相對公平,但關注上下文的雙向LSTM 比只關注上文的LSTM 分類效果有所提升;CNN+BiLSTM+注意力模型、混合深度學習模型通過增加CNN 和注意力機制可以更好地提取局部關鍵特征,與BiLSTM 單一的深度學習模型相比,混合深度學習模型的精確率、召回率和F1 值分別提升1.88%、3.56% 和2.72%,證明混合深度學習模型結合cw2vec 模型在情感分類上更有效。
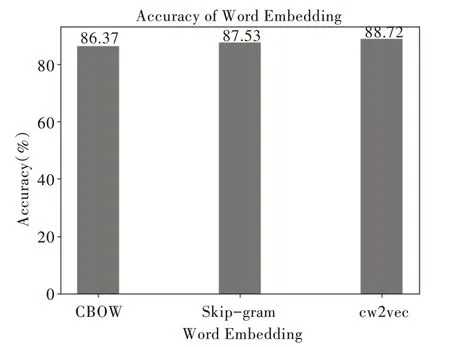
Fig.5 Comparison of segmentation model results圖5 分詞模型結果對比
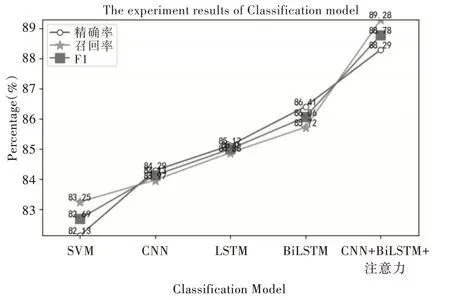
Fig.6 Experimental results of classification model圖6 分類模型實驗結果
4 結語
本文提出基于中文筆畫的cw2vec 和CNN-BiLSTM 注意力模型相結合的混合深度學習中文微博文本情感分類方法,通過cw2vec 模型將中文文本表示為詞向量作為CNN 的輸入層,并使用CNN 提取局部特征,利用BiLSTM模型提取中文文本的上下文特征并增加注意力模型獲取重要特征,加權后使用Softmax 函數進行分類。使用公開標注的中文微博數據集,先通過與CBOW 模型和Skipgram 模型進行對比,證明基于中文筆畫的cw2vec 模型的有效性,然后在cw2vec 模型基礎上與SVM、CNN、LSTM 和BiLSTM 經典模型進行對比,證明本文提出的cw2vec 和CNN-BiLSTM 注意力模型結合的方法有效。由于本文重點研究中文微博信息,沒有考慮英文文本,未來可考慮在中英文文本混合分類中加入中文微博表情方法進行情感分類研究。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中國生殖健康(2018年5期)2018-11-06 07:15:40
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
