基于YOLO 的快速道路目標檢測研究
2021-03-24 08:21:56范智翰
現代計算機 2021年3期
范智翰
(四川大學視覺合成圖形圖像技術國防重點學科實驗室,成都610065)
0 引言
在圖像處理工作中,目標檢測作為科研人員研究的熱門領域,主要采用識別圖像中目標位置的技術,用于解決“是什么?在哪里”的問題。自2012 年AlexNet的誕生后,目標檢測領域科研人員的研究方向從傳統向深度學習轉變,因為基于深度學習的目標檢測不僅具有較低的誤檢率和漏檢率,并且隨著顯卡性能高速增長準確率也逐漸接近理想值。近年來目標檢測最熱門的應用領域是道路目標檢測,無論是近年來各大科技公司投入巨資的無人駕駛汽車領域,還是有著不錯前景的車載攝像頭測距,都迫切的需要一個準確率與實時性俱佳的目標檢測算法。
傳統目標檢測方法一般是在給定的圖像上選出一些候選區域,之后對這些區域提取特征,這個過程一般需要人工來獲取原始輸入中與目標有關的表達信息,最后在提取出的與目標相關的特征信息上進行分類器學習,例如經典的SIFT[1]、HoG[2]等方法。然而這些方法都有一個明顯缺陷,就是特征的選取會受限于算法設計者的經驗與復雜的實際情況,這會導致設計者在特征選取上較為困難,并且可能出現選取特征不足以較為完整地描述該目標導致信息丟失的情況。
卷積神經網絡(Convolutional Neural Network,CNN)結合了人工神經網絡和卷積運算,對不同類型的目標及諸如形變、截斷以及扭曲等特殊情況也具有良好的魯棒性;除此之外它通過稀疏連接和權值共享大大減少了傳統神經網絡的參數數量,很多基于卷積神經網絡的檢測方法或模型在各種目標識別場景中都獲得了令人較為滿意的結果。2014 年Girshick 等人在提出了R-CNN 算法[3],在目標檢測這一領域引入CNN,檢測結果明顯優于傳統目標檢測算法,之后又誕生了Fast R-CNN[4]、Faster R-CNN[5]等改進算法。這類算法是先由候選區域算法生成一些樣本候選框,之后通過卷積神經網絡進行樣本分類。這類算法主要通過一個卷積神經網絡來完成目標檢測過程,要提取CNN 卷積特征,在訓練網絡時首先是訓練RPN 網絡,然后訓練目標區域檢測的網絡,可以看作是兩步操作,所以這類算法也被稱為two-stage 類的目標檢測算法。這類算法準確度不錯,但是在檢測時間上很難滿足道路目標檢測實時性的要求。
但實時目標檢測模型應該能夠在極短時間內檢測并解析目標,為了提高檢測速率,此領域相關科研人員提出了一類直接回歸計算物體的類別概率和位置坐標的算法,這類算法主要通過主干網絡給出類別和位置信息,不使用RPN 網絡所以只有一步操作,也被稱為one-stage 類目標檢測算法,YOLO 便是這類算法中的一個佼佼者。
1 YOLO的原理及發展
YOLO(You Only Look Once)網絡在2015 年 由Joseph Redmon 團隊提出,是最早的one-stage 類目標檢測算法。YOLO 網絡將縮放后的圖像劃分成S×S 個區域,每個區域負責檢測中心點位于本網格內的物體。每個區域會預測N 個不同的邊界框,即對每幅圖像一共生成S×S×N 個邊界候選框[6]。最后采用置信度來評估每個預測目標是否準確,置信度由兩個指標綜合判斷,分別是存在目標物體的概率以及邊界框的準確度,其中邊界框的準確度用交并比IOU 來表示:

公式中分子代表有效區域面積,即圖1 中的灰色部分,分母代表兩個邊界框一共所占面積(重疊部分只算一次)。

圖1
YOLO 自誕生起就引起了廣泛的關注,它使實時檢測變為了可能。遺憾的是,雖然速度大幅提升,但犧牲了準確率。官方團隊為了兼顧速度與效率,相繼推出了YOLOv2 與YOLOv3,還有適用于簡單場景的YOLO-Tiny 版本。
YOLO 的官方實現框架是DarkNet,DarkNet 是一種比較小眾的框架,也有相關研究人員用TensorFlow與Keras 實現,但截至2019 年底,YOLO 的歷代版本更迭都采用DarkNet 框架,本實驗也是基于DarkNet 實現的YOLOv3-Tiny 進行改動。
2 相關工作
2.1 批規范化處理BN層
機器學習訓練過程中,每次會從訓練集中選取設定批次大小的訓練數據,但每批數據的特征表現并不一致,隨著網絡不斷深入,每批數據的特征差距會對收斂速度產生明顯影響。針對這個問題可采用BN(Batch Normalization)來規范化某些層或所有層的輸入,從而可以固定每層輸入信號的均值與方差。這樣一來,即使網絡模型較深層的響應或梯度很小,也可通過BN 的規范化作用將其的尺度變大,以此便可減少深層網絡訓練很可能帶來的梯度起伏變化的相關問題[7]。
批量規范化處理不僅加快了模型收斂速度,而且更重要的是能有效抑制在不斷深入的神經網絡中可能發生的“梯度彌散”、“梯度爆炸”等問題,從而使得訓練深層網絡模型更加穩定,所以BN 層成為了幾乎所有卷積神經網絡的標配。
YOLO 從v2 版本起也加入了BN 來改進訓練和mAP,之后的版本也都采用了BN 層對數據進行處理。但加入BN 層本身是需要計算資源的,對于檢測目標類別少,且網絡層數不多的YOLOv3-Tiny,是否真的需要BN 層是一個值得思考的問題。如前文所述加入BN層是為了解決每一層特征分布不均衡的問題,而在淺層網絡中,特征不均引起的梯度問題并不明顯,而加入BN 層讓計算量明顯增大,會大大影響YOLO 的實時性,所以本實驗去掉了BN 層來增加YOLO 的檢測速度。
2.2 密集神經網絡
傳統的卷積神經網絡CNN 為了更好、更高效、更準確地去挖掘深層特征,會將網絡加深或者將網絡結構變寬使得模型能更好地去描述輸入數據內容。
CVPR 2017 獲獎論文作者胡杰提出了一種新的方式來獲取更多的特征,他表示隨著網絡深度的加深,梯度消失問題會愈加明顯,在保證網絡中每層特征信息都能盡可能傳輸的前提下,直接讓當前層連接前面所有層。為了能夠保證前面網絡層的特性,每一層將之前所有層的輸入進行整合,之后將輸出的特征圖傳遞給之后的所有層。這種連接方式使得特征和梯度的傳遞更加有效,網絡收斂速度就會加快,更容易得到理想的訓練結果。每一層都可以直接利用損失函數的梯度以及最開始的輸入信息,相當于是一種無形的深度監督(implicit deep supervision)[8]。將每層輸入都接收之前層的輸出,每層的輸出特征都是之后所有層的輸入,這種稠密連接模塊(dense block)的會比傳統的卷積網絡擁有更少的參數,因為它不需要再重新學習多余的特征圖,特征收斂更快。傳統的網絡層間特征傳遞可以被看成一種層與層之間依次傳遞的算法。每一層接收前一層的輸出,然后將新的特征傳遞給下一層。它改變了本來的特征圖,但也保留了需要的特征,讓其依舊能提供給后面的網絡。但當網絡很深的時候,每一層接收到之前網絡層的特征信息會非常龐大,處理巨量的信息會使訓練和收斂都明顯變慢,并且對特征的提取也變得更加困難,所以dense block 更適合在淺層網絡中使用,而本試驗改進的YOLOv3-Tiny 本身是一個淺層網絡,所以實驗在去掉BN 層的同時加入密集連接層,既能加快收斂,也能更好提高準確率與檢測速度。
本實驗改動后的網絡如圖2。
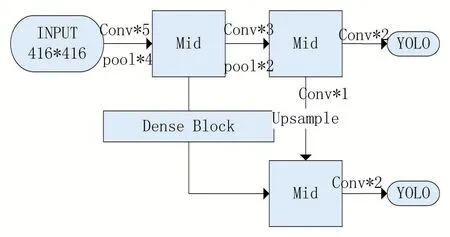
圖2 網絡示意圖
本實驗改動后的網絡命名為YOLO-DWB(YOLODenseNetWithoutBN)。
如前文所訴,前考慮網絡前段信息本身較少,收斂速度較快,基本特征較為明顯。在網絡收斂明顯變慢的后段加入一層密集連接層,接收更多的信息來減少后面網絡的計算量。
3 實驗
本實驗采用個人標注的道路實況數據集,實驗基于YOLO 的DarkNet 框架實現,采用一種配置訓練,兩種配置測試:一種CPU 是Intel Core i7-8700,顯卡為NVIDIA GTX-1080Ti,也是本試驗的訓練機;另一種CPU 是Intel Core i5-6400,顯卡為NVIDIA GT-730,采用本組配置進行測試是考慮到在車載環境下,移動端微型計算機顯卡性能有限,但一般會好于NVIDIA GT730,故采用此配置作為移動端能否實時快速的衡量標準。
3.1 數據集描述及訓練過程
為了更好地模擬車載攝像頭檢測環境,本實驗采用的數據集為由行車記錄儀保存的實際行車錄像截取的道路實況圖片。數據集包括鄉村道路,城市道路,高速公路等常見道路行車,存在各種程度的遮擋和截斷,選取的圖片均為白天或光線較好的情況下的道路實況。本實驗一共有三個類別的標簽,分別為:person、car、motor,其中motor 類是如電瓶車、自行車這類物體的,因為其特征相似,區分度較小,故歸為一類。本實驗一共選取2800 張不同路況的道路圖片,選取其中2300 張作為訓練集,500 張作為測試集。數據集樣例圖及識別樣例圖如圖3 與圖4 所示。

圖3

圖4
YOLO 官方的DarkNet 框架實現中提供了數據增廣,對圖片進行翻轉、旋轉、截取等操作來提升準確率與泛化能力。本文網絡YOLO-DWB 將訓練圖像縮放至416×416 像素,按前文的網絡示意圖過程進行訓練。批次大小(BatchSize)設置為128,學習率初始為10-3,后依次下降至10-4,迭代10 萬次后為10-5,每25000 次迭代測試一次數據,一共迭代150000 次。
3.2 評價指標與結果分析
本實驗以檢測率和檢測速率兩項指標對YOLO 與YOLO-DWB 進行評估,其中,檢測率為成功檢測的物體個數除以該類別物體總個數,成功檢測的目標是指物體類別正確且置信度大于0.5 的檢出目標,公式如下:
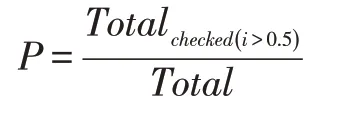
檢測速率即檢測一張圖片的時間,本實驗換算為FPS 表示,即每秒檢測的圖片數量。本實驗繪圖表示了兩種網絡在迭代過程中的收斂速度,橫軸為迭代次數,縱軸為檢測率。
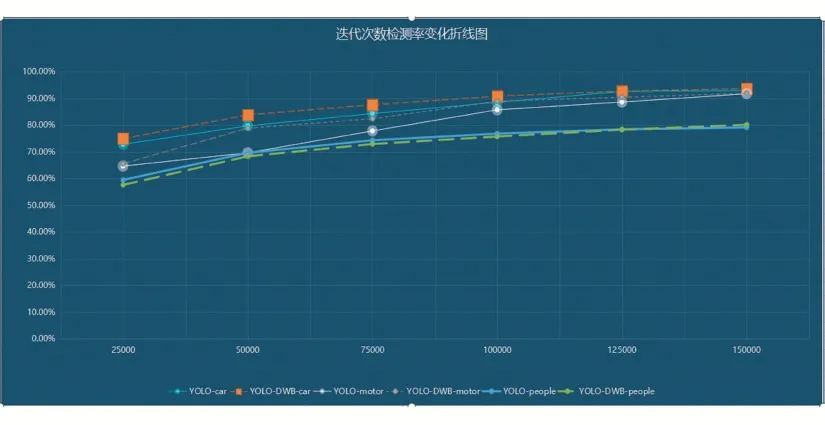
圖5 迭代次數檢測率變化折線圖
從圖中可以看到,YOLO-DWB(虛線)的收斂速度要略優于YOLO,但差距不大,在迭代次數巨大時有一定優勢,最終檢測率基本一樣,YOLO-DWB 在準確率方面沒有明顯優勢。
檢測率及檢測速度如表1、表2 所示。
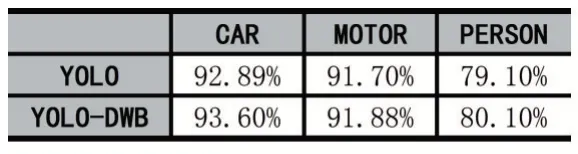
表1 (檢測率)

表2 (檢測速率)
從表1 中可以看到,去掉BN 層后再加入密集連接模塊,YOLO 的識別率變化不大,只有一點很小的提升,考慮到訓練誤差可以忽略。其中汽車和摩托類檢測率比較理想,行人類檢測率較低,這是因為小目標物體的漏檢問題一貫是目標檢測算法中一個比較難解決的問題。不過從表2 中看,檢測速率提升明顯,特別是在圖形性較弱的NVIDIA GT-730 上,速度提升了54.43%。在NVIDIA 1080Ti 上提升僅為16.61%,考慮這張顯卡本身性能強勁,原網絡已經擁有很高的幀率,提升幅度會更多地受其他因素影響。YOLO-DWB 能在NVIDIA GT-730 上跑出24.4 幀/秒的速度,那么對于目前移動端性能較強的GPU 來說能夠輕松達到30幀以上的幀率,行車記錄儀中視頻默認為30 幀,故達到30 幀以上便能夠實現實時目標檢測。
4 結語
本文實驗將以DarkNet 為實現框架YOLO 去掉BN 層,并在網絡中段加入一層密集連接層,從結果來總結實驗中的兩個改動可以得到如下結論:
(1)通過對訓練曲線的觀察,密集連接在YOLO 網絡中對收斂速度有較為明顯的影響,能更快地達到理想的效率。
(2)在YOLO 網絡中去掉批規范化處理BN 層后,加入密集連接層,對網絡最終模型的識別速度有較大影響,特別是GPU 能力偏弱的顯卡提升尤為明顯,對于在移動端需要實時的目標檢測識別等任務具有參考意義。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
