醫(yī)療輔助診斷系統(tǒng)中新型的雙向隱私保護(hù)方法*
2021-03-19 06:12:10陳磊磊陳蘭香
密碼學(xué)報(bào) 2021年1期
陳磊磊, 陳蘭香, 穆 怡,2
1. 福建師范大學(xué) 數(shù)學(xué)與信息學(xué)院福建省網(wǎng)絡(luò)安全與密碼技術(shù)重點(diǎn)實(shí)驗(yàn)室, 福州350117
2. 澳門城市大學(xué) 數(shù)據(jù)科學(xué)研究院, 澳門
1 引言
傳統(tǒng)的醫(yī)療診斷是醫(yī)生通過整理與分析一組臨床數(shù)據(jù)(包括癥狀、實(shí)驗(yàn)檢查等) 進(jìn)行診斷, 依靠的是醫(yī)生的知識(shí)基礎(chǔ)、個(gè)人洞察力以及對(duì)可用信息的整理與分析的能力. 其診斷準(zhǔn)確率完全依賴醫(yī)生的判斷,即使是經(jīng)驗(yàn)豐富的醫(yī)生也可能因?yàn)樽陨碓蚨龀鲥e(cuò)誤的分析及判斷, 因此可能導(dǎo)致診斷結(jié)果出錯(cuò)的幾率較大.
近些年, 機(jī)器學(xué)習(xí)技術(shù)取得長(zhǎng)足的發(fā)展與進(jìn)步, 利用機(jī)器學(xué)習(xí)的醫(yī)療輔助診斷系統(tǒng)(Medically Assisted Diagnosis Systems, MADS) 也得到極大的關(guān)注與發(fā)展. MADS 可以實(shí)現(xiàn)對(duì)疾病的全面分析, 幫助臨床醫(yī)生更好地進(jìn)行診斷, 可以極大地降低誤診和漏診的概率. 同時(shí), 確診的數(shù)據(jù)可以及時(shí)地添加到數(shù)據(jù)庫(kù), 有助于構(gòu)建更加有效的決策樹. 此外, 系統(tǒng)的自我更新功能可以更好地適應(yīng)醫(yī)學(xué)信息的爆炸式增長(zhǎng).
然而, 醫(yī)療信息化技術(shù)在改善醫(yī)療診治水平的同時(shí), 也導(dǎo)致患者隱私泄露、數(shù)據(jù)丟失、業(yè)務(wù)中斷等安全威脅. 現(xiàn)有的醫(yī)療輔助診斷系統(tǒng)大都注重診斷的準(zhǔn)確性而忽視了隱私保護(hù)的重要性. 因此, 為了保護(hù)醫(yī)療輔助診斷系統(tǒng)中患者的個(gè)人隱私, 本文提出一種新的結(jié)合決策樹與OT 技術(shù)的雙向隱私保護(hù)模型. 該模型在用戶進(jìn)行醫(yī)療數(shù)據(jù)查詢并得到準(zhǔn)確查詢結(jié)果的情況下, 能夠極好地保護(hù)用戶、服務(wù)器以及數(shù)據(jù)庫(kù)的隱私信息.
本文提出的醫(yī)療輔助診斷系統(tǒng)的隱私保護(hù)方法分為兩個(gè)階段: 決策樹構(gòu)建與查詢階段. 在決策樹構(gòu)建階段, 針對(duì)數(shù)據(jù)庫(kù)的來源不同對(duì)醫(yī)療輔助診斷系統(tǒng)進(jìn)行分類, 分為服務(wù)器自身?yè)碛袛?shù)據(jù)庫(kù)的MADS 和數(shù)據(jù)來源于第三方的MADS. 針對(duì)服務(wù)器自身?yè)碛袛?shù)據(jù)庫(kù)的MADS, 可以采用典型的決策樹算法構(gòu)建決策樹. 針對(duì)數(shù)據(jù)來源于第三方的MADS 采用熊等人[1]提出的用于構(gòu)建決策樹的差分隱私保護(hù)數(shù)據(jù)發(fā)布算法(DT-Diff) 進(jìn)行決策樹的構(gòu)建, 確保在構(gòu)建決策樹的過程中不會(huì)泄露數(shù)據(jù)庫(kù)的隱私, 本文將重點(diǎn)介紹這一類方案. 構(gòu)建決策樹不僅有助于提高診斷的準(zhǔn)確性, 也有助于提高方案的查詢效率.
查詢階段包括建立索引協(xié)議和OT 協(xié)議兩個(gè)方面. 為了將決策樹算法與OT 協(xié)議有效結(jié)合, 我們提出一種決策樹索引協(xié)議, 可以高效地將決策樹信息數(shù)字化, 從而便于利用OT 協(xié)議保護(hù)雙向隱私. 客戶端和服務(wù)器通過該索引協(xié)議對(duì)各自的數(shù)據(jù)建立索引, 從而為數(shù)據(jù)查詢做好鋪墊. OT 協(xié)議不僅保護(hù)客戶端的隱私, 同時(shí)也可以保證客戶端只能獲得查詢的相關(guān)信息, 而不能獲得其它額外信息, 從而保護(hù)服務(wù)器的隱私.理論分析表明, 本文提出的方法不僅保護(hù)了數(shù)據(jù)庫(kù)的隱私也保護(hù)了客戶端和服務(wù)器的隱私, 并且具有較高的通信效率. 實(shí)驗(yàn)結(jié)果也表明, 此模型不僅具有較高的查詢效率還具有較高的查詢準(zhǔn)確率.
以下章節(jié)安排如下: 第2 節(jié)介紹醫(yī)療輔助診斷系統(tǒng)的相關(guān)研究工作, 指出本研究工作與之前研究工作的不同. 第3 節(jié)介紹系統(tǒng)模型及其相關(guān)的基礎(chǔ)知識(shí). 第4 節(jié)詳細(xì)介紹本文提出的方法在MADS 系統(tǒng)中的應(yīng)用設(shè)計(jì)與實(shí)現(xiàn). 第5 節(jié)對(duì)該方法在MADS 系統(tǒng)中的應(yīng)用進(jìn)行安全性分析與性能評(píng)估, 最后對(duì)本文進(jìn)行總結(jié)并介紹下一步的工作.
2 相關(guān)工作
當(dāng)今信息化時(shí)代, 利用大數(shù)據(jù)可以更好地改善人們的生活. 在健康醫(yī)療領(lǐng)域, 隨著醫(yī)院信息化建設(shè)的不斷發(fā)展, 醫(yī)院數(shù)據(jù)庫(kù)中的信息呈爆炸式增長(zhǎng), 而醫(yī)療數(shù)據(jù)對(duì)于疾病的診斷、控制和各種醫(yī)療研究具有重要的價(jià)值. 機(jī)器學(xué)習(xí)利用計(jì)算機(jī)模擬人類的學(xué)習(xí)行為, 通過建模來對(duì)已有的數(shù)據(jù)進(jìn)行分析處理來獲取新經(jīng)驗(yàn)與新知識(shí), 不斷改善性能并實(shí)現(xiàn)自身完善.
機(jī)器學(xué)習(xí)已在健康醫(yī)療領(lǐng)域得到廣泛應(yīng)用. 如Castro-Zunti 等人[2]首次使用基于統(tǒng)計(jì)機(jī)器學(xué)習(xí)和深度學(xué)習(xí)的分類器, 通過對(duì)計(jì)算機(jī)斷層掃描(Computed Tomography, CT) 圖像分析, 結(jié)合患者的年齡來檢測(cè)早期強(qiáng)直性脊柱炎(Ankylosing Spondylitis, AS) 癥狀的侵蝕. 實(shí)驗(yàn)結(jié)果顯示隨機(jī)森林分類器的性能優(yōu)于kNN 分類器, 并且在不減少驗(yàn)證損失的情況下進(jìn)行訓(xùn)練的深度學(xué)習(xí)分類器是最佳的. Alabi 等人[3]比較了四種預(yù)測(cè)口舌鱗狀細(xì)胞癌(Oral Tongue Squamous Cell Carcinoma, OTSCC) 患者局部復(fù)發(fā)風(fēng)險(xiǎn)的機(jī)器學(xué)習(xí)算法的性能, 這些算法分別是支持向量機(jī)(Support Vector Machine, SVM)、樸素貝葉斯(Naive Bayes, NB)、增強(qiáng)決策樹(Boosted Decision Tree, BDT) 和決策森林(Decision Forest, DF).實(shí)驗(yàn)結(jié)果表明, 改進(jìn)后的決策樹算法能獲得最佳的分類精度. 此外應(yīng)用增強(qiáng)決策樹機(jī)器學(xué)習(xí)算法可以對(duì)OTSCC 患者進(jìn)行分層, 從而幫助其制定個(gè)性化的治療計(jì)劃. Liu 等人[4]在分類前采用隨機(jī)森林回歸的方法來填充缺失值, 并將基于深度神經(jīng)網(wǎng)絡(luò)(Deep Neural Network, DNN) 的自動(dòng)超參數(shù)優(yōu)化(Automated Hyperparameter Optimization, AutoHPO) 應(yīng)用于不平衡數(shù)據(jù)集的筆畫預(yù)測(cè), 為基于不完整和等級(jí)不平衡的生理數(shù)據(jù)開發(fā)一種混合機(jī)器學(xué)習(xí)方法來預(yù)測(cè)腦卒中的臨床診斷. 結(jié)果表明該方法有效地降低了假陰性率, 總體準(zhǔn)確率較高, 成功地降低了卒中預(yù)測(cè)的誤診率. Tseng 等人[5]使用機(jī)器學(xué)習(xí)算法, 即隨機(jī)森林、支持向量機(jī)、邏輯回歸和貝葉斯分類算法, 根據(jù)腫瘤細(xì)胞的表面標(biāo)記物和血清試驗(yàn)來預(yù)測(cè)乳腺癌. 實(shí)驗(yàn)結(jié)果顯示, 他們提出的基于隨機(jī)森林的模型被認(rèn)為是至少提前3 個(gè)月預(yù)測(cè)乳腺癌轉(zhuǎn)移的最佳模型, 有利于早發(fā)現(xiàn)乳腺癌復(fù)發(fā)及盡早治療.
為了更加高效地利用已有的醫(yī)療知識(shí), 在健康醫(yī)療診斷中, 人們通常使用決策樹對(duì)醫(yī)療大數(shù)據(jù)進(jìn)行分析從而對(duì)患者的發(fā)病類型及概率進(jìn)行有效地預(yù)測(cè).
如Ting 等人[6]通過基于專家經(jīng)驗(yàn)的特征提取技術(shù)與決策樹算法的自動(dòng)特征選擇能力相結(jié)合,開發(fā)了一個(gè)預(yù)測(cè)中度到重度阻塞性睡眠呼吸暫停(Obstructive Sleep Apnea, OSA) 綜合癥的診斷系統(tǒng). 與多變量logistic 回歸模型和其他四種決策樹算法進(jìn)行比較,結(jié)果顯示,所提出的最佳預(yù)測(cè)公式在靈敏度為98.2%和特異性為93.2% 的總體準(zhǔn)確度達(dá)到96.9%. Yu 等人[7]使用思維導(dǎo)圖和迭代決策樹(Iterative Decision Tree, IDT) 方法來整合臨床實(shí)踐指南, 開發(fā)一個(gè)治療甲狀腺結(jié)節(jié)的臨床決策支持系統(tǒng)(Clinical Decision Support System, CDSS). 實(shí)驗(yàn)數(shù)據(jù)顯示, CDSS 建議與常規(guī)臨床治療的一致性為78.9%. Kolluru 等人[8]開發(fā)了一種使用決策樹對(duì)血管內(nèi)光學(xué)相干斷層掃描圖像中體素斑塊類型進(jìn)行分類的方法. 此方法利用受物理啟發(fā)的光學(xué)特征、強(qiáng)度特征和紋理特征來區(qū)分不同的菌斑類型, 并將體素分為四類, 即纖維化型、鈣化型、富脂型和其他型. 實(shí)驗(yàn)結(jié)果顯示, 在訓(xùn)練集的所有褶皺和所有斑塊類型上取得了92% 的良好準(zhǔn)確率. 以上研究工作說明決策樹分類算法在醫(yī)療輔助診斷中具有極高的應(yīng)用價(jià)值, 但是這些工作只考慮了模型的準(zhǔn)確率而忽視了數(shù)據(jù)的隱私保護(hù).
健康醫(yī)療數(shù)據(jù)是高敏感數(shù)據(jù), 隱私泄露會(huì)對(duì)患者造成極大的傷害. 為了保護(hù)患者數(shù)據(jù)隱私, 2018 年,Zhang 等人[9]提出了一種新穎的身份驗(yàn)證和密鑰協(xié)商機(jī)制, 該機(jī)制通過協(xié)商共享密鑰來加密/解密敏感信息從而保護(hù)通信過程中的隱私數(shù)據(jù). 該方案利用混沌地圖實(shí)現(xiàn)相互認(rèn)證和密鑰約束, 并利用動(dòng)態(tài)身份來實(shí)現(xiàn)用戶的匿名性和對(duì)高度隱私要求的護(hù)理點(diǎn)的用戶不可追溯性. 2019 年, Lee[10]提出一種自適應(yīng)可逆水印算法, 可直接應(yīng)用于保留醫(yī)學(xué)圖像質(zhì)量的醫(yī)療系統(tǒng)以保護(hù)醫(yī)療記錄. 2020 年, Zhu 等人[11]利用人臉交換技術(shù), 使得患者的臉部可能會(huì)交換為適當(dāng)?shù)哪繕?biāo)臉部而變得無法識(shí)別, 從而達(dá)到保護(hù)醫(yī)療視頻中的患者隱私的目的.
與以上方案不同, 本文首次提出結(jié)合決策樹與不經(jīng)意傳輸技術(shù)實(shí)現(xiàn)醫(yī)療輔助診斷系統(tǒng)的雙向隱私保護(hù). 提出的方法利用決策樹對(duì)已有診斷信息進(jìn)行分類來形成輔助診斷, 為了實(shí)現(xiàn)查詢過程中的雙向隱私保護(hù), 首先利用差分隱私對(duì)決策樹加入噪聲從而確保決策樹構(gòu)建過程中不會(huì)泄露數(shù)據(jù)庫(kù)的隱私. 為了將決策樹算法與OT 協(xié)議有效結(jié)合, 我們提出一種決策樹索引協(xié)議, 可以高效地將決策樹信息數(shù)字化, 從而便于利用OT 協(xié)議保護(hù)客戶端的隱私, 同時(shí)也可以保證客戶端只能獲得查詢的相關(guān)信息, 而不能獲得其它額外信息, 從而保護(hù)服務(wù)器的隱私. 提出的方法最早將決策樹與OT 技術(shù)應(yīng)用于醫(yī)療輔助診斷系統(tǒng).
3 基礎(chǔ)知識(shí)
3.1 符號(hào)定義
本文采用的符號(hào)如下所示.

3.2 系統(tǒng)模型
本文提出的支持雙向隱私保護(hù)的醫(yī)療輔助診斷系統(tǒng)包括三個(gè)實(shí)體, 即數(shù)據(jù)提供者、客戶端和服務(wù)器,其中客戶端是用戶查詢的入口, 服務(wù)器為用戶提供查詢服務(wù), 其系統(tǒng)模型如圖1 所示. 雙向隱私保護(hù)指同時(shí)保護(hù)客戶端和服務(wù)器的隱私, 同時(shí)為了保護(hù)數(shù)據(jù)提供者的數(shù)據(jù)隱私, 我們利用文獻(xiàn)[1] 提出的用于構(gòu)建決策樹的差分隱私保護(hù)數(shù)據(jù)發(fā)布算法DT-Diff 進(jìn)行決策樹的構(gòu)建, 確保在構(gòu)建決策樹的過程中不會(huì)泄露數(shù)據(jù)庫(kù)的隱私. 為了保護(hù)客戶端和服務(wù)器的隱私, 我們利用文獻(xiàn)[12] 提出的針對(duì)惡意接收者的OT 協(xié)議確保查詢時(shí)客戶端和服務(wù)器的隱私. OT 協(xié)議使得客戶端只能得到發(fā)送的查詢請(qǐng)求對(duì)應(yīng)的查詢結(jié)果, 而不能得到其他任何信息, 從而保護(hù)服務(wù)器的隱私; 同時(shí), OT 協(xié)議可以保證服務(wù)器不知道客戶端查詢的信息,從而確保客戶端的隱私.
提出的醫(yī)療輔助診斷系統(tǒng)雙向隱私保護(hù)方法主要包括兩個(gè)階段. (1) 決策樹構(gòu)建階段: 為了保護(hù)數(shù)據(jù)提供者的數(shù)據(jù)隱私, 對(duì)數(shù)據(jù)執(zhí)行隱私保護(hù)算法. 與DT-Diff 算法略有不同的是, 本文將此算法分為兩個(gè)部分來執(zhí)行. 第一步, 數(shù)據(jù)提供者首先對(duì)數(shù)據(jù)庫(kù)中的數(shù)據(jù)進(jìn)行完全泛化, 然后通過循環(huán)迭代對(duì)數(shù)據(jù)進(jìn)行逐步細(xì)分以得到所有細(xì)分方案s, 并計(jì)算每種細(xì)分方案的可用性水平u(D,s), 此后, 數(shù)據(jù)提供者將得到的所有細(xì)分方案及其對(duì)應(yīng)的被選擇概率發(fā)送給服務(wù)器. 第二步, 服務(wù)器采用隨機(jī)函數(shù), 根據(jù)方案被選擇概率在所有細(xì)分方案中選擇一種細(xì)分方案構(gòu)建決策樹. (2) 查詢階段: 客戶端發(fā)送查詢請(qǐng)求給服務(wù)器, 服務(wù)器根據(jù)設(shè)計(jì)的OT 算法協(xié)議將計(jì)算結(jié)果返回給客戶端, 客戶端通過OT 協(xié)議計(jì)算得到查詢結(jié)果.
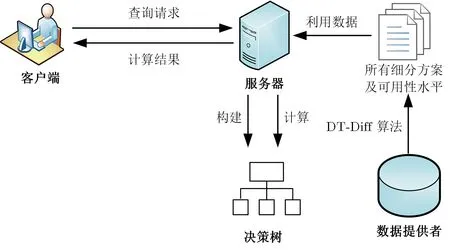
圖1 系統(tǒng)模型Figure 1 System model
本文設(shè)計(jì)的OT 協(xié)議可以保證服務(wù)器不能得到客戶端的計(jì)算結(jié)果, 客戶端也只能得到查詢相關(guān)的信息, 而得不到其它額外信息, 從而可以實(shí)現(xiàn)雙向隱私保護(hù). 為了將DT-Diff 算法和OT 協(xié)議有效結(jié)合, 我們提出決策樹索引協(xié)議, 可以高效地將決策樹信息數(shù)字化. 決策樹索引由服務(wù)器構(gòu)建并發(fā)布, 客戶端能夠采用同樣的索引協(xié)議將查詢請(qǐng)求信息數(shù)字化, 從而利用OT 協(xié)議實(shí)現(xiàn)隱私保護(hù).
3.3 差分隱私
3.3.1 定義
差分隱私[13]是Dwork 在2006 年針對(duì)統(tǒng)計(jì)數(shù)據(jù)庫(kù)的隱私泄露問題提出的一種新的隱私定義. 在此定義下, 單個(gè)記錄的變化對(duì)數(shù)據(jù)集處理結(jié)果的影響幾乎是微乎其微的.
定義1 (差分隱私) 對(duì)于任意兩個(gè)鄰近數(shù)據(jù)集D1和D2, 數(shù)據(jù)間最多相差一條記錄, 給定一個(gè)隱私保護(hù)算法A, range(A) 表示算法A 所有可能輸出構(gòu)成的集合, 對(duì)于range(A) 的任意子集S, 若算法A 滿足公式(1),
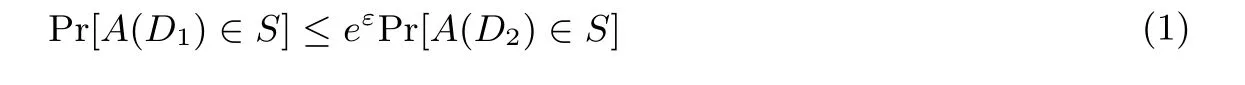
則稱算法A 提供ε-差分隱私保護(hù). 其中Pr[Es] 表示事件Es發(fā)生的概率, 即隱私泄露的風(fēng)險(xiǎn). 參數(shù)ε 稱為隱私保護(hù)預(yù)算[14], 即由數(shù)據(jù)擁有者視數(shù)據(jù)安全需求所指定的隱私保護(hù)水平.
3.3.2 實(shí)現(xiàn)機(jī)制
為了使一個(gè)隨機(jī)化算法具有ε-差分隱私性, 文獻(xiàn)[15] 提出了實(shí)現(xiàn)差分隱私保護(hù)的Laplace 機(jī)制.Laplace 機(jī)制通過向確切的查詢結(jié)果中加入服從Laplace 分布的隨機(jī)噪聲來實(shí)現(xiàn)ε-差分隱私保護(hù). 記位置參數(shù)為0、尺度參數(shù)為b 的Laplace 分布為L(zhǎng)ap(b), 那么其概率密度函數(shù)為公式(2).

定義2 (Laplace 機(jī)制) 給定數(shù)據(jù)集D, 設(shè)有函數(shù)f :D →Rd(表示d 維實(shí)數(shù)向量), 其敏感度為?f,那么隨機(jī)算法A(D) = f(D)+Y 提供ε-差分隱私保護(hù), 其中Y ~Lap(?f/ε) 為隨機(jī)噪聲, 服從尺度參數(shù)為?f/ε 的Laplace 分布.
由于Laplace 機(jī)制僅適用于數(shù)值型數(shù)據(jù), 而在實(shí)際應(yīng)用中, 有大量的非數(shù)值型數(shù)據(jù). 因此, McSherry等人[16]提出了指數(shù)機(jī)制.
定義3 (指數(shù)機(jī)制) 設(shè)算法A 的輸入為數(shù)據(jù)庫(kù)D, 輸出為一實(shí)體對(duì)象r ∈range(A), range(A) 為算法A 的輸出域, 函數(shù)q(D,r) →R 稱為輸出值r 的可用性度量函數(shù), 用來評(píng)估輸出值r 的優(yōu)劣程度. 其中R 表示實(shí)數(shù)集, ?q 是函數(shù)q 的敏感度. 若算法A 以正比于eεq(D,s)/2?q的概率從range(A) 中選擇并輸出r, 那么算法A 提供ε-差分隱私保護(hù).
此外, 還有其他的機(jī)制建立在這兩個(gè)經(jīng)典機(jī)制之上, 如基于數(shù)據(jù)劃分與數(shù)據(jù)聚合[17–20]、基于適應(yīng)性查詢[21]的隱私保護(hù)機(jī)制. 其它隱私保護(hù)機(jī)制還有基于高斯分布[22]、基于相關(guān)性[23]、基于最優(yōu)機(jī)制[24]以及基于變換編碼[25]等.
3.4 OT 協(xié)議
3.4.1 定義

3.4.2 針對(duì)惡意用戶的OT 協(xié)議
文獻(xiàn)[12] 提出的OT 協(xié)議是一個(gè)OTnk協(xié)議, 即接收方同時(shí)選擇k 個(gè)消息. 文獻(xiàn)[12] 考慮了半誠(chéng)實(shí)的發(fā)送方和半誠(chéng)實(shí)/惡意的接收方, 而本文考慮的是惡意接收方的情況, 即在醫(yī)療輔助診斷系統(tǒng)中客戶端可能是不誠(chéng)實(shí)的甚至是惡意的. 針對(duì)惡意接收方的OTnk協(xié)議設(shè)計(jì)如算法1 所示, 其中發(fā)送方是服務(wù)器, 接收方是客戶端.
在算法1 中, 接收方首先根據(jù){σ1,σ2,··· ,σk} 經(jīng)過計(jì)算得到{A1,A2,··· ,Ak} 并發(fā)送給發(fā)送方,基于Diffie-Hellman 困難假設(shè), 發(fā)送方不可能通過{A1,A2,··· ,Ak} 得到{σ1,σ2,··· ,σk}, 因此接收方的信息是無條件安全的. 在收到接收方發(fā)送的{A1,A2,··· ,Ak}, 發(fā)送方計(jì)算y、{D1,D2,··· ,Dk}以及 {c1,c2,··· ,cn} 并發(fā)送給接收方. 接收方根據(jù)發(fā)送方傳來的參數(shù)計(jì)算出 Kj, 進(jìn)一步得到{σ1,σ2,··· ,σk} 對(duì)應(yīng)的{mσ1,mσ2,··· ,mσk}. 在此過程中接收方只得到發(fā)送方的y、{D1,D2,··· ,Dk}以及{c1,c2,··· ,cn}, 因?yàn)榻邮辗街惠斎肓藍(lán)σ1,σ2,··· ,σk}, 因此接收方不會(huì)得到其它額外的信息. 綜上所述, 算法1 既保護(hù)了接收方的隱私, 也保護(hù)了發(fā)送方的隱私, 因?yàn)榻邮辗皆诓樵冞^程中只得到了與其查詢相關(guān)的信息, 而不能獲得其它任何額外的信息.

算法1 針對(duì)惡意接收方的OTnk 協(xié)議Input: (g,H1,H2,Gq), 其中Gq 是Z?p 的子群, 其階為q, g 是Gq 的一個(gè)生成子群, H1, H2 為哈希函數(shù). 發(fā)送方的數(shù)據(jù){m1,m2,··· ,mn}, 接收方的選擇{σ1,σ2,··· ,σk}.Output: mσ1,mσ2,··· ,mσk.1 接收方計(jì)算wσj = H1(σj) 和Aj = wσj gaj , 其中aj ∈R Z?p, j = 1,2,··· ,k;2 接收方將A1,A2,··· ,Ak 發(fā)送給發(fā)送方;3 發(fā)送方計(jì)算y = gx, Dj = (Aj)x, wi = H1(i), ci = mi ⊕H2(wxi), 其中x ∈R Z?p, i = 1,2,··· ,n,j = 1,2,··· ,k;4 發(fā)送方將y、D1,D2,··· ,Dk 和c1,c2,··· ,cn 發(fā)送給接收方;5 接收方計(jì)算Kj = Dj/yaj, 得到mσj = cσj ⊕H2(Kj).
其正確性推導(dǎo)見公式(3).

4 新型的雙向隱私保護(hù)方法
為了實(shí)現(xiàn)醫(yī)療輔助診斷系統(tǒng)中的雙向隱私保護(hù), 首先利用決策樹對(duì)已有診斷信息進(jìn)行分類來形成輔助診斷, 為了實(shí)現(xiàn)查詢過程中的雙向隱私保護(hù), 首先利用差分隱私對(duì)決策樹加入噪聲從而確保決策樹構(gòu)建過程中不會(huì)泄露數(shù)據(jù)庫(kù)的隱私. 無論是決策樹還是OT 協(xié)議, 在系統(tǒng)中都不能直接應(yīng)用, 為了將決策樹算法與OT 協(xié)議有效結(jié)合, 我們提出一種決策樹索引協(xié)議, 可以高效地將決策樹信息數(shù)字化, 從而在醫(yī)療輔助系統(tǒng)中應(yīng)用設(shè)計(jì)的OT 協(xié)議實(shí)現(xiàn)客戶端和服務(wù)器的雙向隱私保護(hù).
4.1 基于DT-Diff 算法的決策樹構(gòu)建
利用DT-Diff 算法來構(gòu)建決策樹的過程包括兩個(gè)階段: (1) 細(xì)分方案階段, 數(shù)據(jù)提供者將數(shù)據(jù)庫(kù)中的數(shù)據(jù)進(jìn)行完全泛化后再細(xì)分, 并計(jì)算每種細(xì)分方案被選擇的概率; (2) 決策樹構(gòu)建階段, 服務(wù)器按照一定的概率分布選擇一種細(xì)分方案構(gòu)建決策樹. 下面將對(duì)兩個(gè)階段進(jìn)行詳述.
4.1.1 細(xì)分方案劃分
數(shù)據(jù)提供者首先對(duì)數(shù)據(jù)集進(jìn)行完全泛化, 然后通過多次循環(huán)迭代完成數(shù)據(jù)的逐步細(xì)分, 每次迭代的主要任務(wù)是從全部屬性值中以指數(shù)機(jī)制選擇一個(gè)值進(jìn)行細(xì)分, 并計(jì)算每種細(xì)分方案s 的可用性水平u(D,s).在用指數(shù)機(jī)制選擇一個(gè)屬性值進(jìn)行細(xì)分時(shí), 需要根據(jù)屬性值的類型采用相應(yīng)的細(xì)分方法. 對(duì)于離散屬性的細(xì)分要依照事先設(shè)計(jì)的細(xì)分層次樹, 對(duì)于連續(xù)屬性的細(xì)分則是從其值域中選擇分裂點(diǎn)來將其一分為二, 必須保證選擇的分裂點(diǎn)在數(shù)據(jù)集中沒有出現(xiàn), 否則會(huì)違背差分隱私的要求. 數(shù)據(jù)的細(xì)分流程如圖2 所示.
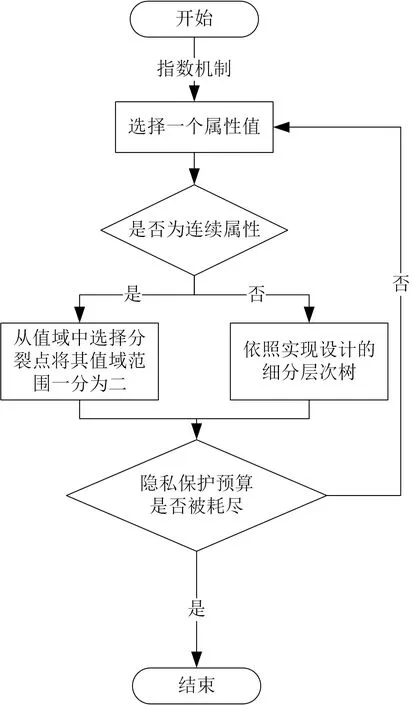
圖2 數(shù)據(jù)細(xì)分Figure 2 Data subdivision
以計(jì)算生物學(xué)中的Acute Inflammations (急性炎癥) 數(shù)據(jù)集[29]的部分屬性為例, 如表1 所示.

表1 原始數(shù)據(jù)集Table 1 Original dataset
包括3 個(gè)癥狀屬性, 其中離散屬性Urination (表示排尿是否持續(xù)) 與Nausea (表示是否惡心) 的值域均為{Yes, No}, 連續(xù)屬性TEMP (表示患者的體溫) 的值域?yàn)閇35.5, 41.5]. 類別屬性有Urocystitis (表示是否患膀胱炎) 與Nephritis (表示是否患腎源性腎炎). 對(duì)該數(shù)據(jù)集的細(xì)分處理過程如圖3 所示. 第一步是初始化, 然后進(jìn)行三輪循環(huán)迭代就可以得到全部細(xì)分方案.
得到細(xì)分方案后, 需要計(jì)算每種細(xì)分方案s 的可用性水平u(D,s), 主要有兩種方式[1]: 基于信息增益與基于最大頻數(shù)和.
(1) 基于信息增益的可用性函數(shù)

圖3 細(xì)分處理過程Figure 3 Subdivision process
基于信息增益的可用性函數(shù)見公式(4), 其中v 為屬性Atrri的一個(gè)值, v1,··· ,vk為v 細(xì)分后的值,Dv表示Atrri=v 的元組構(gòu)成的數(shù)據(jù)集, I(Dv) 為數(shù)據(jù)集Dv的熵, H(Dv) 是所有子集的熵的加權(quán)和.
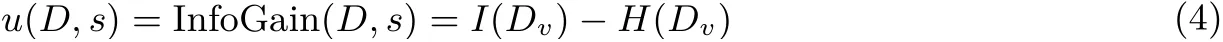
數(shù)據(jù)集Dv的熵I(Dv) 的計(jì)算見公式(5), 其中t 是分類屬性不同取值的種類數(shù), 即t 個(gè)不同類Ci,屬于類Ci的樣本個(gè)數(shù)為ci, Pri=ci/|Dv|, |Dv| 表示Dv中元組的個(gè)數(shù).
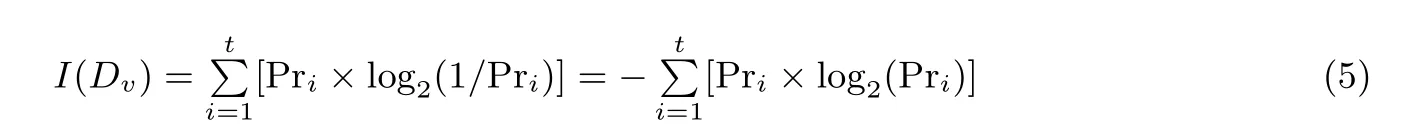
所有子集的熵的加權(quán)和H(Dv) 的計(jì)算見公式(6), 其中k 是v 細(xì)分后的值的個(gè)數(shù), Dvj表示Atrri=vj的元組構(gòu)成的數(shù)據(jù)集, I(Dvj) 是數(shù)據(jù)集Dvj的熵.
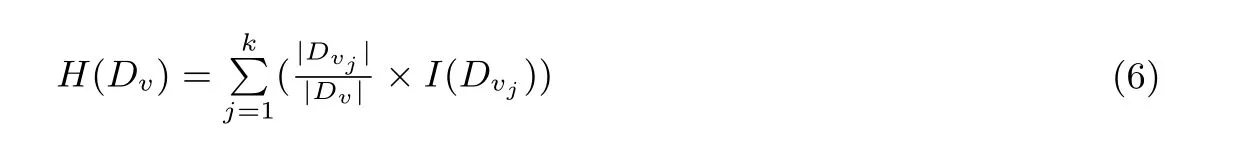

由文獻(xiàn)[1] 知, 采用基于最大頻數(shù)和的可用性函數(shù)的查詢準(zhǔn)確率高于采用基于信息增益的可用性函數(shù),我們將在實(shí)驗(yàn)部分對(duì)采用不同可用性函數(shù)的查詢準(zhǔn)確率進(jìn)行評(píng)估, 從而驗(yàn)證文獻(xiàn)[1] 中針對(duì)可用性函數(shù)的實(shí)驗(yàn)結(jié)果.
細(xì)分方案的劃分如算法2 所示, 其中solution 為所有的細(xì)分方案集S 的集合. 方案s 被選擇的概率計(jì)算見公式(8).

其中E(D,s) = eεu(D,s)/2?u, 表示方案s 以正比于eεu(D,s)/2?u的概率參與全局選擇. 針對(duì)連續(xù)屬性值,設(shè)sz表示任一連續(xù)屬性值細(xì)分方案集Sj中的一個(gè)方案, 其中z =1,2,··· ,|Sj|, |Sj| 表示細(xì)分方案集Sj中方案的數(shù)量. u(D,sz) 表示方案sz的可用性水平. 根據(jù)細(xì)分方案劃分的基本原理, 方案sz在細(xì)分方案集Sj中以指數(shù)機(jī)制被選擇的概率見公式(9).
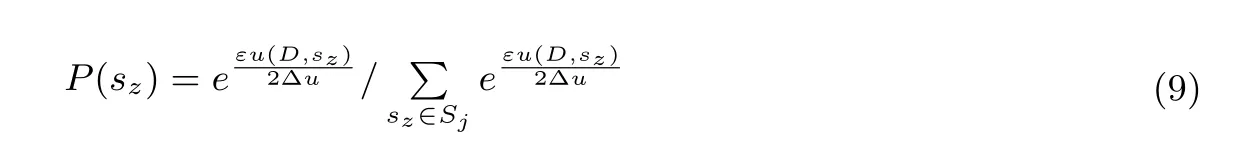
連續(xù)屬性值的細(xì)分方案sz以正比于P(sz)eεu(D,s)/2?u的概率參與全局選擇, 即針對(duì)連續(xù)屬性值,E(D,sz) = P(sz)eεu(D,s)/2?u. 針對(duì)離散屬性或文本型屬性的細(xì)分方案s, 則以正比eεu(D,s)/2?u的概率參與全局選擇. 即E(D,s)=eεu(D,s)/2?u.

?
4.1.2 決策樹構(gòu)建
數(shù)據(jù)提供者將所有細(xì)分方案及其對(duì)應(yīng)方案被選擇的概率發(fā)送給服務(wù)器, 服務(wù)器根據(jù)方案被選擇的概率, 使用隨機(jī)函數(shù)按照一定的概率分布在所有細(xì)分方案中選擇一種細(xì)分方案構(gòu)建決策樹. 細(xì)分方案選擇如算法3 所示.
4.2 基于OT 協(xié)議的雙向隱私保護(hù)
4.2.1 決策樹索引協(xié)議
決策樹是一種樹形結(jié)構(gòu), 上述決策樹的每個(gè)內(nèi)部節(jié)點(diǎn)表示一個(gè)屬性, 每個(gè)分支表示對(duì)屬性取值的一個(gè)判斷結(jié)果, 末端葉子節(jié)點(diǎn)表示根據(jù)屬性判斷得到的一種分類結(jié)果. 這種數(shù)據(jù)結(jié)構(gòu)在OT 協(xié)議中是無法直接處理的, 為了使得上述決策樹算法可應(yīng)用在基于OT 的隱私保護(hù)協(xié)議中, 我們提出將決策樹數(shù)字化的決策樹索引協(xié)議.
決策樹的數(shù)據(jù)屬性及分類結(jié)果主要包括數(shù)值型數(shù)據(jù)與文本型數(shù)據(jù), 為了將這些數(shù)據(jù)數(shù)字化, 采取的索引機(jī)制是: 對(duì)于連續(xù)型數(shù)值數(shù)據(jù), 先將連續(xù)數(shù)據(jù)劃分為區(qū)間, 然后對(duì)區(qū)間依次編號(hào), 編號(hào)從0 開始, 編號(hào)值即為索引值; 而對(duì)于離散型數(shù)值數(shù)據(jù)和文本型數(shù)據(jù), 則根據(jù)其值進(jìn)行編號(hào), 編號(hào)從0 開始, 編號(hào)值即為索引值.
根據(jù)醫(yī)療數(shù)據(jù)屬性的作用, 可以將醫(yī)療數(shù)據(jù)的屬性分為兩類, 即癥狀屬性與類別屬性. 服務(wù)器構(gòu)建決策樹后, 創(chuàng)建并發(fā)布決策樹索引協(xié)議, 索引協(xié)議包括屬性排列和屬性索引表兩部分. 屬性排列主要是對(duì)屬性的先后順序加以描述, 本節(jié)主要介紹屬性索引表的建立, 以圖3 的細(xì)分為例展開介紹.
(1) 對(duì)連續(xù)型數(shù)值數(shù)據(jù)的處理
患者的體溫屬性TEMP 為連續(xù)型數(shù)值數(shù)據(jù), 其值域?yàn)閇35.5, 41.5], 細(xì)分完成之后TEMP 被劃分為[35.5, 38.2] 與(38.2,41.5] 兩個(gè)區(qū)間, 可以認(rèn)為屬性TEMP 有兩種取值, 因此建立如表2 的索引表.
(2) 對(duì)離散型數(shù)值數(shù)據(jù)和文本型數(shù)據(jù)的處理
屬性Urination 表示患者排尿是否持續(xù), 為文本型數(shù)據(jù), 屬性Urination 的值域?yàn)閧yes, no}, 將yes的索引取為0, 將no 的索引取為1. 因此可以建立如表3 的索引表.

表2 TEMP 屬性索引表Table 2 Index table of TEMP attribute

表3 Urination 屬性索引表Table 3 Index table of Urination attribute
根據(jù)上述索引規(guī)則, 圖3 對(duì)應(yīng)的屬性索引如表4 所示.

表4 屬性索引表Table 4 Index table of attributes
為每個(gè)屬性建立索引后, 服務(wù)器要對(duì)決策樹的每個(gè)等價(jià)類進(jìn)行處理, 即將決策樹中每個(gè)等價(jià)類用二元組(癥狀對(duì)應(yīng)的索引, 疾病索引) 表示, 仍然以圖3 為例介紹具體過程.
令l 為癥狀屬性的個(gè)數(shù)(圖3 中l(wèi) = 3), h 為決策樹中除類別屬性之外的其他屬性值個(gè)數(shù)的最大值(圖3 中h=2), 那么癥狀對(duì)應(yīng)的索引可以表示為公式(10).
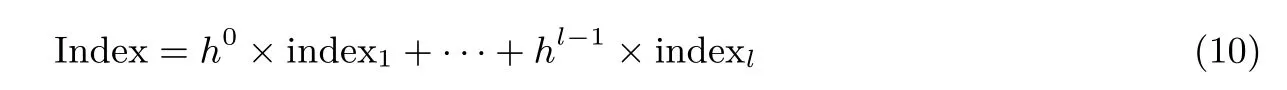
其中Index 表示癥狀對(duì)應(yīng)的索引, indexi表示第i(1 ≤i ≤l) 個(gè)屬性對(duì)應(yīng)取值的索引.
按照以上公式對(duì)所有的類別屬性使用相同的方法可以得出疾病的類型, 以類別屬性Urocystitis 和Nephritis 為例, 其索引可以表示為公式(11).
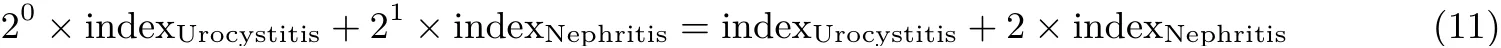
由上式可以看出此疾病索引值有0、1、2 與3 四種. 其中0 表示Urocystitis = 0 ∩Nephritis = 0,1 表示Urocystitis = 1 ∩Nephritis = 0, 2 表示Urocystitis = 0 ∩Nephritis = 1, 3 表示Urocystitis =1 ∩Nephritis=1.
為了保證查詢的準(zhǔn)確性, 在對(duì)決策樹建立索引之前需要將決策樹補(bǔ)全, 即將癥狀屬性所有可能的組合方式都展現(xiàn)在決策樹上, 再對(duì)補(bǔ)全的決策樹建立索引.
4.2.2 基于OT 的雙向隱私保護(hù)協(xié)議
通過決策樹索引協(xié)議將決策樹數(shù)字化后, 就可以設(shè)計(jì)基于OT 協(xié)議的隱私保護(hù)協(xié)議保護(hù)查詢過程中客戶端和服務(wù)器的雙向隱私. 本文設(shè)計(jì)的基于OTnk的雙向隱私保護(hù)協(xié)議取k = 1, 雙向隱私保護(hù)協(xié)議如算法4 所示, 其中客戶端是接收方, 服務(wù)器是發(fā)送方.

算法4 基于OT 的雙向隱私保護(hù)協(xié)議Input: (g,H1,H2,Gq), 其中Gq 是Z?p 的子群, 其階為q, g 是Gq 的一個(gè)生成子群, H1, H2 為哈希函數(shù). 發(fā)送方的數(shù)據(jù)mIndex1,mIndex2,··· ,mIndexn, 其中mIndexi 表示服務(wù)器集合中第i(1 ≤i ≤n) 個(gè)癥狀索引對(duì)應(yīng)的疾病索引, 接收方的選擇IC.Output: mIC.1 接收方計(jì)算wIC = H1(IC) 和AIC = wICgaIC , 其中aIC ∈R Z?p;2 接收方將AIC 發(fā)送給發(fā)送方;3 發(fā)送方計(jì)算y = gx, DIC = (AIC)x, wi = H1(Indexi), ci = mIndexi ⊕H2(wxi), 其中x ∈R Z?p,i = 1,2,··· ,n;4 發(fā)送方將y、DIC 和c1,c2,··· ,cn 發(fā)送給接收方;5 接收方計(jì)算KIC = DIC/yaIC, 得到mIC = cIC ⊕H2(KIC).
在執(zhí)行算法之前, 假設(shè)服務(wù)器已經(jīng)構(gòu)建好了決策樹及其對(duì)應(yīng)的索引, 客戶端先將要查詢的癥狀輸入并得到癥狀對(duì)應(yīng)的索引(其中癥狀有多個(gè)屬性, 一個(gè)癥狀對(duì)應(yīng)一條索引). 在算法4 中, 客戶端首先使用索引IC 經(jīng)過計(jì)算得到AIC并發(fā)送給服務(wù)器, 基于Diffie-Hellman 困難假設(shè)[12], 服務(wù)器不可能通過AIC得到IC, 因此客戶端的信息是無條件安全的. 在收到客戶端發(fā)送的AIC, 服務(wù)器計(jì)算y、DIC以及決策樹對(duì)應(yīng)的c1,c2,··· ,cn并發(fā)送給客戶端. 客戶端根據(jù)服務(wù)器傳來的參數(shù)計(jì)算出KIC, 然后計(jì)算H2(KIC), 再在c1,c2,··· ,cn中查找與H2(KIC) 值相等的H2(wxi) 對(duì)應(yīng)的i 值, 從而得出cIC, 進(jìn)一步得到索引IC 對(duì)應(yīng)的疾病類型mIC. 在此過程中客戶端只得到服務(wù)器的y 和c1,c2,··· ,cn, 因?yàn)榭蛻舳酥惠斎肓怂饕齀C, 因此客戶端不會(huì)得到其它額外的信息.
以表1 的數(shù)據(jù)為例, 構(gòu)建的決策樹如圖4(a) 所示, 為了保證查詢結(jié)果的準(zhǔn)確性, 在對(duì)決策樹建立索引之前需要將決策樹補(bǔ)全, 將圖4(a) 的決策樹補(bǔ)全后的決策樹如圖4(b) 所示. 癥狀屬性的排列為TEMP、Urination 與Nausea, 類別屬性的排列為Urocystitis 與Nephritis.
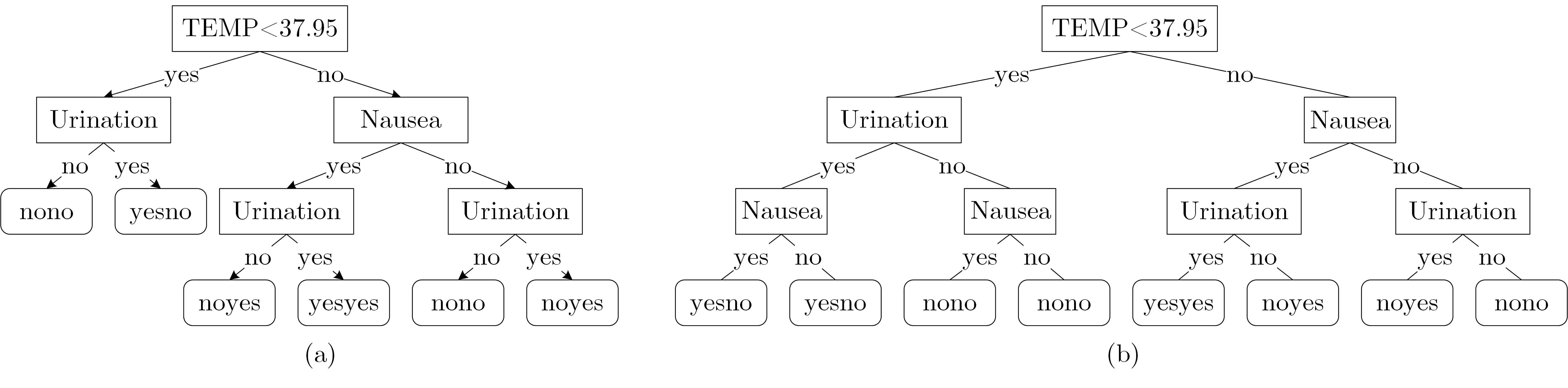
圖4 決策樹Figure 4 Decision trees
屬性的排列與建立索引的方式均公開, 采用先序遍歷的方法遍歷決策樹, 采用表4 的屬性索引表, 建立索引之后服務(wù)器存儲(chǔ)的數(shù)據(jù)如表5 所示.
假設(shè)客戶端擁有的癥狀信息為{TEMP=37, Urination =‘no’, Nausea =‘yes’}, 則IC 的計(jì)算如下:
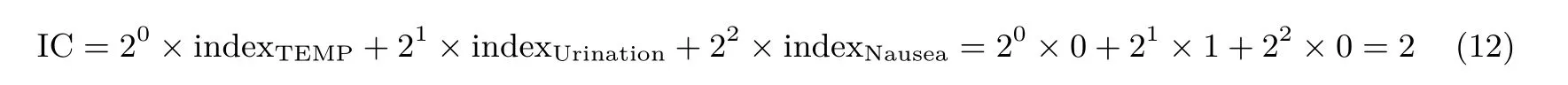
客戶端使用索引IC = 2 (表示索引的值為2) 經(jīng)過計(jì)算得到AIC= H1(IC)gaIC, 并將AIC發(fā)送給服務(wù)器(即查詢時(shí)服務(wù)器只需要知道客戶端的AIC). 因?yàn)榉?wù)器只知道客戶端的AIC, 不可能根據(jù)AIC計(jì)算出客戶端的IC. 因此, 此過程保護(hù)了客戶端的IC(即保護(hù)了客戶端的查詢隱私).
服務(wù)器擁有決策樹的每個(gè)等價(jià)類的癥狀索引以及對(duì)應(yīng)的疾病類型. 服務(wù)器需要計(jì)算y = gx, DIC=(AIC)x=(H1(IC)gaIC)x, 并通過ci=mIndexi⊕H2(wxi) (其中mIndexi表示第i 個(gè)索引對(duì)應(yīng)的疾病類型)計(jì)算決策樹每個(gè)等價(jià)類對(duì)應(yīng)的c1,c2,··· ,c8(中8 表示圖4(b) 決策樹中等價(jià)類的個(gè)數(shù)), 然后服務(wù)器將y、DIC與c1,c2,··· ,c8發(fā)送給客戶端. 在此過程中, 客戶端知道y 及c1,c2,··· ,c8, 并且只知道自身的DIC,因此, 客戶端只能通過DIC得到IC = 2 對(duì)應(yīng)的mIC, 而不會(huì)得到其它的任何信息. 即此過程保護(hù)了服務(wù)器的隱私, 使得客戶端不知道除自身癥狀對(duì)應(yīng)的疾病類型之外的其它任何信息.

表5 屬性索引表Table 5 Index table of attributes
最后,客戶端根據(jù)服務(wù)器傳來的參數(shù)計(jì)算出KIC=DIC/yaIC,然后計(jì)算H2(KIC),再在c1,c2,··· ,c8中查找與H2(KIC) 值相等的H2(wxi) 對(duì)應(yīng)的i = 3, 從而得出IC = 2 對(duì)應(yīng)的c 的值為c3, 進(jìn)一步得到索引IC 對(duì)應(yīng)的疾病類型mIC= ‘nono’ (表示客戶端輸入癥狀對(duì)應(yīng)的疾病類型為既沒有患膀胱炎, 也沒有患腎炎). 因?yàn)榇诉^程由客戶端計(jì)算, 因此服務(wù)器不知道客戶端得到的是什么信息, 從而保護(hù)了客戶端的隱私.
綜上所述, 在整個(gè)查詢過程中, 我們?cè)O(shè)計(jì)的基于OT 的雙向隱私保護(hù)協(xié)議既保護(hù)了客戶端的索引IC(即查詢隱私), 也保護(hù)了服務(wù)器的隱私, 因?yàn)榭蛻舳嗽诓樵冞^程中只得到了與其查詢癥狀相關(guān)的疾病信息, 而不能獲得其它任何額外的信息.
5 安全性分析與性能評(píng)估
5.1 安全性分析
本文提出的醫(yī)療輔助診斷系統(tǒng)中新型的雙向隱私保護(hù)主要提供三方面的隱私保護(hù):
(1) 數(shù)據(jù)提供者的數(shù)據(jù)庫(kù)隱私保護(hù): 通過利用DT-Diff 算法對(duì)原始數(shù)據(jù)執(zhí)行差分隱私保護(hù)后再構(gòu)建決策樹, 文獻(xiàn)[1] 已經(jīng)證明DT-Diff 算法可以實(shí)現(xiàn)ε-差分隱私保護(hù).
(2) 客戶端的查詢隱私: 通過設(shè)計(jì)的基于OT 的隱私保護(hù)協(xié)議, 可以確保服務(wù)器只知道客戶端的AIC,不能根據(jù)AIC計(jì)算出客戶端的IC, 即不能知道客戶端查詢哪些癥狀屬性, 從而保護(hù)客戶端的查詢隱私.
(3) 服務(wù)器的信息隱私: 通過設(shè)計(jì)的基于OT 的隱私保護(hù)協(xié)議, 客戶端知道y 及c1,c2,··· ,cn, 并且只知道自身的DIC, 因此, 客戶端只能通過DIC得到IC 對(duì)應(yīng)的mIC, 而不會(huì)得到其它的任何信息. 即此過程保護(hù)了服務(wù)器的隱私, 使得客戶端不知道除自身癥狀對(duì)應(yīng)的疾病類型之外的其它任何信息.
5.2 性能評(píng)估
為了測(cè)試支持雙向隱私保護(hù)的醫(yī)療輔助診斷系統(tǒng)的性能, 我們對(duì)該系統(tǒng)進(jìn)行了實(shí)驗(yàn). 實(shí)驗(yàn)的硬件平臺(tái)為64 位Win 7 操作系統(tǒng)、CPU 頻率2.60 GHz、RAM 為4 GB. 使用Python 開發(fā)語(yǔ)言, 數(shù)據(jù)庫(kù)使用MySQL. 測(cè)試使用UCI 機(jī)器學(xué)習(xí)數(shù)據(jù)庫(kù)中的Acute Inflammations 數(shù)據(jù)集, 實(shí)驗(yàn)分別從查詢準(zhǔn)確率、查詢效率以及算法復(fù)雜度三個(gè)方面評(píng)估系統(tǒng)的性能.
Acute Inflammations 數(shù)據(jù)集包含8 個(gè)屬性, 其中癥狀屬性6 個(gè), 類別屬性2 個(gè). 癥狀屬性包含1個(gè)連續(xù)屬性TEMP(表示患者的體溫)、5 個(gè)文本屬性分別為Nausea(表示是否惡心)、Lumbago(表示是否腰痛)、Urination(表示排尿是否持續(xù))、U-pain(表示排尿是否疼痛) 與U-discomfort(表示尿道是否不適). 類別屬性均為文本屬性, 分別為Urocystitis (表示是否患膀胱炎) 與Nephritis (表示是否患腎源性腎炎). 數(shù)據(jù)集共有600 個(gè)元組(不含缺失值) 為訓(xùn)練數(shù)據(jù), 其中100 個(gè)構(gòu)成測(cè)試數(shù)據(jù). 服務(wù)器構(gòu)建的決策樹如圖5 所示. 從圖5 中可以得出, 屬性U-pain 與U-discomfort 的值不影響疾病診斷的結(jié)果.
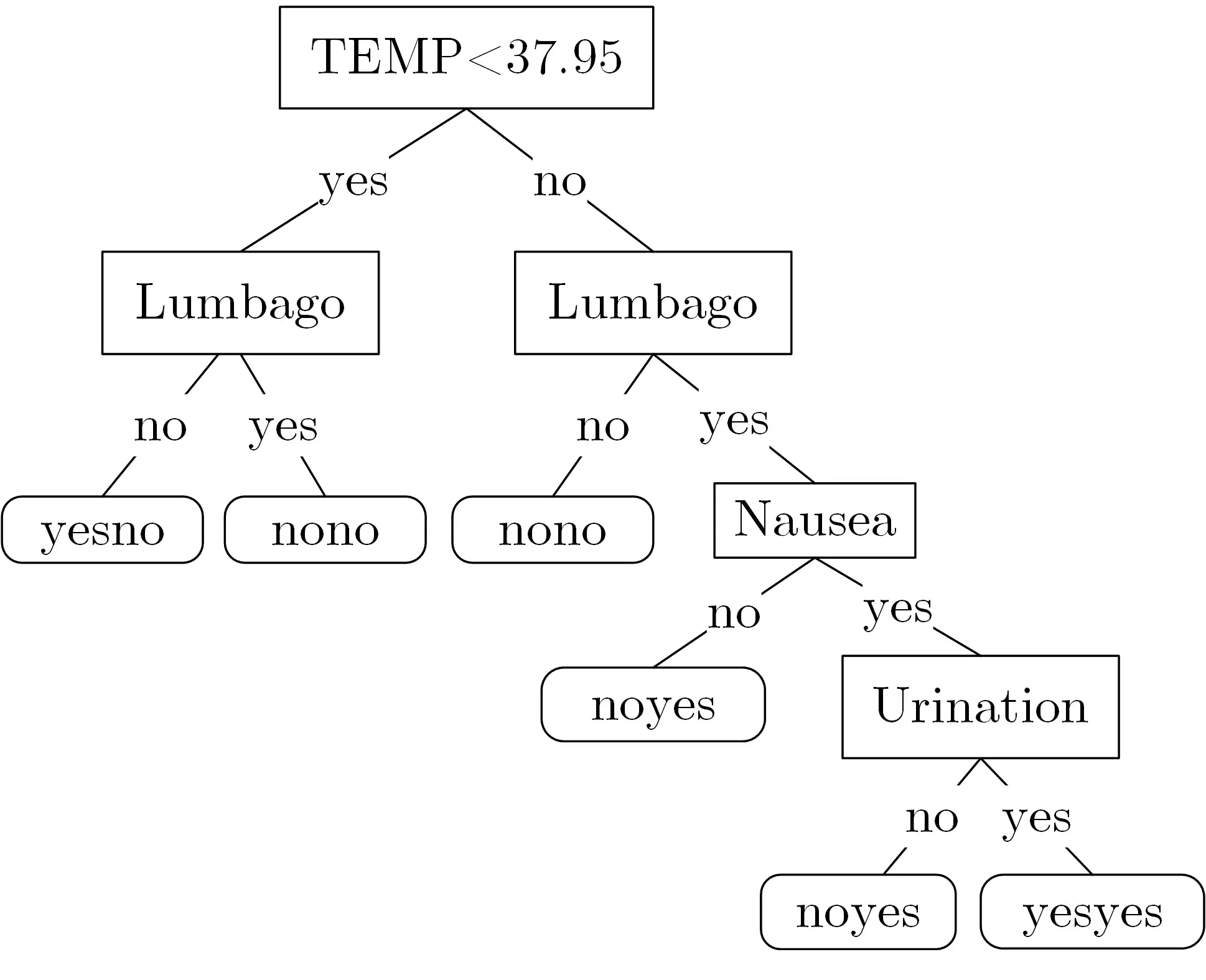
圖5 服務(wù)器決策樹Figure 5 Server decision trees
(1) 查詢準(zhǔn)確率
醫(yī)療輔助診斷系統(tǒng)的查詢準(zhǔn)確率取決于構(gòu)建的決策樹及其構(gòu)建決策樹時(shí)的隱私預(yù)算參數(shù)ε 和細(xì)分次數(shù). 其中, 構(gòu)建的決策樹對(duì)查詢的準(zhǔn)確率影響較大, 而構(gòu)建的決策樹性能好壞取決于原始數(shù)據(jù)集. 在ε =0.02、0.05、0.1 與0.25, 細(xì)分次數(shù)分別為4、7、10、13 與16 時(shí), 進(jìn)行20 組實(shí)驗(yàn). 當(dāng)采用基于信息增益的可用性函數(shù)時(shí), 其查詢準(zhǔn)確率與細(xì)分次數(shù)的關(guān)系如圖6(a) 所示. 在ε = 0.02 時(shí), 其查詢準(zhǔn)確率最低為75.6%, 最高為76.8%; 在ε=0.25 時(shí), 其查詢準(zhǔn)確率最低為77.3%, 最高為79.5%.
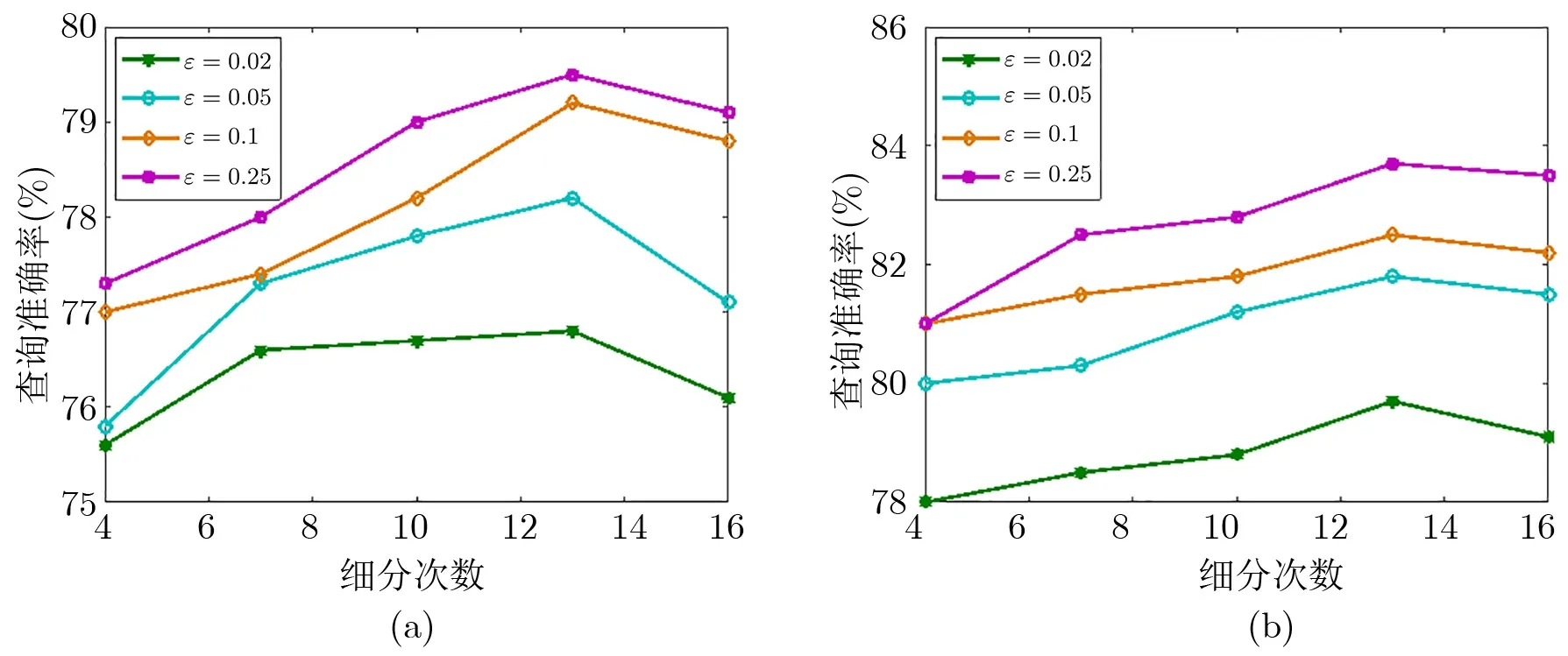
圖6 (a) 可用性函數(shù)為InfoGain(D,s) 時(shí)的查詢準(zhǔn)確率; (b) 可用性函數(shù)為MaxFS(D,s) 時(shí)的查詢準(zhǔn)確率Figure 6 (a) Query accuracy when the availability function is InfoGain(D,s); (b) Query accuracy when the availability function is MaxFS(D,s)
當(dāng)采用基于最大頻數(shù)和的可用性函數(shù)時(shí), 其查詢準(zhǔn)確率與細(xì)分次數(shù)的關(guān)系如圖6(b) 所示. 在ε=0.02時(shí), 其查詢準(zhǔn)確率最低為78%, 最高為79.7%; 在ε=0.25 時(shí), 其查詢準(zhǔn)確率最低為81%, 最高為83.7%.
差分隱私中隱私預(yù)算參數(shù)ε 越小, 其隱私保護(hù)強(qiáng)度越大, 即數(shù)據(jù)被擾動(dòng)得越厲害, 則其查詢準(zhǔn)確率越低. 當(dāng)隱私預(yù)算參數(shù)相同時(shí), 細(xì)分次數(shù)越多, 查詢準(zhǔn)確率越高. 無論是采用哪種可用性函數(shù), 其查詢準(zhǔn)確率都隨著隱私預(yù)算參數(shù)的增大而提高, 而且兩種可用性函數(shù)都是在細(xì)分次數(shù)為13 時(shí), 其查詢準(zhǔn)確率最高. 隨著細(xì)分次數(shù)的增加, 其查詢準(zhǔn)確率呈下降趨勢(shì). 原因在于當(dāng)細(xì)分次數(shù)到達(dá)某個(gè)閾值時(shí), 泛化結(jié)果中等價(jià)類的數(shù)量增加, 導(dǎo)致總體加入的噪聲增加, 從而使得查詢準(zhǔn)確率下降. 實(shí)驗(yàn)結(jié)果表明, 采用基于最大頻數(shù)和的可用性函數(shù)的查詢準(zhǔn)確率高于采用基于信息增益的可用性函數(shù).
(2) 查詢效率
在醫(yī)療輔助診斷系統(tǒng)中, 首先由服務(wù)器構(gòu)建好決策樹后, 客戶端才能查詢, 因此查詢效率主要指執(zhí)行雙向隱私保護(hù)協(xié)議的查詢效率, 并且與屬性數(shù)量及連續(xù)屬性的分類值有關(guān). 因?yàn)殡x散屬性的分類值是確定的, 因此查詢效率與離散屬性的分類值無關(guān). 屬性數(shù)量越多, 索引數(shù)據(jù)越多, 查詢效率越低. 在屬性個(gè)數(shù)相同時(shí), 屬性對(duì)應(yīng)的分類越多, 索引數(shù)據(jù)越多, 查詢效率越低.
圖7(a)是提供雙向隱私保護(hù)的系統(tǒng)的查詢時(shí)間開銷與查詢次數(shù)的關(guān)系,其平均查詢時(shí)間為0.0084 秒.與圖7(b) 不提供雙向隱私保護(hù)的系統(tǒng)的查詢時(shí)間大約多了0.0074 秒. 因此我們提出的支持雙向隱私保護(hù)的系統(tǒng)查詢是高效的.
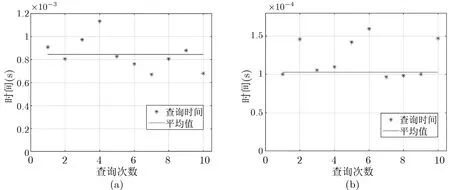
圖7 (a) 支持雙向隱私保護(hù)時(shí)的查詢效率; (b) 不支持雙向隱私保護(hù)時(shí)的查詢效率Figure 7 (a) Query efficiency when two-way privacy protection is supported; (b) Query efficiency when two-way privacy protection is not supported
為了提高實(shí)驗(yàn)的準(zhǔn)確率, 我們以10 次查詢時(shí)間的平均值作為每組查詢花費(fèi)的時(shí)間. 圖8(a) 顯示屬性個(gè)數(shù)與查詢時(shí)間的關(guān)系, 實(shí)驗(yàn)結(jié)果顯示, 在屬性分類值個(gè)數(shù)相同的情況下, 屬性個(gè)數(shù)越多, 查詢時(shí)間越長(zhǎng),查詢效率越低; 屬性個(gè)數(shù)越少, 查詢時(shí)間越少, 查詢效率越高. 圖8(b) 顯示屬性分類值個(gè)數(shù)與查詢時(shí)間的關(guān)系, 在屬性個(gè)數(shù)相同的情況下, 屬性分類值個(gè)數(shù)越多, 查詢時(shí)間越長(zhǎng), 查詢效率越低; 屬性分類值個(gè)數(shù)越少, 查詢時(shí)間越少, 查詢效率越高.
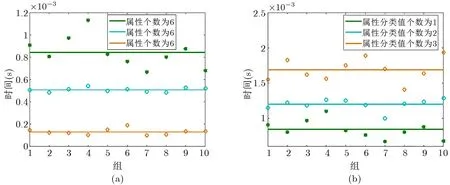
圖8 (a) 屬性個(gè)數(shù)與查詢時(shí)間的關(guān)系; (b) 屬性分類值個(gè)數(shù)與查詢時(shí)間的關(guān)系Figure 8 (a) Number of attributes versus query time; (b) Number of attribute classification values versus query time
(3) 算法復(fù)雜度
假設(shè)數(shù)據(jù)集有k 個(gè)屬性, 每個(gè)屬性的分類個(gè)數(shù)為ai(1 ≤i ≤k), 那么在建立索引之后服務(wù)器擁有的數(shù)據(jù)集規(guī)模為a1×a2×···×ak.
本文使用的雙向隱私保護(hù)協(xié)議是一個(gè)兩輪協(xié)議, 客戶端發(fā)送1 個(gè)消息, 通信復(fù)雜度為O(1). 服務(wù)器發(fā)送 a1×a2×···×ak+ 2 個(gè)消息, 通信復(fù)雜度為 O(a1×a2×···×ak), 因此總的通信復(fù)雜度為O(a1×a2×···×ak).
在進(jìn)行數(shù)據(jù)查詢時(shí), 客戶端執(zhí)行2 次模冪運(yùn)算, 服務(wù)器執(zhí)行a1×a2×···×ak+2 次模冪運(yùn)算, 因此總共執(zhí)行a1×a2×···×ak+4 次模冪運(yùn)算. 通常認(rèn)為服務(wù)器提供強(qiáng)大的計(jì)算能力, 因此系統(tǒng)重點(diǎn)關(guān)注客戶端的計(jì)算開銷.
6 結(jié)論與下一步工作
本文最早提出結(jié)合決策樹與OT 技術(shù)實(shí)現(xiàn)醫(yī)療輔助診斷系統(tǒng)中的雙向隱私保護(hù), 為了將OT 協(xié)議算法用于執(zhí)行了隱私保護(hù)的決策樹算法, 我們提出一種決策樹索引協(xié)議, 可以高效地將決策樹信息數(shù)字化,從而便于利用OT 協(xié)議保護(hù)客戶端的隱私, 同時(shí)也可以保證客戶端只能獲得查詢的相關(guān)信息, 而不能獲得其它額外信息, 從而保護(hù)服務(wù)器的隱私. 實(shí)驗(yàn)結(jié)果表明提出的方法不僅具有較高的查詢效率, 同時(shí)還具有較高的查詢準(zhǔn)確率. 下一步考慮如何在確保系統(tǒng)安全和效率的前提下降低系統(tǒng)的復(fù)雜性.
