少數民族大學生學業成績影響因素分析
2021-03-18 06:53:32
科學與信息化 2021年7期
北京第二外國語學院網絡與信息中心 北京 100024
引言
隨著我國教育、教學水平的不斷提高與高等教育的不斷擴大化,越來越多的少數民族學生赴內地高校求學深造,少數民族大學生已成為我國高校大學生群體中的重要組成部分和社會高等專業人才的重要力量。但少數民族地區所具有的文化多元、人才缺乏、發展滯后的地域特征,使少數民族大學生普遍呈現出漢語、英語水平不高、基礎知識儲備不足、學習動機相對不強等特征[1]。如何采集各類相關數據對少數民族大學生與全體本科生的各項相關數據進行描述性對比分析,還原少數民族大學生的學業真實情況[2],找出學業成績的影響因素,以便根據其特點因材施教,助力提高少數民族學生的學業成績是目前高校面臨的重要課題。
1 研究對象及方法
研究以北京某高校2013-2019級7個年級共962位少數民族學生為研究對象。參考國內大部分高校通用的GPA(績點成績)計算方法,以GPA作為衡量學生學業成績的標準,從學校各業務系統的數據中抽取出與研究主題相關的數據,進行描述性對比分析,而后利用挖掘算法,建立各特征因素對少數民族學生學業成績的影響模型。根據學生的績點成績對學生進行學業成績名次排序,名次在前20%及以內的學生學業成績設為A,名次在20%~40%的學生學業成績設為B,以此類推,名次在后20%的學生學業成績為E,通過驗證少數民族學生學業成績預測模型準確率及精度驗證影響因素選擇的合理性。
2 數據獲取及描述性統計分析
2.1 數據獲取
研究從相關系統中提取到學生相關信息包括:籍貫、性別等人口統計信息;年級、院系、專業等學籍信息;校園消費、上網時長、外借圖書館冊數等校園行為信息,將所獲取的這些信息特征作為影響少數民族學生學業成績的潛在因素。
2.2 描述性統計對比分析
(1)GPA統計分析
研究分別對少數民族學生和全體本科本的績點成績進行了統計,數據顯示:2013-2019級少數民族學生的GPA均值為2.81,全體本科生的GPA均值為3.13,少數民族學生的GPA均值較全體本科生偏低10.22%。
(2)數值型特征統計分析
少數民族學生和全體本科本的數值型特征描述性分析如表1所示,包含上網時常、借書數量、消費天數、入館天數、日均消費等行為特征的分布情況。
由上述對比可知,少數民族學生在上網時長、年借書冊數、年消費次數、自習次數的均值都低于全體本科生,日均消費數則高于全體本科生。
3 建立影響因素模型
3.1 數據拆分
對962條數據采用隨機抽樣的方法抽取80%的樣本數據共769條數據作為訓練數據集,用來訓練建立模型,余下的20%樣本數據共193條數據則作為測試數據集,測評數據集用于在模型建立后檢測模型的性能。
3.2 篩選影響因素
研究選取隨機森林算法構建少數民族學生學業成績影響因素模型,為使構建的模型易于理解,需要從全部特征中選取相關性強的特征因素構建最優影響因素子集[3]。選用最優特征子集的方法可以縮短模型的訓練時間,增加模型的通用性,降低過擬合的風險。研究采用了正向選擇法進行最優特征集選擇:從空特征集開始,向特征集合中加入一個該集合不包含的特征,然后對新的集合進行評估,找出評估結果最佳的特征變量加入當前集合;不斷重復,直到加入任何新的特征變量都不能提高評估結果為止。通過實驗得到當隨機森林分類模型包含年消費天數、性別、年借書數量、年自習天數、日均消費、籍貫、年上網時常、所在專業8個特征時模型擬合程度是最佳的。
3.3 模型性能評估
在構建好隨機森林的分類模型后,以測試集中的193條記錄對模型的分類性能進行評估測試。模型驗證結果的混淆矩陣見表2。
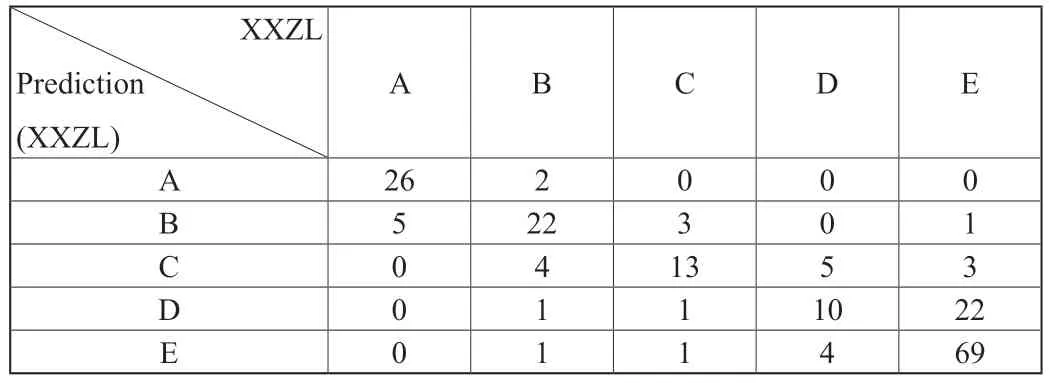
表2 模型混淆矩陣
混淆矩陣一個n行n列矩陣,其中n為分類數。在該矩陣中,正類(positive)為1,負類(negative)為0。混淆矩陣主對角線上的值為TP(True Positive)即正類且預測為正類的樣本個數;每列除主對角線元素以外的其他位置元素值為FP(False Positive)即正類且預測為負類的樣本個數。此外還可通過計算得到模型的TN(True Negative)負類且預測為負類的樣本個數和FN(False Negative)即正類且預測為負類的樣本個數。分類模型的準確率及精度的計算公式可表示為:Precision。通過對表2的計算可得到,隨機森林模型的驗證預測準確率達到72.54%,預測精度達到70.92%,證明了特征變量選擇是合適的。
4 影響因素分析
(1)總的來看,相對于漢族學生,少數民族學生的學業成績整體呈落后狀態。
(2)學生管理部門應重視少數民族學生的年在校天數較漢族學生偏少的現狀,對于少數民族學生的考勤情況應給予更多關注。
(3)性別差異導致少數民族學生的學業成績出現分化現象,應采取相應措施來改善此種局面。
(4)學校相關部門應著力改善少數民族學生的學習環境,盡可能地為少數民族學生營造良好的學習氛圍,引導和鼓勵少數民族學生增加閱讀量和其他自主學習機會。
(5)與傳統觀念不同的是,上網時間的增加不僅不會影響少數民族學生的學業成績反而會起到促進作用,應當引導學生正確使用網絡資源。
(6)外部因素對少數民族學生學業成績的影響遠小于內部因素的影響[5],而且學生在校行為比其他因素對學業成績的影響力更大。
5 結束語
(1)本文考慮少數民族學生的學業成績的影響因素時,未將學生的歷史成績作為影響因素指標。在實際應用中,若加入該因素,重新生成模型,模型準確度和精度可能會有提升。
(2)由于數據統計時對數據時間區間的設定為2013年1月至2019年12月,以2019級少數民族學生數據為測試集,并以對2019-2020學年第一學期的期未績點成績對預測結果進行驗證。模型的預測準確性明顯降低,僅為44%左右,造成這種結果的原因可能包含:
1)新生校園行為數據的數據量較小。
2)新生入學后對大學生活有適應期,其行為數據尚未穩定。
3)以大一第一學期的期末成績代表學生的學業成績有其片面性,但可以發現模型不太適用于新生學習情況預測。
(3)以少數民族學生為樣本的學習質量分析有其局限性,未來可從其他角度對學生進行分類,進行學生學業成績的預測和監控。
研究從促進少數民族學生管理工作開展、提高學生管理工作效率、促進少數民族大學生學業成績提高的角度出發,以少數民族大學生這一特殊的大學生群體為對象開展的學業成績影響因素分析研究,力求突破以往單一的分析視角,利用客觀數據對影響少數民族學生學業成績的因素展開全面、科學的分析。以經過預處理的少數民族本科生在校期間的相關數據為樣本進行模型訓練,建立少數民族學生學業成績和影響因素之間的映射關系,并以對隨機森林算法構建模型的分類預測率驗證影響因素選擇合理性。
但本研究也存在一些不足之處,對于影響因素對于少數民族學生學業成績是如何產生影響的還有待進一步研究。
猜你喜歡
中老年保健(2022年5期)2022-08-24 02:36:04
中學生數理化·八年級物理人教版(2022年3期)2022-03-16 05:55:08
當代陜西(2021年12期)2021-08-05 07:45:46
當代陜西(2021年2期)2021-03-29 07:41:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國塑料(2016年3期)2016-06-15 20:30:00
冰雪運動(2016年4期)2016-04-16 05:54:56
劍南文學(2015年1期)2015-02-28 01:15:15
