基于面部特征圖對(duì)稱的人臉正面化生成對(duì)抗網(wǎng)絡(luò)算法
2021-03-18 13:45:12*
計(jì)算機(jī)應(yīng)用 2021年3期
*
(1.中北大學(xué)大數(shù)據(jù)學(xué)院,太原 030051;2.山西省醫(yī)學(xué)影像與數(shù)據(jù)分析工程研究中心(中北大學(xué)),太原 030051;3.山西警察學(xué)院刑事科學(xué)技術(shù)系,太原 030401)
0 引言
隨著深度學(xué)習(xí)的發(fā)展,人臉正面識(shí)別的性能有了很大提升,而監(jiān)控視頻中獲得的人臉圖像往往同時(shí)受到偏轉(zhuǎn)角和俯仰角的影響,對(duì)于這種包含多角度變化的側(cè)臉圖像,現(xiàn)有人臉識(shí)別系統(tǒng)的識(shí)別準(zhǔn)確率較低。目前針對(duì)多角度側(cè)臉識(shí)別主要有兩種方法:一種是學(xué)習(xí)不受姿態(tài)影響的人臉身份特征[1-2];另一種是利用單一側(cè)臉圖像恢復(fù)出保留身份的逼真正臉圖像,也稱為人臉正面化[3-8]。就第一種方法而言,由于現(xiàn)有人臉數(shù)據(jù)集呈現(xiàn)長(zhǎng)尾分布,在姿態(tài)變化上分布不均勻,因此很難學(xué)習(xí)到較為魯棒的姿態(tài)不變性人臉特征[3]。第二種方法人臉正面化可以作為一種預(yù)處理操作部署在人臉識(shí)別系統(tǒng)中,使得現(xiàn)有性能強(qiáng)的識(shí)別系統(tǒng)不需要重新訓(xùn)練也可以在一定程度上提升識(shí)別準(zhǔn)確率,同時(shí)在某些場(chǎng)景中,正面化的結(jié)果可以作為關(guān)鍵的參考材料,例如在刑偵領(lǐng)域,可以為辦案人員提供參考。此外,人臉正面化在其他領(lǐng)域也具有重要的實(shí)用意義。
目前針對(duì)監(jiān)控?cái)z像頭得到的側(cè)臉進(jìn)行正面化主要有兩方面的困難:被遮擋信息的補(bǔ)全和保留身份問(wèn)題。
對(duì)于解決多角度側(cè)臉被遮擋信息補(bǔ)全的問(wèn)題,現(xiàn)有方法可以分為兩種:基于二維方法[4-8]和基于三維方法[9-11]。
基于三維的方法需要二維圖像到三維模型的映射,這一過(guò)程會(huì)引入較大誤差,且三維方法得到的正面化圖像通常不夠真實(shí),會(huì)出現(xiàn)人工偽影和嚴(yán)重的面部紋理信息丟失情況,并且在大角度姿態(tài)下,三維方法的性能會(huì)嚴(yán)重下降[4]。
基于二維的方法在大角度姿態(tài)下相比三維方法性能較好,是目前人臉正面化算法中使用最多的。Kan等[5]利用自編碼器提出堆疊漸進(jìn)式自編碼器(Stacked Progressive Auto-Encoder,SPAE),以漸進(jìn)方式把大角度側(cè)臉逐漸轉(zhuǎn)換為小角度最終實(shí)現(xiàn)正面化。Yim等[6]提出包括主深度神經(jīng)網(wǎng)絡(luò)(Main Deep Neural Network,Main DNN)和輔深度神經(jīng)網(wǎng)絡(luò)(Auxiliary Deep Neural Network,Auxiliary DNN)的多任務(wù)學(xué)習(xí)模型,Main DNN負(fù)責(zé)生成目標(biāo)姿態(tài)下的人臉圖像,Auxiliary DNN 利用生成圖作為輸入來(lái)重建原始輸入圖像,以這種多任務(wù)方式保留更多的身份信息。但這些方法在訓(xùn)練時(shí)由于引入的約束較少,得到的生成圖像較為模糊。近幾年,生成對(duì)抗網(wǎng)絡(luò)(Generative Adversarial Network,GAN)[12]提升了二維圖像生成任務(wù)的視覺(jué)效果,很多基于GAN 的人臉正面化方法被提出。兩路生成對(duì)抗網(wǎng)絡(luò)(Two-Pathway Generative Adversarial Network,TP-GAN)[7]提出了雙支路生成對(duì)抗網(wǎng)絡(luò),通過(guò)全局和局部?jī)蓷l路徑分別處理側(cè)臉圖像,再將兩部分結(jié)果進(jìn)行融合得到最終的正面人臉,同時(shí)根據(jù)人臉對(duì)稱性先驗(yàn)提出對(duì)稱損失來(lái)補(bǔ)全被遮擋部分,但這是從圖像層面上補(bǔ)全信息。人臉正面化模型(Face Normalization Model,F(xiàn)NM)[4]提出了一系列人臉注意力機(jī)制判別器來(lái)判別生成圖的真實(shí)性,從而增加對(duì)生成器的懲罰,得到逼真的正面人臉圖像。用于面部姿態(tài)分析的多偏轉(zhuǎn)多俯仰高質(zhì)量數(shù)據(jù)庫(kù)(Multi-yaw Multi-pitch high-quality database for Facial Pose Analysis,M2FPA)[8]采用軟注意力的方式利用人臉解析網(wǎng)絡(luò)分割出頭發(fā)、五官和皮膚,分別給每一部分增加判別器判別其真假,以補(bǔ)全丟失的面部信息從而實(shí)現(xiàn)正面化。上述這些基于GAN 的方法大多通過(guò)改進(jìn)判別器結(jié)構(gòu),從而增大對(duì)生成器的懲罰,促使生成器生成被遮擋部分,但即使判別器能力強(qiáng),多角度姿態(tài)的自遮擋問(wèn)題使得輸入圖像本身有效的面部特征較少,造成生成器可利用的信息較少,使得生成過(guò)程困難。因此,為了增加可利用信息,緩解自遮擋問(wèn)題,本文根據(jù)人臉對(duì)稱性這一先驗(yàn)知識(shí),設(shè)計(jì)了特征圖對(duì)稱模塊,即根據(jù)鼻尖位置判斷輸入側(cè)臉的朝向,然后將編碼器卷積層提取的特征圖依據(jù)人臉朝向進(jìn)行鏡像對(duì)稱,從特征層面上補(bǔ)全被遮擋的關(guān)鍵人臉信息,幫助生成器生成缺失的面部信息。
對(duì)于保留身份問(wèn)題,現(xiàn)有正面化方法[3-4,7-8]利用性能強(qiáng)的人臉識(shí)別網(wǎng)絡(luò)提取生成圖和真實(shí)圖的深層身份特征,通過(guò)降低特征之間的感知距離使得生成圖的身份信息保留,這種方法通過(guò)全局方式保留生成圖的面部整體特征,但在局部特征保留上關(guān)注較少,文獻(xiàn)[13-14]指出眼周區(qū)域即包含眼睛和眉毛的矩形區(qū)域是面部中具有高判別性的區(qū)域,因此本文在文獻(xiàn)[3-4,7-8]提出的身份保留損失基礎(chǔ)上,加入了眼周特征保留損失,分別從全局和局部的角度來(lái)提高生成圖像的身份信息保留。
本文的主要工作如下:
1)本文提出了一個(gè)端到端的特征圖對(duì)稱人臉正面化生成對(duì)抗網(wǎng)絡(luò)(Symmetric Generative Adversarial Network,Sym-GAN),可以根據(jù)單張大角度下的側(cè)臉圖像生成保留其身份的正面化圖像。生成器中加入了特征圖對(duì)稱模塊,可以對(duì)多角度變化的側(cè)臉圖像進(jìn)行一定程度的信息補(bǔ)全。
2)為了使得生成圖保留更多關(guān)鍵的身份信息,同時(shí)利用人臉全局特征和眼周局部特征,通過(guò)縮小生成圖像和真實(shí)圖像對(duì)在面部區(qū)域和眼周區(qū)域的特征向量距離,使得生成正臉圖保留更多的身份信息。
3)即使Sym-GAN 未包含任何人臉識(shí)別網(wǎng)絡(luò),但它可以輕松地部署在人臉識(shí)別系統(tǒng)中,作為一種預(yù)處理操作來(lái)專門處理多角度變化的側(cè)臉圖像,以提高現(xiàn)有人臉識(shí)別系統(tǒng)的性能。
在公開數(shù)據(jù)集CAS-PEAL-R1[15]上進(jìn)行了定性和定量實(shí)驗(yàn),實(shí)驗(yàn)結(jié)果證明本文提出的Sym-GAN 可以有效提高人臉識(shí)別模型在多角度側(cè)臉下的識(shí)別性能。
1 人臉正面化
目前基于生成對(duì)抗網(wǎng)絡(luò)的人臉正面化方法主要包括TPGAN[7]、M2FPA[8]、雙注意力生成對(duì)抗網(wǎng)絡(luò)(Dual-Attention Generative Adversarial Network,DA-GAN)[16]。如圖1 所示,TP-GAN提出包括全局和局部路徑的雙支路生成器,全局路徑處理側(cè)臉圖像得到正面臉型輪廓,局部路徑處理各五官圖像塊輸出對(duì)應(yīng)正面圖像,最后將全局和局部路徑的結(jié)果進(jìn)行融合得到正面圖像。TP-GAN 的生成器采用編-解碼結(jié)構(gòu),同時(shí)加入跳層拼接利用編碼器提取的側(cè)臉特征進(jìn)行特征融合,但側(cè)臉特征包含的信息較少,使得解碼器上采樣過(guò)程中可用的有效特征較少。對(duì)于TP-GAN 的雙路徑生成器,網(wǎng)絡(luò)結(jié)構(gòu)龐大,生成圖像受最慢路徑影響,在訓(xùn)練和預(yù)測(cè)時(shí)效率低,針對(duì)這一問(wèn)題,M2FPA 和DA-GAN 只采用全局路徑的單支路網(wǎng)絡(luò)也可以達(dá)到相同效果。對(duì)于生成圖身份信息保留,TP-GAN、M2FPA 和DA-GAN 使用的身份保留損失是以面部全局角度提高生成圖身份信息保留,對(duì)局部具有高辨別能力的五官信息關(guān)注較少。
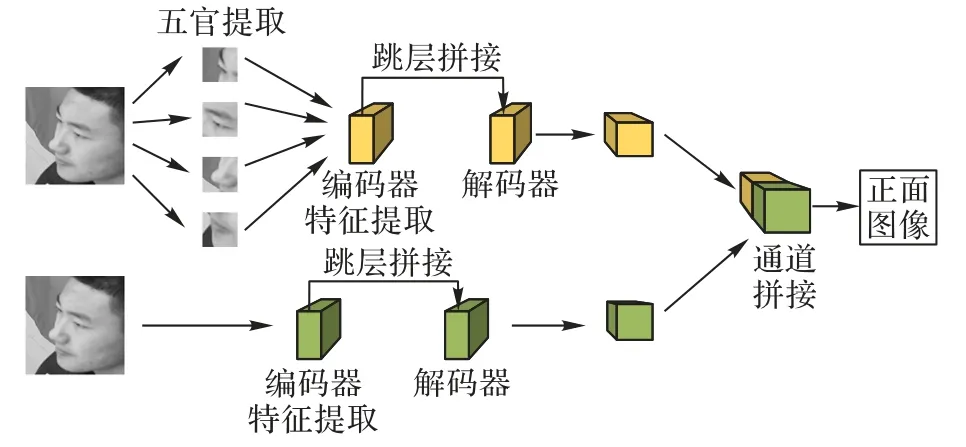
圖1 TP-GAN網(wǎng)絡(luò)框架Fig.1 Network framework of TP-GAN
2 Sym-GAN
本文提出的Sym-GAN 用于對(duì)受多角度變化的側(cè)臉實(shí)現(xiàn)正面化生成,網(wǎng)絡(luò)框架如圖2所示。Sym-GAN 由生成器-判別器組成。生成器和TP-GAN 全局路徑生成器一樣采用編解碼結(jié)構(gòu)。編碼器對(duì)輸入側(cè)臉圖像提取特征,同時(shí)借助特征圖對(duì)稱模塊,將側(cè)臉特征依據(jù)鼻尖位置鏡像對(duì)稱;解碼器將編碼器提取的深層特征進(jìn)行多次反卷積,在上采樣過(guò)程中加入跳層拼接,將原始側(cè)臉特征圖、對(duì)稱特征圖、輸入圖像在通道維度上進(jìn)行拼接,最終輸出生成正臉圖像。判別器采用深層卷積網(wǎng)絡(luò)判定生成圖和基準(zhǔn)圖的真實(shí)性,促使生成器生成逼真的正面圖像。Sym-GAN 主要包含兩個(gè)模塊:特征圖對(duì)稱模塊和改進(jìn)的解碼器跳層拼接模塊。根據(jù)人臉對(duì)稱性這一先驗(yàn)提出了特征圖對(duì)稱模塊,應(yīng)用于解碼器跳層拼接,以補(bǔ)全丟失的人臉關(guān)鍵信息,從而緩解自遮擋造成的生成器對(duì)丟失部分生成困難的問(wèn)題。改進(jìn)的解碼器跳層拼接是指對(duì)TP-GAN 解碼器跳層拼接進(jìn)行改進(jìn),在反卷積過(guò)程中拼接了編碼器提取的側(cè)臉特征圖、對(duì)稱特征圖以及輸入圖,可以起到補(bǔ)全信息和增強(qiáng)面部細(xì)節(jié)學(xué)習(xí)的作用。此外,本文在身份特征保留損失的基礎(chǔ)上,加入了眼周特征保留損失來(lái)訓(xùn)練生成器。身份特征從全局角度表征一些面部紋理特征和五官間的拓?fù)浣Y(jié)構(gòu),眼周特征從局部角度表征眉毛、眼型和眼間距等局部身份信息,從而提高生成圖全局和局部區(qū)域身份信息保留能力。下面將詳細(xì)介紹特征對(duì)稱模塊和改進(jìn)的解碼器跳層拼接模塊,眼周特征保留損失在3.2節(jié)眼周特征保留損失介紹。
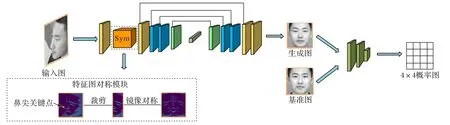
圖2 Sym-GAN網(wǎng)絡(luò)框架Fig.2 Network framework of Sym-GAN
2.1 特征圖對(duì)稱編碼器
編碼器的作用是將輸入圖像通過(guò)多層卷積提取特征,得到高維人臉特征表達(dá)向量,解碼器對(duì)特征向量進(jìn)行上采樣恢復(fù)出正面圖。對(duì)于多角度變化下的側(cè)臉正面化任務(wù),為了保證生成正面人臉逼真且保留足夠多的身份信息,編碼器一方面需要對(duì)輸入圖像進(jìn)行信息過(guò)濾,濾去背景噪聲和與人臉身份無(wú)關(guān)的角度信息,為解碼器提供更為緊湊的面部特征向量;另一方面需要提供給解碼器較為豐富有效的面部信息,以緩解自遮擋導(dǎo)致的人臉信息丟失問(wèn)題。為了實(shí)現(xiàn)這一目的,本文在編碼器對(duì)側(cè)臉圖像進(jìn)行下采樣過(guò)程中加入了特征圖對(duì)稱模塊,首先使用預(yù)訓(xùn)練的人臉特征點(diǎn)檢測(cè)器視網(wǎng)膜人臉(Retinaface)[17]對(duì)輸入側(cè)臉圖像進(jìn)行特征點(diǎn)檢測(cè),通過(guò)鼻尖點(diǎn)位置坐標(biāo)來(lái)判斷當(dāng)前輸入側(cè)臉的朝向,將側(cè)臉圖像中信息包含較多的一側(cè)以鼻尖橫坐標(biāo)為中心做鏡像對(duì)稱,編碼器提取的特征圖和對(duì)稱后的特征圖可視化效果如圖3 所示,對(duì)稱特征圖應(yīng)用于解碼器跳層拼接,以補(bǔ)全丟失的人臉信息。編碼器繼續(xù)對(duì)側(cè)臉特征圖進(jìn)行下采樣得到256 維的深層人臉特征表達(dá)向量。

圖3 特征圖對(duì)稱模塊Fig.3 Feature map symmetry module
2.2 改進(jìn)的解碼器跳層拼接
解碼器作用是將編碼器得到的高層特征依次經(jīng)過(guò)多個(gè)反卷積層進(jìn)行上采樣,直到生成圖的分辨率和輸入圖一致。本文對(duì)TP-GAN 解碼器跳層拼接做出改進(jìn),TP-GAN 在跳層拼接時(shí)只將側(cè)臉特征圖、輸入原圖和反卷積特征圖進(jìn)行拼接,如圖4 所示。本文的改進(jìn)方法為:在解碼過(guò)程中,每層反卷積輸入的特征圖由編碼器中對(duì)應(yīng)尺度側(cè)臉特征圖、特征圖對(duì)稱模塊得到的對(duì)稱特征圖、同一尺寸的輸入側(cè)臉圖以及前一層反卷積的輸出特征圖拼接得到。相較于TP-GAN 的拼接方式,本文得到的對(duì)稱特征圖也參與了拼接,這種拼接方式不僅可以實(shí)現(xiàn)特征融合,也可以在特征層面上對(duì)丟失側(cè)臉特征進(jìn)行模擬和補(bǔ)全,以緩解生成器生成過(guò)程中能利用的有效面部信息較少的困難,從而生成出具有高細(xì)節(jié)保真的正面圖像。
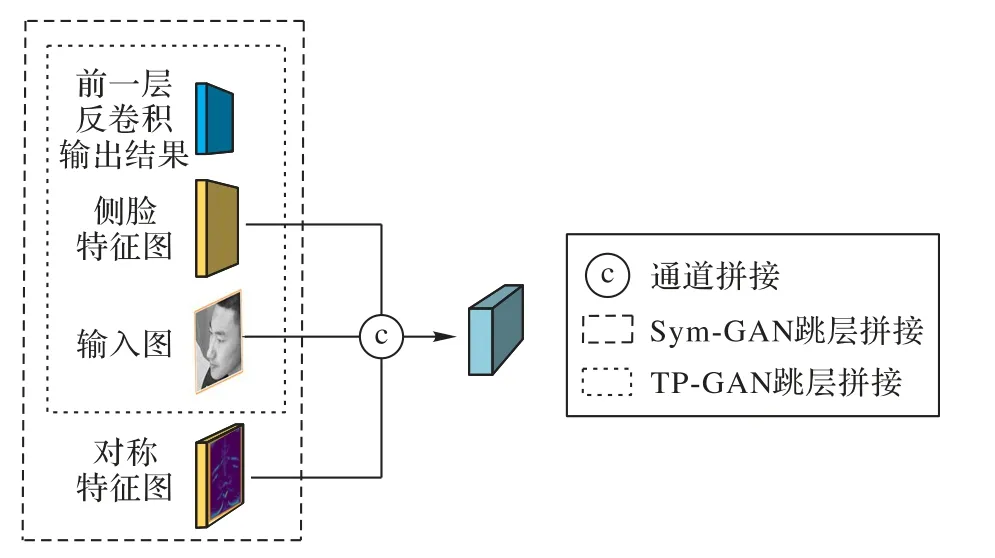
圖4 改進(jìn)的解碼器跳層拼接Fig.4 Skip layer splicing of improved decoder
2.3 判別器結(jié)構(gòu)
判別器的作用是判別生成圖和真實(shí)圖的真假性,從而對(duì)生成器造成一定的懲罰,使得生成器生成的結(jié)果更接近真實(shí)圖像。本文采用的判別器結(jié)構(gòu)如圖5所示,由6層卷積層組成,其中在第4層和第5層卷積層之后加入殘差塊,使得網(wǎng)絡(luò)層數(shù)加深,從而提取到更為抽象的面部細(xì)節(jié)特征,提高判別器的判別能力。從第5層到第6層采用1×1卷積核用于降低特征通道,最后輸出4×4概率圖。本文采用1×1卷積核代替全連接層,是因?yàn)槿B接層會(huì)破壞圖像的空間結(jié)構(gòu),而1×1卷積核可以保證在降低特征圖維度的同時(shí)不改變圖像的空間結(jié)構(gòu),即不破壞面部拓?fù)浣Y(jié)構(gòu)。此外,相較于傳統(tǒng)生成對(duì)抗網(wǎng)絡(luò)中判別器只輸出一個(gè)標(biāo)量值來(lái)表示生成圖或真實(shí)圖整幅圖像的真實(shí)性,本文的判別器輸出4×4概率圖,其中每一個(gè)概率值對(duì)應(yīng)圖像中一個(gè)局部感受野,可以恰好將人臉五官位置進(jìn)行分離判別,采用這種方法可以提高判別器對(duì)局部細(xì)節(jié)的判別能力,從而促使生成器生成高細(xì)節(jié)保留、高分辨率的正面人臉圖像。
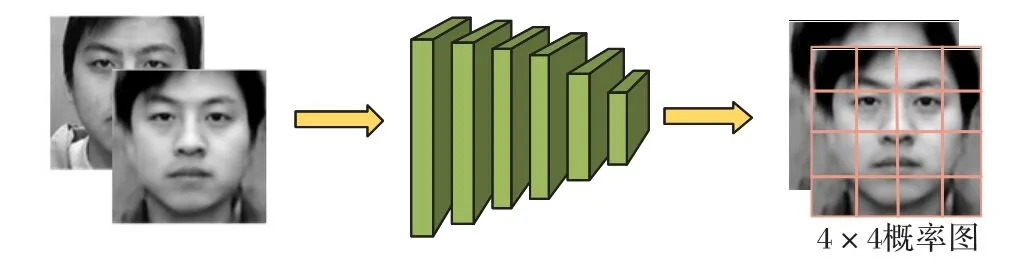
圖5 判別器網(wǎng)絡(luò)結(jié)構(gòu)Fig.5 Network structure of discriminator
3 損失函數(shù)設(shè)計(jì)
3.1 整體目標(biāo)函數(shù)
用于訓(xùn)練Sym-GAN 的目標(biāo)函數(shù)Lsyn由一系列損失函數(shù)加權(quán)和組成,公式如下所示:
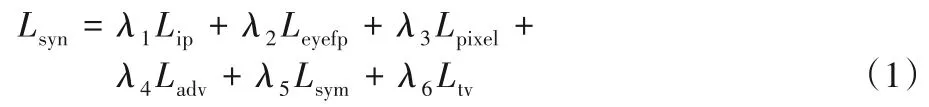
其中:Lip表示身份保留損失,以全局角度保留生成圖身份信息;在Lip的基礎(chǔ)上,為了增加對(duì)生成圖局部身份信息的關(guān)注,本文提出眼周特征保留損失Leyefp;Lpixel表示多尺度像素級(jí)損失,確保生成圖和真實(shí)圖的內(nèi)容一致性;Ladv表示對(duì)抗損失,使生成圖在視覺(jué)效果上較好;Lsym表示對(duì)稱損失,用于緩解自遮擋問(wèn)題;Ltv表示總差分正則化,降低生成圖的人工偽影,提高視覺(jué)效果;λ1、λ2、λ3、λ4、λ5、λ6為對(duì)應(yīng)的權(quán)重參數(shù)。下面將詳細(xì)介紹每一個(gè)損失函數(shù)。
3.2 眼周特征保留損失
為了保留生成圖身份信息,文獻(xiàn)[7-8]利用輕卷積神經(jīng)網(wǎng)絡(luò)(Light Convolutional Neural Network,Light CNN)[18]提取生成圖和真實(shí)圖的高維特征向量構(gòu)成感知損失來(lái)確保生成圖身份信息保留,這種方式是以全局角度關(guān)注生成圖的身份特征,而對(duì)面部局部區(qū)域的身份信息關(guān)注較少;文獻(xiàn)[13-14]指出眼周區(qū)域(即包含眉毛和眼睛的矩形區(qū)域)是面部最具有判別能力的區(qū)域之一,表明眼周區(qū)域相較面部其他五官,可以表征出更加獨(dú)特的人臉身份特征。因此,為了提高生成圖全局和局部區(qū)域的身份特征保留,在文獻(xiàn)[7-8]身份保留損失的基礎(chǔ)上,提出眼周特征保留損失,文獻(xiàn)[19]分析了傳統(tǒng)特征提取方法,如局部二值模式(Local Binary Pattern,LBP)[20]、方向梯度直方圖(Histogram of Oriented Gradient,HOG)[21]、尺度不變特征變換(Scale-Invariant Feature Transform,SIFT)[22]和現(xiàn)有卷積特征在眼周圖像識(shí)別效果,提出了現(xiàn)有的卷積特征在眼周圖像上也有較好的識(shí)別性能,且實(shí)驗(yàn)表明使用殘差網(wǎng)絡(luò)(Residual Network,ResNet)[23]ResNet50 在眼周圖像上的第73 層特征識(shí)別效果相對(duì)較好。因此,本文按照如圖6所示設(shè)計(jì)了眼周特征保留損失,利用ResNet50 分別提取生成圖和真實(shí)圖的左右眼區(qū)域的第73層特征,然后分別計(jì)算對(duì)應(yīng)特征之間的余弦距離,將兩部分距離相加得到眼周特征保留損失,作為訓(xùn)練生成器損失函數(shù)的一部分,約束局部區(qū)域身份保留。
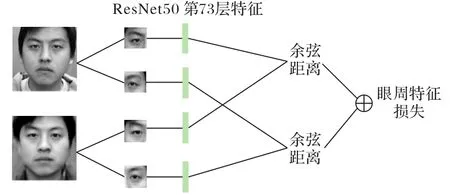
圖6 眼周特征保留損失計(jì)算Fig.6 Calculation of preserving loss of periocular feature
眼周特征保留損失函數(shù)公式如下所示:
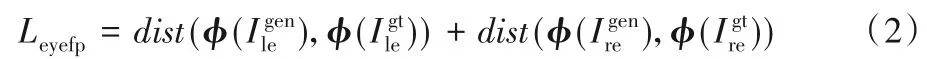
其中:φ(·)定義為ResNet50提取的第73層網(wǎng)絡(luò)的特征和分別表示生成圖像和基準(zhǔn)圖像分別表示I*的左右眼區(qū)域圖像;dist表示余弦距離。
3.3 身份保留損失
為了保留生成圖像全局身份信息,按照文獻(xiàn)[7-8],使用預(yù)訓(xùn)練人臉識(shí)別網(wǎng)絡(luò)提取的高維特征向量構(gòu)成感知損失來(lái)保留生成圖的身份信息。

其中:φ(·)定義為預(yù)訓(xùn)練的人臉識(shí)別網(wǎng)絡(luò)Light CNN 提取的最后一層全連接層的特征,由于Light CNN 是在大規(guī)模人臉數(shù)據(jù)集上進(jìn)行訓(xùn)練,它可以提取到更為普遍、更為顯著的人臉特征表示向量2范數(shù)。
3.4 多尺度像素級(jí)損失
按照文獻(xiàn)[7],加入多尺度像素級(jí)損失來(lái)確保生成圖像Igen和基準(zhǔn)圖像Igt在內(nèi)容上的一致性,此外也可提高生成圖像Igen的逼真程度。
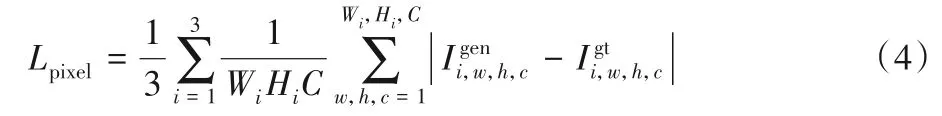
其中:i表示第i個(gè)圖像尺寸,分別在圖像尺寸為128×128、64×64、32×32大小的生成圖Igen和真實(shí)圖Igt之間計(jì)算像素值的L1距離;C表示圖像的通道數(shù),Wi和Hi分別表示對(duì)應(yīng)分辨率圖像的寬和高。
3.5 對(duì)抗損失
Sym-GAN 由兩部分組成:生成器G 和判別器D。判別器D 的目的是從真實(shí)圖和生成圖中區(qū)分出真實(shí)圖。生成器G 的目的是生成接近真實(shí)的圖像以欺騙判別器。生成器和判別器之間的訓(xùn)練[12]可表示為:
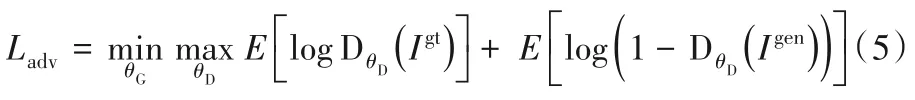
對(duì)抗損失Ladv可以幫助生成圖在視覺(jué)感官上產(chǎn)生較好的效果。
3.6 對(duì)稱損失
文獻(xiàn)[7]提出的對(duì)稱損失,可以有效地緩解自遮擋問(wèn)題以提高模型在大角度姿態(tài)下的正面化生成性能。
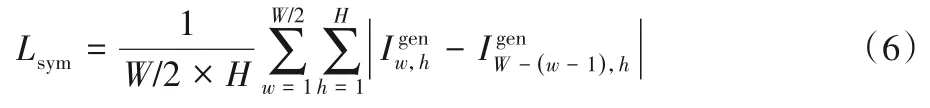
其中:W-(w-1)表示生成圖Igen中w位置的對(duì)稱橫坐標(biāo)。
3.7 總變分正則化
通常,GAN 模型生成的圖像會(huì)產(chǎn)生許多的人工偽影,干擾視覺(jué)質(zhì)量和識(shí)別性能,按照文獻(xiàn)[3],在生成圖像中加入了總變分正則化項(xiàng)以緩解這一問(wèn)題。
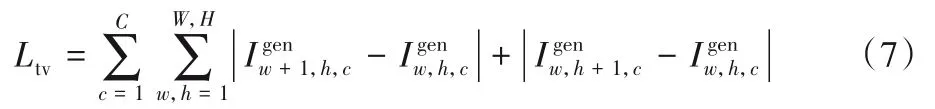
其中:W和H表示最終生成圖像的寬和高。
4 實(shí)驗(yàn)與結(jié)果分析
Sym-GAN 的核心目標(biāo)是根據(jù)包含多角度變化的側(cè)臉合成其逼真的正面人臉,同時(shí)能夠保留足夠的身份信息。在4.2節(jié)中展示了提出的Sym-GAN 在公開數(shù)據(jù)集上的定性正面化合成效果,在4.3 節(jié)中定量評(píng)估了Sym-GAN 對(duì)人臉識(shí)別網(wǎng)絡(luò)的增強(qiáng)效果。在4.4 節(jié)中,針對(duì)Sym-GAN 不同結(jié)構(gòu)變體和損失函數(shù)變體進(jìn)行了消融實(shí)驗(yàn),以分析其各自的作用。
4.1 實(shí)驗(yàn)設(shè)置
CAS-PEAL-R1 數(shù)據(jù)集是一個(gè)公開的大規(guī)模中國(guó)人臉數(shù)據(jù)集,它涵蓋了姿態(tài)、表情、裝飾物和光照等變化。該數(shù)據(jù)集總共包含1 040 個(gè)人的30 863 張灰度圖像,其中男性有595人、女性有445 人。本文中只使用含有姿態(tài)變化的圖像,包含7 個(gè)偏轉(zhuǎn)角度(0°,± 15°,± 30°,± 45°)和3 個(gè)俯仰角度(0°,± 30°),共21 種角度變化。使用前600 人構(gòu)成訓(xùn)練集,剩下的440人構(gòu)成測(cè)試集。
使用人臉檢測(cè)模型Retinaface 對(duì)圖像進(jìn)行預(yù)處理,將CAS-PEAL-R1 數(shù)據(jù)集中用于實(shí)驗(yàn)評(píng)估的所有圖像裁剪到分辨率為128×128,并且為了保證正面化的效果,對(duì)所有基準(zhǔn)正面圖像進(jìn)行對(duì)齊處理,即保證左右眼特征點(diǎn)處于同一水平線上,且確保兩眼連線的中點(diǎn)落在裁剪后圖像的中點(diǎn)上。用于計(jì)算身份損失的預(yù)訓(xùn)練人臉識(shí)別網(wǎng)絡(luò)Light CNN-29在訓(xùn)練期間參數(shù)固定,眼周區(qū)域大小選取數(shù)據(jù)集眼周矩形框的平均尺寸。本文的模型采用Pytorch 深度學(xué)習(xí)框架實(shí)現(xiàn)。選擇β1為0.9,β2為0.99 的Adam 優(yōu)化器,學(xué)習(xí)率為2-4,圖像分辨率為128×128 時(shí)設(shè)置batch size 為16。在一張NVIDIA Tesla P100 GPU(16 GB)上訓(xùn)練網(wǎng)絡(luò)。在所有實(shí)驗(yàn)中,依據(jù)經(jīng)驗(yàn)分別設(shè)置權(quán)重參數(shù)λ1,λ2,λ3,λ4,λ5,λ6為0.01,0.05,150,0.1,0.01,1。
4.2 人臉正面化效果
本文以側(cè)臉圖像作為輸入圖像,以偏轉(zhuǎn)角和俯仰角都為0°的正面圖像作為基準(zhǔn)圖像訓(xùn)練網(wǎng)絡(luò)。圖7所示為Sym-GAN在各個(gè)俯仰角的生成結(jié)果。可以觀察到,生成圖像和基準(zhǔn)圖像不僅在全局的面部結(jié)構(gòu)上保持一致,同時(shí)在眉毛和眼型等局部細(xì)節(jié)上也與基準(zhǔn)圖像接近,證明了本文提出的眼周特征保留損失對(duì)局部區(qū)域特征保留具有一定的作用。
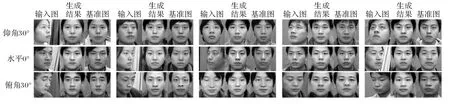
圖7 Sym-GAN在CAS-PEAL-R1數(shù)據(jù)集上不同俯仰角的生成正面人臉圖像Fig.7 Frontal images generated by Sym-GAN on images with different pitch angles in CAS-PEAL-R1 dataset
本文提供了一系列人臉正面化方法的生成結(jié)果與Sym-GAN 進(jìn)行比較,包括TP-GAN[7]、完整表示生成對(duì)抗網(wǎng)絡(luò)(Complete Representations Generative Adversarial Network,CRGAN)[24]、M2FPA[8]、DA-GAN[16],生成效果對(duì)比結(jié)果如圖8 所示。由圖8 可以看出,在眼周部分Sym-GAN 模型的生成效果相較其他方法與基準(zhǔn)圖像更為接近。此外,相較其他方法在判別器加入一些區(qū)域約束,會(huì)造成其他區(qū)域出現(xiàn)模糊的現(xiàn)象,本文方法使用相對(duì)簡(jiǎn)單的判別器結(jié)構(gòu),保證了面部整體細(xì)節(jié)的一致性。
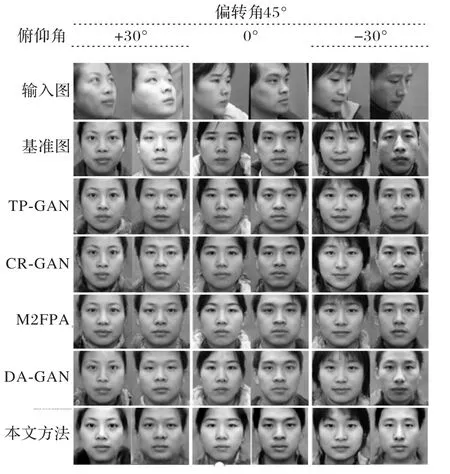
圖8 CAS-PEAL-R1數(shù)據(jù)集上不同方法的比較Fig.8 Comparison of different methods on CAS-PEAL-R1 dataset
4.3 姿態(tài)無(wú)關(guān)的人臉識(shí)別
人臉正面化可以作為人臉識(shí)別模型的一種預(yù)處理操作,所以使用人臉識(shí)別準(zhǔn)確率作為評(píng)價(jià)指標(biāo)來(lái)評(píng)估不同正面化方法的身份保留能力。識(shí)別準(zhǔn)確率越高,人臉合成過(guò)程中保留下的人臉特征越多,正面化合成的效果越好。因此,本文在CAS-PEAL-R1數(shù)據(jù)集上定量驗(yàn)證Sym-GAN 模型“通過(guò)生成再進(jìn)行識(shí)別”的有效性。把Sym-GAN 模型作為預(yù)處理操作,然后使用預(yù)訓(xùn)練人臉識(shí)別模型Light CNN 作為人臉特征提取器,并使用距離度量計(jì)算生成圖像和真實(shí)圖像對(duì)之間的相似度。表1 所示為不同方法在CAS-PEAL-R1 數(shù)據(jù)集上的Rank-1 識(shí)別準(zhǔn)確率。從表1 中可以觀察到,在一些極端角度上,本文的方法可以得到更高的識(shí)別準(zhǔn)確率,證明了本文方法在側(cè)臉正面化任務(wù)上的有效性。
4.4 消融實(shí)驗(yàn)
為了驗(yàn)證Sym-GAN 模型的優(yōu)勢(shì)以及其各個(gè)組成部分的貢獻(xiàn),進(jìn)行了消融對(duì)比實(shí)驗(yàn)。圖9為本文方法與其3個(gè)不完全變體在CAS-PEAL-R1數(shù)據(jù)集上的可視化比較結(jié)果。從圖9可以看出,若消去總變分正則化損失,會(huì)產(chǎn)生更多的人工偽影;若消去身份信息保留損失,在臉型輪廓上和基準(zhǔn)圖像差距較大;此外,加入眼周特征保留損失,可以使眉毛和眼型上與基準(zhǔn)圖像更加接近,并且網(wǎng)絡(luò)訓(xùn)練中有無(wú)眼周特征保留損失對(duì)身份信息保留損失收斂的對(duì)比如圖10(a)和(b)所示,加入眼周特征保留損失有助于身份信息保留損失的收斂,從而對(duì)面部全局身份信息保留起到一定積極作用。表2 為本文方法與其3 個(gè)不同變體在CAS-PEAL-R1 數(shù)據(jù)集上的Rank-1 識(shí)別率,也可以展示出身份保留損失和眼周特征保留損失在身份信息保留過(guò)程中的有效作用。

表1 CAS-PEAL-R1數(shù)據(jù)集上不同方法的Rank-1識(shí)別率 單位:%Tab.1 Rank-1 recognition rates of different methods on CAS-PEAL-R1 dataset unit:%

圖9 Sym-GAN模型及其變體在CAS-PEAL-R1數(shù)據(jù)集上的生成效果Fig.9 Generation results of Sym-GAN model and its variants on CAS-PEAL-R1 dataset
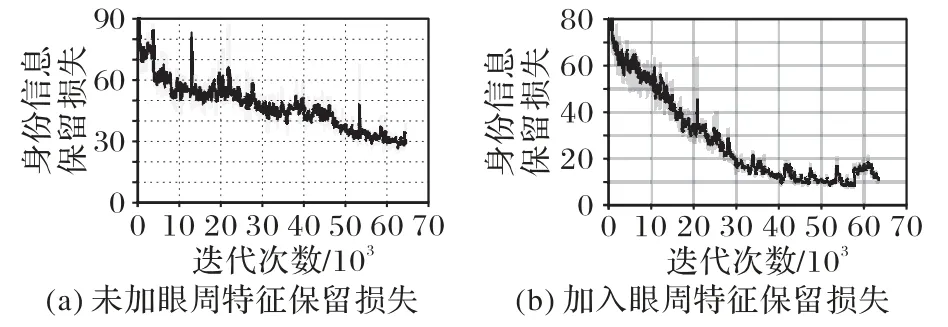
圖10 身份信息保留損失曲線對(duì)比Fig.10 Comparison of identity information preserving loss curves
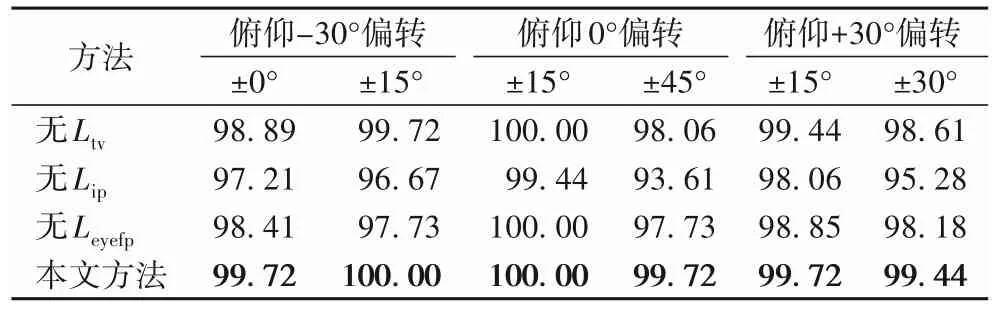
表2 CAS-PEAL-R1數(shù)據(jù)集上各消融結(jié)果的Rank-1識(shí)別率 單位:%Tab.2 Rank-1 recognition rates of ablation results on CAS-PEAL-R1 dataset unit:%
5 結(jié)語(yǔ)
本文針對(duì)多角度側(cè)臉正面化問(wèn)題提出了一種基于面部特征圖對(duì)稱和眼周特征保留損失的生成對(duì)抗網(wǎng)絡(luò)模型。首先,根據(jù)人臉對(duì)稱性這一先驗(yàn)知識(shí),本文提出了特征圖對(duì)稱模塊,用于緩解大角度姿態(tài)下人臉存在的自遮擋現(xiàn)象造成正面化生成較為困難的問(wèn)題。此外,受益于眼周區(qū)域相較于面部其他五官,具有較高的判別能力,加入了眼周特征保留損失使得在生成過(guò)程中對(duì)眼周區(qū)域增大關(guān)注,從而提高生成圖的身份信息保留程度。定性的正面化結(jié)果和定量的人臉識(shí)別性能的實(shí)驗(yàn)驗(yàn)證了本文方法的有效性。同時(shí),將對(duì)面部各五官特征對(duì)人臉識(shí)別的貢獻(xiàn)度進(jìn)行調(diào)研,在眼周保留損失的基礎(chǔ)上嘗試加入面部其他高辨別區(qū)域的身份特征保留從而進(jìn)一步提高生成人臉的效果。
猜你喜歡
作文中學(xué)版(2022年1期)2022-04-14 08:00:34
學(xué)生天地(2020年31期)2020-06-01 02:32:06
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
計(jì)算機(jī)工程(2015年8期)2015-07-03 12:19:07
中外會(huì)展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
電子設(shè)計(jì)工程(2014年8期)2014-02-27 11:57:26
