基于領域自適應方法的統計機器翻譯模型的優化研究
2021-03-17 07:41:28楊玲
科學技術創新 2021年5期
楊玲
(武警工程大學,陜西 西安710086)
1 概述
把一種語言轉變成另一種我們想要的語言這一過程稱為機器翻譯[1]。其中比較常用的方法有基于記憶的翻譯方法、基于實例的翻譯方法、基于統計的翻譯方法、基于神經網絡的翻譯方法。目前,基于統計的機器翻譯模型被稱為這一領域的主流方法,是由Brown[1]等人提出,該模型可分為翻譯模塊、語言模型訓練模塊、解碼模塊。在進行翻譯模型訓練時需要進行詞對齊,由于統計機器翻譯模型在訓練詞對齊模型時未對訓練集進行分類訓練,會影響系統的翻譯性能。因此,本文提出運用最大熵分類器及領域自適應方法對統計機器翻譯模型進行優化,旨在進一步改善模型的翻譯性能。
2 統計機器翻譯模型的優化策略
傳統統計機器翻譯方法的系統原理是,用已對齊好的大規模平行語料訓練詞對齊模型,然后基于此詞對齊模型建立翻譯模型和語言模型并訓練模型參數。但是訓練模型的平行語料來自不同領域,有些詞在不同領域意思也不用,這會影響模型參數的準確度,基于此建立起的翻譯模型和語言模型精確度也會下降,由此得到的譯文不夠準確。為解決這一問題,我們運用領域自適應方法提高統計機器翻譯模型的翻譯精度,即首先應用最大熵分類器的方法對平行語料進行篩選,這一步保證了訓練詞對齊模型的語料符合標準,從而確保了模型參數的精確度。接下來可以運用LDA 模型對雙語平行語料進行主題提取,并得到每個主題對應的語料。然后對每個主題訓練其相應的詞對齊模型,再訓練每個主題的翻譯模型和語言模型。
語料可以劃分為完全平行句、部分平行句對和完全不平行句對。通過觀察可以發現,高質量平行句一般會呈現很多共性:源語言和目標語言互譯準確、源語言和目標語言都比較流暢,基于此特征可以提出使用句對特征評價平行句對質量,利用分類器進行自動判別句對質量好壞的方法。該過程可分為兩部分,第一部分是挑選用于訓練分類器的正負例句對,首先確定句對特征,依據句對在各個特征上的得分對句對進行排序。綜合各個排序的結果,構造區分性較大的訓練句對集合。將那些在各個特征中表現均不好的句對作為負例句對。余下的句對為待分類句對,需要訓練分類器自動分類。第二部分利用前一部分構造得到的正負例句對集合訓練一個最大熵分類器,通過學習正負例句對的特征,分類器可以自動地對句對進行質量判定。然后使用該分類器對第一部分的待分類句對進行自動分類。在分類器的選擇上,本文采用最大熵模型作為分類器進行分類任務。

圖1 基于分類的平行語料選擇方法流程圖
2.1 基于最大熵分類器的平行語料篩選
統計機器翻譯模型需要用到大規模的雙語平行語料進行訓練,因此語料的質量會影響模型的翻譯性能。所以需要對訓練語料進行篩選,淘汰影響系統翻譯質量的語料,保留質量較好的語料進行訓練,這樣可以從源頭上確保系統翻譯質量。本節利用最大熵模型分類器[2]對待訓練語料進行分類,語料可以分為完全平行句對、部分平行句對、和不平行句對,因此我們的任務是可以從這些大規模的平行語料中找到完全平行句對,用這些來訓練模型。首先,我們需要選擇訓練分類器的正負例句,依據每個句對在句對特征的得分來區分正負例句,將得分高的作為正例句,得分低的作為負例句,通過對正負例句的學習,分類器可以對句對進行質量評定,從而使用訓練好的分類器對語料進行篩選。
篩選流程:篩選語料有以下五個關鍵的環節:
(1)句對特征打分。在訓練語料中的句對進行特征得分計算;
(2)句對排序。在上一環節的基礎上,依據每個句對的得分情況進行排序,在此,每一個特征對應都有一個排序結果。
(3)分離器訓練。
(4)分類器自動分類。使用分類器對待分類句對進行分類,然后將分類結果和訓練分類器句對進行融合,得到最終的分類結果。
2.2 主題模型
為了提高系統的翻譯性能,本文利用LDA 模型[3]挖掘雙語語料中的領域信息,從而應用到該領域翻譯模型的搭建中,以提高參數精確度。LDA 模型是一個三層貝葉斯模型[4]。
LDA 模型:
David Blei[3]在2003 年提出隱含狄利克雷分配,這是一種用于離散數據集合的建模方法,它可以自動地完成挖掘大規模語料庫中所蘊含的主題信息。LDA 模型首先基于一篇文檔,這個文檔要求由許多主題組成,LDA 模型將這個文檔看作是這些主題的不同比例的混合,每個主題是指詞表中的一個多項式分布。
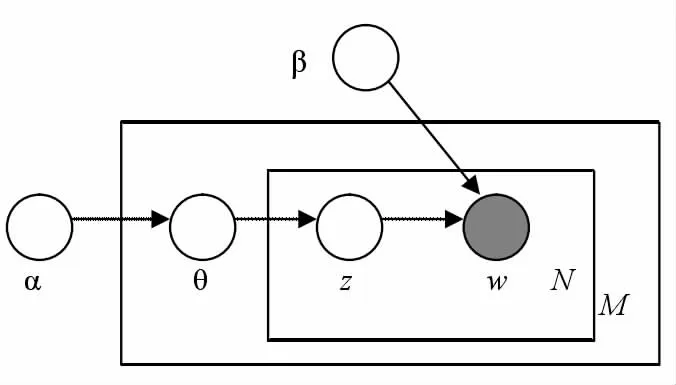
圖2 LDA 概率模型
2.3 領域自適應方法下詞對齊模型原理解析
由于訓練翻譯模型的語料種類較多,對于這種異源的數據進行詞對齊模型訓練,再搭建翻譯模型,這會導致翻譯的準確率下降。比如古漢語短文中有關于醫學的文章,也有關于軍事戰爭的文章,如果我們不對這些異源的數據進行領域區分,這樣就會大大降低我們翻譯準確率,因此在訓練詞對齊模型時,首先要考慮領域這一特性[4]。但是,不同的領域雖有本領域特有的詞語,但是也會有領域之外的詞匯,這一點可以看出領域之間既有共同點也會有不同點,但是我們不能簡單的將不同領域劃分為互無交集的幾個部分分別去訓練詞對齊模型,這會造成信息丟失,準確率下降。因此,為了使得詞對齊準確率提高,將在統計詞對齊模型中引入領域的信息。即對于訓練語料的每個句子首先通過LAD 模型得到其所屬領域的概率,接下來結合領域內與領域外的詞來進行詞對齊。即通過加權技術來實現領域內模型與領域外模型相互結合來提高領域內的詞對齊準確率[5]。

領域自適應詞對齊的訓練過程指:假設雙語平行語料庫由s 個句對組成,首先用LAD 模型對語料庫領域信息進行提取,則假設某一句對(f,e)屬于某一領域的概率為pk[6],則接下來為每一領域訓練相應的詞對齊模型,訓練過程用EM算法進行參數估計:在E 步,兩個詞共同出現在頻率:
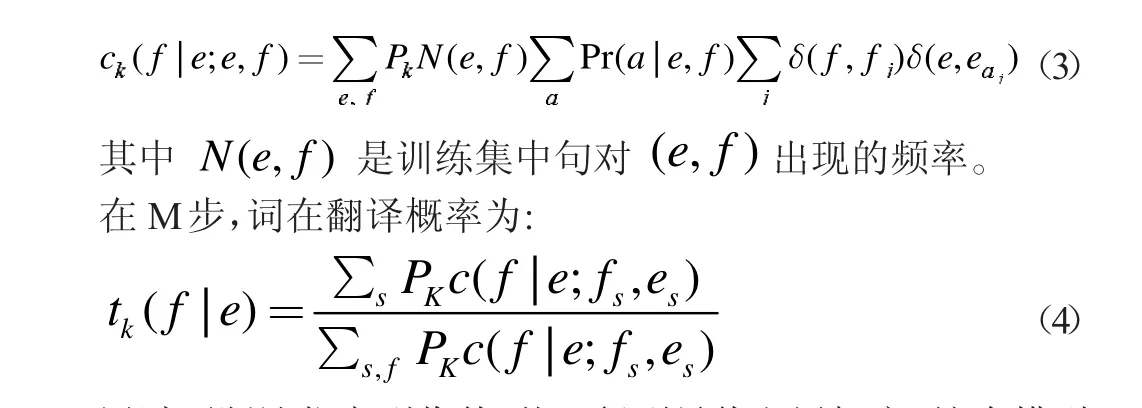
通過不斷迭代直到收斂,從而得到最終翻譯概率。這個模型中,當一個句對屬于某個領域的概率越大,則詞對齊結果就會屬于當前領域,最終在此基礎上相應的翻譯模型,則該模型能夠呈現出所屬領域準確率最高的結果。
3 結論
本文主要介紹了統計機器翻譯模型的改進方法,首先運用最大熵分類器的方法,對訓練統計機器翻譯模型的語料進行篩選,提升了語料的準確性。接下來對篩選的語料運用LDA 主題模型確定了語料的主題,在統計機器翻譯模型詞對齊的過程中對每個進行詞對齊過程的句子結合其對應的主題概率,從而使行詞對齊的結果更精確,進而提升了統計機器翻譯模型中翻譯模型與語言模型的精度,使得統計機器翻譯模型性能有了一定程度的提高。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
