基于XGboost模型的城市軌道交通列車運(yùn)行速度實(shí)時異常檢測研究
2021-03-15 12:31:48劉杰
重慶交通大學(xué)學(xué)報(自然科學(xué)版) 2021年3期
劉 杰
(重慶工程職業(yè)技術(shù)學(xué)院 智能制造與交通學(xué)院,重慶 402260)
0 引 言
截至2018年底,中國內(nèi)地共34個城市開通城市軌道交通運(yùn)營服務(wù),開通城軌交通線路171條,線路總長度為5 295.1 km,同比增長15.53%。2012—2018年,中國城市軌道交通運(yùn)營線路總長度年復(fù)合增長率高達(dá)17.06%。隨著城市軌道交通的迅猛發(fā)展,人們越發(fā)重視行車安全。對列車運(yùn)行速度的監(jiān)控是掌握列車運(yùn)行是否安全的一個重要方面,因此對列車運(yùn)行過程的速度異常檢測十分重要。
國內(nèi)外針對城軌列車運(yùn)行速度異常檢測研究較少。一般異常檢測主要方法有基于距離、密度、聚類和深度學(xué)習(xí)的異常檢測算法。竇珊等[1]提出基于LSTM長短期記憶的檢測模型,首先引入一層LSTM對時間序列數(shù)據(jù)進(jìn)行向量表示,再采用另一層LSTM對時間序列逆序重構(gòu),將重構(gòu)值與實(shí)際值對比并通過極大似然估計(jì)得出異常概率,最終通過學(xué)習(xí)異常報警閾值判斷異常;曾惟如等[2]提出了一種學(xué)習(xí)時間序列內(nèi)在模式關(guān)系的層級實(shí)時記憶網(wǎng)絡(luò),首先離散表征原數(shù)據(jù)相關(guān)性,然后輸入層級記憶模型網(wǎng)絡(luò)預(yù)測下一時刻數(shù)值,最終通過和實(shí)際值比較判斷異常;陳興蜀等[3]對網(wǎng)絡(luò)流量異常檢測進(jìn)行了研究,首先對實(shí)際網(wǎng)絡(luò)流量長期觀測提取正常網(wǎng)絡(luò)行為多維特征,然后引入時間序列偏離度概念,并且根據(jù)網(wǎng)絡(luò)環(huán)境變化對更新偏離度,最后利用支持向量機(jī)分類來結(jié)合各維度信息對異常做綜合判斷;閆偉等[4]也對網(wǎng)絡(luò)流量時間序列異常檢測進(jìn)行研究,首先提取網(wǎng)絡(luò)流量時間序列數(shù)據(jù)并進(jìn)行小波降噪消除干擾因素影響,然后建立狀態(tài)回聲流量網(wǎng)絡(luò)模型檢測異常;余宇峰等[5]以窗口來進(jìn)行子序列分割,用分割后的子序列來預(yù)測,并根據(jù)窗口大小及用戶期望動態(tài)設(shè)定異常判定閾值;陳乾等[6]提出基于距離和自回歸的聯(lián)合檢測方法,計(jì)算待檢測矢量和訓(xùn)練集中各歷史矢量距離,只要小于閾值,則判斷為異常,在考慮算法通用性和復(fù)雜性上,該研究采用的是線性回歸;孫梅玉[7]首先在時間序列GMBR表示的基礎(chǔ)上提出異常模式定義,再將基于距離和基于密度的方法結(jié)合來檢測異常;徐永紅等[8]以滑動窗口為基礎(chǔ),將協(xié)方差矩陣作為時間序列的描述算子,用黎曼距離作為相似性度量標(biāo)準(zhǔn),以統(tǒng)計(jì)過程控制圖作為評價對多元時間序列做異常檢測;李海林等[9]針對增量式時間序列效率低的問題,提出基于頻繁模式異常檢測方法,首先將時間序列符號化,再利用符號化的特征找出頻繁模式,最后度量頻繁模式和新增時間序列之間的相似度來做異常判斷;曹丹陽等[10]基于密度的方法,首先將陰極壓降時間序列分割成不重疊的子序列,再基于子序列的局部密度判斷異常子序列;朱煒玉等[11]首先基于AR自回歸對水質(zhì)時間序列預(yù)測,然后采用孤立森林算法去做異常檢測,得到了較滿意結(jié)果。
以上是將各種時間序列異常檢測技術(shù)和方法運(yùn)用于不同領(lǐng)域的研究成果,但是并沒有針對城市軌道交通運(yùn)行速度異常檢測的研究,因此筆者主要提出一種針對城市軌道交通列車運(yùn)行速度異常檢測算法。
1 列車運(yùn)行速度實(shí)時異常檢測原理
列車運(yùn)行速度異常檢測的本質(zhì)均為利用歷史數(shù)據(jù)信息來做預(yù)測,通過比較預(yù)測值和實(shí)際值來判斷異常。其難點(diǎn)在于以下3點(diǎn):①如何充分挖掘歷史數(shù)據(jù)信息;②如何設(shè)定預(yù)測值和實(shí)際值的異常判斷閾值;③實(shí)時檢測對模型算法計(jì)算時間效率要求較高。筆者實(shí)際研究場景為城市軌道交通列車運(yùn)行的時間-速度數(shù)據(jù)異常檢測。首先采用可變滑動窗口分割子序列,將得到的子序列作為樣例訓(xùn)練XGboost預(yù)測模型 ,然后用XGboost的預(yù)測值區(qū)間作為列車速度真實(shí)值可疑判定標(biāo)準(zhǔn),最后用Grubbs檢驗(yàn)判斷異常。
列車運(yùn)行指除去停站時間外的行駛過程。全過程由若干站間運(yùn)行子過程組成。每個子過程從數(shù)據(jù)上可表示為時間-速度值的時間序列,因此列車運(yùn)行異常檢測問題就是一個時間序列異常點(diǎn)檢測問題。
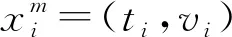
(1)
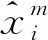
(2)
m=1,2,…,M2)
(3)
式中:M2為測試時間序列個數(shù);f為預(yù)測模型;S為測試序列集合且S={s1,s2,…,sM2}。
(4)
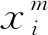
2 基于XGboost的預(yù)測模型構(gòu)建
XGboost(extrem gradient boosting)是一種由若干棵回歸樹組合而成的提升集成算法,其每一輪訓(xùn)練在上一輪基礎(chǔ)上迭代而來,第t次迭代目標(biāo)函數(shù)為[12]:
(5)
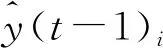
式(2)中obj(t)表示t棵回歸樹集成模型的目標(biāo)函數(shù)優(yōu)化,因此進(jìn)一步簡化為單棵回歸樹優(yōu)化問題,目標(biāo)函數(shù)如式(6)~式(7):
(6)
(7)
(8)
式中:T為單棵回歸樹葉子節(jié)點(diǎn)個數(shù);λ為單棵回歸樹葉子節(jié)點(diǎn)權(quán)值復(fù)雜度懲罰系數(shù);γ為單棵回歸樹葉子節(jié)點(diǎn)數(shù)量復(fù)雜度懲罰系數(shù);qj為第j個葉子節(jié)點(diǎn)包含的樣本集合。
XGboost的本質(zhì)就是通過樣本訓(xùn)練得到若干棵回歸樹,而每一棵樹的構(gòu)造都是從一個根節(jié)點(diǎn)開始的二分裂生長過程,因此式(3)最終簡化為樹節(jié)點(diǎn)分裂目標(biāo)函數(shù):
(9)
2.1 滑動窗口抽樣
D={d1,d2,…,dM1}為列車運(yùn)行歷史時間速度序列集合,其中,dm=(x1,x2,…,xnm)為第m個列車運(yùn)行時間速度序列。nm為第m個時間序列長度值,M1為觀測值時間序列個數(shù)。對于任意從dm∈D提取的樣本要反映序列的局部特征,而最后得到的樣本全集能反映整個序列的特征。抽樣步驟如下:
步驟1:令m=1,k=1,A=φ,A為樣例集合且(zk,yk)∈TD,(zk,yk)為第k個樣例,其中zk為樣本,yk為標(biāo)簽值。
步驟2:令i=1。
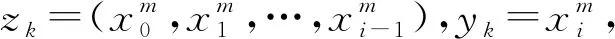
步驟4:如果i=nm,則m=m+1,轉(zhuǎn)步驟5;否則轉(zhuǎn)步驟2。
步驟5:如果m>M1,則結(jié)束,輸出A,否則轉(zhuǎn)步驟2。
2.2 XGboost模型訓(xùn)練
通過2.1節(jié)得到的樣例集合A,采用五折交叉驗(yàn)證方法劃分訓(xùn)練集和驗(yàn)證集,循環(huán)評估模型預(yù)測效果。在劃分時按隨機(jī)抽樣原則,以避免采樣誤差[13]。
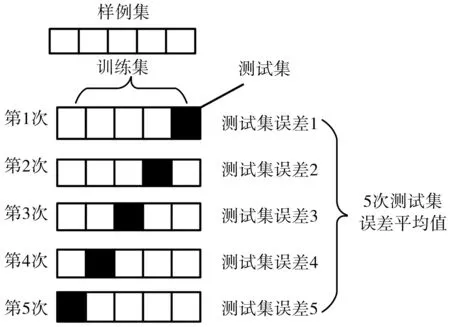
圖1 五折交叉驗(yàn)證過程
由圖1可以看出,每一次迭代均將樣例集劃分為訓(xùn)練集和驗(yàn)證集。在訓(xùn)練集中用XGboost方法迭代訓(xùn)練模型,運(yùn)用網(wǎng)格搜索方法選擇XGboost模型參數(shù)最優(yōu)值,逐步調(diào)參,最后利用驗(yàn)證集臺驗(yàn)證預(yù)測效果選取最優(yōu)參數(shù)組,從而得到最終的預(yù)測模型f。利用預(yù)測模型就可以對列車在實(shí)際運(yùn)行過程中采集的數(shù)據(jù)進(jìn)行實(shí)時預(yù)測。
3 異常判定
異常判定分為兩個階段。第一階段是判斷第i時刻預(yù)測值和列車速度真實(shí)值之差是否在閾值區(qū)間內(nèi),如果在區(qū)間內(nèi),則為正常,否則判定為可疑點(diǎn)。第二階段是如果列車速度真實(shí)值被判定為可疑,則對該點(diǎn)進(jìn)一步用Grubbs檢驗(yàn)判定是否為異常點(diǎn)。
3.1 可疑點(diǎn)判斷
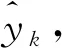
(10)
式中:μe和σe分別為誤差正態(tài)分布的均值和標(biāo)準(zhǔn)差。
接下來將集合E看作e的樣本集,根據(jù)最大似然原理對μe和σe進(jìn)行參數(shù)估計(jì),如式(11)~式(13):
(11)
(12)
PI=[μe-3σe,μe+3σe]
(13)
式中:PI為閾值區(qū)間;|E|為集合E的元素個數(shù)。
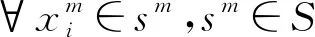
(14)
3.2 Grubbs異常檢驗(yàn)
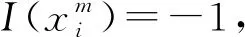
步驟1:初始化檢驗(yàn)水平α=0.01的Grubbs檢驗(yàn)臨界值分別為C3=1.155,C4=1.492,C5=1.749。
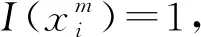
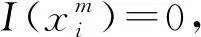
將異常判定兩個階段的算法步驟合在一起,得到完整異常判定算法,步驟如下:
步驟1:m=1,sm∈S,轉(zhuǎn)步驟2。
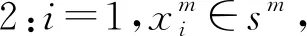
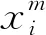
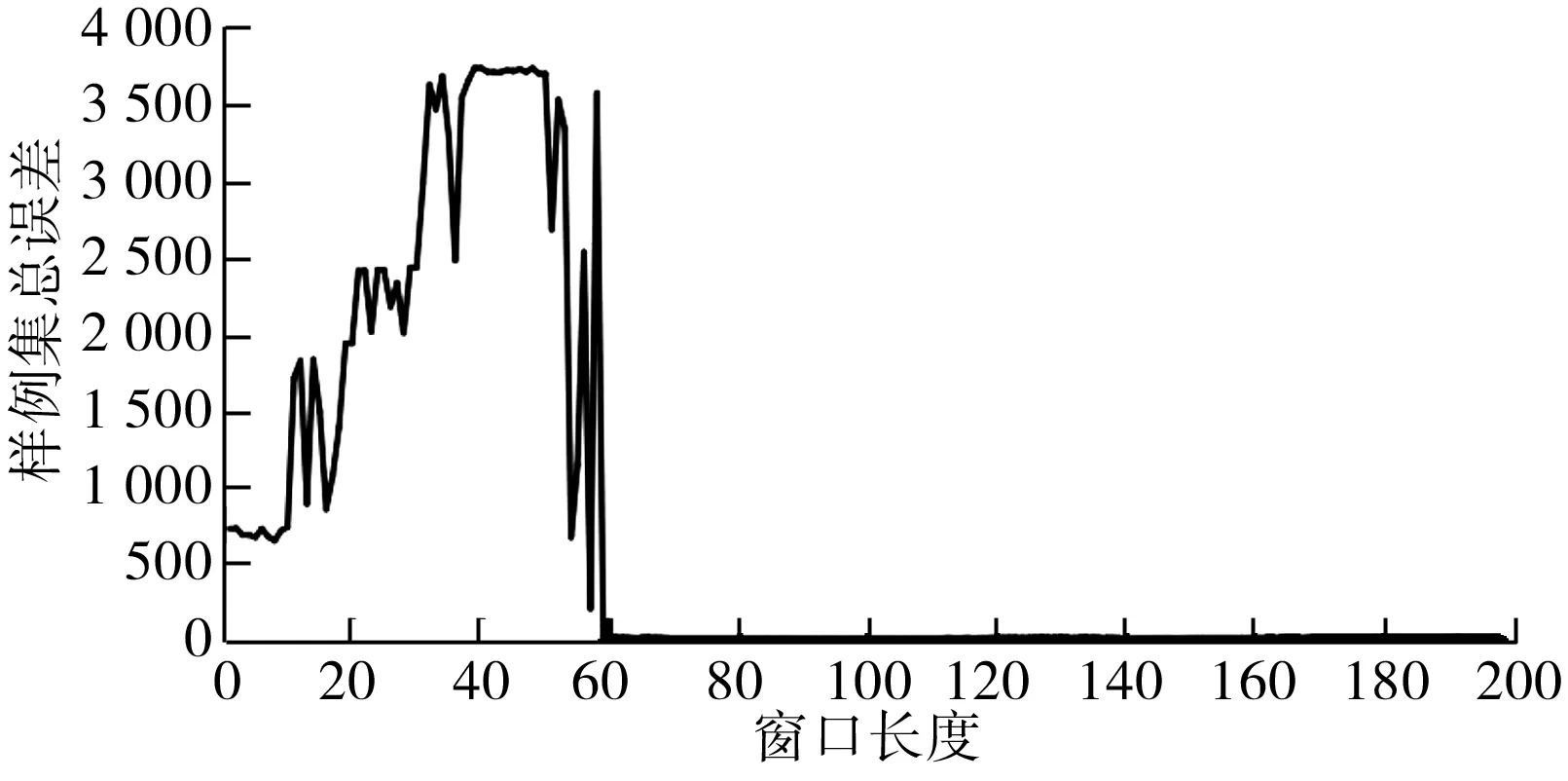
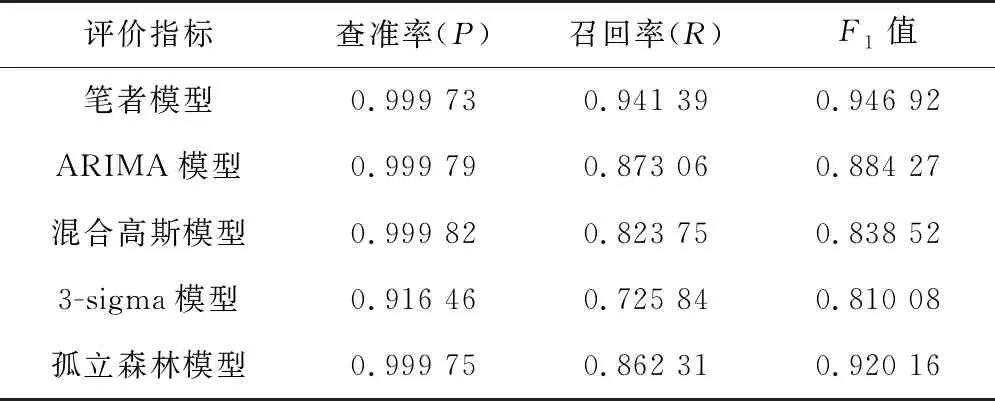
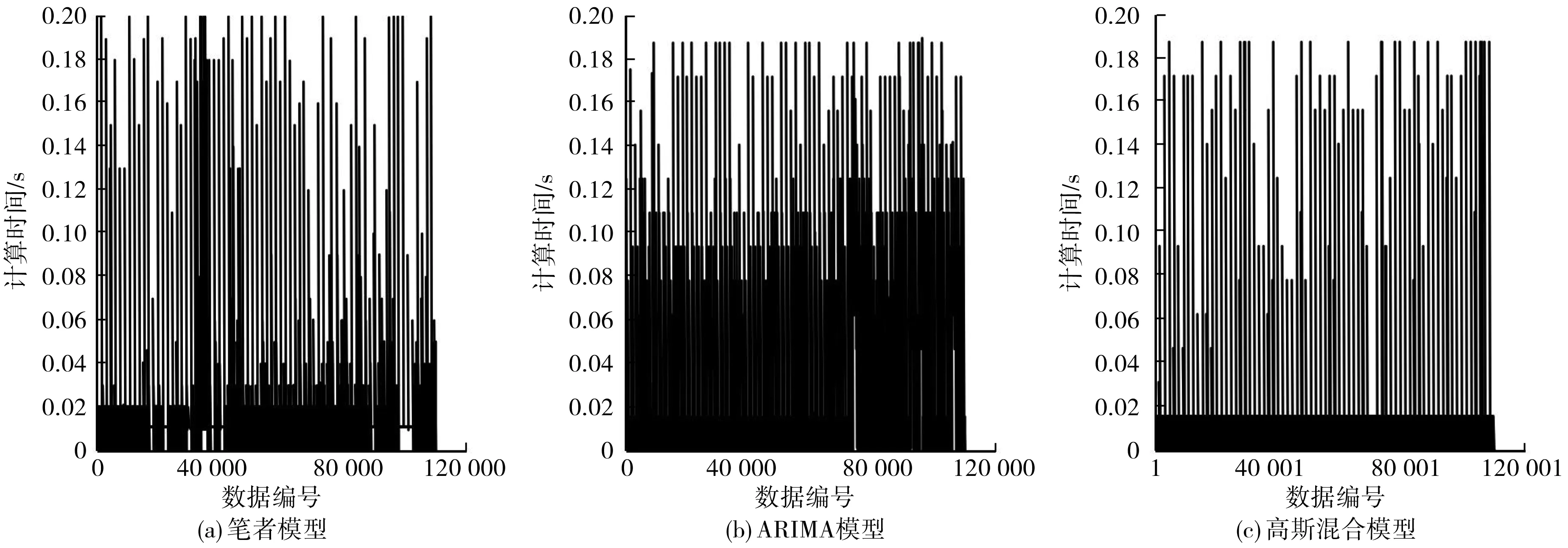
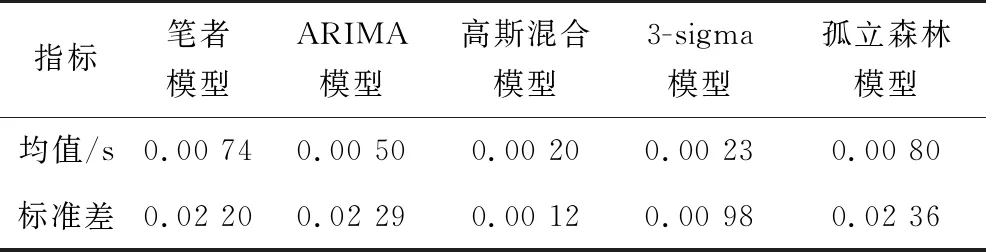
步驟6:如果i 步驟7:如果m 綜上所述,異常檢測整個流程如圖2。 圖2 實(shí)驗(yàn)流程 實(shí)驗(yàn)在windows10系統(tǒng)、2.7 GHz Inter Core i7 處理器、Python 3.6.4 環(huán)境下進(jìn)行,以重慶地鐵6號線15個車一個月行車數(shù)據(jù)為基礎(chǔ)數(shù)據(jù)集,抽樣得到151 771條樣例。測試集數(shù)據(jù)采用人工標(biāo)注過異常點(diǎn)的時間序列72條共110 232個數(shù)據(jù)點(diǎn),其中標(biāo)記異常點(diǎn)總數(shù)3 012個。 在樣例集上運(yùn)用五折交叉驗(yàn)證和網(wǎng)格搜索計(jì)算得到樣例集總誤差隨窗口長度參數(shù)變化情況如圖3。 圖3 樣例集總誤差和窗口長度變化情況 從圖3可以看出,不同r取值會影響XGboost預(yù)測模型的預(yù)測精度。實(shí)驗(yàn)結(jié)果表明,當(dāng)r=90時,預(yù)測總誤差最小值為18.554 4,因此筆者選擇r=90所對應(yīng)的XGboost模型作為最終預(yù)測模型,其最優(yōu)參數(shù)取值為:max_depth=8, min_child_weight=1,gamma=0.0,colsample_bytree=0.8, subsample=0.8,eta=0.05,r=90。其中, eta為學(xué)習(xí)率;min_child_weight為最小葉子節(jié)點(diǎn)樣本權(quán)重和;max_depth為單棵樹最大深度;gamma為節(jié)點(diǎn)分裂所需的最小損失函數(shù)下降值;colsample_bytree為特征的隨機(jī)采樣比例;subsample為生成樹的隨機(jī)采樣比例。 上述得到XGboost預(yù)測模型在樣例集上的誤差,結(jié)合式(10)~式(12)計(jì)算得到μe=-0.000 002,σe=0.009 395和PI=[-0.028 187,0.028 183]。 基于上述計(jì)算參數(shù)將得到的異常檢測模型同ARIMA模型、高斯混合模型、3-sigma模型和孤立森林模型進(jìn)行對比,在查準(zhǔn)率(P)、召回率(R)和F1值3個指標(biāo)上的對比結(jié)果如下表1。 表1 模型評估指標(biāo)對比 從表1可以看出,在查準(zhǔn)率上5種模型都有很高準(zhǔn)確率,最低的3-sigma模型為0.916 46,說明模型的誤報率都很低。但是通過分析可知,樣例集中正常點(diǎn)和異常點(diǎn)的比例為35.597 6,說明樣例占比極不均衡,因此在樣本不均衡情況下即使查準(zhǔn)率接近100%也并不能作為模型整體檢測性能的關(guān)鍵指標(biāo)。再從召回率來看,R值分別為0.941 39、0.873 06、0.823 75、0.810 08和0.920 16,這說明在漏報率方面筆者模型性能優(yōu)于其他模型。F1值是一個綜合P值和R值考慮的模型性能評估指標(biāo),從其結(jié)果來看筆者模型在整體檢測性能上也要優(yōu)于其他模型。 在實(shí)際異常檢測過程中必須要考慮模型的計(jì)算時間效率,否則不滿足實(shí)時檢測的要求。重慶行車數(shù)據(jù)的采集時間間隔為0.2 s,這要求模型從當(dāng)前時刻算起,預(yù)測下一時刻數(shù)據(jù)和異常點(diǎn)判定時間總和小于0.2 s。5種模型在測試集上計(jì)算時間如圖4。 圖4 計(jì)算時間 從圖4可以看出,5種模型在測試集所有數(shù)據(jù)點(diǎn)上的計(jì)算時間均小于0.2 s,說明它們均滿足實(shí)時檢測要求。經(jīng)統(tǒng)計(jì)各模型計(jì)算時間的均值和標(biāo)準(zhǔn)差如表2。 表2 均值和標(biāo)準(zhǔn)差統(tǒng)計(jì) 從表2可以看出,從均值來看,時間效率平均水平從高到低分別是高斯混合、3-sigma、ARIMA、筆者模型和孤立森林,說明高斯混合和3-sigma模型 計(jì)算時間是最快的。從標(biāo)準(zhǔn)差來看,從低到高分別是高斯混合、3-sigma、筆者模型、ARIMA和孤立森林,說明高斯混合和3-sigma模型計(jì)算時間也最穩(wěn)定。分析可知,高斯混合和3-sigma模型都是基于概率密度的判斷模型,其時間開銷主要在數(shù)據(jù)點(diǎn)異常概率計(jì)算上,而在異常判定時只需與閾值比較,幾乎不需要時間開銷。相比而言,其它3種模型都是基于預(yù)測值的判斷模型,除了在預(yù)測值生成上的時間開銷高于概率密度計(jì)算外,還在異常判定時有檢驗(yàn)計(jì)算時間開銷,因此總的時間效率水平和穩(wěn)定性低于高斯混合和3-sigma模型。 列車運(yùn)行速度實(shí)施異常檢測對于城市軌道交通正常運(yùn)營起安全監(jiān)控作用。筆者針對城軌列車運(yùn)行速度異常檢測提出基于XGboost模型和Grubbs檢驗(yàn)的方法,可有效解決其他方法中召回率不高的不足。實(shí)驗(yàn)結(jié)果表明,筆者提出模型在測試集上整體性能表現(xiàn)優(yōu)于其他對比模型,而且在F1值上超過90%,說明在誤報率和漏報率兩個方面都有較好表現(xiàn),滿足城市軌道交通列車運(yùn)行速度實(shí)時異常檢測的時間要求,模型的計(jì)算效率在實(shí)際測試中是有效的。鑒于異常檢測預(yù)測模型在訓(xùn)練上計(jì)算開銷巨大,特別在模型調(diào)參優(yōu)化上非常耗時,如何加快模型訓(xùn)練速度是進(jìn)一步研究方向。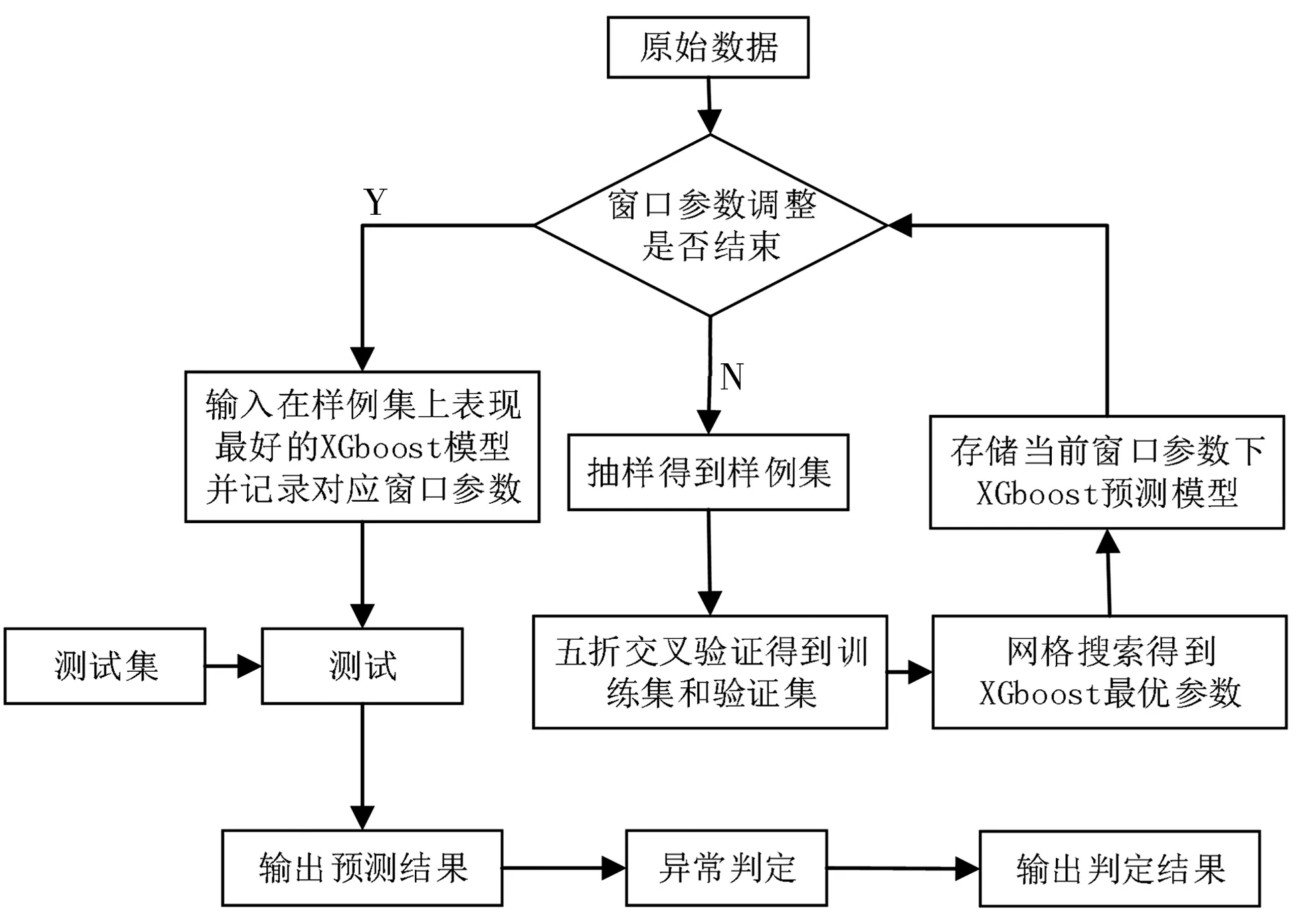
4 實(shí)例分析
4.1 實(shí)驗(yàn)環(huán)境和數(shù)據(jù)集
4.2 最優(yōu)參數(shù)選擇
4.3 實(shí)驗(yàn)結(jié)果對比
4.4 時間效率分析
5 結(jié) 論
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24光學(xué)精密工程(2016年6期)2016-11-07 09:07:19海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
