基于機(jī)器學(xué)習(xí)的海里油耗估計(jì)算法
2021-03-09 09:41:42李湘軍朱慧敏譚笑張瑞薛晨彭志強(qiáng)
新型工業(yè)化 2021年1期
李湘軍,朱慧敏,譚笑,張瑞,薛晨,彭志強(qiáng)
(震兌工業(yè)智能科技有限公司,廣東 深圳 518101)
0 引言
當(dāng)前世界經(jīng)濟(jì)形勢(shì)低迷,國際航運(yùn)市場(chǎng)也不可避免地受到影響,如何降低航運(yùn)的成本,提高利潤(rùn),成為國際航運(yùn)市場(chǎng)普遍關(guān)心的話題,而降低主機(jī)燃油消耗則是其中關(guān)鍵的一環(huán)。與此同時(shí),隨著生產(chǎn)力的發(fā)展,人民生活水平的提高,越來越多的國家開始關(guān)注環(huán)境問題,要求航運(yùn)船舶降低碳排放量。這些均促使著航運(yùn)公司追求更低的主機(jī)燃油消耗。
一方面,挖掘與主機(jī)燃油消耗相關(guān)的因素,進(jìn)而建立主機(jī)的燃油消耗模型,是進(jìn)一步實(shí)現(xiàn)更低主機(jī)燃油消耗的重要條件。另一方面,流量計(jì)價(jià)格昂貴,也給船運(yùn)公司造成了一定的負(fù)擔(dān),而當(dāng)前基于實(shí)際航行數(shù)據(jù)進(jìn)行油耗估計(jì)的研究卻很少。在此背景下,本文提出了基于機(jī)器學(xué)習(xí)方法的海里油耗估計(jì)模型,既為指導(dǎo)船舶更高效地利用燃油,也為船舶無流量計(jì)運(yùn)行而依賴算法根據(jù)實(shí)際航行數(shù)據(jù)估計(jì)船舶燃油流量奠定了基礎(chǔ)。
首先,本文利用隨機(jī)森林算法從眾多的參數(shù)中選擇出了與主機(jī)燃油流量最相關(guān)的五個(gè)參數(shù);其次,對(duì)輸入的五個(gè)特征維度進(jìn)行了預(yù)處理;最后,為了驗(yàn)證所選特征的有效性,本文從眾多船舶參數(shù)中隨機(jī)抽取五個(gè)特征與所選特征進(jìn)行建模對(duì)比,多次實(shí)驗(yàn)結(jié)果表明隨機(jī)森林所選特征取得了最高的準(zhǔn)確度,證明了該方法的有效性。
為了增強(qiáng)模型的可解釋性,本文使用LASSO回歸建模對(duì)主機(jī)燃油消耗進(jìn)行預(yù)測(cè),實(shí)驗(yàn)結(jié)果表明LASSO算法具有較好的預(yù)測(cè)結(jié)果和較強(qiáng)的可解釋性。
1 隨機(jī)森林和LASSO回歸
現(xiàn)實(shí)情況下,一個(gè)數(shù)據(jù)集中往往有成百上千個(gè)特征,如何在其中選擇對(duì)結(jié)果影響最大的那幾個(gè)特征,以此來縮減建立模型時(shí)的特征數(shù)是我們非常關(guān)心的問題[1-2]。因此,本文首先利用了隨機(jī)森林算法從眾多的船舶參數(shù)中進(jìn)行了特征選擇,通過隨機(jī)森林來進(jìn)行特征選取的主要優(yōu)點(diǎn)在于,可以處理特征較多的數(shù)據(jù)集,并且使用隨機(jī)森林算法進(jìn)行特征提取前,無需對(duì)數(shù)據(jù)進(jìn)行標(biāo)準(zhǔn)化處理。
隨機(jī)森林是機(jī)器學(xué)習(xí)中的一種常用方法[3],是用隨機(jī)的方式生成由多個(gè)沒有關(guān)系的決策樹組成的森林。其中決策樹是一個(gè)樹結(jié)構(gòu)[4],每個(gè)非葉節(jié)點(diǎn)表示一個(gè)根據(jù)特征屬性的劃分方法,每個(gè)分支代表這個(gè)特征屬性在某個(gè)值域上的輸出,而每個(gè)葉節(jié)點(diǎn)存放一個(gè)輸出結(jié)果。使用決策樹進(jìn)行決策的過程就是從根節(jié)點(diǎn)開始,測(cè)試待分類項(xiàng)中相應(yīng)的特征屬性,并按照其值選擇輸出分支,直到到達(dá)葉子節(jié)點(diǎn),最終將葉子節(jié)點(diǎn)存放的類別作為決策結(jié)果。
獲得森林之后,當(dāng)有一個(gè)新的輸入樣本進(jìn)入時(shí),森林中的每一棵決策樹將分別進(jìn)行判斷樣本的所屬類別(對(duì)于分類算法),被選擇最多的類別即為最終的分類結(jié)果。另外,隨機(jī)森林還可以進(jìn)行無監(jiān)督學(xué)習(xí)聚類和異常點(diǎn)檢測(cè)。
在統(tǒng)計(jì)學(xué)[5]和機(jī)器學(xué)習(xí)[6]中,LASSO算法[7]是一種同時(shí)進(jìn)行特征選擇和正則化的回歸分析方法,可以增強(qiáng)統(tǒng)計(jì)模型的預(yù)測(cè)準(zhǔn)確性和可解釋性。LASSO算法揭示了很多估計(jì)量的重要性質(zhì),例如 LASSO系數(shù)估計(jì)值和軟閾值之間的聯(lián)系,當(dāng)協(xié)變量共線時(shí),LASSO系數(shù)估計(jì)值不一定唯一。
LASSO算法的特點(diǎn)是在擬合廣義線性模型的同時(shí)進(jìn)行變量篩選和復(fù)雜度調(diào)整。例如,假設(shè)模型有100個(gè)系數(shù),但其中只有10個(gè)系數(shù)是非零系數(shù),這實(shí)際上是說“其他90個(gè)變量對(duì)預(yù)測(cè)目標(biāo)值沒有用處”。LASSO回歸自動(dòng)進(jìn)行了“參數(shù)選擇”,未被選中的特征變量對(duì)整體的權(quán)重為0。基于上述特點(diǎn),本文采用了LASSO算法進(jìn)行燃油消耗模型構(gòu)建。
2 算法流程
本文應(yīng)用算法流程如圖1所示。
2.1 特征選擇
根據(jù)兩艘船舶不同數(shù)據(jù)進(jìn)行特征選擇,步驟如下:
(1)用N來表示訓(xùn)練用例(樣本)的個(gè)數(shù),M表示特征數(shù)目。
(2)輸入用于確定決策樹上一個(gè)節(jié)點(diǎn)的決策結(jié)果的特征數(shù)目m。

圖1 算法應(yīng)用流程圖
(3)從N個(gè)訓(xùn)練用例(樣本)中以有放回抽樣的方式,取樣N次,形成一個(gè)訓(xùn)練集,并用未抽到的用例(樣本)作預(yù)測(cè),評(píng)估其誤差。
(4)對(duì)于每一個(gè)節(jié)點(diǎn),隨機(jī)選擇m個(gè)特征,決策樹上每個(gè)節(jié)點(diǎn)的決定都是基于這些特征確定的。根據(jù)這m個(gè)特征,計(jì)算其最佳的生成方式。
(5)每棵樹都會(huì)完整成長(zhǎng)而不會(huì)剪枝,這有可能在建完一棵正常樹狀模型后會(huì)被采用。
本文采用sklearn開源模塊庫[8]集成算法模塊ensemble[9]中的隨機(jī)森林算法相關(guān)的函數(shù)進(jìn)行實(shí)現(xiàn),此過程共需要輸入3個(gè)超參數(shù):①n_estimators:它表示建立的樹的數(shù)量。一般來說,樹的數(shù)量越多,性能越好,預(yù)測(cè)也越穩(wěn)定,但這也會(huì)減慢計(jì)算速度。基于經(jīng)驗(yàn),在實(shí)踐中選擇數(shù)百棵樹是比較好的選擇,故本次分析過程取值100。②n_jobs:超參數(shù)表示引擎允許使用處理器的數(shù)量。若值為1,則只能使用一個(gè)處理器。 值為-1則表示沒有限制。設(shè)置n_jobs可以加快模型計(jì)算速度,本次分析過程設(shè)置為-1。③oob_score:它是一種隨機(jī)森林交叉驗(yàn)證方法,即是否采用袋外樣本來評(píng)估模型的好壞。默認(rèn)是False。本文設(shè)置為True,因?yàn)榇夥謹(jǐn)?shù)反應(yīng)了一個(gè)模型擬合后的泛化能力。
2.2 數(shù)據(jù)標(biāo)準(zhǔn)化
在進(jìn)入機(jī)器學(xué)習(xí)模型前通常需要對(duì)原始數(shù)據(jù)進(jìn)行中心化處理和標(biāo)準(zhǔn)化處理。在實(shí)船數(shù)據(jù)中,各變量擁有不同的量綱和量綱單位,因此在后續(xù)決策模型訓(xùn)練使用前,同樣需要對(duì)原始數(shù)據(jù)進(jìn)行標(biāo)準(zhǔn)化處理,過程如公式(1)所示。

標(biāo)準(zhǔn)化是基于原始數(shù)據(jù)的均值(μ)和標(biāo)準(zhǔn)差進(jìn)行數(shù)據(jù)的標(biāo)準(zhǔn)化。經(jīng)過處理的數(shù)據(jù)符合標(biāo)準(zhǔn)正態(tài)分布,即均值為0,標(biāo)準(zhǔn)差為1。
2.3 模型構(gòu)建
在模型構(gòu)建過程中,首先利用隨機(jī)森林根據(jù)參數(shù)重要性進(jìn)行排序,選擇重要的參數(shù)進(jìn)行LASSO回歸建模并確定其相關(guān)系數(shù)。最后針對(duì)不同船舶數(shù)據(jù)重復(fù)上述步驟直至獲得LASSO回歸函數(shù)。
3 實(shí)船驗(yàn)證
3.1 測(cè)試數(shù)據(jù)集信息
利用隨機(jī)森林進(jìn)行特征提取,最終選擇出了與燃油消耗相關(guān)性排名較高的5個(gè)特征,表1為兩船舶特征提取結(jié)果。

表1 特征提取結(jié)果
根據(jù)上述特征選擇結(jié)果,我們提取到了如表2所示的測(cè)試數(shù)據(jù)集。

表2 測(cè)試數(shù)據(jù)
測(cè)試集數(shù)據(jù)同樣需要進(jìn)行數(shù)據(jù)標(biāo)準(zhǔn)化操作,需要注意的是在針對(duì)測(cè)試集進(jìn)行標(biāo)準(zhǔn)化時(shí)應(yīng)該與訓(xùn)練數(shù)據(jù)集的轉(zhuǎn)化標(biāo)準(zhǔn)保持一致,如1號(hào)船舶測(cè)試集標(biāo)準(zhǔn)化過程應(yīng)該按照1號(hào)船舶訓(xùn)練集的各變量均值及方差進(jìn)行轉(zhuǎn)化,1號(hào)船舶測(cè)試集速度變量標(biāo)準(zhǔn)化如式(2)所示:

式中:μtrain是訓(xùn)練集中變量船速S的均值;是訓(xùn)練集中變量船速S的方差。
經(jīng)過上述標(biāo)準(zhǔn)化后,為了驗(yàn)證我們選擇到的特征有效性,我們采用了SVM算法進(jìn)行模型訓(xùn)練。以1號(hào)船舶數(shù)據(jù)為例,首先我們進(jìn)行了如表2所示的五個(gè)特征到海里油耗的預(yù)測(cè),進(jìn)一步地,我們從眾多的船舶參數(shù),包括時(shí)間戳、對(duì)水速度、船艏向、舵角、水深、吃水、航速、風(fēng)向、風(fēng)速、緯度、經(jīng)度、轉(zhuǎn)速、主機(jī)功率、1號(hào)電機(jī)功率、2號(hào)電機(jī)功率、3號(hào)電機(jī)功率、電機(jī)進(jìn)口流量、電機(jī)出口流量、滑失率當(dāng)中隨機(jī)抽取5個(gè)特征進(jìn)行訓(xùn)練(為了保證海里油耗是可以計(jì)算的,其中5個(gè)特征中必然有航速數(shù)據(jù))。重復(fù)四次隨機(jī)選取特征,最后一次用隨機(jī)森林選擇到的五個(gè)特征進(jìn)行訓(xùn)練,偏差采用中位數(shù)絕對(duì)誤差,得到如表3所示的結(jié)果。如表中所示,第5次實(shí)驗(yàn)取得了最高的準(zhǔn)確度。因此,我們能夠看出隨機(jī)森林選擇到的特征是有效果的。

表3 特征驗(yàn)證
3.2 模型準(zhǔn)確性衡量
為了增強(qiáng)模型的可解釋性,本文嘗試采用了LASSO回歸進(jìn)行建模。經(jīng)過LASSO回歸模型訓(xùn)練,得到的1號(hào)船舶模型如公式(3)所示,2號(hào)船舶如公式(4)所示。
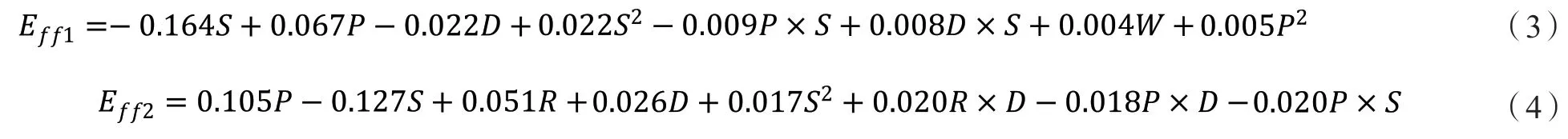
式中:S表示實(shí)際航速,P表示主機(jī)功率,R表示主機(jī)轉(zhuǎn)速,D表示吃水,W表示風(fēng)速,Eff表示海里油耗。
為了驗(yàn)證上述訓(xùn)練模型的準(zhǔn)確性,評(píng)價(jià)回歸模型程度優(yōu)劣程度和所擬合的回歸方程效果,我們一方面采用了R2來衡量模型預(yù)測(cè)值的準(zhǔn)確性。決定系數(shù)(Coefficient of Determination)是反映模型擬合優(yōu)度的重要的統(tǒng)計(jì)量,為回歸平方和與總平方和之比[10]。R2數(shù)值大小反映了回歸貢獻(xiàn)的相對(duì)程度,其取值在0到1之間,且無單位,即在因變量Y的總變異中回歸關(guān)系所能解釋的百分比。另一方面,通過計(jì)算MSE(Mean Square Error)來衡量線性模型的準(zhǔn)確性[11]。該統(tǒng)計(jì)參數(shù)是預(yù)測(cè)數(shù)據(jù)和原始數(shù)據(jù)對(duì)應(yīng)點(diǎn)誤差的平方和的均值,計(jì)算公式如式(5):

式中:yi是真實(shí)數(shù)據(jù),是擬合的數(shù)據(jù),其中n為樣本的個(gè)數(shù)。
如表4所示為模型測(cè)試結(jié)果。如圖2和圖3所示為測(cè)試集目標(biāo)參數(shù)真實(shí)值與模型預(yù)測(cè)值可視化對(duì)比,由于測(cè)試集數(shù)據(jù)較多,本次可視化過程只隨機(jī)選取測(cè)試集中200個(gè)目標(biāo)參數(shù),及其對(duì)應(yīng)的模型預(yù)測(cè)值進(jìn)行展示,以方便觀察。圖2與圖3分別代表了兩船舶模型測(cè)試結(jié)果,藍(lán)色虛線代表模型預(yù)測(cè)值,綠色實(shí)線代表目標(biāo)參數(shù)真實(shí)值。觀察圖2和3所示的預(yù)測(cè)值和真實(shí)值對(duì)比結(jié)果和表4所示的R2和MSE值,可以看出模型能夠較好地通過篩選到的五個(gè)特征擬合海里油耗,這驗(yàn)證了LASSO算法的有效性。同時(shí),從公式(3)和(4)中,我們能夠看出模型具有很好的可解釋性。

表4 模型測(cè)試結(jié)果

圖2 號(hào)船舶預(yù)測(cè)值與真實(shí)值對(duì)比

圖3 號(hào)船舶預(yù)測(cè)值與真實(shí)值對(duì)比
4 結(jié)論
本文基于隨機(jī)森林和LASSO算法構(gòu)建了海里油耗模型,實(shí)驗(yàn)結(jié)果表明我們的方法取得了較好的效果,可以通過所篩選到的五個(gè)船舶參數(shù)較為精確地估計(jì)主機(jī)海里油耗,從而為節(jié)省船舶航行時(shí)的海里油耗提供了依據(jù),為最終實(shí)現(xiàn)更加科學(xué)指導(dǎo)船舶運(yùn)營(yíng)實(shí)現(xiàn)降低燃油消耗和實(shí)現(xiàn)船舶無流量計(jì)運(yùn)行打下了良好基礎(chǔ)。
猜你喜歡
艦船科學(xué)技術(shù)(2022年14期)2022-09-22 03:07:40
口腔護(hù)理用品工業(yè)(2021年4期)2021-11-02 08:22:56
船舶(2021年4期)2021-09-07 17:32:22
小哥白尼(趣味科學(xué))(2019年10期)2020-01-18 09:16:22
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
中國公路(2017年9期)2017-07-25 13:26:38
汽車維修與保養(yǎng)(2015年8期)2015-04-17 03:32:51
中國質(zhì)量與標(biāo)準(zhǔn)導(dǎo)報(bào)(2014年9期)2014-02-28 22:25:45
