基于深度學(xué)習(xí)的實(shí)時(shí)車輛檢測(cè)研究
2021-03-08 09:41:28黃生鵬范平清
軟件工程 2021年1期
關(guān)鍵詞:特征提取
黃生鵬 范平清


摘? 要:針對(duì)城市交通復(fù)雜場(chǎng)景下車輛檢測(cè)存在準(zhǔn)確率低的問(wèn)題,提出改進(jìn)SSD(單發(fā)多箱探測(cè)器)目標(biāo)檢測(cè)算法。首先基于輕量化的PeleeNet(一種基于密集卷積網(wǎng)絡(luò)的輕量化網(wǎng)絡(luò)變體)網(wǎng)絡(luò)結(jié)構(gòu)改進(jìn)SSD算法中VGG16(視覺(jué)幾何群網(wǎng)絡(luò))特征提取網(wǎng)絡(luò),在保證提取豐富特征的前提下,有效地減少模型參數(shù),提高模型的實(shí)時(shí)性;其次設(shè)計(jì)了多尺度特征融合模塊和底層特征增強(qiáng)模塊,提高特征的表達(dá)性能;最后根據(jù)數(shù)據(jù)集中目標(biāo)的大小調(diào)整默認(rèn)框的長(zhǎng)寬比例,并在后三個(gè)特征層的每個(gè)單元上增加默認(rèn)框。實(shí)驗(yàn)結(jié)果表明,改進(jìn)后的目標(biāo)檢測(cè)算法的準(zhǔn)確率mAP(平均精度)為79.83%,與原始SSD相比提高了2.25%,并驗(yàn)證了改進(jìn)SSD算法的有效性。
關(guān)鍵詞:實(shí)時(shí)性;SSD;默認(rèn)框;特征提取
中圖分類號(hào):TP391? ? ?文獻(xiàn)標(biāo)識(shí)碼:A
文章編號(hào):2096-1472(2021)-01-13-04
Abstract: This paper proposes an improved SSD (Single Shot Multiple Box Detector) target detection algorithm to improve the vehicle detection accuracy in complex urban traffic scenarios. Firstly, VGG16 (Visual Geometry Group Network) feature extraction network algorithm in SSD is improved based on the lightweight PeleeNet (A lightweight network variant based on dense convolution network.) network structure. Under the premise of ensuring the extraction of rich features, it can effectively reduce model parameters and improve the real-time performance of the model. Secondly, a multi-scale feature fusion module and a low-level feature enhancement module are designed to improve the expression performance of features. Finally, length-width ratio of the default frame is adjusted according to the target size in data set, and the default frame is added to each cell of the last three feature layers. Experimental results show that the accuracy of mAP (mean Average Precision) of target detection algorithm is improved to 79.83%, which is 2.25% higher than the original SSD. So the improved SSD algorithm is verified to be effective.
Keywords: real-time; SSD; default frame; feature extraction
1? ?引言(Introduction)
高級(jí)輔助駕駛系統(tǒng)(Advanced Driver Assistance Systems, ADAS)是提高行車安全的重要技術(shù)手段之一,能否對(duì)行車環(huán)境中前方行駛車輛進(jìn)行有效的實(shí)時(shí)檢測(cè)是完成ADAS功能的首要前提[1]。
目前,視覺(jué)車輛檢測(cè)技術(shù)主要分為兩類:基于傳統(tǒng)圖像特征的目標(biāo)檢測(cè)算法和基于深度學(xué)習(xí)的目標(biāo)檢測(cè)算法。傳統(tǒng)的目標(biāo)檢測(cè)算法主要采用人工設(shè)計(jì)的目標(biāo)物特征,如HOG(Histogram of Oriented Gradient)[2]、Haar(Haar-like features)[3]等,將這些特征送入SVM(Support Vector Machines)[4]等分類器中進(jìn)行目標(biāo)分類檢測(cè)。基于深度學(xué)習(xí)的目標(biāo)檢測(cè)算法主要有兩個(gè)分支:以R-CNN(Region-based Convolutional Neural Networks)[5]、Fast R-CNN[6]、Faster-RCNN(Towards Real-Time object Detection with Region Proposal Networks)[7]、R-FCN(Object detection via region-based fully convolution networks)[8]算法為代表的基于候選框的兩階段目標(biāo)檢測(cè)算法;另一條路線是以YOLO(You Only Look Once)[9]、SSD[10]、Retina-Net(Focal Loss for Dense Object Detection)[11]為代表的單階段目標(biāo)檢測(cè)算法。基于深度學(xué)習(xí)的單階段目標(biāo)檢測(cè)算法是當(dāng)前應(yīng)用于車輛實(shí)時(shí)性檢測(cè)的主流方法,尤其是SSD目標(biāo)檢測(cè)框架的應(yīng)用場(chǎng)景廣泛。
本文主要在多尺度目標(biāo)檢測(cè)算法SSD的基礎(chǔ)上進(jìn)行改進(jìn),采用一種基于DenseNet(Dense Convolutional Network)[12]的輕量化網(wǎng)絡(luò)結(jié)構(gòu)變體PeleeNet[13],改進(jìn)原始SSD目標(biāo)檢測(cè)算法。在保證提取豐富特征的前提下降低計(jì)算成本,滿足實(shí)時(shí)性要求。針對(duì)實(shí)際工程項(xiàng)目采集的數(shù)據(jù)集進(jìn)行目標(biāo)尺寸分析,設(shè)計(jì)合理的區(qū)域候選框大小及長(zhǎng)寬比例,提高車輛目標(biāo)的檢測(cè)準(zhǔn)確率。
2? ?SSD算法(SSD algorithm)
2.1? ?SSD模型結(jié)構(gòu)
SSD目標(biāo)檢測(cè)算法的主干網(wǎng)絡(luò)結(jié)構(gòu)為VGG16,在VGG16的基礎(chǔ)上新增加了不同卷積層來(lái)獲得多尺度特征圖,最終利用這些特征圖進(jìn)行多尺度的目標(biāo)檢測(cè)。SSD網(wǎng)絡(luò)結(jié)構(gòu)如圖1所示,輸入端是一張高為300,寬為300,通道數(shù)為R、G、B的彩色圖像;接著將兩個(gè)全連接層fc6、fc7分別替換為卷積層Conv6、Conv7;然后再添加四個(gè)卷積層。整個(gè)網(wǎng)絡(luò)共獲得六個(gè)不同尺度的特征圖:Conv4_3、Conv7、Conv8_2、Conv9_2、Conv10_2、Conv11_2。不同尺度的特征圖所對(duì)應(yīng)的感受不一樣,各特征圖設(shè)置先驗(yàn)框的數(shù)量也不一樣,針對(duì)這六個(gè)特征層分別用兩個(gè)并列的卷積核進(jìn)行卷積,一個(gè)用來(lái)預(yù)測(cè)邊框,另一個(gè)用來(lái)獲得不同類別的置信度。最終的檢測(cè)結(jié)果由非極大值抑制算法NMS(Non-Maximum Suppression)輸出。
2.2? ?SSD候選框
SSD采用多尺度特征圖預(yù)測(cè)的方法,就是借鑒Faster R-CNN中的anchor的理念,在特征圖的feature map cell上設(shè)置不同尺寸和不同長(zhǎng)寬比的候選框。每個(gè)特征圖上的候選框按以下公式計(jì)算:
式中,代表第個(gè)特征圖默認(rèn)框大小相對(duì)于網(wǎng)絡(luò)輸入的比例,是一個(gè)歸一化的值。代表最小的比例,代表最大的比例。代表個(gè)特征圖中的第個(gè),其中為特征圖的個(gè)數(shù)。
默認(rèn)框在不同的特征層有不同的尺寸,而且在同一個(gè)特征層又有不同的寬高比。共有五種不同的寬高比。寬高的計(jì)算公式如下:
式(2)、式(3)中、分別表示候選框的寬、高。若寬高比為1時(shí),候選框另增加一個(gè)。用于檢測(cè)的特征圖上默認(rèn)有六個(gè)候選框,但實(shí)際上Conv4_3、Conv10_2和Conv11_2層僅設(shè)置了四個(gè)候選框,它們均舍棄了3:1、1:3的候選框。SSD各預(yù)測(cè)層的候選框大小詳見(jiàn)表1。從統(tǒng)計(jì)數(shù)據(jù)可看出,高層特征圖的尺寸越來(lái)越小,候選框的大小逐漸增大。所以底層特征圖主要用來(lái)檢測(cè)小目標(biāo),高層特征圖被用來(lái)檢測(cè)大目標(biāo)。
3? 基于PeleeNet的改進(jìn)SSD模型(Improved SSD model based on PeleeNet)
原始的SSD框架主要分為三部分:主干網(wǎng)絡(luò)、檢測(cè)網(wǎng)絡(luò)、分類網(wǎng)絡(luò)。主干網(wǎng)絡(luò)主要用來(lái)提取特征,幾種常見(jiàn)的特征提取網(wǎng)絡(luò)包括ResNet、GoogleNet、VGGNet、Inception-Net,各種改進(jìn)主干網(wǎng)絡(luò)的SSD模型由此產(chǎn)生。以VGGNet為主干結(jié)構(gòu)的SSD模型,在進(jìn)行目標(biāo)檢測(cè)時(shí)的幀率難以滿足ADAS功能的實(shí)時(shí)應(yīng)用需求。為實(shí)現(xiàn)在移動(dòng)端的目標(biāo)檢測(cè),檢測(cè)精度和檢測(cè)準(zhǔn)確率需要同時(shí)兼顧,因此特征提取網(wǎng)絡(luò)結(jié)構(gòu)不能太復(fù)雜,參數(shù)量不能太大。本文在原始SSD框架的基礎(chǔ)上,將特征提取網(wǎng)絡(luò)VGGNet替換為輕量化的網(wǎng)絡(luò)PeleeNet,顯著減少了網(wǎng)絡(luò)參數(shù);同時(shí)PeleeNet采用了卷積、批歸一化、激活函數(shù)的順序組合,而不是卷積、激活函數(shù)、批歸一化的組合,這樣可以將批歸一化和卷積進(jìn)行合并運(yùn)算,進(jìn)一步提高檢測(cè)速度。依然采用SSD模型的多尺度預(yù)測(cè)方法,并在此基礎(chǔ)上提出一種多尺度特征融合模塊(Feature Fusion Module, FFM)與特征增強(qiáng)模塊(Feature Enhance Module, FEM),以提高底層特征圖的語(yǔ)義信息,進(jìn)一步提高對(duì)小目標(biāo)的檢測(cè)率。
PeleeNet-SSD算法的模型結(jié)構(gòu)如圖2所示。模型的整體結(jié)構(gòu)分為兩個(gè)部分:一部分是在前端的PeleeNet網(wǎng)絡(luò),主要用于提取目標(biāo)特征;另一部分是位于后端的檢測(cè)網(wǎng)絡(luò),主要作用是對(duì)前面產(chǎn)生的特征層進(jìn)行目標(biāo)的類別分類和位置回歸,最后通過(guò)非極大值抑制算法輸出目標(biāo)框。
3.1? ?特征融合模塊與特征增強(qiáng)模塊
3.1.1? ?特征融合模塊
本文設(shè)計(jì)了多尺度特征融合模塊(FFM),如圖3所示。將含有不同語(yǔ)義信息的特征圖進(jìn)行融合產(chǎn)生新的特征圖,并用其進(jìn)行后面的預(yù)測(cè)階段。
為了同時(shí)擁有底層特征圖的語(yǔ)義信息與高層特征圖抽象的語(yǔ)義信息,本文采用了3×3的卷積尺度以擴(kuò)大感受野,并在其后面增加1×1尺度的卷積以增強(qiáng)非線性特性。其中第三個(gè)分支(branch3)是下一尺度的特征圖進(jìn)行反卷積操作,使其和上一尺度擁有相同的寬高和通道數(shù)。最后通過(guò)Concatenate操作將二者合并產(chǎn)生融合后的特征圖,用其進(jìn)行目標(biāo)預(yù)測(cè)可以很好地檢測(cè)出小尺度目標(biāo)。
3.1.2? ?特征增強(qiáng)模塊
SSD算法利用底層特征圖進(jìn)行小目標(biāo)的檢測(cè),然而底層特征圖的語(yǔ)義信息相對(duì)較少,導(dǎo)致檢測(cè)效果一般。本文針對(duì)底層特征圖語(yǔ)義信息不強(qiáng)的特點(diǎn),設(shè)計(jì)了底層特征增強(qiáng)模塊,如圖4所示。通過(guò)兩組類似的卷積組來(lái)加深淺層特征圖,同時(shí)在每組后面都有1×1尺度的卷積,用來(lái)增大感受野和非線性特性。同時(shí)本結(jié)構(gòu)采用的是S×1和1×S的卷積層而不是直接采用S×S的卷積層,從而可以減少計(jì)算時(shí)間成本。
3.2? ?候選框的設(shè)計(jì)
特征提取的好壞決定了目標(biāo)檢測(cè)算法的性能,而有效地特征提取取決于訓(xùn)練數(shù)據(jù)。標(biāo)準(zhǔn)的SSD目標(biāo)檢測(cè)算法中的訓(xùn)練數(shù)據(jù)就是候選框區(qū)域。為了保證對(duì)不同大小和不同縱橫比的目標(biāo)進(jìn)行預(yù)測(cè),SSD算法在不同的特征圖上設(shè)置了不同的候選框。當(dāng)候選框與真實(shí)框的重疊度大于0.5時(shí),被認(rèn)定為正樣本;反之,為負(fù)樣本。候選框的大小和縱橫比應(yīng)該根據(jù)真實(shí)的數(shù)據(jù)集進(jìn)行設(shè)置,這樣可以獲得較高的匹配度,同時(shí)也可以減少背景無(wú)效區(qū)域?qū)τ谔卣魈崛〉挠绊憽6耶?dāng)候選框與真實(shí)框越相近,坐標(biāo)框的回歸也就越容易,如果差異較大,就需要復(fù)雜的非線性模型進(jìn)行求解。本文所采集的數(shù)據(jù)分布如圖5所示,圖中的彩色直線表示SSD原始的默認(rèn)框比例,彩色正方形表示各預(yù)測(cè)層。從圖5可知,原候選框長(zhǎng)寬比與數(shù)據(jù)集分布偏差過(guò)大,因此需要根據(jù)實(shí)際采集的車輛數(shù)據(jù)集設(shè)計(jì)合理的候選框尺度和比例。
由車輛尺寸分布圖可知,大部分?jǐn)?shù)據(jù)集的長(zhǎng)寬比介于1至3。因此,可以去掉比例為1/3的默認(rèn)框,同時(shí)在后三個(gè)預(yù)測(cè)層加入3/2的長(zhǎng)寬比默認(rèn)框。這樣可以提高模型的采樣率,而且能降低計(jì)算量。改進(jìn)后的候選框尺寸分布如圖6所示。
4? ?實(shí)驗(yàn)分析(Experimental analysis)
4.1? ?數(shù)據(jù)集制作及訓(xùn)練過(guò)程
本文所采用的數(shù)據(jù)集,來(lái)自中國(guó)某城市道路交通的行駛車輛數(shù)據(jù)。通過(guò)搭建單目相機(jī)采集系統(tǒng),獲取各個(gè)路段的視頻數(shù)據(jù),通過(guò)對(duì)視頻數(shù)據(jù)的剪切處理最終獲得訓(xùn)練圖片。使用LabelImg圖像標(biāo)注工具,對(duì)圖片中的車輛進(jìn)行人工標(biāo)注,同時(shí)生成與之對(duì)應(yīng)的xml文檔,如圖7所示。本數(shù)據(jù)集包含10 000張圖片用于訓(xùn)練和驗(yàn)證,2 000張圖片用于測(cè)試,數(shù)據(jù)樣本標(biāo)簽為汽車(Car)、卡車(Truck)、公交車(Bus)、工程車(Shop truck)。數(shù)據(jù)集中包含街道、環(huán)線、高速等路段的交通狀況。為了進(jìn)一步增強(qiáng)數(shù)據(jù),本文對(duì)訓(xùn)練圖片進(jìn)行隨機(jī)縮放、水平旋轉(zhuǎn),隨機(jī)改變圖片的色調(diào)、飽和度及鏡像處理。
本實(shí)驗(yàn)所采用的深度學(xué)習(xí)框架為caffe,GPU型號(hào)為RTX 2080 TI。本文首先在KITTI數(shù)據(jù)集上對(duì)改進(jìn)的車輛檢測(cè)算法進(jìn)行20輪的迭代,獲取預(yù)訓(xùn)練權(quán)重參數(shù)。并在此基礎(chǔ)上對(duì)改進(jìn)的目標(biāo)檢測(cè)算法進(jìn)行微調(diào)訓(xùn)練,訓(xùn)練時(shí)采用的優(yōu)化方法為隨機(jī)梯度下降算法(SGD),初始學(xué)習(xí)率為0.01,學(xué)習(xí)策略采用multistep,gamma為0.5。當(dāng)?shù)螖?shù)為50 000次時(shí)更新一次學(xué)習(xí)率,其中momentum為0.9,權(quán)重衰減為0.000 5,訓(xùn)練的batch size設(shè)為32,共迭代200 000次。訓(xùn)練過(guò)程中的loss值如圖8所示。
4.2? ?評(píng)價(jià)方法
本文采用的主要評(píng)價(jià)指標(biāo)是平均準(zhǔn)確率均值mAP,其是目標(biāo)檢測(cè)算法中衡量精確度的指標(biāo)。mAP的計(jì)算與準(zhǔn)確率(Precision)、召回率(Recall)相關(guān)。準(zhǔn)確率表示預(yù)測(cè)為正的樣本中的正樣本所占的比例;召回率表示正樣本中被正確預(yù)測(cè)所占的比例。P-R曲線全面評(píng)價(jià)了檢測(cè)器的精度性能,該指標(biāo)為平均準(zhǔn)確率(Average Precision,AP)。計(jì)算公式如下:
式中,表示被正確檢測(cè)的數(shù)量,表示被誤檢的數(shù)量,表示漏檢的數(shù)量,表示樣本點(diǎn)數(shù)量,表示需要檢測(cè)的類別數(shù)量。
4.3? ?實(shí)驗(yàn)結(jié)果與分析
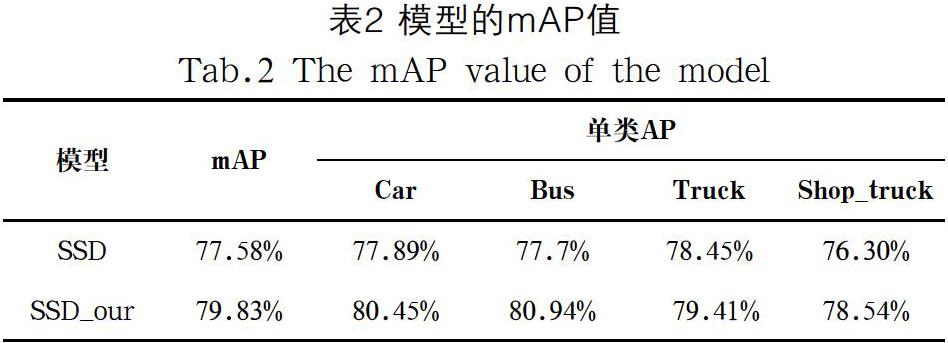
本文將標(biāo)準(zhǔn)SSD和改進(jìn)后的SSD_our網(wǎng)絡(luò)分別在所采集的數(shù)據(jù)集上進(jìn)行訓(xùn)練與測(cè)試,模型的檢測(cè)性能詳見(jiàn)表2。改進(jìn)后檢測(cè)模型的mAP為79.83%,且模型大小僅為原始模型大小的1/5。
實(shí)際道路視頻測(cè)試效果如圖9所示。改進(jìn)后的SSD對(duì)高速行駛的小型汽車檢測(cè)的準(zhǔn)確率更高,這是因?yàn)樘卣魈崛【W(wǎng)絡(luò)擁有更少的網(wǎng)絡(luò)參數(shù),提高了計(jì)算速度。同時(shí)在分析數(shù)據(jù)尺度的基礎(chǔ)上,在預(yù)測(cè)層上設(shè)置了合理的長(zhǎng)寬比的默認(rèn)框,進(jìn)一步降低了噪聲的影響以及提升了特征提取的效果。
5? ?結(jié)論(Conclusion)
本文針對(duì)車輛目標(biāo)檢測(cè)實(shí)時(shí)性低、準(zhǔn)確率低、魯棒性差等問(wèn)題,在SSD目標(biāo)檢測(cè)算法的基礎(chǔ)上,采用特征學(xué)習(xí)能力更強(qiáng)的peleeNet網(wǎng)絡(luò)進(jìn)行主干網(wǎng)絡(luò)的替換。由于輕量化的peleeNet網(wǎng)絡(luò)結(jié)構(gòu)設(shè)計(jì),使得模型參數(shù)更少,滿足實(shí)時(shí)性要求。并且,重新設(shè)計(jì)了SSD候選框,使其更加符合真實(shí)的目標(biāo)框,提高了訓(xùn)練過(guò)程中正樣本的采樣率。實(shí)驗(yàn)結(jié)果表明,本文改進(jìn)后的目標(biāo)檢測(cè)算法的準(zhǔn)確率達(dá)到了79.83%,與標(biāo)準(zhǔn)SSD相比提高了2.25%。本文的方法在檢測(cè)速度和檢測(cè)精度方面有所提高,后續(xù)研究工作將在豐富的數(shù)據(jù)集上進(jìn)行實(shí)驗(yàn),進(jìn)一步提高模型的泛化能力。
參考文獻(xiàn)(References)
[1] Reynolds C W. Flocks, Herds, and Schools: A Distributed Behavioral Model[J]. ACM SIGGRAPH Computer Graphics, 1987, 21(4):25-34.
[2] Dalal N, Triggs B. Histograms of Oriented Gradients for Human Detection[C]. IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2005), 2005:886-893.
[3] Viola P, Jones M. Robust Real-time Object Detection[J]. International Journal of Computer Vision, 2001(57) :137-154.
[4] Burges C J C. A Tutorial on Support Vector Machines for Pattern Recognition[J]. Data Mining and Knowledge Discovery, 1998, 2(2):121-167.
[5] Girshick R, Donahue J, Darrell T, et al. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation[C]. The IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2014), 2014:580-587.
[6] Girshick R. Fast R-CNN[C]. The IEEE International Conference on Computer Vision (ICCV 2015), 2015:1440-1448.
[7] Ren S, He K, Girshick R, et al. Faster R-CNN: Towards Real-Time object Detection with Region Proposal Networks[C]. 29th Neural Information Processing Systems (NIPS 2015), 2015:91-99.
[8] Dai J, Li Y, He K, et al. R-FCN: Object detection via region-based fully convolution networks[C]. 30th Conference on Neural Information Processing Systems (NIPS 2016), 2016:379-387.
[9] 王宇寧,龐智恒,袁德明.基于YOLO算法的車輛實(shí)時(shí)檢測(cè)[J].武漢理工大學(xué)學(xué)報(bào),2016,38(010):41-46.
[10] 吳水清,王宇,師巖.基于SSD的車輛目標(biāo)檢測(cè)[J].計(jì)算機(jī)與現(xiàn)代化,2019(05):39-44.
[11] Lin T Y, Goyal P, Girshick R, et al. Focal Loss for Dense Object Detection[C]. The IEEE International Conference on Computer Vision (ICCV 2017), 2017:2980-2988.
[12] Huang G, Liu Z, Maaten L V D, et al. Densely Connected Convolutional Networks[C]. The IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), 2017:4700-4708.
[13] Wang R J, Li X, Ling C X. Pelee: A Real-Time Object Detection System on Mobile Devices[C]. The IEEE Conference on Neural Information Processing Systems (NIPS 2018), 2018:1963-1972.
作者簡(jiǎn)介:
黃生鵬(1993-),男,碩士生.研究領(lǐng)域:圖像處理.
范平清(1980-),女,博士,副教授.研究領(lǐng)域:系統(tǒng)動(dòng)力學(xué),機(jī)器視覺(jué),壓電驅(qū)動(dòng).本文通訊作者.
猜你喜歡
艦船科學(xué)技術(shù)(2022年15期)2022-09-14 09:21:50
電子制作(2019年15期)2019-08-27 01:12:00
電子制作(2018年19期)2018-11-14 02:37:08
自動(dòng)化學(xué)報(bào)(2017年7期)2017-04-18 13:41:09
自動(dòng)化學(xué)報(bào)(2017年11期)2017-04-04 02:52:58
中國(guó)生物醫(yī)學(xué)工程學(xué)報(bào)(2017年6期)2017-02-10 05:11:45
廣西科技大學(xué)學(xué)報(bào)(2016年1期)2016-06-22 13:10:38
計(jì)算機(jī)工程(2015年4期)2015-07-05 08:28:02
機(jī)電信息(2015年3期)2015-02-27 15:54:46
機(jī)械工程師(2015年10期)2015-02-02 01:13:49
