基于稀疏注意力機制的城軌車輛軸溫預(yù)測模型*
2021-02-27 09:14:40張恒志蔣雨良
科技與創(chuàng)新 2021年3期
關(guān)鍵詞:模型
張恒志,蔣雨良
(1.中車青島四方機車車輛股份有限公司,山東 青島266109;2.西南交通大學(xué)機械工程學(xué)院,四川 成都610031)
1 引言
時間序列是各領(lǐng)域內(nèi)都十分常見的數(shù)據(jù)形式,考慮到趨勢、狀態(tài)預(yù)測的重要意義,針對時間序列的預(yù)測、異常檢測已有不同程度的發(fā)展[1]。軸承是軌道車輛重要的旋轉(zhuǎn)部件,隨著列車在交路中運行,安裝在車輛走行部上的各個軸承的溫度傳感器所采集溫度呈現(xiàn)因各項激勵而產(chǎn)生的不同變化[2]。異常的軸承溫升表征軸承運行狀態(tài)異常,監(jiān)測分析軸承溫度及相關(guān)數(shù)據(jù)能有效檢測軸承異常,幫助找出溫升相關(guān)因素,診斷軸承異常。基于軸承溫度的時間序列變化趨勢進(jìn)行建模,盡可能地提前對軸承進(jìn)行預(yù)警,提前診斷軸承是否故障,預(yù)防重大安全事故對列車運行安全具有重要意義[3]。
傳統(tǒng)機器學(xué)習(xí)方法,如逐步線性回歸[4]、支持向量機[5]等方法在列車履歷數(shù)據(jù)上的應(yīng)用具有良好的預(yù)測結(jié)果。深度學(xué)習(xí)由于其優(yōu)秀的特征學(xué)習(xí)能力,在軸溫預(yù)測領(lǐng)域引起了越來越多的關(guān)注。針對時間序列的預(yù)測模型也在逐步發(fā)展,從初始的循環(huán)神經(jīng)網(wǎng)絡(luò)[6-7](Recurrent Neural Networks,RNN)到使用雙向、深度[8-9]的概念進(jìn)一步增加網(wǎng)絡(luò)的性能再到已在文本識別、時間序列預(yù)測方面普遍使用的長短時記憶[10](Long Short-Term Memory networks,LSTM)、門控循環(huán)單元[11](Gated Recurrent Unit networks,GRU)的提出,此類網(wǎng)絡(luò)的實質(zhì)上均是一個基于馬爾科夫決策過程的遞推框架。深度學(xué)習(xí)作為前沿的機器學(xué)習(xí)技術(shù),如運用LSTM 建立短時機車軸溫預(yù)測模型[12],能達(dá)到比傳統(tǒng)機器學(xué)習(xí)方法更優(yōu)的效果。
Google 所提出的Transformer 深度學(xué)習(xí)模型[13],拋棄了逐步遞推的方式,使用注意力機制作為基礎(chǔ),在機器翻譯領(lǐng)域能夠達(dá)到更優(yōu)效果。但單純的注意力機制計算復(fù)雜程度很高,這使得長序列模型中的顯存占用量和計算時間居高不下。
有鑒于此,本文提出基于稀疏注意力機制的城軌車輛軸溫預(yù)測模型。運用稀疏的特性改進(jìn)注意力機制,降低計算復(fù)雜度和顯存占用量,將診斷流程分為線下訓(xùn)練、在線預(yù)測和故障診斷三個步驟。首先訓(xùn)練一個軸承的模型,將該軸承的模型遷移到其他軸承上,再將改進(jìn)后的注意力網(wǎng)絡(luò)模型運用在城軌車輛上對軸承溫度進(jìn)行預(yù)測,該模型能夠在長時間序列輸入上達(dá)到更優(yōu)的精度,并能夠預(yù)測軸承的溫度變化。
2 模型和流程介紹
2.1 稀疏注意力機制
稀疏是結(jié)合了空洞(Atrous)和局部(Local)的概念。空洞源于空洞卷積(Atrous Convolution),對數(shù)據(jù)的相關(guān)性進(jìn)行了約束,要求在自注意力的相關(guān)性計算過程中,每個輸入元素只能和它的相對距離為d(設(shè)定值)倍數(shù)的元素關(guān)聯(lián);局部則是放棄了全局的關(guān)聯(lián),只和輸入元素前后距離為d的元素關(guān)聯(lián)。稀疏結(jié)合了兩者的概念,針對距離小于等于d的元素采用了局部注意力的方式,針對相對距離為不為1d,2d,…的元素,則將注意力置為0,因此,稀疏注意力能夠結(jié)合空洞和局部兩者的優(yōu)勢,既考慮了局部關(guān)聯(lián),又對全局關(guān)聯(lián)做出了改進(jìn),三種方式注意力對比如圖1 所示。
注意力的一般公式為:
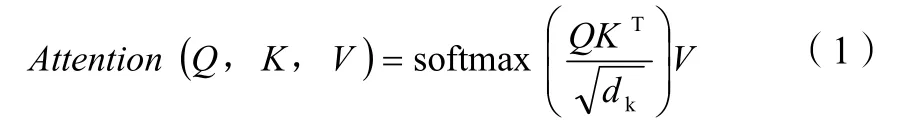

圖1 各類注意力對比
在軸溫預(yù)測模型中,輸入為時間序列,為了對未來時間進(jìn)行遮擋,不讓網(wǎng)絡(luò)使用未來的信息作為輸入預(yù)知未來,對注意力矩陣進(jìn)行處理,公式為:

在式(2)中,M表示對矩陣進(jìn)行Mask 掩碼編譯,將整個上三角陣元素置為-∞,軸溫預(yù)測模型中稀疏注意力的矩陣形式如圖2 所示,涂黑的方塊表示未來的信息,對角一列表示輸入數(shù)據(jù),白色的方塊表示注意力置為0。

圖2 稀疏注意力矩陣
2.2 模型微調(diào)
遷移學(xué)習(xí)是把已經(jīng)訓(xùn)練好的模型的參數(shù)遷移到新的數(shù)據(jù)來幫助新模型訓(xùn)練的學(xué)習(xí)方式。考慮到大部分的數(shù)據(jù)或任務(wù)是存在相關(guān)性的,所以通過遷移學(xué)習(xí)可以將已經(jīng)學(xué)習(xí)到的模型參數(shù)分享給新的模型,從而加快優(yōu)化模型的學(xué)習(xí)效率而不用從零開始。
fine-tune 是進(jìn)行遷移學(xué)習(xí)的一種手段。由于訓(xùn)練多個模型所消耗的時間太長、計算資源不足時,無法重頭開始訓(xùn)練一個效果良好的模型。于是通過遷移學(xué)習(xí),將一個網(wǎng)絡(luò)的前幾層參數(shù)保持不變,因為前幾層為主要提取特征。
因此,我們也可以把這幾層當(dāng)作特征提取器,保持原有的權(quán)重不變,提取現(xiàn)有的特征。考慮到軸承均處于車輛的走行部,包括齒輪箱、軸箱、電機等多個測點,承受相似的工況與激勵,將模型進(jìn)行遷移,可大程度縮短訓(xùn)練所需時間,因此建立完第一個模型后,固定前幾層權(quán)重,調(diào)小學(xué)習(xí)率和迭代次數(shù),只訓(xùn)練最后一層,逐個訓(xùn)練模型,完成對城軌車輛的軸溫預(yù)測。
2.3 軸溫預(yù)測流程構(gòu)建
預(yù)測流程的構(gòu)建包括線下訓(xùn)練、在線預(yù)測和故障診斷三個部分,基于稀疏注意力機制的軸溫預(yù)測模型能夠保持對長時間序列的注意力,因此本文所構(gòu)建的模型輸入為一個多維時間序列,輸出為未來一段時間內(nèi)的軸承溫度值,整個網(wǎng)絡(luò)結(jié)構(gòu)如圖3 所示。
輸入數(shù)據(jù)先經(jīng)過隱層進(jìn)行編碼,再輸入稀疏注意力進(jìn)行注意力分配,最后結(jié)合注意力輸出,再次編碼得到結(jié)果。網(wǎng)絡(luò)為回歸任務(wù),使用MAPE作為網(wǎng)絡(luò)的損失函數(shù),其公式為:
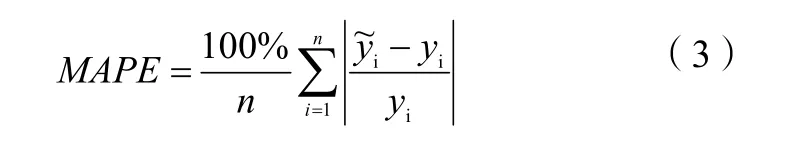
式(3)中:MAPE的取值為[0,+∞],如果值為0 表示模型為完美模型,值越大則表示精度越低;n為樣本數(shù)量;為預(yù)測值;yi為實際值。
圖4 為整個診斷流程,線下訓(xùn)練時,我們使用線下的數(shù)據(jù),先對數(shù)據(jù)進(jìn)行預(yù)處理,包括對缺失值進(jìn)行中位數(shù)填充、對跳變值進(jìn)行平滑處理以及將整個輸入進(jìn)行歸一化到[0,1]進(jìn)行無量綱處理三個部分。處理好的數(shù)據(jù)劃分成訓(xùn)練集和驗證集,按照網(wǎng)絡(luò)結(jié)構(gòu)要求輸入網(wǎng)絡(luò)進(jìn)行模型訓(xùn)練,完成對首個軸承的網(wǎng)絡(luò)訓(xùn)練后,降低學(xué)習(xí)率和迭代次數(shù),逐個遷移到其他軸承上,完成對城軌車輛所有軸承溫度測點的建模,并完成線下訓(xùn)練過程。
線下將網(wǎng)絡(luò)全部訓(xùn)練完成后,在線預(yù)測時會逐個使用網(wǎng)絡(luò),在線數(shù)據(jù)經(jīng)車載系統(tǒng)傳回后,對數(shù)據(jù)同樣進(jìn)行預(yù)處理,并運用網(wǎng)絡(luò)進(jìn)行預(yù)測,所預(yù)測的未來溫度結(jié)果會保存下來,并在未來的實際溫度值傳回后進(jìn)行對比。對于正常結(jié)果,會再次等待車載系統(tǒng)傳回數(shù)據(jù)進(jìn)行下一次對比;而異常結(jié)果會先定位到故障位置,要求車輛停車檢查,直至找到故障原因,排除故障才能繼續(xù)運行。
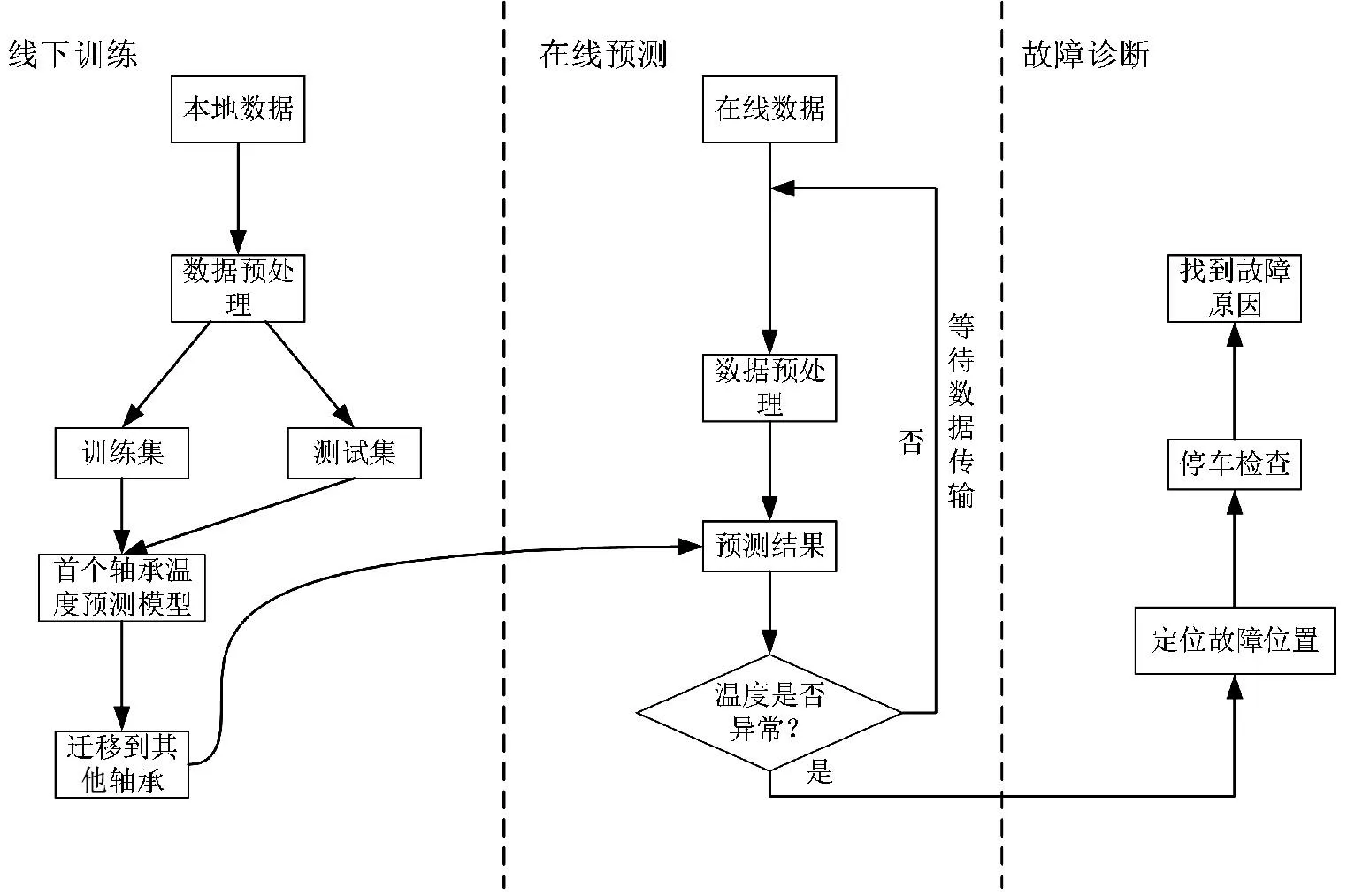
圖4 診斷流程
3 實例驗證
3.1 數(shù)據(jù)及超參數(shù)說明
采用某型城軌車輛的運行數(shù)據(jù)作為數(shù)據(jù)集。為了模擬實際運行環(huán)境以及線上線下交互的運用模式,先將數(shù)據(jù)進(jìn)行拆分,大部分?jǐn)?shù)據(jù)作為線下訓(xùn)練的本地數(shù)據(jù),進(jìn)行訓(xùn)練和驗證完成對網(wǎng)絡(luò)的構(gòu)建,一小部分?jǐn)?shù)據(jù)模擬在線預(yù)測的情況,以測試網(wǎng)絡(luò)模型的精度。車軸不同位置的溫度取決于許多因素,例如城軌車輛的物理狀態(tài)(包括行駛速度和牽引力水平)、路徑特性(包括高度和坡度)、環(huán)境溫度和其他環(huán)境參數(shù)以及來自各種來源的干擾。選擇其中的一些主要參數(shù),并從部署在機車不同位置的數(shù)據(jù)傳感器收集時間序列數(shù)據(jù)。
本文所選擇的數(shù)據(jù)特征包括城軌車輛的運行速度、環(huán)境溫度、各個軸上軸承測點溫度。如圖5 所示為各個數(shù)據(jù)特征的走勢。

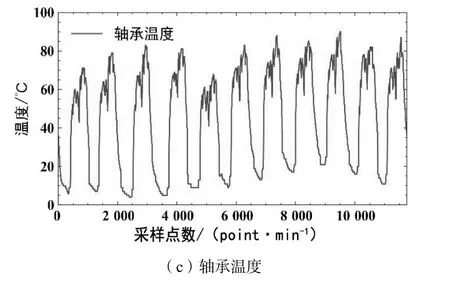
圖5 城軌車輛數(shù)據(jù)集
本文設(shè)置學(xué)習(xí)率為0.001,遷移學(xué)習(xí)率為0.000 1,使用Adam 優(yōu)化器進(jìn)行優(yōu)化,迭代次數(shù)為1 000 次,遷移迭代次數(shù)為500 次,batch-size 為64,設(shè)置輸入長度為300,輸出長度為30,稀疏注意力設(shè)定值d為5,所有實驗配置環(huán)境為Tensorflow 1.10.0、Keras 2.2.0 以及Python 3.6.2 進(jìn)行實驗,使用操作系統(tǒng)Windows10、CPU Intel 7-8550U@1.80GHz、GPU NVIDIA GeForce GTX 1050、內(nèi)存16G DDR4 的計算平臺進(jìn)行建模。
3.2 驗證結(jié)果
為了驗證稀疏注意力模型能夠處理更長的時間序列,設(shè)置3 組對比組,分別輸入輸出長度為100、200、300,并將RNN、LSTM 與稀疏注意力一同進(jìn)行對比,對比結(jié)果如圖6所示。
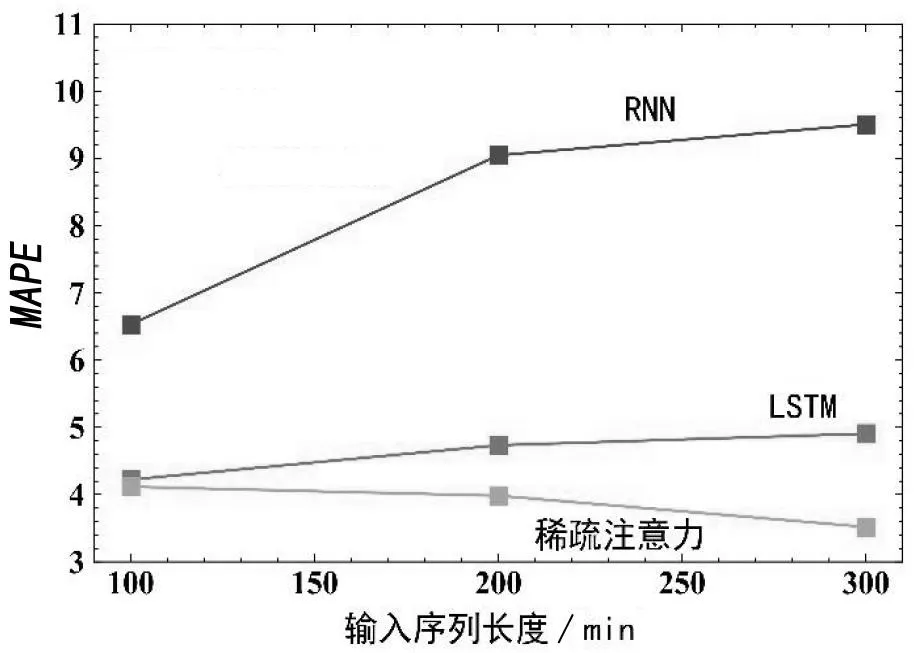
圖6 序列長度影響精度結(jié)果
對結(jié)果進(jìn)行分析:RNN 作為最初始的循環(huán)神經(jīng)網(wǎng)絡(luò),隨著序列長度逐漸增加,MAPE也逐漸增加,精度降低,說明隨著序列長度增加循環(huán)神經(jīng)網(wǎng)絡(luò)的記憶能力逐漸降低;LSTM 在RNN 網(wǎng)絡(luò)的基礎(chǔ)上引入了門機制,隨著序列長度的增加,LSTM 的記憶能力仍然會降低,但整體精度會高于RNN;稀疏注意力機制隨著序列長度的增加,能夠運用稀疏的特性記憶更長的序列,驗證結(jié)果表明,整個模型的精度在序列長度增加后得到進(jìn)一步提升。
按照3.1 所設(shè)定的超參數(shù),先對第一個軸承進(jìn)行建模后遷移到其他軸承上,以軸箱軸承作為初始建模對象,逐個遷移到齒輪箱、電機的軸承。
遷移的效果如表1 所示。
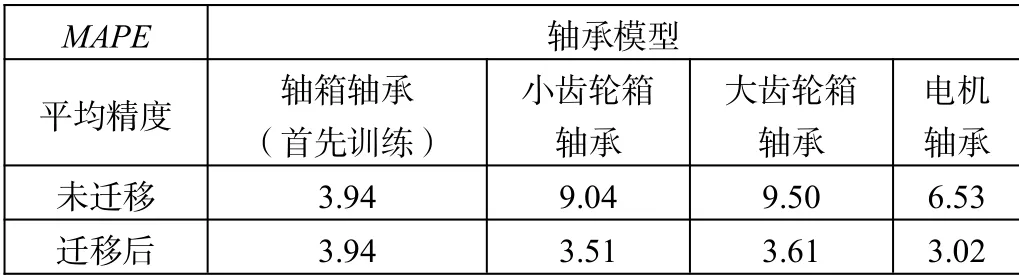
表1 遷移前后精度
將軸箱軸承作為首先選用的軸承進(jìn)行訓(xùn)練,訓(xùn)練后的模型先在未遷移的情況下對其他軸承進(jìn)行了測試,通過MAPE的評價指標(biāo)可以看到,每個軸承需對應(yīng)不同的模型,單個軸承的模型應(yīng)用到其他類型的軸承會使得精度降低。將模型按照設(shè)定的迭代次數(shù)和精度進(jìn)行了遷移,遷移后各個軸承均有各自的模型,因此模型數(shù)量增加,同時精度均得到了提升。圖7 展示的是稀疏注意力模型所預(yù)測的結(jié)果,本文所構(gòu)建的稀疏注意力機制模型能夠預(yù)測未來30 min 的溫度變化情況,具有能夠捕捉溫度變化的能力。
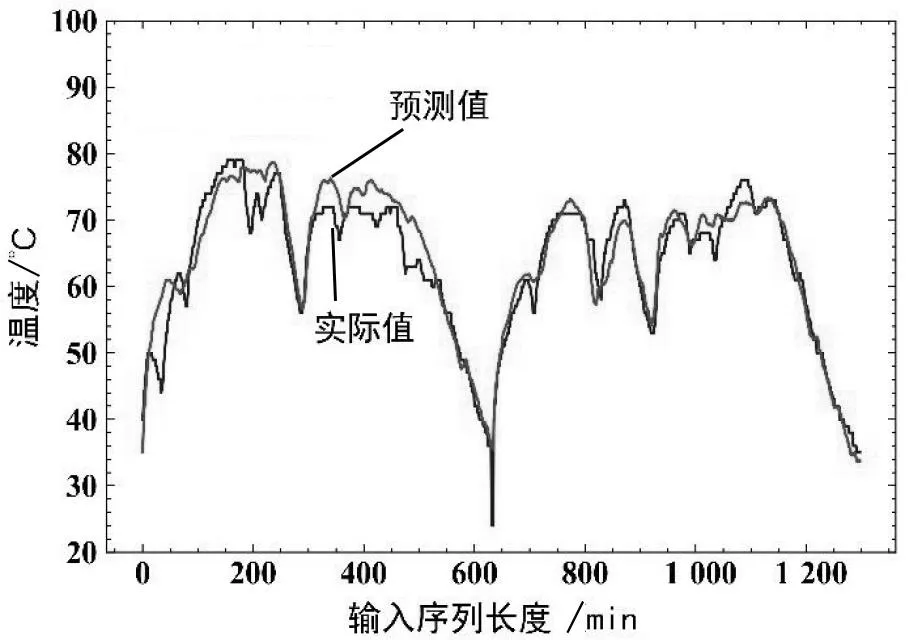
圖7 預(yù)測結(jié)果
4 結(jié)論
溫度預(yù)測可用于預(yù)測城軌車輛的軸承溫度,本文基于稀疏注意力機制模型,開發(fā)了城軌車輛的軸承溫度預(yù)測框架,預(yù)測結(jié)果表明該模型基于輸入的多維時間序列能夠捕獲車軸溫度,預(yù)測模型的有效性在城軌車輛的實際運行數(shù)據(jù)上得到驗證。在RNN、LSTM 上進(jìn)行序列長度的對比,驗證了稀疏注意力機制能夠運用稀疏的特性在長序列上捕捉到更多的信息并且不會出現(xiàn)記憶能力的降低。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導(dǎo)航定位學(xué)報(2022年4期)2022-08-15 08:27:00
中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀(jì)智能(數(shù)學(xué)備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學(xué)院學(xué)報(2021年2期)2021-07-19 08:35:14
新世紀(jì)智能(數(shù)學(xué)備考)(2020年9期)2021-01-04 00:25:14
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
