基于情感復寫的中文文本情感遷移方法
2021-02-27 08:53:34曾澤宇程芃森楊頻
現代計算機 2021年35期
曾澤宇,程芃森,楊頻
(四川大學網絡空間安全學院,成都 610065)
0 引言
文本情感遷移是自然語言處理領域中的一項新興技術,其目的是將文本中的情感屬性遷移到指定情感,并將文本的非情感內容予以保留。但由于語言表達的多樣性以及文本的離散性,文本情感遷移技術成為了一項具有挑戰性的任務[1]。
目前多數方法采用基于分離情感和內容的方法,主要包含兩個步驟:首先分離文本中情感和非情感內容,再將分離后的非情感內容與目標情感融合。在本文中,我們采用CycleGAN[2]結構來訓練基于Transformer[3]模型的生成器,實現了一步策略,即在無需分離內容和情感的條件下實現情感遷移任務,一定程度上改善了文本糾纏和隱式表達語句無法進行遷移的問題。我們的方法做出了以下貢獻:
(1)與多數傳統方法不同,我們的方法實現了一步策略,無需將情感和非情感內容分離,有效降低了遷移過程中的信息損失并達到較高的遷移準確率。實驗結果顯示,在遷移準確率和內容不變性上均有良好的效果。
(2)目前大多數情感遷移任務都是針對英文進行研究,但由于中文文本語義信息更加豐富,情感遷移任務更難實現,少有針對中文的研究。在本文中,我們在中文下進行實驗,并取得了較好的效果。
1 相關工作
在近些年,風格遷移任務在計算機視覺領域中得到廣泛研究,Gatys等[4]通過實驗證明CNN網絡能夠分別提取出圖像的內容特征和風格特征,從而提出了將任意原始圖像和目標風格相結合的方法。隨后,Zhu等[2]針對缺少平行數據的問題,基于生成對抗網絡從兩個具有不同風格且非平行的數據域中提取出風格特征,實現了在沒有平行數據條件下的風格遷移。受圖像領域風格遷移任務的啟發,近年自然語言處理領域誕生了針對文本的情感遷移任務,得到廣泛關注,并不斷有新方法提出,其中主流方法包括情感分離和情感復寫。
基于情感分離的方法是在文本情感遷移任務中廣泛使用的方法,Shen、Fu、Hu等人[5-7]均采取了該方法,通過對抗訓練的方式將文本內容從原句中分離,再將分離后的文本輸入到指定的情感解碼器中。此方法能夠達到一定的情感遷移準確性,但是在內容不變性上效果不理想。其主要原因在于缺乏平行語料,導致模型難以準確區分情感信息和非情感信息,從而造成了比較嚴重的文本屬性糾纏[8]問題。Xu等[9]假定文本情感屬性是通過特定的詞匯表達出來的,只要改變這些特定詞匯,就能夠直接改變整句文本的情感屬性,通過使用自注意力機制(self-attention)得到的注意力權重作為分類器特征,從而找出情感屬性詞并刪除,將其替換為期望的目標情感詞匯。Hu等人[8]提出的MaskAE模型,在上述刪除情感詞方法的基礎上,采用大型情感詞典來匹配原句中的情感詞,將匹配到的情感詞遮蔽后進行替換,但該方法不可避免的需要維護一個大型詞典,但通常構建和維護能夠全面覆蓋各種詞匯的詞典是一個比較困難的任務。
在基于情感復寫的方法中,Lample等[10]指出分離情感方法并非完善的解決方法,同時證明了分離情感的操作在文本情感遷移任務中并非必須。Luo等[11]基于強化學習的框架實現了無需內容和情感分離的遷移方法,需要訓練兩個序列模型來遷移情感,其中一個模型將原始文本作為遷移成目標情感文本,另一個模型則將目標情感文本遷移回原始文本,同時通過兩個獎勵函數來保證內容保留和情感遷移成功率。Dai等[12]提出Style Transformer模型,首次將Transformer模型應用到文本情感遷移任務上,避免了先前研究廣泛使用的RNN模型造成的長期依賴問題。
我們的方法采用了情感復寫的方法,基于CycleGAN網絡結構通過對抗來訓練來生成器和鑒別器,并通過Transformer模型的注意力機制來自動捕獲句子中的情感特征。
2 模型
在本文中,我們基于CycleGAN網絡結構來訓練生成器G,通過兩個鑒別器D1和D2來判斷兩種不同情感的文本,模型訓練過程如圖1所示。

圖1 模型訓練過程
2.1 CycleGAN
CycleGAN[6]中構建了兩個對稱的GAN,能夠實現兩個遷移方向的任務,解決了在缺少平行數據集的情況下,模型無法學習到從X(Y)屬性數據到目標Y(X)屬性數據的問題。CycleGAN通過對抗損失函數來訓練生成器G1學習映射X→Y,并使得鑒別器D1難以區分生成樣本y?∈G(X),生成器G2學習映射Y→X,同時G1和G2構成了一個循環結構,網絡通過循環一致性損失函數以確保內容不變性,即G2(G1()x)≈x。對于y∈Y的數據做同樣的處理。
在網絡中,通過構建多個損失函數來保證跨域遷移成功率和內容不變性,其中每個方向的情感遷移任務主要包含兩個損失函數,分別為對抗損失函數LGAN和循環一致性損失函數Lcycle。以屬性X→Y數據的情感遷移為例,LGAN的公式如下:

其中G1(x)表示屬性x∈X數據通過生成器G1遷移為具有Y屬性數據,鑒別器D1用于鑒別遷移樣本G1(x)和真實樣本y∈Y。
循環一致性損失函數計算數據x和x?的分布差異。為通過生成器G1進行情感遷移后再通過生成器G2遷移回原始情感的數據,即因此損失函數計算公式如下:
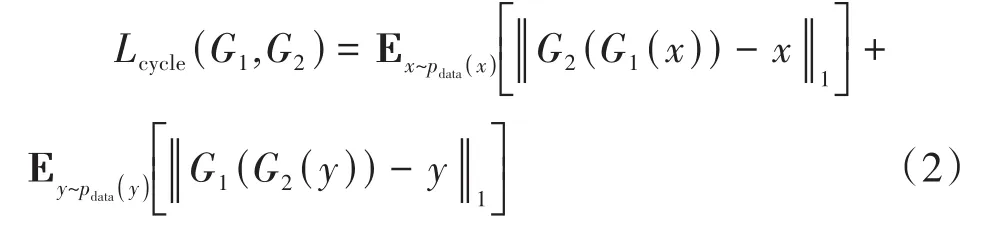
那么總的損失函數包括兩個對抗損失函數LGAN和循環一致性損失函數Lcycle,公式如下:
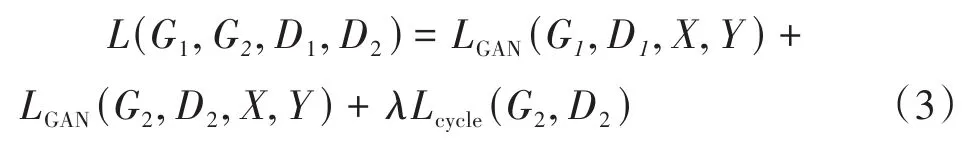
2.2 生成器
在我們的方法中,為了讓生成器更容易捕獲文本情感特征,生成器采用了Style Transformer[12]模型。Style Transformer模型上為了實現更好的實現情感遷移任務,相較傳統Transformer模型在嵌入層對輸入語句x=(x1,…,xn)進行嵌入的同時,還對輸入語句的情感s進行嵌入,即編碼器的輸入為(s,x),Style Transformer的公式如下:
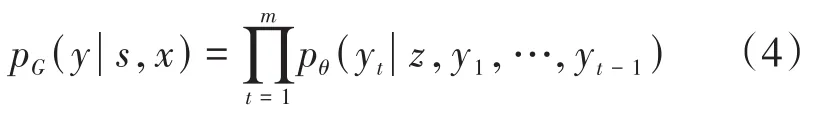
2.3 鑒別器
在本文中,由于是兩個數據域之間的情感遷移任務,即X→Y(Y→X),我們在每個情感遷移方向都設置了一個情感分類器,包含嵌入層和線性層。鑒別器D1輸入數據為生成數據?=G(s2,y),鑒別器D2輸入數據為生成數據?=G(s1,y),并分別對兩個方向的生成序列作出真假判斷,公式如下:

2.4 訓練方法
模型訓練過程包含兩個階段,第一階段為預訓練生成器G和鑒別器D,第二階段為對抗訓練生成器G和鑒別器D。
在第一階段訓練過程中,我們首先預訓練生成器G,使得生成器G能夠復寫兩個不同情感數據中的文本,即G(s1,x)≈x和G(s2,y)≈y,定義了損失函數Lself,通過最小化生成樣本G(s1,x)和真實樣本x∈X以及G(s2,y)和y∈Y的交叉熵來訓練生成器G,即采用了最大似然估計(maximum likelihood estimation)的方法[13],Lself公式如下:
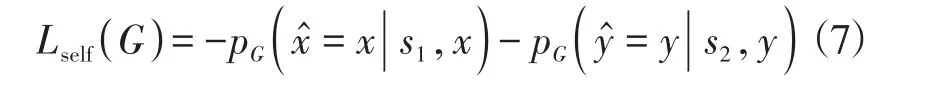
預訓練生成器G后,我們對鑒別器D1和D2進行預訓練,預訓練鑒別器是為了在對抗訓練的初始階段就能給予生成序列更準確的判斷,使得D1和D2能夠區分不同數據中的情感S1和S2。
在第二階段訓練中,通過對抗訓練來進行情感遷移任務的訓練,我們引入了三個損失函數,包括對抗損失函數LGAN1、LGAN2和循環一致性損失Lcycle,目的是為了提高情感遷移成功率和降低內容遷移損失。
其中對抗損失函數為了使生成器G能夠生成鑒別器D1評價為真的屬性數據y?=G(s2,x),同時能夠生成鑒別器D2評價為真的數據x?=G(s1,y)。LGAN1如下:
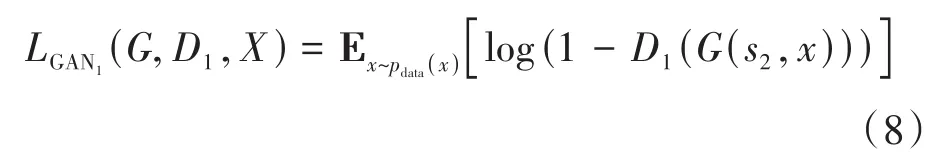
循環一致性損失函數用于保證遷移數據的內容不變,公式如下:
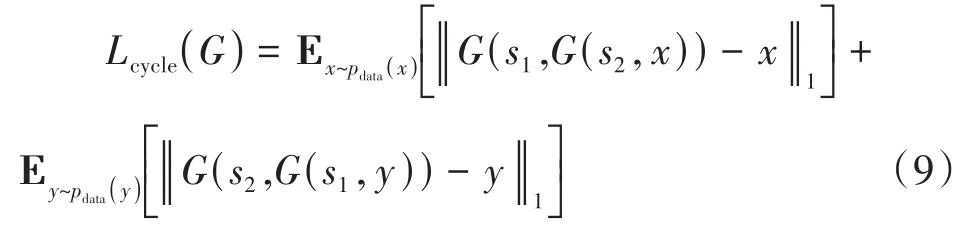
在鑒別器D1和D2的訓練過程中,為了鑒別器能夠區別真實樣本y∈Y(x∈X)和生成樣本y?(x?),同時使得生成器G生成更符合真實樣本分布的數據,引入了損失函數Ldis1和Ldis2,通過真實樣本和生成樣本并最小化損失函數值來訓練鑒別器。對于鑒別器D1,我們將真實數據y∈Y設定為真標簽數據(y,1),將生成數據設定為假標簽數據同理,對于鑒別器D2,我們將真實數據x∈X設定為真標簽數據(x,1),將生成數據設定為假標簽數據Ldis1公式如下:

3 實驗
3.1 數據集
中文數據集為網上收集數據,均來自電商平臺商品評論,總共282811條評論數據,其中包含積極和消極兩種情感傾向,積極情感傾向數據212966條,消極情感數據69845條,數據平均長度為13.3字,最長評論長度20字。為了驗證和測試模型,我們從中隨機提取了1600條評論作為驗證集,600條評論作為測試集。
3.2 實驗參數
在實驗中,生成器的編碼器和解碼器均為4層Transformer結構,每一層的多頭注意力機制中head數量設置為4,模型采用Adam動態優化算法,學習率為0.0001。我們使用了Stanford CoreNLP[14]進行中文分詞,Transformer隱藏層大小為300維;詞向量采用了預訓練的中文word2vec詞向量[15],維度300維;訓練批次大小為48。
3.3 實驗結果
由于當前缺乏針對中文的研究,且當前文本生成評價指標難以準確有效的評價中文生成文本的質量,所以在實驗中我們采取情感遷移成功率作為主要評價指標,遷移成功率通過分類器進行自動計算,分類器模型基于Fasttext模型[16]。實驗結果顯示,我們的模型在情感遷移任務上達到了82.3%的遷移成功率。
其中部分測試集樣本結果如表1所示,通過結果可以看出我們的模型在針對中文的實驗下總體能達到比較好的效果。

表1 測試樣本結果
從測試樣本中可以看出,在大多數情況下,如序號1、2、3、6、8等測試樣本中,模型能夠準確無損的實現情感遷移任務,保持了非情感內容不變并實現情感屬性的遷移。但在一些測試樣本中,模型也出現一定問題,比如在原句5的測試中,模型出現了遷移用詞不當的問題,模型將“實惠”復寫為“過時”,雖然實現了情感上的反轉,但是“過時”在此處形容不恰當。在序號4、7的測試樣本中,模型在生成語句時出現生成未能正確截止的問題,比如生成4的中,模型雖然成功實現了情感遷移,但是在句尾多生成了“好,”。通過在基于中文數據集的實驗結果顯示,我們的模型總體上達到良好的效果,在大多數情況下能夠良好地完成情感遷移任務。
4 結語
本文研究了針對中文非平行數據的文本情感遷移任務,與傳統需要將情感和內容分離的方法不同,采取了情感復寫的方法,在CycleGAN的基礎上來訓練模型,采用了改進的Transformer模型作為生成器,達成了一步策略。該方法自動提取不同數據之間的情感特征,通過對抗損失函數和循環一致性損失函數來分別保證情感遷移的準確性和內容不變性。通過中文數據集實驗結果顯示,該方法在情感遷移準確率上達到了較好的指標,在大多數場景下能夠準確有效地實現情感遷移任務。
猜你喜歡
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中國生殖健康(2018年5期)2018-11-06 07:15:40
Coco薇(2016年2期)2016-03-22 02:42:52
小學教學參考(2015年20期)2016-01-15 08:44:38
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
