基于聯邦學習的司機駕駛狀態識別
2021-02-27 08:53:22胡宇翔高琛譚北海
現代計算機 2021年35期
胡宇翔,高琛,譚北海
(1.廣東工業大學自動化學院,廣州 510006;2.廣州蔚馳科技有限公司,廣州 511455)
0 引言
隨著經濟的持續增長,運輸需求也在增長,交通行業正在迅速發展。交通行業憑借其獨特的優勢,幫助實現現代化和提高了人民的生活水平。但隨之出現的是頻繁發生的交通事故。
隨著世界各地的公路數量和汽車數量的急劇增加,交通事故發生的概率也在迅速增加,導致了許多的人員傷亡和經濟方面的損失。針對這些問題,需要采取相關有效措施減少交通事故的發生。根據相關數據顯示,事故頻繁發生的一個很重要的原因是駕駛員在駕駛過程中的疏忽[1]。為了減少交通事故的發生,汽車制造商引進了各種在保證汽車安全方面對生命安全起著重要作用的安全保護設備,隨著對汽車安全的重視,汽車安全將不可避免地成為研究領域的熱點。近年來,安全輔助駕駛的相關研究工作受到了世界各國的廣泛關注。目前,許多廠家致力于對車道偏離警告和保持車輛安全距離兩個方向的研究和探索。目前這兩個方面的技術有紅外探測、雷達探測、超聲波探測、激光探測、機器視覺探測等。統計數據顯示,如果可以在車禍發生前警告司機危險,許多交通事故就可以減少。因此,通過駕駛輔助系統,獲取司機駕駛狀態,并在駕駛員不注意時提供預警,是減少交通事故的有效措施。
2017年,谷歌首先引入了聯邦學習的概念。從分散的移動設備中訓練模型,之后通過服務器聚合這些本地模型更新共享模型,聯邦學習可以實現分散數據下模型的協同訓練,其中數量眾多的客戶端在中央服務器的協調下以協作的方式共同訓練模型,客戶端無需上傳或者進行數據交換,只需要向中央服務器傳輸本地訓練好的模型就可以了。這樣,本地客戶端始終都可以保有對本地私有數據的控制權,既可以減少收集數據、管理數據和保存數據的成本,又可以滿足越來越嚴格的數據隱私保護的要求。聯邦學習“數據不動,模型動”的特點在交通、金融、消費等領域都有著非常好的發展前景[2]。
本文針對駕駛識別和聯邦學習的特點,提出一種基于聯邦學習的司機駕駛狀態識別的方法,利用聯邦學習“數據不動,模型動”的特點,在保護車輛數據隱私的情況下,充分利用車載數據資源訓練出性能好的模型應用于實際交通場景幫助減少交通事故的發生。實驗以kaggle分心駕駛數據集作為實驗數據集,以VGG16作為模型特征提取網絡,運用基于迭代模型平均的聯邦學習算法協調服務器和客戶端模型訓練和聚合,結果證明該方法具有可行性,訓練出的模型性能良好。
1 相關工作
1.1 聯邦學習
作為連接數據孤島的橋梁,聯邦學習可以在滿足數據安全隱私及相關部門監管要求的前提下,使得各個用戶有效利用本地數據模型來獲得高質量的聯邦學習模型。可是隨著聯邦學習的不斷發展,其也暴露出許多問題,比如模型訓練存在的潛在攻擊、通信效率相對較慢、用戶數據可用性差、設備的不穩定性以及參與用戶處于不公平地位等。所以,聯邦學習需考慮隱私安全、通信效率、異構性以及公平性等因素,可以采用安全多方計算、模型壓縮、知識蒸餾、博弈論等技術,來構建一個更加安全、有效、公平的聯邦學習模型[3]。
1.2 駕駛狀態識別
近年來,國內外許多學者對駕駛行為狀態進行了深入研究,慢慢地已經從普通傳感器檢測發展到通過機器視覺算法對面部表情、生理參數、操作行為的檢測判斷。人體行為識別作為計算機視覺領域及深度學習理論的重要研究熱點,最具有代表性的是卷積神經網絡,其網絡結構有AlexNet、VGG、InceptionNet模型等,特征提取算法有主成分分析法、局部二值模式、方向梯度直方圖和尺度不變特征變換等,常見的分類器則有決策樹、支持向量機、softmax分類器等[4]。
2 基于聯邦學習的司機駕駛狀態識別方法
2.1 概述
本文建模的應用場景為:交通領域的AI部門根據實際需求,想研究出一種根據司機駕駛狀態提前預警危險的輔助駕駛系統,相關部門最終決定選擇結合聯邦學習和圖像分類網絡模型來實現該任務。AI部門工程師采用星形網絡拓撲結構部署聯邦學習算法中的服務器和客戶端,中心節點為服務器,邊緣節點是各客戶端,服務器和客戶端之間通行是雙向的,各個客戶端之間不進行通信[5]。其中,客戶端代表具有不同數據資源的各種行駛的車輛,服務器指的是云服務器。用于檢測司機駕駛狀態的圖像分類網絡模型被部署于各個客戶端,在服務器端設置聯邦學習模型參數的聚合算法以及通行輪換等。訓練的時候,首先在服務器進行全局模型的初始化,之后每輪通信中服務器首先會將本輪全局模型向各客戶端廣播,客戶端將接收的模型參數作為本輪局部模型訓練的初始參數并結合本地私有數據進行訓練,客戶端訓練完成后向服務器上傳局部模型參數進行模型參數更新。服務器接收到各客戶端的局部模型參數后進行新一輪的全局模型更新,依此循環,直到達到指定的通信輪換次數。本文假設服務器是具備安全性和可靠性,并且所有客戶端設備不存在受到惡意攻擊或者通信延時等帶來的問題[6]。本文算法示意圖如圖1所示,其中序號標明了訓練過程模型傳輸流程,其他客戶端依此類推。
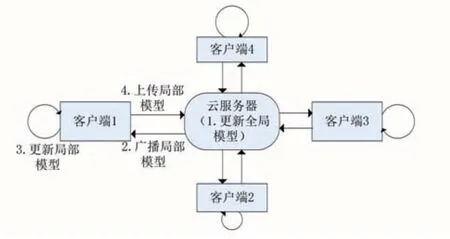
圖1 本文算法示意圖
2.2 基于迭代模型平均的聯邦學習
對于基于迭代模型平均的聯邦學習,我們假設有一個固定的K個客戶端集合,每個客戶端都有一個固定的本地數據集。在每一輪的開始,選擇客戶端的一個隨機比率C,服務器將當前的全局模型發送給每個客戶端。然后,每個選定范圍內的客戶端根據接收的全局模型及其本地數據集執行本地計算進行訓練,并向服務器發送本地訓練的局部模型用于全局模型的更新。然后服務器將這些來自客戶端的局部模型更新應用到其全局模型,然后重復此過程。
對機器學習的問題,我們通常采取fi(w)=l(xi,yi;w)來表述,也就是說,損失預測的例子(xi,yi)由模型參數w得出。我們假設有K個客戶數據分區,Pk代表集合中第K個用戶,nk= ||Pk代表第K個用戶數據集的個數,因此,我們可以將優化的目標函數寫為:
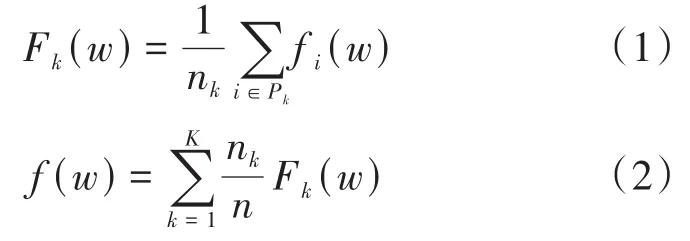
大量成功的深度學習應用幾乎完全依賴于隨機梯度下降(SGD)來進行優化,事實上,許多進步可以理解為調整模型的結構以及損失函數,使其更易于通過簡單的基于梯度的方法進行優化[7]。因此,本文聯邦學習的優化對象選擇SGD,確立了優化的目標后,整體的優化流程可表述為以下步驟。
假設有K個客戶端,以下標k作為標識,隨機選取的客戶端比率為C,B是本地客戶端的minibatchsize,E是本地客戶端訓練輪換次數,η是學習率。
●對于服務器端:
Step1:初始化初始全局模型參數w0
Step2:依通信輪換次數t=1,2,…循環執行以下步驟:

●對于客戶端:
Step1:依據minibatchsize大小B對本地用戶數據集Pk劃分,記為β
Step2:依據本地訓練輪換次數E循環執行更新:b∈β,w-η?l(w;b)
Step3:上傳w給服務器端
2.3 駕駛狀態識別模型
針對駕駛狀態識別任務特點,本文以VGG16為基礎進行修改來進行分類識別,VGG是由Si?monyan和Zisserman提出的卷積神經網絡模型,該模型參加2014年的ImageNet圖像分類與定位挑戰賽,取得了優異成績,VGG模型的主要特點是采用了很小的卷積核尺寸以及相對其他網絡更深的網絡結構,本文實驗以pytorch中預置的VGG16為基礎保留其特征層,將分類層置空并將其接到自定義的分類層,整體的駕駛狀態識別模型結構簡圖如圖2所示。
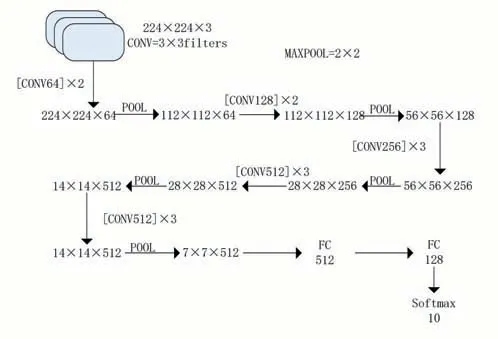
圖2 駕駛狀態識別模型結構簡圖
3 實驗與結果分析
3.1 數據集
本文以kaggle的state-farm-distracted-driverdetection數據集為實驗數據集,其中,test用于測試的,Train用于訓練的,Train文件夾下共有10個子文件夾,每個子文件夾下的圖片屬于同類,每類共有2000多張圖片,這10類及其含義如表1所示,分心駕駛數據集示例如圖3所示,Test文件夾下直接是圖片,接近8萬張,但是每個文件分別屬于哪類并不知道:

圖3 分心駕駛數據集示例

表1 kaggle分心駕駛數據集各分類含義
3.2 實驗細節
本實驗共設置10個客戶端模擬現實世界的10個車輛,從總數據中隨機分配數據到各個客戶端,以獨立同分布的方式呈現。數據集以8∶2的比例劃分為訓練集和測試集,對原始數據集進行隨機分配,分成10份作為各個客戶端的初始本地私有數據集,由于數據量有限,客戶端完成數據分配后,對數據進行數據增強操作,本文采用翻轉、平移、旋轉等數據增強方式對各客戶端數據進行擴充,客戶端的訓練輪換次數為3,批大小設置為10,初始學習率為η=0.001,采用學習率衰減策略,衰減因子為0.996,客戶端和服務器端的通信輪換次數為10,每輪通信包含3個主要過程:服務器廣播、客戶端局部更新、服務器聚合。客戶端與服務器均采用GTX 2080 Ti的GPU,CPU為3核Intel E5系列,運行內存為10 G,采用10 Gbit/s的以太網,操作系統為Ubuntu,Python版本為Python 3.7,深度學習框架采用Pytorch 1.3版本。
3.3 實驗結果
經過10輪通信循環,在云服務器端耗時4小時訓練得到如圖4和圖5的測試結果,從圖中比較可以看出經過5次通信輪換后準確率已經達到了99%以上,測試的loss也已經到0.5以下,隨后基本穩定在在一定數值,整體訓練得到了比較高的準確率。

圖4 測試準確率

圖5 測試損失loss
同時,對司機駕駛狀態的檢測識別,本文進行了另外兩個對比實驗,實驗情況如下:
(1)對比實驗1:基于MobilenetV2司機駕駛行為。
MobileNetV2作為對MobileNetV1的改進版,同樣也是一個輕量化的卷積神經網絡,MobileNet-V2的特點就是采用depth-wise sepa?rable convolution來減少運算量以及參數量,而在網絡結構上,借鑒Resnet采用shortcut的方式。實驗1與上文基于聯邦學習的司機駕駛狀態檢測方法采用同樣的軟硬件實驗環境,實驗的測試準確率和測試loss如圖6、圖7所示,測試準確率最終穩定在95%左右,測試的loss穩定在0.1左右。
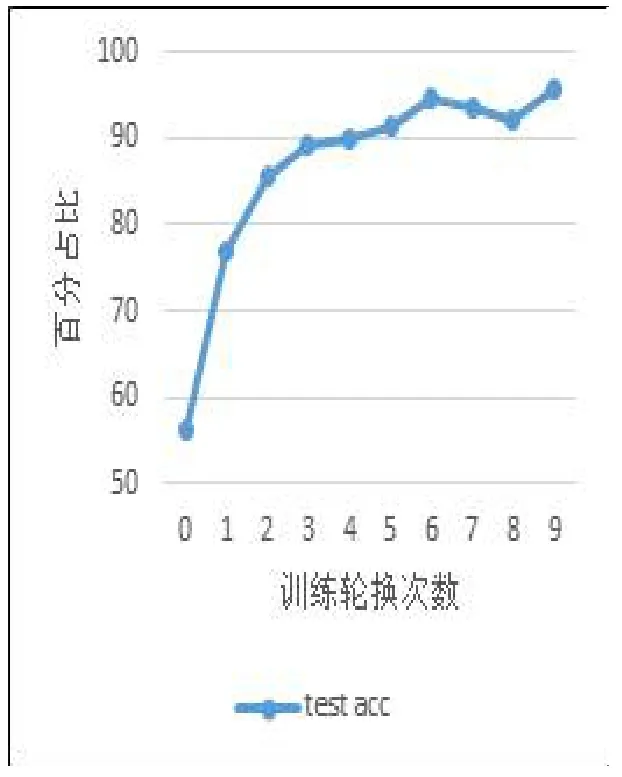
圖6 測試準確率
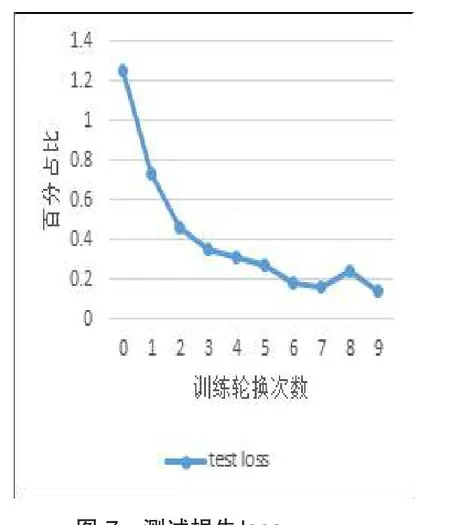
圖7 測試損失loss
(2)對比實驗2:基于VGG16司機駕駛行為檢測。
VGG16網絡作為卷積神經網絡中的一個經典網絡有著優秀的檢測性能,實驗二同樣采用與上文基于聯邦學習的司機駕駛狀態檢測方法采用同樣的軟硬件實驗環境,實驗的測試準確率和測試loss如圖8、圖9所示,測試準確率最終穩定在98%左右,測試的loss穩定在0.05左右。

圖8 測試準確率
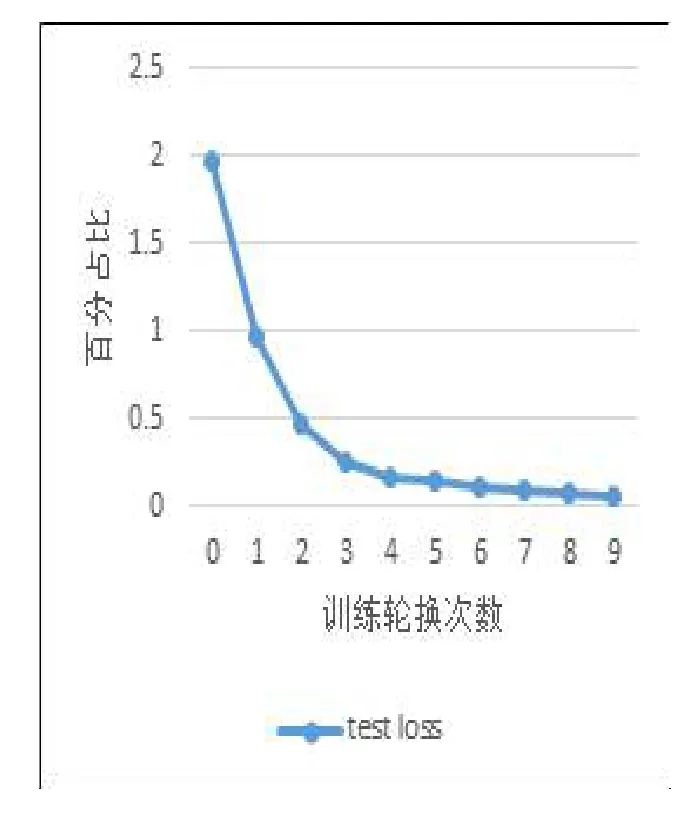
圖9 測試損失loss
綜合對比以上三個實驗可知,本文提出的基于聯邦學習加VGG16的司機駕駛狀態檢測訓練周期更短,訓練出的模型性能更加優異。
4 結語
本文將聯邦學習機制引入輔助駕駛識別場景中,部署單服務器-多客戶端結構用于模型訓練,讓多個車輛客戶端合作訓練完成司機駕駛狀態識別模型,各個客戶端始終保有著對本地私有數據的控制,不需要與其他用戶共享自己的私有數據,整套系統充分利用現有的車輛數據資源,這樣的方法可以幫助交通領域相關部門在節省數據收集管理等成本的同時又可以訓練出性能非常優異的模型用于輔助駕駛識別,減少交通事故的發生,并且這樣的方法可以在模型性能發生變化時很方便地更新模型。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
核科學與工程(2015年4期)2015-09-26 11:59:03
