基于云計算環境的非結構化大數據存儲系統開發
2021-02-25 09:17:30曹海平
通信電源技術 2021年17期
曹海平
(湖北國土資源職業學院,湖北 武漢 430090)
0 引 言
云計算實際上是一個大規模的分布式計算平臺,一方面能夠在單個計算機環境下運行,另一方面也可以依托于互聯網和許多計算機連接到一起,利用每個電腦的計算能力完成海量數據計算任務。在利用云計算進行海量數據信息處理時,其最大的問題點在于如何妥善安置大規模數據的存儲問題[1]。這是由于在進行海量數據計算的過程中,不同數據信息需要存儲到不同的硬件資源上,而當下已有的硬件資源難以達到海量數據的存儲要求,使得計算機需要反復進行尋址,浪費大量時間,不利于提高云計算效率與效果[2]。所以,設計一個可以滿足需求的大數據存儲系統,對進一步提高云計算應用效果有著非常大的幫助。本文提出了一種非結構化大數據存儲系統,從多個通道入手,完成基于云計算背景的非結構化大數據硬件與邏輯設計,有效解決了云計算環境下海量數據存儲問題,提高了云計算效率。
1 基于大數據的智慧教育應用模式探究
非結構化大數據擁有存儲形式多種多樣、數據格式繁多、業務流程多樣、數據標準化程度低以及信息數據量龐大等特征[3]。為了更好地實現對海量非結構化數據資源的存儲,依托于分層網絡結構,將云計算環境下非結構化大數據劃分為多個功能層,涵蓋有應用層、會話層、數據層、路由層和物理層。每個層有著各自具體的功能,應用層主要是為依托于云計算的非結構化大數據應用提供相應的接口;會話層在行使權限上表現更高的能力,擁有系統安全管控能力;數據層的主要功能是對依托于云計算的非結構化數據與元數據進行有效掌控;路由層的具體功能是確保相連設備交互穩定,同時實現路徑計算[4-6]。
1.1 基于云計算環境的非結構化大數據存儲系統開發框架
云計算屬于分布式計算范疇,依托于將互聯網中的不同計算節點視為資源地,實現對互聯網資源的分析與整合,同時基于相應的專業軟件完成對資源的管理。Hadoop是完成云計算必不可少的一部分,而在Hadoop中HBase又是極其關鍵的內容。
HBase屬于一種分布式、面向列的數據儲存系統,能夠實現對海量數據的隨時讀取與訪問[7]。HBase具備將表劃分為多個區域的功能,各個區域都涵蓋了表中所有行的一個子集,另外包含了一個主節點。以此節點為基礎,對初始安裝、給定服務區等相應區域進行引導,同時當區域服務產生問題時,能夠幫助其解決問題點,總的來說,主節點負載不重[8,9]。
依托于HBase的非結構化大數據存儲系統框架開發過程中,選擇分布式架構中包含的主從方式,一方面提高了數據庫的擴展能力,使得數據庫的應用范圍更加廣泛,另一方面也確保了數據的一致性,為提高數據應用質量奠定基礎。依托于HBase的基于云計算環境非結構化大數據儲存體系框架如圖1所示。
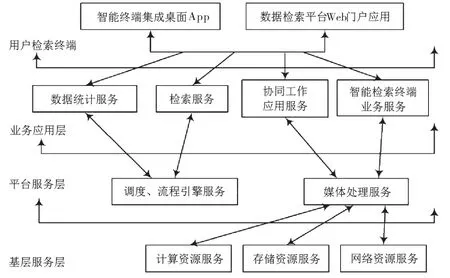
圖1 依托于HBase的云計算環境非結構化大數據存儲系統
基于云計算背景的非結構化大數據存儲系統依托于網絡收集與整合云計算環境下的大規模數據,然后利用后臺系統對非結構化大數據進行有效存儲。非結構化大數據儲存平臺如圖2所示。

圖2 非結構化大數據儲存平臺
1.2 基于云計算環境的非結構化大數據存儲算法開發
在實際進行云計算網絡環境中非結構化數據儲存架構探究過程中,按照依托于云計算的非結構化大數據調度模型以及存儲方式相似性較高的屬性,能夠獲取依托于云計算背景下的非結構化大數據儲存方式的二元域分布標準。假使利用k代表非結構化中眾多數據中大數據源的具體個數,有k+ε個節點,以此為載體獲得k+ε個非結構化大數據存儲個體,要求ε是一個大于零的常數[10-12]。為了簡化計算煩瑣度,便于觀察與核實,使用Yi代替k+ε個非結構化大數據存儲個體,其中i表示為1,2,3,…,k+ε,從而可以得到Yi的表達公式為:

式中,X1,X2,…,Xk是k個不同非結構化大數據源資源包,gi是一個行向量,該向量是獨立的,同時取值范圍處于二元域F2={0,1}之間。
依托于矩陣,k+ε個非結構化大數據存儲資源包可以表示為:

利用上面的計算方法,能夠實現對非結構化大數據存儲算法的開發,進而得到非結構化大數據存儲系統。
2 仿真實驗結果分析
為了更好地論證筆者開發的非結構化大數據存儲系統的可行性,針對該系統開展模擬實驗,以MATLAB R2018b為模擬平臺,使用Inter P4 2GB處理器作為實驗硬件,模擬非結構化大數據存儲情況。將本文開發的存儲方法與分布式云計算環境下的非結構化大數據存儲方法進行對比,得到各自的存儲性能,進而完成對比實驗。
兩種方法針對不同規模非結構化大數據開展存儲工作,得到對應的存儲時間,如表1所示。
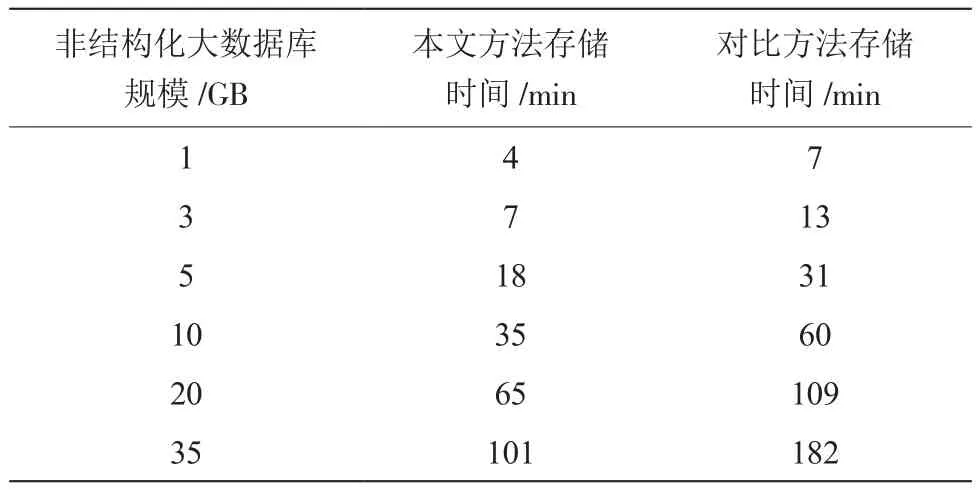
表1 兩種方法下同等非結構化大數據存儲時間對比
從表1中可以看出,不論非結構化大數據數據庫規模如何變化,使用本文開發的方法存儲時間均要低于分布式云計算環境下的非結構化大數據存儲方法,證明本文開發的非結構化大數據存儲系統切實可行。
3 結 論
在現代云計算應用越來越廣泛的背景下,云計算數據規模也逐步增大,人們逐漸意識到加強非結構化數據存儲的必要性,相比較于傳統非結構化數據存儲中系統煩瑣、應用成本高的問題,本文開發的存儲方法在保證數據完整性的基礎上還擁有較高的存儲速度,表現出良好的應用前景。
