基于Dirichlet多項式混合模型的復雜人體行為識別
2021-02-25 08:52:04蘇春芳傅立成李梃穎簡易緯
計算機應用與軟件 2021年2期
蘇春芳 傅立成 李梃穎 簡易緯
1(江陰職業技術學院 江蘇 江陰 214405)2(臺灣大學 臺灣 臺北 10617)
0 引 言
隨著人民生活水平的提高和醫療技術的高度發展,人的壽命得到了延長,同時也加劇了人口老齡化的步伐。中國國家統計局的統計數據顯示,在未來的一段時間內,老年人口比重將持續上升,人口老齡化程度將繼續加深。2018年末60歲及以上人口為24 949萬人,占總人口的17.9%,與2017年末數據相比,比重上升了0.6個百分點;65歲及以上人口為16 658萬人,所占比例為11.9%,比重上升0.5個百分點[1]。隨之而來的問題是如何給予老人合理、健康的照顧,因此在非臨床環境下具有行為辨識功能的輔助照顧系統成為當前研究的熱點。近年來主流的行為辯識技術主要分為兩大類,一類是基于圖像的行為識別技術,文獻[2]應用深度學習算法對圖像數據進行學習,建立一種基于深度學習算法的行為識別模型,該模型能夠識別12類行為,準確率達到81.8% ;文獻[3]通過提取視頻流的時空軌跡特征,提出一種分層的、用于識別復雜行為動作的模型。另一類是基于機器視覺的行為識別技術,它雖然可以對日常行為進行識別,但是為了保護使用者的隱私,一種非侵入式的、基于傳感器的行為識別技術應運而生。隨著IoT(Internet of Things)技術的進步,很容易收集到來自傳感器的日常行為數據,通過對來自可穿戴式設備的數據的分析,文獻[4]能夠對日常家務勞動中的行為進行識別,文獻[5]成功地對室內、室外9種日常行為進行識別。鑒于對使用者隱私的保護,基于可穿戴式設備的行為識別技術越來越受到人們的歡迎。目前采集的傳感器數據主要包括加速度、角速度等,表征的是身體特定部位(如腰、手腕、 腳踝、髖部)的運動特征,通過對這些數據進行特征抽取,對日常行為進行特征描述,進而達到對日常行為的識別。在上述研究中,一個不可忽視的問題是樣本集的質量,需關注樣本集能否準確地對日常生活中的行為動作進行描述。正是由于樣本集對復雜的日常行為的描述不夠充分,目前大部分的研究多集中在對簡單的日常行為(如坐、跑、走、躺)進行識別。對于復雜的日常行為的識別,文獻[6]通過將走路、打開藥瓶、打開水杯3種日常行為分解為抬起胳膊、手掌向上、走路等7個簡單的動作,進而將對復雜日常行為識別的問題轉化為對7種簡單日常行為的識別,沒有考慮到復雜日常行為自身的特性。相比于簡單的日常行為,復雜行為是由一系列的簡單行為組成的集合,會持續一定的時間,實際生活中絕大多數日常行為是復雜日常行為,因此對復雜行為動作的識別更能滿足日常照顧護理領域的需要,具有更廣泛的應用前景。對復雜行為的表征需要考慮到上下文之間的關系以及動作單元發生的時序性,目前對日常生活中較為復雜的日常行為的檢測存在準確率較低的問題。
對復雜行為識別的研究主要分為兩類:一類是不區分簡單行為動作和復雜行為動作,使用同樣的檢測模型[7];另一類認為復雜行為是由一系列簡單動作構成的,其中文獻[8]將復雜行為分解為若干簡單的日常行為,但是需要人為地對簡單行為動作進行類別標注。由于復雜的行為是一個動態變化的過程,即便是同一種行為在不同的地點、時間發生,動作序列也存在差異性,人為標注可能會忽略一些重要的、未知的動作單元。為了克服人工標注簡單行為類別的弊端,文獻[9]使用聚類算法對原始數據(加速度數據)進行聚類,但是由于使用的是一種有監督的聚類算法,需要事先指定聚類的個數。在實際生活中,由于復雜行為中包含的簡單行為動作的數量是事先未知的,k值的設定將影響聚類的效率。文獻[10-11]使用無監督的聚類算法,發現復雜行為的動作單元,然后將復雜的行為表征為一系列由簡單運動單元組成的集合,從而實現對復雜行為識別, 但是其忽略了動作單元,即高層語義特征在時域上的表現,進而影響行為識別的效率。高層語義特征即主題序列具有隱含的價值,文獻[12]將高層語義特征應用到人體行為識別中,文獻[13]通過挖掘具有時序特征的主題序列,成功建立臨床路徑模型。
考慮到上述因素,本文提出一種基于無監督的狄利克雷(Dirichlet)多項式混合模型的高層語義特征抽取方法,融合時序特征,對復雜行為進行高層語義描述、表征,構建高層語義特征數據集。在提取高層語義特征基礎上,應用滑動時間窗,建立文檔-詞矩陣(DTM),構建日常行為的文本集,從而提高對復雜行為的識別率,提高行為模型的泛化能力。
1 問題描述
從運動學角度來看,人們的日常行為都是由一系列有規律的身體的運動組成。為了檢測身體的運動,通常情況下在身體的特定部位(如腰部、腕部、腳踝、胳膊等部分)固定傳感器,通過分析傳感器數據來檢測日常行為。鑒于居家日常行為的特點,本研究采用微軟公司生產的Band2智能手環,其內置了豐富的傳感器,通過在試驗者右手手腕部位佩戴手環,這些來自傳感器的原始數據直接反映了手腕運動的特征。
描述手腕運動的加速度、方向角的屬性屬于低層特征,對應于文檔-主題模型中的“字”,是描述人體行為的最小單元;“字”的有序組合被稱為 “詞”,是對日常行為的高層語義描述。基于原始數據,抽取低層特征,在此基礎上提取高層動作語義特征是本研究的核心工作。
基于主題的行為識別的困難在于描述人體行為的“字”存在不確定性,不僅數量不確定,而且“字”本身隨著時間、地點的不同也存在差異。由于個體差異,即使同一個人在不同的時間、不同的情景下執行同一個動作,“字”也存在一定的差異。假定一種日常行為總能用一系統反映手腕動作的“字”表示,如“掃地”可以表示為一系列手臂前、后有序運動的“字”的集合,記為T掃地={W1,W2,…,Wi},其中i是“字”的數量,這里不僅i動態可變,Wi也會因人而異,存在差異性。
在之前的工作中提出了基于異構多傳感器信息融合的人體行為識別的方法[10-11],在研究中發現時序特征對行為識別準確率有一定的影響,如果忽略時序特征將會導致無法對相似的行為進行準確的識別。本文提出一種基于時間序列的日常行為表征方法,增加了對日常行為的高層動作語義描述,從而提高了系統對復雜行為的識別準確率和泛化能力。
2 預備知識
2.1 基本定義
本文涉及的相關概念定義,定義如下:
定義1運動元(movement syllable)。指某個時間點(以秒為單位)的手腕的運動,包括手部運動的加速度、方位角,是運動中的最小單元,對應于文檔中音節的概念。
定義2基本特征。指在某一固定時間段內(以分鐘為單位)抽取手部動作的特征,描述的是一個時間片內(time slice)手部的運動特征,對應于文本主題模型中字的概念。
定義3高層語義特征(meaningful feature)。具有一定語義含義、可切分的簡單的手臂動作,如手臂抬起、放下、翻轉等,對應于文本主題模型中的詞的概念。
狄利克雷過程混合模型(Dirichlet Process Mixture Model,DPMM)是一種非參數貝葉斯聚類方法,不需要人為事先指定聚類的數量,可以根據數據集的實際情況自主進行聚類,從中發現隱含的主題[14-15],本文相關的符號定義如表1所示。

表1 相關符號注解
2.2 狄利克雷過程混合模型
通常情況下在對樣本集進行聚類分析時,需要事先設定聚類的個數k,而k的取值將直接影響聚類的結果,如果事先設定的k不合理,將大大影響聚類的結果。在現實世界中,往往k是未知的,例如在行為分析中,我們無法事先得知一個行為動作由什么樣的手腕動作組成,進而不能對一個日常行為進行準確的語義描述。將一種日常行為Di表征為一系統具有語義特征的語義動作Ti的困難在于Ti具有一定的不確定性,Ti的數量也是未知的,即便是同一個人多次重復同一個的動作Di,其表征序列也是不盡相同的。由于DPMM會根據數據集動態地進行聚類,用于發現新的未知的類,故本文將DPMM應用到行為識別中,動態地對行為動作進行聚類,發現潛在的語義動作[16]。
假定樣本集中的數據都是由一個參數為θ的分布產生,聚類的目的是把θi相同的樣本歸為同一類,將整個樣本集劃分為具有一定語義特性的K個類。θi是從一個參數為a、H的狄利克雷過程產生,θi是Θ參數空間的一個元素,用來表征一個潛在的觀測值xi所屬的類別。每一個觀測值xi, 都對應一個θi,同一類中的樣本具有同樣的參數分布θi。
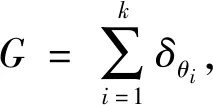
假設{a1,a2,…,ak}是Θ區域上的一個任意的劃分,G在每個區域內的測度都服從一個參數為a和H的狄利克雷分布,性質如式(1)所示,其概率密度如式(2)所示。
G(a1),G(a2),…,G(ak)~DIR(aH(a1),aH(a1),…,aH(ak))
(1)
p(p1,p2,…,pk|a1,a2,…,ak)=
(2)
式中:Γ(·)為gamma函數。
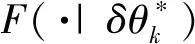
G~DP(α,H)θi~Gxi~F(x|θi)
(3)
(4)
DPMM在實際應用中,主要有狄利克雷多元正態混合模型和狄利克雷多項式混合模型兩種模型,狄利克雷多元正態混合模型主要用于對高斯數據進行聚類分析。而狄利克雷多項式混合模型主要用于對分檔的聚類分析[17],該模型的層次結構相對復雜,文檔中主題T服從一個參數為φ的離散多布式分布,記為Muti(φ),而φ又服從一個參數為α的狄利克雷分布;主題中的單詞的分布是一個參數為θZi的離散的多項式分類,而θZi又服從一個參數為β的狄利克雷分布,公式如式(5)所示,圖模型如圖1所示。
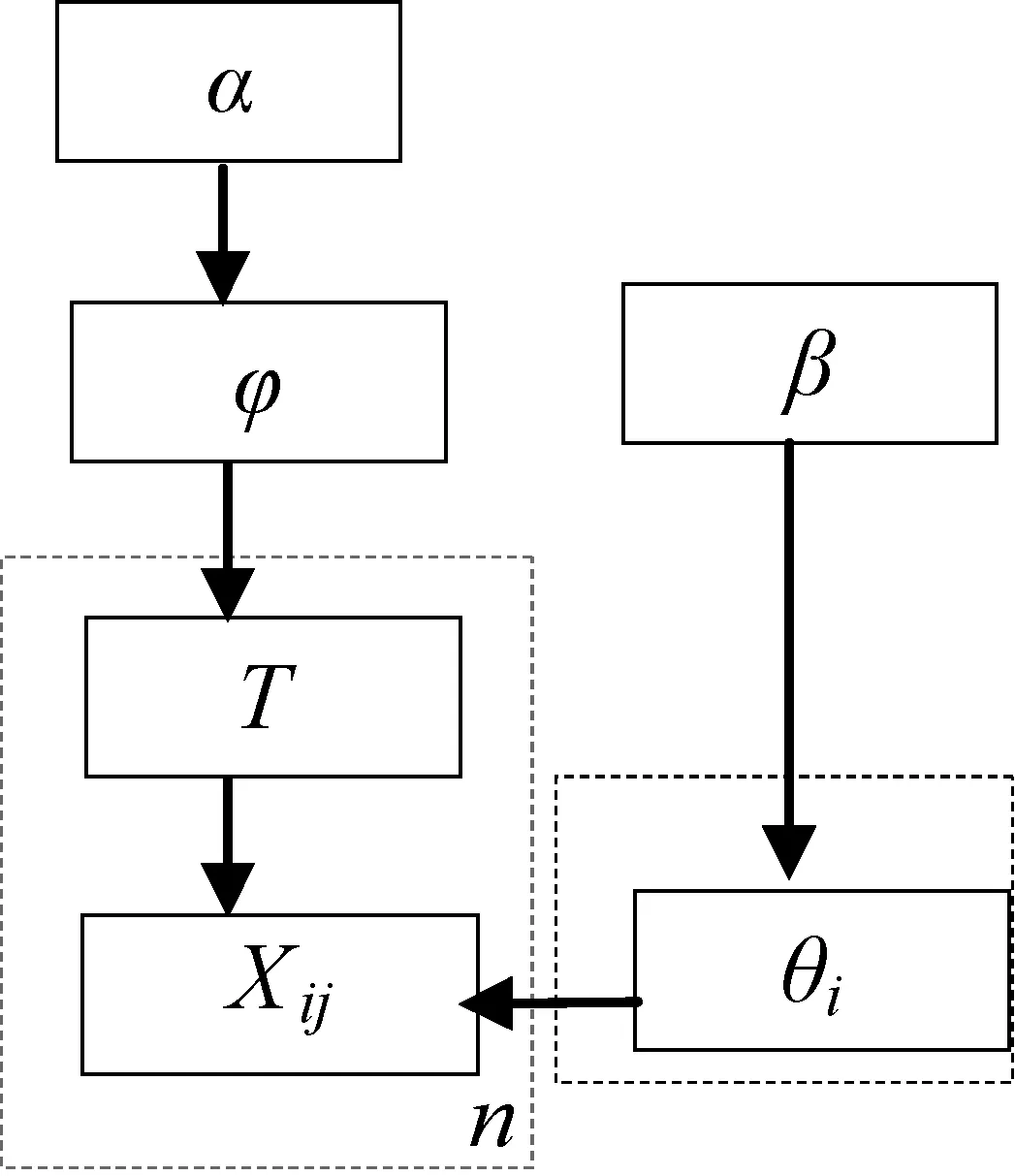
圖1 狄利克雷多項式混合模型圖模型
φ~Drichlet(α)Ti=1,2,…,n~Muti(φ)θk=1,2,…,l~Dirichlet(β)xi=1,2,…,n,j=1,2,…,di~Muti(θTi)
(5)
行為識別集可視為由若干未知的日常行為組成,而每一種日常行為又是由一系列手部動作組成,因此日常行為數據集可以看到文本研究領域的文本集。在這些日常行為中又包含一些具體的語義行為,文本研究中的每一個主題又是由一系列運動元組成,可以看作是詞的概念。本文將狄利克雷多項式混合模型(The Dirichlet-Multinomial Mixture Model)應用在行為識別中,通過式(6)計算后驗概率,得到模型的參數φ、T、θ、X。
(6)
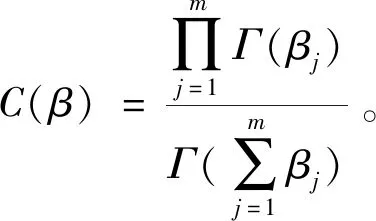
3 方案流程與算法實現
3.1 行為特征提取
采集Band2傳感器數據并抽取特征,生成原始數據特征集,記作X={X1,X2,…,Xn},即文本集,其中文本Xi由m個屬性構成,對應文本模型中的詞,而具有一定語義含義的動作就是文本模型中的主題T,該模型的構造過程主要包括文本-主題分布和主題-詞匯分布兩種分布,具體的生成過程如下所述:
1) 假設主題的概率分布服從一個參數為α的狄利克雷的先驗分布φ~DIR(α)。
2) 依據主題的先驗分布,生成語義主題T-行為的分布Ti=1,2,…,n~Multi(φ)。
3) 假設單詞的分布服從一個參數為β的狄利克雷的先驗分布θ~DIR(β)。
4) 依據θ生成單詞-主題的分布xi = 1,2,…,n,j = 1,2,…,m~Multi(θTi),其中m對應單詞數量,是行為數據集中文本的長度。
狄利克雷多項式混合模型的先驗是主題-文檔服從參數為α的狄利克雷的先驗分布,單詞-主題分布則服從參數β的狄利克雷的先驗分布。在該模式構造的過程中,采用Collapsed 吉布斯采樣的方法來評估主題T的后驗概率的概率分布,主題在t時刻的概率分布依賴于t-1時刻的x-i主題的概率分布[18],公式如下:
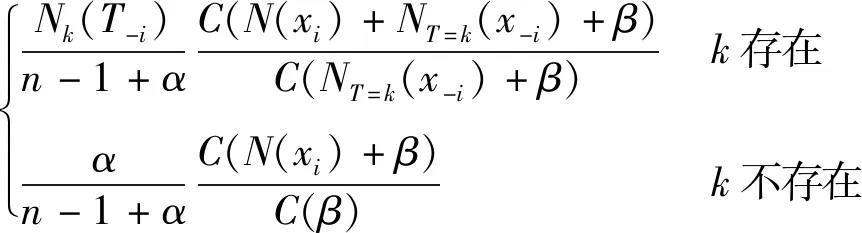
(7)
樣本集X的構造方法如文獻[10]所述,主要分為3個步驟:
(1) 微軟Band2手環內置加速度、陀螺儀傳感器,對手腕動作進行采樣,數據集記為V={axt,ayt,azt,gxt,gyt,gzt}。
(2) 基于原始數據集V,借鑒航空領域對飛機姿態的描述,抽取方位角特征翻滾(Roll)、俯仰(Pitch)、偏擺(Yaw),記為O={Rt,Pt,Yt}。
(3) 樣本數據集X={x1,x2,…,xn}是由一系列行為動作構成的文本集。基于步驟(1)、步驟(2)的處理結果,由式(8)-式(12)抽取行為動作的“字”序列,記為{μx,σx,μy,σy,μz,σz,μp,σp,μr,σr,μy,σy,μSVM},進而構建行為動作文本集。
循環執行步驟(1)-步驟(3),直到所有的原始數據集處理結束,行為動作文本集X構造完畢。
(8)
(9)
(10)
(11)
(12)
3.2 動作語義主題聚類
對行為動作文本集進行聚類分析,把具有相同分布的文本聚為一類,宏觀上表現為具有一定的語義含義的行為動作,采用文獻[11]中的框架建立語義動作聚類模型,在已知動作-語義行為主題的先驗概率分布的前提下,使用 Collapsed吉布斯采樣來學習、推測狄利克雷多項式混合模型中的參數θ、φ。
算法1基于吉布斯采樣的DMM算法
輸入:行為訓練樣本集D,迭代次數I。
輸出:主題分布超參數φ;特征單詞分布超參數θ。
2. for文檔Xi∈{X1,X2,…,Xn} do;
3. 隨機初始化文檔Xi∈Ti;
4.Tx←T;
5.mT←mT+1 andnt=nt+Nx;
6. for 單詞Xij∈Xido
8. for 迭代次數i∈[1,I] do
9. for 文檔Xi∈{X1,X2,…,Xn} do
10. 從Txi中去掉文檔Xi,重新計算T=Txi;
11.mTxi(mTxi-1;
12.nxi=nxi+Nxi;
13. for 單詞Xij∈Xido
15. 由式(6)采樣T,替換Txi
Ti←T~P(Ti=k|T-i,x1:n,α,β);
16.mT←mT+1 andnt=nt+Nx;
17. for 單詞Xij∈Xido
4 實驗設計與分析
4.1 實驗環境配置
鑒于人體運動的行為習慣,本文在實驗志愿者右手配置微軟Band2手環,采集三軸加速度和方向角數據,構建行為數據集。設定采集頻率為30 Hz, 采樣周期為35分鐘,對于每種日常行為采樣時間為5分鐘,包含7種日常行為,共收集7 840×60個有效樣本。然后按照3.1節行為特征提取的方法對有效樣本進行處理,抽取特征,進而構建日常行為文本集X,包含7 840個文檔,每篇文檔中包含若干個特征單詞,有效樣本集描述如表2所示。
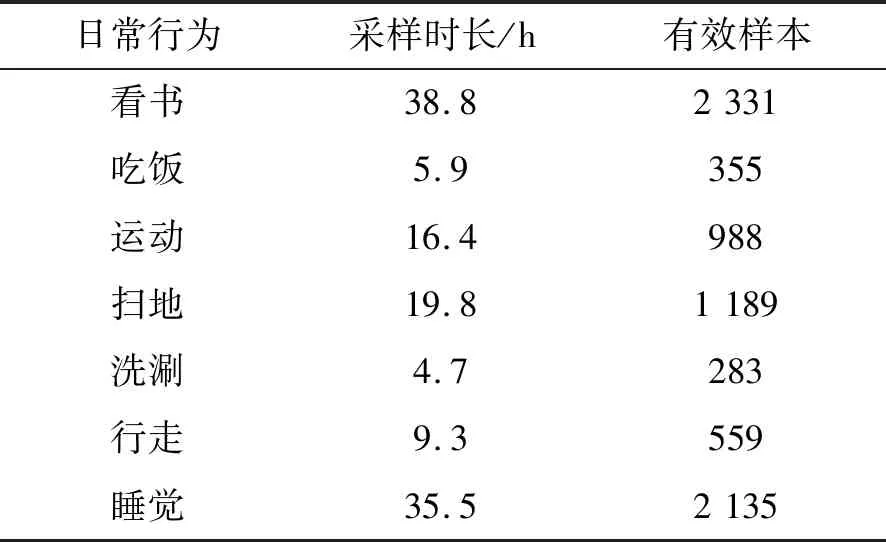
表2 實驗數據集
4.2 高層語義動作聚類
基于狄利克雷多項式混合模型,依據各文本的低層特征,對樣本集進行無監督的聚類分析,將樣本聚合為m類,其中每個主題Ti都具有一定的語義含義,宏觀上可視為一個特定的動作,微觀上表現為一系列具有相似的三軸加速度和姿態角特征的文本,如手腕傾斜一定角度、低速上抬等語義動作,簇標號記為ti,ti∈[1,m],m是聚類后簇的數量。每種日常行為都可以表征為一系列的語義動作,由于日常行為的不同,語義簇的數量也各不相關,如圖2所示。
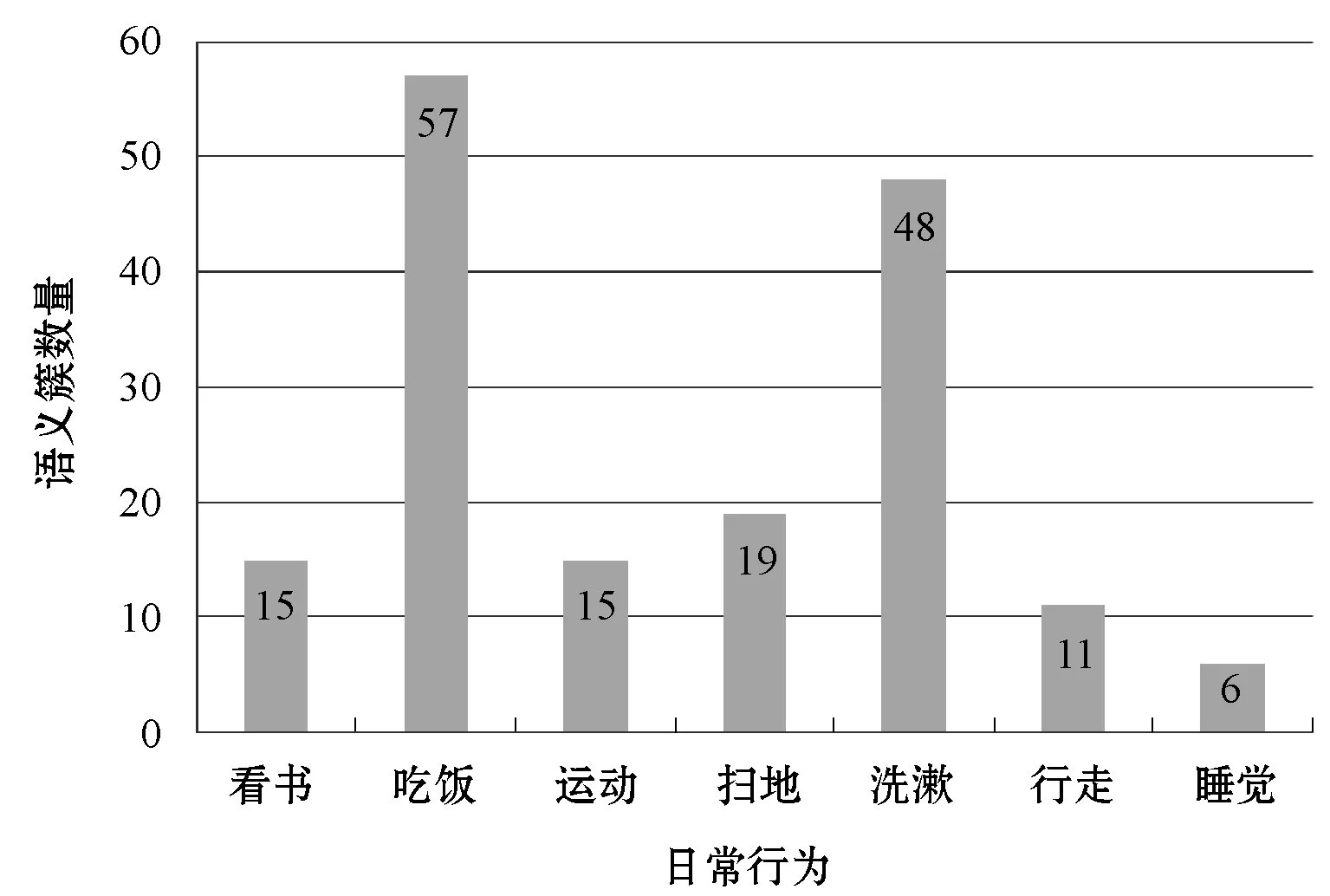
圖2 日常行為-語義簇數量對應關系
每一個語義簇都對應語義動作字典中一個具有某種具體含義的動作,語義簇數量反映的是在從事一個日常行為的過程中手腕動作變化的程度,通常情況下日常行為越復雜,其包含的手腕動作就越多樣化,圖2中“睡覺”相對于更為復雜的“洗漱”、“吃飯”等日常行為,語義簇數量就少得多。另外語義簇數量也會因人而異,即使從事同一種日常行為,語義簇數量也會呈現差異性,以上原因都會導致語義字典的差異性,具有一定的不確定性,因此會降低日常行為分析模型的泛化性,給行為分析增加了難度。
為此,本文對聚類后的結果進行歸一化處理,在此基礎上把一個復雜的日常行為表征為語義動作ti組成的行為序列。基于時間片si,對樣本集進行分割,對于切分好的樣本,基于滑動窗口模式,對樣本進行語義動作表征,構造樣本集的高層語義動作數據集,Witj是動作語義特征,具有一定的語義含義,Witj∈[1,m]。圖3描述的是7種復雜日常行為在30分鐘內語義動作的變化趨勢,也就是手腕動作的變化趨勢,在睡覺中,人的手腕的動作幾乎不變,呈現一條直線;讀書行為動作中,手腕的動作變化幅度不大,變化較為平緩,語義特征mti∈[1,50];在清掃中,手腕的語義動作變化增強,mti∈[100,130];洗漱、吃飯動作的變化最大,語義簇mti∈[100,500]。
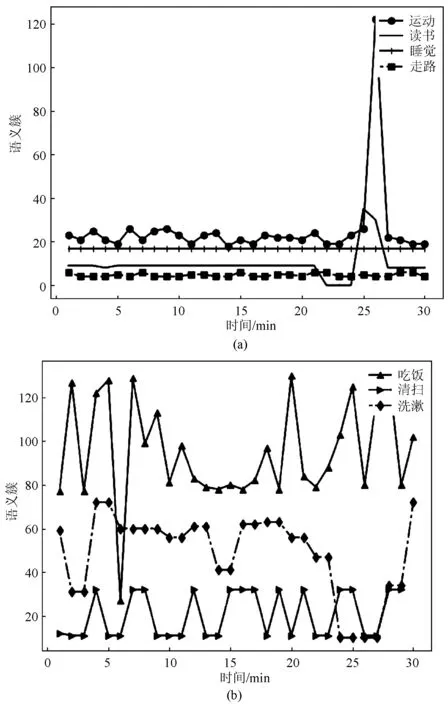
圖3 行為-語義表征
4.3 行為識別分析
假設一個復雜的行為要持續一定的時長,那么對于復雜日常行為一定可以表示為一系列語義動作的有序組合,對應文本集中的一個文本。基于4.2節聚類結果,采用滑動時間窗模式,本文滑動窗口長度設置為5(大約為5分鐘),重疊率60%,重新構建日常行為高層語義樣本集。
本系統對4名志愿者分別采集行走、看書、運動等7種日常行為數據,并按照第3節中所述的方法構建復雜行為的樣本集,應用動態貝葉斯網絡對樣本集進行分類,分類結果如表3-表6所示。
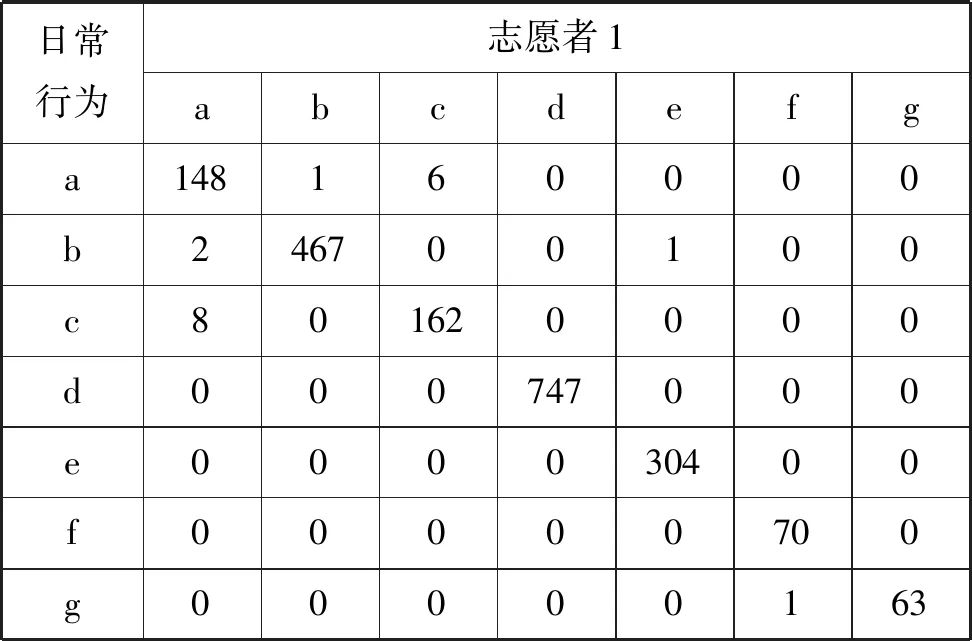
表3 志愿者1分類結果
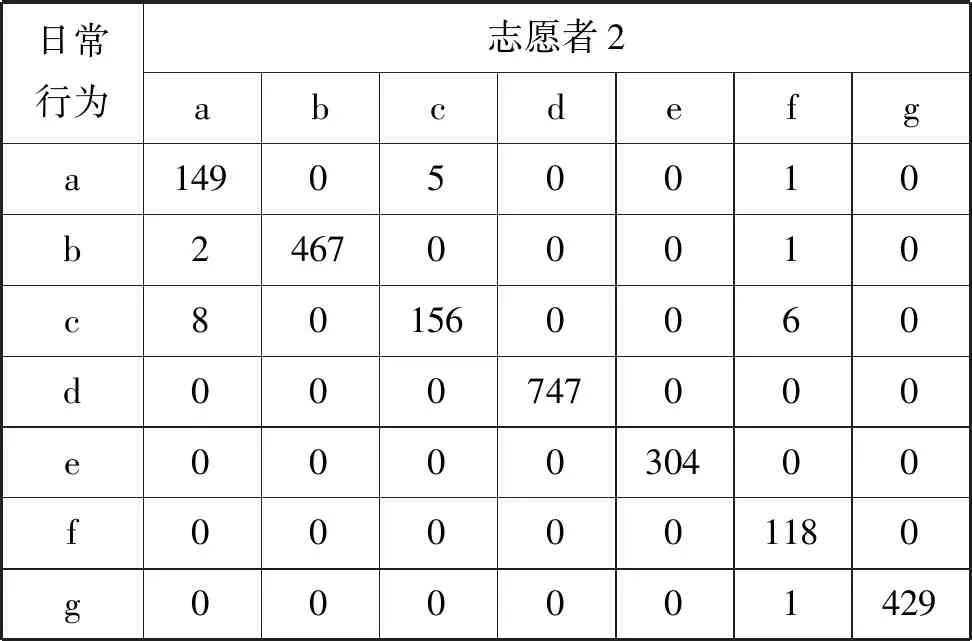
表4 志愿者2分類結果
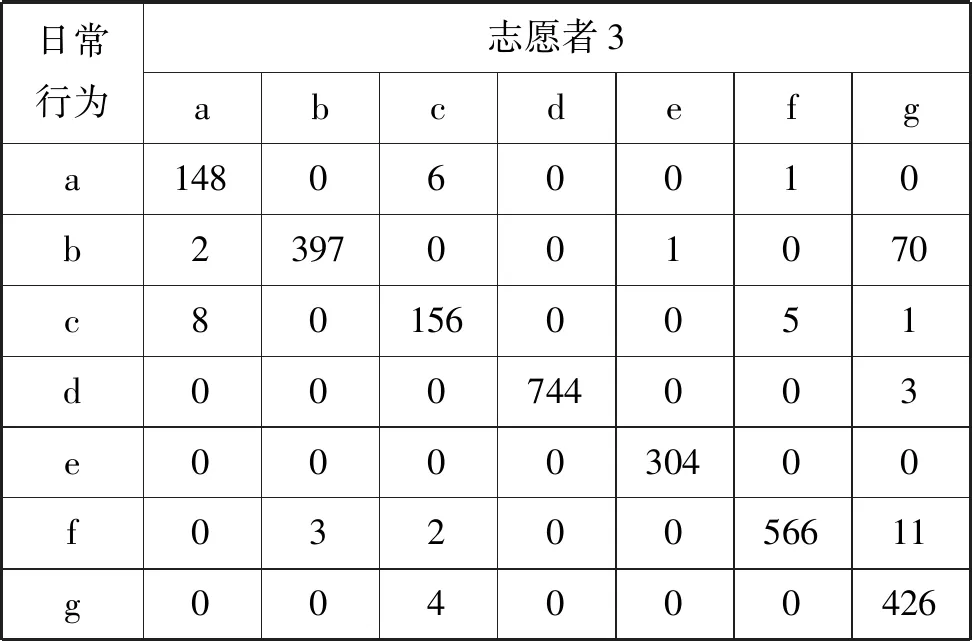
表5 志愿者3分類結果
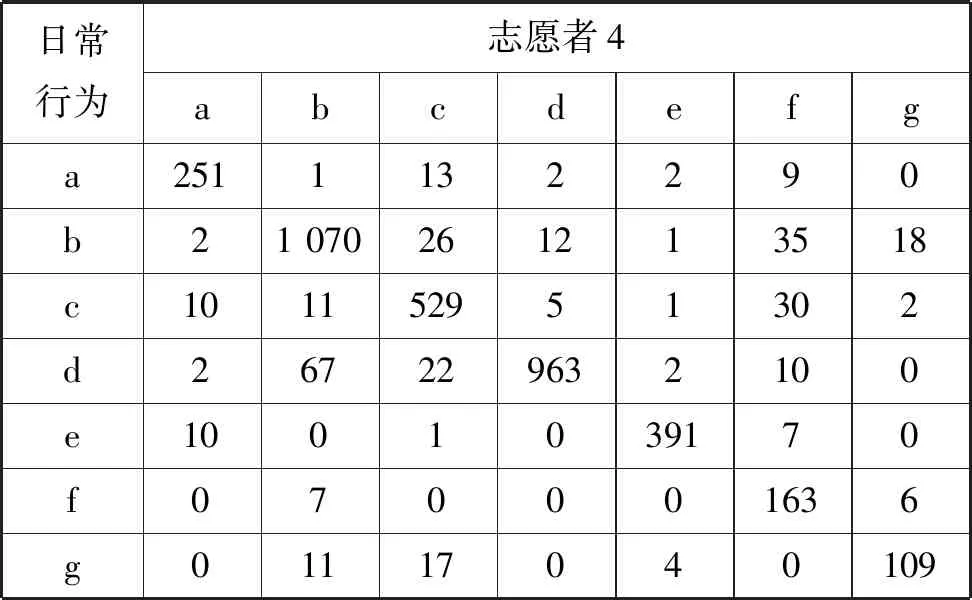
表6 志愿者4分類結果
表中符號集{a,b,c,d,e,f,g}表示日常行為,分別代表a:行走;b:讀書;c:清掃; d:睡覺;e:鍛煉;f:吃飯;g:洗漱。
為了評估行為識別模型的效率,分別計算模型的準確率(Precision)和召回率(Recall),如式(13)、式(14)所示,其中:TP是真陽性 (True Positive);TN是假陽性(True Negative);FP是假陽性(False Positive);FN是假陰性(False Negative)。對4名志愿者的日常行為分別進行在線測試,準確率和召回率結果分別如表7、表8所示。
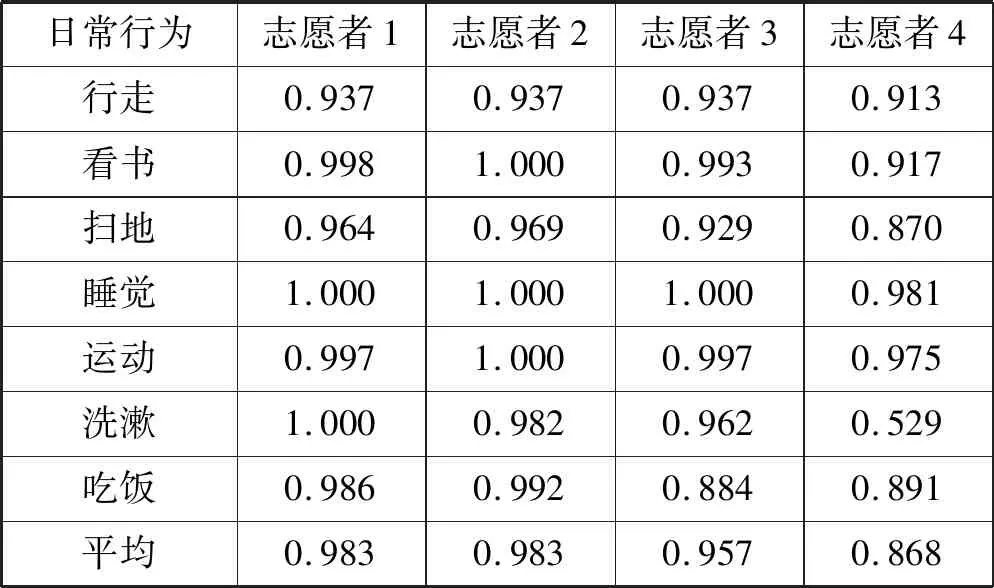
表7 行為識別模型準確率
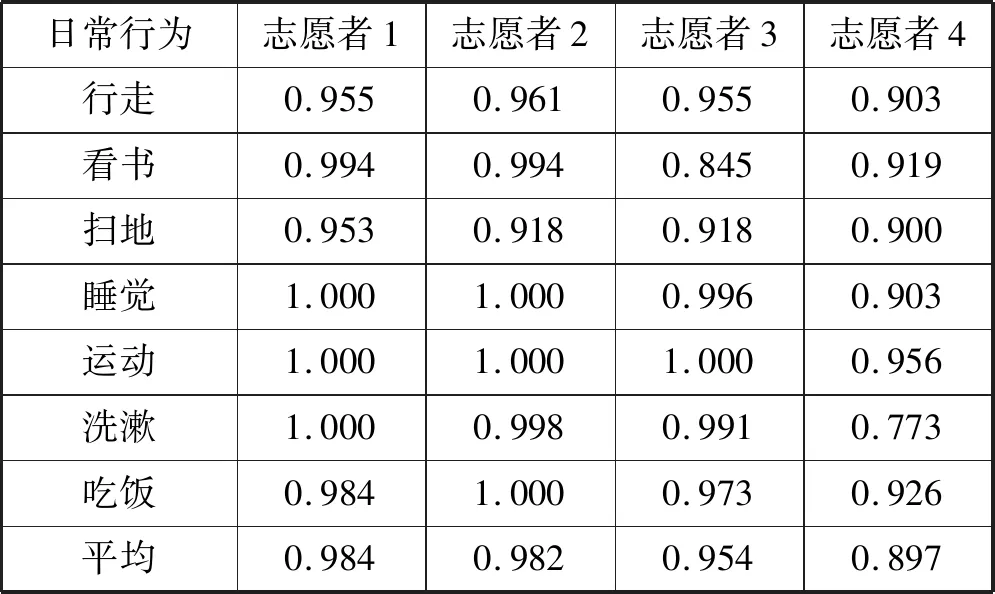
表8 行為識別模型召回率
(13)
(14)
人們從事日常活動,都有各自喜歡的動作模型,從傳感器的角度,客觀反映為不同的語義簇,例如每個人都有自己喜歡的睡覺姿勢,這些姿勢在一個時間片內呈現一定的規律,大部分數據被分到這一主類中,但是也有少量數據具有不同的運動模型,與其他類的特征相似,就被標注為其他的類別。如果一種日常行為分類標簽大于1,這就意味著人們在從事該種日常行為時,有多種動作模型,意味著該種日常行為是一種復合式的行為,由多種子行為組合而成。如表3、表4、表5所示,“睡覺”行為全部被分到同一類中,意味著志愿者睡姿穩定,整個過程中保持著相似的姿態;而由于志愿者4在“睡覺”行為中夾雜著翻身、起身坐起等子動作,從表6的分類結果中可以看出該行為包含5種子行為,其中有67條數據記錄與“讀書”具有相似的運動模型,被分到“讀書”類別中,對應“起身坐起”的子行為。
如表7、表8所示,“洗漱”、“吃飯”、“掃地”三種日常行為不僅包含多種子行為,而且動作的變化性較大,如:隨著清掃位置的不同,“掃地”表現為不同的手部動作;“吃飯”會隨著菜品在餐桌擺放位置不同而呈現不同的高層語義主題;變化最大的是“洗漱”,包含“洗臉”、“洗手”等多種差異性較大的子行為。上述差異性直觀反映在信號向量幅度(Signal Vecor Magnitude,SVM)的變化,圖4顯示的是志愿者4的7種日常行為在2分鐘內,信號向量幅度的變化量,其中變化量最大的是“洗漱”,變化幅度為246.73,最小的是“睡覺”,變化量為0.61。

圖4 信號向量變化幅度
由于向量的這種變化,因此從某一個時間點,行為動作存在較大的差異性,甚至完全不同,一般情況下日常行為復雜性越大,信號向量變化幅度就越大,從而表現為子行為的多樣性。但是從一個較長的時間周期來看,運動模型又具有一定的相似性,志愿者偏好的行為動作被分到主類中,而隨機的、不常發生的動作被分到其他類中。通過對4個志愿者的分類結果進行分析,平均有93.3%的“掃地”行為、93.83% 的“吃飯”行為、86.83% 的“洗漱”行為被分到主類中。
5 結 語
由于日常行為特征的個體差異性,本文基于Dirichlet多項式混合模型,挖掘隱藏在復雜日常行為中的高層語義動作。首先基于文本挖掘的領域知識,挖掘日常行為的語義動作,構建語義動作詞典;然后基于時間窗模式,構建復雜行為動作的高層語義動作文本集,融合高級語義特征與日常行為的時序特征,提高對復雜日常行為的表征;最后應用分類算法對日常行為進行分類,提高了對復雜行為動作檢測的準確率。實驗結果表明,本文方法能有效地發現未知的高層語義動作特征,準確地對復雜的日常行為進行描述,具有所生成的樣本集小、行為識別率高的優點,不僅可以應用在輔導照顧領域,還可以用于臨床環境下對某些疾病的輔助診療。
由于日常行為的執行周期存在動態可變性,本文對復雜行為的表征是基于固定時長的滑動時間窗模型;又由于復雜行為自身的多變性,使得本系統對個別行為(如“洗漱”)的識別率還較低。今后一方面將繼續開展對日常行為分隔的研究,構建基于動態時間窗的行為分隔、識別模型,從而提高對復雜行為的識別率;另一方面針對語義動作詞典的差異性,在提高本系統泛化性、構建多模式識別平臺方面開展進一步的研究。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
現代語文(2016年21期)2016-05-25 13:13:44
少兒科學周刊·少年版(2015年4期)2015-07-07 20:56:37
大連民族大學學報(2015年2期)2015-02-27 08:28:11
