基于改進YOLOv3的自然場景人員口罩佩戴檢測算法①
2021-02-23 06:30:36程可欣王玉德
計算機系統(tǒng)應(yīng)用 2021年2期
關(guān)鍵詞:檢測
程可欣,王玉德
(曲阜師范大學(xué) 物理工程學(xué)院,曲阜 273165)
佩戴口罩是一種隔離和遏制新型冠狀病毒、預(yù)防新冠肺炎的有效方法.為保護人民的身體健康與生命安全,最大限度地降低和消除因疫情對生產(chǎn)經(jīng)營造成的影響,需要對復(fù)產(chǎn)復(fù)工人員規(guī)范佩戴口罩進行的監(jiān)督和提醒.依靠肉眼觀察是否佩戴口罩,不僅耗費人力物力,而且有極大的漏檢風(fēng)險和近距離接觸的感染風(fēng)險,因此,需要一種基于圖像處理的高精度高速度的口罩佩戴檢測算法.
牛作東等提出了一種改進RetinaFace的自然場景口罩佩戴檢測算法,該算法基于ResNet-152 網(wǎng)絡(luò),FPS(每秒傳輸幀數(shù),Frames Per Second)較低,不適用于實際的檢測環(huán)境[1].YOLOv3 算法利用回歸思想,通過CNN 網(wǎng)絡(luò)一次性生成目標位置邊框和目標類別,這種方式使得檢測速度更快、模型泛化能力強,同時可以減少背景錯誤產(chǎn)生,因此本文選擇該方法進行檢測.國內(nèi)對該方法已有了成熟而廣泛的應(yīng)用,如鄭秋梅等在交通場景上使用該方法進行車輛檢測[2],王毅恒等使用該方法對農(nóng)場環(huán)境下的奶牛進行檢測[3],孟本成等使用該方法對行人進行檢測[4]等.YOLOv3 算法雖然檢測速度快,但小目標漏檢的風(fēng)險相對更高,鑒于上述問題,本文提出改進目標邊框損失的YOLOv3算法對自然場景下人員是否佩戴口罩進行檢測,更好地做好人員防護.
1 基本原理
YOLOv3 算法是Redmon 等在2018年提出的[5],改進了網(wǎng)絡(luò)結(jié)構(gòu)、網(wǎng)絡(luò)特征及損失計算3 個部分,在保持速度優(yōu)勢的前提下,進一步提升了對小目標的檢測能力和檢測精度.
1.1 DarkNet-53 網(wǎng)絡(luò)
YOLOv3 結(jié)構(gòu)由骨架網(wǎng)絡(luò)DarkNet-53和檢測網(wǎng)絡(luò)兩部分組成,用于特征提取和多尺度預(yù)測[6].YOLOv3網(wǎng)絡(luò)結(jié)構(gòu)如圖1.
DarkNet-53 網(wǎng)絡(luò)共有53 層卷積層,最后一層為1×1 卷積實現(xiàn)全連接,主體網(wǎng)絡(luò)共有52 個卷積.52 個卷積層中,第一層由一個32 個3×3 卷積核組成的過濾器進行卷積,后面的卷積層是由5 組重復(fù)的殘差單元(resblock body)構(gòu)成的,這5 組殘差單元每個單元由一個單獨的卷積層與一組重復(fù)執(zhí)行的卷積層構(gòu)成,重復(fù)執(zhí)行的卷積層分別重復(fù)1、2、8、8、4 次;在每個重復(fù)執(zhí)行的卷積層中,先執(zhí)行1×1的卷積操作,再執(zhí)行3×3的卷積操作,過濾器數(shù)量先減半,再恢復(fù),共1+(1+1×2)+ (1+2×2)+ (1+8×2)+ (1+8×2)+(1+4×2)=52 層.
YOLOv3 模型的輸出為3 個不同尺度的特征層,分別位于DarkNet-53 網(wǎng)絡(luò)的中間層、中下層和底層,用于檢測不同大小的物體.如圖1所示,對3 個特征層進行5 組卷積處理,可輸出該特征層對應(yīng)的預(yù)測結(jié)果.
1.2 網(wǎng)絡(luò)性能分析
DarkNet-53 特征提取網(wǎng)絡(luò)通過大量的3×3和1×1 卷積層構(gòu)成,該網(wǎng)絡(luò)在ImageNet 數(shù)據(jù)集下測試,網(wǎng)絡(luò)性能比ResNet 網(wǎng)絡(luò)更好[3],結(jié)果如表1.
通過表1我們可以看到,在圖像分類的準確率以及檢測速度等方面,DarkNet-53 網(wǎng)絡(luò)與其他3 種網(wǎng)絡(luò)模型相比,表現(xiàn)更加優(yōu)越.DarkNet-53 網(wǎng)絡(luò)在滿足檢測實時性的同時比DarkNet-19 具有更高的精度,并且在網(wǎng)絡(luò)性能相差無幾的情況下,網(wǎng)絡(luò)的速度約是ResNet-152 網(wǎng)絡(luò)的2 倍.
2 損失函數(shù)改進
2.1 GIoU 損失函數(shù)
在原始YOLOv3 算法中,使用均方誤差作為目標定位損失函數(shù)來進行目標框的回歸,均方誤差函數(shù)對尺度較為敏感,并且無法反應(yīng)不同質(zhì)量的預(yù)測結(jié)果,故大量使用YOLOv3 算法的工作中,常使用預(yù)測框和真實目標框的IoU 值來衡量兩個邊界框之間的相似性,雖然改善了這兩個問題,卻也帶來了新問題.首先,當預(yù)測框和真實框之間沒有重合時,IoU的值為0,導(dǎo)致優(yōu)化損失函數(shù)時梯度也為0,意味著無法優(yōu)化.其次,即使預(yù)測框和真實框之間相重合且具有相同的IoU 值時,檢測的效果也具有較大差異.
Rezatofighi 等于CVPR2019 上提出了GIoU(Generalized IoU,廣義IoU)目標邊界框優(yōu)化方法,GIoU針對IoU 無法反應(yīng)不重疊的兩個框之間距離和重疊框?qū)R方式的問題進行了優(yōu)化,圖2中3 幅圖的IoU 均為0.33,GIoU的值分別是0.33,0.24和?0.1,這表明如果兩個邊界框重疊和對齊得越好,那么得到的GIoU 值就會越高[7].
圖2中黑色框為真實框A,灰色為預(yù)測框B,虛線框為最小可包含A、B的框C.假設(shè)有框A和B,總可以找到一個最小的封閉矩形C,將A和B 包含在內(nèi),然后計算C 中除了A和B 外的部分的面積占C 總面積的比值,再用A 與B的IoU 減去這個比值,IoU 計算公式和GIoU 計算公式如式(1)、式(2)所示.
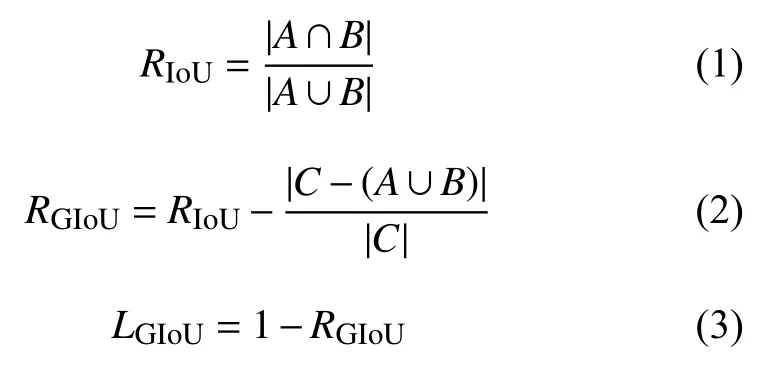
GIoU 與IoU 類似,可以作為一種距離度量,損失可以由式(3)計算.GIoU 對物體的大小并不敏感,其值總是小于等于IoU,是IoU的下界.在兩個形狀完全重合時,GIoU和IoU 大小均為1.GIoU 引入了包含框A和B 兩個形狀的C,解決了IoU 不能反映重疊方式,無法優(yōu)化IoU為0的預(yù)測框的問題.al
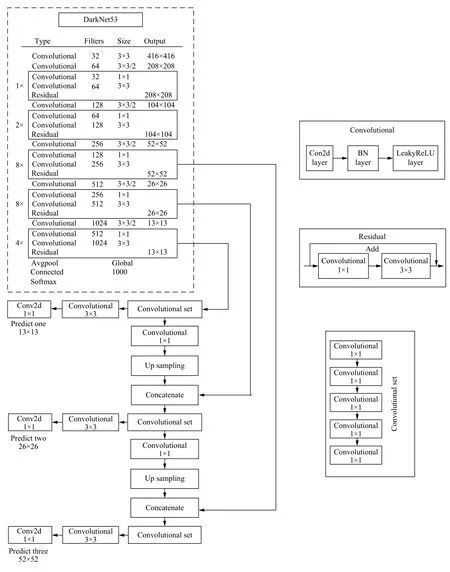
圖1 YOLOv3 網(wǎng)絡(luò)結(jié)構(gòu)(含DarkNet-53)
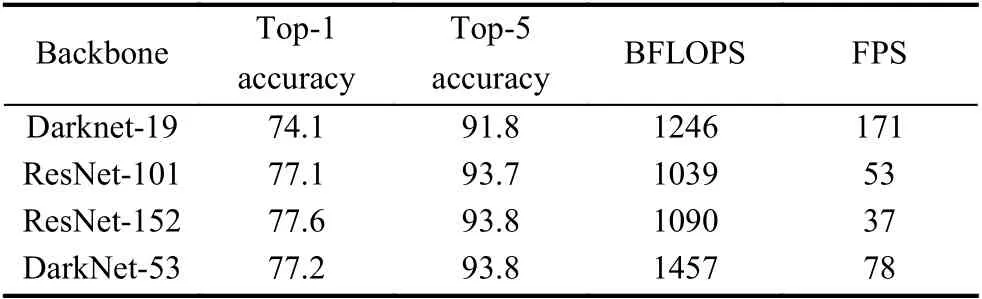
表1 4 種網(wǎng)絡(luò)框架性能對比
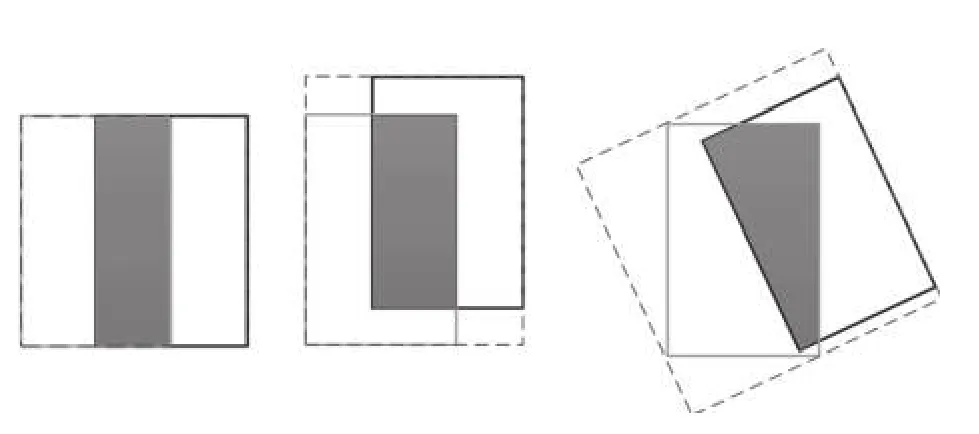
圖2 IoU 均為0.33 時3 種不同的重疊情況
2.2 Loss 損失計算
本文將LGIoU損失函數(shù)應(yīng)用于YOLOv3 目標檢測算法中,以LGIoU直接作為邊界框回歸損失函數(shù)代替原來的均方差和損失函數(shù).
損失函數(shù)的公式包含目標定位損失、目標置信度損失和目標類別損失3 個部分,分別對應(yīng)式(4)中的第一項、第二、三項和第四項.
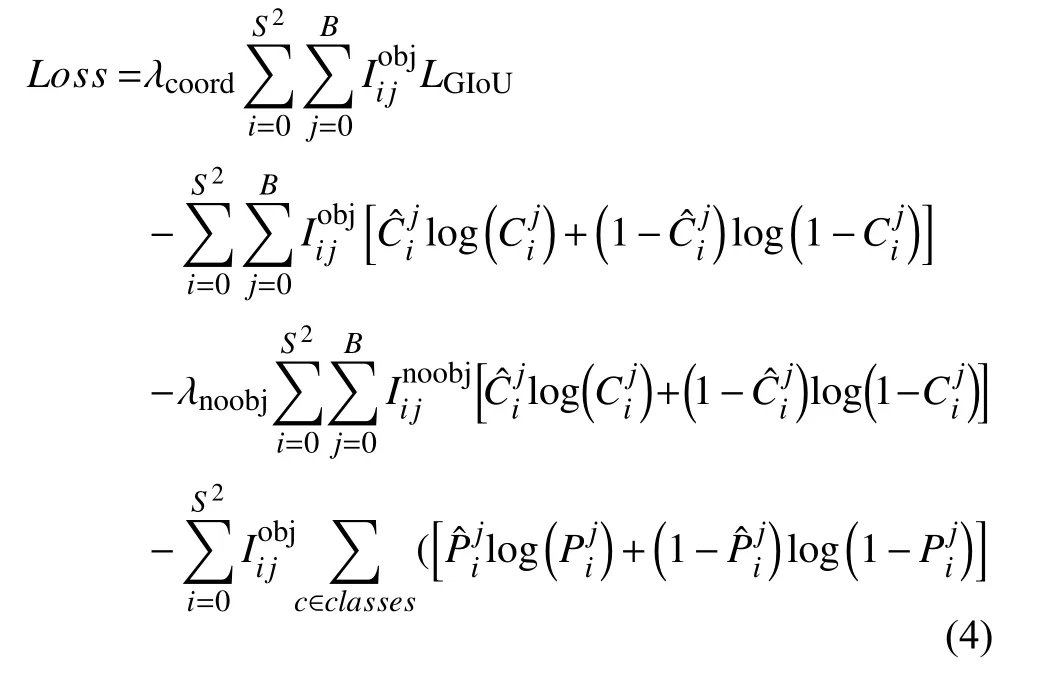
3 算法流程
該算法流程主要分為特征提取和多尺度預(yù)測兩部分,圖片經(jīng)過DarkNet-53 網(wǎng)絡(luò),生成3 種尺度的特征圖,每種尺度的特征圖劃分為大小不同的網(wǎng)格,每個網(wǎng)格預(yù)測3 個先驗框,經(jīng)過非極大抑制等,得到預(yù)測框,在訓(xùn)練過程中,還會進行損失函數(shù)計算,更新權(quán)重.
4 實驗與結(jié)果分析
實驗用計算機配置為Intel Corei5-5200 2.20 GHz CPU、Tesla V100-SXM2 GPU,顯存16 GB.軟件環(huán)境為Linux 操作系統(tǒng)、PyCharm2019.3.3、PyTorch 框架.
文中使用了AIZOO 團隊公開的人臉口罩佩戴數(shù)據(jù)集,該數(shù)據(jù)集中的圖片來源于WIDER FACE 數(shù)據(jù)集[8]和中科院信工所葛仕明老師開源的MAFA 數(shù)據(jù)集[9],圖片示例如圖3,對應(yīng)的標注數(shù)據(jù)如表2.訓(xùn)練樣本與測試樣本按0.7:0.3 劃分,訓(xùn)練集共5566 張圖片,來自MAFA的圖片2873 張(基本都是戴口罩的圖片)、WIDER Face 圖片2693 張(基本都是不戴口罩的圖片).驗證集共2385 張圖片,取自MAFA 1188 張、WIDER Face 1197 張.
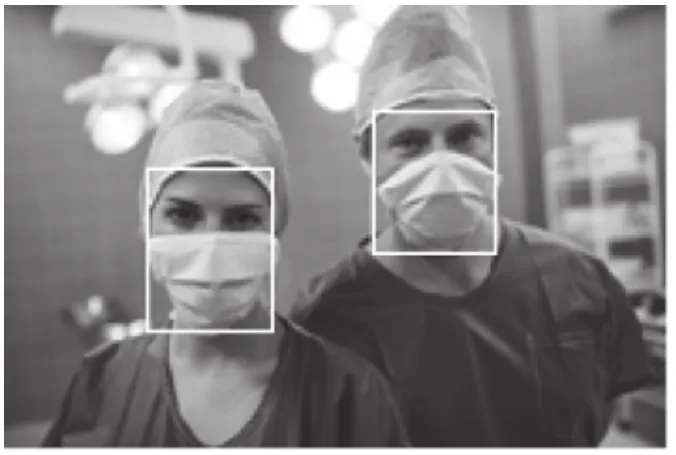
圖3 數(shù)據(jù)集示例圖片

表2 示例圖片標注數(shù)據(jù)
采用遷移學(xué)習(xí)的方式,采用了ImageNet 預(yù)訓(xùn)練好的模型參數(shù),通過初始化模型前47 層卷積層參數(shù)、微調(diào)末端參數(shù)的方式對模型進行訓(xùn)練,將檢測類別按是否佩戴口罩調(diào)整為2 種、初始學(xué)習(xí)率設(shè)置為0.01、batchsize為16.
從圖4–圖6可以看出,使用GIoU 作為目標邊界框損失函數(shù)總是小于IoU,該結(jié)果符合GIoU的特點,平均檢測精度(mAP)上升速度更快且有小幅度的提高.在使用GIoU的條件下,訓(xùn)練迭代次數(shù)到達50 次后,mAP曲線漸趨平緩,最后達到88.4%左右不再增加,而GIoU一直平穩(wěn)下降至0.93,目標定位損失下降至0.315,目標分類損失下降至0.0361.驗證集數(shù)量少后期易出現(xiàn)過擬合現(xiàn)象,故迭代次數(shù)達到100 次時停止訓(xùn)練.
GIoU 作為目標邊界框損失函數(shù)的訓(xùn)練模型,多目標檢測的平均精度達到88.4%,佩戴口罩的類別達到96.5%,檢測結(jié)果如表3,與IoU 相比均有提高.
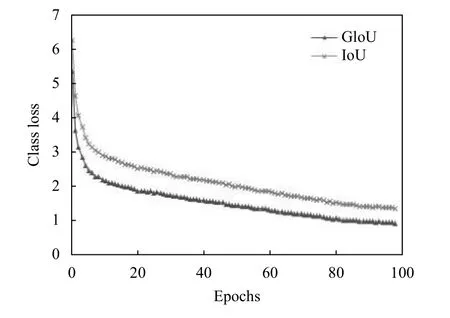
圖4 GIoU 與IoU 訓(xùn)練過程曲線
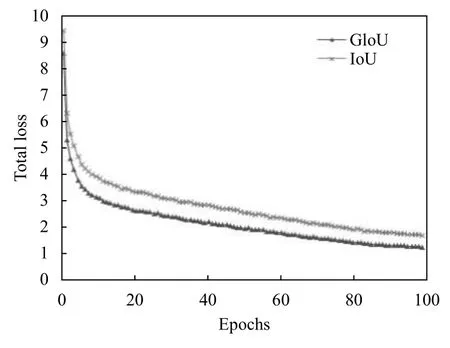
圖5 使用GIoU 與IoU的YOLOv3 總損失函數(shù)訓(xùn)練過程曲線
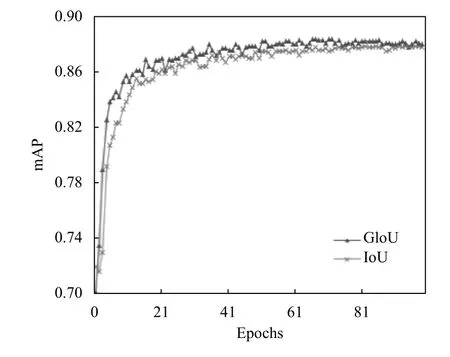
圖6 GIoU-YOLOv3 與IoU-YOLOv3 mAP 訓(xùn)練過程曲線

表3 不同類別使用GIoU和IoU的mAP 對比
圖7(a)為GIoU-YOLOv3 測試結(jié)果,圖7(b)組圖片為IoU-YOLOv3 測試結(jié)果.從測試結(jié)果可見GIoUYOLOv3 算法針對小目標的漏檢率有明顯降低.

圖7 未戴口罩和佩戴口罩的檢測圖像
圖8為從網(wǎng)絡(luò)隨機爬取的512×320 大小416 幀的視頻的測試結(jié)果,共用時10.751 s,平均每幀用時0.026 s,FPS 達到38.69,滿足實時檢測的要求.
5 結(jié)論
論文提出改進檢測目標邊框損失的自然場景人員口罩佩戴檢測算法,在一定程度上減小了漏檢率,mAP也有一定的提高.該方法平均每秒檢測約38 張圖片,可以實現(xiàn)實時檢測.同時,對佩戴口罩類別的檢測準確率可達96.5%,行人是否佩戴口罩的mAP 達到了88.4%.在多目標檢測上有較好的表現(xiàn),檢測速度更快、成本更低、準確率更高.

圖8 視頻測試結(jié)果部分截取
猜你喜歡
中國設(shè)備工程(2022年12期)2022-07-11 04:33:00
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年9期)2019-11-25 07:34:36
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年9期)2019-11-25 07:34:34
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年12期)2019-05-21 02:53:50
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年12期)2019-05-21 02:53:48
