基于歷史結果緩存的路網k近鄰查詢算法
2021-02-11 12:45:38李佳佳楊亞星宗傳玉夏秀峰
沈陽航空航天大學學報 2021年6期
李佳佳,楊亞星,朱 睿,宗傳玉,夏秀峰
(沈陽航空航天大學 計算機學院,沈陽 110136)
路網中的k近鄰(kNearest Neighbor,kNN)查詢是在給定被查詢的興趣點(POI)集合中,返回路網中距離查詢點最近的k個POI對象。近年來,隨著網絡通信的發展,kNN查詢成了一個重要的研究課題,引起越來越多學者的關注,在地圖導航、救援服務、位置感知廣告服務等方面具有廣闊的應用場景,例如用戶查找距離最近的酒店。
路網中每天存在大量的在線k近鄰查詢,現有研究中要么采用在線擴展路網的查詢方式,要么采用基于索引結構的查詢方式,通常關注基于單一查詢效率的提升,而沒有考慮大量集中查詢的效率。如在學校、小區等區域比較集中的查詢中,存在許多結果相似的查詢,但每次都需要向服務器發起查詢請求,重新進行k近鄰查詢,大大增加了服務器的負擔。為此本文提出基于歷史結果緩存的k近鄰查詢算法(Cache basedkNN,CBkNN),旨在重用緩存的歷史k近鄰查詢結果,減少服務器的查詢代價。
不同于現有的研究,本文研究的基于緩存的k近鄰查詢有以下特點:
(1)提出了共享前綴匹配模型,通過對緩存結果的共享匹配,提高緩存命中率。
(2)提出基于結點的緩存存儲結構,快速查找可利用的歷史查詢結果,提高查詢共享匹配效率。
(3)通過在真實路網中進行大量實驗,結果表明,CBkNN算法比不使用緩存的INE算法快25%,比緩存算法MkNN響應時間少15%。
1 相關工作
目前對基于路網的k近鄰查詢算法研究或采用無索引的在線擴展方式,如INE算法、IER算法[1];或利用預先計算的索引結構來加快查找效率,如island[2]、S-GRID[3]、DisBrw[4]、ROAD[5-6]、G-tree[7-8]、TOAIN[9]等算法。前者只存儲路網中節點和邊的信息,需要大量在線計算;后者在存儲基本路網信息的同時,需要預先計算一些節點信息,需要較長的預處理時間及較大的存儲空間。2016年,發表在VLDB的文獻[10-11]對以上算法進行了詳細的實驗對比,實驗結果表明INE算法在POI密度較高的情況下性能較優。
基于INE算法,Thomsen等[12]提出了多步驟kNN查詢算法(MkNN),通過歷史結果的選擇性存儲,在下一步查詢中重用存儲的歷史結果。MkNN算法中的歷史kNN結果只起到輔助作用,減少了在線擴展路網中的節點,并沒有直接回答新查詢。同時,該算法依然存在INE算法的局限性,在POI稀疏的情況下,算法效率依舊較低。
文獻[13]和[14]利用歷史最短路徑結果回答最短路徑查詢。通過子路徑匹配,即在緩存的最短路徑中匹配新查詢的起點和終點,用于回答新的查詢。文獻[15]提出緩存路徑規劃(PPC)算法,與前者的僅當緩存與新查詢完全匹配時才使用緩存的方法不同,PPC算法利用部分匹配的緩存路徑來回答新查詢的一部分,剩余部分重新查詢。雖然基于緩存的最短路徑算法并不能直接應用于kNN查詢算法,但為本文研究提供了一些靈感。
綜上所述,現有的kNN查詢技術大多只關注單次查詢效率,并沒有考慮查詢結果的重用問題。盡管有些工作提出了基于緩存的最短路徑查詢優化方式,但最短路徑查詢和kNN查詢具有本質上的不同,并不能直接應用在kNN查詢上。因此,研究基于緩存的kNN查詢具有非常重要的意義。
2 問題定義
定義1路網。路網G由集合V、E和W組成,記為G(V,E,W),其中V{v1,…,vn}表示節點的集合,E{(vi,vj)|vi,vjV,i≠j}表示連接兩個不同節點的邊的集合,W={(vi,vj)|vi,vj∈V,i≠j}表示邊的長度。圖1所示為一個路網圖。
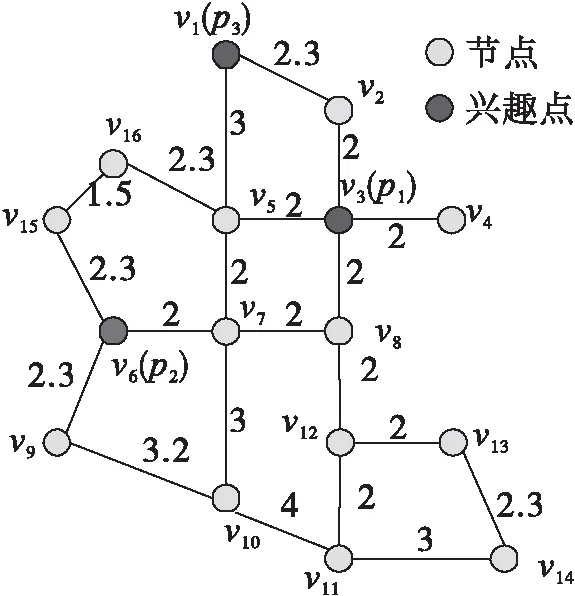
圖1 路網圖
定義2 路網k近鄰查詢。給定POI集合P和查詢點q,返回路網中距離查詢點q最近的k個POI的結果集合R,其形式化定義為:kNN(q)={p∈R, R?P|?v∈P-R,dist(q,p)≤dist(q,v)}
定義3緩存C。緩存是kNN查詢結果的集合。
定義4查詢日志Qlogs。查詢日志是由過去用戶發布的帶有時間戳的查詢集合。
3 CBkNN查詢框架
CBkNN查詢框架主要分為k近鄰共享檢測、緩存結構、緩存管理和緩存命中k近鄰結果計算,如圖2所示。
當用戶發起查詢請求,首先需要查找共享檢測產生的共享記錄表,確定可以重利用緩存中的歷史kNN結果。如果能夠利用緩存結果,即緩存命中,則可以根據已有的歷史kNN結果計算新查詢的kNN結果,并返回給用戶。如果不能重用歷史結果,即緩存未命中,則需要向服務器發起查詢請求,使用其它算法(INE)進行kNN查詢來獲取結果,同時需要更新緩存,對查詢結果進行共享檢測。
4 CBkNN算法
本文的主要目的是通過利用緩存的kNN查詢結果來回答新的kNN查詢,從而減少在線查詢時服務器的工作量。最直接的解決方案是新查詢和緩存的歷史查詢完全匹配,即歷史查詢點和新查詢點相同,并且歷史查詢的k值大于等于新查詢的k值,這種匹配通常被稱為緩存命中;反之,稱為緩存未命中。而在實際應用中,歷史查詢點和新查詢點相同的情況并不多見,因此提高歷史查詢結果的重復利用是本文的工作重點。
4.1 k近鄰緩存結果共享檢測
引理1 給定查詢點q,路網節點v和興趣點p。如果p是q的k近鄰結果之一,并且q到達p的最短路徑經過v,那么p也是v的k近鄰結果之一。引理1的示意圖如圖3所示。

圖3 近鄰共享
證明 假設p不是v的k近鄰結果,那么dist(v,p)>dist(v,pk),pk表示第k個近鄰結果。因為p是q的k近鄰結果之一,即dist(q,p)≤dist(q,pk),p{p1,…,pk},q到達p的最短路徑經過v,那么dist(q,p)=dist(q,v)+dist(v,p),所以dist(v,p)≤dist(q,pk)dist(q,v)≤dist(v,pk),與dist(v,p)>dist(v,pk)相矛盾,因此p也是v的k近鄰結果之一。
基于引理1作進一步延伸,如果q到k個近鄰結果的最短路徑都經過v,那么q的k近鄰結果也是v的k近鄰結果。
定義5 共享前綴。給定路網節點q和v,以及POI集合P={p1,p2,…,pk}。如果P是q的k近鄰結果,且q到前k′個近鄰POI的路徑經過v,其中1≤k′≤k,那么v是q的共享前綴,k′是共享結果值。
如圖4所示,v2是v1的共享前綴。證明,已知v1的3NN結果是p1,p2,p3,v1到前2個近鄰結果的最短路徑都經過v2,即:
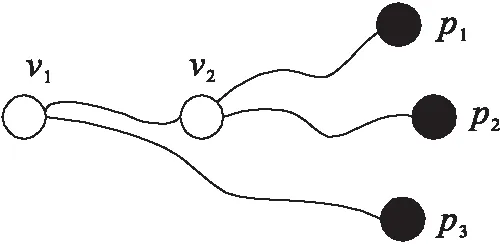
圖4 共享前綴
dist(v1,p1)≤dist(v1,p2)≤dist(v1,p3)
(1)
dist(v1,p1)=dist(v1,v2)+dist(v2,p1)
(2)
dist(v1,p2)=dist(v1,v2)+dist(v2,p2)
(3)
由公式(1)(2)(3)可知,
dist(v1,p1)-dist(v1,v2)
≤dist(v1,p2)-dist(v1,v2)
(4)
即:
dist(v2,p1)≤dist(v2,p2)
(5)
那么p1,p2也是v2的2近鄰結果,所以v2是v1的共享前綴。
通過對歷史結果進行共享前綴檢測,使更多的查詢節點重利用歷史結果,提高緩存命中率。首先,獲取q的第一個近鄰結果的最短路徑;然后,依次獲取路徑上的節點v,確認其他近鄰結果的路徑是否經過v,確定v共享結果的個數k′;最后,將(q,k′,dist(q,v))放入緩存的共享記錄表L中,其偽代碼如算法1所示。

算法1:共享前綴檢測輸入:q,kNN(q)輸出:L1.path1←kNN(q)//從kNN(q)中獲取第一個近鄰結果的路徑2.forv∈path13.k′=0//共享值初始化4.for1≤j≤k5. ifv∈pathj//確定近鄰路徑中經過相同的節點v6. k′←k′+1;7. ifk′≥k′min8. L.v←(q,k′,dist(q,v))//將(q,k′,dist(q,v))加入v的共享表L中9.returnL
4.2 緩存結構
緩存結構包括歷史查詢日志表QLogs和共享記錄表L。歷史查詢日志表存儲歷史查詢的詳細結果,共享記錄表基于節點的存儲結構,存儲每個節點可以共享的歷史查詢集合,允許新查詢快速查找歷史查詢日志表中可利用的歷史結果。
歷史查詢日志表記錄了歷史查詢點的詳細查詢結果,包括k個POI和查詢點到POI的最短路徑。其結構為:nodeID:r1,r2,…,ri,…,rk,其中ri的結構是ri:

表1 歷史查詢日志表
根據共享前綴檢測算法,對于歷史查詢日志表中的每個記錄,路徑中的每個節點都能重利用歷史結果。所以可以根據共享前綴檢測算法對歷史查詢日志表中的每個結果進行共享前綴檢測,同時共享記錄表升序記錄共享歷史查詢點和共享結果個數。共享記錄表的結構為:nodeID:

表2 共享記錄表
4.3 緩存的更新維護
由于緩存大小有限,因此在緩存已滿時,必須刪除某個使用效率低的歷史k近鄰查詢記錄,替換使用效率高的查詢記錄。本節通過探索路網中kNN查詢的獨特特征來提出一種新的緩存替換策略。
查詢點的k值越大,查詢結果中查詢點到POI的最短路徑經過的節點越多,查詢結果中共享前綴節點可能會越多,同時k值越大,代表kNN結果能夠服務的k值范圍越大,那么歷史結果被利用的可能性越大。因此,歷史查詢點的k值越大,歷史結果被重利用的可能性越大,緩存的命中率越高。為了提高緩存的命中率,本文用k值較大的結果替換k值較小的緩存結果。當新查詢點q的k值大于緩存中相同的歷史查詢點q′的k值時,用q的結果替換q′的結果,提高緩存的命中率。其算法的偽代碼如算法2所示。

算法2:緩存構建和更新輸入:q,kNN(q),C輸出:C1.ifCisnotfullthen2. Insertq.resultintoC//放入緩存3. L←kNN(q)//q結果共享檢測4. returnC5.else6. ifq.kq′.k,q′∈Cthen7. q′.result←q.result//更新緩存8. else9. C←LRU,LFU//LRU或者LFU策略更新10. L←kNN(q)//q結果共享檢測11. endif12.endif13.returnC
4.4 CBkNN算法
基于共享前綴檢測,更多的節點能夠重利用歷史kNN查詢結果,提高了緩存命中率。為了方便討論,本文對緩存命中的概念進行了如下定義:
定義6緩存命中。給定一個k近鄰查詢q,如果緩存中存在一個歷史查詢q′,q是q′的共享前綴,且共享結果值k′ ≥k,則稱為緩存命中。
本文根據緩存的歷史結果,計算新查詢的kNN結果。由定義5可知,新查詢到POI的路網距離計算模型為:
dist(q,pi)=dist(q′,pi)-dist(q′,q)
(6)
算法3展示了基于緩存的k近鄰查詢算法。步驟(1)為從共享表中獲取查詢共享的歷史查詢結果。步驟(2~3)是在緩存中查找共享的結果。步驟(4~7)是根據歷史結果計算查詢點q的k近鄰結果。步驟(8)是在緩存未命中的情況下,使用其他方法計算查詢的k近鄰結果,并更新緩存和共享表。

算法3:基于緩存的k近鄰查詢輸入:q,k,G,C輸出:R1.qAC←L //從L中獲取q的共享緩存結果2.ifqAC?andk′k//獲取第一個緩存歷史點3. Rq′←Qlogs //獲取qAC中歷史查詢k′值最大記錄4.fori=1tok,pi∈Rq′5. dist(q′,pi),dist(q′,q)←Rq′6. dist(q,pi)=dist(q′,pi)-dist(q′,q)7. R←(pi,dist(q,pi))8.elseR←INE // INE方法計算結果,并更新緩存9.returnR
5 實驗
5.1 實驗參數
本文使用真實的德國奧爾登堡地圖數據集對算法性能進行全面的評估。地圖具有6 105個節點和7 035條邊,如表3所示,實驗的默認參數用加粗字體表示。其中緩存大小|C|是地圖數據的12%。
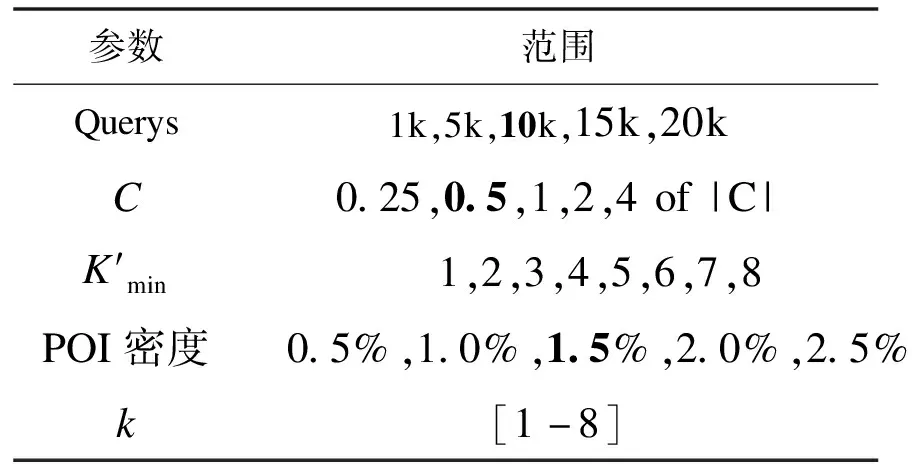
表3 實驗參數
為了模擬真實情景,保證實驗的真實性,本文在路網中設置集中查詢區域,并隨機模擬產生POI、查詢點和查詢k值。同時為了測試CBkNN算法的性能,本文使用了不同的緩存策略LRU(Least recently used)和LFU(Least frequently used)。LRU會將近期最不會訪問的數據淘汰掉,LFU淘汰近期使用頻率最小的數據。同時與INE和MkNN[1]算法進行比較,INE算法是非緩存算法,MkNN算法是重用歷史結果的算法。文獻[10]對非索引的kNN算法進行了詳細的實驗對比,INE算法的綜合性能最優,所以本文的非緩存算法采用INE算法。基于緩存的最短路徑查詢算法[11-12]使用時間節省率和命中率作為評估性能的重要指標,所以本文主要比較兩個性能參數:時間節省率和命中率。查詢時間節省率是緩存算法相對于非緩存算法的節省時間的比值,其計算公式為
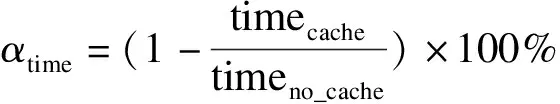
(7)
其中timeno_cache是沒有使用緩存的INE算法響應時間,timecache是使用緩存算法的響應時間,時間節省率越大代表性能越好。命中率是緩存使用效率重要指標,命中率的計算公式為
(8)
其中hitcache是緩存命中的次數,Q是查詢總數量。
5.2 實驗結果
本文以INE算法作為基礎對比實驗,通過測量緩存命中率和時間節省率檢測MkNN算法和CBkNN算法的性能,然而MkNN算法中每次查詢需要使用多個緩存結果,并不能統計出緩存命中率,所以本文并不比較MkNN算法的命中率。每組實驗只改變一個參數,其余參數設置為表3的默認值。通過實驗,本文測量了多個參數對算法性能的影響。
(1)查詢數量
圖5展示了查詢數量對算法性能的影響。從圖5中可以看出,隨著查詢數量的增多,CBkNN算法的命中率和時間節省率都在提高,最終趨于穩定。這是由于查詢數量較少時,緩存中的結果并不是集中區域的查詢,所以緩存命中率較低,時間節省率也處于較低水平。隨著查詢數量的增加,緩存中的結果經過替換變成常用查詢,命中率不斷提高,查詢時間節省率也不斷提高。圖5a中可以看出,查詢數量到達5k和15k后,LRU策略緩存和LFU策略緩存的緩存命中率以及時間節省率都趨于穩定。
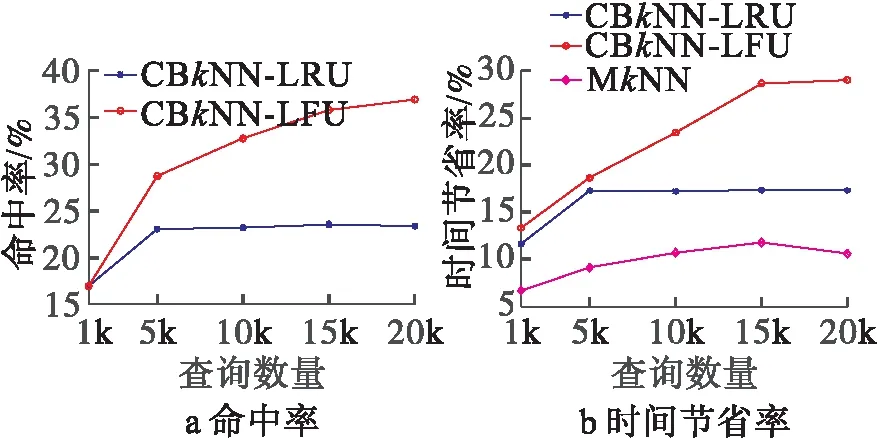
圖5 查詢數量
同時也可以發現,LFU策略的緩存性能優于LRU策略,這是由于查詢集中頻率較高的區域,LFU策略側重于查詢的頻率,而LRU側重于查詢的最近時間。從圖5b可以看出本文的CBkNN算法優于MkNN算法。這是由于MkNN算法只是使用歷史結果作為候選結果,減少查詢擴展的節點,而本文的CBkNN算法直接使用歷史結果,減少更多的擴展節點。
(2)緩存大小
緩存的大小直接決定了系統可存儲最大k近鄰結果的數量,圖6展示了緩存大小對算法性能的影響,可以看出本文的CBkNN算法性能最優。
從圖6a中可以看出,隨著緩存的增大,所有算法的緩存命中率在逐步提高。這是因為緩存越大,存儲的歷史結果越多,緩存中可以命中的查詢越多,所以緩存命中率越高。
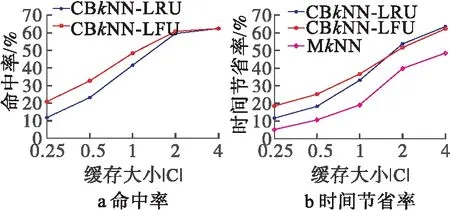
圖6 緩存大小
圖6b中可以發現,隨著緩存的增大,查詢時間節省率會逐漸減少。這是因為緩存增大,命中率提高,能夠利用緩存直接得到更多查詢結果,所以計算量減少,查詢時間節省率提高。
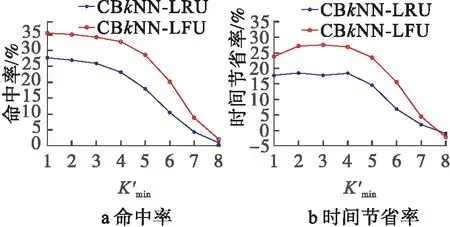
圖7 共享最小k′值
從圖7可知,共享最小k′值越大,CBkNN算法的命中率越低,查詢節省時間率越低。這是因為對緩存中的歷史結果進行共享匹配時,共享k′值越大,緩存中單個緩存能夠共享緩存結果的節點越少,導致命中率降低,節省時間率降低。
(4)POI密度
圖8為不同POI密度下的命中率和時間節省率。
從圖8中可以看出,隨著POI密度增加,CBkNN算法的命中率降低,查詢時間節省率也隨之降低。這是因為POI密度增加,查詢點到POI的路網距離減小,單個緩存結果共享前綴節點減少,所以命中率降低,時間節省率也隨之降低。
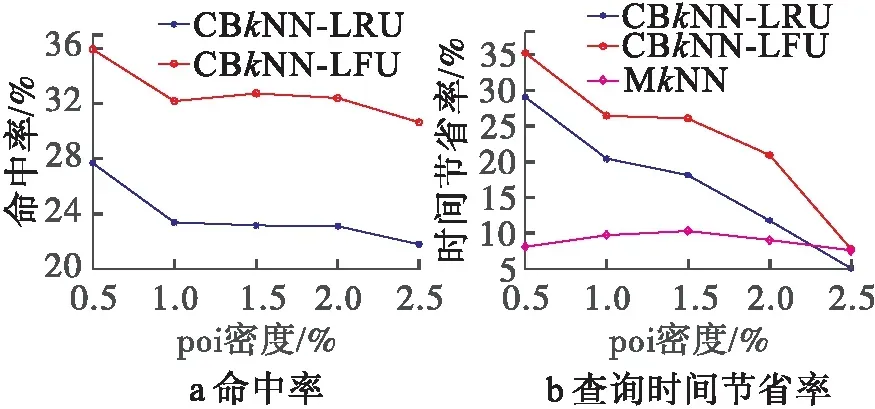
圖8 POI密度
6 結論
本文提出了一種基于歷史結果緩存的路網kNN查詢算法,提出了共享前綴匹配模型,通過對緩存結果的共享匹配,提高緩存命中率。提出基于節點的緩存存儲結構,快速查找可利用的歷史查詢結果,提高查詢共享匹配效率。實驗表明,本文的CBkNN算法與沒有緩存的INE算法相比,系統減少25%的時間延遲,與緩存算法MkNN相比響應時間減少10%。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
全體育(2016年4期)2016-11-02 18:57:28
海峽科技與產業(2016年3期)2016-05-17 04:32:12
科普童話·百科探秘(2015年6期)2015-10-13 07:21:18
科普童話·百科探秘(2015年9期)2015-09-22 07:36:52
科普童話·百科探秘(2015年8期)2015-08-14 07:13:06
