基于SOM-K-means算法的番茄果實(shí)識(shí)別與定位方法
2021-02-01 11:14:12陶涵虓崔立昊劉大為孫建桐
農(nóng)業(yè)機(jī)械學(xué)報(bào) 2021年1期
李 寒 陶涵虓 崔立昊 劉大為 孫建桐 張 漫
(1.中國(guó)農(nóng)業(yè)大學(xué)現(xiàn)代精細(xì)農(nóng)業(yè)系統(tǒng)集成研究教育部重點(diǎn)實(shí)驗(yàn)室, 北京 100083;2.中國(guó)農(nóng)業(yè)大學(xué)農(nóng)業(yè)農(nóng)村部農(nóng)業(yè)信息獲取技術(shù)重點(diǎn)實(shí)驗(yàn)室, 北京 100083)
0 引言
在農(nóng)業(yè)生產(chǎn)中,由于果實(shí)的狀態(tài)存在差異性、局部植株樣貌存在復(fù)雜性[1-2],因此目前絕大多數(shù)采摘工作由人工完成。為了節(jié)約成本、提高采摘效率,采摘機(jī)器人已廣泛使用,機(jī)器人自動(dòng)采摘時(shí)對(duì)果實(shí)的準(zhǔn)確識(shí)別已成為研究熱點(diǎn)[3-4]。自動(dòng)采摘一般分為果實(shí)識(shí)別、定位、采摘,果實(shí)識(shí)別和定位的準(zhǔn)確與否對(duì)采摘結(jié)果至關(guān)重要。
基于果實(shí)二維圖像信息,孫建桐等[5]提出一種基于幾何形態(tài)學(xué)和迭代隨機(jī)圓相結(jié)合的目標(biāo)提取算法,以分割粘連番茄果實(shí)。李寒等[6]提出,對(duì)粘連或被遮擋的番茄果實(shí)采用局部極大值法和隨機(jī)圓環(huán)變化檢測(cè)圓算法進(jìn)行目標(biāo)提取,再使用SURF算法進(jìn)行目標(biāo)匹配。SI等[7]提出通過(guò)立體匹配和隨機(jī)環(huán)算法進(jìn)行蘋果果實(shí)定位。由于沒有結(jié)合果實(shí)的深度信息,這些方法對(duì)于復(fù)雜自然環(huán)境下粘連或被遮擋的果實(shí)識(shí)別效果有限。MEHTA等[8]提出通過(guò)多個(gè)相機(jī)得到偽立體視覺,進(jìn)而對(duì)番茄進(jìn)行定位,雖然引入了立體視覺,但是需要多個(gè)相機(jī),成本較高,算法也較為復(fù)雜。
隨著科學(xué)技術(shù)的發(fā)展,RGB-D相機(jī)(可以獨(dú)立獲取彩色圖像和深度圖像的相機(jī))的出現(xiàn)為解決該問(wèn)題提供了思路[9-10]。雖然已經(jīng)有大量研究成果[11-14],但其正確識(shí)別率和識(shí)別速度還不能滿足大批量采摘的要求。
根據(jù)采摘機(jī)器人對(duì)果實(shí)進(jìn)行識(shí)別和定位的要求,需要研究一種快速、準(zhǔn)確的重疊果實(shí)分割方法[15-17]。聚類方法在圖像分割中的應(yīng)用有很多研究成果。聚類(Clustering)方法可分為劃分法、層次法、密度法、網(wǎng)格法、模型法等。自組織映射(Self-organizing map,SOM)算法在聚類模型法中較有代表性,它可以通過(guò)自身訓(xùn)練,自動(dòng)對(duì)輸入模式進(jìn)行聚類,具有簡(jiǎn)明性和實(shí)用性[18-19]。K-means算法在劃分法中有代表性,具有設(shè)計(jì)簡(jiǎn)單、收斂快速、聚類有效的特點(diǎn)[20-22]。
本文以番茄為研究對(duì)象,使用ZED相機(jī)采集圖像,綜合顏色信息和深度點(diǎn)云信息,對(duì)番茄果實(shí)的識(shí)別、分割和定位進(jìn)行研究,將SOM神經(jīng)網(wǎng)絡(luò)和K-means算法相結(jié)合,提出一種基于RGB-D圖像和K-means優(yōu)化的SOM算法(SOM-K-means)的番茄果實(shí)識(shí)別與分割方法,以解決因番茄果實(shí)粘連、遮擋而造成的圖像難以分割的問(wèn)題。
1 材料與方法
1.1 試驗(yàn)材料與設(shè)備
試驗(yàn)所用番茄圖像拍攝于中國(guó)農(nóng)業(yè)科學(xué)院番茄種植大棚內(nèi)。拍攝時(shí)間2019年1月3日15:00—16:30和2019年1月8日14:00—16:00,光線良好,試驗(yàn)圖像如圖1所示,并用游標(biāo)卡尺對(duì)每個(gè)番茄的實(shí)際半徑進(jìn)行測(cè)量。大棚內(nèi)所種番茄果實(shí)品種是實(shí)驗(yàn)品種,果實(shí)大小適中且多處存在番茄重疊現(xiàn)象。番茄是否成熟由有經(jīng)驗(yàn)的番茄采摘人員確認(rèn)。
使用Stereolabs公司生產(chǎn)的ZED相機(jī)采集圖像,該相機(jī)為雙目相機(jī),可以獲取圖像的深度信息。在Windows平臺(tái)上,通過(guò)Visual Studio 2015將ZED相機(jī)與OpenCV庫(kù)以Cmake為編譯器進(jìn)行結(jié)合,成功實(shí)現(xiàn)了對(duì)圖像三維信息的處理。
1.2 果實(shí)識(shí)別與定位方法
果實(shí)識(shí)別與定位方法包括3個(gè)步驟:RGB圖像預(yù)處理;深度點(diǎn)云處理;點(diǎn)云數(shù)據(jù)聚類及果實(shí)輪廓擬合。具體流程如圖2所示。
1.2.1RGB圖像預(yù)處理
考慮到番茄果實(shí)顏色與周圍種植環(huán)境的顯著差異,將采集到的RGB位圖進(jìn)行轉(zhuǎn)換,運(yùn)用HSV空間對(duì)番茄進(jìn)行處理,其中H、S、V分別表示圖像的色調(diào)、飽和度和亮度。首先對(duì)圖像的亮度分量V進(jìn)行脈沖噪聲判斷,若存在噪聲則對(duì)圖像進(jìn)行濾波增強(qiáng)處理。通過(guò)反復(fù)試驗(yàn),獲得成熟番茄果實(shí)的H、S、V分量的灰度取值范圍,對(duì)不在該范圍里的點(diǎn)進(jìn)行過(guò)濾,再經(jīng)過(guò)二值化得到將番茄果實(shí)與其他物體分開的二值圖像。關(guān)于閾值的選取,由于實(shí)際果實(shí)檢測(cè)時(shí)是實(shí)時(shí)拍攝,使用自適應(yīng)取值會(huì)導(dǎo)致延遲較長(zhǎng),不利于實(shí)際采摘。所以本文方法以番茄果實(shí)是否成熟為界限,經(jīng)數(shù)據(jù)分析和測(cè)試,設(shè)定H、S、V分量的灰度范圍分別為0~20、170~180,110~255,46~255,從而對(duì)圖像進(jìn)行分割,剔除灰度范圍外的部分,實(shí)現(xiàn)成熟番茄果實(shí)的分割。對(duì)二值圖像進(jìn)行分割,利用形態(tài)學(xué)閉運(yùn)算去掉內(nèi)部輪廓、小輪廓以降低誤識(shí)別率。但由于在實(shí)際采摘過(guò)程中,番茄會(huì)出現(xiàn)葉子遮擋、粘連的情況,因此還需要根據(jù)圖像的深度信息對(duì)不同番茄果實(shí)進(jìn)行分離。
1.2.2深度點(diǎn)云處理
ZED相機(jī)提供了雙目立體視覺的功能,因此可以生成圖像的深度圖,如圖3所示。ZED相機(jī)可以檢測(cè)的有效范圍是0.3~5 m。較淺的顏色表示距離較小;較深的顏色表示距離較大。完全黑色的點(diǎn)表示檢測(cè)距離超出了ZED相機(jī)的有效檢測(cè)范圍。這些點(diǎn)的深度是非數(shù)字的,被濾除。
在圖3中,不同顏色輪廓上點(diǎn)的深度差大于同一個(gè)番茄果實(shí)輪廓上點(diǎn)的深度差的最大值,表明這些點(diǎn)屬于不同的番茄果實(shí)輪廓。
使用ZED相機(jī)獲取圖像分割信息的同時(shí)也可以獲得輪廓矢量信息。輪廓矢量中的每個(gè)元素都是一個(gè)點(diǎn)結(jié)構(gòu)。在深度圖中讀取每個(gè)點(diǎn)的三維坐標(biāo)信息;之后遍歷這些點(diǎn),通過(guò)ZED相機(jī)自帶的getValue函數(shù)對(duì)圖像進(jìn)行三維重建,將世界坐標(biāo)系轉(zhuǎn)換為相機(jī)坐標(biāo)系進(jìn)而得到點(diǎn)云中的點(diǎn)在相機(jī)坐標(biāo)下的三維坐標(biāo)信息。通過(guò)輸入輸出流把點(diǎn)云的三維坐標(biāo)信息導(dǎo)入到本地文件中并具體分為二維坐標(biāo)和深度信息。考慮到ZED相機(jī)識(shí)別距離范圍的局限性,為了提高SOM神經(jīng)網(wǎng)絡(luò)聚類的準(zhǔn)確性,在獲取數(shù)據(jù)文件后,對(duì)數(shù)據(jù)進(jìn)行過(guò)濾,通過(guò)密度聚類對(duì)具有高分散性的點(diǎn)進(jìn)行濾波,以獲得精度更高的點(diǎn)。
1.2.3點(diǎn)云數(shù)據(jù)聚類及果實(shí)輪廓擬合
本文用K-means算法對(duì)SOM算法進(jìn)行優(yōu)化,提出SOM-K-means聚類算法。將已獲取的點(diǎn)云數(shù)據(jù)進(jìn)行處理后,使用SOM-K-means算法對(duì)其進(jìn)行聚類,進(jìn)一步得到識(shí)別和定位結(jié)果。
(1)SOM算法
SOM算法是一種聚類和高維可視化的無(wú)監(jiān)督學(xué)習(xí)算法。SOM 神經(jīng)網(wǎng)絡(luò)是一種非監(jiān)督、自適應(yīng)、自組織的網(wǎng)絡(luò),它由輸入層與輸出層(也叫作競(jìng)爭(zhēng)層)組成,輸出層中的一個(gè)節(jié)點(diǎn)代表一個(gè)需要聚成的類。訓(xùn)練時(shí)采用“競(jìng)爭(zhēng)學(xué)習(xí)”的方式,每個(gè)輸入的樣例在輸出層中找到一個(gè)和它最相似的節(jié)點(diǎn),稱為激活節(jié)點(diǎn)。接著對(duì)激活節(jié)點(diǎn)的參數(shù)進(jìn)行更新,同時(shí),和激活節(jié)點(diǎn)臨近的點(diǎn)也根據(jù)它們距激活節(jié)點(diǎn)的距離適當(dāng)更新參數(shù)。
設(shè)輸入樣本為X=(x1,x2, …,xn),是一個(gè)n維向量,則輸入層由n個(gè)輸入神經(jīng)元組成;輸出層Wi=(wi1,wi2, …,win),1≤i≤m,有m個(gè)權(quán)值向量,則輸出層由m個(gè)輸出神經(jīng)元組成。輸入層與輸出層中的神經(jīng)元互相連接,其結(jié)構(gòu)如圖4所示。
SOM算法的步驟如下:①初始化,設(shè)定網(wǎng)絡(luò)的權(quán)值、學(xué)習(xí)率初值、鄰域半徑以及學(xué)習(xí)次數(shù)。權(quán)值使用較小的隨機(jī)值進(jìn)行初始化,并對(duì)輸入向量和權(quán)值做歸一化處理
X′=X/‖X‖
(1)
W′i=Wi/‖Wi‖
(2)
式中X′——進(jìn)行歸一化處理后的輸入向量
W′i——進(jìn)行歸一化處理后的權(quán)值向量
②采樣并隨機(jī)選取輸入量,將數(shù)據(jù)集中的樣本輸入到神經(jīng)網(wǎng)絡(luò)中。③樣本與權(quán)值向量做點(diǎn)積,進(jìn)行競(jìng)爭(zhēng),點(diǎn)積值最大的輸出神經(jīng)元記為該樣本的獲勝神經(jīng)元。④對(duì)權(quán)值進(jìn)行更新,對(duì)獲勝的神經(jīng)元及其拓?fù)溧徲騼?nèi)的神經(jīng)元的權(quán)值進(jìn)行更新。
W(t+1)=W(t)+η(t,d)(X-W(t))
(3)
其中
η(t,d)=η(t)e-d
(4)
式中t——訓(xùn)練時(shí)間
d——獲勝神經(jīng)元的拓?fù)渚嚯x
η——學(xué)習(xí)率,是關(guān)于t與d的函數(shù)
W(t)——更新前的權(quán)值
其中,η(t)一般取迭代次數(shù)的倒數(shù)。⑤更新學(xué)習(xí)率η及拓?fù)溧徲騈, 其中,N隨時(shí)間增大距離變小。⑥判斷模型是否收斂,如果學(xué)習(xí)率η≤ηmin或達(dá)到預(yù)設(shè)的迭代次數(shù),結(jié)束算法,否則跳轉(zhuǎn)到步驟②。
該算法的優(yōu)點(diǎn)是無(wú)需監(jiān)督,無(wú)需提前告知分類數(shù)便能自動(dòng)對(duì)輸入模式進(jìn)行聚類,容錯(cuò)性強(qiáng),對(duì)異常值和噪聲不敏感。其缺點(diǎn)是在訓(xùn)練數(shù)據(jù)時(shí)會(huì)出現(xiàn)有些神經(jīng)元始終不能勝出,導(dǎo)致分類結(jié)果不準(zhǔn)確;SOM網(wǎng)絡(luò)收斂時(shí)間較長(zhǎng),運(yùn)算效率較低。
(2)K-means算法
K-means算法采用距離作為相似性的評(píng)價(jià)指標(biāo),即數(shù)據(jù)對(duì)象間的距離越小,則它們的相似性越高,越有可能為同一個(gè)類簇,并把得到緊湊且獨(dú)立的簇作為最終目標(biāo)。
K-means算法步驟如下:①?gòu)臄?shù)據(jù)集中隨機(jī)選取k個(gè)數(shù)據(jù)對(duì)象作為k個(gè)簇的初始聚類中心點(diǎn)。②計(jì)算剩余每個(gè)數(shù)據(jù)對(duì)象與各個(gè)簇的聚類中心之間的距離,并把每個(gè)數(shù)據(jù)對(duì)象歸到距離它最近的聚類中心的類。③更新每個(gè)簇的聚類中心,即根據(jù)聚類中現(xiàn)有的對(duì)象重新計(jì)算每個(gè)簇的聚類中心,以各個(gè)簇內(nèi)所有對(duì)象的平均值作為新的聚類中心。④重復(fù)步驟②、③直至新的聚類中心與原聚類中心相等或小于指定閾值,算法結(jié)束。
該算法的優(yōu)點(diǎn)是算法快速、簡(jiǎn)單,收斂速度快;缺點(diǎn)是初始聚類中心的設(shè)定對(duì)于聚類結(jié)果影響較大;聚類種數(shù)k需要預(yù)先給定,而在很多情況下k的估計(jì)是非常困難的。
(3)SOM-K-means算法
基于SOM算法和K-means 算法的步驟以及各自的優(yōu)劣,本研究將二者結(jié)合,對(duì)SOM算法進(jìn)行優(yōu)化。由于SOM算法無(wú)需提前告知分類數(shù)便能自動(dòng)對(duì)輸入模式進(jìn)行聚類,但在訓(xùn)練數(shù)據(jù)時(shí)可能出現(xiàn)有些神經(jīng)元始終不能勝出,導(dǎo)致分類結(jié)果不準(zhǔn)確,且網(wǎng)絡(luò)收斂時(shí)間較長(zhǎng);而K-means算法的優(yōu)點(diǎn)便是收斂速度快,但初始聚類中心和k的大小很難提前確定。因此,本文提出SOM-K-means算法,即SOM的優(yōu)化算法,將SOM與K-means算法結(jié)合,既解決了K-means算法中初始聚類中心和k的設(shè)定問(wèn)題,又克服了SOM算法中網(wǎng)絡(luò)收斂較慢、分類結(jié)果不準(zhǔn)確的缺陷。
SOM-K-means算法步驟如下:①將數(shù)據(jù)集輸入到SOM神經(jīng)網(wǎng)絡(luò)中進(jìn)行聚類,輸出分類種數(shù)以及初步分類結(jié)果。②將步驟①中得到的分類種數(shù)作為k值,分類結(jié)果中每一類中隨機(jī)取一個(gè)數(shù)據(jù)對(duì)象作為初始聚類中心,執(zhí)行K-means算法進(jìn)行聚類并得到最終結(jié)果。
本文算法在保持 SOM 網(wǎng)絡(luò)自組織特性的同時(shí),創(chuàng)新性地將SOM算法和K-means算法相結(jié)合,融合了SOM和K-means算法的優(yōu)點(diǎn),又彌補(bǔ)了兩種算法的缺陷,在分類結(jié)果的準(zhǔn)確度和運(yùn)算效率上都有了較大的提高。SOM-K-means算法的流程圖如圖5所示。

1.2.4算法性能評(píng)價(jià)
經(jīng)上述操作后能得到番茄識(shí)別結(jié)果,進(jìn)而對(duì)識(shí)別和定位結(jié)果進(jìn)行分析。本試驗(yàn)通過(guò)正確識(shí)別番茄個(gè)數(shù)與圖中實(shí)際番茄數(shù)是否相等來(lái)評(píng)價(jià)識(shí)別結(jié)果;通過(guò)果實(shí)實(shí)際半徑與擬合輪廓半徑比較來(lái)對(duì)果實(shí)定位精度進(jìn)行評(píng)價(jià)。
在結(jié)果分析中,首先將圖像的相機(jī)坐標(biāo)系轉(zhuǎn)換為世界坐標(biāo)系,以便與真實(shí)值進(jìn)行比較,進(jìn)而對(duì)識(shí)別結(jié)果和定位精度進(jìn)行評(píng)價(jià)。
對(duì)于識(shí)別結(jié)果的評(píng)價(jià),統(tǒng)計(jì)圖像中實(shí)際番茄個(gè)數(shù)、算法識(shí)別番茄個(gè)數(shù)、算法漏識(shí)別番茄個(gè)數(shù)、正確識(shí)別番茄個(gè)數(shù)、錯(cuò)誤識(shí)別番茄個(gè)數(shù)。輸出結(jié)果中,黃色的圓為算法識(shí)別的番茄輪廓,算法識(shí)別番茄個(gè)數(shù)即為圖中黃色圓的個(gè)數(shù),正確識(shí)別番茄個(gè)數(shù)即為圖中黃色圓本身與實(shí)際番茄果實(shí)半徑和圓心誤差分別不超過(guò)5.00 mm和3.00 mm的黃色圓個(gè)數(shù),錯(cuò)誤識(shí)別番茄個(gè)數(shù)即為圖中黃色圓本身與實(shí)際番茄果實(shí)半徑和圓心誤差分別大于5.00 mm和3.00 mm的黃色圓個(gè)數(shù)。由正確識(shí)別的番茄個(gè)數(shù)占實(shí)際番茄個(gè)數(shù)的比例計(jì)算出識(shí)別的正確率。
對(duì)于定位精度的驗(yàn)證,隨機(jī)抽取結(jié)果圖的部分樣本,通過(guò)比較實(shí)際番茄半徑和擬合輪廓半徑,計(jì)算出識(shí)別結(jié)果的均方根誤差、平均偏差、平均相對(duì)誤差。
2 試驗(yàn)結(jié)果與分析
從采集的圖像中隨機(jī)選取80幅作為樣本,每幅圖像根據(jù)番茄果實(shí)的數(shù)量和尺寸可以得到600~2 000個(gè)信息點(diǎn)。使用SOM-K-means算法對(duì)其處理之后,統(tǒng)計(jì)識(shí)別結(jié)果的混淆矩陣來(lái)對(duì)該方法進(jìn)行評(píng)估。通過(guò)統(tǒng)計(jì)和計(jì)算得到試驗(yàn)的準(zhǔn)確率、精確率、靈敏度、特異度4個(gè)指標(biāo)值,并對(duì)該算法的可靠性進(jìn)行分析。
2.1 圖像處理與數(shù)據(jù)采集
圖像預(yù)處理過(guò)程中的中間圖像如圖6所示。
對(duì)捕獲的圖像進(jìn)行預(yù)處理,獲得分割的番茄輪廓點(diǎn)云。從原始圖像及其深度圖獲得點(diǎn)云的3D信息。經(jīng)過(guò)三維重建后,真實(shí)世界點(diǎn)云的信息通過(guò)C++中的輸入和輸出保存到創(chuàng)建的試驗(yàn)文件中。
在試驗(yàn)中發(fā)現(xiàn)實(shí)際拍攝過(guò)程中,點(diǎn)云信息中會(huì)有一些誤判的點(diǎn),這種點(diǎn)一般比較離散。選取最小輪廓的點(diǎn)數(shù)為30,運(yùn)用密度聚類方法,把偏離密集區(qū)域的點(diǎn)去掉,提高點(diǎn)云矩陣信息的容錯(cuò)性和正確率。
2.2 SOM-K-means算法識(shí)別結(jié)果
執(zhí)行SOM-K-means算法后,果實(shí)輪廓點(diǎn)云的聚類結(jié)果如圖7所示。圖中每個(gè)點(diǎn)表示輪廓上的一個(gè)點(diǎn),縱坐標(biāo)是深度,橫坐標(biāo)表示二維信息。由圖7可知,該算法共識(shí)別出3個(gè)番茄果實(shí)。
利用最小二乘法分別擬合出各類點(diǎn)所屬的圓,結(jié)果如圖8所示。在圖8中,有3個(gè)成熟的番茄果實(shí)。將相機(jī)坐標(biāo)系轉(zhuǎn)換為世界坐標(biāo)系,并通過(guò)測(cè)量和計(jì)算得到擬合圓與對(duì)應(yīng)番茄果實(shí)的半徑和圓心誤差均小于誤差閾值,即3個(gè)番茄果實(shí)均識(shí)別正確。另外,由于番茄果實(shí)輪廓并不是完全的圓形,因此擬合的圓與果實(shí)實(shí)際輪廓有一定的誤差。
2.3 結(jié)果統(tǒng)計(jì)與驗(yàn)證
對(duì)80幅樣本圖像進(jìn)行預(yù)處理,執(zhí)行SOM-K-means算法并輸出結(jié)果,統(tǒng)計(jì)圖像中實(shí)際番茄個(gè)數(shù)、算法識(shí)別番茄個(gè)數(shù)、算法漏識(shí)別番茄個(gè)數(shù)、正確識(shí)別番茄個(gè)數(shù)、錯(cuò)誤識(shí)別番茄個(gè)數(shù),并對(duì)識(shí)別結(jié)果進(jìn)行分析。以圖8為例,根據(jù)1.2.4節(jié)的評(píng)價(jià)指標(biāo),圖中實(shí)際番茄果實(shí)個(gè)數(shù)為3個(gè),算法識(shí)別番茄果實(shí)個(gè)數(shù)為3個(gè),算法漏識(shí)別番茄果實(shí)個(gè)數(shù)為0個(gè),正確識(shí)別番茄果實(shí)的個(gè)數(shù)為3個(gè),錯(cuò)誤識(shí)別番茄果實(shí)的個(gè)數(shù)為0個(gè)。
此外,試驗(yàn)中的80幅圖像樣本包含了不同自然環(huán)境下的番茄果實(shí)圖像,圖9為部分圖像的果實(shí)識(shí)別和定位結(jié)果。從圖中可以看出,本文算法對(duì)于有葉子遮擋的多個(gè)粘連番茄果實(shí)、有未成熟番茄遮擋的多個(gè)成熟番茄果實(shí)、較暗環(huán)境下的重疊番茄果實(shí)、較強(qiáng)光照下的重疊番茄果實(shí)均具有較強(qiáng)的魯棒性。
對(duì)80幅圖像樣本的識(shí)別結(jié)果進(jìn)行統(tǒng)計(jì)和計(jì)算,得到試驗(yàn)的識(shí)別率、漏識(shí)別率、正確識(shí)別率和錯(cuò)誤識(shí)別率如表1所示,識(shí)別率為92.0%,正確識(shí)別率為87.2%。

表1 果實(shí)識(shí)別結(jié)果Tab.1 Fruit recognition results
隨機(jī)選擇15幅圖像以測(cè)試定位精度。表2為番茄果實(shí)擬合輪廓半徑、實(shí)際測(cè)量半徑、偏差和相對(duì)誤差。擬合輪廓半徑為圖中擬合圓的半徑,實(shí)際測(cè)量半徑為用游標(biāo)卡尺手動(dòng)測(cè)量的番茄果實(shí)半徑,單位均為mm,精度均為0.01 mm。識(shí)別結(jié)果的均方根誤差(RMSE)為1.66 mm,平均相對(duì)誤差為3.95%。
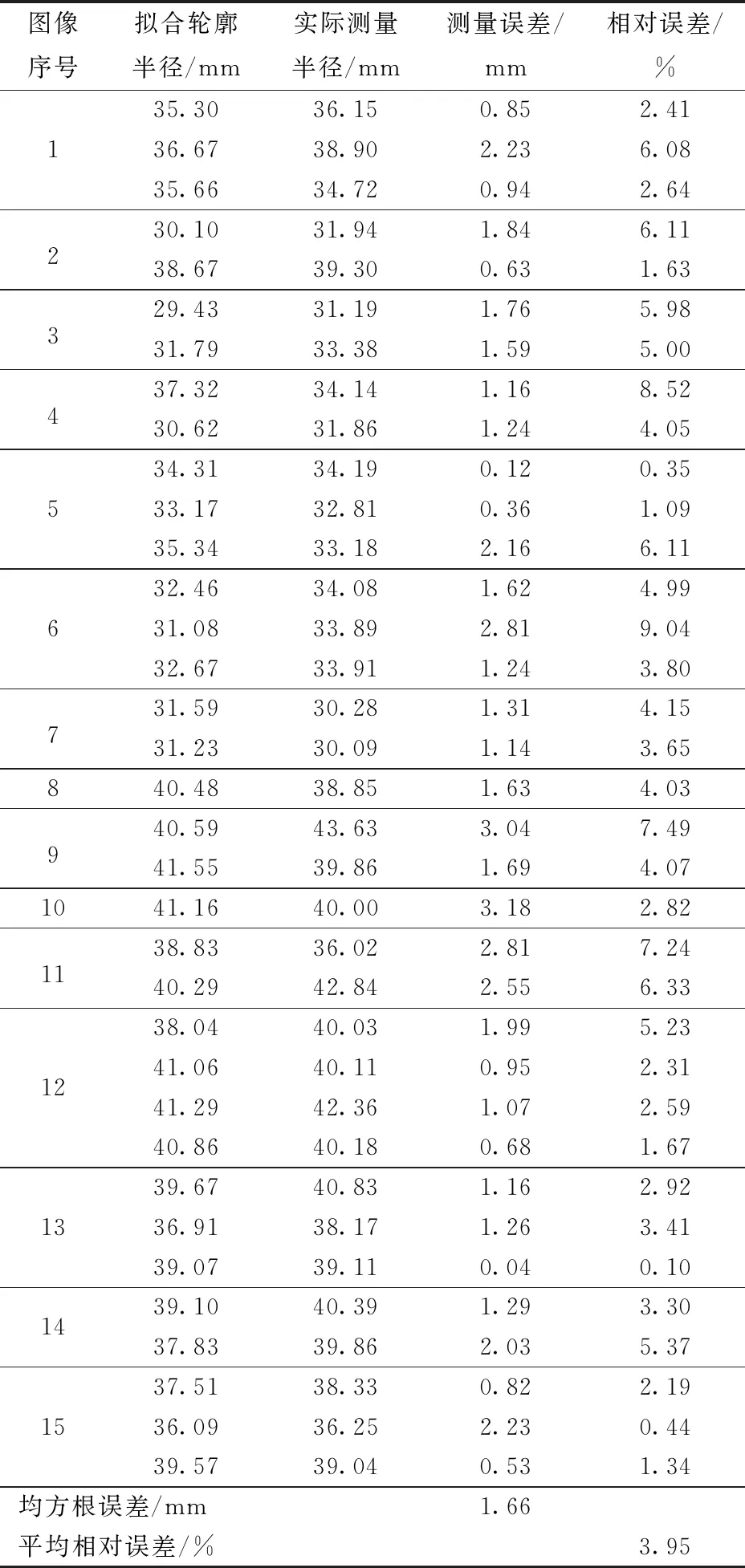
表2 番茄果實(shí)實(shí)際測(cè)量半徑與擬合輪廓半徑Tab.2 Actual measured radius and fitted contour radius of tomato fruit
3 對(duì)比試驗(yàn)與分析
為進(jìn)一步驗(yàn)證本文方法的性能,加入對(duì)比試驗(yàn),將其與在二維圖像上利用Hough變換進(jìn)行果實(shí)識(shí)別的傳統(tǒng)方法進(jìn)行比較。
選取與上述試驗(yàn)相同的圖像樣本,采用在二維圖像上利用Hough變換進(jìn)行果實(shí)識(shí)別,將其識(shí)別結(jié)果與本文方法進(jìn)行對(duì)比。對(duì)比試驗(yàn)中,根據(jù)采集的輸入圖像對(duì)Hough變換進(jìn)行了改進(jìn):修改CIRCLE_HOUGHPEAKS函數(shù)中的Threshold變量,改成對(duì)圓投票數(shù)矩陣最大值的0.99倍,相當(dāng)于取最大值投票數(shù)99%的圓心和半徑。由此得到的識(shí)別結(jié)果如表3所示。

表3 對(duì)比試驗(yàn)的番茄果實(shí)識(shí)別結(jié)果Tab.3 Tomato fruit recognition results of comparative experiments
由對(duì)比試驗(yàn)結(jié)果可知,采用二維平面上的霍夫圓方法對(duì)果實(shí)進(jìn)行識(shí)別的正確識(shí)別率為69.0%,比本文方法低了18.2個(gè)百分點(diǎn)。因此,在番茄重疊情況比較復(fù)雜的情況下,本文方法的性能相較在二維平面上利用Hough變換的方法有了明顯的提升。
結(jié)合試驗(yàn)過(guò)程和結(jié)果,將兩種方法進(jìn)行對(duì)比分析。在二維圖像上利用Hough變換的方法需要提前輸入的參數(shù)較多,包括番茄果實(shí)個(gè)數(shù)和半徑范圍,以及設(shè)置參數(shù)投票矩陣閾值,選取投票率高的圓心和半徑;且其在識(shí)別過(guò)程中對(duì)于圖像中干擾項(xiàng)的處理能力不強(qiáng),導(dǎo)致在非番茄區(qū)域也出現(xiàn)了很多圓,從而有相當(dāng)一部分的投票從番茄區(qū)域流失,增加了錯(cuò)誤率。本文方法則首先對(duì)圖像進(jìn)行預(yù)處理,通過(guò)顏色、亮度等信息能夠很好地識(shí)別番茄區(qū)域,然后利用果實(shí)輪廓的三維信息進(jìn)行聚類從而識(shí)別到重疊番茄,其中深度信息的獲取對(duì)于識(shí)別和定位重疊番茄尤為重要。因此本文提出方法的正確識(shí)別率較高,且在比較復(fù)雜的情況下具有較強(qiáng)的魯棒性。
4 結(jié)論
(1)針對(duì)重疊番茄果實(shí)難以分割與識(shí)別的問(wèn)題,提出一種基于RGB-D圖像與改進(jìn)的SOM-K-means算法的番茄果實(shí)識(shí)別方法。在二維圖像的基礎(chǔ)上,提取輪廓點(diǎn)的深度信息進(jìn)行三維聚類;聚類時(shí)結(jié)合SOM算法和K-means算法的優(yōu)點(diǎn)對(duì)SOM算法進(jìn)行優(yōu)化,提出改進(jìn)的SOM-K-means算法,有效提高了運(yùn)算效率和果實(shí)識(shí)別的綜合性能。經(jīng)過(guò)大量試驗(yàn),得出本文方法的正確識(shí)別率為87.2%。
(2)RGB-D相機(jī)對(duì)成熟番茄果實(shí)的定位結(jié)果均方根誤差(RMSE)為1.66 mm,平均相對(duì)誤差為3.95%,基本滿足采摘機(jī)器人的要求。
(3)本試驗(yàn)綜合輪廓的深度信息,通過(guò)聚類將重疊果實(shí)的輪廓分開,然后分別進(jìn)行圓擬合,在番茄果實(shí)識(shí)別定位方面,比傳統(tǒng)的在二維平面上利用Hough變換進(jìn)行果實(shí)識(shí)別定位的方法具有更高的準(zhǔn)確性和更強(qiáng)的魯棒性。
