區間值數據的代價敏感特征選擇
2021-01-30 14:00:50代建華陳姣龍
南京大學學報(自然科學版) 2021年1期
劉 瓊 ,代建華* ,陳姣龍
(1.智能計算與語言信息處理湖南省重點實驗室,湖南師范大學,長沙,410081;2.湖南師范大學信息科學與工程學院,長沙,410081)
隨著社會的快速發展,存在的數據也越來越多,數據中往往包含有不確定性,而區間數據是一個重要的類型.一方面,客觀上由于測量、計算所帶來的數據誤差往往不是一個確定的數,而是一個區間范圍;另一方面,主觀上人們在描述和理解某些數據時,也更傾向一個區間范圍,而不是一個確定的值,比如身高、體重、收入等.高維的區間值數據在現實生活中廣泛存在,因此研究區間值數據的特征選擇具有重要的意義.針對區間值數據的特征選擇問題,學者已進行了相關研究.例如,Du and Hu[1]提出區間值有序決策表的近似分布約簡.Yang et al[2]提出基于α 序關系區間值信息系統屬性約簡.Dai et al[3]在區間值決策系統中利用概率方法建立優勢度的模糊粗糙集模型,并利用該模型進行近似分布約簡.Li[4]提出基于區間值信息系統的模糊概念格的特征選擇方法.Dai et al[5]提出基于不完備區間值決策系統的特征選擇.尹繼亮等[6]提出區間值決策系統的局部屬性約簡.Shu et al[7]提出基于不確定度量的區間值缺失屬性約簡.閆岳君和代建華[8]提出區間序信息系統的無監督特征選擇.
值得注意的是,上述針對區間數據的特征選擇方法沒有考慮數據自身的測試代價和誤分類代價.代價敏感在數據挖掘和機器學習中得到了廣泛的關注[9-14].在代價敏感的應用中,代價可以用許多不同的單位來度量,例如在醫學領域里,代價可以是非癌癥患者被誤判為癌癥患者的可能.在圖像識別中,代價可以是被錯誤分類的損失.本文考慮到測試代價和誤分類代價,研究代價敏感區間數據特征選擇.首先,利用鄰域粗糙集給出區間值鄰域的概念,并通過區間值鄰域進行分類,進而重定義基于區間值鄰域的熵結構;其次,構造了區間值系統下的代價敏感函數,引入測試代價和誤分類代價,并提出基于代價敏感的區間值特征選擇方法;最后,通過實驗驗證了本文方法的有效性.本文的主要貢獻有:
(1)利用KL 散度度量兩個區間值之間的關聯,并構造了區間值鄰域,進而重新定義了區間值鄰域的熵結構;
(2)構造區間值系統下的代價敏感函數,代價敏感函數有效地考慮了區間值數據自身的測試代價和誤分類代價;
(3)提出基于代價敏感的區間值特征選擇方法,該方法可以選擇代價較小但擁有較多有效信息量的特征.
1 預備知識
本節重點回顧一些相關概念.

顯然,IND(C)具有自反性、對稱性和傳遞性.U/IND(C)表示所有等價類IND(C)的族,可以簡寫為U/C.
定義1是一個決策信息系統,其中U是非空有限對象集合,稱為論域;C為條件特征集合,D為決策特征集合;V是所有特征域的并集,B?C,關于特征集B的信息熵定義如下:
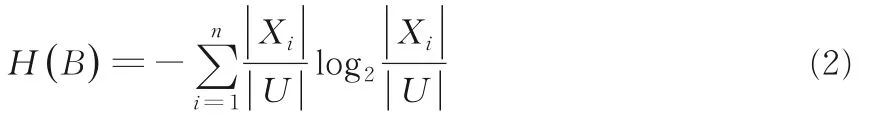
定義2是一個決策信息系統,其中U是非空有限對象集合,C為條件特征集合,D為決策特征集合;V是所有特征域的并集,B,Y2,…,Ym} .特征集B和K的聯合熵定義為:
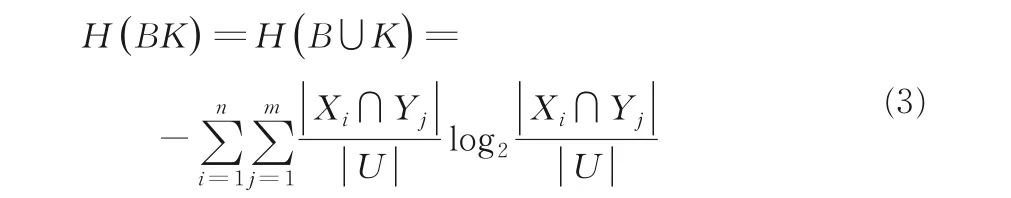
定義3是一個決策信息系統,其中U是非空有限對象集合,C為條件特征集合,D表示決策特征,V是所有特征域的并集,…,Ym} .條件特征集P關于決策特征D的條件熵定義為:

定義4是一個決策信息系統,其中U是非空有限對象集合,C為條件特征集合,D表示決策特征,V是所有特征域的并集,…,Ym} .特征集合P和決策特征D的互信息定義為:
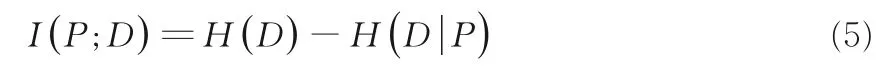
對于一個正態分布,μ是數學期望,σ是標準差,x位于區間(μ-3σ,μ+3σ)外的概率小于0.3%.在實際問題中,往往認為當置信水平達到95%時,已具備統計學意義.考慮到區間值數據為一段有限區間,而分布是無限的,因此本文通過使用合適的參數,使得區間盡可能落在95%的置信區間內.任意給定一個區間[a,b],本文取區間中值作為期望值作為標準差,這樣就構成一個正態分布S~N(μ,σ2),以滿足該區間[a,b]具備統計學意義[15].
定義5設P~N是兩個正態分布,則關于P,Q兩個分布之間的距離可利用KL 散度定義:
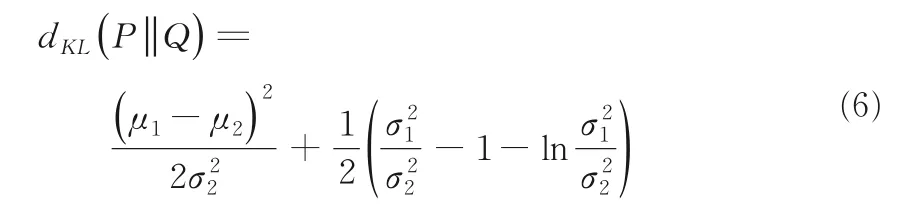
考慮到KL 散度不滿足對稱性,因此對于兩個分布之間的距離度量可重定義為如下形式:
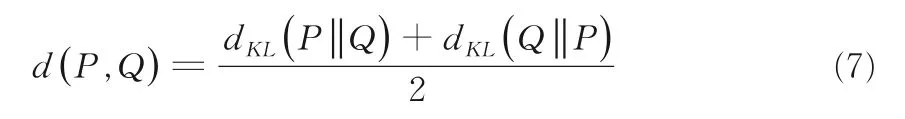
2 基于區間分類誤差的鄰域粗糙集
本節提出基于區間分類誤差的鄰域粗糙集模型(Interval-Classification-Error-Based Neighborhood Rough Set Model)并證明一些相關性質.是一個鄰域決策信息系統,其中U={x1,x2,…,xn}是n維對象集合,稱為論域;C為所有條件特征集合;D表示決策特征,N為樣本關于特征的鄰域映射函數,其中?x∈U,a∈C,Na(x)={y∈U|da(x,y)≤δ} .
定義6是一個鄰域決策信息系統,其中U={x1,x2,…,xn}為n維對象集合,C為所有條件特征集合;D表示決策特征,N為樣本關于特征的鄰域映射函數.設a∈C,x∈U.對于任意對象區間值[n,m],首先取區間中值作為期望值作為標準差,這樣就構成一個滿足統計學意義的正態分布,然后基于式(6)和式(7)定義對象x在特征a下的鄰域:
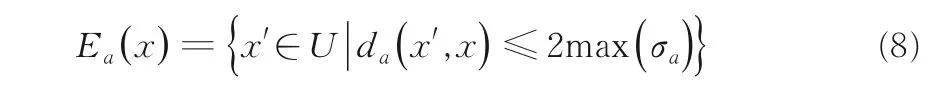
da(x',x)表示對象x'和x在特征a下的兩個分布之間的距離,max(σa)表示特征a下所有對象的最大標準差,也稱為上邊界域.
設特征a的測量誤差值都在區間[-b,b]之間,對特征a來說,對象x的真實值是a'(x).但是由于測量誤差的原因,其測量值a(x)會在一個區間范圍內,即a'(x)-b≤a(x) ≤a'(x)+b.特別地,在極端情況下,同一對象的觀測值可能是從端點取得的,即a-b或a+b.則有(a'(x)+b)-(a'(x)-b)=2b,所以觀測值不應超過2b,故本文的鄰域差設計為2max(σa).
定義7是一個鄰域決策信息系統,其中U={x1,x2,…,xn}為n維對象集合,C為所有條件特征集合,D表示決策特征,N為樣本關于特征的鄰域映射函數.設B?C,?x∈U,對象x關于特征集合B的鄰域定義為:

根據定義7 得出以下性質:
性質1是一個鄰域決策信息系統,P?C,?x∈U,EP(x) 滿足以下性質:
(1)自反性:?x∈U,x∈EP(x);
(2)對稱性:?xi,xj∈U,如果xj∈EP(xi)則xi∈EP(xj).
證 明
(1)根據式(8)和式(9),?a∈P,x∈U,有da(x',x) ≤2 max (σa),而da(x,x)=0 且max (σa)≥0,則?x∈U,x∈Ea(x),然后根據式(9)可得?x∈U,x∈EP(x).
(2)因為?xi,xj∈U,xj∈EP(xi),根據式(9)可知,?a∈P,xi,xj∈U有xj∈Ea(xi),從式(8)可以明顯看出Ea(x)具有對稱性,故?a∈P,xi,xj∈U有xi∈Ea(xj),從而有xi∈EP(xj).
給定一個非空特征集合P,RP是定義在特征P上的鄰域等價關系,用關系矩陣?M(RP)表示:
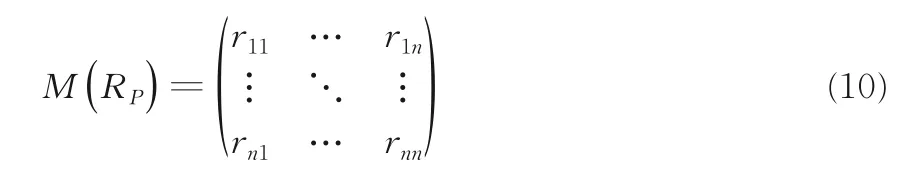
其中,rij是xi和xj的關系值,也可以寫作RP(xi,xj),n=|U|,?xi,xj∈U,若xj∈EP(xi)或xi∈EP(xj)則rij=1,否則rij=0.
根據性質1 可以得到RP滿足自反性rii=1 和對稱性rij=rji.
任意給定一個非空特征集合P1,P2,RP1,RP2是分別定義在特征集合P1,P2上的鄰域等價關系.?x,y∈U,幾種關系矩陣的運算方式定義如下:
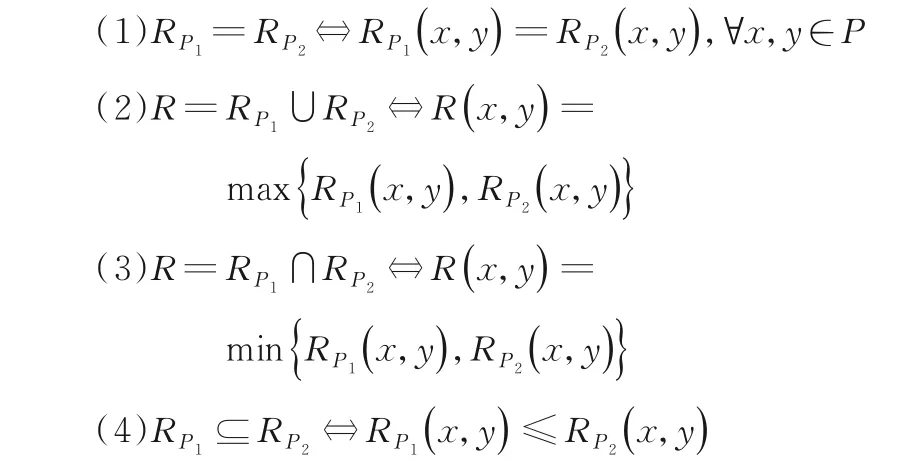
定義8[xi]R基數定義如下:

定義9給定一個鄰域決策信息系統NS=,其中U={x1,x2,…,xn}為n維對象集合,C為所有條件特征集合,D表示決策特征,N為樣本關于特征的鄰域映射函數.設A?C,R為特征集A上的鄰域等價關系.關于特征集A的信息熵可以定義為如下形式:
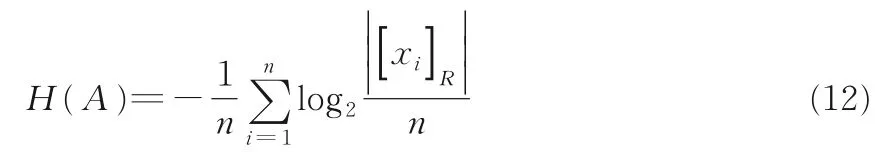
定義10給定一個鄰域決策信息系統NS=其中U={x1,x2,…,xn}為n維對象集合,C為所有條件屬性集合;D表示決策屬性,N為樣本關于屬性的鄰域映射函數.設B,K?C,[xi]B和[xi]K分別是屬性集B,K上的等價類.關于屬性集B和K的聯合熵的定義如下所示:
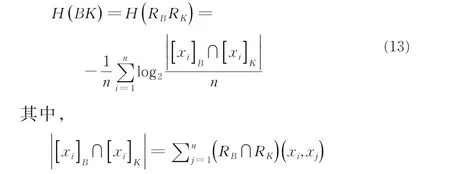
RB,RK分別表示定義在屬性集B,K上的鄰域等價關系.
定義11給定一個鄰域信息系統NS=,其中U={x1,x2,…,xn}為n維對象集合,C為所有條件屬性集合;D表示決策屬性,N為樣本關于屬性的鄰域映射函數.設P?C,[xi]P和[xi]D分別是屬性集P,D上的等價類.條件屬性集P關于決策屬性D的條件熵定義如下:
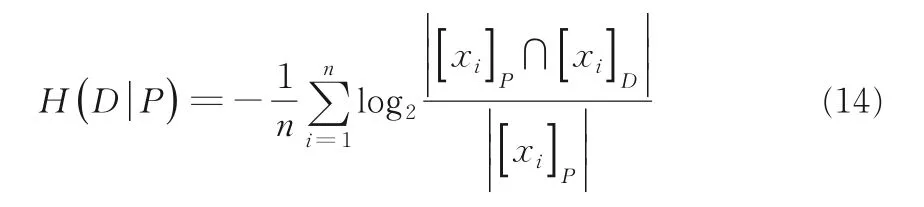
為了便于理解式(8)的鄰域Ea(x)和最大標準差max (σa),下面用例子來說明.
例1一個區間決策信息系統由表1 構成.U={x1,x2,…,x6},C={a1,a2,a3} 且決策屬性d在論域U上的劃分為U/d={{x1,x2,x3},{x4,x5,x6} }.設X1={x1,x2,x3},X2={x4,x5,x6} .首先基于表1 給出屬性下的最大標準差max(σa1)=9.375,ma x(σa2)=3.675,max(σa3)=0.0575.根據式(8)可以計算出所有屬性的鄰域,結果如表2所示.設B1={a1,a2},B2={a1,a3},B3={a2,a3} .根據表2 和式(9)可以計算出B1,B2,B3鄰域EB1(x),EB2(x),EB3(x)分別為:
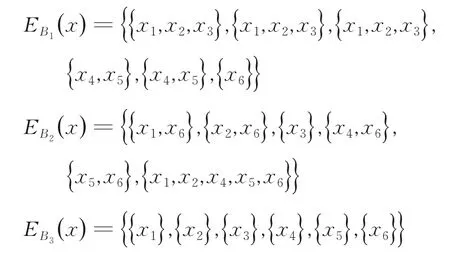
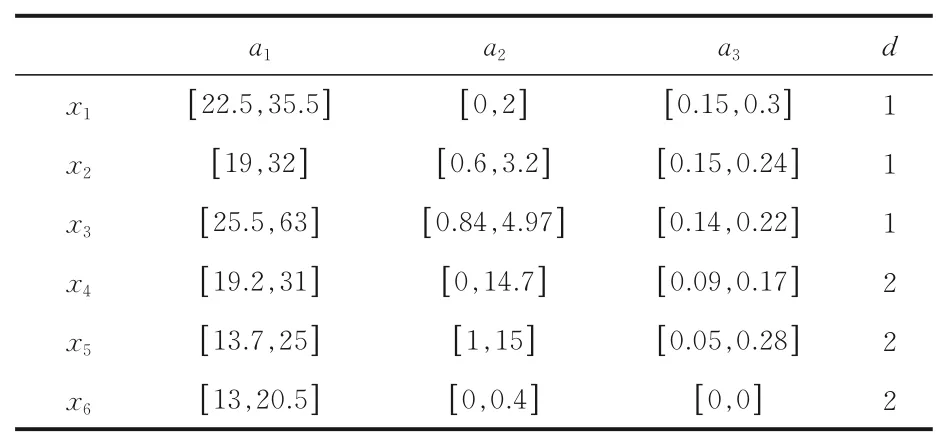
表1 區間決策系統一個實例Table 1 An example of interval decision system

表2 鄰 域Table 2 The neighborhoods
3 基于代價敏感的特征選擇問題
通常數據本身有測試代價,即獲得數據精度所付出的代價,并且現實生活中的數據因為一系列原因可能導致一定的誤分類代價.因此,本節提出基于區間值數據的測試代價和誤分類結構.
3.1 代價函數對于一個鄰域決策信息系統其中U={x1,x2,…,xn}為n維對象集合,C為所有條件屬性集合;D表示決策屬性,N為樣本關于屬性的鄰域映射函數.設a∈C,tc為測試代價函數,tc(a)max是屬性a下所有對象的最高測試代價,即屬性a獲得最高數據精度所付出的測試代價,則每個對象的最高總測試代價為tc本文給定屬性a,測試代價函數根據應用背景以不同的形式表示,本文的線性函數的測試代價函數設計為:

其中,λa∈[0,1 ]是測試代價的一個調節因子,調節所有對象的測試代價,使每個對象的總測試代價趨于平衡.
對任意B?C,每個對象總測試代價(Total Test Cost,TTC)定義為:

設mc為誤分類代價函數,(n,m)為從類n到類m的誤分類.誤分類代價函數定義如下:
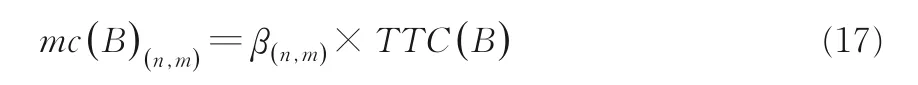
其中,β(n,m)>0 是一個懲罰因子,用于懲罰從類n到類m?誤分類的對象x.另一種誤分類代價常數函數定義如下:

MC(n,m)為從類n分類到類m的誤分類代價,是一個常數.
3.2 平均總代價的計算考慮到一個對象往往屬于多個鄰域粒,可能導致誤分類代價被重復計算.本文使用文獻[16]中新的誤分類代價計算方法,可以避免過多的重復計算.
(1)如果?y∈EB(x)且d(y)=d(x),則把對象x分類到本身所在類,所以mc(x,B)=0.
(2)如果?y∈EB(x)且d(y)≠d(x),考慮到同一鄰域粒的對象是不可區分的,假設它們在分類時具有相同的決策值,那么可以對x進行分類,使EB(x)中所有對象的誤分類總代價最小化,從而得到相應的mc(x,B).
則平均誤分類代價(Average Mis-classification Cost,AMC)定義如下:
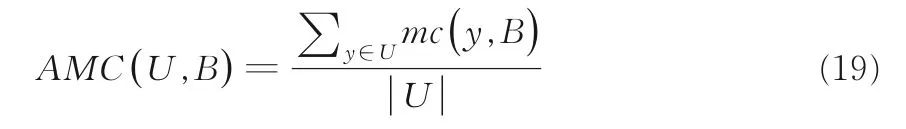
因為對象的總測試代價是相同的且等于TTC(B),所以平均總代價(Average Total Cost,ATC)定義如下:
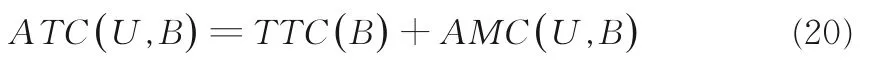
例2(續例1)給定:tc(a1)max=20,tc(a2)max=63,tc(a3)max=15,λa1=0.3,λa2=0.4,λa3=0.2,則tc(C)max==98.設B={a1,a3},因為tc(a1)=20×0.3=6和tc(a3)=15×0.2=3,則有TTC(B)=6+3=9.那么設β(1,2)=40 和β(2,1)=10,有mc(B)(1,2)=40×9=360,mc(B)(2,1)=10×9=90.
根據例1 所計算的鄰域,有:
EB(x1)={x1,x6},EB(x2)={x2,x6}
EB(x3)={x3},EB(x4)={x4,x6}
EB(x5)={x5,x6},EB(x6)={x1,x2,x4,x5,x6}
結合表1,將每個對象按照其鄰域進行分類,得到誤分類代價.具體來說,對于對象x1,假設鄰域EB(x1)中所有對象都被分類到類“1”,則鄰域EB(x1)中所有對象的誤分類總代價為90.相反,如果將鄰域EB(x1)中所有對象分類到類“2”,則相應的誤分類總代價為360.因此將鄰域EB(x1)中所有對象分類到類“1”以獲得較少的誤分類總代價.根據表1,對象x1本身決策屬性為類“1”,所以對象x1被正確分類,mc(x1,B)=0.對于對象x6,如果把鄰域EB(x6)中所有對象分類到類“1”,則鄰域EB(x6)中所有對象的誤分類總代價為90×3=270.相反,如果將鄰域EB(x6)中所有對象分類到類“2”,則相應的誤分類總代價為360×2=720.因此,選擇將鄰域EB(x6)中所有對象分類到類“1”,在這種情況下,x6本身決策屬性為類“2”,但被誤分類到類“1”,所以mc(x6,B)=90.同理可得mc(x2,B)=mc(x3,B)=mc(x4,B)=mc(x5,B)=0.
根據式(19),AMC(U,B)=90 ∕6=15,然后根據式(20)得到ATC(U,B)=9+15=24.
代價敏感屬性約簡的目的是找到一個屬性子集,并使得總代價最小化[17-21],盡可能多地保留原始數據中的信息.基于代價敏感區間值屬性約簡的問題形式定義如下:


4 基于代價敏感區間值特征選擇算法
本節提出基于代價敏感的區間值屬性約簡算法,算法具體步驟展示在算法1 中.
算法1 遵循Liao et al[16]討論的添加-刪除策略,主要包含三個步驟:第一步,初始化全局變量;第二步,選擇出相應的屬性子集B;第三步是刪除階段,根據屬性B中的平均總代價來刪除冗余的屬性.


分析時間復雜度.對于選擇屬性階段,最壞的情況下,while 循環m次,即所有條件屬性都被選擇;while 循環體內部最壞的情況下for 循環將執行次,for 循環體內部計算條件熵的時間復雜度為O(nm),其中n為對象個數.故在選擇屬性階段時間復雜度為O(nm3).對于刪除階段,最壞的情況下屬性全部被刪除,這種情況while 循環執行|B|次,相應的for 循環將執行次,for 循環體內部平均總代價的時間復雜度,根據式(20)可知為O(max(n,m)),故刪除階段時間的復雜度為故在最壞的情況下算法1的時間復雜度為O(nm3).
5 實驗與結果
為了驗證提出算法的有效性,在11 個真實數據集上進行了實驗.數據集都是從UCI 數據庫中獲得,其中Face,Fish,Water 條件屬性值都是原始區間值數據,其他數據集的原始屬性值為實值.表3 展示了實驗數據的詳細信息.
5.1 實驗準備在進行實驗之前,首先將實值數據進行區間化預處理,根據3.1 節對實驗數據進行代價函數預處理,先對實驗數據的屬性集設置測試代價.對于屬性數目小于15 的數據集,設最高測試代價tc(a)max為分布在[20,100 ]內的均勻分布的隨機整數,而其他數據集則設置在[20,200 ]內,測試代價調節因子λa∈[0,1 ],設置誤分類代價懲罰因子β(n,m)為[10,100 ]內的整數,誤分類代價常數函數MC(n,m)設為[5000,50000]內的整數.例如Water 數據集中有兩個類,分別為類1 和類2,設置懲罰因子β(1,2)=20 和β(2,1)=50;Face 數據集中有九個類,設置誤分類代價常數函數MC(n,m)=10000.
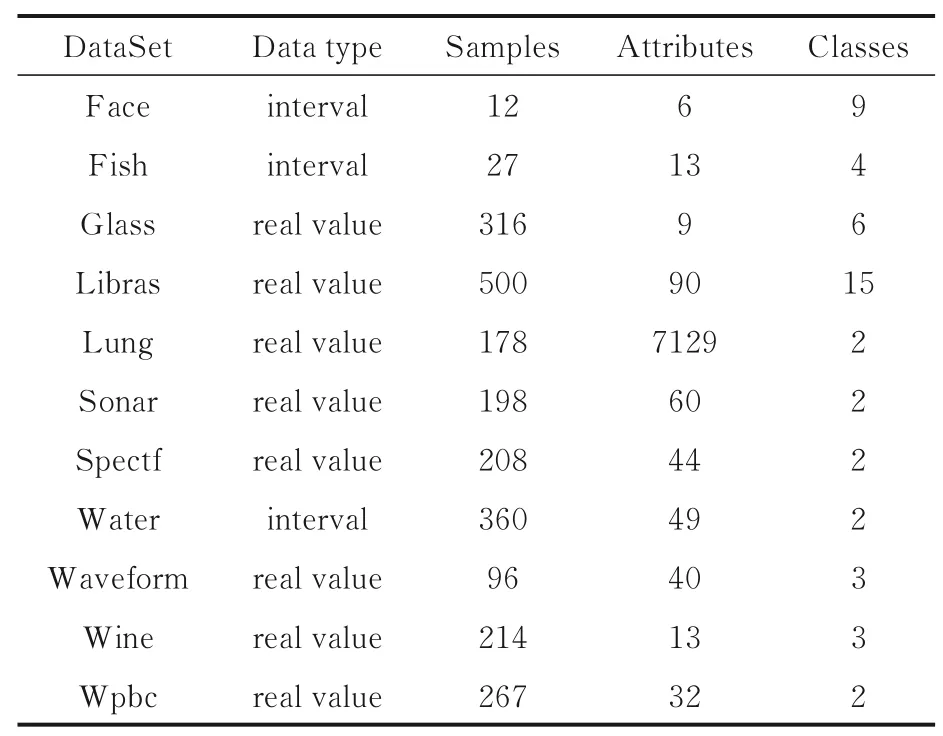
表3 數據集介紹Table 3 The introduction of datasets
本文所有實驗都在相同的軟硬件環境下進行.CPU:Intel(R)Core(TM)i5-9300H CPU @2.40 GHz;RAM:16.0 GB;操作系統:Windows 10;Matlab 版本:Matlab 2019b.
5.2 實驗結果實驗的結果展示于表4 中.如表4 所示,TTC,AMC,ATC每列下面劃分為三列,第一列為未經屬性約簡的結果(NFSR),第二列為Dai et al[22]的方法(ARCE)經過屬性約簡后的結果,第三列為本文方法經過屬性約簡后的結果(CSIVARA).每一行中最小平均總代價(ATC)用黑體字突出顯示.
表4 中Sonar 數據集上CSIVARA 的平均總代價高于ARCE;Libras 和Waveform 數據集上CSIVARA 的最小平均總代價接近最低平均總代價;其他八個數據中CSIVARA 的最小平均總代價都遠低于未約簡前的和對比方法ARCE 的最小平均總代價.總體來說,CSIVARA 表現最好.
5.3 比較與分析為了進一步分析實驗結果,將CSIVARA 和ARCE 的分類精度進行對比.
為了比較區間值決策信息系統上屬性約簡的分類性能,利用擴展的KNN 分類器進行分類性能的實驗.
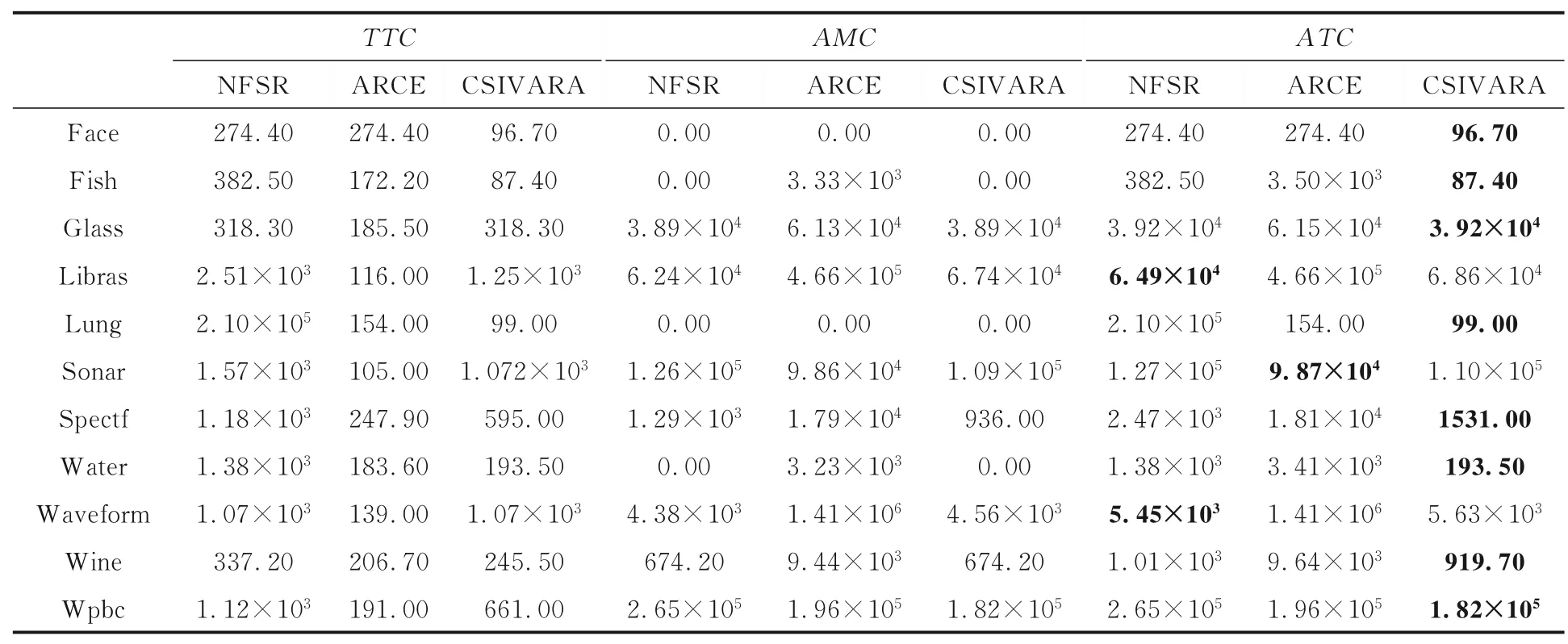
表4 三種方法的平均總代價的比較Table 4 The average total cost of the three methods
設X和Y是兩個在區間值信息系統下的對象,是兩個在第k個屬性下的區間值.X和Y之間距離定義如下[23]:
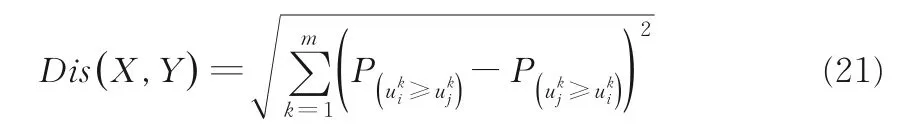
其中m為條件屬性數量,是兩個區間值之間的相似度.
考慮Fish 和Face 數據集的樣本數太少,采用留一交叉驗證的方式驗證分類精度,而對于其他數據則采用十折交叉驗證的方式.另外,由于隨機性的問題,所有的實驗結果都運行20 次,并取20 次平均值作為最終的分類精度,本文使用KNN(k=3)分類器進行實驗.分類精度結果如圖1 所示,可見兩種方法在Face 數據集中的分類精度持平;在Lung 數據集中,CSIVARA 分類精度略低于ARCE;在Spectf 和Water 數據集中,兩種方法分類精度結果非常接近;在其他七個數據集中,CSIVARA 的分類精度都優于ARCE,特別是在Libras 數據集中,CSIVARA 分類精度顯著高于ARCE.

圖1 在KNN (k=3)分類器上的平均分類精度結果Fig.1 Results of average classification accuracy on KNN (k=3)classifier
實驗分析結果表明,CSIVARA 分類精度高于ARCE,同時還保證了平均總代價最小化.
6 結論
本文提出基于代價敏感的區間值屬性約簡方法,該方法根據原始數據的分布構建了基于區間值數據的代價敏感函數,充分考慮了測試代價和誤分類代價對于數據的影響.最終實驗表明,本文提出的方法可以在平均總代價較小的情況下有效地選擇重要的候選屬性.未來的工作將繼續探討區間鄰域決策系統存在缺失值的情況.
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
山東青年(2016年1期)2016-02-28 14:25:25
河南科技(2014年23期)2014-02-27 14:19:15
當代修辭學(2014年3期)2014-01-21 02:30:44
