基于樣本熵的語音信號檢測算法
2021-01-28 03:08:46陳佳琪鄭曉慶
海軍航空大學學報 2020年5期
陳佳琪,鄭 強,鄭曉慶
(海軍航空大學,山東煙臺264001)
船舶航行時,語音通訊與交流是必不可少的。但船舶航行過程中,各種設備產生的巨大噪聲嚴重干擾了通訊端語音信號,使得有用的語音不能被正常接收,影響了船舶工作者的正常交流。故削除語音信號通訊端工作環境中船舶的噪聲干擾,增強語音信號,對語音交流的準確性和舒適性有重要意義。實現語音信號增強,須從含噪信號中將語音信號和船舶背景噪聲正確地檢測分離,以便進一步通過譜減法等方法實現語音增強。
為了達到語音降噪增強的目的,關鍵是要把源信號中無語音的噪聲段與語音段進行分離。目前,國內外學者進行了相關的分析研究,提出的方法有時域和頻域特征處理方法。如,基于短時能量、過零率、譜散度[1],倒譜分析、短時分形維數[2],頻帶方差[3],多重線性回歸分析[4]及修正調制譜估計[5]等。但這些方法在用于艦船背景噪聲時遇到了以下困難:①船舶類型多種多樣,運行狀態千變萬化,因而其噪聲特征各不相同,背景噪聲復雜多變;②艦船設備工作時噪聲巨大,很多時候在時域可將語音信號完全掩蓋,使信號的信噪比很低;③同背景噪聲一樣,說話人的性別與年齡的不同也會導致語音信號的巨大差異。船舶背景噪聲和語音信號的復雜多變使許多檢測方法因類內特征離散度大而失效。所以,須探索新的噪聲段與語音段的檢測分離方法,以適應船舶背景噪聲特征[6]。
樣本熵是Richman提出的一種時間序列復雜性的測試方法[7],復雜度代表了信號序列中出現新信息量的大小[8]。語音信號與船舶工作噪聲信號的產生機理是不同的,語音信號是由肺部收縮產生的氣流經過聲門和聲道引起震蕩產生的;船舶工作噪聲與船舶的結構、材質和發動機樣式等有關。因此,2種信號時間序列的信息變化程序存在差別。本文在分析2種信號復雜性特征的基礎上,利用2 種信號在時間序列中出現新信息量的大小和變化幅度的不同,通過時域信號樣本熵,實現了含噪信號中語音段和船舶背景噪聲段的正確分離。通過實測數據實驗驗證,該方法具有不錯的檢測效果。
1 信號特征分析
艦船背景噪聲與語音信號本身都為復雜多變的信號,類內特征皆有較大的離散性,故可以信號發聲機理為基礎研究2 者的不同之處,并利用頻譜的相似性將信號進行分離。
船舶作為一種工作環境,有其本身的特殊性。船舶背景噪聲主要由船舶發動機、發電機等各種設備的運行產生,對于實際的工作環境,船舶自身的大小、材料、發動機類型等會成為其噪聲特性的決定性因素[9]。這說明當在一個較短時間內,分析其噪聲特點時,由于船舶自身運動狀態及發動機狀態等通常會保持一個較穩定的狀態,因而對其噪聲進行頻譜等各種特征分析時,短時間內的頻譜特性會較為穩定[10-11]。圖1 為某船舶背景噪聲相鄰時間幀信號的頻譜分布。可以看出,其相鄰幀的頻譜分布表現出較好的相似性,即具有短時穩定性。

圖1 船舶背景噪聲信號相鄰幀頻譜分布相似性Fig.1 Spectrum distribution similarity of adjacent frames of ship background noise signal
語音信號由肺部收縮產生的氣流經過聲門和聲道引起震蕩而產生。語音中有意義的最小單元是單詞,單詞由音素組成[12-14],音素是語音中的最小單位。一段語音信號中會選擇不同的單詞來表達內容,通過音素引起氣流、聲門和聲道的不斷變化,從而表現出即使在一個較短時間內,其相鄰時間幀信號的頻譜等特征表現出較大的差異,如圖2 所示。為純凈語音信號相鄰幀信號的頻譜分布特性,其頻譜計算方法與圖1相同,且都進行了頻譜曲線平滑處理。
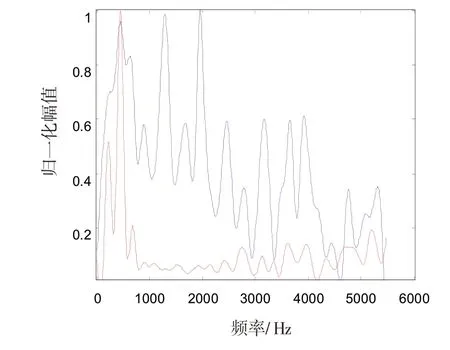
圖2 語音信號相鄰幀頻譜分布特征Fig.2 Spectrum distribution characteristics of adjacent frames of speech signal
綜上所述,不同的發聲機理,使語音信號與船舶背景噪聲信號的短時頻譜相似性有較大的差異。對于背景噪聲信號,其短時幀間頻譜分布相似性較大,因而其信號時間序列中的新信息量較少;而語音信號由于短時幀間頻譜的分布相差很大,其信號時間序列中的新信息量會較多[15-18]。因此,通過樣本熵來描述含噪聲語音信號中語音段與噪聲段信號的新信息量差異,可以實現2種信號的判別。
2 含噪語音信號的樣本熵
2.1 樣本熵的定義和物理意義
樣本熵的定義為:通過度量信號中產生新模式的概率大小來衡量時間序列復雜性,新模式產生的概率越大,序列的復雜性就越大。當數據向量由m 維增加至m+1 維時,繼續保持其相似性的條件概率[15],則樣本熵可表示為:

式(1)中:N 為信號長度;r 為相似容限;Bm(r) 和Bm+1(r)的定義如式(4)所示。
時間序列產生新模式的概率越大,序列越復雜,相應的樣本熵越大。樣本熵從統計的角度來區別時間過程的復雜性,表征信號序列中前后數據的差異變化,只須要較短的數據就可以估計出來。
2.2 樣本熵的計算
設每幀長度為N 的含船舶背景噪聲的語音信號經過預處理后為x,其組成m 維向量為:


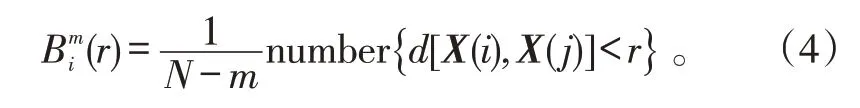
式(4)中,i,j ∈[ ]1,N-m+1 且i ≠j,對所有i 值求平均得:


3 基于樣本熵的語音信號與輻射噪聲判別算法
采樣率為11 025 Hz 的輸入信號,基于樣本熵的信號判別算法的實現步驟如下:
步驟1:信號分幀。對信號進行預加重處理并使用漢明窗分幀,每幀512 個數據點,幀移點數為256。實驗中,m=2,容許值r=0.2。
步驟2:對信號類別初始判別。首先,根據式(6)計算樣本熵SampEn;然后,根據式(7)計算自適應閾值Thre1。

式(7)中:λ1與λ2的值通過試驗確定,這里取值為λ1=4 和λ2=6;u、δ 為信號的均值與標準差。
比較SampEn 的值與Thre1的值:
如果SampEn ≤Thre1,信號為語音信號;
如果SampEn>Thre1,信號為輻射噪聲。
從而實現對每1幀信號的初始判別。
步驟3:鄰域平滑處理。根據同一種信號通道持續一定時間的規律,以當前信號幀及其前2 幀信號作為當前幀類別判斷的鄰域,對信號進行平滑處理。當鄰域幀信號中有2 幀以上的信號類別為環境噪聲,則當前幀信號最終類別判定為環境噪聲,反之亦然。在對信號進行平滑處理時,以鄰域幀信號的初始判別類型為判據。
4 算法實驗驗證
本文使用實測數據來驗證算法的有效性。其中,船舶工作環境噪聲數據主要為空投浮標和被動全向聲吶采集的數據,包括商船、漁船等,數據文件共400 min,語音信號包括采用海泰HTPXI1008 數據采集器搭配麥克風在實驗室錄制的數據、網上公開的語音算法驗證庫中的語音數據共400 min,數據采樣率均調整為11 025 Hz。實驗中,以1s 時間長度為一個處理片段,片段內數據劃分成10 幀,按照前面介紹的算法執行。
如圖3 所示,為測試基于頻譜趨勢相似性的信號識別算法的性能及對不同數據的適應性,將測試數據分成3個子集進行實驗。
子集1:該數據子集主要包括不同說話者的語音信號,主要用來測試算法對語音信號的識別性能和對不同說話者語音的適應性。實驗中,每個錄制的數據取20 s 進行實驗,其結果如圖3 a)所示。
子集2:該數據子集主要包括不同的水聲目標輻射噪聲數據。為實驗的需要,采用與子集1 相同的數據文件長度,該數據子集主要用來測試算法對水聲目標輻射噪聲信號的識別性能和適應性,其識別結果如圖3 b)所示。
子集3:該數據子集由不同的語音信號和水聲目標輻射噪聲信號組成,每個數據文件取20 s 進行實驗。該子集主要用來測試算法對語音信號和水聲目標噪聲信號同時存在時的識別效果。同時,測試對語音信號與水聲目標信號起始位置的識別精度,實驗結果如圖3 c)、3 d)所示。其中,圖3 c)為每個語音數據文件與水聲目標數據文件交替讀取識別,而圖3 d)為數據文件隨機讀取識別結果。
圖3的4個識別結果中都包含4個子圖,從下到上分別是時域信號幅值、在時域信號上計算得到的短時頻譜Pearson 相關系數方差、初始未經過平滑處理的識別結果和算法的最終識別結果。
每個圖中,第1 個和第2 個子圖的縱坐標分別表示實驗對目標的判斷結果。
子圖縱坐標取值中,1 表示識別結果為水聲目標輻射噪聲信號;2 表示采用多閾值方法但未進行結果平滑時被識別為水聲目標信號待定信號;3 表示語音信號待定信號;4表示識別結果為語音信號。
從圖3 中可以看出,算法對不同類型和不同工況下的水聲目標信號以及對不同說話者的語音信號都取得了較好的識別效果,對不同組合方式形成的混合信號也取得了準確的識別結果。
為了量化該算法的判別精度,將正確判別信號時間和信號總時間進行比較,即:

對所有實驗數據信號處理后的結果如表1 所示。從表1 中可以看出,基于時域信號樣本熵的語音信號與環境噪聲信號判別算法取得了較高的穩定精度。

表1 語音信號與輻射噪聲信號判別結果Tab.1 Discrimination results of voice signal and radiated noise signal %
5 結論
本文通過分析語音信號與船舶工作環境噪聲信號的不同產生機理,利用2 種信號在時域時間序列中出現新信息量的大小和變化幅度不同,通過信號樣本熵實現了2種信號的判別。本文僅使用樣本熵一個特征,避免了多特征之間的相關性帶來的不確定因素以及特征值的計算帶來的計算量較大等不足,通過大量實測數據的實驗驗證,算法取得了理想的判別結果。
猜你喜歡
艦船科學技術(2022年14期)2022-09-22 03:07:40
艦船科學技術(2022年2期)2022-03-29 01:12:44
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
小哥白尼(趣味科學)(2019年10期)2020-01-18 09:16:22
船舶標準化工程師(2019年4期)2019-07-24 07:21:12
中國生殖健康(2019年3期)2019-02-01 06:12:26
中國船檢(2017年3期)2017-05-18 11:33:09
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
海軍航空大學學報(2015年3期)2015-11-11 17:20:00
