一種基于依存句法和WRD 的句子相似計算方法*
2021-01-26 04:00:42石元兵金貴濤
通信技術 2021年1期
周 俊,石元兵,魏 忠,金貴濤,郭 紅
(衛士通信息產業股份有限公司,四川 成都 610041)
0 引言
在自然語言處理技術中,句子相似度計算是一項重要的基礎研究技術,被廣泛應用于很多領域。比如,在信息檢索領域中,可以使用句子相似計算技術計算輸入查詢句的相似檢索句子,從而得到更準確的檢索結果;在敏感數據檢測領域,可以使用句子相似計算技術來檢測目標文檔的句子與指定敏感句是否相似,從而判斷目標文檔是否是敏感文檔。因此,句子相似計算技術的發展與很多領域的技術應用密切相關,成為自然語言處理技術中的一個研究重點。
目前,主要的句子相似計算技術可以分為以下幾類。
(1)基于統計的相似度計算[1],即對兩個句子的字、詞語、短語等不同成分維度的不同特征(如字頻、詞頻、TF-IDF[2]等)進行統計,統計結果越相近表示兩個句子越相似。這種方法的弱點是沒有考慮語義維度上的相似性。
(2)基于語義詞典的相似度計算[3]。因為語義詞典(如同義詞詞林、知網等)能夠表征兩個詞語之間的語義相似關系,所以可以使用語義詞典(如同義詞詞林、知網等)檢測兩個句子的語義相似詞語。語義相似詞語越多,表示這兩個句子越相似。這種方法的弱點是語義相似詞典的詞語太少,無法滿足層出不窮的新詞語。
(3)基于向量空間模型的相似度計算,即把句子轉化為向量來表示,從而使兩個句子的相似計算轉變為對應的兩個向量的距離計算。常用的向量模型有VSM、LSA、Word2vec 等[4]。這種方法的弱點是假設句子中的所有詞語都是獨立的,沒有考慮詞語之間的內部關聯。
針對上述3 種方法的不足,本文提出一種基于依存句法分析和Word Rotator’s Distance 語義距離技術的句子相似度計算方法。該方法首先使用依存句法分析技術對句子的詞語進行依存關系分析,提取出句子中的主謂、定中以及狀中等結構詞語組成特征集,然后使用Word Rotator’s Distance 語義距離技術計算兩個句子的特征集的相似關系。本文提出的句子相似度計算方法充分考慮了句法結構關系,消除了多詞語混雜計算的弊端,能夠充分理解句子的完整語義,且實驗效果證明了其是一種比較準確的句子相似計算方法。
1 依存句法分析
句法分析是對句子進行分析以得到句子的句法結構或詞語之間關系的處理過程。句法分析技術是語言理解的重要一環,也能夠為其他自然語言處理任務提供支持。
最常見的句法分析任務可以分為兩種。
(1)句法結構分析(Syntactic Structure Parsing),又稱短語結構分析(Phrase Structure Parsing),也叫成分句法分析(Constituent Syntactic Parsing),作用是識別出句子中的短語結構以及短語之間的層次句法關系,用短語結構來描述句子語法結構并理解句子語義。
(2)依存關系分析,又稱依存句法分析(Dependency Syntactic Parsing),簡稱依存分析,作用是識別句子中詞語與詞語之間的相互依存關系,用詞語與詞語之間的依存關系來描述句子語法結構并理解句子語義。
依存句法由法國語言學家Tesniere L最先提出。在依存句法理論中,句子成分之間普遍存在支配和被支配的關系,叫做依存關系。依存關系和語義緊密關聯,可以反映出句子各成分之間的語義修飾關系,因此可以通過解析詞語之間的依存關系來分析句法結構,實現對句子語義的準確理解[5]。
通常一個依存關系發生在兩個詞語之間。這兩個詞語構成了一個依存對:一個詞語是核心詞(Head),也叫支配詞;另一個詞語是修飾詞,也叫從屬詞(Dependent)。依存關系通常用一個有向弧表示,叫做依存弧。依存弧的方向由從屬詞指向支配詞。根據兩個詞語之間的不同句法關系,可以將依存關系細分為不同的類型。常見的依存關系類型如表1 所示。
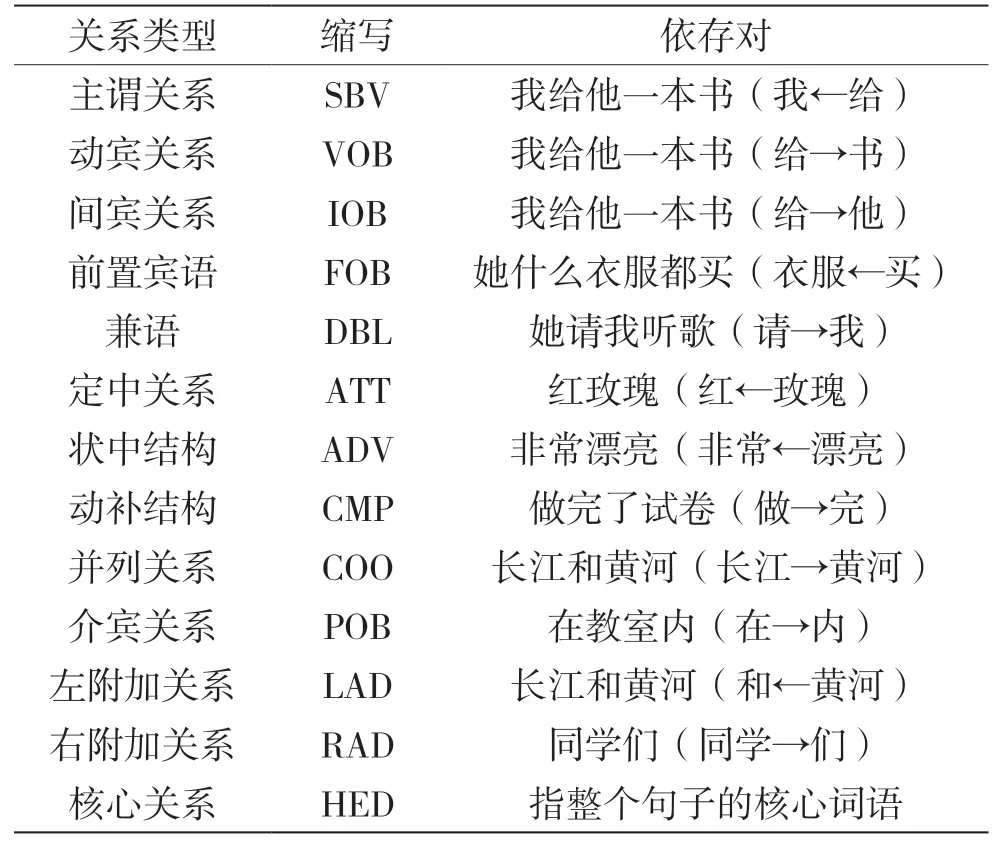
表1 常見的依存關系類型
與短語結構句法相比,依存句法具有以下優點:
(1)在依存句法中,所有的依存關系都是以動詞為核心,能夠突出句子中的核心詞語;
(2)在依存句法中,依存關系強調了句子各詞語之間的功能關系,更易于進行句子的語義表示。
例如,“句子相似計算是自然語言處理技術的一個重要研究方向”的依存關系圖如圖1 所示。
對應的依存關系如表2 所示。

圖1 依存關系圖例子

表2 依存關系例子
可以看出,對句子進行依存句法分析能夠比較準確地反映句子的結構,且依存對的詞語能夠比較準確地反映出句子的語義。
因此,通過依存句法對句子進行語法結構分析后得到的依存關系和詞語,能夠用來進行句子相似計算。兩個句子同類型的依存關系越多,每類依存關系的詞語越相近,這兩個句子就越相似。
2 WRD 語義距離
詞語旋轉距離(Word Rotator’s Distance,WRD)是2020 年Yokoi S、Takahashi R 等人提出的計算兩個文檔之間距離的方法[6]。WRD 是對詞移距離(Word Mover’s Distance,WMD)算法的改進,是在詞向量Word2vec 的基礎上用來衡量兩個文檔相似度的算法。它綜合兩個文檔中所有詞語(去除停用詞)來計算文檔相似度,適用于文檔相似度和短文本相似度的計算。
Word2vec 是2013 年谷歌提出的一種將詞語表征為向量的工具[7],是目前應用最廣泛的詞向量技術之一。Word2vec 將詞語表示為N維空間中的點。在該N維空間中點的距離可以表征詞語間的相似度。距離越小,相似度越高。在Word2vec 詞向量空間中能夠展現詞語的語義特性如:

可見,利用Word2vec 能夠提取出詞語的語義關系,為計算文本相似度提供了條件。
WMD 是于2015 年由Matt J.Kusner 等人提出的一種利用詞向量計算多個詞語之間距離的算法[8],用于表征兩個文檔之間的語義相似度(WMD 距離越大,文檔之間相似度越小)。WMD 算法基于搬土距離(Earth Mover’s Distance,EMD)模型計算文檔間的距離。EMD 模型是一種兩個概率分布間距離的度量方式,一個典型的實例是運輸問題,即從倉庫1、倉庫2 運送貨物到用戶A、用戶B 最優運送方式的問題,綜合考慮倉庫貨物的存儲量、用戶需求量以及倉庫到用戶距離,通過線性規劃可以找出最小代價的運送方式。WMD 計算兩個文檔之間的相似度,是將文檔A 中的詞語視為貨物,將文檔B 中的詞語視為用戶,將詞語間的相似度視為距離,將詞語在文檔中的權重視為貨物的數量,以此將文檔A 中的詞語“轉移”到文檔B,使用EMD 模型求解最小的“轉移”代價。“轉移”過程如圖2所示。
WMD 計算文檔A 與文檔B 之間距離的步驟如下。
(1)去除停用詞。對文檔進行分詞,并去除文檔中的停用詞。
(2)計算詞語權重。采用歸一化詞袋模型(normalized Bag-Of-Words,nBOW)計算文檔詞語權重,其中第i個詞語詞頻權重表示為:

式中,ci表示詞語i在文檔中出現的次數。
(3)利用EMD 模型計算文檔距離。依據前文對EMD 的介紹,使用EMD 模型需要先構建權重矩陣和距離矩陣。
①構建權重矩陣。文檔的權重矩陣由文檔中詞語權重向量組成,在第(2)步中已經對文檔詞語權重進行了計算,記文檔A 的權重矩陣為d∈Rn,文檔B 的權重矩陣為d′∈Rn。
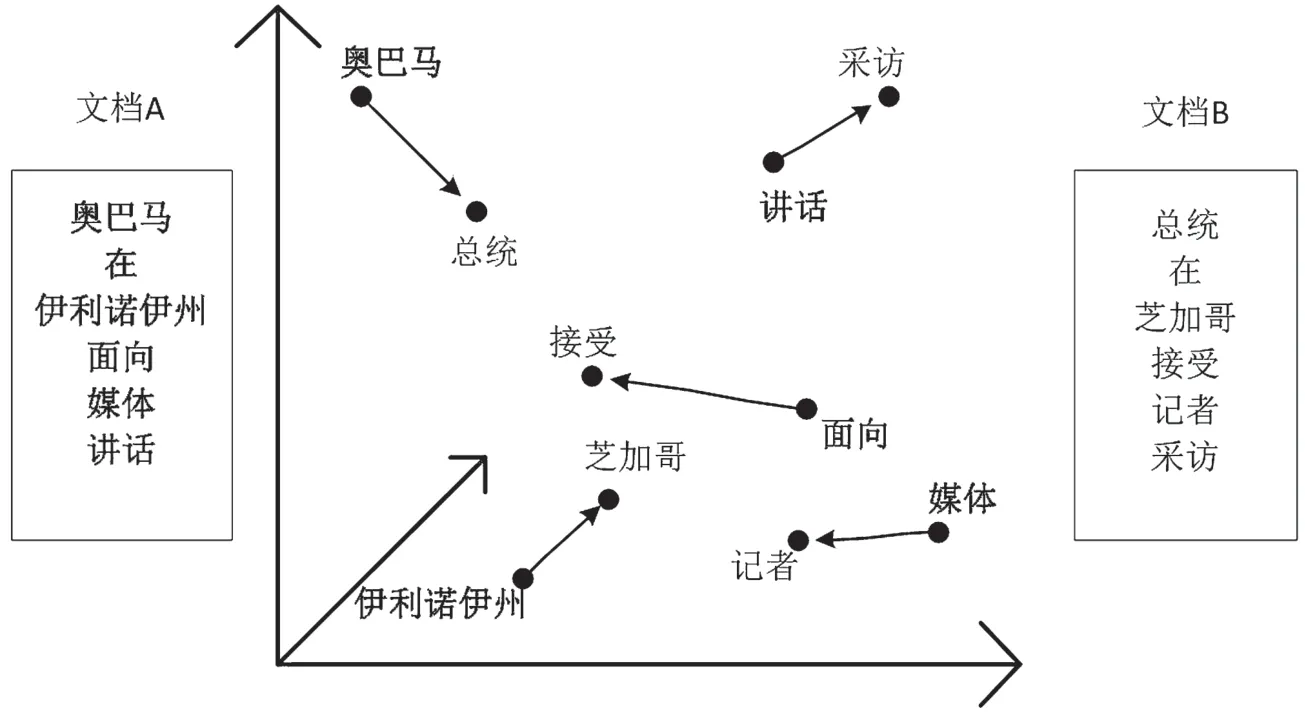
圖2 WMD 例子
②構建距離矩陣。Word2vec 向量空間中提供了一種天然的距離計算方式,即歐式距離。記詞語i到詞語j的距離為:

式中,c(i,j)表示從一個詞語i轉移到詞語j需要的代價。
記文檔A 中詞語i到文檔B 中詞語j的轉移量為Tij≥0。為了使文檔A 中的詞語能夠完全轉移到文檔B 中,則文檔A 中詞語i的轉出量必須等于詞語i自身的權重(倉庫的出貨量等于儲存量),即:

同理,文檔B 中詞語的轉入量必須等于自身的權重(用戶的收貨量等于需求量),即:

因此,文檔A 到文檔B 的距離為:

使用EMD 模型求解,可得文檔A 與文檔B 的距離。
WRD 算法在WMD 算法上做了兩點改進。
(1)對權重矩陣的改進。在WMD 中以詞頻作為權重,而WRD 以詞向量模長作為權重矩陣,即權重矩陣為:
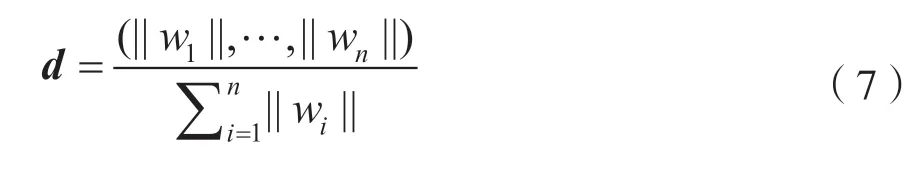
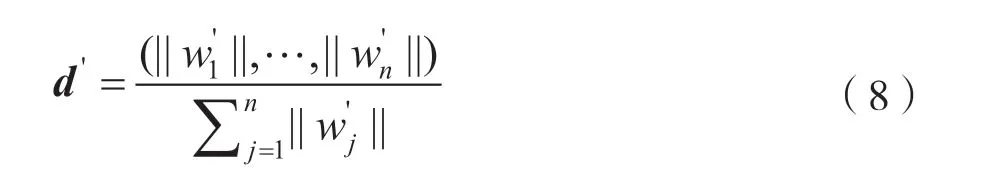
(2)對距離矩陣的改進。在WMD 中以詞向量的歐式距離作為詞語的距離,而WRD 以詞向量的cosine 距離作為詞語的距離,即:

改進后的WRD充分利用了詞語語義上的特點,結合Word2vec 計算詞語間的語義相似度,從而更大程度地挖掘了文檔間的語義相似。WRD 以cosine距離作為距離的度量方式,使WRD 算法的取值范圍為[0,2],利于文檔相似結果的判斷。
WRD 與WMD 對比如表3 所示。

表3 WRD 與WMD 例子對比
從表3 計算結果可以看出,WRD 語義距離在取值范圍[0,2]之間,更便于進行輔助決策。
3 算法流程
本文提出的基于依存句法分析和WRD 語義距離技術的句子相似計算方法流程,如圖3 所示。

圖3 句子相似計算流程
3.1 步驟1:句法分析
對兩個句子A、B 分別進行依存句法分析,得到各類依存關系的依存對。例如,句子A 的主謂關系依存對SBV_A、句子A 的定中關系依存對ATT_A 等,同一類型的依存對可能會有多個。例句A“數據安全是信息安全領域的一個重要環節”、例句B“對敏感數據進行識別和保護是數據安全的一個重要研究方向”,對應的依存對如表4 所示。
3.2 步驟2:提取詞集
提取每個依存對中的支配詞和從屬詞,組成各類依存關系的支配詞集(Word set of Head)和從屬詞集(Word set of Dependency),如表5 所示。
3.3 步驟3:計算WRD 語義距離
分別對兩個句子的同一種依存關系的同類詞集進行WRD 語義距離計算,如果支配詞集或者從屬詞集的WRD 語義距離小于某個閾值(一般設置為0.8),表示支配詞集或者從屬詞集相似,則這兩個句子具有部分相似的該種依存關系;如果該種依存關系的支配詞集或者從屬詞集都相似,則這兩個句子之間具有完全相似的該種依存關系。

表4 例句A 與B 的依存對
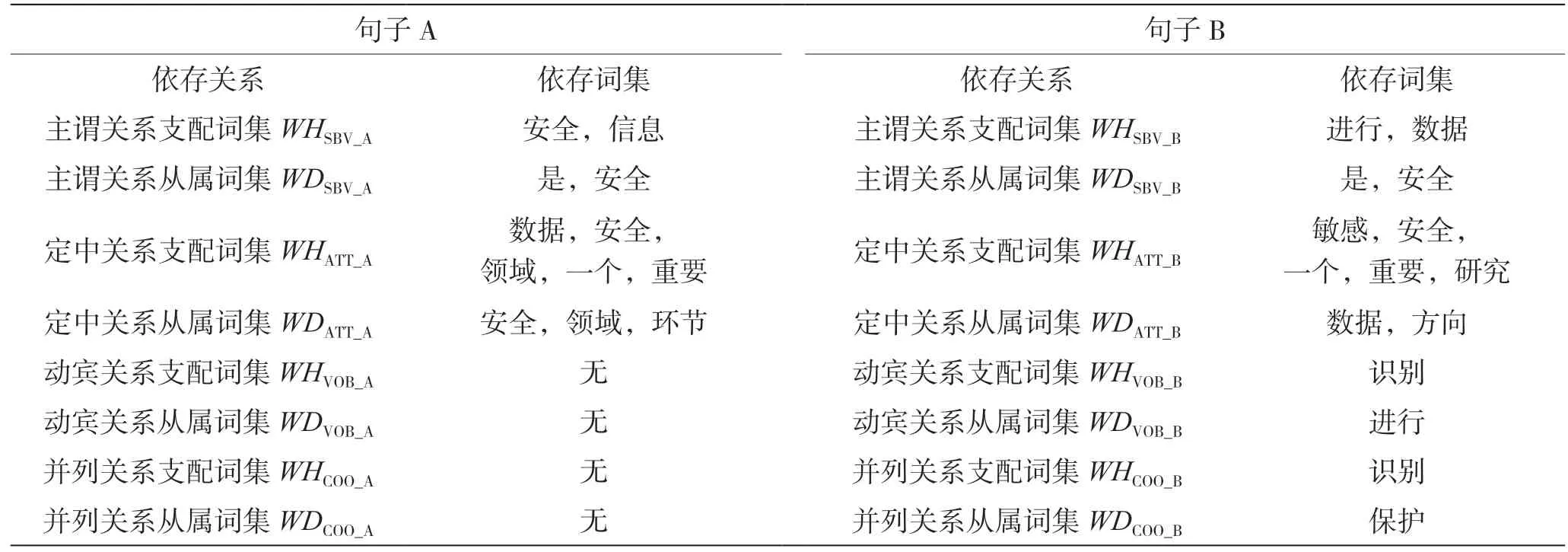
表5 例句A 與B 的依存詞集

表6 例句A 與B 的依存詞集相似結果
3.4 步驟4:句子相似指數
通過對大量語言材料的統計分析發現,不同類型句子進行相似技術應該重點關注不同的依存關系,如在對政府報告、技術報告、科技文獻等比較正式場景的語言材料要較多關注主謂、動賓、間賓等依存關系,而在對新聞、社交等比較非正式場景的語言材料要較多關注定中、附加等依存關系。因此,本文給每個依存關系詞集設計了一個權重,可以根據業務要求進行調整,初始值都為1。將相似依存關系詞集的權重值進行累加,并根據式(1)計算得到一個介于0 和1 之間的句子相似指數Indexsim。句子相似指數越接近0,表示兩個句子越不相似;越接近1,表示兩個句子越相似。

例句A“數據安全是信息安全領域的一個重要環節”和例句B“對敏感數據進行識別和保護是數據安全的一個重要研究方向”,都是從科技文獻語言材料中摘取出來的,因此將主謂關系支配詞集和主謂關系從屬詞集的權重都設置為2,其他權重保持不變,得到兩個句子的相似指數:

它表示句子A 與句子B 之間部分內容相似。
4 實 驗
下面討論本文的技術方法與前文論述的3 種方法的比較。
4.1 實驗數據說明
本文實驗數據選取兩個教育新聞進行相似計算,使用維基中文百科和新聞語料訓練的具有超800 萬詞語量的詞向量模型。
文件1:“針對最近我國赴比利時留學人員接連發生入境時被比海關拒絕或者辦理身份證明時被比警方要求限期出境的事件,教育部23 日提醒赴比利時留學人員應注意嚴格遵守比方相關規定。據記者了解,發生以上問題的主要原因是:部分留學人員未能按大學或者語言培訓中心錄取通知書規定的時間報到,在入境時被比海關扣留,一旦學校答復不予注冊,就被拒絕入境;有的留學人員聽信網上發布的信息或傳言,花錢購買所謂‘合法’經濟擔保,辦理身份證明;有的甚至使用假經濟擔保辦理身份證明,比政府有關部門發現查證后,留學人員被要求限期離境。為防止類似事件再次發生,教育部提醒赴比利時高校或者語言培訓中心學習的留學人員,必須嚴格遵守比利時的相關規定,要按照通知的入學注冊日期到學校報到。如果因故延遲,請事先與學校聯系并獲得批準。另外,不要輕信網上或者其他人發布的可以‘有償提供合法經濟擔保或合法身份證明’的信息,以免遭受不必要的損失。”
文件2:“在3 月24 日的法國文化開放日活動的留學專題講座中,法駐穗總領事館文化處文化教育領事穆沙琳、法國駐華大使館語言與學術評估中心CELA 廣州地區主任沈伊莎貝爾、法國教育國際協作署廣州辦事處負責人劉媛媛就有關留學法國進行解答。據介紹,法國的留學政策會優先考慮理工科、商科或管理類專業、碩士及碩士以上學歷以及校級交流和獲得獎學金的學生。雖然去法國讀書的大部分是經濟類專業的學生,藝術類專業學生也不少,這些學生法國都歡迎,但更歡迎理工科學生。法領館的人士強調,對學生沒有明確的分數線要求,主要看各個學生的具體情況。有關人士表示,面試時會了解學生在中國讀書的情況、專業,去法國留學的計劃,希望拿到一個什么樣的文憑,以后想找什么樣的工作,從事什么職業等。據介紹,有的學生到法國后可能會換專業,法國方面會考慮學生本身的條件,看他選的專業對不對,并提出一些建議。”
4.2 實驗分析
本實驗使用句子相似計算中3 種常見方法TFIDF、語義詞典、詞向量加權平均以及本文提出的依存句法+WRD 方法進行相似度計算,結果如表7所示。

表7 4 種句子相似結果對比
從表7 的結果來看:TF-IDF 和語義詞典的相似結果錯誤,因為這兩種方法都無法準確度量相似詞語;詞向量加權平均雖然得到了正確的相似計算結果,但是相似計算得分不高,因為這種方法對所有詞語一視同仁,沒有考慮不同句法結構上的詞語應該區別對待;依存句法+WRD 方法得到了較高的相似計算得分,體現了這兩個文檔的高度相似關系。
5 結語
準確的句子相似計算對數據安全業務非常重要,可以給分類、自動摘要等應用提供準確的決策輔助。本文通過融合依存句法分析技術和WRD 語義距離技術,設計了一種增強的句子相似計算方法。實驗結果表明,該方法得到的句子相似結果更加準確和全面,能夠為數據安全防護應用提供更好的輔助決策和更全面的業務分析手段。
猜你喜歡
中華詩詞(2021年3期)2021-12-31 08:07:22
大連民族大學學報(2021年2期)2021-07-16 05:41:42
開放教育研究(2020年2期)2020-03-31 01:54:14
中華詩詞(2018年3期)2018-08-01 06:40:40
中華詩詞(2018年11期)2018-03-26 06:41:32
現代語文(2016年21期)2016-05-25 13:13:44
國際漢語學報(2016年2期)2016-05-17 04:04:08
大連民族大學學報(2015年2期)2015-02-27 08:28:11
當代修辭學(2014年3期)2014-01-21 02:30:46
當代修辭學(2011年6期)2011-01-29 02:49:50
