基于跡比率的多數(shù)據(jù)集判別分析維數(shù)壓縮
2021-01-26 07:37:18趙小彤宋恩彬
四川大學(xué)學(xué)報(自然科學(xué)版) 2021年1期
趙小彤, 李 智, 宋恩彬,2
(1.四川大學(xué)數(shù)學(xué)學(xué)院, 成都 610064; 2.四川大學(xué)空天科學(xué)與工程學(xué)院, 成都 610064; 3.電子信息控制重點實驗室, 成都 610063)
1 引言
主成分分析算法(PCA)是數(shù)據(jù)挖掘和特征提取的有效工具,在生物信息學(xué)[1-2]、基因組學(xué)、定量金融學(xué)和信號處理等領(lǐng)域有廣泛應(yīng)用. PCA的目標(biāo)是得到高維數(shù)據(jù)的低維表示,同時盡可能保留高維數(shù)據(jù)的信息[3].然而,很多實際場景通常涉及到多個數(shù)據(jù)集,其中人們感興趣的是提取出某個數(shù)據(jù)集相對其他數(shù)據(jù)集特有的信息[1-17]. 例如,考慮兩個基因表達觀測數(shù)據(jù)集,它們來自于對多個種族人群的觀測. 第一個數(shù)據(jù)集包含癌癥患者的基因表達,是我們感興趣的數(shù)據(jù)集,稱之為目標(biāo)數(shù)據(jù). 第二個數(shù)據(jù)集則是由健康人群的基因表達組成,稱為背景數(shù)據(jù). 如果將PCA單獨應(yīng)用于目標(biāo)數(shù)據(jù),或目標(biāo)數(shù)據(jù)與背景數(shù)據(jù)的結(jié)合,可能都僅能獲得兩個數(shù)據(jù)集公共的背景信息(人口模型、性別等),而不能描述癌癥患者的判別信息.為處理上述問題,Abid等[4]首次提出了對比主成分分析算法(cPCA),并將其用于提取兩個數(shù)據(jù)集之間的判別信息. 具體而言,cPCA尋找使得目標(biāo)數(shù)據(jù)方差極大且背景數(shù)據(jù)方差極小的方向.cPCA在選取超參數(shù)時需要進行多次特征分解和譜聚類算法[6],計算復(fù)雜度高. 基于文獻[4],文獻[5]給出了判別主成分分析算法(dPCA),dPCA不需要額外的超參數(shù),計算復(fù)雜度會低一些. 但dPCA不能處理背景方差矩陣奇異的情形,且進行后續(xù)分類算法時分類效果不佳,對高維數(shù)據(jù)的低維特征提取合理性有待改進. 近期,很多學(xué)者將這兩種算法應(yīng)用于各種實際場景[7-8],但這兩種算法在實際應(yīng)用中都具有一定的局限性.
本文提出了一種處理多數(shù)據(jù)集的新方法,稱為跡比率主成分分析算法(trPCA). trPCA通過求解一個跡比率問題提取出目標(biāo)數(shù)據(jù)相對背景數(shù)據(jù)特有的低維表示. trPCA能夠處理背景方差陣奇異的情形,并且計算成本低于cPCA. 進一步,針對多個背景數(shù)據(jù)集情形,本文將trPCA推廣給出了多背景數(shù)據(jù)集跡比率主成分分析算法(MtrPCA),該方法可以提取出某個數(shù)據(jù)集相對其他所有背景數(shù)據(jù)集特有的低維表示.
2 預(yù)備知識

(1)

文獻[4]提出的cPCA方法旨在尋找子空間使得目標(biāo)數(shù)據(jù)集方差盡量大且背景數(shù)據(jù)集方差盡量小. 具體而言,我們解如下問題:
s.t.UTU=Ik
(2)
當(dāng)α=0時,cPCA只選擇極大化目標(biāo)方差的方向,從而退化為只對xi做PCA. 當(dāng)α=∞時,cPCA將目標(biāo)數(shù)據(jù)投影到背景數(shù)據(jù)方差陣的零空間. 因此,α的選取至關(guān)重要.在文獻[4]中,cPCA先根據(jù)多個α的預(yù)選值分別進行特征分解,然后再進行譜聚類,最終輸出幾個α值以及相應(yīng)的子空間. 但是,對于高維數(shù)據(jù),該算法會產(chǎn)生很高的計算復(fù)雜度,并且選擇不適當(dāng)?shù)摩習(xí)?dǎo)致結(jié)果有很大偏差.
基于文獻[4],文獻[5]提出了dPCA方法,即求解下述比率跡(Ratio Trace)問題:
(3)
3 算法描述
3.1 跡比率主成分分析
基于上述分析,我們提出一種新方法.考慮如下的跡比率(Trace Ratio)問題,我們稱之為跡比率主成分分析算法(trPCA):
(4)
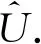
算法3.1跡比率主成分分析
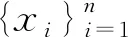
3.計算經(jīng)驗協(xié)方差矩陣Cxx和Cyy;
4.用二分法[10]求解問題(4);
值得注意的是,雖然很多監(jiān)督、半監(jiān)督維數(shù)壓縮算法最終都會轉(zhuǎn)為求解跡比率問題,如線性判別分析(LDA)[13]、邊界Fisher分析(MFA)[14]、局部線性嵌入(LLE)等, 但這些算法所解決的問題都與本文不同.
通過下面的定理,我們可以得出trPCA和cPCA之間的關(guān)系,證明詳見文獻[8].
定理3.2對d階實對稱矩陣Cxx0和Cyy?0,U∈Rd×k,
當(dāng)且僅當(dāng)

由定理3.2可知,當(dāng)α等于某個值時,trPCA和cPCA具有一定的等價性.
前文已經(jīng)提到,dPCA的解經(jīng)過任何一個非奇異矩陣變換之后還是最優(yōu)解,而trPCA的解經(jīng)過正交變換之后還是最優(yōu)解. 因此,如果基于歐氏距離處理聚類或分類問題,trPCA的不同解得到的聚類或分類結(jié)果是不變的,但dPCA的不同解可能會使得投影后的距離發(fā)生改變,從而導(dǎo)致聚類或分類的結(jié)果不穩(wěn)定.
注1當(dāng)k=1,即提取的主成分維數(shù)為一維時,trPCA和dPCA方法是等價的,同為下述優(yōu)化問題:
注2當(dāng)沒有背景數(shù)據(jù)時,Cyy=Id成立,trPCA退化為PCA.
3.2 背景方差奇異情形
為處理Cyy奇異情形,我們將問題(4)等價地轉(zhuǎn)化為下述問題:
(5)
其中Ct=Cxx+Cyy. 問題(5)的目標(biāo)函數(shù)值必然屬于區(qū)間[0,1],且最大值1對應(yīng)于問題(4)的最大值∞. 我們對Cxx的零空間{x|Cxxx=0}不感興趣,這是因為xTCxxx=0,其零空間中不包含關(guān)于目標(biāo)數(shù)據(jù)集的任何有用信息,把它們從問題(5)的約束空間中移除并不會犧牲特征提取準(zhǔn)確度. 實際上,由于屬于Cxx零空間且不屬于Cyy零空間的部分不可能是問題(5)的最優(yōu)解,所以我們只需移除Ct的零空間.
進一步,在很多實際場景中,涉及到越來越多的高維數(shù)據(jù),樣本協(xié)方差矩陣的條件數(shù)很大,甚至接近于奇異情形. 為了更好的特征提取效果,接近Ct零空間的部分也要移除.對Ct進行特征分解可得
Ct=QΛQT
(6)
其中Λ=[λ1,λ2,…,λd],λl≥0,l=1,2,…,d.我們假設(shè)特征值已按由大到小順序排列,Q為正交矩陣. 選取1≤d′≤d-1使得
(7)
其中閾值ε為一個很小的標(biāo)量. 取矩陣Q的前d′列組成矩陣W. 解空間可以被限制在由W的列空間張成的子空間里,即U=WV,V∈Rd′×k. 從而(5)式定義的問題可以轉(zhuǎn)化為如下問題,稱為修正的trPCA方法:
(8)
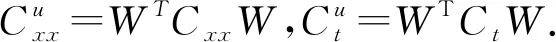
修正的trPCA算法的具體執(zhí)行步驟如下.
算法3.3修正的跡比率主成分分析
3.計算經(jīng)驗協(xié)方差矩陣Cxx和Cyy;
4.利用(6)式進行特征分解;
5.利用(7)去除方差陣接近零空間的部分;
6.利用二分法[10]求解問題(8);
注4當(dāng)Cyy奇異時,由問題(8)可得到和定理3.1類似的結(jié)論.
3.3 多背景數(shù)據(jù)集情形
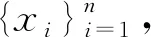
為相應(yīng)的樣本協(xié)方差矩陣. 我們的目標(biāo)是挖掘出能明顯表示目標(biāo)數(shù)據(jù),同時又不屬于任何背景數(shù)據(jù)的潛在子空間向量.
基于dPCA算法,文獻[5]提出了多背景數(shù)據(jù)判別主成分分析(MdPCA),該方法求解以下問題:
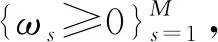
基于前面對單一背景數(shù)據(jù)的分析,我們應(yīng)該尋找使得目標(biāo)方差極大,且所有的背景方差極小的方向. 形式上,我們求解以下極大化問題,稱為多背景數(shù)據(jù)跡比率主成分分析(MtrPCA)算法:
(9)
注5對于參數(shù)ωs的選取有兩種方法:
(i) 用譜聚類[6]的方法選出少數(shù)幾個可以產(chǎn)生最具代表性子空間的ωs;
(ii) 將問題(9)中的ωs與U聯(lián)合進行優(yōu)化.
為了驗證本文所提算法在進行判別分析時的性能,本節(jié)提供了4個數(shù)值算例,與已有算法進行對比.
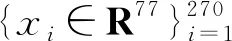
我們對數(shù)據(jù)集{{xi},{yj}}應(yīng)用了trPCA、dPCA與cPCA算法,其中應(yīng)用trPCA算法時(7)式中的ε取成0.001, cPCA算法的參數(shù)α選為1,10和100. 單獨對{xi}進行PCA算法處理. 為了便于展示,所有提取的主成分維數(shù)都為2,并且前兩個主成分即為圖1的橫、縱坐標(biāo). 如圖1所示,圓圈表示接受藥物治療的老鼠,叉號表示沒有接受治療的老鼠,trPCA可以較好地區(qū)分兩個不同的子類,而PCA和dPCA算法不能很好的區(qū)分兩個子類. cPCA算法對α的不同選值較為敏感,特征提取效果不穩(wěn)定.
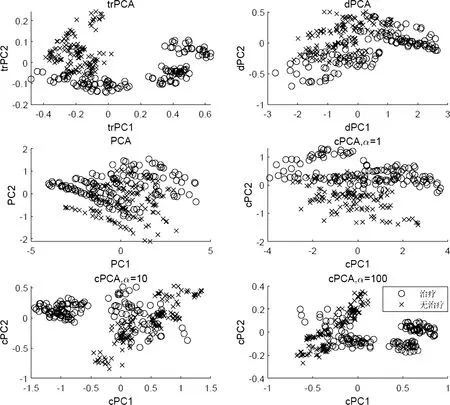
圖1 尋找老鼠蛋白質(zhì)表達數(shù)據(jù)中的子類
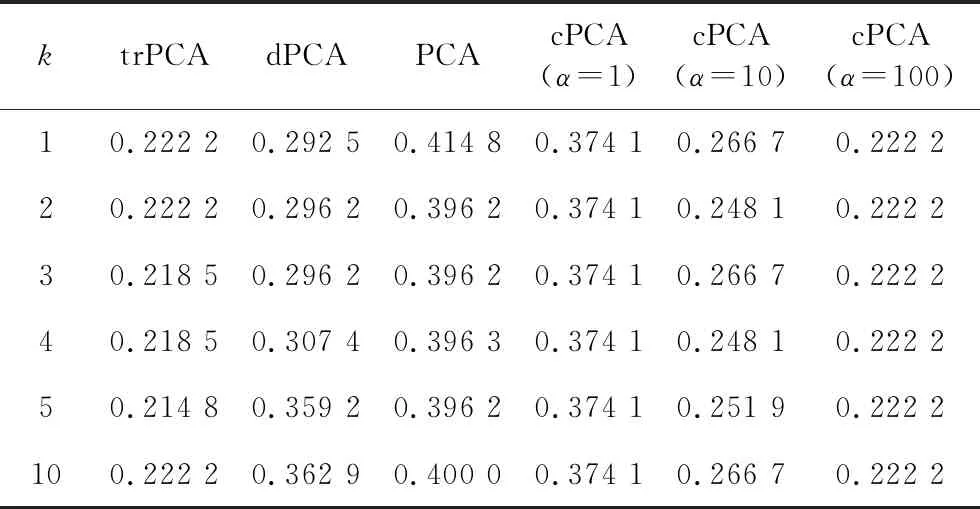
表1 基于老鼠蛋白質(zhì)表達數(shù)據(jù)特征提取的聚類誤差
為了進一步衡量不同算法的表現(xiàn),我們先用這些算法提取出目標(biāo)數(shù)據(jù)的k維主成分,再對提取后的低維表示通過K-均值聚類分成兩類,最后比較這幾種算法的聚類誤差. 聚類誤差定義為錯誤聚類的數(shù)據(jù)個數(shù)與目標(biāo)數(shù)據(jù)的總個數(shù)的比值. 如表1所示,trPCA算法的聚類誤差要小于dPCA和PCA算法,cPCA算法的聚類誤差只有當(dāng)選取合適的α?xí)r才會低一些,但α的選取會產(chǎn)生很高的計算復(fù)雜度. 因而在后面的實驗中我們主要和dPCA算法進行比較.
例4.2當(dāng)背景方差矩陣Cyy奇異時,dPCA算法無法處理,而trPCA算法可以通過解修正的trPCA算法來避免Cyy奇異所帶來的困擾. 在第二個實驗中,為了檢驗trPCA算法處理奇異情形的表現(xiàn),我們考慮由兩個目標(biāo)子集構(gòu)成的目標(biāo)數(shù)據(jù){xi}. 目標(biāo)子類1包含120個280維向量,前200維N(0,1),后80維來自于N(0,10). 目標(biāo)子類2也包含120個280維向量,其中前200維由N(6,1)生成,后80維由N(0,10)生成. 背景數(shù)據(jù)集{yj}包含240個280維向量,前200維來自于N(0,3),后80維來自于N(0,10),詳見表2. 此時Cyy顯然是不可逆的.

表2 背景方差奇異情形下的數(shù)據(jù)生成分布假設(shè)匯總
圖2 背景方差奇異時的特征提取
求解問題(8),提取前兩個主成分trPC1和trPC2可以得到如圖2的結(jié)果,其中的圓圈表示子類1的數(shù)據(jù),叉號表示子類2的數(shù)據(jù).由圖可見,trPCA算法可以很好的處理背景方差奇異的情形,并且能有效提取出目標(biāo)子類相對背景數(shù)據(jù)的判別信息. dPCA算法則無法處理此類問題.
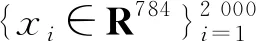
我們對數(shù)據(jù)集{{xi},{yj}}應(yīng)用了trPCA算法和dPCA算法,并單獨對{xi}應(yīng)用PCA算法. 提取的主成分維數(shù)為2. 如圖3所示,點表示數(shù)字1,叉號表示數(shù)字2,trPCA的判別效果要優(yōu)于其它兩種算法.
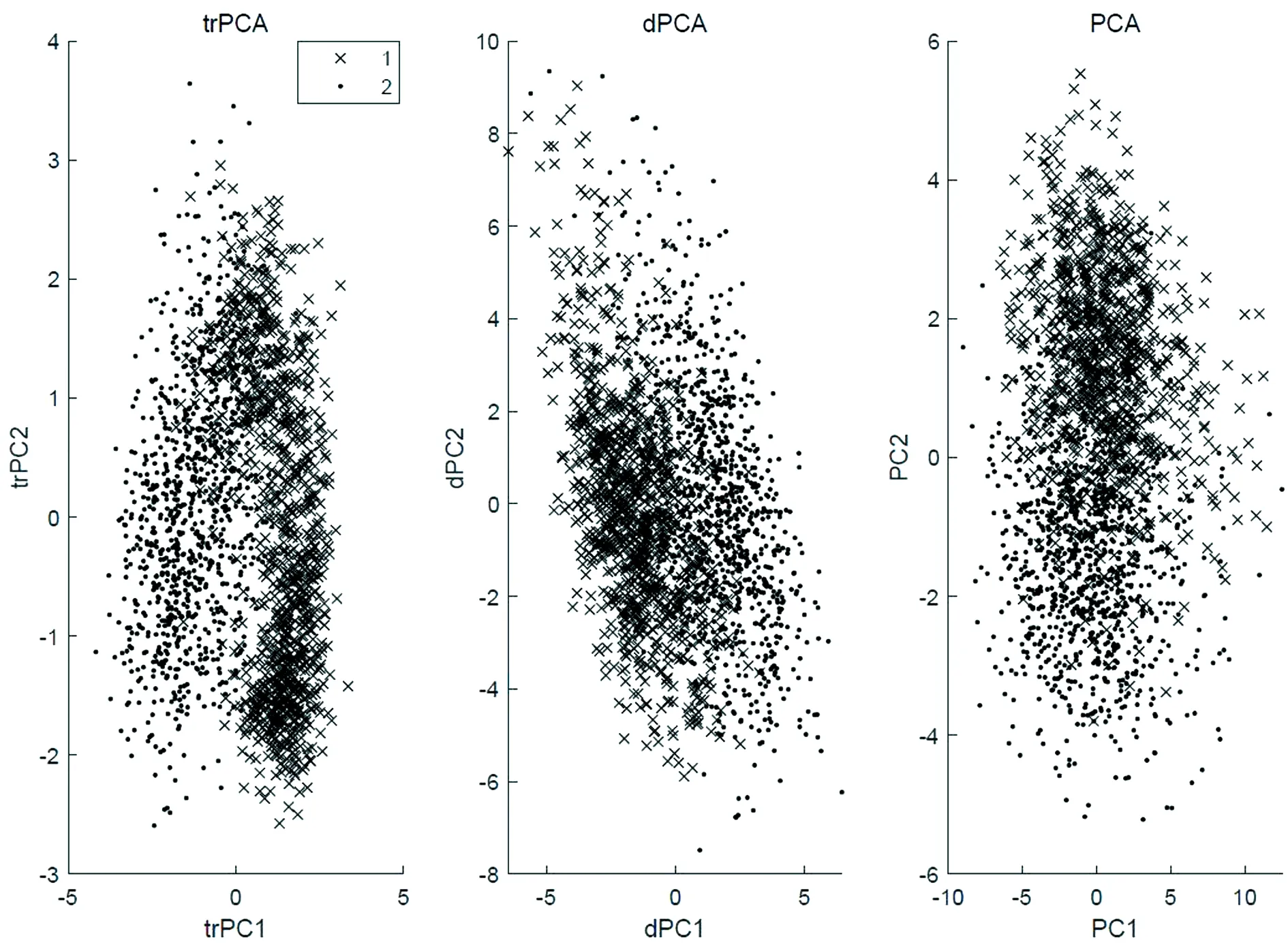
圖3 單背景疊加手寫數(shù)字1和2的特征提取
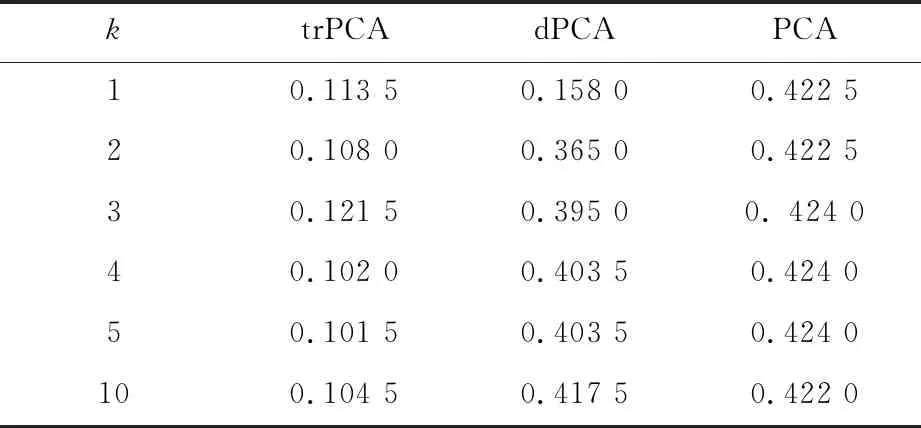
表3 基于單背景疊加手寫數(shù)字特征提取的聚類誤差
接下來,在提取出目標(biāo)數(shù)據(jù)的k維表示后,我們進行K-均值聚類,表3給出這幾種算法的聚類誤差.可見trPCA算法的聚類效果遠好于其它兩種算法.
為了展示trPCA算法在處理高維數(shù)據(jù)時的高效性,下表給出了這幾種算法在MATLAB中處理上述問題時k從1取到10的運行總時間.可見trPCA算法的運行時間小于其它算法,體現(xiàn)了trPCA算法相對于其它幾種算法的高效性.

表4 幾種算法的運行時間比較
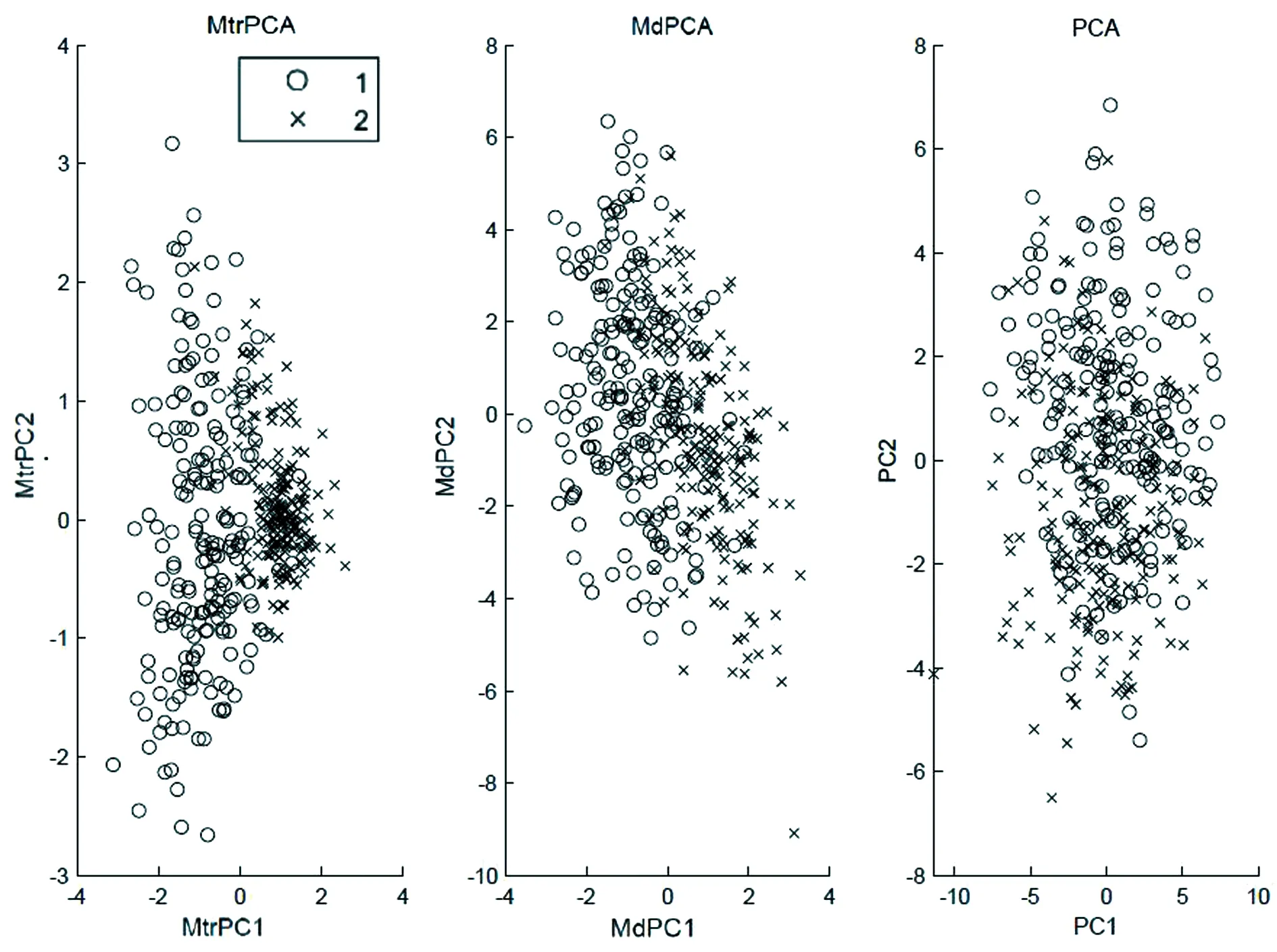
圖4 多背景疊加手寫數(shù)字1和2的特征提取
接下來進行K-均值聚類,當(dāng)提取的特征維數(shù)不同時,相應(yīng)的聚類誤差如下表所示. 可以看到MtrPCA算法的聚類誤差遠小于MdPCA算法和PCA算法.
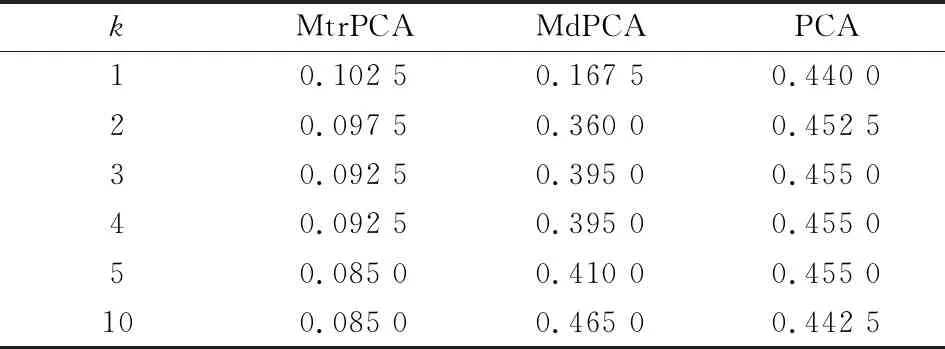
表5 基于多背景疊加手寫數(shù)字?jǐn)?shù)據(jù)特征提取的聚類誤差
5 結(jié) 論
在各種實際場景中,我們更希望能找出某個數(shù)據(jù)集相對于其它數(shù)據(jù)集所具有的獨特判別信息. 本文提出了一種新方法,稱為trPCA算法,對多個數(shù)據(jù)集進行判別分析.該算法可推廣至多背景數(shù)據(jù)模型MtrPCA算法. 與dPCA算法相比,trPCA算法可以處理背景方差矩陣奇異的情形,特征提取效果以及后續(xù)處理分類或聚類問題也都優(yōu)于dPCA算法. 作為cPCA算法的改進,trPCA算法不需要額外的超參數(shù)且有高效的算法進行求解,計算復(fù)雜度低. 最后,多個數(shù)值模擬表明本文所提算法相較于已有算法具有更好的性能.
猜你喜歡
艦船科學(xué)技術(shù)(2022年15期)2022-09-14 09:21:50
汽車工程師(2021年12期)2022-01-17 02:29:54
當(dāng)代陜西(2020年14期)2021-01-08 09:30:42
奧秘(創(chuàng)新大賽)(2020年7期)2020-07-27 08:26:32
電子制作(2019年15期)2019-08-27 01:12:00
電子制作(2018年19期)2018-11-14 02:37:08
自動化學(xué)報(2017年11期)2017-04-04 02:52:58
貴州師范學(xué)院學(xué)報(2016年4期)2016-12-01 03:54:07
紡織服裝流行趨勢展望(2016年1期)2016-05-04 03:45:20
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
