Conditional Random Field Tracking Model Based on a Visual Long Short Term Memory Network
2021-01-23 02:35:14PeiXinLiuZhaoShengZhuXiaoFengYeXiaoFengLi
Pei-Xin Liu | Zhao-Sheng Zhu | Xiao-Feng Ye | Xiao-Feng Li
Abstract—In dense pedestrian tracking, frequent object occlusions and close distances between objects cause difficulty when accurately estimating object trajectories.In this study, a conditional random field tracking model is established by using a visual long short term memory network in the three-dimensional (3D) space and the motion estimations jointly performed on object trajectory segments.Object visual field information is added to the long short term memory network to improve the accuracy of the motion related object pair selection and motion estimation.To address the uncertainty of the length and interval of trajectory segments, a multimode long short term memory network is proposed for the object motion estimation.The tracking performance is evaluated using the PETS2009 dataset.The experimental results show that the proposed method achieves better performance than the tracking methods based on the independent motion estimation.
1.lntroduction
Dense pedestrian tracking is a difficult problem for multiple object tracking (MOT).In the tracking by the detection (TBD) scheme[1]-[5], frequent occlusions lead to the generation of short term object trajectory segments,which carry relatively little information and make it difficult to carry out accurate motion estimations, resulting in errors in data association, thereby reducing the tracking performance.In addition, in a dense pedestrian scenario, the distances between objects are often very small, which causes their motion relation complex and difficult to handle.
Probabilistic graph model methods, such as the conditional random field (CRF) tracking methods[6]-[9]and hypergraph model based tracking methods[10]-[12], take into account the relation between the dense objects and perform global data association, but independent motion estimations of the object trajectories still cannot obtain accurate similarities between the object trajectory segments.In the study of pedestrian trajectory predictions, the social long short term memory (social LSTM) network established in [13] can jointly predict the trajectories of multiple pedestrians nearby, which effectively avoids motion conflicts among objects.In [14], different weights were defined for the spatial relation based on the distance between objects, thus providing a more reliable basis for the joint prediction.In this paper, an improvement called visual LSTM (VLSTM) network is proposed which uses the visual field and spatial position of the objects to find closely related trajectory pairs, thereby estimating the object trajectories more effectively.Based on this VLSTM network, a CRF tracking model is established.The nodes are pairs of trajectory segments with possibilities of temporal association.VLSTM is used to find the trajectory segment pairs with possibilities of motion conflicts based on the object visual field information, and two nodes are connected with an edge.
VLSTM then performs the joint motion estimation on these trajectory segment pairs, calculates the joint similarity between the trajectory segments in the two nodes, and uses this similarity as the binary energy in the CRF model.The similarity between the segments in the nodes without connecting edges is used as the unary energy.According to [7], the data association is transformed into a minimum energy issue to output the objects trajectories.The trajectory segments are of different lengths and the time intervals between them are uncertain.In addition, the LSTM network can use only the trajectory of the predefined fixed duration to obtain the predictions for another fixed duration; therefore, the trajectory prediction network cannot be directly used in the CRF model.Hence, a multimode VLSTM prediction model is designed to adapt to the calculation of the CRF model parameters.
The main contributions of this study are as follows:
1) A VLSTM trajectory prediction model is proposed and the object visual field information is added to the LSTM network to effectively select object pairs with a close spatial relation, thus improving the accuracy of the trajectory prediction.
2) A three-dimensional (3D) spatial CRF data association model is built based on VLSTM to address dense pedestrian tracking issues.
3) A multimode VLSTM motion prediction model is designed for the tracking system to solve the CRF model malfunctioning problem caused by the uncertainties in the lengths of the trajectory segments and the time intervals between trajectory segments.
The rest of this paper is as follows: Section 2 introduces the VLSTM trajectory prediction model,Section 3 discusses the CRF data association model based on VLSTM, and Section 4 describes the experiments, which is followed by conclusions.
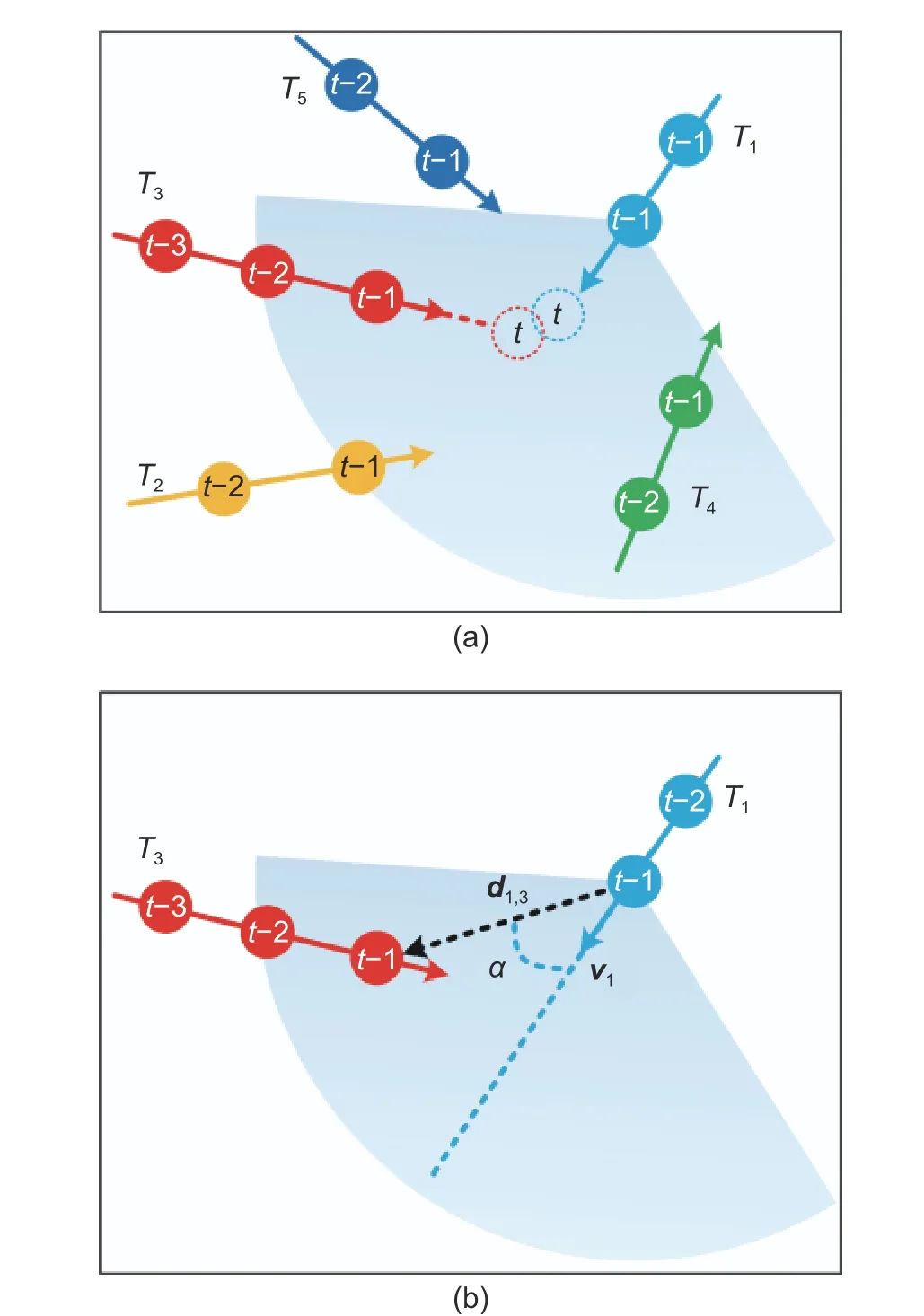
Fig.1.Calculation of motion relation between objects: (a)extraction of visual field information for a trajectory segment and (b) spatial relation based on visual field.
2.VLSTM Trajectory Prediction Model
The trajectory prediction methods in [13] and [14]focused on multiple objects nearby and predicts their future trajectories according to the principle of social force.These schemes make use of the spatial position relation of these objects and the predictions are not very accurate.As shown in Fig.1 (a), to predict the next position of the trajectory segmentT1, the social force theory takes into account the impacts ofT2,T3,T4, andT5.However, through the careful analysis of the pedestrian’s visual field, we think thatT5is out of the sight ofT1and has no effect on the motion ofT1.AlthoughT2,T3, andT4are all within the scope ofT1meanwhileT2andT4are not very close toT1, soT1only pays attention toT3.
In this paper, the crowd interaction deep neural network (CIDNN) proposed in [14] was improved to predict the future trajectories.As that in [14], a location encoder module output the spatial affinities and a motion encoder module employed LSTM networks to encode the motion information for each trajectory segment.A new visual field analysis module is added to identify objects based on their potential impacts.Its output helps the crowd interaction and prediction module to remove the impacts of irrelevant objects by clearing the corresponding spatial affinities.The new framework is called as VLSTM trajectory prediction model as shown in Fig.2.In the location relation encoder, a multilayer fully connected neural network is used to encode the spatial coordinates of trajectory segments.It contains 3 layers, the number of hidden nodes in these layers is 32, 64, and 128, respectively.In the motion encoder, the number of hidden nodes in the motion encoder is 100.

Fig.2.VLSTM trajectory prediction model.
Suppose that the trajectory segment setTcontainsNsegments.In the visual field analysis module, the visual relation between each pair of trajectory segments is calculated.As shown in Fig.1 (a), the visual field ofT1is used to exclude the influence fromT5.For all trajectory segments, a zero-one matrix G of visual correlation is obtained:
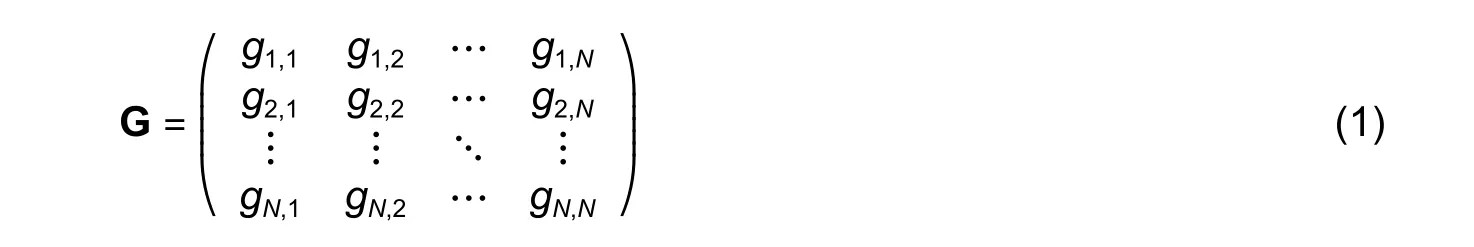
wheregi,jindicates whether a trajectory segmentTjis in the visual field ofTi, calculated by (2):
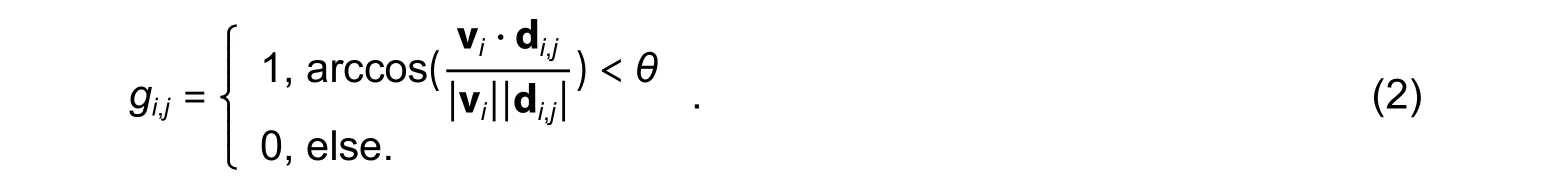
In Fig.1 (b), v1is the motion vector ofT1at timet?1 and d1,3is the displacement vector ofT3fromT1at timet?1.When the angle between the two vectors is smaller than the visual field rangeθ,T3is in the visual field ofT1and therefore,T1andT3are visually correlated.Wheni=j, thengi,j=1.As shown in Fig.1 (a),T1is in the visual field range ofT5, but the reverse is not true, and therefore,gi,j≠gj,i.
As shown in Fig.2, as in the case of CIDNN[14], the 3D position of the trajectory segment is sent to the threelayer fully connected network for encoding, and a spatial correlation matrix A for the trajectories is then created by normalizing the encoded results through the softmax function:
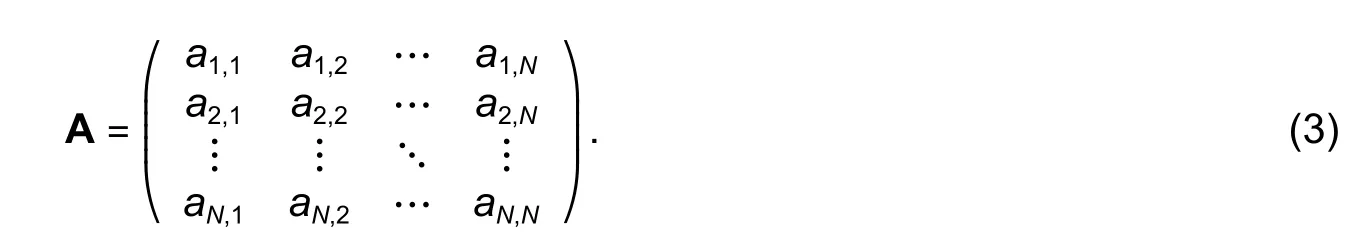
In (3),ai,jis the spatial affinity between trajectory segmentsTiandTjgiven by (4):

where hiis the 128-dimensional encoding vector of the coordinates of the trajectory segmentTi, processed by a three-layer fully connected network.The visual correlation matrix G and the spatial correlation matrix A are element-wisely multiplied to obtain the final trajectory relation matrix C:

where ? is element-wisely multiplied.
The vectors from LSTMs are combined into E.The multiplication of C and E weighs the vectors by the corresponding influences in the visual fields.A fully connected network is then used to obtain the final predicted displacementsF(T).The network training process is designed to solve for the network parameters (6) when the minimum error is achieved:

whereF(Ti(e?n∶e)) is the displacement output of the trajectory segmentTiby VLSTM.The displacement ofδframes is predicted by usingn+1 detection at the tail ofTias the network input.AndF(Ti(e?n∶e),t) is the predicted displacement at the framet,P(Ti(t)) is the coordinate ofTiat the framet, and T is the trajectory annotation set serving as the training reference data.
3.CRF Data Association Model Based on VLSTM
In a sparse pedestrian tracking scenario, the route of each pedestrian is rarely affected by others.Considering the temporal association between objects, the network flow model[3]or the linear programming method[4]can be used to effectively complete the data association.However, in the dense pedestrian scenario, the distances between objects are small and various complex problems, such as occlusions, cooperative motions, and interlaced motions, frequently occur, thus making it very difficult to predict object trajectories or associate trajectory segments.Therefore, the motion relation between the objects is taken into account during data association.In this section, the VLSTM based CRF data association model will be discussed, as shown in Fig.3, including the establishment of the model, the design of the multimode motion estimation model, and the calculation of model parameters.
3.1.VLSTM CRF Model Establishment
As shown in Fig.3, we first use the detection to generate the trajectory segment setT={Ti} by the dual threshold method[15]and then map the coordinate of each trajectory segment into the 3D space through the camera calibration parameters.If the time relation between the two trajectory segmentsTmandTnsatisfies condition (7):

wheret(Tn(e)) is the time of the last detectionTn(e) ofTnandt(Tm(s)) is the frame number of the first detectionTm(s) ofTm.If they are consecutive in time and the time interval is smaller than the occlusion processing range thresholdδo, they have an association possibility.TmandTncan be established as the node vi= (Tm,Tn)to serve as a connection candidate pair andLiis their connection status, whereLi= 1 denotes “connected”andLi= 0 denotes “disconnected”.

Fig.3.Multiple object tracking system framework.
In [7] and [9], if trajectory segments from two nodes were head close or tail close, they would be connected by an edge, and the similarity between the trajectory segments in the two nodes was jointly calculated.This method of establishing edges based on the proximity is similar to the method of measuring the motion relation between trajectories based on the spatial distance in the trajectory prediction methods.Trajectory segment pairs without motion conflicts are considered, which increase the number of edges and thus, complicate the model.In addition,although dense trajectories nodes are connected by edges, the motion estimations of the trajectories segments are still performed independently, which will cause a large deviation in the trajectory similarity calculations and data association errors.To address the above two issues, this study uses the visual field analysis module in VLSTM proposed in Section 2 to guide the establishment of edges and uses VLSTM to perform joint motion estimations on the trajectory segment pairs connected by edges.According to (5), the correlation matrix of the trajectory relation C is obtained.When the maximumCmpis greater than the thresholdδa, a motion conflict is most likely to occur between trajectory segmentsTmandTpat the next frame, i.e., the motion relationship between them is the closest and therefore the joint motion estimation is required.The nodes for these, namely vi= (Tm,Tn) and vj= (Tp,Tq), are connected by the edge ek= (vi, vj).
3.2.Energy Calculation by Multimode VLSTM
In the TBD scheme, the tracking issue is solved for the optimal connection stateL={Li} under the condition of the given tracking segmentT={Ti}, as shown in (8):

According to [11], this maximum posterior probability problem can be transformed into solving the problem of the minimum energy in the CRF model:

whereU(Li∣T) andB(Li,Lj∣T) represent the unary energy function and the binary energy function, respectively.In addition, the object uniqueness constraint condition needs to be met:

In other words, each trajectory segmentTmonly belongs to one object, where F(Tm) is the node set vx=(Tm,Ty) ofTm.t(Tm(e))<t(Ty(s)) is satisfied in these nodes, whilet(Ty(e))<t(Tm(s)) is satisfied in L(Tm).
The unary energy functionU(Li∣T)=?log(P(Li∣T)) represents the association probability ofTmandTnin node vi, which is determined by the appearances and motions of the two trajectory segments in (11):

whereΛa(Tm,Tn) andΛm(Tm,Tn) denote the appearance similarity and motion similarity betweenTmandTn.The appearance similarity is calculated by using color histograms.The color histograms of the head and tail detectionTm(e) andTn(s) are calculated, and the similarity is calculated using the Bhattacharyya distance Bh(·).In a dense pedestrian scenario, more element detection is used to calculate their average similarities:

The calculation of motion similarities is shown in Fig.4.The VLSTM network is used for the forward and backward predictions ofTmandTnand to obtain the predictions for the two trajectoriesThen, the distance between them is calculated and the motion similarity (13) between the two trajectories is calculated by using the Gaussian function, where the mean value is 0, the standard deviation isσ,te=t(Tm(e)), andts=t(Tn(s)).
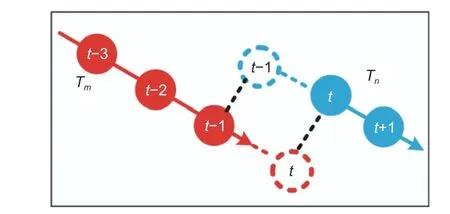
Fig.4.Motion similarity calculation.
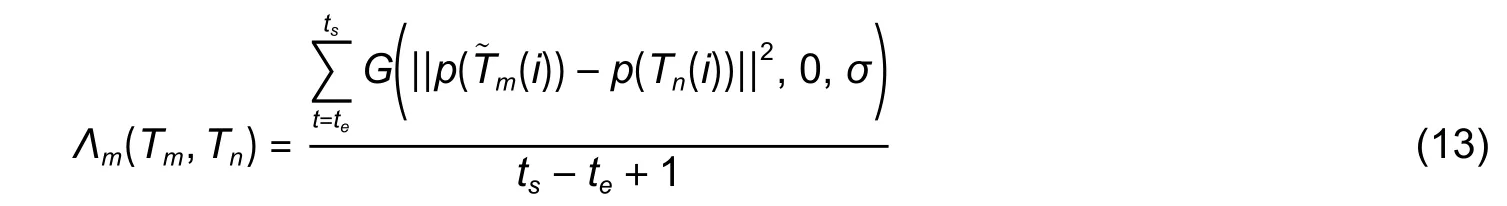
whereG(·) is the Gaussian function,is the estimated coordinates ofTm, andp(Tn(i)) is the coordinates ofTn(i).
Nodes without edge connections mean that the objects are sparse.Similar to the above described process for solving the unary energy function, the VLSTM network works independently, namely as a conventional LSTM network[16].For a dense object trajectory segment pair corresponding to two nodes with an edge connection, their motions are not independent and will interfere with each other; therefore, an independent prediction will cause a matching error.To this end, VLSTM is used to jointly predict them to calculate a binary energy functionB(Li∣T),which is related to the probabilityP(Li,Lj∣T) of the edge ei,j:
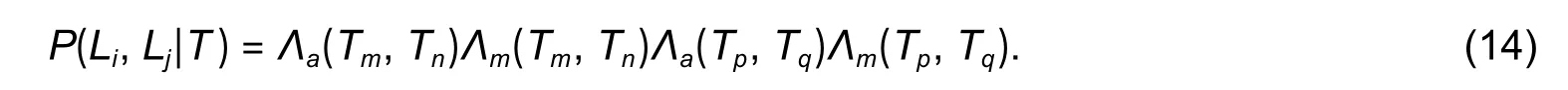
The calculation methods for appearance similarity and motion similarity are the same as those for the unary energy function.P(Li,Lj∣T) is the joint of similarity in the two nodes connected by the edge ek=(vi,vj).The higher the joint of similarity, the higher the connection probability of the two nodes themselves, and the smaller the value of the binary energy function.
In the data association process, because the trajectory segments have different lengths, the time intervals between segments are also different.In addition, the LSTM network can only predict the data from the fixed duration based on the trajectory of a predefined length, and therefore is not suitable for solving the above mentioned uncertainty issue in the tracking.For this reason, we design a multimode VLSTM motion prediction method to solve this problem.We use VL(ori,Nc,Np,δp) to denote a VLSTM network model, where ori is the prediction direction.We take the above described calculation of the motion similarity ofTmandTnas an example.Sincet(Tm(e))<t(Tn(s)),Tmonly requires a forward prediction, whileTnrequires a backward prediction.Ncis the number of jointly predicted trajectories.WhenNc=1, the network is degraded to an independent LSTM network which is suitable for solving a unary energy function for nodes without edge connections.WhenNc>1, it is an issue that considers multiple trajectories, namely, calculating a binary energy function for nodes with edge connections.In this study, only the most closely related trajectory segment pairs are considered,Nc=2.This approach can be extended to find more related trajectories, which would extend the edges to hyperedges.This would make the model more complex but can deal with the complex relations between trajectory segments over a larger range.Npis the number of frames prepared for the prediction, which is determined based on the lengths of the trajectory segments.Andδpis the number of frames predicted, which is determined by the time intervalδobetween the two trajectory segments.
For the model solution, please refer to the approximate solution proposed in [7].The only difference lies in the solution for the time association.In this model, the nodes without edge connections are directly associated based on the unary energy function.The unary energy function of two nodes with an edge connection is associated with the prediction result of VLSTM, so the two unary energy functions are determined by the binary energy function corresponding to the edge.
4.Experiments
In this section, the multiple object tracking system using the multimode trajectory prediction model will be evaluated.Because only the 3D position of the object trajectories is used in the trajectory prediction, this experiment uses the evaluation dataset PETS2009[17]in multiple view multiple object tracking, including the S2.L1 view 1, S2.L2 view 1, and S2.L3 view 1.
The criteria proposed in [18] are used for evaluation.Among these criteria, the multiple object tracking accuracy(MOTA) is the most important tracking performance indicator, which represents the comprehensive performance of FP, FN, and IDs:

where F Ptis the number of false alarms in each frame, FNtis the number of untracked objects in each frame, and IDstis the number of mismatches.Another important tracking performance indicator is the multiple object tracking precision (MOTP), which indicates both the accuracy of data management and the accuracy of the trajectory prediction.The tracking performance is measured by MT and ML, where MT is the number of trajectories whose tracking degrees exceed 80% and ML is the number of trajectories whose tracking degrees are smaller than 20%.
The S2.L1, S2.L2, and S2.L3 datasets are used in the experiment.Two views are used for data fusion to construct 3D tracking trajectory segments.VL(1,2,2,5), VL(?1,2,2,5), VL(1,2,5,5), and VL(?1,2,5,5) are trained to calculate the motion similarity between trajectory segments, and the occlusion threshold is set to 10 to match the predicted range of the network.The four models can adapt to the prediction of various trajectory fragments.The training set of VLSTM is taken from S2.L1, S2.L2, and S2.L3 data sets, respectively.The method of cross selection is adopted, that is, the VLSTM training set for S2.L1 is taken from the Ground Truth of S2.L2, the VLSTM training set for S2.L1 is taken from the Ground Truth of S2.L3, and the VLSTM training set for S2.L3 was taken from the Ground Truth of S2.L2.The stochastic gradient descent method in small-batch is used to optimize the objective function to train the VLSTM.During network training, the minibatch size is set to 256, the learning rate is 0.02, and the number of epochs is 5000.The parameter initialization is the same as that of CIDNN[14].
In the process of data association, an independent fitting method, an independent LSTM method, and a VLSTM method are used to calculate the motion similarities between trajectories and to obtain the object trajectories through data association based on the appearance similarities.The variations in tracking performance are observed by changing the distance threshold between the trajectory segments and the comparison results are shown in Fig.5.

Fig.5.Tracking performance comparisons: (a) S2.L1, (b) S2.L2, and (c) S2.L3.
In Fig.5, the solid line curve represents the tracking method based on the VLSTM network, the dashed curve represents the tracking method based on independent fitting, and the dotted curve represents the tracking method based on independent LSTM.It can be seen from the figure that, in all the three experiments, the VLSTM method achieves the best tracking performance and reaches the peak as soon as the distance threshold increases.This indicates that VLSTM can generate more accurate object predictions than the independent prediction methods.In addition, S2.L2 and S2.L3 are dense pedestrian tracking scenarios.It can be seen that the VLSTM method has obvious advantages over the independent LSTM method, which indicates that considering the closely related object pairs for the trajectory prediction can improve the accuracy of the predictions as well as the tracking performance.In addition, in dense scenarios, there are trajectory segments with different short duration.Due to a lack of information, it is difficult to make accurate predictions using the fitting method.VLSTM is able to provide effective predictions for short segments by using a large amount of training and by considering possible conflicts.
A reasonable distance threshold is selected in the above three experiments to compare the results in terms of the indicators, as shown in Table 1.The arrow direction indicates the better.It is clear that the tracking method based on VLSTM achieves the highest tracking accuracy with the same threshold.In particular, for the dense pedestrian tracking scenarios S2.L2 and S2.L3, the VLSTM-based tracking method is superior in both the maximum tracking rate MT and the loss rate ML, which is also reflected in excellent FP and FN.Fewer IDs indicate that more reliable motion estimation can lead to the better association of the trajectory segments.
Then, the VLSTM based tracking method is compared with other tracking methods based on the conventional motion prediction models using the dense pedestrian datasets S2.L2 and S2.L3; the results are shown in Table 2.The method based on VLSTM achieves the highest object tracking accuracy MOTA and tracking precision MOTP.This shows that the multimode VLSTM motion estimation method is effective for the dense pedestrian scenario.The CRF model based on VLSTM can accurately find the trajectory segment pairs with close spatial relationships,thus improving the tracking accuracy.This is indicated by higher MT and lower ML.Due to the large gap between the trajectory segments caused by occlusions, IDs of the VLSTM method are worse than those of the other methods, so the multimode VLSTM in this study should prepare more mode training for long time occlusions situations.

Table 1:Modular comparison results of the tracking performance

Table 2:Tracking performance comparison with existing tracking methods
Finally, the tracking results of the three scenarios are illustrated.Figs.6 (a), (b), and (c) are the tracking results of S2.L1 (frames 1 to 340), S2.L2 (frames 1 to 100), and S2.L3 (frames 1 to 210), respectively, from the main perspective.From the figures, it can be seen that in the sparse scenario S2.L1, the data association in this study can generate relatively complete object trajectories.For the dense pedestrian tracking scenarios in S2.L2 and S2.L3, the multimode VLSTM trajectory prediction method provides a reliable guarantee for the association of the trajectory segments, as shown in Figs.6 (b) and (c).Although the two sequences are related to dense pedestrians tracking, the object trajectories are reasonable and have not interfered with one another to be deformed.

Fig.6.Trajectories of the tracking results: (a) S2.L1 (frames 1 to 340), (b) S2.L2 (frames 1 to 100), and (c) S2.L3 (frames 1 to 210).
5.Conclusions
In this paper, the frequent occlusions problem of dense pedestrian tracking is studied, and a VLSTM based CRF data association model is proposed to address the association of dense trajectory segments.VLSTM is used to establish edges and calculate the CRF model parameters.Object trajectories are obtained by solving for the minimum energy of the model.Through the tracking system experiment, the addition of VLSTM improves the tracking performance.Compared with the conventional linear, nonlinear fitting, and the independent LSTM network motion estimation methods, the multimode trajectory prediction model can not only perform robust predictions with limited information, but also provide predictions of complex motions.These advantages are all required in dense pedestrian tracking scenarios.The future research will consider adding the appearance information to VLSTM for joint training, which may further improve the prediction accuracy and robustness of the network.
Disclosures
The authors declare no conflicts of interest.
 Journal of Electronic Science and Technology2020年4期
Journal of Electronic Science and Technology2020年4期
- Journal of Electronic Science and Technology的其它文章
- Smart Meter Development for Cloud-Based Home Electricity Monitor System
- Approach for Grid Connected PV Management:Advance Solar Prediction and Enhancement of Voltage Stability Margin Using FACTS Device
- Comparative Study of 10-MW High-Temperature Superconductor Wind Generator with Overlapped Field Coil Arrangement
- Characteristic Length of Metallic Nanorods under Physical Vapor Deposition
- Computational lntelligence Prediction Model lntegrating Empirical Mode Decomposition,Principal Component Analysis, and Weighted k-Nearest Neighbor
- Data Bucket-Based Fragment Management for Solid State Drive Storage System