基于SSA-LightGBM的交通流量調查數據趨勢預測①
2021-01-22 05:43:42孫朝云楊榮新
計算機系統應用 2021年1期
徐 磊,孫朝云,李 偉,楊榮新
(長安大學 信息工程學院,西安 710064)
隨著國民經濟的發展,我國機動車數量快速增長,道路擁堵時常發生,高速公路作為我國公路的楷模,其服務水平比一般的道路更好.交通流量調(交調)數據是研究高速公路通行能力的重要參考指標,為了提高高速公路的服務水平,對高速公路進行更好的整修和養護,亟需加強對交調數據的預測研究.
預測研究的關鍵在于預測模型的建立,提高預測結果精準度的重要方法便是選擇合適有效的預測模型.序列預測通常分為時間序列預測和多元回歸預測,目前在國內外研究中,大多是通過傳統的神經網絡方法對序列進行預測.例如,Zhou 等人針對傳統數學統計方法的局限性等問題建立BP 神經網絡預測模型,通過將BP 算法與指數平滑和線性回歸方法進行比較,最后證明了BP 算法預測結果能為企業制定庫存計劃提供更好的建議[1].成云等人針對現階段城市道路交通流預測精度不高的局限性,提出了一種基于差分自回歸滑動平均和小波神經網絡組合模型的預測方法來進行交通流預測,最后證明了組合模型可以提高交通流預測精度[2].Zhang 等人為了更準確的預測交通流量,實現交通控制和交通擁堵管理,提出了一種基于XGboost和LightGBM 算法的組合預測模型,實驗結果表明組合模型比單個模型有更高的預測精度[3].Wu 等人針對2008-2018年云南省貨運數據及其影響因素建立了灰色神經網絡模型,對云南的貨運量進行了預測,并將其與BP 神經網絡預測結果進行比較最后證明了灰色神經網絡具有更好的預測效果[4,5].Li 等人考慮到植物蒸騰量對溫室自動灌溉具有重要的作用,在2020年建立了隨機森林回歸模型,通過整合植物和環境參數建立植物蒸騰量預測模型,該研究為溫室種植蔬菜高效生產和智能灌溉提供了科學參考,為節約水資源也提供了一種有效途徑[6].
上述方法中無論是采用單純的數學模型還是采用機器學習模型對長期的周期性比較強的數據均不能實現精準預測,只能粗略的顯示數據的大致走向,局部詳細的信息表現較差,因此本文考慮到高速公路交調數據具有很強的周期性等特點提出了基于SSA-LightGBM的預測模型.
1 研究數據選取及算法流程
本文針對陜西省高速公路展開研究,對韓城高速公路進行實地考察調研,以韓城高速7~8月1344 條交調數據進行研究.
1.1 數據介紹
表1為韓城高速交調數據表(前5 行數據).從表中可以看出交調數據一共由觀察日期、小時、觀測站名稱、觀測里程、中小客流量、大客車流量、小貨車流量、中貨車流量、大貨車流量、特大貨車流量、集裝箱流量組成.

表1 韓城高速交調數據表
為了使不同交通工具組成的交通流能夠在同樣的尺度下進行分析,使其具有可比性,在分析計算通行能力和服務水平時,需要將各類車輛交通量換算成標準機動車當量,需要用到車輛換算系數,如表2所示,這里只考慮汽車,將其分為3 檔:小型車、中型車、大型車,其中小型車又分為中小客車和小型貨車,折算系數為1;中型車分為大客車和中型貨車,折算系數為1.5;大型車分為大型貨車、特大貨車和集裝箱車,大型貨車折算系數為3,特大貨車和集裝箱車折算系數為4.

表2 折算系數參考表
1.2 數據展示
通過對韓城高速交調數據進行換算,如圖1對機動車當量進行可視化,展示了2019年7月1日-2019年8月25日韓城高速公路交調數據當量變化.從圖中可以清晰的看出除了少數天呈現極小或者極大的情況,其他天數整體呈現周期狀態.當量=小型車×1+中型車×1.5+大型貨車×3+特大貨車×4+集裝箱車×4.

圖1 韓城高速交調當量變化圖
1.3 算法流程圖
本文的算法流程圖如圖2所示對原始數據進行整合,計算出高速公路交調數據機動車當量,然后對原始數據利用奇異普分解方法(SSA)進行數據分解,得到周期信號和隨機信號,再利用機器學習模型(LightGBM)對隨機項進行預測,將預測結果和周期延伸信號結合得到最終的預測結果.另一方面利用XGBoost、LightGBM等單獨的機器學習方法對當量數據進行預測,最后將預測結果同SSA-LightGBM 方法得到的結果進行對比分析,比較不同模型的預測效果.

圖2 算法流程圖
2 SSA-LightGBM 預測模型原理
2.1 奇異譜分解(SSA)
奇異譜分解(Singular Spectrum Analysis,SSA)是通過分解原序列中的時間主分量,得到不同層次上的分量序列,然后將分解出來的低頻視為序列變化的長期趨勢,最終得到數據序列的最佳諧波個數,以此確定時間序列的周期信號.
本文將奇異譜分解分為4 個步驟,分別是:
(1)嵌入.選擇適當的窗口長度m,將一維時間序列Y(T)=((y1),···,(yT))轉換為多維時間序列:X1,···Xn,(Xi=(yi,···,yi+m?1),n=T?m+1),得到軌跡矩陣,即:
(2)奇異值分解.通過對矩陣SVD 分解,得到XXT的L個特征值.具體步驟是:將X轉置得到XT,然后利用XXT得到方陣,再利用方陣的性質求得矩陣的特征值[7-9],即利用(XTX)νi=λiνi,求得σ即是奇異值,μ是奇異向量.
(3)分組.假設有N個奇異值σ1,σ2,···,σN,定義第i個奇異值的方差貢獻率為由大到小選擇前M個奇異值,使其方差貢獻率之和大于一定閾值.
(4)確定最佳諧波個數.利用前M個奇異值的方差貢獻率之和大于一定閾值(0.85)來確定最佳諧波個數M.當P(i)≥0.85 時,我們認為此時的i即為最佳的諧波個數,即M=i.然后利用三角函數的性質將數據構造成周期函數.
2.2 周期項和隨機項的確定
設{yt,t=1,2,···,N}為時間序列,若將其看作由周期項和隨機項組成,可以用組合模式yt=pt+xt描述,其中pt為 周期項,xt為隨機項.pt的表達式如下:

其中,M為諧波個數,
2.3 LightGBM 模型
LightGBM 是一種梯度Boosting 框架,使用基于決策樹的學習算法,具有快速、高效、支持并行化學習、可以處理大規模數據等優點.
(1)梯度提升.
梯度提升是在不斷的迭代過程中,對模型不停的增加子模型,同時保證最終的損失函數值在不斷的下降.GBDT 是一種梯度提升決策樹,是由多個決策樹組成,利用最速下降的近似方法,即利用損失函數的負梯度在當前模型的值作為我們回歸提升樹算法的殘差的近似值,來擬合一個回歸樹[10-12].
假設我們每一個單獨的子模型為fi(x),我們的復合模型為:

損失函數為L[Fm(x),Y],每一次對模型中添加新的子模型后,使得我們的損失函數不斷朝著0 發展.
(2)LightGBM 原理
LightGBM 是在傳統的梯度提升樹(GBDT)上使用直方圖優化(Histogram)算法,先把連續的特征值離散化成k個整數,同時構造一個寬度為k的直方圖.在遍歷數據的時候,根據離散化后的值作為索引在直方圖中累積統計量,當遍歷一次數據后,直方圖累積了需要的統計量,然后根據直方圖的離散值,遍歷尋找最優的分割點.同時使用帶深度限制的Leaf-wise 的葉子生長策略,經過一次數據可以同時分裂同一層的葉子,容易進行多線程優化,也好控制模型復雜度,不容易過擬合[13-15].表3給出LightGBM 模型主要參數含義.

表3 LightGBM 模型參數含義
3 SSA-LightGBM 模型預測分析
3.1 對數據進行奇異譜分解
此處將2019年的7月1日到2019年8月25日的1344 條數據分為兩部分,利用前70%的941 條數據預測后30%的403 條數據并將其與對應的真實數據進行對比.對前部分數據進行奇異譜分析時選取的窗口長度為200,可以得到方差貢獻率圖(見圖3).從圖中可以看出,當i≥56 時,P(i)≥85%,滿足本文的數據處理要求,即當顯著諧波個數M為56 時,對應個三角函數信號能表征序列的最主要趨勢.

圖3 方差貢獻率圖
然后,可構造周期函數,得到圖4.周期函數對應的公式為:

式中,M為諧波個數56,

圖4 周期函數對比圖
表4詳細介紹了周期函數Pt 中每一個參數的具體含義和取值.根據周期函數的性質,利用周期不變性對周期函數進行延伸得到2019年8月9日到8月25日周期函數延拓圖(圖5).然后由交調當量原始數據減去周期項(xt=yt?pt),可得到圖6所示的隨機項.

表4 周期函數各參數含義
本文采用LightGBM 機器學習方法對交調當量隨機項數據進行預測,表5為LightGBM 模型常用參數的取值,其他參數均采用默認.圖7中曲實線為交調當量隨機項前941 條數據,后面虛線為使用LightGBM預測的403 條隨機當量數據.
4 預測效果評價
我們將SSA-LightGBM 模型得到的2019年8月9日到8月25日周期函數延拓結果和隨機項預測值相疊加得到最終交調當量預測值(見圖8,紅色曲線).為了驗證SSA-LightGBM 模型的預測效果,本文還分別用XGBoost 和LightGBM 機器學習方法對數據進行了預測(利用2019年7月1日到8月8日的數據預測2019年8月9日到8月25日的數據).由于這2 種模型為單純機器學習預測方法,且不是本文的研究對象,故此處不詳細描述各種方法的預測過程.將不同預測模型得到的預測結果與韓城交調當量的原數據進行對比,得到圖8.圖中黑色曲線為韓城高速交調數據的原數據,紅色曲線為SSA-LightGBM 模型的預測結果,XGBoost 和LightGBM 模型的預測結果分別對應藍色和綠色虛線.從圖中可以發現,單獨使用XGBoost 和LightGBM 模型得到的曲線整趨勢能表示原始數據,但是整體均低于原始數據不能完整的表示當量的局部特征.只有橙色虛線SSA-LightGBM 模型預測的結果能夠實現高精度穩定預測2019年8月9日到8月25日交調當量變化趨勢.
另外,本文還采用常用的平均絕對值誤差(MAE)、均方根誤差(RMSE)和相關系數(R2)分析評價了不同模型預測結果的精度(表6),各指標的公式、含義及評價標準見表7.從表中可以發現本文的模型MAE和RMSE均低于XGBoost 和LightGBM 模型說明模型的穩定性和平均誤差優于單獨的機器學習模型,R2大于另外兩個模型說明預測效果好相關性強.

圖5 周期函數延拓圖

圖6 交調當量隨機項

表5 LightGBM 模型參數取值

圖7 隨機項預測結果

圖8 不同模型預測結果對比圖

表6 各模型評價指數
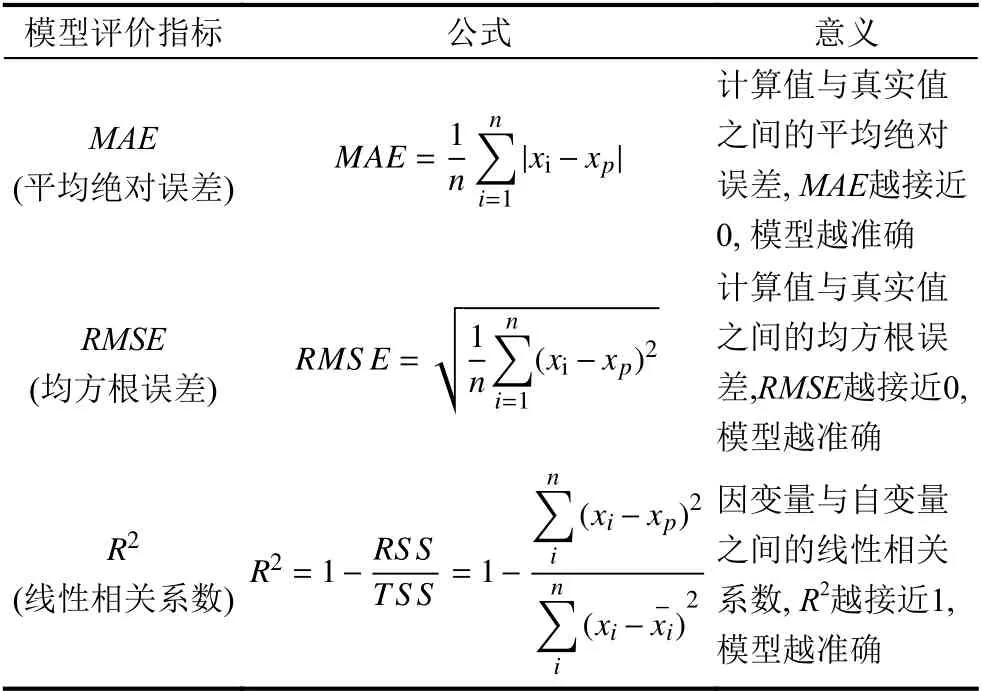
表7 評價指標
綜上,無論是直觀的曲線對比(圖8),還是數學統計方法(表6),均證明SSA-LightGBM 模型可以高精度、高穩定性地預測2019年8月韓城高速交調數據當量變化趨勢.我們可以使用該模型對全國的高速公路交調數據進行預測,這對我國高速公路更好的休整和養護以及服務水平的提升具有重要的參考價值.
5 結論
由于傳統的時間序列預測模型和單獨的機器學習模型對周期性比較強的時間序列預測存在一定弊端,本文采用SSA-LightGBM 模型進行預測,以韓城高速2019年7月到8月兩個月1344 條交調數據為例,以前70%的數據作為模型的訓練集,以后30%的數據作為驗證集.將結果與單純的機器學習模型XGBoost 和LightGBM 模型進行對比,發現本文提出的模型預測結果更接近真實值,同時該模型的MAE、R2和RMSE均優于其他兩個模型,表明本文的模型可以很好地預測韓城高速交調當量數據,這對該地區高速公路的整修擴建、養護具有一定的指導意義.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
建材發展導向(2021年20期)2021-11-20 05:43:18
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
小學閱讀指南·低年級版(2017年11期)2017-12-06 15:14:59
光學精密工程(2016年6期)2016-11-07 09:07:19
中國交通信息化(2016年9期)2016-06-06 07:42:10
核科學與工程(2015年4期)2015-09-26 11:59:03
小說月刊(2014年4期)2014-04-23 08:52:20
河南科技(2014年18期)2014-02-27 14:15:06
