基于熵權(quán)層次分析法的云平臺負載預(yù)測
2021-01-20 08:31:56王宗杰
計算機工程與設(shè)計 2021年1期
關(guān)鍵詞:模型
王宗杰,郭 舉,2+
(1.北京科技大學(xué) 計算機與通信工程學(xué)院,北京 100083;2.北京起重運輸機械設(shè)計研究院 研發(fā)中心,北京 100007)
0 引 言
通過將底層硬件資源抽象為虛擬機節(jié)點[1],云平臺可持續(xù)穩(wěn)定地處理頻繁且種類多樣的用戶請求,但同時產(chǎn)生了計算節(jié)點間負載不均衡的問題。伴隨著云計算技術(shù)的迅猛發(fā)展[2],出現(xiàn)了不同種類[3]的負載均衡技術(shù)[4],緩解了云平臺負載不均衡的問題[5]。目前國內(nèi)外關(guān)于云平臺的負載均衡技術(shù)理論研究和工程實踐產(chǎn)生了大量的研究成果。文獻[6]利用層次分析法分析4種影響云平臺負載的因素,計算云平臺的負載值。該負載值能較好反映當(dāng)前平臺的資源利用情況,但使用單一的主觀賦權(quán)法所得權(quán)值具有主觀片面性。文獻[7]利用熵權(quán)法建立了對輸電方案的模糊評價模型,提取了評價指標(biāo)的有效信息,但使用單一客觀賦權(quán)法所得結(jié)果不全面。文獻[8]利用指數(shù)平滑法預(yù)測了云平臺的負載值,預(yù)測值由歷史負載值加權(quán)平均得到。該模型系統(tǒng)資源占用小,但負載誤差會逐步增大,預(yù)測精度較低。文獻[9]提出基于支持向量機的云平臺資源分配策略,實現(xiàn)對云平臺資源的動態(tài)分配。文獻[10]利用哈希算法將數(shù)據(jù)存放到不同的數(shù)據(jù)節(jié)點上,實現(xiàn)各節(jié)點的負載均衡。文獻[11]提出了能量感知資源管理算法,動態(tài)調(diào)整虛擬機資源分配情況。針對前人研究存在的問題,提出了更全面的負載評估模型和負載預(yù)測算法,實驗結(jié)果驗證了其有效性。
1 云平臺負載評估預(yù)測方案
云平臺負載評估預(yù)測方案包含負載評估和負載預(yù)測兩部分內(nèi)容。負載評估階段選取4種評價指標(biāo),利用層次分析法和熵權(quán)法計算出云平臺負載序列值。然后,采用差分整合移動平均自回歸模型 (autoregressive integrated moving average model,ARIMA)和BP(back propagation)模型和BP神經(jīng)網(wǎng)絡(luò)分別處理負載序列的線性部分和非線性部分,最終得出云平臺負載預(yù)測值。
1.1 層次分析法
層次分析法(analytic hierarchy process,AHP)是對一些較為復(fù)雜模糊的問題作出決策的多準(zhǔn)則決策分析方法[12],主要目標(biāo)是解決多目標(biāo)的復(fù)雜問題,它本質(zhì)上是一種建立在對問題定性和定量基礎(chǔ)上的決策分析方法。為了得到被評價屬性的權(quán)值,它采用決策者主觀經(jīng)驗判斷各個屬性之間的相對重要程度,建立評價矩陣,隨后逐步計算得出各個屬性的權(quán)值,適用于一些定量方法難以應(yīng)用的復(fù)雜問題。
本文采用AHP法賦權(quán)計算主觀權(quán)重,主要方法和步驟如下:
步驟1 構(gòu)建遞階層次結(jié)構(gòu)模型。
步驟2 根據(jù)各屬性指標(biāo)的相對重要程度,建立判斷矩陣
其中,c、m、d、n依次代表計算資源、內(nèi)存資源、硬盤資源、帶寬資源。Wij表示資源i對資源j的重要程度,其取值依照九分位比例標(biāo)尺。判斷矩陣完成之后,需依照式(1)、式(2)對其進行完整性檢查
(1)
(2)
步驟3 計算權(quán)重向量
采用方根法計算權(quán)重向量。將判斷矩陣WA中的元素按照每行相乘得到新向量WT,再將該新向量的每個分量開n次方(此處n為4)得到向量WL,最后將所得向量WL進行歸一化處理即得權(quán)重向量W。
步驟4 一致性檢驗

表1 平均隨機一致性指標(biāo)
步驟5 調(diào)整判斷矩陣
若判斷矩陣通過步驟4的一致性檢驗,則歸一化后的權(quán)重向量即是各因素的權(quán)重系數(shù)。否則需對判斷矩陣進行調(diào)整,直至滿足一致性檢驗。
1.2 熵權(quán)法
熵最早由香農(nóng)引入信息論,目前已經(jīng)在金融經(jīng)濟、制造技術(shù)等眾多領(lǐng)域得到了眾多應(yīng)用。一般來說,信息熵Ej越小的指標(biāo),其變異程度越大,包含的信息量也越多,對綜合評價的影響也越大,那么分配的權(quán)重也應(yīng)該越大;反之,該指標(biāo)分配的權(quán)重越小。熵權(quán)法(entropy wright method,EWM)的原始數(shù)據(jù)來源于評價過程中,這一方面可以充分利用歷史數(shù)據(jù)對權(quán)重的影響程度,但另一方面也造成熵權(quán)法在確定指標(biāo)時會隨著樣本的變化而變化,對數(shù)據(jù)樣本具有依賴性,限制了對其的應(yīng)用。
本文在建立評價模型時,采用熵權(quán)法獲得各指標(biāo)的客觀權(quán)重,具體計算步驟如下:
步驟1 構(gòu)建初始矩陣并進行標(biāo)準(zhǔn)化處理
對于給定的N個對象,M個指標(biāo)P1,P2…PM, 其中Pi={p1,p2,…pN}, 構(gòu)建初始矩陣X
對初始矩陣采用歸一法進行標(biāo)準(zhǔn)化處理,得新的矩陣Y,其中
(3)
步驟2 計算各指標(biāo)的信息熵
由上面對信息熵的定義,可得一組數(shù)據(jù)的信息熵為
(4)
其中,pij由式(5)給出,若pij=0,則都定義
(5)
步驟3 計算各指標(biāo)的權(quán)重
根據(jù)信息熵的計算公式,可計算出各個指標(biāo)的信息熵為Ei,利用式(6)可計算出各個指標(biāo)的權(quán)重
(6)
1.3 自回歸積分移動平均模型
基于時間序列的預(yù)測技術(shù)通過統(tǒng)計分析收集的歷史數(shù)據(jù),獲得一般的事物變化趨勢,對數(shù)據(jù)進行不同程度的處理,減少外界因素對變化規(guī)律的影響,最終對事物的發(fā)生進行預(yù)測。ARIMA是一種較常用的基于時間序列的預(yù)測模型[13]。
本文利用ARIMA模型對ARMA(自回歸滑動平均模型)模型進一步優(yōu)化,解決了ARMA只能分析平穩(wěn)序列的問題。ARIMA實質(zhì)是ARMA模型與查分運算的組合形式,首先通過一定階數(shù)的差分處理時間序列數(shù)據(jù),使不平穩(wěn)數(shù)據(jù)成為平穩(wěn)數(shù)據(jù),接下來就可以使用ARMA模型對差分后的數(shù)據(jù)進行擬合。ARIMA模型在時間序列分析方法中應(yīng)用的比較廣泛,建模流程如圖1所示。
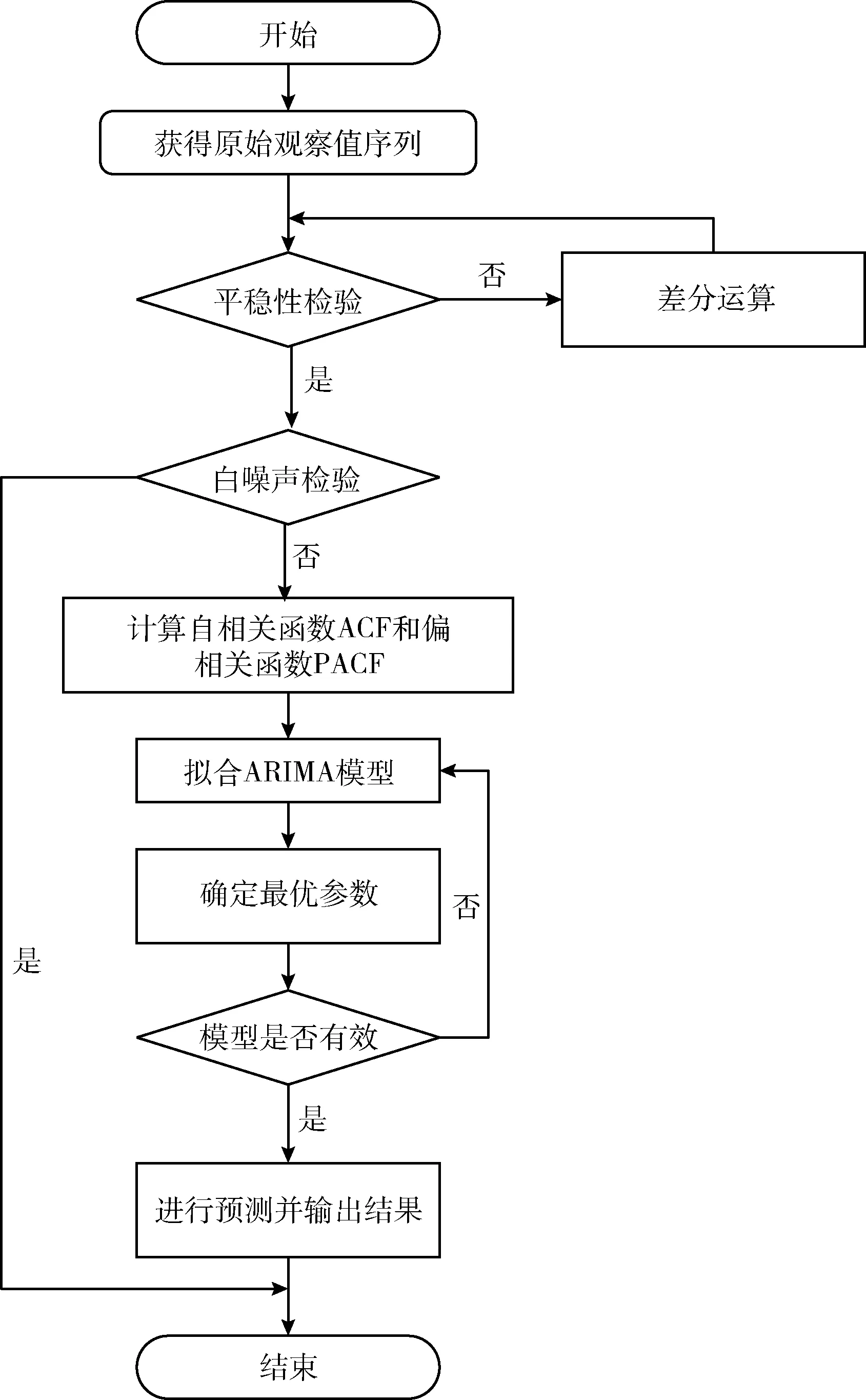
圖1 ARIMA建模流程
首先對時間序列數(shù)據(jù)進行平穩(wěn)性檢測、白噪聲檢驗處理,其后通過自相關(guān)函數(shù)和偏相關(guān)函數(shù)PACF確立ARIMA模型的參數(shù)范圍,并通過數(shù)據(jù)擬合確定最終模型參數(shù)。最后使用ARIMA模型預(yù)測時間序列數(shù)據(jù)。
1.4 BP神經(jīng)網(wǎng)絡(luò)
BP神經(jīng)網(wǎng)絡(luò)是一種按照誤差逆向傳播算法訓(xùn)練的多層前饋神經(jīng)網(wǎng)絡(luò),是目前被廣泛應(yīng)用在預(yù)測領(lǐng)域的模型。BP神經(jīng)網(wǎng)絡(luò)主要依靠自身的訓(xùn)練,自主訓(xùn)練某些數(shù)據(jù)規(guī)律,不需要提前給出輸入輸出之間的映射關(guān)系。在應(yīng)用時,只需給出輸入值,即可給出最接近期望輸出值的預(yù)測結(jié)果。BP神經(jīng)網(wǎng)絡(luò)實現(xiàn)預(yù)測的核心是BP算法,其思想利用梯度搜索技術(shù)和梯度下降法,最終獲得輸出值和實際值的誤差的均方差最小。BP神經(jīng)網(wǎng)絡(luò)的拓撲結(jié)構(gòu)如圖2所示。
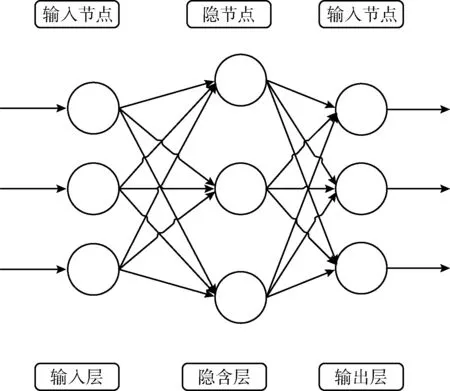
圖2 BP神經(jīng)網(wǎng)絡(luò)拓撲結(jié)構(gòu)
BP神經(jīng)網(wǎng)絡(luò)首先根據(jù)業(yè)務(wù)目標(biāo)選取樣本數(shù)據(jù)。之后進行數(shù)據(jù)預(yù)處理操作。對于短期變化劇烈的數(shù)據(jù)不適合直接作為輸入數(shù)據(jù)。輸入數(shù)據(jù)序列越穩(wěn)定均勻,對于建模預(yù)測就越有利。一般建立BP神經(jīng)網(wǎng)絡(luò)之前,首先會對數(shù)據(jù)進行歸一化處理,得到平滑的數(shù)據(jù)序列作為網(wǎng)絡(luò)的輸入,歸一化處理后,一定程度上降低最終預(yù)測結(jié)果中的無效噪聲。
其次根據(jù)負載特點,設(shè)計網(wǎng)絡(luò)結(jié)構(gòu)并給出網(wǎng)絡(luò)的相關(guān)參數(shù),包括網(wǎng)絡(luò)層數(shù)、輸入輸出節(jié)點書、隱含層節(jié)點數(shù)、激活函數(shù)等。正確設(shè)計這些參數(shù),對于預(yù)測效果至關(guān)重要。
模型建立完成之后,開始訓(xùn)練數(shù)據(jù)樣本集。當(dāng)網(wǎng)絡(luò)訓(xùn)練的次數(shù)達到上限或輸出的數(shù)據(jù)誤差滿足要求時,輸出訓(xùn)練好的模型并對負載值進行預(yù)測。其訓(xùn)練過程如圖3所示。

圖3 BP神經(jīng)網(wǎng)絡(luò)訓(xùn)練過程
1.5 基于ARIMA-BP的云平臺負載預(yù)測模型
對于云平臺的負載值來說,它受到內(nèi)部因素和外部因素的影響,因此云平臺的負載值中隱含了線性特征和非線性特征,是線性特征影響因素和非線性特征影響因素的綜合反映。
對于負載值的預(yù)測可以使用適應(yīng)處理分析線性時間序列的模型和適應(yīng)處理分析非線性時間序列的模型組成的組合模型對其分析處理。
本文使用線性擬合能力較好的ARIMA模型和非線性擬合能力較好的BP神經(jīng)模型構(gòu)成組合預(yù)測模型,對云平臺的負載值進行分析預(yù)測。ARIMA模型可以提取出云平臺負載值的線性特性,BP神經(jīng)網(wǎng)絡(luò)可以提取出云平臺負載值的非線性特征,兩者結(jié)合構(gòu)成的組合模型不僅彌補了只采用單一預(yù)測模型分析的不足之處,又能夠充分發(fā)揮各個預(yù)測模型的優(yōu)勢之處。組合模型的整體流程如圖4所示。
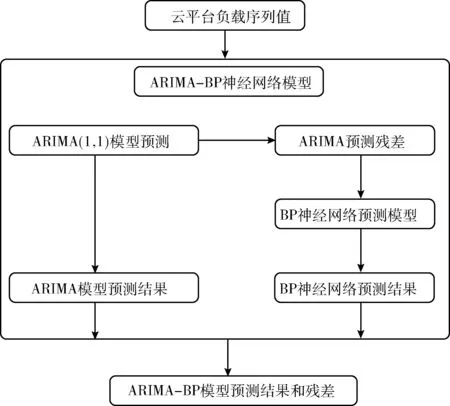
圖4 基于ARIMA-BP的組合模型原理
2 實驗驗證
2.1 建立基于熵權(quán)層次分析法的動態(tài)評估模型
2.1.1 動態(tài)主觀權(quán)重
首先構(gòu)建判斷矩陣,本文選取CPU、內(nèi)存、磁盤、網(wǎng)絡(luò)4個因素作為評價指標(biāo),則判斷矩為4行4列的矩陣WA。該矩陣的取值根據(jù)當(dāng)前時刻系統(tǒng)運行負載的變化情況和以往經(jīng)驗。在判斷矩陣WA中,4列元素從左到右依次代表CPU、內(nèi)存、外部磁盤、網(wǎng)絡(luò)帶寬4種影響云平臺負載變化的評價因素
為了下一步計算,需要對該判斷矩陣的列向量進行歸一化處理,之后得到新的矩陣WB
對WB按行求和,然后再進行歸一化處理,得到權(quán)重向量W,該權(quán)重向量的每行值對應(yīng)CPU、內(nèi)存、磁盤、網(wǎng)絡(luò)帶寬4個評價指標(biāo)對應(yīng)在該時刻的權(quán)重值
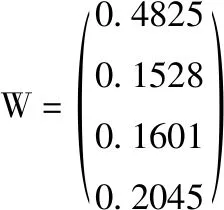
為了驗證該權(quán)重向量的有效性,需要進行一致性檢驗。按照前面章節(jié)所描述的步驟計算拉姆達的值為4.1441。即可得C.I.的值為0.048 06。查表可知R.I.的值取為0.9,則C.R.的值為0.0534,則C.R.<0.1,即權(quán)重向量W的值滿足一致性檢驗,每一行的值即為該時刻對應(yīng)指標(biāo)因素的權(quán)重值。
2.1.2 動態(tài)客觀權(quán)重
熵權(quán)法通過利用指標(biāo)過去一段時間的變化值,計算該指標(biāo)的權(quán)重,因此被稱為是一種客觀賦權(quán)法。熵權(quán)法通過利用指標(biāo)過去一段時間的變化值,計算該指標(biāo)的權(quán)重,因此被稱為是一種客觀賦權(quán)法。本文數(shù)據(jù)來源于yahoo webscope數(shù)據(jù)集,選取其中4個指標(biāo)為列向量,過去20分鐘內(nèi)的使用率作為歷史數(shù)據(jù),構(gòu)建初始數(shù)據(jù)表。對初始化表進行歸一化處理,之后按照公式計算歸一化后的數(shù)據(jù)表中數(shù)據(jù),即得CPU、內(nèi)存、磁盤、網(wǎng)絡(luò)帶寬得信息熵,見表2。

表2 指標(biāo)信息熵
按照式(6)所示,即得在該時刻4個指標(biāo)得權(quán)重值,結(jié)果值見表3。

表3 指標(biāo)權(quán)重
2.1.3 組合評價模型
隨著時間的推移,用戶不同時刻會用不同的請求,導(dǎo)致云平臺的資源消耗處于一個動態(tài)變化的狀態(tài),4個指標(biāo)的權(quán)重是基于當(dāng)前時刻各自的使用情況來確定,為了使得到的指標(biāo)權(quán)重符合當(dāng)前平臺的負載情況,則每當(dāng)資源發(fā)生變化時都需要重新計算當(dāng)前指標(biāo)的權(quán)重值。考慮云平臺負載的變化情況,本文采用層次分析法和熵權(quán)法計算出各個時刻評價指標(biāo)的權(quán)重值后,將得出的主客觀權(quán)重值帶入拉格朗日乘子,得出各個時刻對應(yīng)的CPU、內(nèi)存、磁盤、網(wǎng)絡(luò)帶寬的實時權(quán)重。各指標(biāo)的實時權(quán)重與對應(yīng)的利用率的乘積即是當(dāng)前時刻云平臺的負載值。按照以上步驟,即可得到某實驗對象云平臺的負載時間序列值,部分結(jié)果見表4,該負載值結(jié)合了各硬件資源的主客觀因素,能夠較好反映云平臺的實時負載情況。
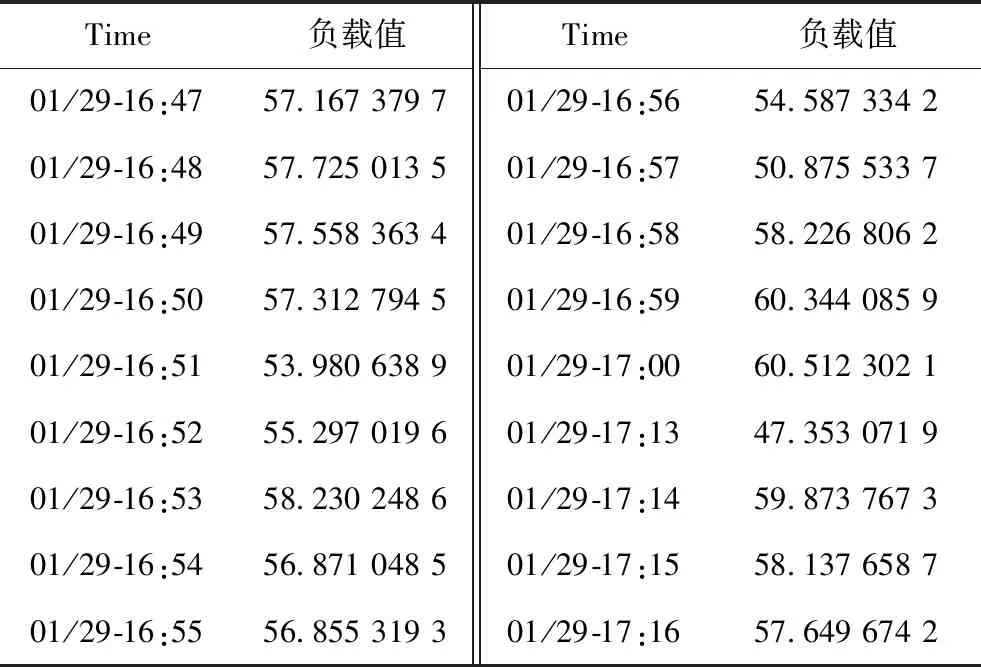
表4 云平臺負載值
2.1.4 結(jié)果分析
本文將熵權(quán)層次法分別同單純使用熵權(quán)法、層次分析法和固定權(quán)重計算得出的負載值對比。采用固定權(quán)重的方法雖然考慮了不用資源對負載的影響情況,但其實質(zhì)是將4種因素的指標(biāo)和縮小至1/4,不能反映系統(tǒng)資源的真實使用情況。層次分析法反映了CPU是系統(tǒng)關(guān)鍵指標(biāo)的主觀經(jīng)驗,未充分體現(xiàn)其它3種指標(biāo)的影響。熵權(quán)法計算得出的云平臺負載值較高,是由于云平臺的內(nèi)存利用率一直處于較高狀態(tài),但從計算機系統(tǒng)的角度來看,內(nèi)存的使用情況并不能代表系統(tǒng)整體的負載。熵權(quán)層次分析法則考慮了CPU在系統(tǒng)運行過程中的關(guān)鍵地位的主管經(jīng)驗,同時也客觀評估了4種指標(biāo)的影響程度,計算得出的負載值能夠更好反映系統(tǒng)的整體運行狀態(tài),較另外3種方法更加科學(xué)合理。4種負載評估方法對比如圖5所示。
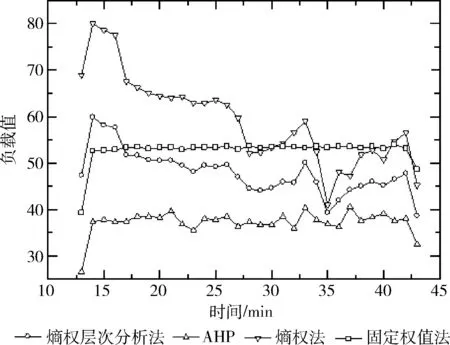
圖5 4種負載評估方法對比
2.2 基于ARIMA-BP模型的云平臺負載預(yù)測
2.2.1 構(gòu)建ARIMA模型
對云平臺負載進行平穩(wěn)性處理和白噪聲檢驗,得到穩(wěn)定的非白噪聲數(shù)據(jù)。根據(jù)平穩(wěn)時間序列模型特征系數(shù)判斷ARIMA模型的參數(shù),模型參數(shù)的確定主要通過觀察自相關(guān)函數(shù)圖和偏自相關(guān)函數(shù)圖。
如圖6所示,是負載數(shù)據(jù)的自相關(guān)(ACF)和偏自相關(guān)(PACF)函數(shù)圖,從圖中可以看出,隨著滯后期數(shù)的增加,時間序列的自相關(guān)系數(shù)從高值降為低值,逐漸趨向零,符合ACF拖尾的特點。同時,偏自相關(guān)系數(shù)也從高值降為低值,逐漸趨向0,符合PACF拖尾的特點;自相關(guān)(ACF)圖和偏自相關(guān)(PACF)圖都呈現(xiàn)出拖尾現(xiàn)象,可以初步判斷該時間序列可以使用ARMA(p,q) 模型。

圖6 自相關(guān)和偏自相關(guān)函數(shù)
在對序列進行差分處理,結(jié)果表明ARIMA(1,1,1) 模型的AIC、SC、HQ值為最小,此時可以選取p=1,q=1,d=1作為模型的參數(shù)值,即ARIMA(1,1,1)。 差分結(jié)果見表5。
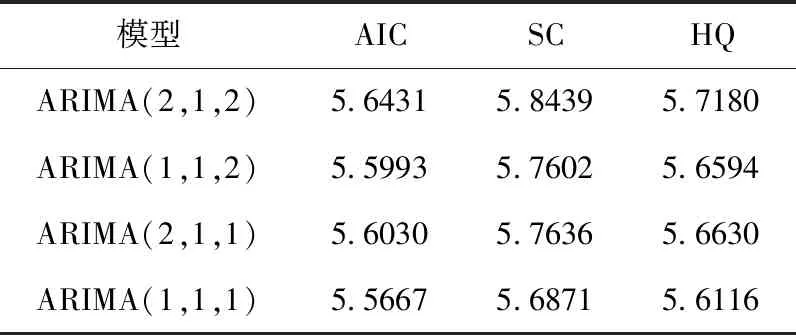
表5 ARIMA模型對比
在使用ARIMA預(yù)測負載并計算出負載殘差后,利用BP神經(jīng)網(wǎng)絡(luò)預(yù)測殘差值,其中輸入層節(jié)點個數(shù)為4,隱藏
層節(jié)點個數(shù)為3,輸出層節(jié)點個數(shù)為1,并設(shè)置訓(xùn)練網(wǎng)絡(luò)的其它參數(shù)。最后利用ARIMA及保存的神經(jīng)網(wǎng)絡(luò)對負載值進行預(yù)測。
2.2.2 結(jié)果分析
圖7是基于ARIMA模型的云平臺負載預(yù)測值和基于ARIMA-BP組合模型的云平臺負載預(yù)測值的對比圖,可以看到后者更加接近真實值。圖8是這兩種預(yù)測模型的誤差對比圖,同樣可以說明基于ARIMA-BP模型的預(yù)測值誤差較小,預(yù)測精度更高。
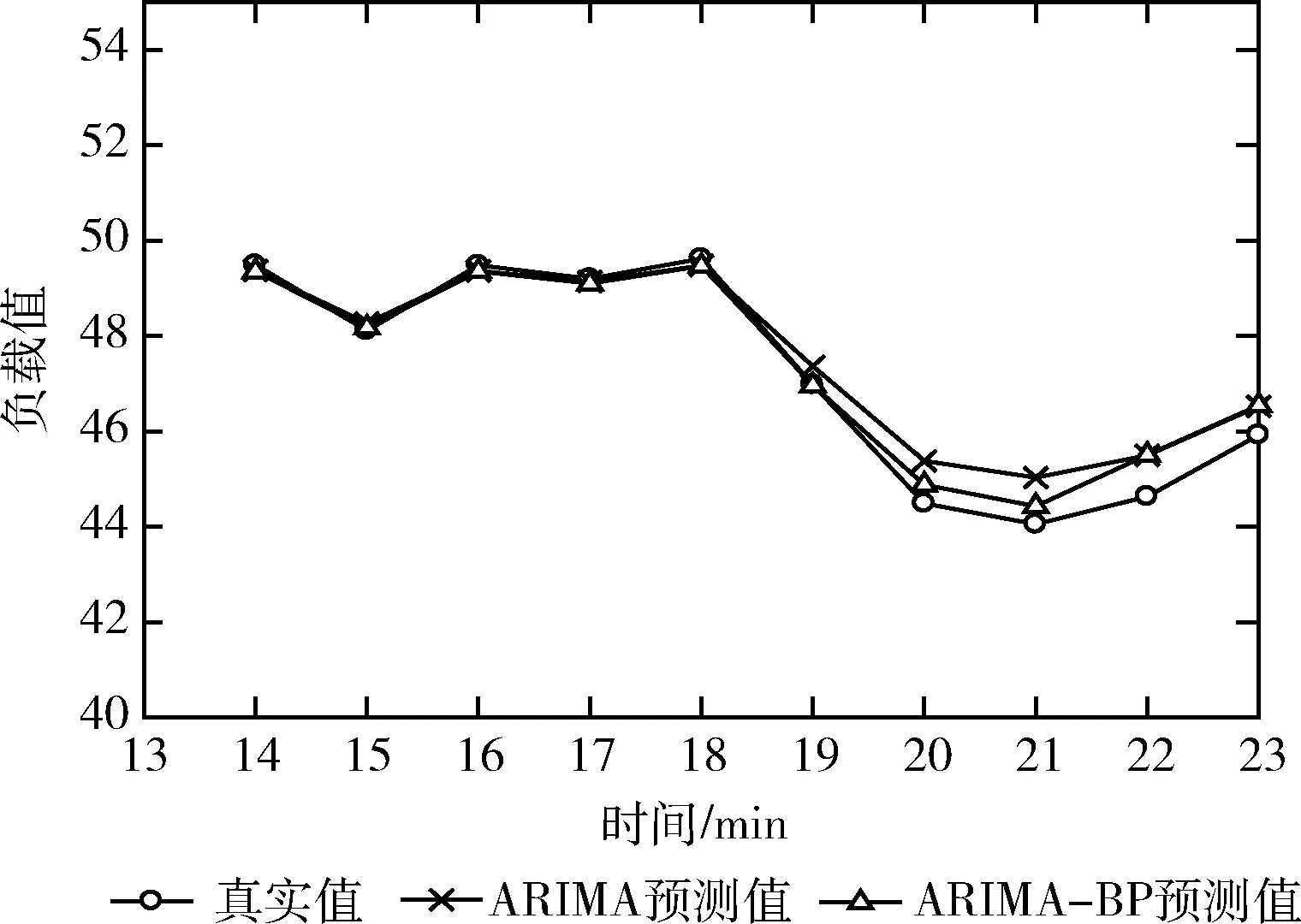
圖7 平臺負載預(yù)測對比
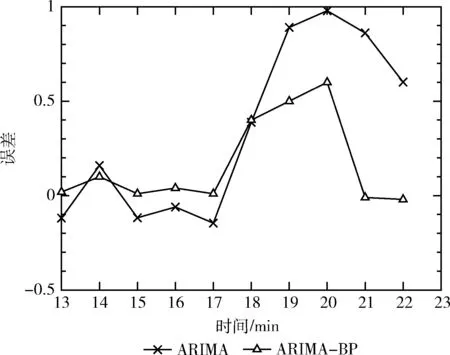
圖8 預(yù)測誤差對比
3 結(jié)束語
本文采用熵權(quán)法和層次分析法結(jié)合的方式建立云平臺負載評價模型,該模型采用4種元素加權(quán)的方式,評估云平臺的負載情況,避免了采用單一元素確定了評價云平臺負載的片面性。在選擇賦權(quán)法時,采用主客觀賦權(quán)法結(jié)合的方式,較使用一種賦權(quán)法更加全面合理。
基于ARIMA模型預(yù)測了云平臺負載數(shù)據(jù)序列的線性部分,其后采用基于BP神經(jīng)網(wǎng)絡(luò)模型預(yù)測了云平臺負載值的非線性部分。最后將構(gòu)建基于ARIMA-BP的組合模型,并使用該模型預(yù)測云平臺負載,所得預(yù)測值與期望值相比,滿足期望誤差,驗證了該模型在預(yù)測云平臺負載值的有效性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導(dǎo)航定位學(xué)報(2022年4期)2022-08-15 08:27:00
中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀(jì)智能(數(shù)學(xué)備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學(xué)院學(xué)報(2021年2期)2021-07-19 08:35:14
新世紀(jì)智能(數(shù)學(xué)備考)(2020年9期)2021-01-04 00:25:14
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
