高速列車晚點預測的機器學習模型
2021-01-19 14:28:20胡瑞文超張夢穎徐傳玲
中國鐵路 2020年11期
關鍵詞:模型
胡瑞,文超,3,張夢穎,徐傳玲
(1.西南交通大學綜合交通運輸國家地方聯合工程實驗室,四川成都610031;2.西南交通大學綜合交通大數據應用技術國家工程實驗室,四川成都610031;3.滑鐵盧大學鐵路研究中心,安大略滑鐵盧N2L 3G1)
0 引言
智能高鐵將云計算、大數據、北斗定位、下一代移動通信、人工智能等先進技術,通過新一代信息技術與高速鐵路技術的集成,全面感知、融合處理、主動學習和科學決策,實現高鐵的智能建造、智能裝備和智能運營。智能調度理論是高速鐵路智能運營的核心基礎理論,“列車晚點傳播問題”和“軌道交通調度指揮智能化及風險預警”入選由教育部、科技部、中國科學院、國家自然科學基金委員會等聯合發起的《10 000個科學難題交通運輸科學卷》[1],說明運營調度智能化理論是軌道交通運輸組織優化亟待解決的難題。
得益于大數據技術的發展,機器學習方法已經在諸多領域的理論研究和運營實踐中凸顯了優勢[2]。在數據充足的條件下,機器學習模型可以研究列車間更為復雜的作用過程,更深入地解析晚點傳播及恢復過程[3]。文超等[4]認為傳統數學模型不能有效處理列車運行產生的巨復雜數據,而機器學習相關模型適用于處理數據驅動的智能鐵路運營分析。Lulli等[5]以描述大型鐵路路網的態勢為目標,混合傳統分析和數據驅動模型的描述方法,構建了一個動態鐵路多源數據分析系統。孫略添等[6]運用灰色模型對技術站列車晚點進行預測,再綜合運用馬爾可夫和改進的神經網絡模型進行修正和預測,最后將2種方法進行了對比,顯示神經網絡模型在大規模數據集情形下預測精度更高。Huang等[7]提出一種基于SVR算法和KF算法的混合模型用于預測列車運行時間,該混合模型結合了2種算法的特點,做到了更短計算時間下的高準確率預測。解熙等[8]建立以6個絕對指標和5個相對指標的列車晚點事件統計體系,對傳統城市軌道交通晚點評價進行了完善。
目前,相關研究對鐵路運行數據的處理尚不夠精細,沒有充分結合高速列車調度實際與機器學習模型運算特點,因此優先運用相關模型對列車數據進行分析,對列車數據進行篩選,可使其在機器學習模型預測中發揮更有效的作用。
1 晚點數據統計分析
1.1 數據描述
數據來源于中國鐵路廣州局集團有限公司管轄的廣深高鐵,時間跨度為2015年6—12月,共計10萬余條。廣深高速鐵路全長113 km,鐵路下行方向分別是廣州南、慶盛、虎門、光明城、深圳北、福田共6個車站。列車運行數據包含高速列車的計劃運行圖和實際運行圖,具體為列車車次、到達車站、實際到達時間、實際出發時間、圖定到達時間、圖定出發時間和經停股道等。使用的數據經過預處理和清洗,具體處理對象有數據記錄為空值、數據記錄錯誤、數據存在極端異常值等,經過清洗后的數據各參數間不存在數量級差異。
1.2 列車晚點描述性統計
要詳細了解列車運行數據的特征和規律,對列車運行數據進行描述性統計是必要的手段。列車晚點時間作為度量列車運行情況的重要指標也是預測的目標,有必要對其進行詳細分析和挖掘,為下一步建模預測晚點時間做準備。箱線圖是一種常見的數據描述方法,常用于表示數據量較大且分布跨度較大的數據集,將一組數據按照由大至小的順序排列,不被納入箱中的數據作為數據分布的異常值,上邊緣為最大值,然后是上四分位數值、中間值、下四分位數和下邊緣。在實際調度過程中,只有終到時間大于圖定終到時間4 min的列車才統計為晚點列車,廣深高鐵各站到達晚點時間箱線見圖1,其中廣州南站晚點時間為始發站出發晚點時間,其余各站為到達晚點時間。

圖1 各站晚點時間箱線
由圖1可知,廣州南站出發晚點列車數為784列,平均晚點時間為14.96 min;慶盛站晚點列車數1 070列,平均晚點時間10.15 min;虎門站晚點列車數604列,平均晚點時間11.20 min;光明城站晚點列車數1 259列,平均晚點時間12.95 min;深圳北站晚點列車數237列,平均晚點時間17.68 min。各站晚點數據描述性統計見表1。結合圖1和表1可知,各站的晚點時間均值都大于第二分位數,這表明各站的晚點時間分布很不均勻,這也是圖1中各站箱線圖繪制的都更接近底部的原因,部分嚴重晚點列車拉高了平均晚點時間。圖1中各站箱線圖上方異常值較多則說明數據呈現明顯的右偏態勢。晚點偏度系數指標也證實了廣深線所有車站的晚點數據分布呈現右偏,廣州南站和深圳北站晚點偏度系數較低,分別為2.16和1.82,而中間站的晚點偏度系數均較高。
對列車相關數據進行進一步分析可知,在始發站廣州南站的始發列車晚點數雖不多,但晚點時間偏高,隨著列車在廣州南—慶盛區間運行,產生了更多的晚點列車,但是晚點時間得到了部分恢復,其中慶盛站—虎門區間恢復了大量晚點時間較短的列車。這是因為列車在區間運行中可有效吸收5 min左右的晚點時間,但對于始發晚點時間大于10 min的列車,往往并不能有效恢復晚點,甚至會產生增晚的情況,導致始發晚點事件本就嚴重的列車在終到站依舊晚點。從晚點方差指標可以看出全線晚點列車分布都不均勻,列車晚點時間跨度都較大,其中始發站廣州南站的始發晚點方差達到了252.11,深圳北站的終到晚點時間方差是236.19,始發和終到站的晚點時間分布跨度最大。各站的晚點時間峰度指標均大于3,表示廣深線的晚點數據分布非常陡。

表1 各站晚點數據描述性統計
2 晚點特征分析及數據降維
結合預處理后的數據計算各列車在各站的到達晚點時間、出發晚點時間、停站時間、實際區間運行時間、圖定區間運行時間、列車接續時間、車站冗余時間、區間冗余時間共8個列車運行參數。由于列車運行參數較多且其數據量較大,有必要對參數進行定量的相關性分析和數據降維處理。
2.1 晚點影響因素定量分析
對于多個特征系數常用皮爾遜相關系數(Pearson)去度量特征系數間的聯系強度,該系數計算公式和應用可參考文獻[9]。現令X1為到達晚點時間,X2為出發晚點時間,X3為停站時間,X4為實際區間運行時間,X5為圖定區間運行時間,X6為列車接續時間,X7為車站冗余時間,X8為區間冗余時間,Z為目標值,即下一車站列車到達晚點時間。經過計算得到各特征系數之間與目標值之間的Pearson(見表2)。從表2可知,X1、X2、X3、X4、X7共5個列車運行參數與目標值的Pearson為正,表明其與列車到下一車站的晚點時間呈現正相關性,其余特征系數值X5、X6、X8的Pearson為負,表明其與列車到下一車站的晚點時間呈現負相關性。
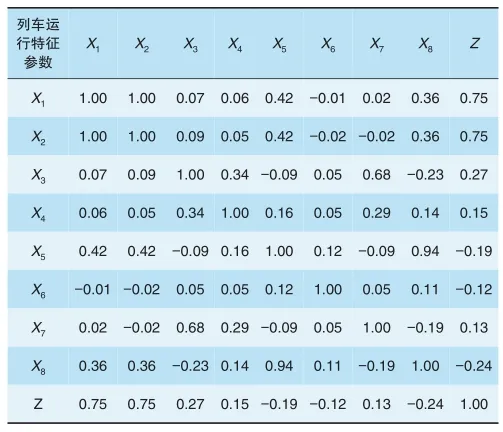
表2 列車運行參數Pearson
2.2 晚點影響因素數據降維
Lasso模型是一種常見的回歸方法,通過壓縮估計構建懲罰函數,計算出一個更簡潔的模型。模型的相關公式和應用可參考文獻[10]。λ取值為5,經過計算得到相關系數非零的數量為5個,各參數相關系數分別為0.298 85、0.601 71、0、0.200 85、-0.426 10、0、0、-0.356 77。將Lasso模型計算的參數系數與Pearson的結果進行結合,得到晚點特征評估表(見表3)。

表3 晚點特征評估
由 表3可 知,X1、X2、X4、X5、X8這5個 參 數 在Lasso系數評估中都是不可縮減的一部分,再綜合考慮Pearson相關系數和列車運行實際情況,停站時間也是預測列車在下一車站晚點時間的重要因素,而列車接續時間和車站冗余時間不會因列車晚點而產生時間值上的變化,只是將事件發生的時間點在時間的水平坐標上平移,因此添加X3停站時間也作為預測晚點時間的參數。綜上,共有6個參數被用于預測模型建立。
3 基于梯度提升決策樹的晚點預測
機器晚點預測是鐵路運營智能化的功能之一,既可一定程度上減輕調度員的工作壓力,也可為調度行車指揮命令提供參考,選擇梯度提升決策樹模型進行預測。
3.1 模型介紹
GBDT算法是一種集成算法,廣泛應用于工業界、金融界和各類數學競賽中[11],由Gradient Boosting算法和Decision Tree算法2部分組成,將2者綜合即為梯度提升決策樹,該集成算法以殘差下降為優化方向,不停地將上一個優化的輸出作為下一次優化的輸入,從而以期達到最優值。該模型算法在回歸分析中的表現非常出色,是目前使用度高且具有良好泛化能力的算法。模型具體步驟如下:
(1)假設有訓練集數據。(xm,ym)為一組數據,則訓練集數據為:
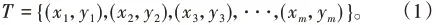
(2)確定生成數個數(迭代數)為N,損失函數為L(y,f(x)),yi為真實值,c為對應預測值,則設置初始化弱回歸器為:
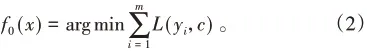
(3)對迭代次數n=1,2,3,…,N,設置負梯度為:

運用上式計算回歸樹,得到第n顆回歸樹。其葉子節點域為Rns,s=1,2,3,???,S,S為回歸樹N的葉子節點個數,計算S的最優擬合值為:

得到S的最優解后,從而更新回歸器:

(4)得到最終學習器為:
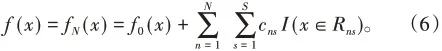
擬解決的是回歸問題,利用負梯度擬合殘差可實現回歸功能[12]。
3.2 晚點預測實驗及結果分析
要運用GBDT模型進行晚點時間預測,還需要對相關重要參數的取值進行研究,將數據集劃分為訓練集和測試集,選取總數據量的20%作為測試集,訓練集數據進行參數訓練。現選取了一些主要參數包括nums學習器的數量、max_features最大特征數、subsample采樣比例、max_depth樹的最大深度。
nums是學習器的數量,即初始學習器的迭代次數,通常取值過小易導致欠擬合,取值過大易導致過擬合,在此默認取值100。nums參數訓練結果見圖2,nums參數隨著取值增加訓練集分數快速提升,該參數取值100。

圖2 nums參數訓練結果
max_features是最大特征數,劃分子節點時需考慮的值。max_features參數訓練結果見圖3,max_features參數隨著取值增加測試集分數波動巨大,當取值大于0.8后較穩定,因此該參數取值1。
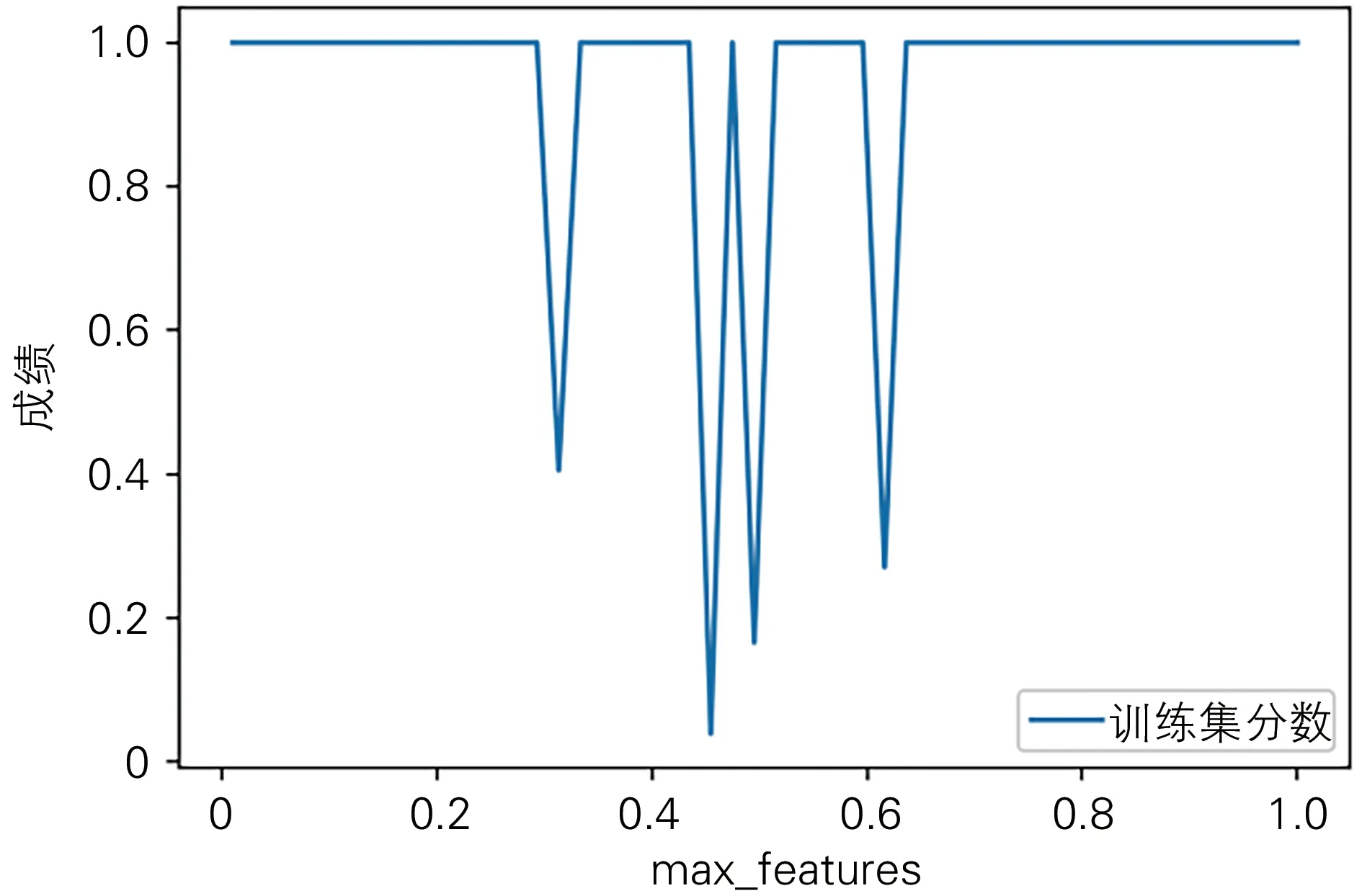
圖3 max_features參數訓練結果
subsample是采樣比例,即在多少數據集上運用決策樹去提升梯度,該值默認比例為100%。subsample參數訓練結果見圖4,subsample參數隨著取值增加,模型測試集分數波動較大,參數取值超過0.6后準確度達到了平穩且優異的狀態,因此該參數值為1。

圖4 subsample參數訓練結果
max_depth是樹的最大深度,決定決策樹生出子樹的深度。max_depth參數訓練結果見圖5,max_depth參數隨著取值增加測試集分數快速提升,取值10以后準確度非常平穩,因此該參數取值17。

圖5 max_depth參數訓練圖
在確定了主要參數取值后,運用GBDT模型預測各列車在下一車站的晚點時間,用R2值和平均絕對誤差MAE評價回歸模型,R2值著重評價晚點時間預測準確度,MAE著重評價對各車次晚點時間預測的誤差。
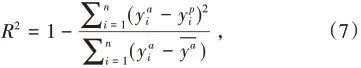

結果顯示預測準確率較高,晚點列車訓練集數據的R2值為0.97,測試集R2值為0.89;晚點列車訓練集數據MAE為0.09 min,測試集MAE為0.32 min。同時,設置以機器學習的近鄰算法模型(KNN)為預測方法的對照組,鄰近樣本個數設置為5,葉子節點數量設置為30,則對照組晚點列車測試集數據的R2值為0.76,MAE為0.84 min。因此,基于GBDT模型的高速列車晚點時間預測的效果是非常優秀的。考慮到測試集數據量較大,因此僅顯示測試集部分列車的預測情況,晚點時間預測效果見圖6。

圖6 GBDT模型部分預測結果對比
繪制圖6時,先繪制表示實際晚點時間的藍色折線,當預測完全一致時,表示預測晚點時間黃色折線將覆蓋藍色折線。結合模型指標與圖6可知,該模型預測結果貼近實際,其預測準確度很高,可以為列車晚點預測提供一定輔助作用。
4 結束語
基于高速列車運行實績,通過充分挖掘和分析列車運行數據,運用皮爾遜相關系數分析數據的相關性,運用Lasso模型實現數據降維,并進而建立高速列車晚點預測的GBDT機器學習模型,模型測試結果表明所建立模型能夠很好地預測高速列車晚點。準確預測高速列車的晚點時間,能夠降低調度工作負荷、提高調度決策的質量,是高速鐵路實現智能調度的重要環節。智能運營是智能高鐵的核心價值體現,是智能高鐵研究和實踐必須攻克的難題,其中高速列車晚點預測及列車運行調整的高鐵調度是重要內容,利用機器學習方法預測高速列車的晚點,將能夠為高鐵調度智能化提供理論支撐,相關預測模型可作為高鐵智能調度決策系統的相應模塊,助力高鐵智能調度系統開發。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
