基于自監督表征學習的海面目標檢測方法
2021-01-16 03:33:30張友梅李曉磊
水下無人系統學報 2020年6期
張 倩, 張友梅, 李曉磊, 宋 然, 張 偉
基于自監督表征學習的海面目標檢測方法
張 倩1, 張友梅2, 李曉磊1, 宋 然1, 張 偉1
(1. 山東大學 控制科學與工程學院, 山東 濟南, 250061; 2. 齊魯工業大學(山東省科學院) 數學與統計學院, 山東 濟南, 250353)
為提升海上無人裝備對海洋的感知與監測能力, 海面目標檢測準確度的提升至關重要。但受復雜海況影響和傳感器限制, 采集高質量海面目標樣本困難, 導致大規模海面目標數據集缺乏, 使得基于深度學習的海面目標檢測發展緩慢。為此, 文中將自監督表征學習引入海面目標檢測領域, 利用動量對比自監督表征學習算法進行船舶特征學習, 從大規模無標簽海面目標數據中挖掘船舶目標特征, 為后續進行基于更快的區域卷積神經網絡的海面目標檢測提供先驗知識。實驗結果表明, 借助于大規模無標簽數據集, 文中提出的基于自監督表征學習的海面目標檢測方法能夠取得與有監督預訓練方法相當的檢測效果, 突破了有標注海面目標樣本不足的限制。文中工作可為進一步研究基于深度學習的海洋智能感知問題提供參考。
海上無人裝備; 目標檢測; 自監督表征學習; 深度學習
0 引言
作為海域遼闊的海洋大國, 提升海洋科技實力對建設海洋強國意義重大。借助于無人艇等海上無人裝備對海域進行實時監測可以有效加強海域管控, 維護我國海洋安全, 因而如何提高海上無人裝備的智能感知能力便成為海洋科技領域的關鍵問題之一。在此背景下, 海面目標檢測成為海洋環境感知領域的熱點研究方向之一。
目標檢測作為計算機視覺領域最具挑戰性的任務之一, 包括定位和分類2個子任務, 即確定所需檢測圖片中所包含目標的位置并對其進行準確分類。近年來, 隨著深度學習理論的快速發展, 基于深度學習的目標檢測算法成為主流, 在通用場景下取得了較好的檢測效果。但深度學習模型往往依賴于大規模數據集進行訓練, 應用較為廣泛的MS COCO(microsoft common objects in cont- ext)[1]、PASCAL(pattern analysis, statical modeling and computational learning)、VOC (visual object classes)[2]等標準數據集中海面目標較少, 因而將在這些數據集上訓練的目標檢測模型直接應用于海面目標檢測任務效果不佳。同時, 由于長期以來海面目標專用數據集較少, 且大多沒有模型訓練所需的邊界框標注, 基于深度學習的海面目標檢測相關研究相對較少。
由于海洋環境不同于陸地和天空, 其環境更加復雜多變, 浪、涌、渦和流等海面波動均會對海面目標檢測造成影響, 相比于通用場景下的目標檢測任務, 海面目標檢測難度更大, 傳統海面目標檢測方法具有諸多局限性。為在海面目標檢測過程中充分利用深度學習模型對視覺信息的感知能力, 并針對現有海面目標檢測數據集樣本量較小、難以滿足模型有監督預訓練需求的問題, 文中首次將自監督表征學習引入海面目標檢測領域,提出了一種基于自監督表征學習的海面目標檢測模型。
1 相關方法介紹
1.1 基于深度學習的目標檢測
基于深度學習的目標檢測模型通常分為單階段檢測模型和兩階段檢測模型。前者根據輸入的圖像特征直接預測物體的邊界框坐標和類別, 代表算法包括YOLO (you only look once)[3]系列、單階段多框檢測器(signle shot multibox detector, SSD)[4]等, 此類算法由于只進行一次邊界框回歸, 因而檢測速度更快, 但檢測精度有待提升。而兩階段算法將目標檢測分為兩步進行:
1) 由候選區域生成網絡(region proposal net- work, RPN)生成一系列候選框, 該過程基于預設的錨點完成了第1次邊界框回歸;
2) 對候選框坐標進行調整, 即進行第2次邊界框回歸, 同時識別框內物體, 檢測精度更高。雖然目前RetinaNet[5]等單階段算法在檢測精度方面已取得很大提升, 但基于兩階段式框架的更快的區域卷積神經網絡(faster regions with convolutional neural network features, Faster R-CNN)[6]、包含掩膜分支的區域卷積神經網絡(mask regions with convolutional neural network features, Mask R-CNN)[7]等依然是目標檢測領域表現優異的主流方法。
1.2 海面目標檢測
海面目標檢測任務是指定位海洋場景圖片中的目標(主要是船舶), 并對其類別(如輪船、帆船及漁船等)進行細分。傳統的海面目標檢測通常包括海天線檢測、背景建模和背景去除3個步驟, 所得的前景區域被認為是包含目標的區域。雖然海天線檢測對提高海面目標檢測效果有所幫助, 但其對惡劣天氣、復雜海況等適應性較差。
近年來, 基于深度學習的海面目標檢測研究不斷出現。Shin等[8]將YOLO v2模型分別在通用場景數據集和海洋場景數據集上訓練, 證明利用海洋數據進行模型訓練是非常有必要的。Moosbauer等[9]發現使用預訓練的Mask R-CNN參數對模型進行初始化檢測效果更佳。但基于深度學習的海面目標檢測研究尚處于起步階段, 文中針對大規模海面目標數據集缺乏所導致的深度學習算法在海面目標檢測領域應用受限的問題, 以充分利用無標簽海洋數據為出發點, 將自監督表征學習引入海面目標檢測領域, 可實現在無需大規模有標注海面目標數據的情況下取得較好的檢測效果。
1.3 自監督學習
自監督學習作為無監督學習范式的一種, 通常從數據本身獲取監督信息, 以此作為人工標注的替代, 模型借助于所獲取的監督信息來學習數據的底層結構特征。目前自監督學習已廣泛應用于自然語言處理領域[10-11], 而對于目標檢測[3-6]、目標跟蹤[12-14]等視覺感知任務, 有監督訓練仍是主流方法。但對缺乏大規模數據標注的海洋感知任務而言, 模型通過采用自監督的方式初步學習如何進行更具普適性的特征提取, 然后在有限的標注數據上結合任務需求對模型進行微調也不失為一種合適的選擇。現有的自監督學習主要包括以自編碼器及其變體[15-17]為代表的生成式方法和以動量對比(momentum contrast, MoCo)[18]、簡易式對比學習(simple framework for contrastive learning of visual representation, SimCLR)[19]為代表的對比式方法, 相比于前者, 對比式方法側重于從原始數據中獲取抽象化的語義信息, 因而更適合于視覺感知與理解任務。
2 海面目標數據集
受復雜海況影響和傳感器限制, 采集大規模、高質量海洋環境及目標數據樣本比較困難, 導致可用于海洋感知研究的開源數據集較少, 且樣本量遠不及ImageNet[20]、MS COCO[1]等通用數據集。
2.1 海上船舶數據集
Gundogdu等[21]于2017年公開了大規模海上船舶數據集(maritime vessels, MARVEL), 該數據集圖片均來自Shipspotting網站, 根據任務需求可分別下載14萬/40萬圖片用于相關研究, 其中的樣本如圖1所示。

圖1 MARVEL數據集樣本示例
MARVEL數據集是目前已知樣本量最大的海洋船舶數據集, 但由于缺乏目標檢測所需的邊界框標注, 無法直接將其用于海面目標檢測任務。文中利用該數據集對自監督海洋船舶特征學習進行研究。
2.2 新加坡海上數據集
2017年Prasad等[22]開源的新加坡海上數據集(Singpore maritime dataset, SMD), 共包括81段視頻, 其中63段有標記, 共包含10類目標。該數據集包含可見光數據(visual, VIS)和紅外數據(near infrared, NIR)兩部分, 文中使用該數據集中的VIS部分(見圖2)進行海面目標檢測研究。

圖2 SMD數據集樣本示例
雖然SMD數據集樣本量不大, 但63段有標記視頻中的目標均有邊界框標注, 可直接用于海面目標檢測任務。文中將該數據集中的視頻數據轉換為圖片數據(每2幀取1幀), 然后進行基于圖像的海面目標檢測研究。
3 基于自監督表征學習的海面目標檢測
針對現有海面目標數據集樣本量不足的問題, 文中嘗試利用無標注的大規模海面目標數據集, 通過引入自監督表征學習相關方法, 挖掘海面目標樣本的底層特征, 為海面目標檢測任務提供先驗知識, 提高基于深度學習的目標檢測模型在海面目標檢測任務上的表現。換言之, 即將海面目標檢測模型訓練分為自監督船舶特征學習和有監督海面目標檢測2個階段進行, 以降低海洋數據樣本不足對檢測效果的影響。
3.1 基于MoCo的船舶特征學習
海面目標以各類船、艇為主, 其間相似性較高, 在無類別標簽的情況下學習樣本特征難度較大, 而對比式學習方法能夠更好地挖掘相似樣本間的差異, 從而學習到更具樣本區分度的特征, 更有利于海面目標檢測、分類等下游任務。因此在自監督船舶特征學習階段, 文中采用He等[18]提出的MoCo方法在無標注海面目標數據上訓練特征提取模型(見圖3)。
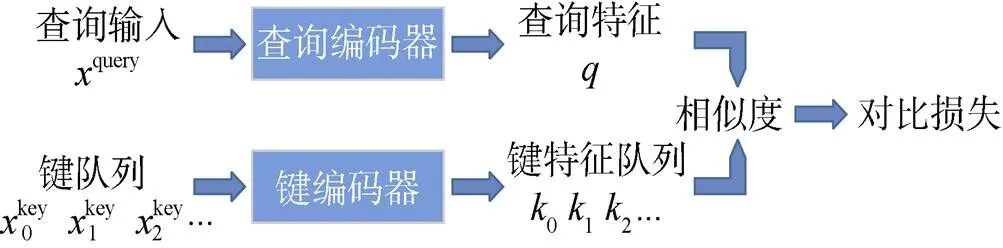
圖3 MoCo自監督表征學習方式
MoCo將對比學習看作字典查找過程, 并提供了一種構建大且連續的動態字典的方式, 其核心思想為: 通過將字典作為一個樣本隊列進行維護來保證字典足夠大; 同時通過采用動量更新的方法更新鍵編碼器來避免其變化過快, 以提高隊列中鍵的表征一致性。
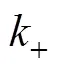
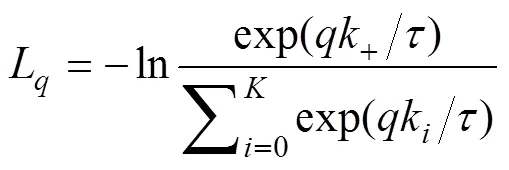
所謂動量更新即在訓練過程中不通過反向傳播更新鍵編碼器參數, 而是采用如下更新方式
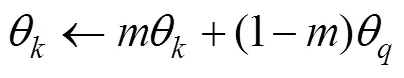
為了驗證基于MoCo的船舶特征學習的有效性, 文中將學得的特征直接用于船舶分類任務, 在MARVEL數據集上進行了實驗研究。
3.2 基于Faster R-CNN的海面目標檢測
在海面目標檢測階段, 采用在通用場景的目標檢測任務上表現優異的Faster R-CNN[6]模型, 如圖4所示, 該模型由用于特征提取的backbone (基礎網絡)、用于生成感興趣區域(region of interest, ROI)的RPN、生成最終檢測結果的ROI -Head三部分組成, 其中ROI-Head包括分類和定位2個分支。
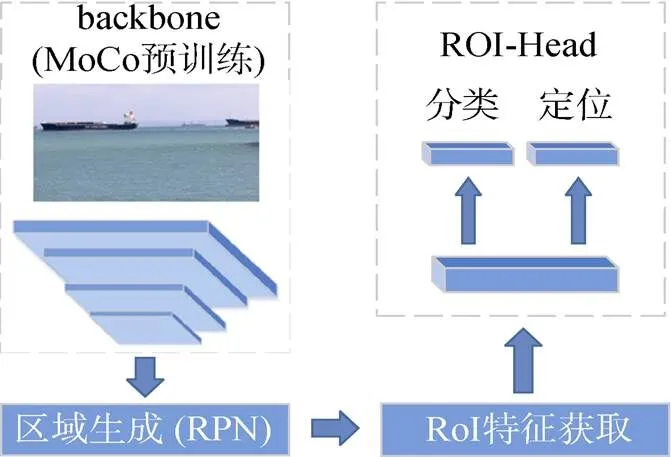
圖4 基于Faster R-CNN的海面目標檢測框架
backbone由深度卷積神經網絡構成, 將輸入圖像映射為深層特征圖, 該部分通常在Image- Net[17]數據集上進行預訓練, 但由于其中的海洋樣本較少, 直接用于海面目標檢測效果不佳。文中模型中的backbone部分采用第1階段自監督船舶特征學習訓練所得的特征提取網絡參數進行初始化, 為目標檢測模型盡可能多地提供海洋環境及船舶相關的先驗知識, 然后在訓練模型其他部分的同時對backbone進行參數微調。
RPN網絡作用于特征圖之上, 以預設的錨點為基準, 輸出預測框相對于錨點的偏移量, 從而生成一系列候選框。通過整合特征圖與候選框信息, 即可獲取每個感興趣區域的特征, 文中采用ROI-Align(ROI對齊)方法代替ROI-Pooling(ROI池化)方法來實現該過程。此外, 在模型訓練過程中, 對分類任務和定位任務分別采用交叉熵損失函數和Smooth L1損失函數。
此外, 考慮到SMD數據集中各類目標樣本分布嚴重不平衡, 為更好地驗證文中所提出的自監督預訓練方法的有效性, 進行了不區分類別的海面目標檢測, 即將圖片中的所有目標均歸類為“目標”。
4 實驗驗證與結果分析
為驗證提出的基于自監督表征學習的海面目標檢測模型(MoCo+Faster R-CNN)的有效性, 文中借助于現有的海洋數據集MARVEL和SMD進行了大量實驗。
4.1 實驗設置
在自監督船舶特征學習階段, 模型中的編碼器均采用ResNet-50網絡, 利用MARVEL數據集中的圖片數據(不使用其對應的標簽)進行模型訓練。為明確樣本量對自監督船舶特征學習效果的影響, 分別使用14萬樣本和40萬樣本進行實驗。為量化自監督船舶特征學習效果, 在MARVEL數據集用于分類任務的14萬樣本上進行了船舶分類實驗, 將學習到的特征直接用于船舶分類, 即在固定特征提取網絡的情況下以有監督的方式訓練了一個線性分類層。
在海面目標檢測階段, 模型的backbone部分使用上一階段訓練的ResNet-50進行模型初始化, 即采用ResNet-50+Faster R-CNN框架。在SMD數據集上進行目標檢測模型的訓練與測試, 采用和Moosbauer等[9]相同的數據集劃分, 將數據集train和val部分視為訓練集, 而后在test數據集上進行模型測試。在測試階段選擇平均準確率(average precision, AP)、平均召回率(average recall, AR)和f-分數(f-score)作為評分標準, 分別在交并比(intersection over union, IOU)閾值為0.3和0.5的條件下進行測試。
文中所有實驗均在Ubuntu 16.04.10系統中進行, 其中船舶特征學習和海面目標檢測部分均使用8塊Nvidia Tesla V100顯卡, 16個CPU; 船舶分類實驗部分使用4塊Nvidia GTX 1080Ti顯卡, 8個CPU。雖然在模型訓練階段所需的計算資源較多, 但在模型測試階段, 在單塊Nvidia GTX 1080Ti 顯卡上僅需約10 ms即可完成單張圖片船舶分類, 200 ms內可完成單張圖片海面目標檢測, 所需計算資源較少且耗時較短。
4.2 實驗結果與分析
文中采用MoCo自監督學習算法在MARVEL數據集上進行船舶特征學習, 并在此基礎上訓練線性分類器完成了對26類船舶的分類任務。表1為MARVEL數據集上船舶分類準確率(acc), 可以看出:
1) Res50_MoCo_14代表利用MARVEL數據集中14萬樣本進行自監督特征學習, 并將學到的特征用于船舶分類;
2) Res50_MoCo_40代表利用MARVEL數據集中40萬樣本進行自監督特征學習, 并將學到的特征用于船舶分類;
3) Res50_Sup代表利用MARVEL數據集中14萬樣本以有監督的方式訓練船舶分類模型。
實驗過程中自監督船舶特征學習和有監督船舶分類模型均訓練50個epoch, 前者額外訓練一個線性分類層。
表1中第2列數據表明, 利用自監督特征學習學到的特征進行船舶分類, 可以達到60%左右的分類準確率, 雖然相比于有監督船舶分類還有一定差距, 但足以說明借助于基于MoCo的自監督學習算法可以實現對船舶目標的有效表征。表2是采用Res50_MoCo_40時MARVEL數據集船舶分類具體實驗結果。
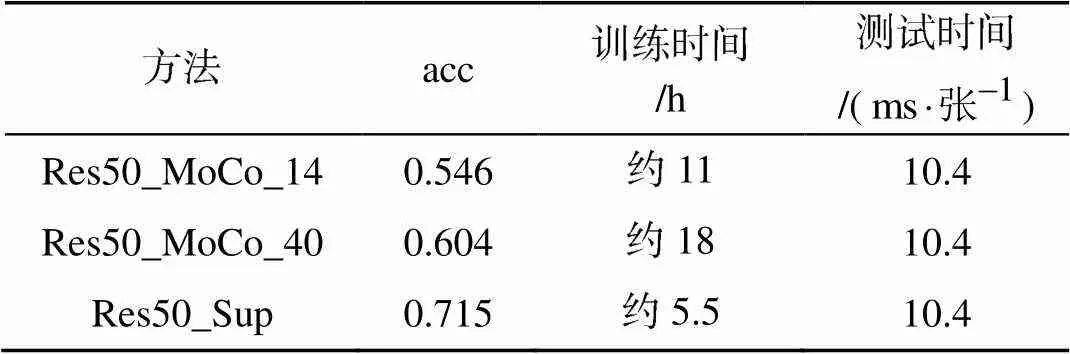
表1 MARVEL數據集船舶分類結果
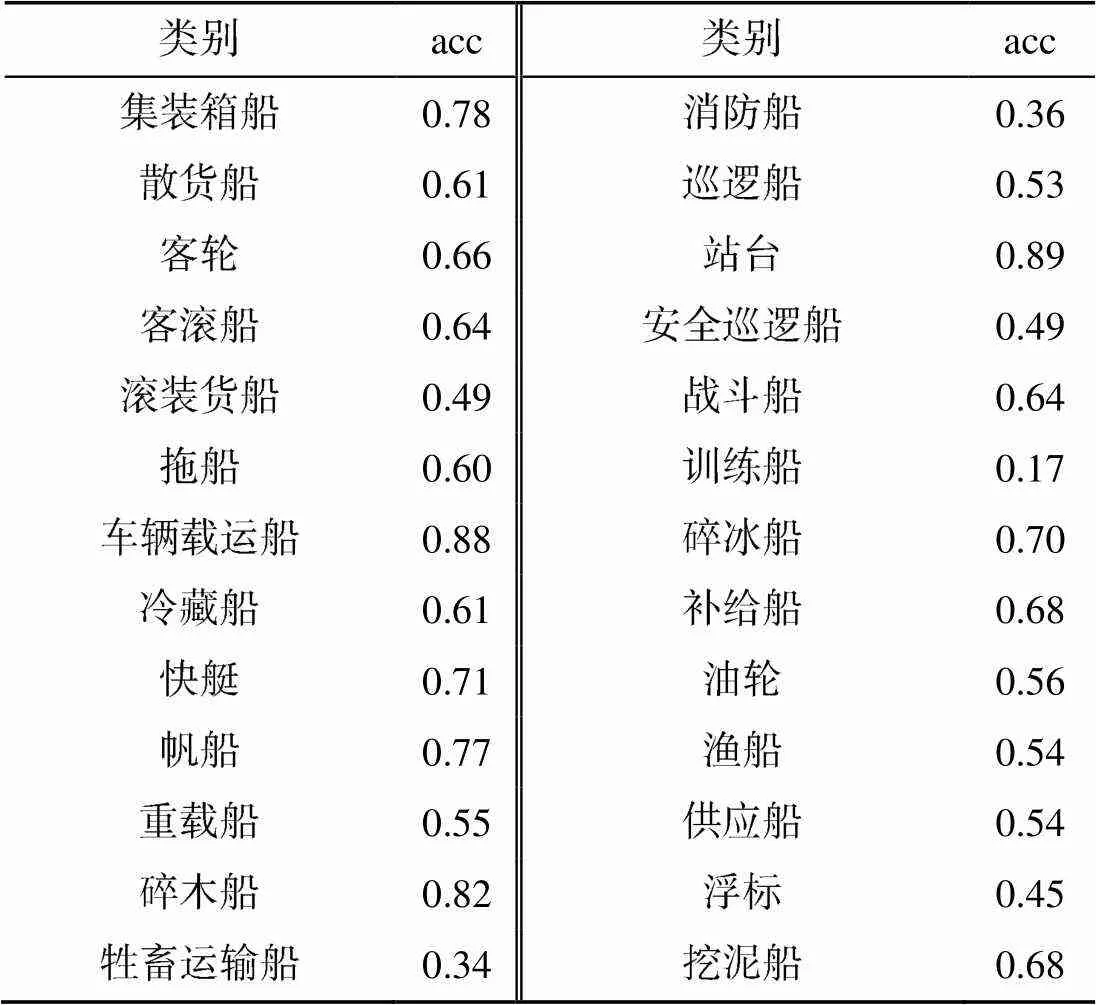
表2 MARVEL數據集船舶分類準確率
由表1數據可以看出, 在模型訓練階段, 相比于有監督方法, 在基于MoCo的船舶特征學習基礎上進行船舶分類需要更長的訓練時間, 但遠低于人工標注大規模數據集所需的時間消耗; 而在測試階段, 由于二者采用相同的模型結構, 因而時間消耗基本一致, 因此在無標簽大規模數據集上進行船舶特征學習來服務于船舶分類、海面目標檢測等下游任務是可行的。
文中利用Faster R-CNN框架, 在SMD數據集上進行了不區分類別的目標檢測, backbone均采用ResNet-50, 但對其采取不同的預訓練方式。
1) Res50_Sup_14_FRCNN: 利用MARVEL數據集中14萬樣本及其標簽對ResNet-50進行有監督預訓練。
2) Res50_MoCo_14_FRCNN: 采用MoCo特征學習方法, 利用MARVEL數據集中14萬樣本對ResNet-50進行自監督預訓練。
3) Res50_MoCo_40_FRCNN: 采用MoCo特征學習方法, 利用MARVEL數據集中40萬樣本對ResNet-50進行自監督預訓練。
表3和表4分別為IOU閾值設置為0.3和0.5時的實驗結果, 其中Res101_MRCNN和Res101_ FRCNN為Moosbauer等[9]采用有監督backbone預訓練方法進行海面目標檢測的實驗結果, DCT (discrete cosine transform)-based GMM(Gaussian mixture model)為Zhang等[23]采用傳統的海天線檢測-背景建模-背景去除方法的實驗結果。
表3和表4中的Res50_Sup_14_FRCNN和Res50_MoCo_14_FRCNN兩行數據可以說明, 無論IOU閾值的取值如何, MoCo+Faster R-CNN方法在海面目標檢測任務中的表現更好。具體來說, 在訓練參數基本一致的情況下, 相比于有監督backbone預訓練的方法, 文中將自監督表征學習用于backbone網絡預訓練, 在代表檢測準確率的AP評分和代表檢測整體效果的f-score評分上均超過了Res50_Sup_14_FRCNN。
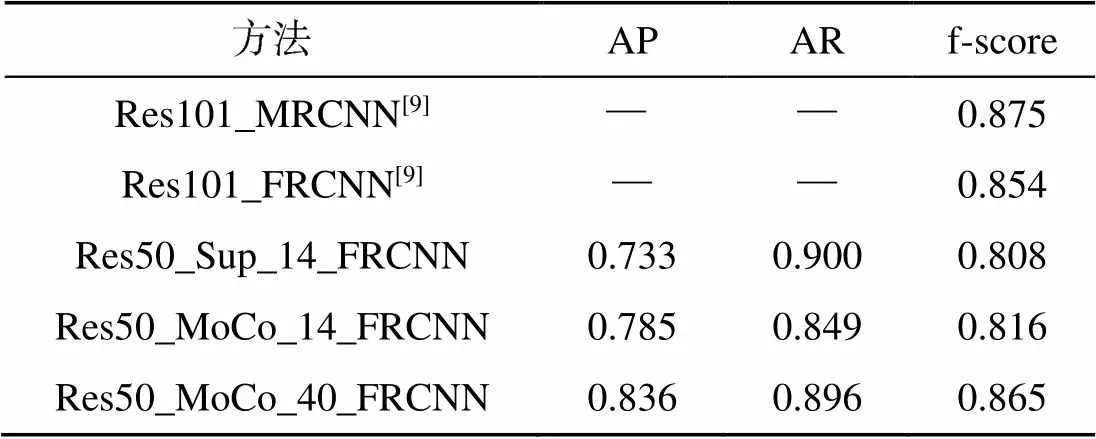
表3 SMD數據集目標檢測結果(IOU_thrs = 0.3)
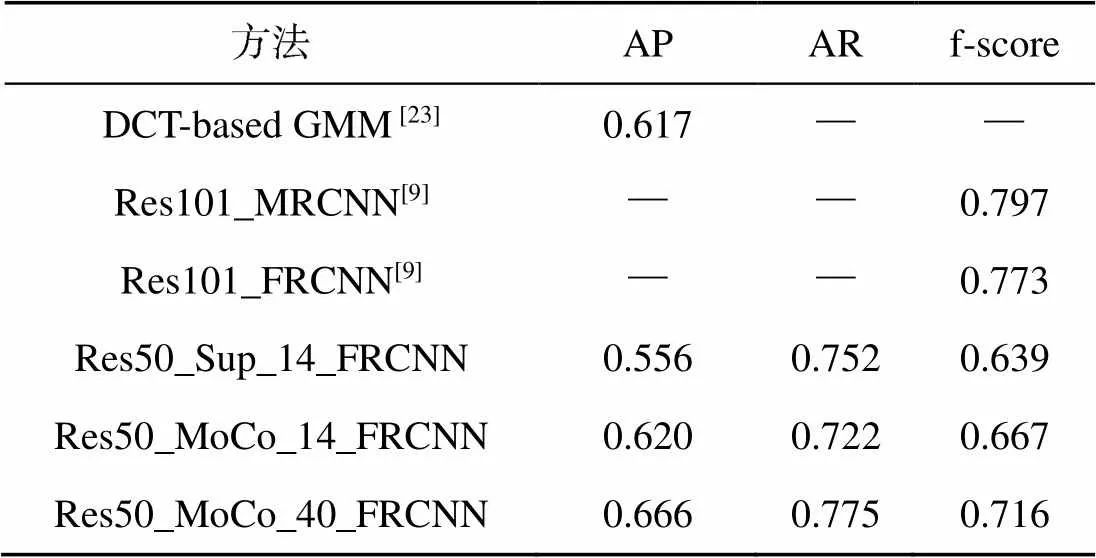
表4 SMD數據集目標檢測結果(IOU_thrs = 0.5)
表3和表4中的Res50_MoCo_14_FRCNN與Res50_MoCo_40_FRCNN兩行數據表明, 隨著用于自監督船舶特征學習樣本量的增加, 海面目標檢測效果全面提升, 尤其是在IOU閾值設為0.3時, 檢測效果超過了使用有監督預訓練ResNet- 101網絡作為backbone并引入特征金字塔(fe- ature pyramid network, FPN)[24]的Res101_ FRCNN方法(f-score分別為0.865和0.854)。由此可以說明, 當無標簽海洋數據樣本的樣本量足夠大時, MoCo+Faster R-CNN海面目標檢測方法可以取得與采用有監督backbone預訓練的方法相當或更好的檢測效果。
此外, 表4的實驗數據表明MoCo+FRCNN海面目標檢測方法的檢測效果優于傳統的DCT- based GMM[20]方法, 也進一步證明了開展基于深度學習的海面目標檢測研究的必要性。
5 結束語
文中將自監督表征學習引入海面目標檢測領域, 采用MoCo方法在大規模無標簽海洋數據上進行海面目標特征學習, 而后將學習到的特征用于海面目標檢測任務。實驗結果表明, 該方法可以取得較好的海面目標檢測效果, 突破了大規模有標注海面目標數據集缺乏對開展基于深度學習的海洋智能感知研究的限制。但由于目前可用的海面目標檢測數據集樣本極度不平衡, 文中研究未能實現對海面目標的多分類, 如何克服樣本不平衡問題, 實現多分類海面目標檢測將是下一步的工作重點。
[1] Lin T Y, Maire M, Belongie S, et al. Microsoft Coco: Common Objects in Context[C]//European Conference on Computer Vision. Zurich: ETH, 2014: 740-755.
[2] Everingham M, Van G L, Williams C K I, et al. The Pascal Visual Object Classes(VOC) Challenge[J]. International Journal of Computer Vision, 2010, 88(2): 303-338.
[3] Redmon J, Divvala S, Girshick R, et al. You Only Look Once: Unified, Real-time Object Detection[C]//Procee- dings of The IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 779-788.
[4] Liu W, Anguelov D, Erhan D, et al. Ssd: Single Shot Multibox Detector[C]//European Conference on Computer Vision. Amsterdam: Springer, Cham, 2016: 21-37.
[5] Lin T Y, Goyal P, Girshick R, et al. Focal Loss for Dense Object Detection[C]//Proceedings of The IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 2980-2988.
[6] Ren S, He K, Girshick R, et al. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Net- works[C]//Advances in Neural Information Processing Sy- stems. Montreal. Montreal: NIPS, 2015: 91-99.
[7] He K, Gkioxari G, Dollár P, et al. Mask R-CNN[C]//Proc- eedings of The IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 2961-2969.
[8] Shin H C, Lee K I, Lee C E. Data Augmentation Method of Object Detection for Deep Learning in Maritime Image[C]//2020 IEEE International Conference on Big Data and Smart Computing(BigComp). Busan: IEEE, 2020: 463-466.
[9] Moosbauer S, Konig D, Jakel J, et al. A Benchmark for Deep Learning Based Object Detection in Maritime En- vironments[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops. Long Beach: IEEE, 2019: 916-925.
[10] Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of Deep Bidirectional Transformers for Language Under- standing[EB/OL]. ArXiv, (2019-05-25)[2020-09-07]. https: //arxiv.org/abs/1810.04805?context=cs.
[11] Wu J, Wang X, Wang W Y. Self-supervised Dialogue Le- arning[EB/OL]. ArXiv, (2019-06-30)[2020-09-07]. https: //arxiv.org/abs/1907.00448.
[12] Song K, Zhang W, Lu W, et al. Visual Object Tracking Via Guessing and Matching[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2019, 30(11): 4182- 4191.
[13] Li P, Chen B, Ouyang W, et al. Gradnet: Gradient-guided Network for Visual Object Tracking[C]//Proceedings of the IEEE International Conference on Computer Vision. Seoul: IEEE, 2019: 6162-6171.
[14] Lan X, Zhang W, Zhang S, et al. Robust Multi-modality Anchor Graph-based Label Prediction for RGB-infrared Tracking[J]. IEEE Transactions on Industrial Informatics, 2019. DOI: 10.1109/TII.2019.2947293.
[15] Kingma D P, Welling M. Auto-encoding Variational Ba- yes[EB/OL]. ArXiv, (2014-05-01)[2020-09-07]. https:// arxiv.org/abs/1312.6114.
[16] Burda Y, Grosse R, Salakhutdinov R. Importance Weigh- ted Autoencoders[EB/OL]. ArXiv, (2015-11-07)[2020-09- 07].https://www.arxiv-vanity.com/papers/1509.00519/.
[17] Maal?e L, Fraccaro M, Liévin V, et al. Biva: A Very Deep Hierarchy of Latent Variables for Generative Modeling [C]//Advances in Neural Information Processing Systems. Vancouver: NIPS, 2019: 6551-6562.
[18] He K, Fan H, Wu Y, et al. Momentum Contrast for UnsuperVised Visual Representation Learning[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Virtual: IEEE, 2020: 9729-9738.
[19] Chen T, Kornblith S, Norouzi M, et al. A Simple Fra- mework for Contrastive Learning of Visual Representations[EB/OL]. ArXiv, (2020-07-01)[2020-09-07]. https:// arxiv.org/abs/2002.05709
[20] Deng J, Dong W, Socher R, et al. Imagenet: A Large-scale Hierarchical Image Database[C]//2009 IEEE Conference on Computer Vision and Pattern Recognition. Miami: IEEE, 2009: 248-255.
[21] Gundogdu E, Solmaz B, Yücesoy V, et al. MARVEL: A Large-scale Image Dataset for Maritime Vessels[C]//Asian Conference on Computer Vision. Taipei: AFCV, 2016: 165-180.
[22] Prasad D K, Rajan D, Rachmawati L, et al. Video Processing from Electro-optical Sensors for Object Detection and Tracking in a Maritime Environment: a Survey[J]. IEEE Transactions on Intelligent Transportation Systems, 2017, 18(8): 1993-2016.
[23] Zhang Y, Li Q Z, Zang F N. Ship Detection for Visual Maritime Surveillance from Non-stationary Platforms[J]. Ocean Engineering, 2017, 141: 53-63.
[24] Lin T Y, Dollár P, Girshick R, et al. Feature Pyramid Networks for Object Detection[C]//Proceedings of The IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 2117-2125.
Maritime Object Detection Method Based on Self-Supervised Representation Learning
ZHANG Qian1, ZHANG You-mei2, LI Xiao-lei1, SONG Ran1, ZHANG Wei1
(1. School of Control Science and Engineering, Shandong University, Jinan 250061, China; 2. School of Mathematics and Statistics, Qilu University of Technology (Shandong Academy of Sciences), Jinan 250353, China)
To improve the perception and monitoring ability of marine unmanned equipment, boosting the performance of maritime object detection is critical. However, complex sea environments and limited sensors make it difficult to collect high-quality samples for a large-scale maritime dataset. This results in a dearth of large-scale sea surface target datasets, which in turn hampers the development of maritime object detection based on deep earning. To address this problem, this study introduces self-supervised representation learning into the field of maritime object detection. Specifically, a momentum-contrast based algorithm is proposed to conduct representation learning of ships, where the characteristics of ship targets are learned from large-scale unlabeled maritime data. This provides prior knowledge for subsequent maritime object detection based on Faster R-CNN. Experimental results show that with the aid of model pre-training on a large-scale unlabeled dataset in a self-supervised manner, the proposed maritime object detection method through self-supervised representation learning has a performance comparable with those that employ supervised model pre-training. The proposed method can thus overcome the limitations caused by an inadequate number of labeled maritime samples.
marine unmanned equipment; target detection; self-supervised representation learning; deep learning
張倩, 張友梅, 李曉磊, 等. 基于自監督表征學習的海面目標檢測方法[J]. 水下無人系統學報, 2020, 28(6): 597-603.
TJ630; TP391.4; TP181
A
2096-3920(2020)06-0597-07
10.11993/j.issn.2096-3920.2020.06.002
2020-09-07;
2020-11-12.
國家自然科學基金項目(61991411).
張 倩(1997-), 女, 在讀碩士, 主要研究方向為模式識別、計算機視覺.
(責任編輯: 楊力軍)
猜你喜歡
艦船科學技術(2022年14期)2022-09-22 03:07:40
船舶(2021年4期)2021-09-07 17:32:22
人大建設(2020年4期)2020-09-21 03:39:12
小哥白尼(趣味科學)(2019年10期)2020-01-18 09:16:22
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
人大建設(2017年2期)2017-07-21 10:59:25
人大建設(2017年9期)2017-02-03 02:53:31
浙江人大(2014年4期)2014-03-20 16:20:16
