分布式深度學習訓練網絡綜述
2021-01-15 08:46:52朱泓睿元國軍姚成吉譚光明戶忠哲張曉揚安學軍
計算機研究與發展 2021年1期
朱泓睿 元國軍 姚成吉 譚光明 王 展 戶忠哲, 張曉揚, 安學軍
1(中國科學院計算技術研究所 北京 100190)
2(中國科學院大學 北京 100049)
3(北京曠視科技有限公司 北京 100080)(zhuhongrui@ncic.ac.cn)
隨著近年來深度學習算法在各類任務中取得比傳統機器學習算法更好的效果,深度學習已廣泛應用于圖像識別[1]、音頻識別[2]和自然語言處理[3]等領域.深度學習及相關交叉領域[4]的研究熱度逐年提升,并在業界取得不少實際成果,應用范圍也越來越廣.
為了在實際應用中取得更好的訓練效果,深度學習訓練的數據集越來越大.標準訓練物體識別的ImageNet數據集包含約128萬張圖片,總大小超過150GB;面向其他采用高分辨率圖像或者視頻專業領域的數據集甚至會高達TB乃至PB級別.另一方面神經網絡結構也越來越復雜,網絡層數和參數的數量不斷增加,從以前的5~8層的神經網絡增加到現在的上百層,甚至超過千層的神經網絡也被提出并使用.
數據集規模和網絡層數的增加使得深度學習的訓練過程需要耗費大量的存儲和計算資源.由于單臺機器的算力有限,故而導致整體訓練時間過長.舉例來說,目前使用一塊NVIDIA P100 GPU以標準數據集ImageNet[5]來訓練神經網絡ResNet-50[6],完成90個Epoch完整周期,就需要花費14天的時間[7].這樣長耗時的訓練給神經網絡訓練調試和研究帶來了諸多不便.
為了減少深度學習訓練時間,近年來以分布式計算為主的加速方法被越來越多地應用在深度學習領域.分布式的深度學習采用多臺GPU服務器,通過構建高性能通信網絡形成分布式深度學習計算的模式,打破了原有的算力限制,使得計算規模擴展成為可能.
現在分布式深度學習已經取得了初步進展,常見的深度學習框架[8-12]都已經開始支持分布式訓練任務,并在一些時間敏感和超大計算量的應用中取得明顯加速效果.但是由于分布式節點數目過多、訓練參數復雜、網絡環境的復雜等因素,分布式深度學習的應用推廣仍然面臨諸多的挑戰,其中最主要的就是分布式計算下的性能問題.
本文調研了大量相關領域會議、期刊等文章,對常用的網絡性能優化方案進行綜述,本文的貢獻主要有3個方面:
1) 分析了目前分布式深度學習所面臨的問題與挑戰.
2) 總結和對比了目前針對分布式深度學習的10種性能優化方案.
3) 對未來分布式深度學習訓練的研究內容和方向進行了總結和展望.
1 分布式訓練中的問題與挑戰
分布式在深度學習訓練時主要存在6方面問題:
1) 節點數增多導致的性能瓶頸
分布式深度學習在參數更新時需要對各節點的參數進行同步,這個過程涉及到通信過程.隨著分布式訓練中節點數目的增多,同步通信過程效率得不到保證,使得整個系統容易出現性能瓶頸.同步通信時需要保證高帶寬和低延遲,這樣通信時間降低,就可以通過計算和通信并行,不會拖慢整個訓練過程.高帶寬和低延遲是保證分布式訓練加速比的基本需求.
2) 網絡環境復雜、多變導致的不穩定
不同分布式集群系統的拓撲、帶寬和延遲等參數各不相同,特別是對于多租戶的云計算環境,網絡環境復雜,且存在不小的波動.因此同一個網絡性能指標在不同的集群、不同的節點甚至不同的時間點測試時都可能存在不小的差異.網絡環境的復雜性一方面可能造成網絡性能的降低,另一方面也增大了實驗測試的難度.
3) 通信參數多變
神經網絡的參數大小決定了分布式訓練通信量的大小,神經網絡層數決定了通信的數量,神經網絡訓練的速度決定了通信的頻率.因此,對于不同的神經網絡,通信特征差異很大,沒有完美的通信方式可以適用于所有的場景.
4) 通信數據量極大
深度學習需要海量的數據作為訓練和測試數據,其數據量可能高達TB甚至PB級別.對于分布式環境來說,一方面單節點存儲能力可能受到限制,另一方面多節點間數據搬運或同步至其他節點也會耗費大量時間,給分布式訓練帶來極大挑戰.
5) 超大規模訓練的應用與數據難以獲取
對于傳統的以CPU為計算核心的機群系統,深度學習應用只在特定的如分類、回歸等任務中具有明顯的優勢,為了使得深度學習在超大規模的集群環境中使用,必須要有合適的應用場景以及足夠豐富的數據源.目前沒有足夠的公開數據與Benchmark以支持更廣泛領域的研究,這也為開展相關研究帶來不小的挑戰.
6) 訓練批大小(batch size)對訓練精度的影響
在大規模分布式系統中進行標準神經網絡與數據集訓練時,則經常會遇到由于節點數上升、batch size上升導致的訓練結果不理想的情況[13-17].原因是為了保證所有計算資源的利用率,系統會增加每一輪訓練(iteration, Iter)使用的訓練集數量(batch size),而當訓練參數batch size過大時,隨機梯度下降(stochastic gradient descent, SGD)算法會逐漸趨近于梯度下降(gradient descent, GD)算法(即每輪訓練使用全部數據集),這會造成訓練參數容易陷入局部最優值的現象,最終造成訓練錯誤率(error rate)達不到標準值.
綜上所述,盡管在不少場景下通過分布式訓練可以獲得更快的訓練速度,解決更復雜、數據量更大的深度學習問題,但分布式深度學習發展中還是存在種種問題與挑戰,歸納起來主要有3點:性能瓶頸、應用瓶頸與理論瓶頸.
本文將詳細分析分布式深度學習中的性能問題,重點圍繞網絡通信方面引起的性能瓶頸.
2 研究現狀
2.1 訓練過程及通信特征
本節介紹目前主流的分布式深度學習訓練過程及其通信行為,這將方便我們理解后續的優化策略.
神經網絡是一種模仿生物大腦結構的多層神經元互連結構[18].訓練過程主要是通過梯度下降[19]的原理,不斷調整神經網絡的各項參數,使得最終參數對于訓練集數據來說盡可能接近全局最優值.在此過程中訓練數據首先以前向傳播的方式經過神經網絡,并得到預測結果,然后比較預測結果和實際結果,再進行反向傳播,從后向前依次調整神經網絡參數,使得神經網絡對于該數據訓練結果預測越來越準確.
傳統的梯度下降(GD)算法[20]一次使用所有的訓練數據來進行神經網絡參數訓練,由于每次訓練數據都是固定不變的,會使得梯度下降方向具有確定性,無法使訓練過程跳出局部最優值,從而遠離全局最優值.目前神經網絡訓練主要采用隨機梯度下降[21]方法,每次從訓練集中隨機選取小批量(mini-batch)的訓練數據集,增加了梯度下降過程中的隨機性,從而盡可能避免了陷入局部最優值,增加了最終訓練的準確性.
分布式深度學習的并行策略主要分為2種:數據并行[22]和模型并行[23].數據并行實際上是將mini-batch進一步進行分割,將切割后的各部分數據分配到不同的計算節點上;而當神經網絡規模過大,超過了單臺機器的承載能力時,通常采用模型并行策略,對神經網絡進行分割,并分配到不同的計算節點上.目前超大型的神經網絡并不普及,因此分布式深度學習訓練主要是以數據并行為主.
對于數據并行的分布式深度學習訓練來說,其具體訓練流程為[8]:
1) 每個節點分別從硬盤或網絡上讀取總共mini-batch大小的數據并拷貝至內存;
2) 從CPU內存拷貝數據至GPU內存;
3) 加載GPU kernel并由前向后逐層計算(前向傳播過程);
4) 計算損失函數(loss)并進行反向傳播,逐層計算梯度值;
5) 同步各節點梯度值(發送自身各層梯度,并接收其他節點的各層梯度);
6) 根據同步后的梯度值更新神經網絡參數.
上述6個步驟完成了一次神經網絡訓練過程(即一個迭代(iteration,Iter)).在實際訓練中,需要完成多次訓練,以達到最終神經網絡參數訓練的目的.以神經網絡ResNet-50訓練ImageNet為例,一次完整訓練需要90時期(epoch),即每張圖片需要被訓練使用90次.假設訓練中我們設置mini-batch=256,由于ImageNet共計約128萬張圖片,每一個Epoch需要訓練約1280 000256=5 000 Iter,即90個Epoch共計5 000×90=450 000次.上述的訓練過程共需重復約450 000次,如果采用4臺機器做分布式訓練,則需要450 0004=112 500次.
上述訓練流程的6個步驟中涉及到網絡通信的部分主要是步驟1,2,5.其中步驟1中如果使用本地磁盤供應數據,則不涉及網絡通信過程.步驟2涉及到了服務器間的通信,其需要將數據通過PCI-e傳輸到GPU中.步驟5中的通信數量和大小主要取決于神經網絡的參數大小和網絡層數等.在通常情況下,一個Iter中每個節點需要傳輸和接收的數據大小都等于神經網絡參數的總大小,而需要傳輸的次數與神經網絡層數相關.因此對于每一層傳輸的數據大小是不同的,頻率間隔也與計算速度有關.對于常用于圖像識別處理的卷積神經網絡(convolutional neural network, CNN)[24],卷積層的參數總數比全連接層的參數要小許多,因此在反向傳播的過程中,各神經網絡層的通信量會呈現先大后小的不均衡現象.
不同的神經網絡具有不同的層數,不同層的參數數量也不盡相同.需要注意的是,對于參數越多的神經網絡,通信占比也會越大,從而更容易造成分布式訓練的瓶頸.
此外,步驟5中也存在對機內各GPU之間數據進行同步操作,因此也存在設備間的通信.
2.2 關于網絡通信的優化
本節介紹目前針對分布式深度學習的主流性能優化方法,詳細分析優化加速原理,對比不同優化方案的利弊.
2.2.1 改善網絡硬件資源
2.1節所述分布式深度學習訓練中的通信特征對于帶寬、延遲具有極高的要求.因此通過改善硬件基礎設施來提升網絡帶寬、降低延遲,是最直接有效的改進通信性能的方法.
對于機間通信的互連網絡,可以采用IB(Infini-Band)[25],OPA(Intel Omni-Path architecture)[26]等方案來實現超高的帶寬和低延遲.它們通過專用的網卡、交換機和專用的協議來實現遠程直接數據存取(remote direct memory access, RDMA)技術,支持微秒級延遲的點對點通信.也可以采用TCPIP協議通過RoCE(RDMA over converged Ethernet)[27]來支持RDMA操作,從而降低通信延遲.
對于機內通信的互連網絡,通常情況下是使用PCI-e總線進行數據傳輸.常見的GPU插槽為PCI-e 3.0×16,速率約為16 GBps.
為了提升GPU之間的通信能力,英偉達推出了GPU Direct技術,其發展主要分為4個階段[28].2010年提出SHM(GPU direct shared memory)技術,通過共享的固定主機內存提供了與第三方PCI Express設備驅動程序加速通信的支持,如圖1所示;2011年提出P2P(GPU direct peer-to-peer)技術,允許使用高速DMA傳輸直接在2個GPU的內存(即顯存)之間加載和存儲數據,如圖2所示;2013年提出了GDR(GPU direct RDMA)[29]技術,使網絡設備可以完全繞過CPU主機內存直接訪問GPU內存,如圖3所示;2019年提出了GPU Direct Storage技術,支持在GPU內存和存儲設備(例如NVMe或NVMe-oF)之間直接傳輸數據.
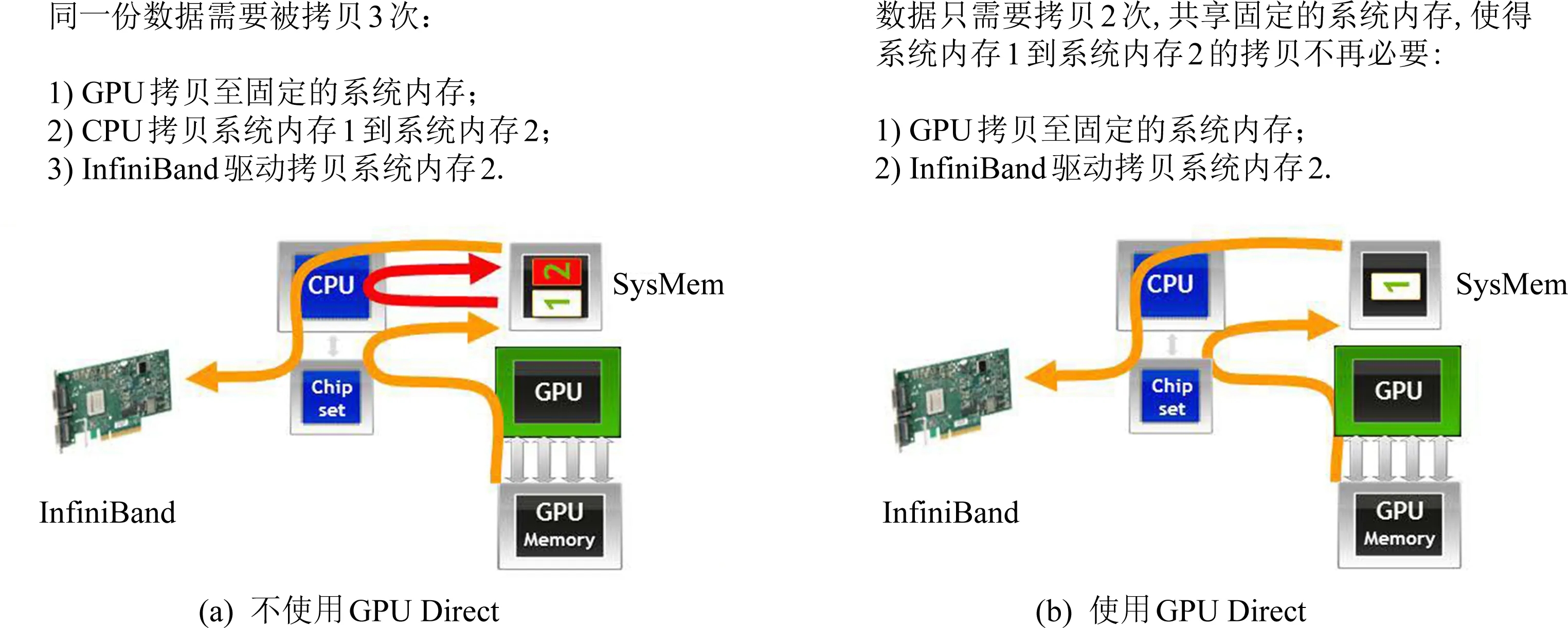
Fig. 1 GPU direct shared memory proposed by NVIDIA in 2010

Fig. 2 GPU direct peer-to-peer proposed by NVIDIA in 2011
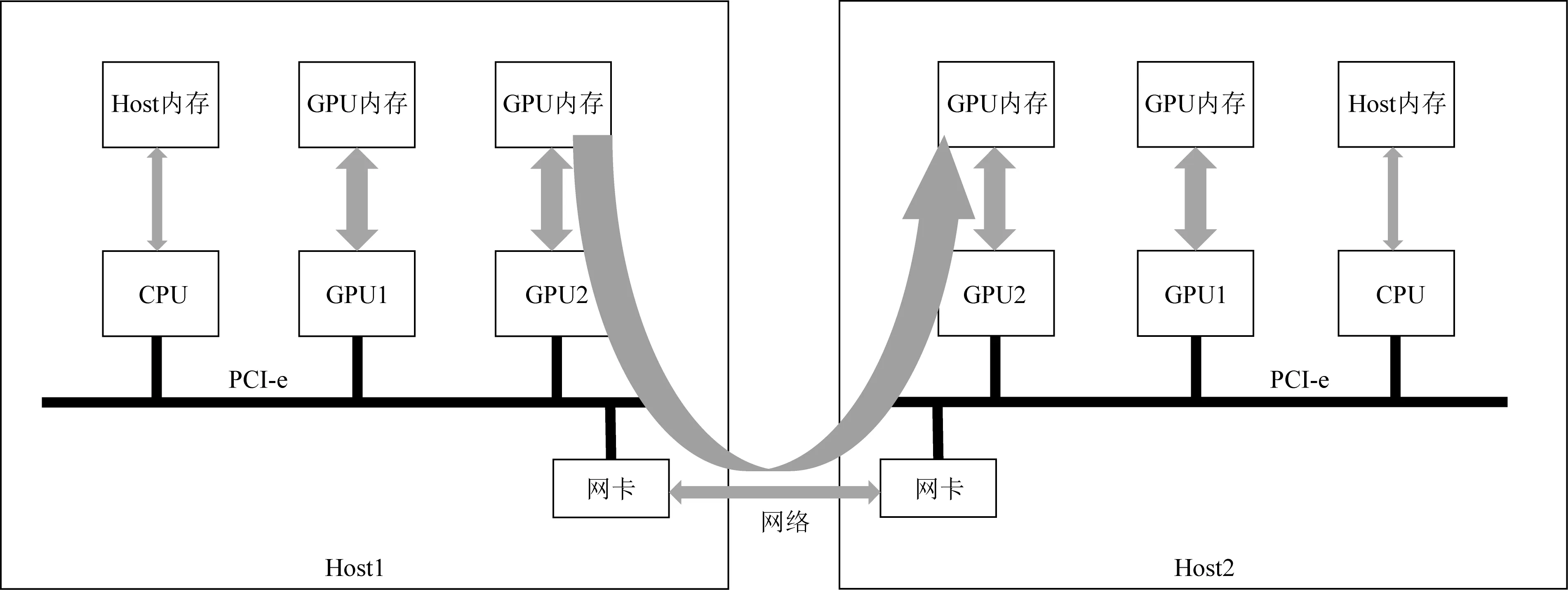
Fig. 3 GPU direct RDMA proposed by NVIDIA in 2013
對于GPU Direct P2P技術,多個GPU通過PCI-e連接到CPU,常見的PCI-e 3.0×16總線的雙向帶寬不超過32 GBps,隨著訓練數據的不斷增長,PCI-e帶寬很難滿足需求,逐漸成為系統瓶頸.為進一步提升多GPU之間的通信性能,充分發揮GPU的計算能力,NVIDIA于2016年發布了全新的NVLink[30]通信架構.
上述新型網絡架構都可以直接提升帶寬和延遲性能,可帶來直接、明顯的性能提升,但需要投入大量成本來更新網絡設施.
2.2.2 采用All-Reduce集合通信

Fig. 4 Parameter server architecture
早期深度學習的分布式訓練采用參數服務器(parameter server, PS)[31]的方式進行數據同步.具體方式為使用一個或多個服務器作為專門管理參數的服務器,其他節點完成一次訓練后,將參數傳至參數服務器;參數服務器收集各節點發送過來的參數,并歸約(平均)這些參數,并將最終的結果分發返回給各計算節點;計算節點收到來自參數服務器的參數后,使用這些參數更新神經網絡參數,并開始下一輪迭代.
參數服務器的結構如圖4所示[32].其優點是算法簡單、易于部署.缺點是參數服務器本身與計算節點間需要進行All-to-All通信,容易產生流量擁塞;其次多機流量在鏈路中需要同時通過同一條鏈路,這種流量聚合容易占滿帶寬,造成帶寬不足的通信瓶頸.針對以上參數服務器的缺點,研究人員提出各種參數服務器的改進辦法,例如增加參數服務器數量、使用多級參數服務器等,但仍然不能徹底解決參數服務器通信瓶頸的問題.
目前主流的同步方式開始摒棄參數服務器,而采用類似于MPI[33]中的集合通信方式.其中All-Reduce集合通信[34-36]是最適合于該場景的集合通信方式,分為Reduce-Scatter和All-Gather這2個步驟.All-Reduce對需要通信的數據進行分片劃分成若干個片段(chunk),在Reduce-Scatter步驟中將chunk分發到其他節點,并從其他計算節點收集到一個完整的chunk(歸約了其他所有節點的該chunk數據);然后在All-Gather過程中發送這個完整的chunk并收集其他節點的其他完整chunk,這樣就能收集到所有通信數據的歸約結果.如圖5所示:

Fig. 5 Architecture of MPI All-Reduce[37]
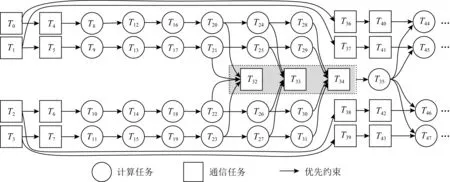
Fig. 6 DAG of distributed deep learning training
All-Reduce集合通信方法在傳統并行分布式計算中運用廣泛,在超算環境下具有長久的積累,具備成熟的并行算法和編譯環境.相對于參數服務器,All-Reduce集合通信摒棄了類似參數服務器的中心管理節點,實現了去中心化,在通信過程中節點間關系平等,不存在流量共同流向中心節點造成的擁塞問題.但是采用All-Reduce后,由于沒有了中心管理節點,給備災容錯、任務調度以及異步通信方法等帶來挑戰.
2.2.3 增加并行度
在2.1節中我們分析了分布式訓練深度學習的過程.為了減少通信或計算的開銷,應當盡可能得讓不存在依賴關系的步驟實現并行化,從而減小時間消耗.
文獻[38]中詳細給出了深度學習訓練中的并行度分析,重點圍繞計算操作(operators)、網絡和訓練3個方面進行研究.其中計算并行加速方法主要是神經網絡本身計算時通過使用矩陣運算來大幅提高并行度,這也是深度學習中GPU替代CPU進行訓練的優勢;網絡方面的并行加速方法包括數據并行(data parallelism)、模型并行(model parallelism)和層流水(layer pipelining)的方式,其中數據并行為目前最常用的多機并行方式,而模型并行通過將完整的神經網絡拆分到不同的計算節點進行計算,適合于神經網絡參數特別大的場合,另外模型并行在一定程度上也可以減小單節點的計算任務;對于層流水方式,可以減小單計算節點的參數存儲量,但并不能直接提高并行度,因為神經網絡訓練無論是前向傳播還是反向傳播都是逐層推進的.
對于實際訓練過程,同時實現計算與通信并行是一個極其有效的優化方案.通信操作發生在每次反向傳播計算該層神經網絡完成的時刻,而反向傳播進行下一次(即前一層)計算時不依賴通信后的結果,因此反向傳播和參數(梯度)同步可以并行執行.文獻[39]中給出了訓練過程的有向無環圖(DAG),如圖6所示:
圖6所示是4個計算節點進行3層神經網絡訓練的一個Iter完整的流程圖.其中T0到T3為各節點獲取數據的過程;T4到T7為設備間通信(主要是CPU內存到GPU內存搬運)過程;T8到T19為前向傳播的3層神經網絡過程,其中T8到T11為第1層,T12到T15為第2層,T16到T19為第3層;T20到T31為反向傳播的3層神經網絡參數計算過程,其中T20到T23為第3層,T24到T27為第2層,T28到T31為第1層;T32到T34分別是神經網絡第3層到第1層參數或梯度的同步通信過程;過程T35是完成參數同步后使用同步后的參數更新神經網絡參數的計算過程,此過程實際上是每個節點自身計算完成的.
在不考慮并行時,一次神經網絡訓練的時間應為
ttotal=tio+tH2D+tforward+tbackward+tcomm+tupdate,
其中,tio是數據從硬盤讀取到CPU內存的時間,tH2D是設備間通信(CPU內存到GPU內存拷貝)的時間,tforward是前向傳播計算時間,tbackward是反向傳播計算時間,tcomm是參數同步的通信時間,tupdate是參數同步后更新時間.
利用該有向無環圖我們可以看出,無邏輯依賴的部分可通過并行的方式來提高整體效率.因此,在設計深度學習框架的時候,應該盡可能將通信部分通過并行的方式隱藏在計算的過程中.目前,各深度學習框架的設計各不相同,有的側重并行,有的并行度一般但計算速度快.在理想的情況下,每一次神經網絡訓練的時間應為

增加并行度的方法更多的是與深度學習框架開發相關的并行優化.如果將訓練中的并行方案做好,可以在理想網絡狀況下將通信時間盡可能隱藏在計算時間內,極大減小了通信時間.缺點是依賴于深度學習框架的開發程度,因此自主開發優化的難度較大.
2.2.4 同步通信算法優化
同步通信最容易成為分布式訓練的瓶頸,因此直接針對All-Reduce的優化也是一個受關注的熱點問題.
集合操作All-Reduce早期集成在消息傳遞接口(message passing interface, MPI)[40]中,因此針對All-Reduce的研究已經比較成熟.
目前使用最廣泛的All-Reduce算法是Ring All-Reduce,其最早由百度公司應用在分布式深度學習訓練中[41],并在實驗環境取得較好的性能.目前,該算法已被主流的深度學習通信框架采用,例如NCCL[42],Horovod[32],gloo[43],GPU-MPI[44]等.其具體原理如圖7所示:

Fig. 7 Ring All-Reduce structure
各計算單元在邏輯上構成一個環狀拓撲,僅與左右2邊的單元通信.將所需同步的數據按照節點數N平均切分成N個chunk,在Reduce-Scatter過程每個節點每次輪詢傳輸一個chunk,并將接收到的chunk做歸約操作.當完成N-1次傳輸后,每個計算單元會收集到一個完整的chunk.之后All-Gather過程重復N-1次傳輸后,每個計算單元都會收到所有的完整歸約的N個chunk.
對于節點數達到數百或數千的分布式訓練任務來說,Ring All-Reduce可能會遇到通信瓶頸.這是由于當通信節點數目增多時,Ring的傳輸次數快速上升,而單次傳輸的數據數量迅速減小,導致大量的小容量包在環形結構上高頻傳輸,導致最終平均傳輸效率降低.
為了優化超大規模下All-Reduce的傳輸效率,許多超大規模實驗中開始使用多維環狀(torus)的結構來替代單維Ring結構,其中每一維度都是完整的環形結構,通過提升維度,可以減小每一維度的環大小,最終顯著減少All-Reduce中傳輸的次數.
NCCL在2.4版本中提出了雙向二叉樹(double binary tree)[45],它使用2個二叉樹結構,使得每一條鏈路單次傳輸的時候沒有鏈路聚合而且雙向帶寬都能得到充分利用.利用二叉樹的結構顯著降低了All-Reduce中的傳輸次數.在實驗環境下雙向二叉樹取得了比傳統Ring和多維度Ring都更出色的性能,尤其是在節點規模比較大時,雙向二叉樹性能優勢更明顯.其基本結構如圖8所示:
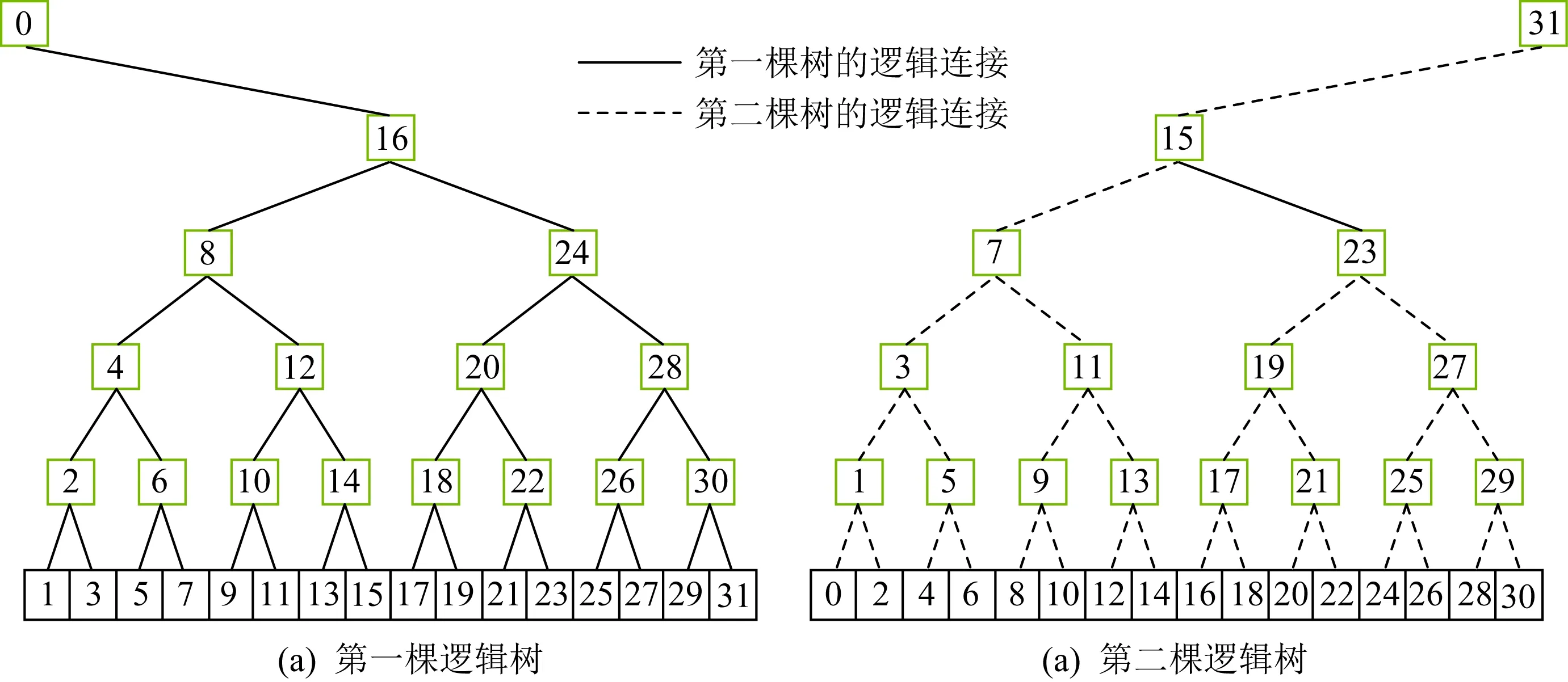
Fig. 8 Double binary tree structure
除此之外,還有許多其他常見的All-Reduce算法.例如Recursive Doubling,Recursive Halving and Doubling,Binary Blocks等.文獻[46]對比了在不同配置環境(節點數、通信包大小)下各種All-Reduce算法的性能,圖9給出了不同All-Reduce算法中通信節點數隨通信量的變化.從此可以看出,不同網絡環境下不同的All-Reduce性能存在不小差異,因此在選擇All-Reduce通信算法的時候需要考慮具體配置環境,包括數據包大小、節點數、網絡狀況等諸多因素.因此如何在特定網絡環境下快速選擇出最優的All-Reduce算法并不容易.
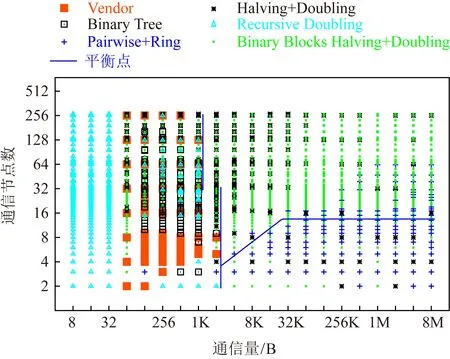
Fig. 9 Performance of different All-Reduce Algorithms
2.2.5 張量融合技術
在2.2.4節中提到不同All-Reduce算法在不同環境下性能是有差異的,那么如何優化使得同一種All-Reduce算法在不同環境下盡可能獲得較好的性能是一個挑戰.
在實際訓練環境下,通常最直接影響一個All-Reduce算法性能的主要是小包的通信性能.無論一個通信框架多么完善,除去本身帶寬限制導致的延遲之外,還存在諸多因素引起的網絡本身的延遲;而對于大包來說,該延遲造成的影響相對于整體傳輸時間來說較小,更容易接近物理極限帶寬;相比之下小包對延遲效應更敏感.
張量融合(tensor fusion)技術[47]被提出并應用于解決同步通信時傳輸量不均等的問題.其原理是將通信的包進行拆分、拼合,從而實現相同大小的數據包傳輸.
Horovod中實現張量融合的步驟為[48]:
1) 判定哪些張量準備開始做Reduce操作,選擇最初幾個可以適配配置標準尺寸的且同數據類型的張量;
2) 為標準尺寸通信單元分配內存;
3) 將選定的張量拷貝至標準尺寸通信單元;
4) 對標準尺寸通信單元執行All-Reduce;
5) 將同步后的數據從標準尺寸單元拷貝至輸出張量;
6) 重復以上過程直到本輪沒有多余的張量需要傳輸.
根據上述的過程我們可以看到,盡管張量融合技術能夠保證數據包的一致性,但需要額外完成2次數據的內存拷貝工作,這同樣也會帶來性能損耗;在訓練框架中進行張量融合,會使得原本應該實時進行同步的All-Reduce操作變成異步的模式;除此之外,如何選定標準尺寸通信單元的大小也是實際使用該方法時所面臨的問題.
2.2.6 使用異步通信
盡管目前使用同步通信已經成為分布式深度學習訓練的主流通信方式,但異步通信作為有效提升訓練效率的方法,也一直是研究熱點.
目前異步通信的實現都是基于參數服務器(parameter server)結構.傳統的同步通信過程中,每一個同步Iter,參數服務器需要收集到所有節點的參數數據,并完成歸約操作后才能發送給各節點完成本輪通信.由于不同節點數據到達參數服務器的時間可能不一樣,參數服務器必須要等待至最慢的節點數據到達之后才能完成整個過程,這個等待過程會導致通信性能及訓練效率的下降;而異步通信中,每個節點數據到達參數服務器后,可以根據異步設置,不需等待或者僅等待少量節點參數到達,就可以直接由參數服務器返回數據,這將在每個訓練Iter中節省大量參數同步時間.
盡管異步訓練方法實現了更好的并行性,但其并非嚴格的梯度下降過程,因此會導致訓練精度下降.對于同步SGD,各計算節點的梯度值是進行累加平均操作,在數學上與單節點訓練相同數據是等同的;而對于異步SGD,同一Iter中每個節點從參數服務器上獲取的參數不能保證相同,相當于是在不同的位置做梯度下降,這種不精準的梯度被稱為渾濁梯度(stale gradients)[49].渾濁梯度的問題會造成訓練始終與同步SGD具有誤差,導致最終可能無法獲得同步SGD那樣精準的結果.
文獻[50]中提及到一種彈性平均SGD(elastic averaging SGD)方法,基于一個數學公式來減小異步通信引起的渾濁梯度問題.但是該方法仍然使用參數服務器的結構,無法避免多對一通信時造成的帶寬瓶頸問題.
文獻[51]中提出了流言SGD(gossiping SGD)方法,使用流言協議(gossip協議)來實現非中心化的異步同步策略.這種方式具有良好的擴展性和容錯性,同時可以實現去中心化.但該方法也存在不少缺點,譬如同步延遲不確定、延遲更高、存在消息冗余等,即數據會重復發送,從而浪費了帶寬.
采用異步通信的方式可以實現在節點間訓練速度不平衡時,傳輸快的節點不需要等待慢的節點數據到達,因此節省了同步時的通信時間.但是目前來說異步通信都是基于參數服務器結構的,還沒有人嘗試在All-Reduce中實現異步結構,此外異步通信還會在一定程度上造成訓練精度的丟失.
2.2.7 量化壓縮與稀疏化壓縮
為了降低通信時間占比,一種直接且有效的方法是降低通信量(大小和數量).深度學習本身是一種模糊計算,因此對于數據精度的要求并不像科學計算那樣高,一定程度上可以通過有損壓縮的方法來顯著降低通信量.目前針對深度學習數據壓縮的方法主要有量化壓縮與稀疏化壓縮2種.
量化壓縮來源于Google的文章[52],通過使用8 b或16 b的整數類型來替代32 b的浮點數類型.這種使用低精度的計算方法很大程度節約了內存與存儲的開銷,同時在可以使用單指令流多數據流SIMD的設備可以顯著增加訓練的速度.而對于分布式訓練來說,低bit的數據傳輸量成倍減小,從而大幅節約了通信時間.同時在一些無浮點數支持的低功耗嵌入式設備中,利用低bit進行訓練或推理都是一個很好的選擇.
量化壓縮是一種有損壓縮,因此在選擇壓縮位數時也需要平衡考慮.目前16 b,8 b量化壓縮已經在實際系統訓練中被使用,實驗表明有限的有損壓縮不會顯著影響訓練精準度.也有研究表明更低位數的量化壓縮,例如3值壓縮(-1,0,1)[53-54]甚至1 b壓縮[55],在某些場景也能滿足使用的需求.
稀疏化壓縮是另一種有損壓縮的方法.在神經網絡參數更新時,并不是每一次都會更新所有的參數,有的參數更新的多,有的參數更新的少.稀疏化壓縮是通過盡可能減小不更新的參數傳輸或更新較小的參數傳輸,來保障重要參數參與通信同步的同時顯著降低通信量.
最早稀疏化壓縮由文獻[56]提出,該文基于閾值(thresholding)方式來選擇傳輸數據,僅當梯度值大于某個固定的閾值時才進行傳輸,這種方式的壓縮率達到了846~2 871倍,極大地減少了通信量.但由于這種閾值是個靜態值,在不同情形下需要手動進行調整.文獻[57]在此基礎上做了若干改進,選擇了正比例和負比例梯度更新的固定比例;文獻[58]提出了梯度下降以基于絕對值通過單個閾值稀疏梯度;還有研究為了保持收斂速度,梯度下降需要添加歸一化[59]等.但是以上壓縮基本都在小訓練集(例如MNIST訓練)和簡單的神經網絡(例如全連接網絡)做測試.文獻[60]中提出的DGC使用了多種策略混合調整,最終使得稀疏化壓縮在復雜神經網絡(例如ResNet-50,AlexNet)中也取得了很好的加速,且沒有顯著影響計算精確率.
總結來說,量化壓縮與稀疏化壓縮方法可以有效減少通信量,從而減小通信時間.但壓縮過程中也存在計算時間消耗,通過作為一種有損壓縮方案會一定程度降低訓練結果的精準度.
2.2.8 與拓撲相關的網絡優化
現實中分布式訓練環境非常復雜,不同的網絡環境差異極大,利用網絡拓撲信息對通信做針對性的優化,可以充分利用帶寬資源,從而實現整體訓練效率的提升.
文獻[61]中針對多計算節點間通信帶寬利用率低的問題,提出利用多個不同路徑的生成樹,盡可能將每一條鏈路每個方向的帶寬充分利用.這種策略針對存在多條通路的網絡環境效果很好,例如DGX-1機內網絡,因為該策略充分利用了標準All-Reduce通信例如Ring中沒有利用到的鏈路,減少了單鏈路的傳輸量.圖10顯示的是Ring All-Reduce針對鏈路的利用圖;圖11中顯示的是算法將通信分為3條鏈路后的利用圖.
Fig. 10 Path for Ring All-Reduce

Fig. 11 Three tree paths for one All-Reduce
目前分布式訓練中一般會將通信方式設置為多級架構(hierarchical),普遍都會針對機內通信和機間通信做不同處理.圖12是典型的All-Reduce在機內、機間的混合方式.其在機內是環狀的通信方式完成第一次All-Reduce,接著在機間通信時僅由一個計算單元與其他節點通信,也是采用環狀的All-Reduce通信方式,最后再將最終All-Reduce結果通過機內廣播至各計算單元.
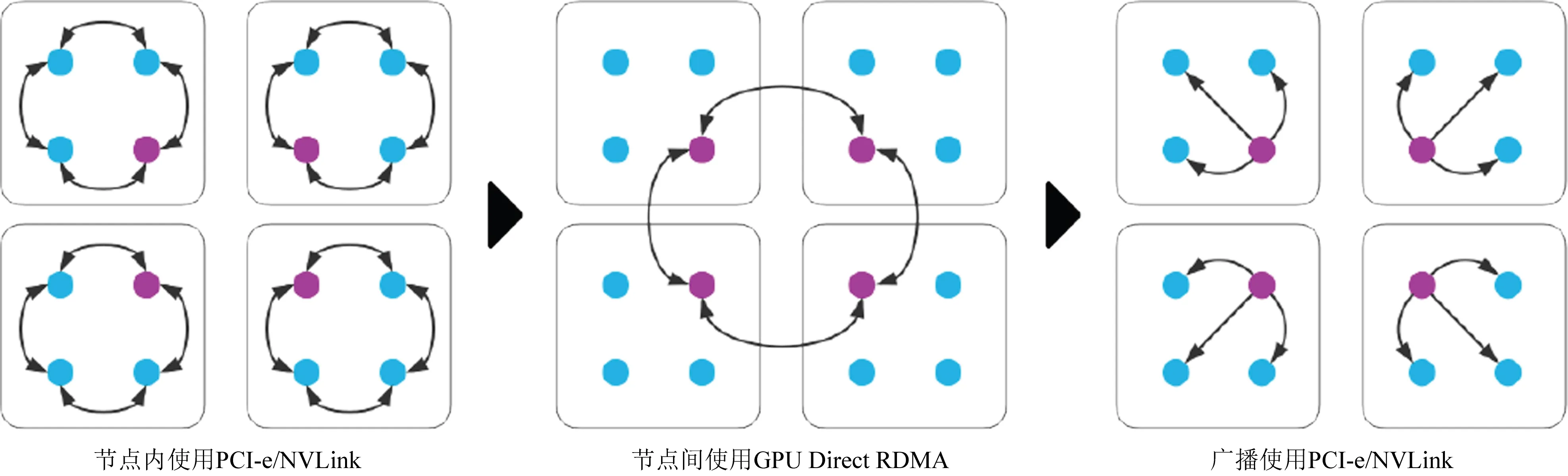
Fig. 12 Hierarchical All-Reduce structure
與拓撲相關的網絡優化可以充分利用環境的特征,尋找最適合的通信手段,從而達到提升性能的效果.但是如何及時完成拓撲發現、如何調整以達到最優效果都是其困難所在.目前對其的研究仍處于起步階段,有待進一步研究.
2.2.9 專用系統設計
在傳統通信網絡無法有效解決通信瓶頸問題時,根據應用訓練環境進行專用的系統設計成為一種可行且實用的途徑.
對于分布式深度學習來說,通信部分是影響其加速比的最大瓶頸,而其中又以參數或梯度的同步操作為主.針對深度學習中All-Reduce采用專用的軟硬件系統設計是一種切實可行的方案.
Mellanox HPC-X[62]中使用了Mellanox的專用交換網絡,如Mellanox網卡(CORE-Direct引擎和硬件標簽匹配)和交換機(支持Mellanox SHARP加速引擎).通過采用SHARP(可擴展分層聚合和縮減協議)技術將集合操作由CPU卸載至交換網絡.由于采用了聚合節點卻又不存在多條鏈路數據聚合到一個鏈路中,減少了鏈路中的數據聚合,緩解了網絡擁塞;另一方面通過將集合操作卸載到網絡,也減少了集合操作的時間,釋放寶貴的計算資源用于計算而不是耗費在通信處理上,減少了網絡傳輸的數據量.
在目前最頂尖的超級計算機Summit中[63],也針對集合通信使用了在網計算的優化方案.Summit使用了混合的架構,每個節點包含了2個22核心的IBM POWER9 CPU以及6個NVIDIA Tesla V100 GPU.超算中共包含約3 400個節點,采用無阻塞胖樹架構互聯,基于Mellanox Infiniband EDR實現存儲以及節點間200 Gbps的帶寬連接.在整個系統設計中,針對通信架構使用了在網計算進行加速,可以用于常見的MPI,SHMEMPGAS等通信框架,在網絡交換機上實現歸約等集合操作.
其他面向深度學習的在網計算方法包括:網卡類計算卸載,例如Mellanox ConnectX(NIC),Cary Aries NIC,IBM BlueGene系列等;交換機類計算卸載,例如G-Net Switch,Mellanox SwitchIB-2,P4 Switch等.其中網卡類計算卸載無法減少集合操作在網絡中的流量,僅能替代CPU或GPU完成All-Reduce中的求和工作;而交換機類計算卸載既可以實現All-Reduce過程中的計算任務,又可以減少鏈路聚合從而緩解網絡擁塞.
使用在網計算等專用系統設計可以從物理層面直接改善分布式深度學習中網絡擁塞的問題,是一種高效且擴展性強的方案,其缺點是需要專用的硬件和配套軟件,具有較高成本.
2.2.10 減小通信占比
在典型神經網絡的網絡層中,主要分為卷積層、激活函數、池化層和全連接層等類型,其中涉及到大量參數和計算的有卷積層和全連接層.由于卷積層每層的參數只有若干個卷積核,并且全連接層2層之間所有神經元都有連接,故而全連接層的參數量遠遠大于卷積層.
以VGG-16[64]為例,Conv1-1,輸入為224×224×3,64個3×3 filter,輸出feature map為224×224×64,其參數量為3×3×3×64=1728.同理Conv2-1,輸入為224×224×64,128個3×3 filter,輸出feature map為112×112×128,Conv2-1的參數量3×3×64×128=73 728.而對于全連接層來說,VGG-16的第一個全連接層中,最后一次卷積得到的feature map為7×7×512,展開成一維向量為1×4 096,因此其參數量為7×7×512×4 096=102 760 448個參數.因為分布式訓練過程中通信的主要內容就是參數或參數的梯度同步,因此全連接層占比多的網絡,其通信計算比就更大,更容易因為通信問題造成瓶頸.
故而在選擇和優化神經網絡時,選擇卷積層比例多而全連接層比例少的網絡可以更有效地減少通信占比.常見的神經網絡及其計算量(GFLOPs)和參數量(即通信量)統計如表1所示:

Table 1 Parameters for Common Neural Networks
通過減小通信占比來優化通信時間是一種被動的優化方法,因為研究人員通常是以數據為驅動的而不是以性能為驅動的.因此,只有在一些極端情況例如終端計算時,才會采用這樣被動的優化方案,例如在低功耗設備上等,通過縮減模型同時盡可能保證結果精確度.
2.3 關于文件傳輸的優化
關于分布式深度學習中關于文件傳輸、數據供應的優化,相關的研究并不多.主要有2方面原因:
1) 并非所有應用都會使數據存儲面臨瓶頸.對于一些標準數據集而言,其數據集大小是有限的.例如ImageNet標準集,其大小在150 GB左右.對于分布式訓練來說,完全可以做到每個節點都拷貝一份數據存放在本地使用.
2) 并非所有的集群架構都存在存儲瓶頸.某些集群架構中將存儲做成了集中存儲的存儲池,并且擁有專門的網絡線路來支撐數據傳輸,這樣無論訓練數據有多大,都不會達到集中存儲池的上限.此外某些集群還針對文件傳輸建立了一套獨立的網絡用來傳輸數據,大大降低了文件傳輸對通信網絡的干擾.
需要著重對文件傳輸進行優化的場景主要是超大數據(一般是非傳統數據集)用于深度學習的訓練過程.例如在文獻[65]中,訓練數據達到了3.5 TB,這不僅對存儲帶來了壓力,對數據的傳輸也帶來了巨大壓力.由于深度學習中并不需要每個節點都使用全部的數據,只需要在一個Epoch過程中,所有節點共計使用過一次全部數據即可.故而文獻[65]提出一種分布式文件分級系統,將文件劃分為多段,供不同的節點訓練使用.同時每個節點使用多線程并行讀取數據,使用8線程時將數據讀取速度提高了6.7倍.該文使用這種方法,可以實現在3 min內完成在summit上對1 024個節點的數據供應,以及7 min對4 500個節點的數據供應.
總體來說,關于文件存儲、傳輸等是一項與實際使用相關性很高的工作.針對其優化更適合在實際系統中遇到實際問題后按需解決,目前還沒有成熟通用的在分布式深度學習訓練中分布式供應數據的系統.
2.4 目前超大規模訓練實例
2.4.1 傳統數據集訓練
本節詳細介紹目前已有的若干分布式深度學習的超大規模訓練實例,分析它們的規模以及如何保證超大規模下的通信性能.
在這些訓練實例中,最常用的性能測試集是使用ResNet-50訓練ImageNet數據集.ResNet在2015年被提出,在ImageNet比賽中獲得了分類任務的第1名,并運用在檢測、分隔和識別等諸多領域,Alpha zero中也使用了ResNet,是目前最常使用的一種CNN網絡.使用一塊NVIDIA M40 GPU和ResNet-50訓練ImageNet訓練集,訓練90個Epoch的完整過程需要1018個單精度浮點操作,需要花費約14天.
文獻[66]基于256個GPU實現了1 h內完成訓練ImageNetResNet-50的成績.實驗中使用了以Facebook’s Big Basin[67]為主的GPU服務器.每個服務器含有8個NVIDIA Tesla P100 GPU,相互之間采用NVLink連接,其每臺服務器本地有高達3.2 TB的SSD硬盤,網絡連接使用Mellanox ConnectX-4 50 Gbps的以太網卡和Wedge100以太網交換機.在軟件方面使用了Caffe2作為訓練框架,Gloo作為通信框架.該實驗具備了優秀的硬件設施系統,而沒有針對分布式訓練做其他方面的性能優化.實驗結果表明,在使用256GPU(32機)時,其單卡效率可以達到8GPU(1機)的約90%.
文獻[68]中使用1 024個GPU完成了15 min使用ResNet-50訓練ImageNet的成績.其使用Preferred Networks提供的MN-1 cluster,包含128個節點,每個節點包含2個Intel Xeon E5-2667 CPU、256 GB內存和8個NVIDIA Tesla P100 GPU,節點間使用Mellanox Infiniband FDR實現互聯.在軟件方面其使用了ChainerChainerMN作為訓練框架,NCCL和Open MPI作為通信庫,亮點在于通信時使用了半精度浮點數來減少通信量.
索尼公司在文獻[70]中實現了224 s訓練ImageNetResNet-50的成績.其使用了ABCI cluster,包含1 088個節點,每個節點含有4塊NVIDIA Tesla V100 GPU、2個Xeon Gold 6148 CPU和376 GB內存.節點內GPU使用NVLink2連接,節點間使用InfiniBand EDR實現互聯.軟件方面其使用了Neural Network Libraries(NNL)作為訓練框架,NCCL和OpenMPI作為通信庫.亮點在于使用了2D-Torus的改善All-Reduce方法,降低了普通Ring All-Reduce的延遲.
除了使用GPU集群實現的訓練,也有使用超算CPU資源實現的分布式深度學習訓練.CPU相比GPU并行計算能力更弱,因此需要更多核心的并行計算才能達到相同效果,這增加了分布式的節點數,對通信過程帶來更多的挑戰.例如文獻[71]中使用2 048個Intel Xeon Platinum 8160處理器,訓練90個Epoch的ImageNetResNet-50花銷20 min,64個Epoch時花費14 min,但是在文章中沒有對性能做針對性優化.
總的來說,在傳統數據集的超大規模訓練上,目前已經基本做到了性能的極限水平.在利用目前最先進的顯卡、網絡設備等支持下,訓練完整的90個Epoch ImageNetResNet-50只需要不到4 min的時間.
2.4.2 非傳統數據集訓練
目前越來越多的新型超算開始采用GPU集群架構,因此也越發適用于超大規模分布式深度學習任務.這使得某些傳統超算任務可以與深度學習建立聯系,使用深度學習的方法來達到更好的效果.
文獻[65]中使用超算集群來實現氣候分析.其在Piz Daint集群中利用Tiramisu網絡,使用5 300塊P100 GPU,達到了21.0PFs的吞吐率和79.0%的并行效率;另外其在Summit集群中利用DeepLabv3+網絡,使用27 360塊V100 GPU,達到了325.8PFs的吞吐率和90.7%的并行效率.
AlphaGo[72]圍棋AI程序早期使用176個GPU的分布式系統來實現版本AlphaGo Fan的訓練.后來在AlphaGo Lee中使用48個TPU的分布式訓練來實現圍棋AI的訓練.直到最新的AlphaGo Zero,才開始使用單機4TPU的結構來降低功耗.
總的來說,深度學習在非傳統應用如圖像、音頻和自然語言處理等方面處于剛剛起步的狀態,隨著未來深度學習的發展以及行業的需求,非傳統應用會越來越廣泛.
3 未來的研究問題與挑戰
隨著深度學習技術的不斷進步,未來越來越多的應用會使用深度學習算法.對于某些超大型的數據集和計算任務,分布式深度學習提供了良好的解決方案.在超算領域,分布式深度學習為傳統計算任務提供了新的解決思路,改善了傳統模型的準確性.
目前針對分布式深度學習的性能優化有諸多方法,如何將這些方法利用在訓練環境中,并緩解性能瓶頸成為一個挑戰.常見的優化方案及其優缺點總結如表2所示.
我們根據目前各優化方案的研究及其成果對表2的10種方案做出關于成熟度的分類.其中較為成熟可靠的方案有:改善網絡硬件資源、采用All-Reduce集合通信、增加并行度、改善同步通信算法、使用張量融合技術;而使用異步通信、量化壓縮與稀疏化壓縮、與拓撲相關的網絡優化、專用系統設計、減小通信占比等方案目前仍處于研究初期或存在較大的缺陷.
盡管目前針對分布式深度學習訓練的性能優化方法有很多,但是目前已有的科研方案中各系統展現了很強的獨立性,各系統采用了不同的優化方案并實現了不同的性能效果.研究之間相互沒有統一性.最主要的原因是由于目前的優化方案不完全成熟,訓練環境差異大,因而未來分布式深度學習仍然面臨諸多挑戰.
展望未來,分布式深度學習性能優化方面具體面臨的困難總結為6點:
1) 對于目前分布式深度學習訓練的推廣,缺乏一套綜合性設計方案.目前已有的深度學習框架、通信框架、通信算法、硬件資源等種類眾多,卻沒有保障分布式的性能,以及使用便利性.因此應該利用相對完善的優化方案,形成系統的深度學習框架系統和性能評測系統,設計出一套在絕大多數環境場景下都能保證分布式訓練性能的系統方案.實現一套綜合性設計方案可以使得廣大用戶、中小型公司與科研單位充分利用分布式加速的好處,是目前分布式深度學習普及的重中之重.

Table 2 Comparison for the 10 Optimization Methods
2) 缺乏針對其他典型環境下的設計方案.除去綜合性的設計方案之外,應該對于各典型環境針對其特點做出常用的系統方案.目前常見的分布式深度學習訓練環境主要有:小型局域網、云計算環境、超算環境、私有集群等.其中不同環境在網絡帶寬、用戶數、穩定性、計算節點數等有顯著的不同,因此對于各典型的訓練環境來說應該采用針對其特點采用不同的優化策略,形成不同的優化設計方案.該方案可以在綜合性系統之上保證分布式訓練在各環境中性能進一步提升.
3) 缺乏已有算法綜合性的性能比較.目前各系統及其優化方案獨立性強,相關的比較研究較為匱乏,因此目前還沒有綜合性的優化算法性能比較.因此在針對環境進行優化設計時,需要將所有算法都進行實驗,這加大了系統設計的復雜程度以及時間成本.
4) 一部分新優化算法不夠成熟,需要進一步研究.表2中優化方案中一部分算法仍處于研究的初始階段,例如與拓撲相關的網絡優化方案;也有目前為止存在很多問題的優化方案,例如稀疏化壓縮等;也有一些無法或不便于大規模推廣,例如專用系統設計等.因此需要繼續改善這些優化方法或提出新的算法,這必然是一個需要研究積淀的長期過程.
5) 缺乏對于極端環境的容錯、冗余方案.目前研究實例中的實現方案大多處在理想的實驗環境中,例如不存在多用戶的干擾,大規模訓練中也不需要考慮服務器宕機等情況.而實際生產實驗環境中,環境要更加復雜,會出現各種各樣的問題導致分布式訓練性能降低、中斷等.因此如何實現對于復雜、極端環境的容忍,多機訓練任務中斷的恢復、多機任務的管理等成為一個挑戰.
6) 缺乏算法參數選擇機制的研究.目前已有的性能優化方案中通常涉及到多參數、多算法等問題,而現有實現主要是根據實驗中的實驗數據和結果人工調整參數以達到最佳性能效果.然而不同的參數對于不同的環境來說通常是不通用的,因此使用實驗中的參數不一定能達到最優的性能效果,需要重新實驗來確定參數.這對于非研究人員來說是一個繁瑣的過程,增加了訓練的時間和精力成本.因此如何確定一個相對更通用的參數或如何實現自動選擇參數將成為未來研究的挑戰.
由于近些年來貿易戰等政策原因,國外針對我國技術封鎖越來越嚴重,未來我國需要在深度學習方面多做技術與科研儲備.
目前來說,國內的深度學習發展主要分為2方面,一方面是由普通高校、研究所等科研人員針對算法應用層面不斷研究;另一方面是由國內頂尖IT企業、AI公司和較有實力的科研單位從底層系統到上層算法的全方面研究.其中前者由于近些年來深度學習的火熱程度,國內研究投入力度大,取得成果在國際上也處于領先水平;而后者由于國內在深度學習領域起步相對歐美國家晚,在底層架構、性能優化等方面基礎相對薄弱.
分布式深度學習作為未來深度學習擴展性能的重要方法,必然會得到越來越多的重視.例如現代超算集群中,越來越多支持GPU集群計算用于支持深度學習.國內在系統結構方面相對較弱,而在新型計算結構(例如GPU)等積累更少.未來應該重視自主研究的計算器件、深度學習框架,多做研究實踐積累和市場推廣,利用市場效應帶動應用推廣,從而實現良性循環.未來國內理想的超算環境應該部署自己的向量計算加速器、使用自產神經網絡框架,甚至在專用網絡器件等設備中也實現國產化.
針對短期內的性能優化,應該著重分析目前主要分布式環境,可以構建基礎數學模型,對環境進行模擬和測試,分析不同環境下分布式訓練時可能會遇到的問題以及可能使用哪些優化方案來解決,分析出主要環境的特點以及相對通用的分布式優化方案;設計出一套相對智能的分布式深度學習框架,可以通過測試不同環境下的通信、計算等特征從而自動選擇可行的優化策略,使得不同用戶在不同環境下都能取得較好的分布式加速性能.
針對長期的性能優化工作,一方面應該繼續對各類優化算法進行研究,改善目前已有優化算法的不足,提出新的算法,以及進行實際系統中算法間的性能比較;另一方面應該加大在底層硬件例如低功耗向量加速器件、網絡通信設備、專用加速器件等研發生產,不斷改善底層軟件框架例如深度學習框架、通信庫等使之愈發成熟.
總體來說,分布式深度學習還處于發展的初始階段.目前絕大多數的深度學習訓練還是處于單機訓練的階段.但是隨著未來更多應用的需求,深度學習對算力的要求越來越高,分布式深度學習會得到越來越多的關注.而分布式深度學習的性能優化是維持分布式訓練加速不可或缺的重要手段,未來在分布式訓練中必然起到至關重要的作用.
4 總 結
分布式深度學習突破了單機訓練的算力瓶頸,為未來深度學習的發展提供了充足的算力支撐,可以為未來相關應用的發展打下重要基礎.然而分布式訓練中會由于通信等問題造成性能瓶頸,因此關于分布式深度學習的性能優化顯得尤為重要.本文闡述了分布式深度學習發展中可能遇到的問題與挑戰,分析了當前網絡通信性能中制約分布式訓練的主要因素,總結和對比了10種優化分布式深度學習網絡性能的方案,最后針對未來分布式深度學習研究提出6個研究挑戰與未來方向.
我們認為未來分布式深度學習將得到更廣泛的應用,針對分布式深度學習的具體優化方案會更加完善.在未來常用的環境中有更成熟、完善的方案來支撐分布式深度學習應用的發展.未來值得我們進一步探討在分布式深度學習中引入各類性能優化技術.
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
