基于BP神經(jīng)網(wǎng)絡的300 MW循環(huán)流化床機組出力預測
2021-01-09 01:48:56韓義張奇月王研凱于英利付旭晨榮俊段倫博
綜合智慧能源 2020年12期
關鍵詞:模型
韓義,張奇月,王研凱,于英利,付旭晨,榮俊,段倫博*
(1.內(nèi)蒙古電力(集團)有限責任公司內(nèi)蒙古電力科學研究院分公司,呼和浩特010020;2.東南大學能源熱轉換及其過程測控教育部重點實驗室,南京210096)
0 引言
蒙西電網(wǎng)[1]網(wǎng)架結構復雜、駕馭難度大,電網(wǎng)統(tǒng)調裝機6.599 GW,500 kV 變電站26 座,220 kV 變電站146 座,110 kV 及以下變電站932 座,系統(tǒng)較復雜;承擔大量的西電東送、蒙電外送任務,若大量負荷不就近消納,將對關鍵線路造成巨大壓力。因此,為了便于電網(wǎng)做出更好的調度安排,保證電網(wǎng)穩(wěn)定運行,進行出力預測變得尤為重要。
隨著機器學習技術的不斷進步,各種行業(yè)均開始應用機器學習來解決實際問題,通過大數(shù)據(jù)技術解決傳統(tǒng)數(shù)據(jù)解決不了的問題。與傳統(tǒng)數(shù)據(jù)相比,大數(shù)據(jù)在數(shù)量、多樣化、價值以及更新速度上具有明顯的優(yōu)勢[2]。隨著分散控制系統(tǒng)(DCS)、廠級實時監(jiān)控信息系統(tǒng)(SIS)、管理信息系統(tǒng)(MIS)以及其他輔助控制系統(tǒng)[3]的廣泛應用及不斷改進,各電廠及電力集團公司存儲了大量的運行數(shù)據(jù)及化驗數(shù)據(jù),形成了覆蓋電站機組生產(chǎn)全過程的數(shù)據(jù)庫,這些數(shù)據(jù)包含大量的隱含信息,以數(shù)據(jù)為中心的信息化理念將極大地變革電力信息化方式[4-8]。
煤質變化等原因造成機的組出力不穩(wěn)定不利于電網(wǎng)調度。因此,提供合適的出力預測方案可以方便電網(wǎng)做出合適的調度安排,避免不必要的風險。基于從頭計算的機組負荷預測自然可以有較高的準確性,但其需要輸入的參數(shù)太多,且大多不能在線測量。以本文研究的循環(huán)流化床機組為例,如果通過在線測量煤質、飛灰含碳量等參數(shù)來準確計算鍋爐熱效率,自然可以實現(xiàn)負荷的預測,但是技術難度大且計算量可觀,難以實現(xiàn)實時應用。如果采用大數(shù)據(jù)理論,則可以避免直接測量這些數(shù)據(jù),直接尋找關鍵參數(shù)和機組出力的關系。同時,通過這一關系,也能反饋機組出力對關鍵參數(shù)的范圍要求,從而界定機組的邊界出力。
徐游波[9]提出汽輪機的運行狀態(tài)隨著蒸汽流量、溫度及壓力等因素的變化而變化,通過對歷史運行數(shù)據(jù)的分析,得出機組出力與主蒸汽流量大致成正比例變化趨勢的結論。通過擬合機組出力與主汽流量的關系計算出力,實現(xiàn)汽輪機側基于歷史運行數(shù)據(jù)的機組負荷預測。該研究雖然可以解決出力預測問題,但隨著時間的推移,擬合函數(shù)的計算精確度會不斷降低。
本文提出通過搭建BP 神經(jīng)網(wǎng)絡模型并利用大數(shù)據(jù)來進行出力預測。利用滑動窗口法,當有新的數(shù)據(jù)樣本進入模型時,直接剔除最舊樣本,更新模型參數(shù),解決了隨著機組的狀態(tài)改變,原有模型的準確性和精度降低、泛化性能下降的缺點[10-12]。相比于模型重構,大大減少了計算量及模型更新所用時間。本文以相關參數(shù)數(shù)據(jù)為網(wǎng)絡的輸入層,以機組出力為輸出層,訓練網(wǎng)絡模型,通過調節(jié)相關參數(shù)值進行仿真試驗,最后得到最優(yōu)網(wǎng)絡模型。
1 研究方法
1.1 研究對象
本文針對某300 MW 循環(huán)流化床機組,該機組鍋爐為單汽包、自然循環(huán)、循環(huán)流化床燃燒方式,由1個膜式水冷壁爐膛,3臺汽冷式旋風分離器和汽冷包墻包覆的尾部豎井組成。汽輪機為亞臨界、高中壓合缸、一次中間再熱、單軸、雙缸雙排汽、直接空冷凝汽式,配有2個主蒸汽閥門、6個高壓調節(jié)閥門、2個中壓主蒸汽閥門、2個中壓調節(jié)閥門。鍋爐設計汽水參數(shù)及汽輪機設計參數(shù)見表1—2。
選用來自此電站系統(tǒng)中存放的海量歷史數(shù)據(jù),主要包括發(fā)電機有功功率、主蒸汽流量和其他管道測點共計48 個不同參數(shù)的信息。選取了其中一段時間,每分鐘一個參數(shù)取一個數(shù)據(jù),即便只有5 d 時間,總數(shù)據(jù)量仍然十分巨大。如果要靠傳統(tǒng)的人為分析,困難系數(shù)是相當大的。以主蒸汽流量及其他相關參數(shù)為輸入,發(fā)電機有功功率為輸出,建立基于BP神經(jīng)網(wǎng)絡的機組出力預測模型,從而對機組出力進行預測。
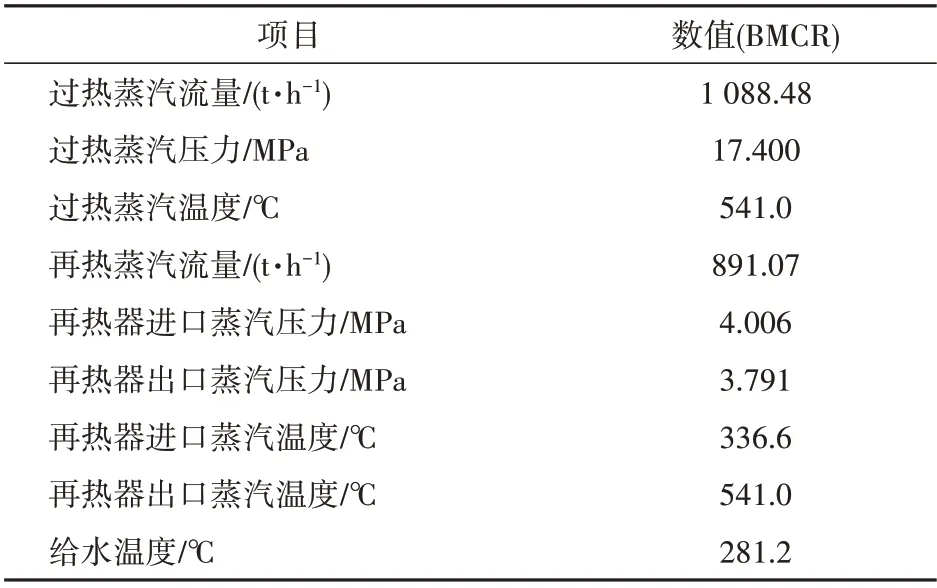
表1 鍋爐設計汽水參數(shù)Tab.1 Design steam-water parameters of the boiler
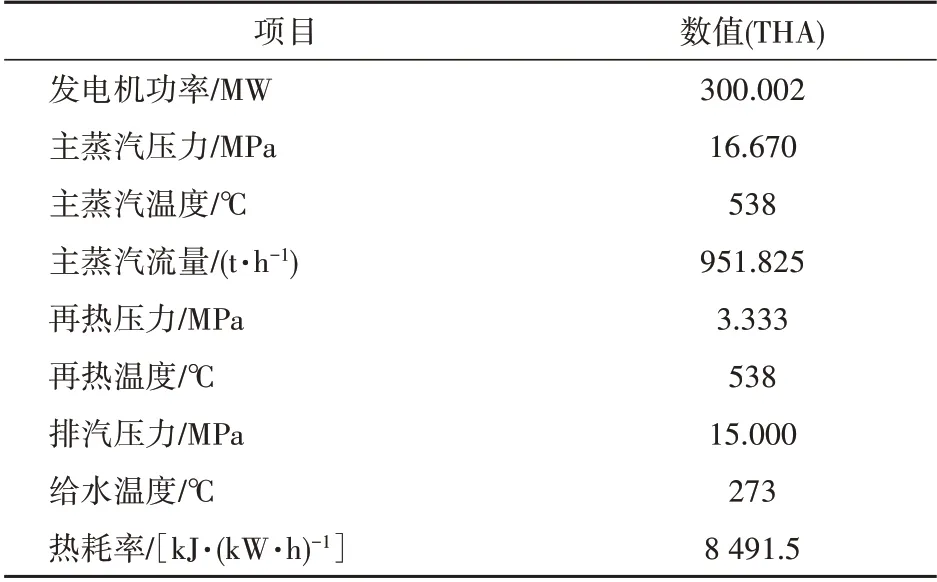
表2 汽輪機設計參數(shù)Tab.2 Design parameters of the steam turbine
1.2 BP神經(jīng)網(wǎng)絡
BP神經(jīng)網(wǎng)絡是一種多層前饋型神經(jīng)網(wǎng)絡,可以實現(xiàn)從輸入到輸出的任意非線性映射[13]。典型的BP網(wǎng)絡結構如圖1所示:輸入層具有R個輸入;隱層具有S個神經(jīng)元,采用S型傳遞函數(shù)。
隱層的非線性傳遞函數(shù)神經(jīng)元的作用為學習輸入與輸出的線性及非線性關系,由于在進行訓練之前一般都會進行數(shù)據(jù)的歸一化處理,所以一般會通過線性輸出層拓寬網(wǎng)絡輸出。BP 神經(jīng)網(wǎng)絡具有很強的非線性映射能力、高度的自學習和自適應能力、一定的容錯能力,在局部神經(jīng)元受到破壞后,對全局的訓練結果不會造成大的影響。
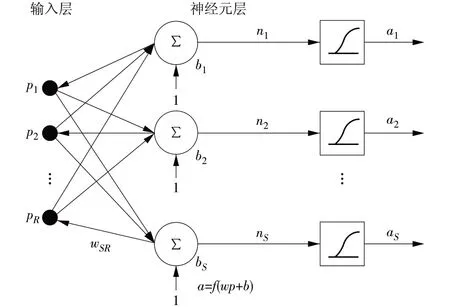
圖1 BP網(wǎng)絡結構Fig.1 BP network structure
BP神經(jīng)網(wǎng)絡在應用方面主要用于函數(shù)逼近、模式識別、分類、數(shù)據(jù)壓縮4方面。本文主要通過相應的輸入與輸出來訓練一個網(wǎng)絡以逼近一個函數(shù),達到預測出力的目的。
1.3 數(shù)據(jù)預處理方法
大型燃煤發(fā)電機組所包含的系統(tǒng)眾多,數(shù)據(jù)復雜,且大量的數(shù)據(jù)中必然存在錯誤數(shù)據(jù)。為了提高模型的精確度,對數(shù)據(jù)進行預處理是十分必要的。
1.3.1 異常數(shù)據(jù)的剔除
對于大數(shù)據(jù)建模而言,需要的數(shù)據(jù)量很大。但是,在實際的測量過程中,儀表的精確性、外界的干擾、測點的選擇、傳感器的故障等均會導致其中部分數(shù)據(jù)受到污染。如果在建模之前不對這些污染數(shù)據(jù)進行剔除,模型的精確性就會受到影響。譚浩藝[14]等人曾經(jīng)通過拉依達準則(即3σ 準則)對數(shù)據(jù)進行預處理,將明顯誤差較大的數(shù)據(jù)剔除。拉依達準則是指先假設一組檢測數(shù)據(jù)只含有隨機誤差,對其進行計算處理得到標準偏差,按一定概率確定一個區(qū)間,認為凡超過這個區(qū)間的誤差,就不屬于隨機誤差而是粗大誤差,含有該誤差的數(shù)據(jù)應予以剔除。在測量次數(shù)充分多的情況下,數(shù)據(jù)的誤差必然趨于正態(tài)分布,因此,電廠大數(shù)據(jù)剛好適合用來剔除異常數(shù)據(jù)。
1.3.2 數(shù)據(jù)的歸一化處理
該模型涉及的參數(shù)很多,不同參數(shù)之間、同參數(shù)之間的樣本數(shù)據(jù)也可能存在較大差距。例如,主蒸汽流量數(shù)值最高達到1 000 t∕h 以上,而各類換熱器進出口的蒸汽壓力數(shù)值卻只有10 MPa 左右。如果樣本數(shù)據(jù)之間的數(shù)值差距過大,神經(jīng)網(wǎng)絡模型的訓練時間會變長,訓練后的模型精準度也不夠。因此,在確定了各個參數(shù)之后,在輸入數(shù)據(jù)之前,最好對數(shù)據(jù)進行歸一化處理[15]。假設參數(shù)原值為a,歸一化處理后的值為b,同類型參數(shù)最大值為amax、最小值為amin,則兩者之間的關系用公式表示為
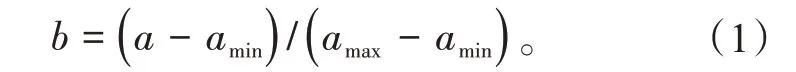
1.3.2 PCA降維
選擇合理的模型變量對于建模來說十分重要。燃煤發(fā)電機組包含眾多的子系統(tǒng),如給煤系統(tǒng)、燃燒系統(tǒng)、給水系統(tǒng)、送風系統(tǒng)等,每個子系統(tǒng)都與眾多的參數(shù)相關聯(lián)。從所有可能對機組出力有影響的參數(shù)中選出關系較為密切的特征參數(shù)作為模型的輸入量,可以獲得近似或是更好的模型性能。通常研究人員選擇模型變量都是依據(jù)長期的經(jīng)驗。然而有時候并沒有完備的理論依據(jù),如果選擇了一些不重要的自變量,模型的精度會降低。本文選用Matlab軟件中自帶的PCA降維函數(shù)對大數(shù)據(jù)進行主成分分析[16-17],在新的參數(shù)坐標下獲取每個主成分所占的影響值,直觀地選擇所需要降的維數(shù)。
2 基于BP神經(jīng)網(wǎng)絡的出力預測模型建立
2.1 BP神經(jīng)網(wǎng)絡模型建立
本研究選取了連續(xù)960 個時間點的樣本數(shù)據(jù),訓練時選取所有時間點的數(shù)據(jù),測試驗證選用后460 個時間點的數(shù)據(jù)。基于BP 神經(jīng)網(wǎng)絡的機組出力預測流程如圖2所示。
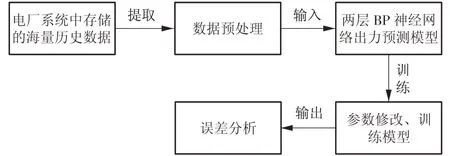
圖2 機組出力預測流程Fig.2 Flow of power unit output prediction
首先對主蒸汽流量及其他相關特征參數(shù)進行異常數(shù)據(jù)剔除、歸一化,以及降維預處理。利用PCA 函數(shù)對所有相關參數(shù)進行處理之后,可以得到輸出影響值,即每一個主成分所貢獻的比例,可以更直觀地選擇所需要降維的組數(shù)。經(jīng)過數(shù)據(jù)處理發(fā)現(xiàn)僅主汽流量所占的比例就達到了96.33%,其次依次是高溫過熱器出口蒸汽壓力、高溫過熱器出口蒸汽溫度、屏式再熱器出口蒸汽壓力、屏式再熱器出口蒸汽溫度、鍋爐給水溫度、有效床溫,分別占比1.78%,0.80%,0.37%,0.20%,0.11%,0.08%。這與徐游波[9]結論相接近。因此,綜合考慮將輸入層數(shù)據(jù)維數(shù)降到7,這樣整個影響比例之和便超過99.90%,其他因素可以忽略不計。
BP 神經(jīng)網(wǎng)絡通過誤差信號不斷反向傳播來減小輸出值與期望值的誤差,達到訓練網(wǎng)絡的目的。在該過程中,隱層神經(jīng)元數(shù)量會影響誤差大小。因此,確定BP神經(jīng)網(wǎng)絡的隱層神經(jīng)元數(shù)量很重要。神經(jīng)網(wǎng)絡預測模型一般選用均方根誤差[18-19]和相對誤差[20]作為評價指標。均方根誤差和相對誤差的計算公式如下所示

式中:RMSE 為均方根誤差,MW;ypredict為預測值,MW;yreal為期望值,MW;n為總預測時間點數(shù)。
通過統(tǒng)計各神經(jīng)元數(shù)量下BP 神經(jīng)網(wǎng)絡模型輸出值與期望輸出值的相對誤差Error 及均方根誤差RMSE,選取最合適的神經(jīng)元數(shù)量。隱層神經(jīng)元數(shù)量從1 到9 進行試驗后,輸出值與期望輸出值的平均相對誤差以及均方根誤差如圖3所示。
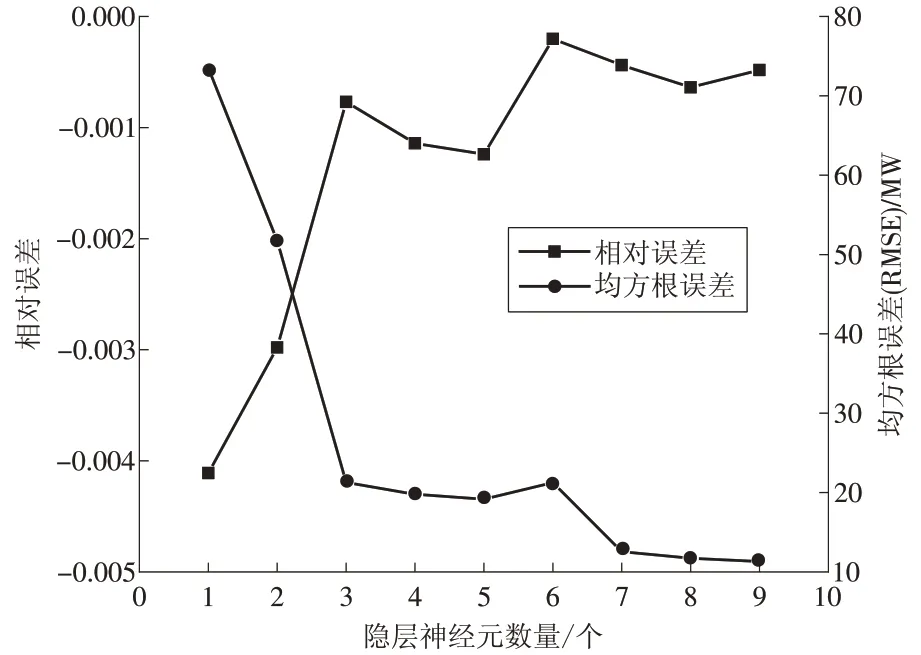
圖3 輸出值與期望值的相對誤差Fig.3 Relative error between the output value and its expected value
由圖3 中可以看出,當隱層神經(jīng)元的數(shù)量增加到7 的時候,BP 神經(jīng)網(wǎng)絡模型的輸出值與期望值的平均相對誤差低于1%,此時的均方根誤差約為13.4 MW,再增加神經(jīng)元數(shù)量模型的精確度也不會得到大的改善。因此,隱層神經(jīng)元的數(shù)量選擇為7。
2.2 BP神經(jīng)網(wǎng)絡的訓練結果分析
當隱層神經(jīng)元數(shù)量為7 時,機組出力的預測值與實際的期望值的曲線如圖4 所示,預測值與期望值的相對誤差如圖5所示。
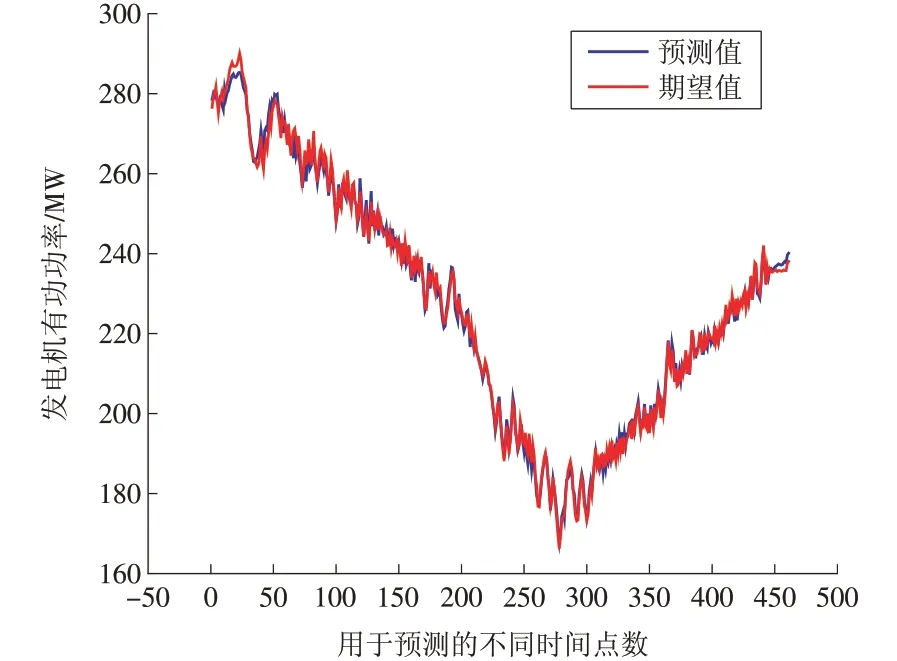
圖4 BP神經(jīng)網(wǎng)絡預測值與期望值的對比Fig.4 Comparison of the predicted value and the expected value made by BP neural network
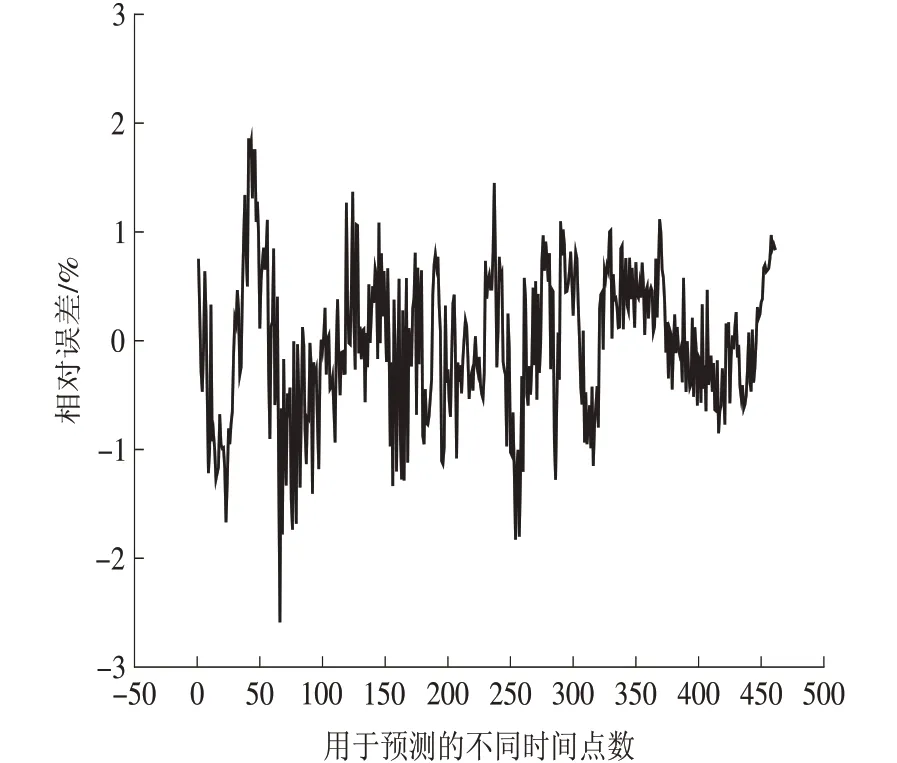
圖5 BP神經(jīng)網(wǎng)絡預測值與期望值的相對誤差Fig.5 Relative error between the predicted value and the expected value made by BP neural network
應用BP 神經(jīng)網(wǎng)絡預測模型預測得到的預測值曲線與實際的期望值曲線接近重合,驗證BP神經(jīng)網(wǎng)絡模型有良好的預測精確度。預測值與期望值的相對誤差除了極個別點以外,都在±2%的范圍內(nèi)。因此,模型的預測穩(wěn)定性也較高,可以滿足需求。
2.3 基于BP神經(jīng)網(wǎng)絡的出力預測
選用訓練數(shù)據(jù)外別的時間點的樣本數(shù)據(jù)來檢驗模型的精度,為了保證模型精度的覆蓋范圍,選用6個不同范圍的數(shù)據(jù),原始數(shù)據(jù)見表3。
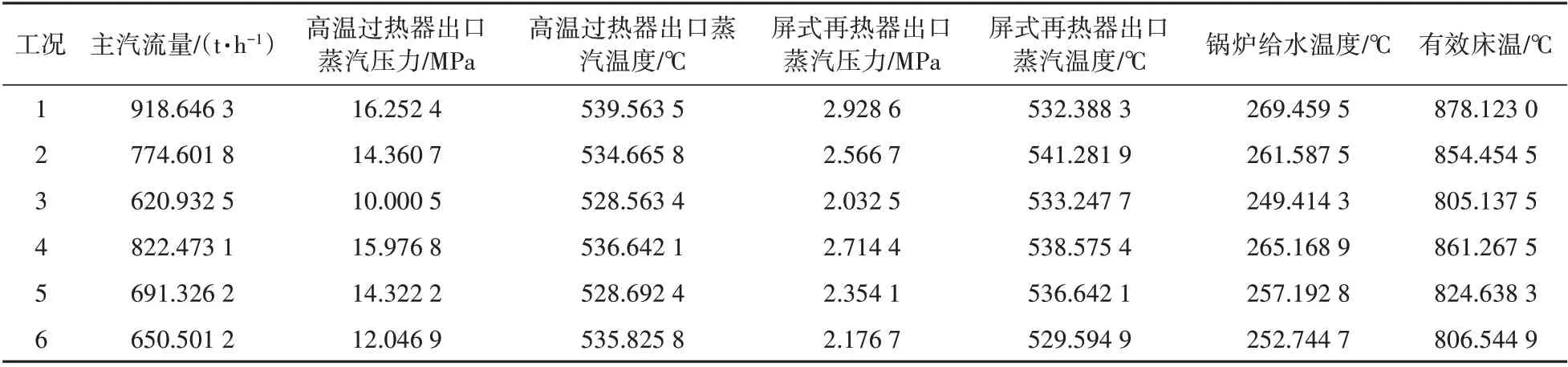
表3 BP神經(jīng)網(wǎng)絡的各項輸入值Tab.3 Inputs of the BP neural network
將下列變量作為輸入量,經(jīng)過模型預測獲得的預測值與期望值的對比見表4。經(jīng)過預測,可以發(fā)現(xiàn)誤差基本都在1%以內(nèi),模型的精度較高,值得信賴。
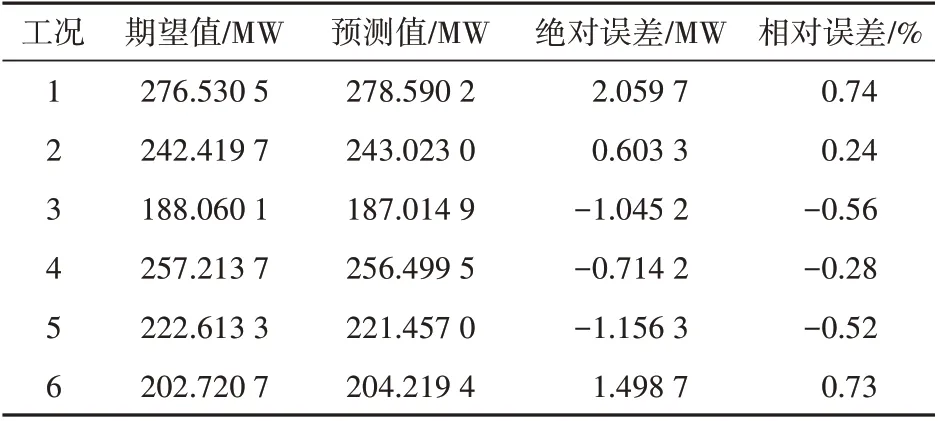
表4 預測值與期望值的對比Tab.4 Comparison of predicted and expected values
3 結論
采用BP 神經(jīng)網(wǎng)絡結合數(shù)據(jù)預處理和PCA 降維,以某300 MW 循環(huán)流化床機組為對象建立機組出力預測模型。經(jīng)過主成分分析發(fā)現(xiàn),主蒸汽流量是影響機組出力的最主要因素,其影響程度達到了96.33%。
高溫過熱器出口蒸汽壓力、高溫過熱器出口蒸汽溫度、屏式再熱器出口蒸汽壓力、屏式再熱器出口蒸汽溫度、鍋爐給水溫度、有效床溫也有一定影響,分 別 占 比1.78%,0.80%,0.37%,0.20%,0.11%,0.08%。誤差分析表明,隱層含有7 個神經(jīng)元即可達到較高的模擬精度。
利用BP 神經(jīng)網(wǎng)絡機組出力預測模型對460 個時間點的數(shù)據(jù)進行驗證試驗,結果表明,該模型與實際運行數(shù)據(jù)吻合良好,相對誤差在±2%以內(nèi),使用訓練樣本外時間點的數(shù)據(jù)進行預測,相對誤差也在±1%以內(nèi),精度較高。
該研究為循環(huán)流化床機組出力預測提供了方法。在電網(wǎng)面對電力調度問題時,通過該出力方法可以有效預測各個火電機組的出力,從而對調度提供有力指導。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數(shù)學備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數(shù)學備考)(2020年9期)2021-01-04 00:25:14
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
