基于CNN和LSTM的睡眠呼吸暫停檢測算法
2021-01-08 02:25:58劉子龍
電子科技 2021年2期
葛 靖,劉子龍
(上海理工大學 光電信息與計算機工程學院,上海200093)
近年來,睡眠呼吸暫停癥(Sleep Apnea Syndrome,SAS)越來越受到人們關注。SAS是發生在睡眠過程中的一種常見的睡眠障礙,一般由上氣道塌陷或其他氣道阻塞引起的呼吸氣流減少或消失且反復發作引起。據研究表明,SAS可能導致多種疾病,如糖尿病、慢性腎病、抑郁癥等,嚴重的甚至會導致猝死。通常來講,最好的睡眠呼吸暫停篩查和診斷方法為多導睡眠圖(Poly Somno Graphy,PSG),但獲取PSG需要病患夜間在醫院進行睡眠監測并記錄各種生理信號,不僅操作不便,且成本較高[1]。
研究人員已經提出多種使用較少生理信號的檢測方法來簡化呼吸事件自動檢測,這在一定程度上克服了PSG的缺點。這些方法多基于生理記錄,例如心電信號(Electro Cardio Graph,ECG)、血氧飽和度、鼾聲,呼吸信號等[2]。目前大多數替代研究都集中在從生理信號中提取時間特征、光譜特征和非線性特征,以及各種特征選擇方法。傳統機器學習分類方法的人工特征識別能力較好,特別是許多監督學習方法如支持向量機和神經網絡等,已被廣泛應用于SAS檢測。
深度學習方法在近幾年逐漸受到人們的青睞,它們在各領域應用中表現出優異的性能。傳統的分類學習方法在睡眠呼吸紊亂事件的自動檢測方面取得了較高的性能,但手動特征提取仍需要相關專業知識且勞動強度大。深度學習無需使用任何領域知識即可自動從輸入信號中學習并查找特征,有著強大的學習能力[3]。
本文選用單導聯心電信號來進行睡眠呼吸暫停綜合癥的檢測。心電信號易受到SAS事件的影響,其檢測也相對普及,可由各種可穿戴設備精準測量。本研究選擇使用卷積網絡(Convolutional Neural Networks,CNN)和長短時記憶模型(Long-Short Term Memory,LSTM)來進行呼吸暫停事件的檢測。
1 材料和方法
1.1 數據集獲取
本研究中用于分析的心電信號均來自于的Physionet Apnea-ECG數據庫。醫學專家對該數據集做了專門的標注信息,具有較強的權威性。每個記錄都帶有一組參考呼吸暫停注釋,注釋記錄每分鐘內呼吸的狀態。這是專家根據同時記錄的相關信號得出的,并提供總呼吸暫停低通氣指數。
該數據庫分為訓練集和測試集,采樣頻率為100 Hz,每組包含35條患者數據記錄,每條記錄具有大約8個小時的ECG數據。本實驗共有32位受試者,包括男性25位、女性7位。受試者年齡在27~63歲之間,體重在53~135 kg之間。“N”和“A”是專家標記的注釋(A代表呼吸暫停,N代表非呼吸暫停)[4]。
1.2 數據預處理及標注
如圖1所示,信號預處理分為兩個階段。第一階段主要任務為去除ECG記錄中的噪聲。從數據集得到的信號存在多種干擾等,如基線漂移、工頻干擾等。為了保證噪聲心電分類的準確率,需要對噪聲進行處理。首先,ECG信號通過60 Hz的陷波濾波器濾波;然后使用截止頻率分別為5 Hz和35 Hz的帶通二階ButterWorth濾波器濾波。每個樣本為1 min的ECG信號,劃分好相應的訓練集和測試集,處理后的ECG信號作為卷積模型的輸入。
第二階段從每段ECG信號中提取了RR間隔和ECG派生呼吸(ECG Derived Respiration,EDR)信號。由數據集注釋信息得到每段ECG信號的R波發生時間,由此得到RR間期信息和EDR信號。EDR信號的獲得經過以下步驟:先濾波后的心電信號進行樣板插值,根據R波峰的幅度變化得到R波的幅度調制信號;然后經過平滑處理和下采樣得到EDR信號[5];最終根據數據集注釋信息和處理好的ECG信號,得到數據集每60 s的ECG信號的間接特征。RR間期和EDR信號。此外,還需從數據集注釋中選取部分與SAS事件有關的其他特征,例如年齡、性別、身體質量指數等。

圖1 數據處理流程圖Figure 1. Flow chart of data process
完成所有數據預處理程序后,第一、二階段的信號分別作為兩個模型的輸入。
1.3 網絡模型設計
CNN與LSTM的選擇參考雙方的優點:CNN模型優點是自動進行特征提取,處理高維數據無壓力,在處理初始ECG信號有很好的優勢,且在多份SAS研究文獻中顯示達到較好的檢測效果;LSTM模型具有時序記憶優點,但時間跨度很大時,序列過長會使得準確率下降,無法有效解決梯度問題。所以原ECG信號(6 000×1)作輸入時無法發揮它的優點。當把ECG派生特征R-R間期當作輸入,則大幅降低了數據量。在時序上,ECG信號是有一定的聯系的,例如心率變異性(Heart Rate Variability,HRV)是由兩個相鄰的R-R間期時間長短決定的,HRV在SA事件上存在變化[6]。LSTM在時序上的特征提取在本文目標上相對優于CNN空間特征提取。
1.3.1 CNN模型
使用一維CNN對時間序列心電信號進行分類,可無需進行任何手動特征提取和后處理,即通過適當的訓練,卷積層即可學習提取特定于患者的特征。CNN層由1個卷積層、池化層和隱藏層組成。通過卷積運算輸出特征圖,卷積層為這些層學習激活輸入信號中特定模式的濾波器(內核)。內核在輸入信號上滑動時與輸入信號卷積。通過卷積運算輸出特征圖,一維卷積層的第i個神經元輸出如下
(1)
式中,b為偏置;f為卷積層的激活函數;m為卷積核的個數;xi為輸入的序列;wj為卷積核的權重矩陣[7]。

圖2 卷積網絡模型結構Figure 2. Architectures of CNN model
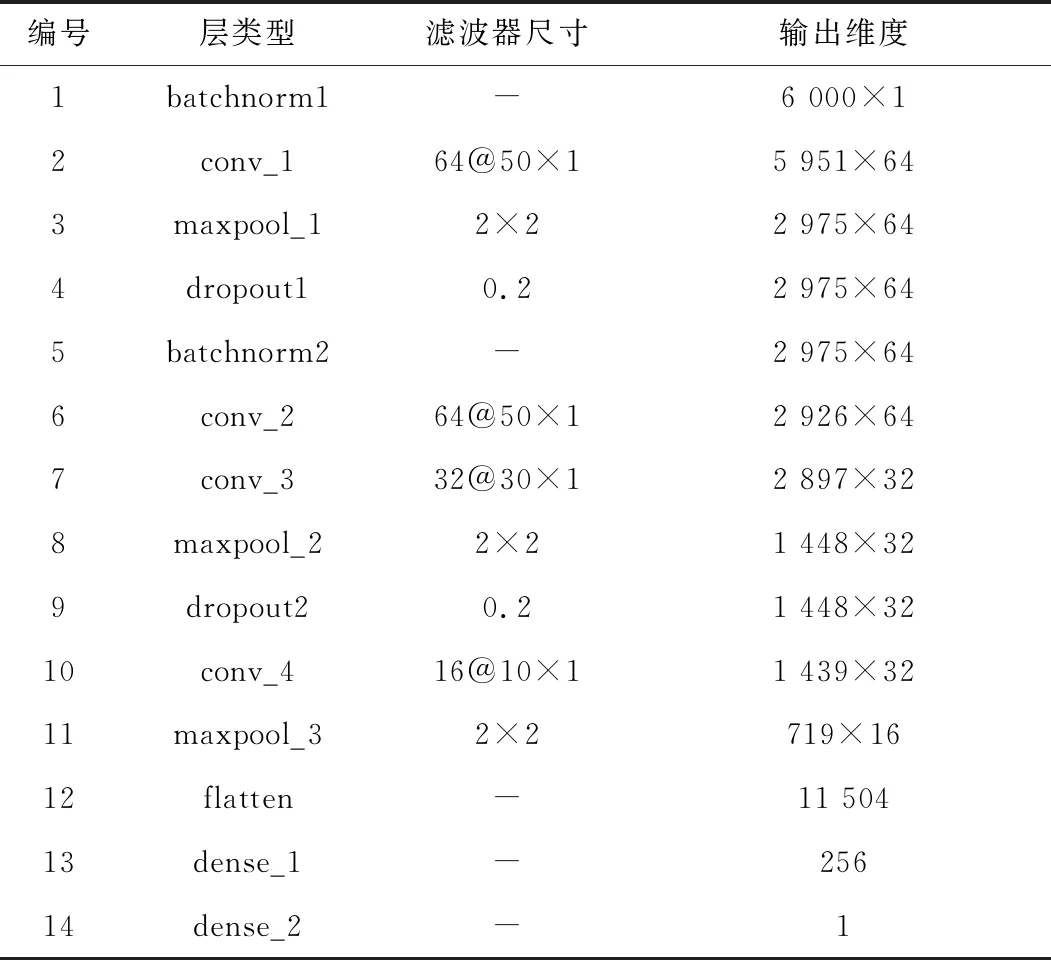
表3表1 CNN模型的網絡配置Table 1. Network configuration of CNN model
用于本研究的一維CNN的模型結構如圖2所示。CNN模型將預處理后的心電段作為輸入,每個樣本6 000點(60 s×100 Hz),輸入層的維度是 6 000 × 1。Relu被用作激活函數,每個卷積后都有一個激活函數,并且通過卷積層之間的池化層對特征進行壓縮,簡化網絡復雜度。在卷積前進行一個BN層來標準化參數,每個池化層之后都進行一個Dropout來防止過擬合[8]。最終通過一層全連接層結合sigmoid激活函數輸出預測結果。
從表1看到的模型參數將3種內核大小應用于卷積層50×1、30×1、10×1。卷積層的內核大小從第一個逐漸減小到最后一個。當所有內核尺寸都太小或統一大時,則會提取不必要的特征或丟失主要特征以降低識別率。
1.3.2 LSTM模型
LSTM屬于循環神經網絡(Recurrent Neural Network,RNN)的一種改良,方便學習時間相關性的數據隨著時間的推移。LSTM基于一個內存單元,通過輸入門處理其內部狀態的讀、寫和重置功能(it),此外還有輸出門(ot)和遺忘門(ft)。每個門的工作是記住何時以及在多大程度上應該更新內存中的權重。遺忘門處理單元的內部狀態,其自適應地忘記或重置單元的內存。這些門的功能如以下表達式所示。
it=σ(Wxixt+Whiht-1+bi)
(2)
ft=σ(Wxfxt+Whfht-1+bf)
(3)
ot=σ(Wxoxt+Whoht-1+bo)
(4)
gt=σ(Wxcxt+Whcht-1+bc)
(5)
ct=ft·ct-1+it·gt
(6)
ht=ot·φ(ct)
(7)
其中,c是細胞激活載體;σ是非線性雙曲正切函數;xt是在時間t到存儲單元層的輸入;W是權重矩陣;bi、bf、bc、bo是偏置量。
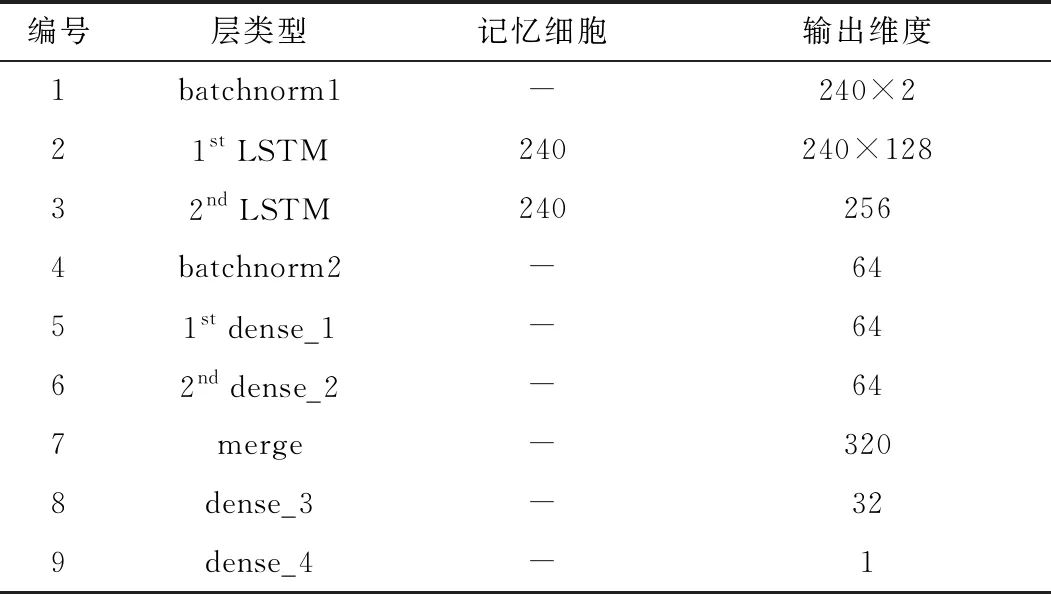
表2 LSTM模型的網絡配置Table 2. Network configuration of LSTM model

圖3 LSTM模型結構Figure 3. Architecture of LSTM model
首先把經過第二階段處理的ECG間接信號作為Input1,通過LSTM 層提取時序特征;接著把每段信號的其他醫療信息年齡性別等作為Input2,設計一個LSTM和FC的組合模型,兩個結構并行;最后通過融合(Merge)層連接輸出。考慮到輸入數據的尺寸不同,先加入批歸一化(Batch Normalization,BN)層對數據標準化,即減去平均值并除以每個值周期的標準差來對信號進行歸一化。如果不進行標準化,則數據分析的結果將受到要素的不同尺寸單位的影響。在以上兩個深度學習模型中,歸一化用于在0和1之間轉換數據;最后對所有模型進行訓練,直到過度擬合開始發生。根據模型的訓練情況一步步對超參數進行調整,不斷優化模型。如果驗證損失在長時期內沒有得到改善,則停止訓練,并將權重恢復為在驗證集中達到最佳性能的值。
2 實驗結果與分析
2.1 實驗設備
本文使用Tensorflow為后端的Keras和Python3.6來實現深度學習方法。Keras是一個深度學習庫,用于構建和評估設計的深度學習方法。每種方法的培訓和測試都是在Win10環境中使用GTX1050Ti的硬件規范進行的。深度學習方法的訓練完全由反向傳播算法監督。基于ADAM更新規則,通過最小化交叉熵損失函數對模型參數進行優化,將數據分割為256個數據段的小批,以優化培訓和測試過程。在對每個小批進行訓練之后,使用此配置計算一個累積梯度。
2.2 實驗結果與分析
本文有3類評價指標:準確率(Accuracy)為被正確分類的樣本所占的比例;精準率(Precision)是預測出來為正樣本的結果中,有多少是正確分類;召回率(Recall)為所有正例中被正確分類的比例,衡量了模型對正例樣本的識別能力
Recall=TP/TP+FN
(8)
Precision=TP/TP+FP
(9)
Accuracy=TP+TN/TP+TN+FP+FN
(10)
其中,TP、TN、、FP和FN分別代表“真陽性”、“ 真陰性”、“ 假陽性”和“假陰性”。

表3 CNN模型和LSTM模型的評價性能
由表3可以看出,LSTM優于CNN模型。CNN模型使用原始ECG信號作為輸入,指標分別為 75.3%、78.1%、80.7%;而LSTM模型的指標分別達到 87.4%,84.2%,85.5%,在ECG長時序分段上從衍生信號自動提取特征更具有優勢。
從表4可知,本文方法的性能具有一定的優越性。文獻[19]使用了隱馬爾可夫和DNN模型,指標分別為84.7%、88.9%、82.1%,精準率和本文相近,準確率上本文較優。文獻[4]使用傳統的SVM達到了91.29%的準確度和89.84%的靈敏度,但其在信號處理上過于復雜繁瑣。特征的提取多達十幾種,涉及到了信號的時域、頻域和非線性特征的特征集。而基于LSTM的方法準確度盡管低于SVM傳統分類方法,但仍具有較好的性能,并結合了人工特征提取和LSTM的模型優點,相比傳統機器學習分類方法更為簡便,有作為呼吸暫停綜合征患者初篩手段的潛力。
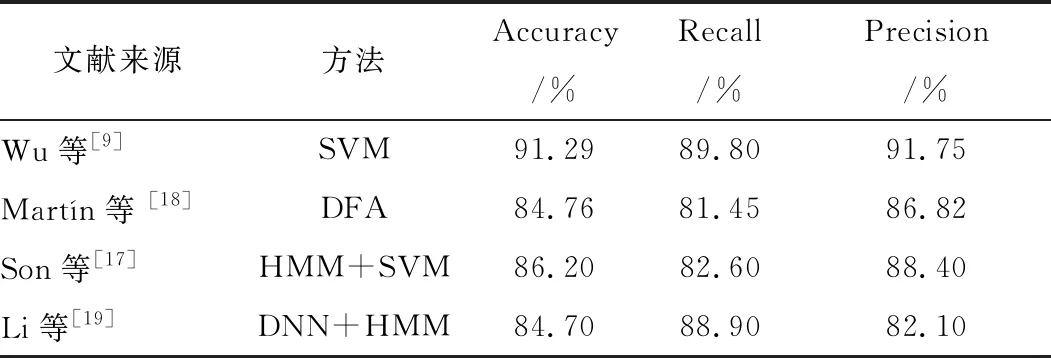
表4 與傳統方法的性能比較
本文也分析了深度學習CNN 模型的不足。在對比了其他多個使用CNN方法的文獻[8,10,12,14]后,研究者認為在輸入為原始ECG信號時,CNN相比其他模型更為適用,且相對ECG時間較短的分段效果更好,其在特征提取時會提高針對性。盡管CNN模型在本文所得精度較低,但當選用第二個模型LSTM以原始ECG信號段作為輸入時,分類效果反而不如CNN模型,存在著諸多問題如精度更低且模型訓練時間長等。使用CNN方法的研究多以原始ECG信號段作為輸入,實驗效果較好。本文的CNN模型也對其做了參照,但并未能達到其所示效果,原因可能為數據庫與處理方式不同。具體地,文獻[10]等選用的是每10 s一個樣本,本文所選的數據庫是基于60 s一次的分段標注,帶來的問題是信號數據太多,不能使卷積網絡更有針對性的提取特征,導致最終的訓練結果不太理想。
LSTM模型輸入則在原始數據集的基礎上做了二次處理,從ECG中提取了EDR信號和RR間期。它們和SAS事件的發生時序上都有著聯系,且使模型的特征提取和學習更為精準。考慮到LSTM的記憶性會得到更好的效果,故文中設計了此模型,且該模型在訓練指標上優于CNN模型。
3 結束語
本文基于輸入ECG信號的處理差異,以深度學習方法設計了相應的最優模型CNN和LSTM用于檢測呼吸暫停事件的發生。通過對比后發現,LSTM模型通過ECG衍生信號作為輸入,結合了人工特征信號提取和LSTM的優點,在長時序分段信號上從衍生信號自動提取特征更具有優勢,具有更好的效果。本文方法提高了SAS檢測的實用性、準確性,更加適用于長時序分段的心電信號。本研究的不足之處在于數據來源不夠廣泛,且模型輸入相對依賴R峰的精準檢測。在未來的工作中,可以驗證樣本ECG時間段的長短劃分是否具有對應的最優模型,并進一步擴展數據來源,優化網絡結構及參數,提高泛化能力。
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年11期)2018-08-04 03:25:42
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
