基于混合變量選擇的綠茶酚氨比近紅外光譜檢測方法
2021-01-08 02:35:54黃俊仕王冬欣熊愛華艾施榮吳瑞梅文建萍
江西農業大學學報 2020年6期
黃俊仕 ,王冬欣,熊愛華,劉 鵬,3,李 紅,艾施榮,吳瑞梅,文建萍*
(1.江西農業大學工學院,江西南昌 330045;2.婺源縣鄣公山茶葉實業有限公司,江西婺源 333200;3.江西機電職業技術學院,江西南昌 330013)
【研究意義】茶葉最早生產于我國,由于其良好的滋味口感和有益的藥用價值,深受消費者喜愛,已經成為世界三大飲料之一。隨著茶文化的推廣以及“一帶一路”等貿易政策的提出,我國茶葉生產和消費總量不斷增長,2018年國內茶葉消費總量達到200萬噸,消費總額達到2 400億元。近年來,茶葉行業不斷增加與茶葉內部有益成分相關的質量控制措施,以提高其市場價值[1]。茶多酚(tea polyphenols,TP)、氨基酸(amino acid,AA)等茶葉內部成分直接影響著茶葉滋味品質。茶多酚含量決定了茶葉滋味的醇厚,兒茶素是茶葉中最豐富的多酚類物質,在綠茶中含量很高,有一種獨特的澀味,適合大多消費者的口味[2]。氨基酸含量影響著茶葉鮮爽味,可以起到緩解澀味,增加甜味的作用[3?4]。澀味與鮮爽味的協調是茶葉滋味的關鍵,即茶葉中茶多酚與氨基酸含量比例(酚氨比)是決定茶葉滋味品質的重要指標。王海利等[3]研究表明酚氨比相對于氨基酸和茶多酚含量單一指標,能更好地反應茶葉滋味,且酚氨比與茶滋味鮮度、醇度和滋味化學總分均存在極顯著負相關性。對于茶葉品質內部成分的檢測,常采用液態色譜?串聯質譜法[5],分光光度法[6],高光譜成像技術[7]等理化方法進行分析,而這些方法存在成本高,耗時耗力,前處理復雜等缺陷,難以適應現場快速檢測需要。近紅外光譜(near infrared spectroscopy,NIR)是一種介于可見光和中紅外之間的電磁輻射,主要反映有機物中C?H,N?H,O?H等含氫基團振動的合頻、倍頻吸收光譜信息,由于該技術具有成本低、效率高、響應速度快、綠色無損等優勢,被廣泛應用于茶葉品質檢測[8?10]。近紅外光譜數據量大,不僅包含分析物相關的有用信息,也存在大量的冗余信息。當所有光譜波長信息均被用于模型建立時,將導致模型計算量大以及過擬合等問題降低模型預測性能,研究者們將這種現象稱之為“維度災難”。
【前人研究進展】針對這一問題,許多研究者利用變量選擇方法提取有效光譜特征波長,用于預測模型的建立,不僅可以提高模型的預測性能,還能提供更佳的解釋性模型。Chen等[11]利用主成分分析方法提取近紅外光譜低維特征,并結合反向傳播自適應提升算法建立8種茶葉滋味相關的內部成分預測模型,模型預測集相關系數大于0.7。Yang等[12]采用聯合區間最小二乘(synergy interval partial least square,Si?PLS)方法優選近紅外光譜變量區間,建立水泥原料主要成分(CaO、SiO2、Al2O3和Fe2O3)檢測模型,預測集相關系數達到0.729 4~0.930 4,平均預測誤差為0.03%~0.13%。然而,即使選擇小區間變量,一些共線性的相關變量依舊存在,且在實際建模中變量數仍然很多。因此,Dong等[13]采用自適應權重加權算法對Si?PLS優選的近紅外光譜區間變量再次進行特征選擇,利用極限學習機結合自適應提升算法建立工夫紅茶發酵過程中茶黃素與茶紅霉素比值快速檢測模型,模型預測集決定系數為0.893,預測均方根誤差為0.004 4。【本研究切入點】面對光譜數據中的大量特征變量,需考慮變量選擇過程計算速度和精度,混合特征篩選方法越來越多的被研究者所關注。【擬解決的關鍵問題】本文采用變量組成集群分析?迭代保留信息變量混合特征提取方法對茶葉浸出物近紅外光譜波長變量進行優選,利用篩選出的特征波長建立隨機森林(randomforest,RF)茶葉滋味品質指標酚氨比預測模型,并與線性偏最小二乘(partial least squares,PLS)模型進行比較。
1 材料與方法
1.1 樣本制備
選取來自不同省份的93個不同等級市售茶葉樣本,所收集的樣本均經過正常的處理和儲存,以確保在處理過程中不會出現明顯的變質。首先,每個樣本稱取3 g干茶加入150 mL沸騰蒸餾水中,蓋上杯蓋浸泡5 min。用濾紙過濾后,待冷卻至25 ℃左右進行后續測定分析。
1.2 酚氨比化學測定
每個樣品取10 mL上層浸出液,滴入25 mL的容量瓶中,用蒸餾水稀釋刻度線。采用福林酚試劑比色法,依據GB/T 8313-2008《茶葉中茶多酚和兒茶素類含量的檢測方法》國家標準進行茶多酚測定;采用茚三酮分光光度法,依據GB/T 8314-2013《茶游離氨基酸總量的測定》國家標準進行氨基酸測定。酚氨比由茶多酚總量除以氨基酸總量得來。圖1所示為茶葉樣本酚氨比統計圖,所有樣本酚氨比呈正態分布。
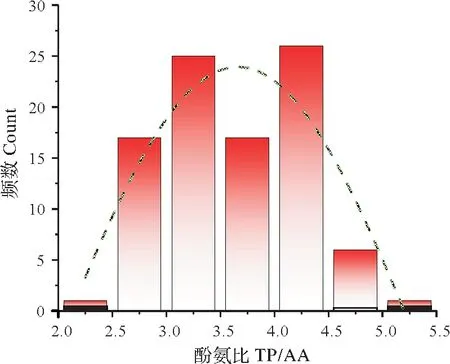
圖1 茶葉樣本酚氨比統計Fig.1 Statistical diagram of ratio of TP to AA for tea samples
1.3 近紅外光譜采集
Antaris II型近紅外光譜儀(美國Thermo Fisher公司)用于檢測茶葉浸出液,并利用InGaAs檢測器光譜數據采集。光譜掃描范圍為10 000~4 000 cm?1,分辨率為3.856 cm?1,掃描次數為32,每個樣本具有1 557個光譜數據。吸光度數據以log(1/R)的形式存儲,R表示透射率。每個樣本被測定3次,以3個光譜的平均值作為該樣本最終光譜數據。由于茶葉浸出液中可能存在氣泡等因素,導致光散射[14],原始光譜中除分析物自身信息外,還包含一些噪音信息。標準正態變量變換(standard normalvariate transformation,SNV)能夠有效消除散射引起的噪音,提高光譜信噪比。因此,在預測模型建立之前選擇SNV方法對茶湯近紅外光譜進行預處理,圖2所示為經預處理后所有樣本光譜圖。
1.4 變量組成集群分析-迭代保留信息變量混合特征提取方法
1.4.1 變量組成集群分析 變量組成集群分析(vari-able combination population analysis,VCPA)[15]是一種基于達爾文“適者生存”進化論的變量選擇方法。該方法主要運用指數衰減函數(exponentially decreasing function,EDF),二進制矩陣采樣法(binary matrix sampling,BMS)和模型集群分析(model population analysis,MPA)從變量空間中選取最優變量子集。首先,采用EDF確定每次迭代剩余變量數,BMS根據剩余變量數從變量空間進行采用組成若干變量子集。然后,利用各變量子集分別建立偏最小二乘子模型,采用MPA方法從前10%的最優子模型中保留出現頻數最多的變量。在保留的變量空間上再次重復以上操作,迭代N次,最終篩選出最優的變量子集[16]。
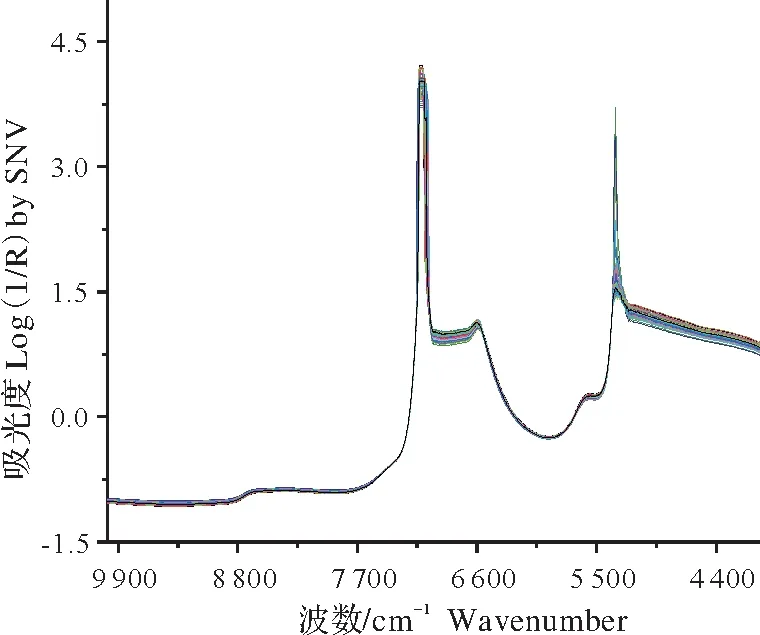
圖2 SNV預處理后的茶湯光譜Fig.2 NIR spectra of tea infusion by SNV preprocessing
1.4.2 迭代保留信息變量 迭代保留信息變量(iteratively retains informative variables,IRIV)[17]把變量分為4類:降低模型性能明顯的干擾信息變量,降低模型性能不明顯的無信息變量,提高模型性能不明顯的弱信息變量和提高模型性能明顯的強信息變量。IRIV可以有效地提出干擾信息變量和無信息變量,并保留弱信息變量和強信息變量[18]。IRIV采用BMS從變量空間進行隨機采用,對于每個變量,IRIV觀察其在所有變量組合中的包含與排除是交叉驗證均方根誤差(root mean square error of crossvalidation,RM-SECV)的差異,而其他變量的狀態(包含或排除)保持不變。每個變量的重要性是根據RMSECV的差異來評估的。如果當RMSECV被排除在變量組合之外時,RMSECV會增加,這表明該變量是有用的和信息豐富的。不斷重復排除策略,直到變量子集中不包含干擾信息變量和無關信息變量。
1.4.3 混合特征提取方法 VCPA采用EDF方法快速剔除變量,最終篩選出的變量數通常較少,一些信息變量可能會被剔除;而IRIV方法充分考慮到每個變量的重要性,因此需要大量的計算時間,當面對大量的變量時,會耗費大量的時間,導致計算效率低下。VCPA?IRIV混合方法能夠充分發揮兩種方法各自優勢、彌補不足。首先采用VCPA進行快速縮小變量空間,設置最終剩余變量數為N;然后再通過IRIV評估剩余變量空間中每個變量的重要性,以優選出最佳變量子集。
1.5 模型建立與評價
采用線性PLS和非線性隨機森林[19]建立茶葉滋味品質成分檢測模型,采用相關系數(R)評價模型預測值與實驗值之間的相關程度,其值范圍為0~1,且越接近1越好;以訓練集均方根誤差(root mean square error of calibration,RMSEC)評價模型訓練誤差,預測集均方根誤差(root mean square error of predic-tion,RMSEP)評價模型預測誤差,其值越小越好;以預測集相對分析誤差(relative percent deviation,RPD)評價模型性能可靠程度。如果RPD大于3.0,說明模型性能可靠,預測精度好,可用于實際檢測;RPD在2.5~3.0,說明模型可靠性有待提高,只能用于實際估測;RPD在2.0~2.5,模型可以近似定量預測;RPD值小于2.0,方法預測不可靠。
2 結果與分析
2.1 光譜特征提取
采用Kennard?Stone(KS)方法將93個樣本劃分為訓練集和測試集,60個樣本作為訓練集用于訓練模型,其余33個樣本為預測集預測模型性能。利用VCPA?IRIV在訓練樣本集上進行特征提取,VCPA?IRIV方法超參數EDF剩余變量數設置為100,迭代次數為50,最優子模型的比例為10%,BMS運行次數為1 000,并采用5折交叉驗證進行變量重要性評價。通過VCPA?IRIV方法最終優選出18個光譜特征,圖3所示為特征變量選擇結果,圖中“★”所標記光譜特征為算法優選的變量子集。從光譜圖(圖1)可知光譜在5 155 cm?1和6 900~7 140 cm?1處分別存在與H2O的O?H第一泛音和H2O中O?H基團的拉伸變形結合有關的強吸收帶。如果用這些強吸收光譜變量來建立校正模型,會影響模型的性能。然而,VCPA?IRIV方法所選的特征變量很好地避開了與H2O強相關的光譜特征信息,表明該方法所提取特征的有效性。
表1所示為采用VCPA?IRIV算法選擇的18個光譜特征及其對應的鍵,其中9 889.177,9 862.179 cm?1為茶多酚與氨基酸上N?H的二級倍頻吸收峰,8 759.096,8 782.237,8 882.518,8 535.394 cm?1為茶多酚與氨基酸C?H的二級倍頻吸收峰,5 904.965,5 951.248,6 032.244,6 124.81,6 225.09,6 255.946,6 263.66 cm?1為C?H和S?H的一級倍頻吸收峰[20],表明VCPA?IRIV方法提取的光譜特征信息可用于茶葉滋味品質指標酚氨比的有效預測。
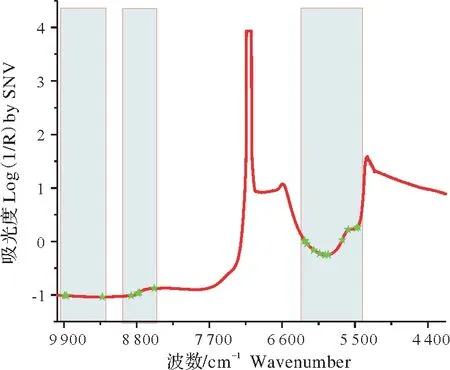
圖3 利用VCPA?IRIV選擇特征變量結果Fig.3 The result of features selected by VCPA?IRIValgorithm

表1 采用VCPA-IRIV算法選擇光譜特征及其對應的鍵Tab.1 Selected spectra intervals by VCPA-IRIV algorithm and their corresponding bonds
2.2 RF預測模型建立
采用VCPA?IRIV方法提取的特征變量,建立隨機森林綠茶滋味品質指標酚氨比預測模型。設置RF算法的超參數回歸數棵數(ntree)為1 000,節點分裂候選變量數(mtry)為所有變量數的1/3,即為6。圖4所示為訓練集和測試集中各樣本的實驗值與RF模型預測值對比圖。由圖4可知,RF模型訓練集的Rc和RMSEC為別為0.949,0.231;測試集的Rp和RMSEP分別為0.943和0.232,表明模型具有較好的泛化性能。測試集的RPD為3.019,說明模型性能可靠,預測精度好,可用于實際檢測。
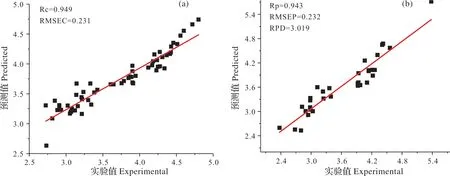
圖4 訓練集(a)和測試集(b)中樣本實驗值與預測值對比圖Fig.4 Comparison of experimental and predicted values of samples in calibration set(a)and prediction set(b)
2.3 模型性能比較
為了進一步表現VCPA?IRIV方法提取光譜特征的有效性,采用競爭性自適應重加權算法[21](com-petitive adaptive reweighted sampling,CARS)和連續投影算法[22](successive projections algorithm,SPA)進行光譜特征選擇比較。表2所示為基于VCPA?IRIV、CARS和SPA提取的特征所建立的PLS與RF預測模型性能比較結果。結果表明,CARS和SPA提取的光譜變量中均集中H2O的強吸收帶(5 155 cm?1和6 900~7 140 cm?1)附近,以這些變量作為輸入所建預測模型的預測效果均較差。VCPA?IRIV提取的光譜變量所建的預測模型中,線性PLS預測模型主成分為10時,模型性能最佳,訓練集的Rc和RMSEC為別為0.920,0.256;測試集的Rp和RMSEP分別為0.907和0.307;測試集的RPD為2.281;表明非線性的RF模型在魯棒性和泛化性能上均優于線性的PLS模型。
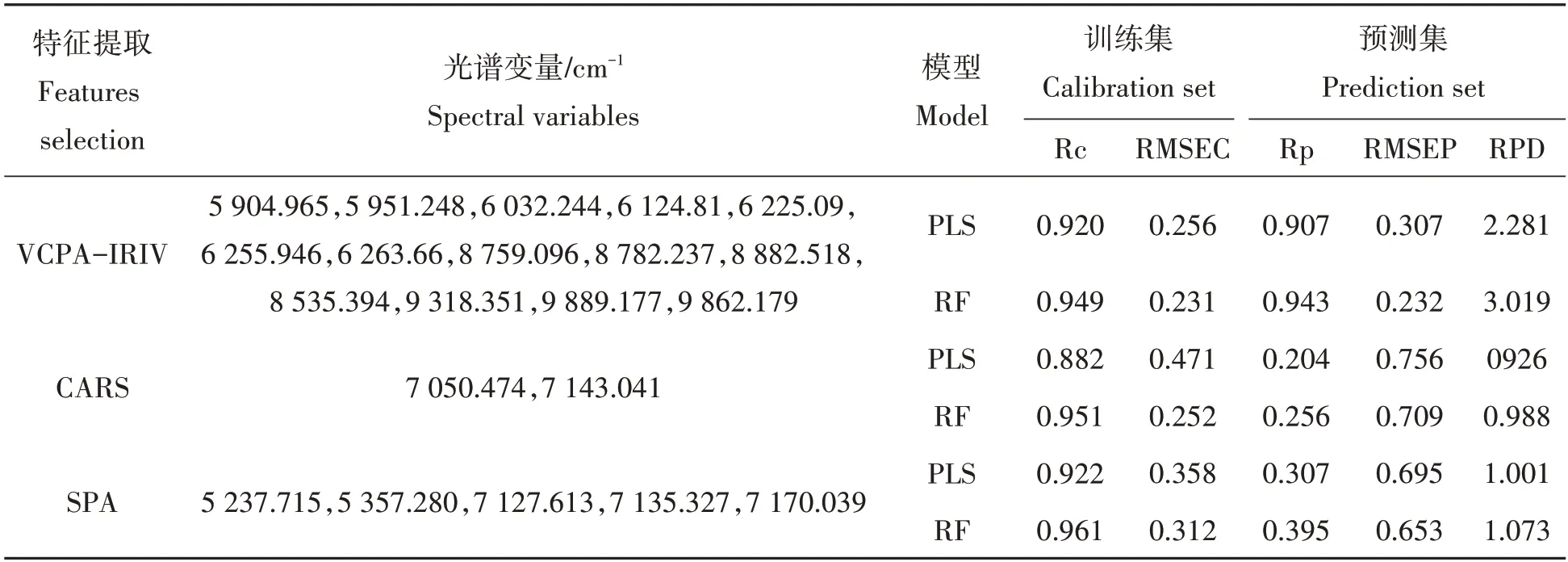
表2 VCPA-IRIV、CARS和SPA提取的特征所建不同預測模型性能比較Tab.2 Comparison of results based on different models based on VCPA-IRIV,CARS and SPA
3 結論與討論
本研究利用近紅外光譜技術結合化學計量學方法實現綠茶滋味品質指標酚氨比值的快速檢測方法。綠茶浸出物近紅外光譜信息中,H2O的強干擾信息及其他冗余信息的引入將嚴重影響綠茶滋味品質指標酚氨比的檢測模型性能。利用VCPA?IRIV、CARS和SPA 3種不同特征提取方法對近紅外光譜變量進行優選,CARS和SPA提取的光譜變量中均集中H20的強吸收帶附近,而VCPA?IRIV方法提取的18個特征光譜變量大多與茶多酚和氨基酸相關,很好地避開了H20的強吸收帶。
此外,近紅外光譜根據當樣品被輻射時復雜有機物中不同的化學鍵吸收或發射不同波長光的原理對分析物進行檢測,由于有機物的分子有各種各樣的振動和化學鍵,它們的光譜響應通常并非簡單的線性耦合在一起,分析物濃度和光譜數據常常呈現非線性關系[23]。利用非線性RF所建綠茶滋味品質指標酚氨比值快速檢測模型性能明顯優于線性PLS模型。VCPA?IRIV優選的18個特征變量作為輸入建立的非線性RF模型性能最佳,訓練集Rc和RMSEC為別為0.949,0.231;測試集的Rp、RMSEP和RPD分別為0.943、0.232和3.019。研究表明VCPA?IRIV方法能夠有效的提出有效光譜變量,消除冗余光譜信息;為利用近紅外光譜技術對綠茶滋味品質指標酚氨比值快速檢測方法提供了新的研究思路,且有助于光譜技術在農產品品質與安全上的推廣運用。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
意林原創版(2016年10期)2016-11-25 10:28:30
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
中外會展(2014年4期)2014-11-27 07:46:46
