融合學(xué)習(xí)模型的巖石光譜特征自動分類
2021-01-06 03:03:00賀金鑫任小玉陳圣波肖志強(qiáng)
光譜學(xué)與光譜分析 2021年1期
賀金鑫,任小玉,陳圣波,熊 玥,肖志強(qiáng),周 孩
1. 吉林大學(xué)地球科學(xué)學(xué)院,吉林 長春 130061 2. 吉林大學(xué)地球探測科學(xué)與技術(shù)學(xué)院,吉林 長春 130061
引 言
在遙感地質(zhì)領(lǐng)域,巖石光譜一直是熱門研究方向之一,主要包括成像光譜巖礦識別、巖石光譜特征分析、影響巖石光譜的因素以及巖石光譜分類。在巖石光譜分類方面,吳輝等基于AVIRIS航空高光譜遙感數(shù)據(jù),首先將預(yù)處理后的數(shù)據(jù)進(jìn)行最小噪聲分離,然后用PPI算法選擇研究對象,最后用線性光譜混合分類模型進(jìn)行巖性分類研究[1]; 張翠芬等人將巖石單元的圖形紋理特征及光譜特征進(jìn)行協(xié)同分類研究,用面對對象方法進(jìn)行圖譜指數(shù)分割,然后用光譜指數(shù)提取巖石信息,劃分精度較好[2]; 徐清俊等人使用ASD光譜儀測量鉆孔巖心數(shù)據(jù),利用ViewSpecpro軟件進(jìn)行格式轉(zhuǎn)換,輸入到ENVI軟件建成光譜庫,與美國USGS光譜庫中典型礦物光譜曲線進(jìn)行對比分析,進(jìn)而識別巖性得出結(jié)論[3]; 周江將ASD光譜儀的光譜曲線與遙感影像通過ENVI軟件相結(jié)合對巖石等地物進(jìn)行分類,與用神經(jīng)網(wǎng)絡(luò)進(jìn)行監(jiān)督分類的結(jié)果相對比[4]。總之,該領(lǐng)域目前的主要問題在于要么是將數(shù)據(jù)進(jìn)行一系列復(fù)雜預(yù)處理后利用傳統(tǒng)模型進(jìn)行分類; 要么因?yàn)閹r石光譜的特殊性,沒有統(tǒng)一的光譜曲線標(biāo)準(zhǔn),使得分類結(jié)果不夠準(zhǔn)確。因此,本文擬在不對巖石光譜數(shù)據(jù)進(jìn)行復(fù)雜預(yù)處理的前提下,構(gòu)建一種基于融合多種機(jī)器學(xué)習(xí)模型的巖石光譜特征自動分類方法; 并與單一分類模型相對比,最終取得更高的分類準(zhǔn)確率。
1 巖石光譜數(shù)據(jù)
1.1 研究區(qū)概況
研究區(qū)位于遼寧省興城市,區(qū)域地貌屬遼西山地黑山丘陵東部邊緣的海濱丘陵,海拔在20~500 m之間,相對高差200~350 m,地勢總體呈西北高而東南低,區(qū)內(nèi)河流發(fā)育,有六股河、煙臺河等匯入遼東灣; 氣候?qū)儆诒卑肭蚺瘻貛啙駶櫄夂颍瑲夂驕睾停蓾裣嘁薣5]。
興城地區(qū)出露的地層為典型的華北型,地層從太古宙到中—新元古界、古生界、中生界和新生界都有分布,發(fā)育較為齊全,主要巖石類型有花崗巖、砂巖、頁巖、白云巖、灰?guī)r、安山巖、玄武巖等[5](如圖1所示)。

圖1 研究區(qū)巖性分布圖 1: 第四系: 礫石、黃土、粉質(zhì)粘土; 2: 閃長巖; 3: 灰?guī)r; 4: 花崗巖; 5: 砂巖; 6: 安山巖; 7: 玄武巖Fig.1 Distribution of rocks in the study area
1.2 巖石光譜測量
用于測量巖石光譜的儀器為美國FieldSpec-3型便攜式實(shí)測光譜儀,所測波長從350 nm的可見光范圍分布到2 500 nm的短波紅外范圍。可見光的光譜測量間隔為1.4 nm,分辨率約為3 nm; 短波紅外的間隔為2 nm,分辨率為6.5~8.5 nm[6]。
目前取得已命名巖石光譜類型有二長花崗巖、花崗斑巖、石英砂巖、中粒巖屑長石砂巖、白云質(zhì)灰?guī)r、鮞狀灰?guī)r、燧石條帶白云巖等。將測量得到的光譜數(shù)據(jù)進(jìn)行整合,最終得到灰?guī)r類379條數(shù)據(jù)、花崗巖類147條數(shù)據(jù)、砂巖類82條數(shù)據(jù),其余類別由于數(shù)據(jù)量過少,暫不予以分類研究(如圖2所示)。
1.3 巖石光譜特征
巖石光譜形狀與其成分、含量等等因素都密切相關(guān)。而同種巖石光譜形態(tài)基本相似; 實(shí)驗(yàn)所得數(shù)據(jù)中,花崗巖和砂巖在1 400 nm左右處都存在水汽吸收帶(如圖3、圖5所示),在1 900 nm處,三類巖石光譜都存在較強(qiáng)吸收谷(如圖3—圖5所示); 花崗巖總體反射率在0~0.5之間,灰?guī)r總體反射率在0~0.7之間,砂巖總體反射率在0~0.6之間(如圖3—圖5所示); 砂巖在900 nm處存在鐵離子吸收譜帶,灰?guī)r在2 300 nm處產(chǎn)生碳酸根離子的特征吸收,石英砂巖、白云巖等幾類巖石在2 200 nm左右處有一個吸收谷,是由于羥基吸收所引起的[5]。
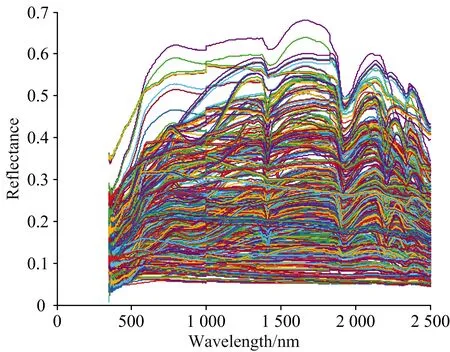
圖2 總樣品數(shù)據(jù)集的巖石光譜反射率Fig.2 Reflectance spectra of the whole samples

圖3 花崗巖光譜反射率Fig.3 Reflectance spectra of granite

圖4 灰?guī)r光譜反射率Fig.4 Reflectance spectra of limestone

圖5 砂巖光譜反射率Fig.5 Reflectance spectra of sandstone
2 巖石光譜特征自動分類
2.1 決策樹模型
決策樹(decision tree,DT)是一個自上而下構(gòu)建的樹形模型,包括根節(jié)點(diǎn),父節(jié)點(diǎn)和子節(jié)點(diǎn),一個分支就代表一個測試輸出。采用了決策樹模型中的CART算法,相比傳統(tǒng)數(shù)學(xué)統(tǒng)計(jì)方法分類更準(zhǔn)確,且數(shù)據(jù)量越大越容易顯現(xiàn)其優(yōu)越性。CART算法計(jì)算基尼系數(shù)來評判數(shù)據(jù)劃分前后的分類效果,基尼系數(shù)越小證明數(shù)據(jù)純度越高; 所以選擇能使分類后得到的基尼系數(shù)最小的特征,將其作為樹中節(jié)點(diǎn)[7]。用CART決策樹對三類巖石光譜數(shù)據(jù)的訓(xùn)練集建模,然后用測試集檢驗(yàn)分類效果。將樹的深度設(shè)置為10; 節(jié)點(diǎn)不純度小于0.02,即不再生成子節(jié)點(diǎn),節(jié)點(diǎn)再劃分所需最小樣本數(shù)設(shè)為2。
2.2 隨機(jī)森林模型
為提高分類準(zhǔn)確率,又選取了決策樹的升級模型——隨機(jī)森林(random forest,RF),它是基于bagging策略的集成學(xué)習(xí),通過多棵樹對數(shù)據(jù)樣本分類。包含兩個隨機(jī)過程: 一是輸入數(shù)據(jù)隨機(jī); 二是分類特征隨機(jī)選取。這樣就得到了多顆CART決策樹弱分類器,再將多個分類器采取投票法的策略,投出票數(shù)最多的作為最終結(jié)果[8]。RF的參數(shù)也分為兩部分: 一是隨機(jī)森林的Bagging框架參數(shù),其中CART決策樹的最大迭代次數(shù)設(shè)置為1 000,劃分CART決策樹特征的評價標(biāo)準(zhǔn)選用基尼系數(shù); 二是決策樹參數(shù),深度25,劃分最大特征數(shù)為45,節(jié)點(diǎn)再劃分所需最小樣本數(shù)設(shè)為2。
2.3 K-最近鄰模型
隨機(jī)森林模型在數(shù)據(jù)噪音較大時易陷入過擬合,且數(shù)據(jù)特征過多時也會對模型準(zhǔn)確率造成較大影響。而K-最近鄰模型(K-nearest neighbor,KNN)依據(jù)不同特征值間的距離進(jìn)行分類,不存在訓(xùn)練過程,只是將最近的劃分為一類。先將數(shù)據(jù)標(biāo)準(zhǔn)化; 然后算出輸入的數(shù)據(jù)與測試集的數(shù)據(jù)的距離,實(shí)驗(yàn)采取的計(jì)算距離方法為閔可夫斯基距離; 找出距離最近的k個,這里k設(shè)置為1; 將出現(xiàn)最多的類別作為輸入數(shù)據(jù)的類別[9]。但KNN需要對每個樣本都予以考慮,當(dāng)數(shù)據(jù)量大時計(jì)算量會很大,效率不高。
2.4 支持向量機(jī)模型
支持向量機(jī)模型(support vector machine,SVM)是通過在數(shù)據(jù)間找到距離最大處來工作的,而數(shù)據(jù)是否線性可分決定著是用硬間隔最大化還是軟間隔最大化[10]。由于巖石光譜數(shù)據(jù)非線性可分,因而將數(shù)據(jù)映射到新空間,使之線性可分。核函數(shù)選高斯核函數(shù); 懲罰系數(shù)設(shè)為10; gamma值設(shè)定為1。
2.5 多種模型相融合
為進(jìn)一步提高巖石光譜特征自動分類的準(zhǔn)確率,采取了融合多個不同模型的辦法,即對不同模型的分類結(jié)果進(jìn)行投票,選擇投票最多的作為最后分類結(jié)果。在此基礎(chǔ)上又分為硬投票和軟投票,硬投票是直接對模型投票而軟投票加入了權(quán)重,可以區(qū)分不同模型的重要度,但二者的基本原則都是少數(shù)服從多數(shù)。由于硬投票可在一定程度上減少過擬合現(xiàn)象的發(fā)生,更加適合分類模型,所以選用了硬投票方法。
3 結(jié)果與討論
將巖石光譜數(shù)據(jù)特征分別導(dǎo)入DT,RF,KNN,SVM以及融合模型(全部基于Python語言編程實(shí)現(xiàn))之中,分類結(jié)果如表1所示。可以看出在四種單一分類模型中: 效果最好的是支持向量機(jī),分類準(zhǔn)確率為98.76%; 其次是K-最近鄰,準(zhǔn)確率為97.10%; 然后是隨機(jī)森林,準(zhǔn)確率為93.80%; 最后是決策樹模型,準(zhǔn)確率為88.84%。而將RF,KNN和SVM三種模型融合后得到的巖石光譜分類準(zhǔn)確率可達(dá)到99.17%。

表1 不同模型的巖石光譜特征自動分類準(zhǔn)確率Table 1 Classification accuracy of rock spectrabased on different models
4 結(jié) 論
在遼寧興城地區(qū)實(shí)測的不同巖石反射光譜數(shù)據(jù)特征基礎(chǔ)之上,分別利用DT,RF,KNN,SVM以及融合模型,進(jìn)行了巖石光譜特征自動分類研究。從測試結(jié)果可以看出: 第一,如果不考慮影響巖石光譜特征的各種因素,直接從光譜數(shù)據(jù)特征本身入手,可以發(fā)現(xiàn)機(jī)器學(xué)習(xí)模型的分類能力相對于傳統(tǒng)的巖石光譜分類方式,效率更高、分類準(zhǔn)確率更好; 第二,四種單一機(jī)器學(xué)習(xí)模型的分類準(zhǔn)確率高低排序?yàn)椋?SVM>KNN>RF>DT; 第三,采用了多種模型融合學(xué)習(xí)的方法,進(jìn)一步提高了巖石光譜特征自動分類的準(zhǔn)確率,可達(dá)99.17%。在后續(xù)研究工作中,將繼續(xù)優(yōu)化現(xiàn)有模型,使之不僅能劃分巖石大類,還能準(zhǔn)確地對細(xì)類巖性進(jìn)行劃分。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
